
Spectrum Sensing Based on STFT-ImpResNet for Cognitive Radio

Abstract
:1. Introduction
- We combined Short-time Fourier transform and a residual network innovatively, and proposed STFT-ImpResNet for spectrum sensing. To the best knowledge of the authors, this is the first time that a combination of STFT and ResNet has been introduced to spectrum sensing.
- We customized a deep learning network structure to achieve a good trade-off between accuracy and computational cost in the context of spectrum sensing. We especially simplified ResNet by replacing the fully connected layer with a global average pooling layer to integrate global information. In addition, a dropout layer was added into the improved residual block to prevent over-fitting effectively.
- We conducted comprehensive experiments which demonstrate that the proposed STFT-ImpResNet algorithm outperforms the existing spectrum sensing algorithms on low signal-to-radio datasets.
2. System Model
3. STFT-ImpResNet Spectrum Sensing Algorithm
3.1. Short-Time Fourier Transform
3.2. Improved ResNet
| Algorithm 1: STFT-ImpResNet Spectrum Sensing |
| Input: Received signal samples X; maximum number of iterations IterMax |
| Output: and |
| 1. Preprocess the received signal samples X into training dataset and test dataset |
| 2. Initialization: iteration counter and random weight |
| 3. Gradient descent training of training dataset in ImpResNet |
| Repeat |
| Update according to Equation (12); |
| Substitute into Equation (13). |
| Until IterMax reached |
| 4. Inference: apply the trained ImpResNet model to the online dataset and output the classification results |
| 5. Calculate the detection probability and the false alarm probability |
4. Experimental Result Analysis
4.1. System Simulation
4.2. Experimental Configuration
4.3. Experimental Results
4.3.1. Effects of Dropout Rates
4.3.2. Effect of the Network Structure
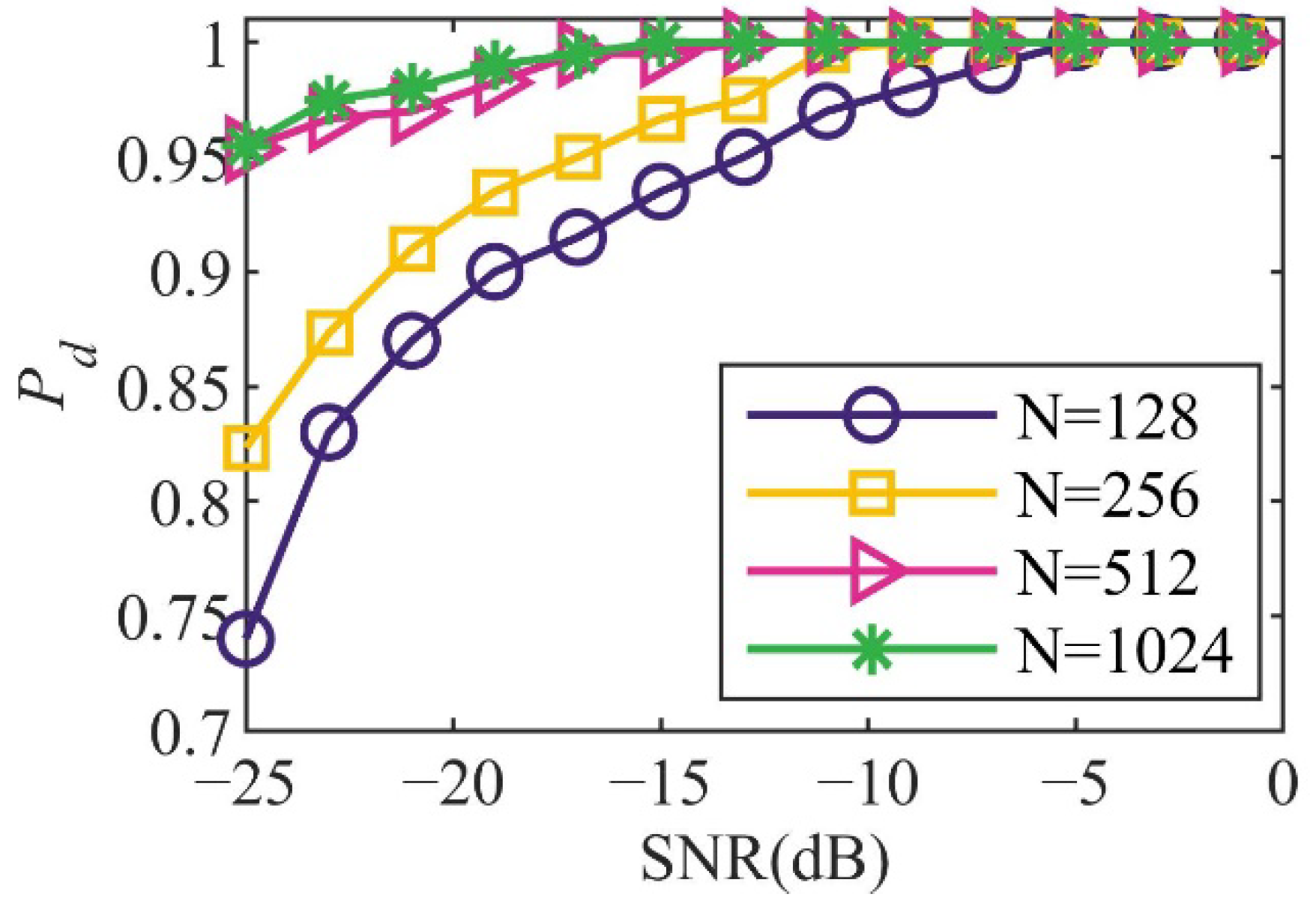
4.3.3. Effect of Sampling Points
4.3.4. Comparison of Efficiency
4.3.5. Effect of Noise Uncertainty
4.3.6. Comparison of ROC
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Federal Communications Commission. FCC Report of the Spectrum Efficiency Working Group; FCC: Columbia, NS, USA, 2002. [Google Scholar]
- Mitola, J.; Maguire, G.Q. Cognitive radio: Making software radios more personal. IEEE Pers. Commun. 1999, 6, 13–18. [Google Scholar] [CrossRef] [Green Version]
- Kanti, J.; Tomar, G.S. Improved sensing detector for wireless regional area networks. Cogent Eng. 2017, 4, 1286729. [Google Scholar] [CrossRef]
