
ViV-Ano: Anomaly Detection and Localization Combining Vision Transformer and Variational Autoencoder in the Manufacturing Process



Abstract
:1. Introduction
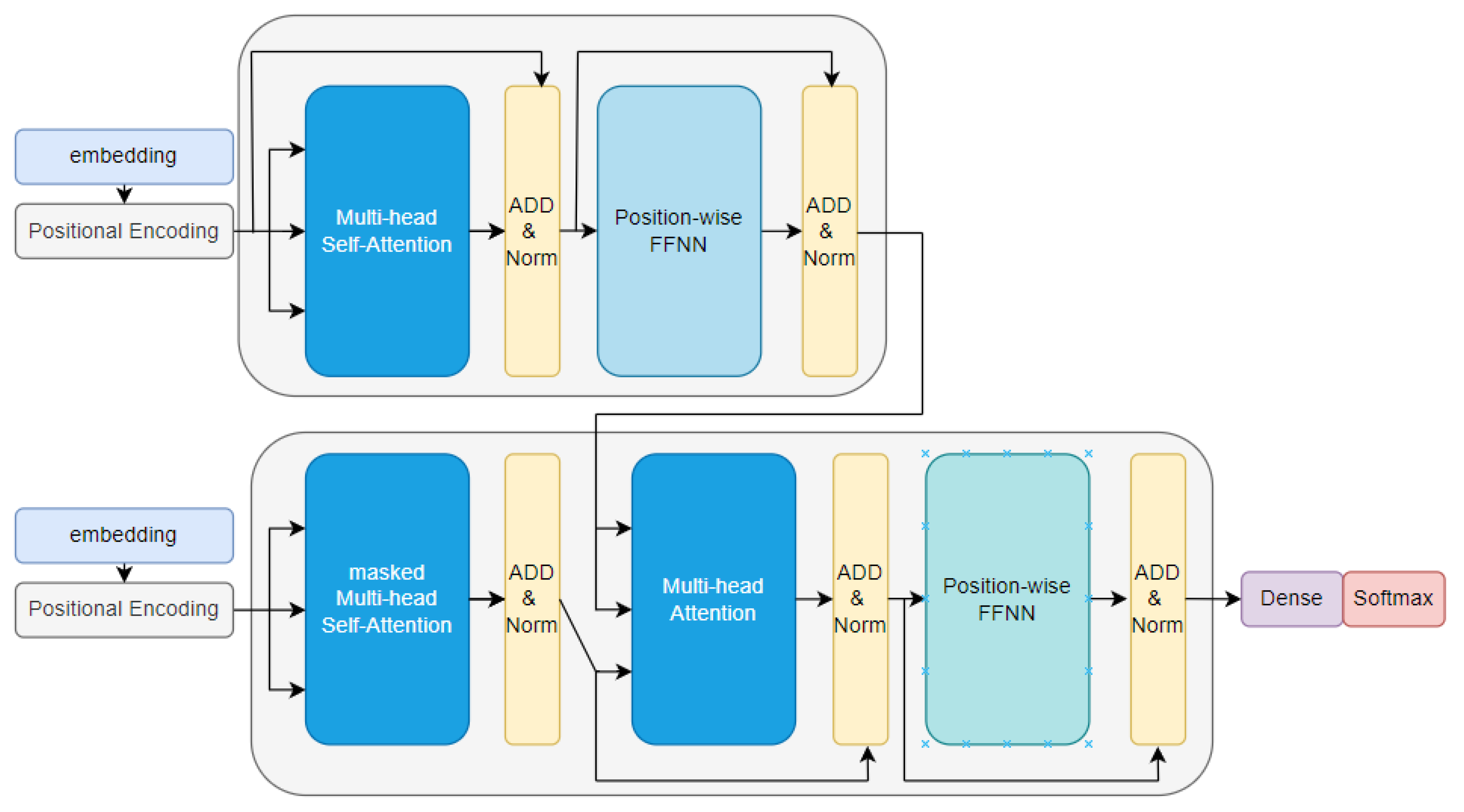
- The image applies the ViT method in the area to be analyzed. ViT has word-like image patches, uses an attention-based approach, and is a model that does not use an existing seq2seq iterative architecture based on attention. In ViT, the model can help interpret the image by allocating weights according to the location of the attention application.
