
A Proposed Priority Pushing and Grasping Strategy Based on an Improved Actor-Critic Algorithm


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- To calculate the TD-Target, use the CME optimization algorithm to select the best action in continuous space.
- Softmax operations are used to improve the temporal differencing method in the policy gradient algorithm.
- Improving the experience replay structure by sampling with a priority sampling strategy, which is then used to propose a dynamic sampling approach.
2. Related Work
2.1. Deep Learning for Robotic Grasping
2.2. Reinforcement Learning for Robotic Grasping
3. Methods
3.1. Reinforcement Learning
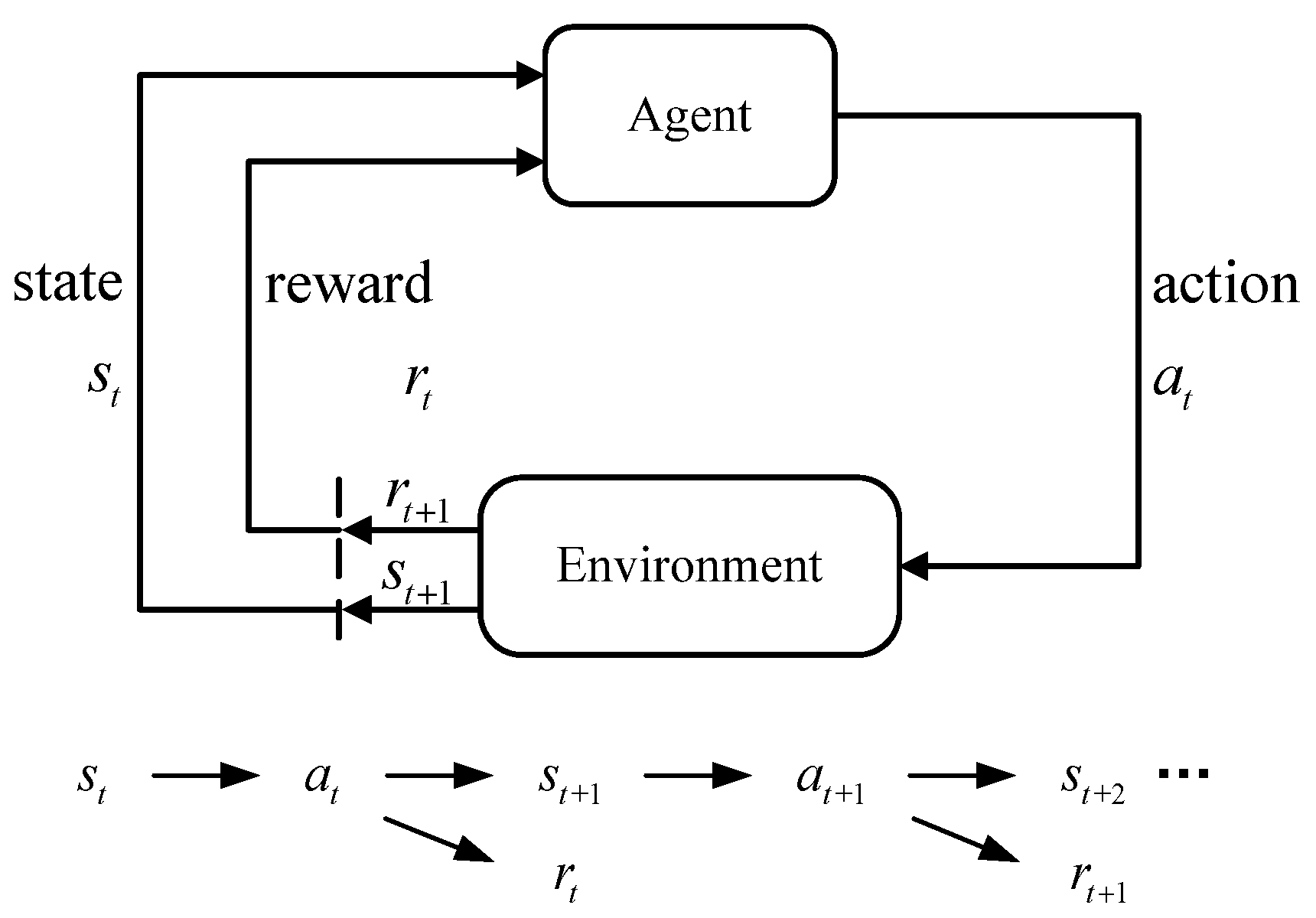
3.2. State Space
3.3. Rewards
3.4. Network
| Algorithm 1 Detailed steps of the improved algorithm CSAC-PER |
3.5. Dynamic Prioritized Experience Replay
4. Experimental Results
4.1. Baseline Methods
- (1)
- Grasping-only is a greedy deterministic grasping strategy that uses a fully convolutional network to predict the action and uses a greedy strategy to select the next action to be executed [38].