- Lee, C.-H.; Wolf, W. Multiple access-inspired cooperative spectrum sensing for cognitive radio. In Proceedings of the MILCOM 2007-IEEE Military Communications Conference, Orlando, FL, USA, 29–31 October 2007; pp. 1–6. [Google Scholar]
- Haykin, S.; Thomson, D.J.; Reed, J.H. Spectrum sensing for cognitive radio. Proc. IEEE 2009, 97, 849–877. [Google Scholar] [CrossRef] [Green Version]
- Koyuncu, H.; Bagwari, A.; Tomar, G.S. Simulation of a smart sensor detection scheme for wireless communication based on modeling. Electronics 2020, 9, 1506. [Google Scholar] [CrossRef]
- Zeng, Y.; Koh, C.L.; Liang, Y.-C. Maximum eigenvalue detection: Theory and application. In Proceedings of the 2008 IEEE International Conference on Communications, Beijing, China, 19–23 May 2008; pp. 4160–4164. [Google Scholar]
- Tian, Z.; Tafesse, Y.; Sadler, B.M. Cyclic feature detection with sub-Nyquist sampling for wideband spectrum sensing. IEEE J. Sel. Top. Signal Process. 2011, 6, 58–69. [Google Scholar] [CrossRef]
- Cohen, D.; Rebeiz, E.; Eldar, Y.C.; Cabric, D. Cyclostationary detection from sub-Nyquist samples for Cognitive Radios: Model reconciliation. In Proceedings of the 2013 5th IEEE International Workshop on Computational Advances in Multi-Sensor Adaptive Processing (CAMSAP), St. Martin, France, 15–18 December 2013; pp. 384–387. [Google Scholar]
- Tang, H. Some physical layer issues of wide-band cognitive radio systems. In Proceedings of the First IEEE International Symposium on New Frontiers in Dynamic Spectrum Access Networks (DySPAN 2005), Baltimore, MD, USA, 8–11 November 2005; pp. 151–159. [Google Scholar]
- Lu, J.; Huang, M.; Yang, J. A covariance matrix-based spectrum sensing technology exploiting stochastic resonance and filters. EURASIP J. Adv. Signal Process. 2021, 2021, 1. [Google Scholar] [CrossRef]
- Chen, S.; Wang, X.; Shen, B. A support vector machine based spectrum sensing for cognitive radios. J. Chongqing Univ. Posts Telecommun. Nat. Sci. Ed. 2019, 31, 313–322. [Google Scholar]
- Azmat, F.; Chen, Y.; Stocks, N. Analysis of spectrum occupancy using machine learning algorithms. IEEE Trans. Veh. Technol. 2015, 65, 6853–6860. [Google Scholar] [CrossRef]
- Tang, Y.-J.; Zhang, Q.-Y.; Lin, W. Artificial neural network based spectrum sensing method for cognitive radio. In Proceedings of the 2010 6th International Conference on Wireless Communications Networking and Mobile Computing (WiCOM), Chengdu, China, 23–25 September 2010; pp. 1–4. [Google Scholar]
- Vyas, M.R.; Patel, D.K.; Lopez-Benitez, M. Artificial neural network based hybrid spectrum sensing scheme for cognitive radio. In Proceedings of the 2017 IEEE 28th annual international symposium on personal, indoor, and mobile radio communications (PIMRC), Montreal, QC, Canada, 8–13 October 2017; pp. 1–7. [Google Scholar]