- Since there is no bias in the transformer base, many datasets are required for learning. We complement the existing ViT’s marked need to learn using a large amount of data and improve the performance and accuracy for anomaly detection through a method of generating new data using the probability distributions of the VAE in combination with the VAE. We propose a ViV-Ano model by combining ViT with a VAE for anomaly detection.
2. Related Work
2.1. Anomaly Detection in Manufacturing
2.2. Traditional Anomaly Detection Methods
2.3. Attention Mechanism
3. ViV-Ano: Vision Transformer and VAE for Anomaly Detection
3.1. Encoder–Decoder Combining ViT and VAE
3.2. Gaussian Mixture Model (GMM)
4. Experiments and Results
4.1. Experimental Environment
4.2. Datasets
4.3. Baselines and Evaluation Metrics
4.4. Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kim, D.; Cha, J.; Oh, S.; Jeong, J. AnoGAN-Based Anomaly Filtering for Intelligent Edge Device in Smart Factory. In Proceedings of the 15th International Conference on Ubiquitous Information Management and Communication 2 (IMCOM), Seoul, Korea, 4–6 January 2021; pp. 1–6. [Google Scholar]
- Cha, J.; Park, J.; Jeong, J. A Novel Defect Classification Scheme Based on Convolutional Autoencoder with Skip Connection in Semiconductor Manufacturing. In Proceedings of the 24th International Conference on Advanced Communication Technology (ICACT), PyeongChang, Korea, 13–16 February 2022; pp. 347–352. [Google Scholar]
- Meneganti, M.; Saviello, F.S.; Tagliaferri, R. Fuzzy neural networks for classification and detection of anomalies. IEEE Trans. Neural Netw. 1998, 9, 848–861. [Google Scholar] [CrossRef] [PubMed]
- Zeng, Q.; Wu, S. A fuzzy clustering approach for intrusion detection. In Proceedings of the International Conference on Web Information Systems and Mining, Shanghai, China, 7–8 November 2009; pp. 728–732. [Google Scholar]
- Lee, T.; Lee, K.B.; Kim, C.O. Performance of machine learning algorithms for class-imbalanced process fault detection problems. IEEE Trans. Semicond. Manuf. 2016, 29, 436–445. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Naseer, S.; Saleem, Y.; Khalid, S.; Bashir, M.K.; Han, J.; Iqbal, M.M.; Han, K. Enhanced network anomaly detection based on deep neural networks. IEEE Access 2018, 6, 48231–48246. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Raghu, M.; Unterthiner, T.; Kornblith, S.; Zhang, C.; Dosovitskiy, A. Do vision transformers see like convolutional neural networks? Adv. Neural Inf. Process. Syst. 2021, 34, 12116–12128. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Cui, Y.; Liu, Z.; Lian, S. A Survey on Unsupervised Industrial Anomaly Detection Algorithms. arXiv 2022, arXiv:2204.11161. [Google Scholar]
- Bozcan, I.; Korndorfer, C.; Madsen, M.W.; Kayacan, E. Score-Based Anomaly Detection for Smart Manufacturing Systems. IEEE/ASME Trans. Mechatron. 2022. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. (CSUR) 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Abdulhammed, R.; Faezipour, M.; Abuzneid, A.; AbuMallouh, A. Deep and machine learning approaches for anomaly-based intrusion detection of imbalanced network traffic. IEEE Sensors Lett. 2018, 3, 1–4. [Google Scholar] [CrossRef]
- Li, Y.; Peng, X.; Zhang, J.; Li, Z.; Wen, M. DCT-GAN: Dilated Convolutional Transformer-based GAN for Time Series Anomaly Detection. IEEE Trans. Knowl. Data Eng. 2021. [Google Scholar] [CrossRef]
- Zhang, H.; Xia, Y.; Yan, T.; Liu, G. Unsupervised Anomaly Detection in Multivariate Time Series through Transformer-based Variational Autoencoder. In Proceedings of the 33rd Chinese Control and Decision Conference (CCDC), Kunming, China, 22–24 May 2021; pp. 281–286. [Google Scholar]
- Han, X.; Chen, K.; Zhou, Y.; Qiu, M.; Fan, C.; Liu, Y.; Zhang, T. A Unified Anomaly Detection Methodology for Lane-Following of Autonomous Driving Systems. In Proceedings of the Intl Conf on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking (ISPA/BDCloud/SocialCom/SustainCom), New York, NY, USA, 30 September–3 October 2021; pp. 836–844. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv 2019, arXiv:1910.10683. [Google Scholar]
- Shoeybi, M.; Patwary, M.; Puri, R.; LeGresley, P.; Casper, J.; Catanzaro, B. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv 2019, arXiv:1909.08053. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Available online: https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html (accessed on 12 June 2022).
