In this section, based on BERT, our pre-training and fine-tuning framework for MEL will be introduced. We will first define the MEL task, and then some terms we used are also explained. Next, we will introduce our three different categories of pre-training tasks, and
Figure 2,
Figure 3 and
Figure 4 show the overview of the tasks. Furthermore, the framework of fine-tuning for MEL is the same as the framework for multimodal pre-training in
Figure 4.
3.1. Task Definition
Just like the general entity linking, the goal of MEL is also mapping the ambiguous mention in input to the entity in a KB. Specifically, in our task, we have the input set where denotes a tweet consisting of a text-image pair , and the mention in the have been already marked as . The KB in our task is a set of entities, i.e., , where denotes a twitter user and can be represented as a two-tuple of user information and timeline . The comes from user profile and includes (e.g., @AndrewYNg), (e.g., Andrew Ng), (e.g., Palo Alto, CA, USA) and (e.g., Co-Founder of Coursera; Stanford CS adjunct faculty. Former head of Baidu AI Group/Google Brain. #ai #machinelearning, #deeplearning #MOOCs) and the denotes all the tweets with images posted by this user.
Before we map the ambiguous mention to a certain entity, candidate generation is an essential step. A candidate set according to the mention can be generated by surface form matching, dictionary lookup and prior probability. In this paper, entities whose contain a mention are considered candidate entities for this mention.
Finally, a score between the mention
in the input tweet and the entity
in the candidate set
is obtained as an evaluation of correlation, and the entity with the highest score is considered to be the ground truth entity.
3.2. Representation
In this section, we will introduce the textual data format used in this paper and the way to the extract visual features. For the mention representation, the
denotes the context of the mention in the tweet, and
denotes the image of the tweet. We use the tokenizer to process the text and pre-trained ResNet50 model to obtain 2048-dimensional image features. The 2048-dimensional image features are finally converted to the same dimension as the text features by a fully-connected layer.
W is a
matrix and
b is a 768-dimensional vector.
Considering that the entities in the KB we used are regular users of Twitter, we use their user profiles to construct the entity context. If the corresponding information is not available, NA is selected as a default. userDescription uses up to the first 30 words. , and mean the last 3 tweets in the timeLine of this user. In addition, considering the length of the entity context, each tweets selects at most the first 35 words.
The format of the is: the username of @userScreen who lives in userLocation is userName and the description is userDescription. some recent tweets of the user include: , and .
The
is handled like
. For the visual features of entities, we process the all images from the user’s
like the mention images, and the final visual representation is obtained by averaging over all these image features.
is the image set of entity’s
and
means the size of the set.
W and
b are the same as in the processing of
above.
3.3. Pre-Training
In this section, we introduce three different types of NSP for pre-training, i.e., mixed-modal, text-only, and multimodal. For NSP, we have sentence = {text, image, , } where and belong to the same input tweet and and belong to the same entity which is the ground truth entity of the mention in the previous input tweet. Therefore, unlike the general NSP task, the input information and the entity information parts of the same we construct are related. With 50% probability, for each sentence in the set of sentences sentences = {, , ..., }, we randomly select a sentence from the set as its next sentence = {, , , } and set the label to 1. With another 50% probability, we select itself as the next sentence and set the label to 0.
Next, for mixed-modal NSP, we use the text from sentence and from to predict the label . In addition to this, the in sentence and the in are also used to predict the label . This type of tasks can help our model to better interact text and image features to determine whether text are related to images.