- Jaglan, R.R.; Mustafa, R.; Agrawal, S. Scalable and robust ANN based cooperative spectrum sensing for cognitive radio networks. Wirel. Pers. Commun. 2018, 99, 1141–1157. [Google Scholar] [CrossRef]
- Han, D.; Sobabe, G.C.; Zhang, C.; Bai, X.; Wang, Z.; Liu, S.; Guo, B. Spectrum sensing for cognitive radio based on convolution neural network. In Proceedings of the 2017 10th international congress on image and signal processing, biomedical engineering and informatics (CISP-BMEI), Shanghai, China, 14–16 October 2017; pp. 1–6. [Google Scholar]
- Pan, G.; Li, J.; Lin, F. A cognitive radio spectrum sensing method for an OFDM signal based on deep learning and cycle spectrum. Int. J. Digit. Multimed. Broadcasting 2020, 2020, 5069021. [Google Scholar] [CrossRef]
- Wu, J.; Lin, J.; Tian, B.; He, J. A signal modulation identification method based on neural network. In Proceedings of the 2020 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 27–29 June 2020; pp. 64–67. [Google Scholar]
- Arya, G.; Bagwari, A.; Chauhan, D.S. Performance analysis of deep learning-based routing protocol for an efficient data transmission in 5G WSN communication. IEEE Access 2022, 10, 9340–9356. [Google Scholar] [CrossRef]
- Solanki, S.; Dehalwar, V.; Choudhary, J. Deep learning for spectrum sensing in cognitive radio. Symmetry 2021, 13, 147. [Google Scholar] [CrossRef]
- Chen, Z.; Xu, Y.-Q.; Wang, H.; Guo, D. Deep STFT-CNN for spectrum sensing in cognitive radio. IEEE Commun. Lett. 2020, 25, 864–868. [Google Scholar] [CrossRef]
- Xue, N.; Niu, L.; Hong, X.; Li, Z.; Hoffaeller, L.; Pöpper, C. Deepsim: Gps spoofing detection on uavs using satellite imagery matching. In Proceedings of the Annual Computer Security Applications Conference, Austin, TX, USA, 7–11 December 2020; pp. 304–319. [Google Scholar]
- Huang, J.; Chen, B.; Yao, B.; He, W. ECG arrhythmia classification using STFT-based spectrogram and convolutional neural network. IEEE Access 2019, 7, 92871–92880. [Google Scholar] [CrossRef]
- Li, Z.; Shao, H.; Niu, L.; Xue, N. Progressive learning algorithm for efficient person re-identification. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 16–23. [Google Scholar]