- Zhou, T.; Li, L.; Li, X.; Feng, C.M.; Li, J.; Shao, L. Group-wise learning for weakly supervised semantic segmentation. IEEE Trans. Image Process. 2021, 31, 799–811. [Google Scholar] [CrossRef]
- Zhou, T.; Qi, S.; Wang, W.; Shen, J.; Zhu, S.C. Cascaded parsing of human-object interaction recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2827–2840. [Google Scholar] [CrossRef]
- Park, D.; Hoshi, Y.; Kemp, C.C. A multimodal anomaly detector for robot-assisted feeding using an lstm-based variational autoencoder. IEEE Robot. Autom. Lett. 2018, 3, 1544–1551. [Google Scholar] [CrossRef] [Green Version]
- Bergmann, P.; Fauser, M.; Sattlegger, D.; Steger, C. MVTec AD–A comprehensive real-world dataset for unsupervised anomaly detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9592–9600. [Google Scholar]
- Bergmann, P.; Fauser, M.; Sattlegger, D.; Steger, C. Uninformed students: Student-teacher anomaly detection with discriminative latent embeddings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4183–4192. [Google Scholar]
- Defard, T.; Setkov, A.; Loesch, A.; Audigier, R. Padim: A patch distribution modeling framework for anomaly detection and localization. In Proceedings of the International Conference on Pattern Recognition, Virtual Event, 10–15 January 2021; pp. 475–489. [Google Scholar]
- Kim, P.Y.; Iftekharuddin, K.M.; Davey, P.G.; Tóth, M.; Garas, A.; Holló, G.; Essock, E.A. Novel fractal feature-based multiclass glaucoma detection and progression prediction. IEEE J. Biomed. Health Inform. 2013, 17, 269–276. [Google Scholar] [CrossRef]
- Nightingale, K.R.; Rouze, N.C.; Rosenzweig, S.J.; Wang, M.H.; Abdelmalek, M.F.; Guy, C.D.; Palmeri, M.L. Derivation and analysis of viscoelastic properties in human liver: Impact of frequency on fibrosis and steatosis staging. IEEE Trans. Ultrason. Ferroelectr. Freq. Control. 2015, 62, 165–175. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abati, D.; Porrello, A.; Calderara, S.; Cucchiara, R. Latent space autoregression for novelty detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 481–490. [Google Scholar]
- Wu, Y.; Balaji, Y.; Vinzamuri, B.; Feizi, S. Mirrored autoencoders with simplex interpolation for unsupervised anomaly detection. arXiv 2020, arXiv:2003.10713. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Chen, C.F.R.; Fan, Q.; Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 357–366. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Category | -CAE | Ano-GAN | FGAN | VAE | ViV-Ano |
|---|---|---|---|---|---|---|
| Class | 0 | |||||
| 1 | ||||||
| 2 | ||||||
| 3 | ||||||
| 4 | ||||||
| 5 | ||||||
| 6 | ||||||
| 7 | ||||||
| 8 | ||||||
| 9 | ||||||
| Mean | - |
| Type | Category | -CAE | DSEBM | ADGAN | DeepSVDD | ViV-Ano |
|---|---|---|---|---|---|---|
| Class | Airplane | |||||
| Automobile | ||||||
| Bird | ||||||