- (2)
- VPG maps action Q values by two action full convolutional networks and uses reinforcement learning methods to learn the synergy between “push” and “grasp” to achieve target grasping.
4.2. Evaluation Metrics
4.3. Simulation Experiments
4.4. Evaluation Tests
5. Conclusions
6. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, W.J.; Yang, G.; Lin, Y.; Ji, C.; Gupta, M.M. On definition of deep learning. In Proceedings of the 2018 World Automation Congress (WAC), Stevenson, WA, USA, 3–6 June 2018; pp. 1–5. [Google Scholar]
- Zeng, A.; Song, S.; Welker, S.; Lee, J.; Rodriguez, A.; Funkhouser, T. Learning synergies between pushing and grasping with self-supervised deep reinforcement learning. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4238–4245. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Bahdanau, D.; Brakel, P.; Xu, K.; Goyal, A.; Lowe, R.; Pineau, J.; Courville, A.; Bengio, Y. An actor-critic algorithm for sequence prediction. arXiv 2016, arXiv:1607.07086. [Google Scholar]
- Rubinstein, R.Y.; Kroese, D.P. The Cross-Entropy Method: A Unified Approach to Combinatorial Optimization, Monte-Carlo Simulation, and Machine Learning; Springer: New York, NY, USA, 2004. [Google Scholar]
- Pan, L.; Cai, Q.; Huang, L. Softmax deep double deterministic policy gradients. Adv. Neural Inf. Process. Syst. 2020, 33, 11767–11777. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]
- Zhao, D.; Wang, H.; Shao, K.; Zhu, Y. Deep reinforcement learning with experience replay based on SARSA. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016; pp. 1–6. [Google Scholar]
- Fang, M.; Li, Y.; Cohn, T. Learning how to active learn: A deep reinforcement learning approach. arXiv 2017, arXiv:1708.02383. [Google Scholar]
- Lenz, I.; Lee, H.; Saxena, A. Deep learning for detecting robotic grasps. Int. J. Robot. Res. 2015, 34, 705–724. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Angelova, A. Real-time grasp detection using convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1316–1322. [Google Scholar]
- Mahler, J.; Liang, J.; Niyaz, S.; Laskey, M.; Doan, R.; Liu, X.; Ojea, J.A.; Goldberg, K. Dex-net 2.0: Deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics. arXiv 2017, arXiv:1703.09312. [Google Scholar]
- Chu, F.J.; Xu, R.; Vela, P.A. Real-world multiobject, multigrasp detection. IEEE Robot. Autom. Lett. 2018, 3, 3355–3362. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Han, M.; Pan, Z.; Xue, T.; Shao, Q.; Ma, J.; Wang, W. Object-agnostic suction grasp affordance detection in dense cluster using self-supervised learning. Docx. arXiv 2019, arXiv:1906.02995. [Google Scholar]
- Wang, C.; Xu, D.; Zhu, Y.; Martín-Martín, R.; Lu, C.; Fei-Fei, L.; Savarese, S. Densefusion: 6d object pose estimation by iterative dense fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3343–3352. [Google Scholar]
- Pinto, L.; Gupta, A. Supersizing self-supervision: Learning to grasp from 50k tries and 700 robot hours. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 3406–3413. [Google Scholar]
- Levine, S.; Pastor, P.; Krizhevsky, A.; Ibarz, J.; Quillen, D. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection. Int. J. Robot. Res. 2017, 37, 027836491771031. [Google Scholar] [CrossRef]
- Kalashnikov, D.; Irpan, A.; Pastor, P.; Ibarz, J.; Herzog, A.; Jang, E.; Quillen, D.; Holly, E.; Kalakrishnan, M.; Vanhoucke, V.; et al. Qt-opt: Scalable deep reinforcement learning for vision-based robotic manipulation (2018). arXiv 2018, arXiv:1806.10293. [Google Scholar]