- Astuti, W.; Sediono, W.; Aibinu, A.; Akmeliawati, R.; Salami, M.-J.E. Adaptive Short Time Fourier Transform (STFT) Analysis of seismic electric signal (SES): A comparison of Hamming and rectangular window. In Proceedings of the 2012 IEEE Symposium on Industrial Electronics and Applications, Bandung, Indonesia, 23–26 September 2012; pp. 372–377. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, F.; Qiu, J.; Wang, Z.; Li, W. Intelligent recognition of surface defects of parts by Resnet. J. Phys. Conf. Ser. 2021, 1883, 012178. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network In Network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Visa, S.; Ramsay, B.; Ralescu, A.L.; Van Der Knaap, E. Confusion matrix-based feature selection. MAICS 2011, 710, 120–127. [Google Scholar]
- Yang, F.; Hao, B.; Yang, L.; Han, Q. A method of high-precision signal recognition based on higher-order cumulants and svm. In Proceedings of the 2018 5th International Conference on Systems and Informatics (ICSAI), Nanjing, China, 10–12 November 2018; pp. 455–459. [Google Scholar]
- Yue, C.; Xi, Z.; Wenbao, A.I. Spectrum sensing algorithm based on residual neural network. Mod. Electron. Tech. 2022, 45, 1–5. [Google Scholar] [CrossRef]
- Zheng, S.; Chen, S.; Qi, P.; Zhou, H.; Yang, X. Spectrum sensing based on deep learning classification for cognitive radios. China Commun. 2020, 17, 138–148. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dropout Rate | Training Accuracy (%) | Validation Accuracy (%) |
|---|---|---|
| 0 | 100 | 93.2 |
| 0.1 | 100 | 95.7 |
| 0.2 | 100 | 97.7 |
| 0.3 | 100 | 98.5 |
| 0.4 | 100 | 99.4 |
| 0.5 | 100 | 98.2 |
| 0.6 | 100 | 96.4 |
| 0.7 | 100 | 94.3 |
| Number of Kernels | Kernel Size | 20-Layer Accuracy | |
|---|---|---|---|
| ResNet1 | 8 | 3 × 3 | 99.4% |
| ResNet2 | 8 | 5 × 5 | 97.8% |
| ResNet3 | 10 | 3 × 3 | 96.7% |
| ResNet4 | 10 | 5 × 5 | 96.3% |
| CNN | 8 | 3 × 3 | 92.6% |
| Training Time (s) | Detection Time (ms) | |||
|---|---|---|---|---|
| STFT-ImpResNet | 0.99 | 0.04 | 29.186 | 12.52 |
| STFT-CNN | 0.91 | 0.3 | 33.143 | 13.95 |
| SVM | 0.6 | 0.42 | 15.646 | 19.03 |
| ED | 0.36 | 0.33 | - | 2.93 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gai, J.; Zhang, L.; Wei, Z. Spectrum Sensing Based on STFT-ImpResNet for Cognitive Radio. Electronics 2022, 11, 2437. https://doi.org/10.3390/electronics11152437
Gai J, Zhang L, Wei Z. Spectrum Sensing Based on STFT-ImpResNet for Cognitive Radio. Electronics. 2022; 11(15):2437. https://doi.org/10.3390/electronics11152437
Chicago/Turabian StyleGai, Jianxin, Linghui Zhang, and Zihao Wei. 2022. "Spectrum Sensing Based on STFT-ImpResNet for Cognitive Radio" Electronics 11, no. 15: 2437. https://doi.org/10.3390/electronics11152437
APA StyleGai, J., Zhang, L., & Wei, Z. (2022). Spectrum Sensing Based on STFT-ImpResNet for Cognitive Radio. Electronics, 11(15), 2437. https://doi.org/10.3390/electronics11152437