| Cat | ||||||
| Deer | ||||||
| Dog | ||||||
| Frog | ||||||
| Horse | ||||||
| Ship | ||||||
| Truck | ||||||
| Mean | - |
| Type | Category | 1-NN | OCSVM | KMean | VAE | AE-SSIM | AnoGAN | CNN | UniStud | ViV-Ano |
|---|---|---|---|---|---|---|---|---|---|---|
| Object | Carpet | 0.512 | 0.355 | 0.253 | 0.501 | 0.647 | 0.204 | 0.469 | 0.695 | |
| Grid | 0.228 | 0.125 | 0.107 | 0.224 | 0.226 | 0.183 | 0.819 | 0.789 | ||
| Leather | 0.446 | 0.306 | 0.308 | 0.635 | 0.561 | 0.378 | 0.641 | 0.786 | ||
| Tile | 0.822 | 0.722 | 0.779 | 0.870 | 0.175 | 0.177 | 0.797 | 0.881 | ||
| Wood | 0.502 | 0.336 | 0.411 | 0.628 | 0.605 | 0.386 | 0.621 | 0.725 | ||
| Bottle | 0.898 | 0.850 | 0.495 | 0.897 | 0.834 | 0.620 | 0.742 | 0.918 | ||
| Cable | 0.806 | 0.431 | 0.513 | 0.654 | 0.478 | 0.383 | 0.558 | 0.865 | ||
| Capsule | 0.631 | 0.554 | 0.387 | 0.526 | 0.860 | 0.306 | 0.306 | 0.869 | ||
| Hazelnut | 0.861 | 0.616 | 0.698 | 0.878 | 0.916 | 0.698 | 0.844 | 0.884 | ||
| Metal Nut | 0.705 | 0.319 | 0.351 | 0.576 | 0.603 | 0.320 | 0.358 | 0.895 | ||
| Pill | 0.725 | 0.544 | 0.514 | 0.769 | 0.830 | 0.776 | 0.460 | 0.895 | ||
| Screw | 0.604 | 0.644 | 0.550 | 0.559 | 0.887 | 0.466 | 0.277 | 0.878 | ||
| Toothbrush | 0.538 | 0.538 | 0.337 | 0.693 | 0.784 | 0.749 | 0.151 | 0.863 | ||
| Transistor | 0.496 | 0.496 | 0.399 | 0.626 | 0.725 | 0.549 | 0.628 | 0.701 | ||
| Zipper | 0.512 | 0.355 | 0.253 | 0.549 | 0.665 | 0.467 | 0.703 | 0.933 | ||
| Mean | - | 0.640 | 0.479 | 0.423 | 0.639 | 0.694 | 0.443 | 0.515 | 0.857 |
| Type | Category | -CAE | ViV-Ano |
|---|---|---|---|
| Object | Carpet | ||
| Grid | |||
| Leather | |||
| Tile | |||
| Wood | |||
| Bottle | |||
| Cable | |||
| Capsule | |||
| Hazelnut | |||
| Metal Nut | |||
| Pill | |||
| Screw | |||
| Toothbrush | |||
| Transistor | |||
| Zipper | |||
| Mean | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, B.; Jeong, J. ViV-Ano: Anomaly Detection and Localization Combining Vision Transformer and Variational Autoencoder in the Manufacturing Process. Electronics 2022, 11, 2306. https://doi.org/10.3390/electronics11152306
Choi B, Jeong J. ViV-Ano: Anomaly Detection and Localization Combining Vision Transformer and Variational Autoencoder in the Manufacturing Process. Electronics. 2022; 11(15):2306. https://doi.org/10.3390/electronics11152306
Chicago/Turabian StyleChoi, Byeonggeun, and Jongpil Jeong. 2022. "ViV-Ano: Anomaly Detection and Localization Combining Vision Transformer and Variational Autoencoder in the Manufacturing Process" Electronics 11, no. 15: 2306. https://doi.org/10.3390/electronics11152306
APA StyleChoi, B., & Jeong, J. (2022). ViV-Ano: Anomaly Detection and Localization Combining Vision Transformer and Variational Autoencoder in the Manufacturing Process. Electronics, 11(15), 2306. https://doi.org/10.3390/electronics11152306