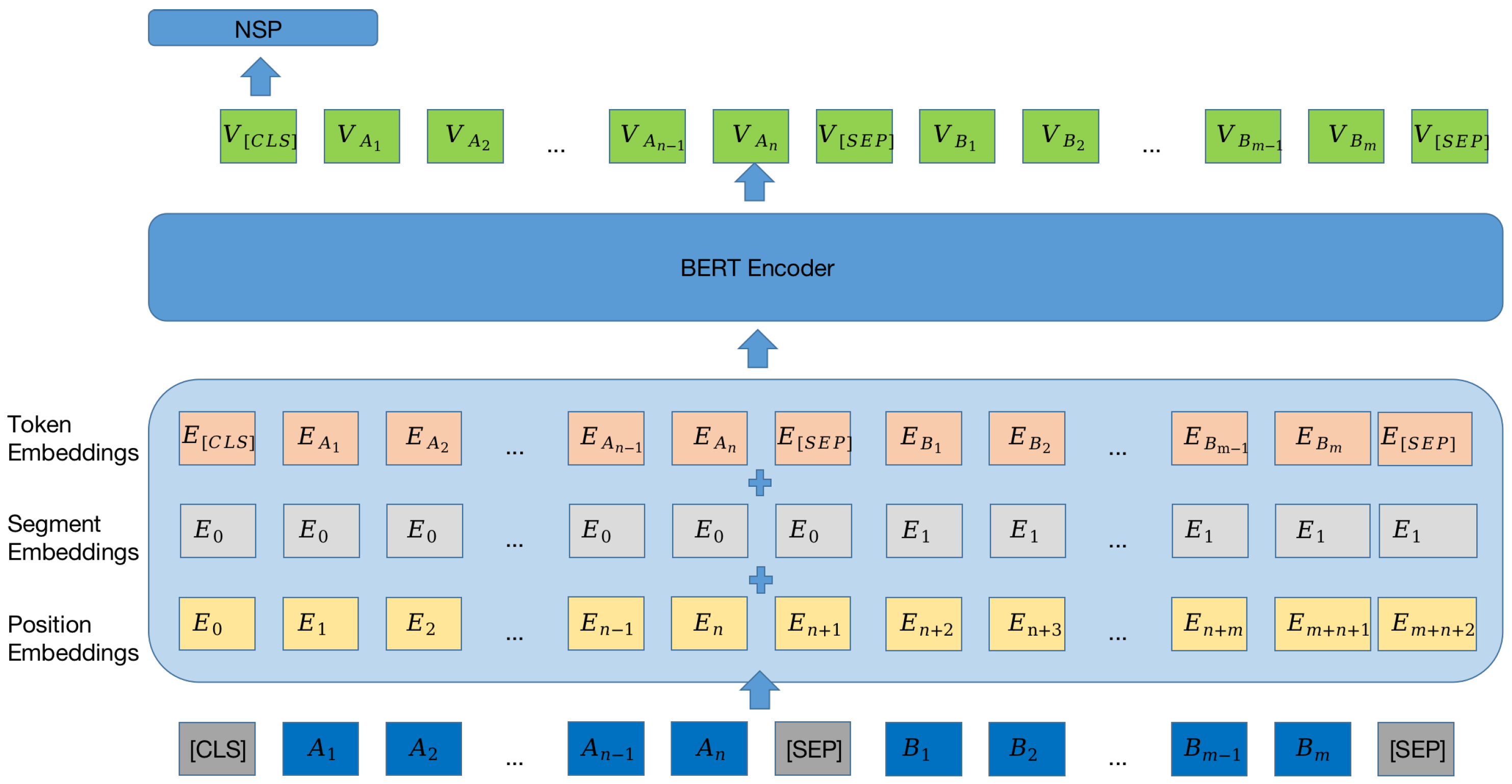
As for text-only NSP, the
text in
sentence and the
in
are used and it allows the model to adapt to the textual features of the tweets. The framework of this task is shown in
Figure 3 and is the same as NSP in BERT [
15].
Then, for multimodal NSP, the text and image in sentence and and in are used to predict the isNext. The model can improve the classification performance on multimodal corpus by this task.
Finally, the roles of
and
in NSP are exchanged, i.e., the original
becomes new
and original
becomes new
. The amount of data used for pre-training is doubled in this way. For the above pre-training task, we use cross-entropy as the loss function. The goal of training is to minimize the loss value.
means the label we set for the NSP pre-training tasks and
means the probability that our model predicts that the label is 1.
is the loss value of each type of pre-training task itself and
is the final loss value for pre-training.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}