- Quillen, D.; Jang, E.; Nachum, O.; Finn, C.; Ibarz, J.; Levine, S. Deep reinforcement learning for vision-based robotic grasping: A simulated comparative evaluation of off-policy methods. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 6284–6291. [Google Scholar]
- Breyer, M.; Furrer, F.; Novkovic, T.; Siegwart, R.; Nieto, J. Comparing task simplifications to learn closed-loop object picking using deep reinforcement learning. IEEE Robot. Autom. Lett. 2019, 4, 1549–1556. [Google Scholar] [CrossRef] [Green Version]
- Clavera, I.; Held, D.; Abbeel, P. Policy transfer via modularity and reward guiding. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1537–1544. [Google Scholar] [CrossRef]
- Haarnoja, T.; Pong, V.; Zhou, A.; Dalal, M.; Abbeel, P.; Levine, S. Composable deep reinforcement learning for robotic manipulation. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 6244–6251. [Google Scholar]
- Singh, A.; Yang, L.; Hartikainen, K.; Finn, C.; Levine, S. End-to-end robotic reinforcement learning without reward engineering. arXiv 2019, arXiv:1904.07854. [Google Scholar]
- Liang, H.; Lou, X.; Choi, C. Knowledge induced deep q-network for a slide-to-wall object grasping. arXiv 2019, arXiv:1910.03781. [Google Scholar]
- Joshi, S.; Kumra, S.; Sahin, F. Robotic grasping using deep reinforcement learning. In Proceedings of the 2020 IEEE 16th International Conference on Automation Science and Engineering (CASE), Hong Kong, China, 20–21 August 2020; pp. 1461–1466. [Google Scholar]
- Xu, K.; Yu, H.; Lai, Q.; Wang, Y.; Xiong, R. Efficient learning of goal-oriented push-grasping synergy in clutter. IEEE Robot. Autom. Lett. 2021, 6, 6337–6344. [Google Scholar] [CrossRef]
- Yang, Y.; Liang, H.; Choi, C. A deep learning approach to grasping the invisible. IEEE Robot. Autom. Lett. 2020, 5, 2232–2239. [Google Scholar] [CrossRef] [Green Version]
- Jaakkola, T.; Singh, S.; Jordan, M. Reinforcement learning algorithm for partially observable Markov decision problems. In Proceedings of the 7th International Conference on Neural Information Processing Systems, Denver, CO, USA, 28 November–1 December 1994; pp. 345–352. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Hundt, A.; Killeen, B.; Greene, N.; Wu, H.; Kwon, H.; Paxton, C.; Hager, G.D. “Good robot!”: Efficient reinforcement learning for multi-step visual tasks with SIM to real transfer. IEEE Robot. Autom. Lett. 2020, 5, 6724–6731. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the Icml, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Ferrari, S.; Cribari-Neto, F. Beta regression for modelling rates and proportions. J. Appl. Stat. 2004, 31, 799–815. [Google Scholar] [CrossRef]
- Zeng, A.; Song, S.; Yu, K.T.; Donlon, E.; Hogan, F.R.; Bauza, M.; Ma, D.; Taylor, O.; Liu, M.; Romo, E.; et al. Robotic pick-and-place of novel objects in clutter with multi-affordance grasping and cross-domain image matching. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 3750–3757. [Google Scholar]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
You, T.; Wu, H.; Xu, X.; Petrovic, P.B.; Rodić, A. A Proposed Priority Pushing and Grasping Strategy Based on an Improved Actor-Critic Algorithm. Electronics 2022, 11, 2065. https://doi.org/10.3390/electronics11132065
You T, Wu H, Xu X, Petrovic PB, Rodić A. A Proposed Priority Pushing and Grasping Strategy Based on an Improved Actor-Critic Algorithm. Electronics. 2022; 11(13):2065. https://doi.org/10.3390/electronics11132065
Chicago/Turabian StyleYou, Tianya, Hao Wu, Xiangrong Xu, Petar B. Petrovic, and Aleksandar Rodić. 2022. "A Proposed Priority Pushing and Grasping Strategy Based on an Improved Actor-Critic Algorithm" Electronics 11, no. 13: 2065. https://doi.org/10.3390/electronics11132065