
Polar Code Parameter Recognition Algorithm Based on Dual Space

Abstract
:1. Introduction
- (1)
- The two basic principles of polar code parameter recognition are given and proven.
- (2)
- The polar code parameter recognition problem is transformed into a hypothesis testing problem, and a complete hypothesis-testing process is provided. The average log-likelihood ratio (LLR) is introduced as a statistic, and the corresponding threshold is derived in detail.
- (3)
- An index of sub-channels transmitting information bits (also called information-bit position) is directly constructed using a Gaussian approximation (GA) method, which helps avoid errors involving correct information bit numbers but incorrect information bit positions.
2. Preliminaries
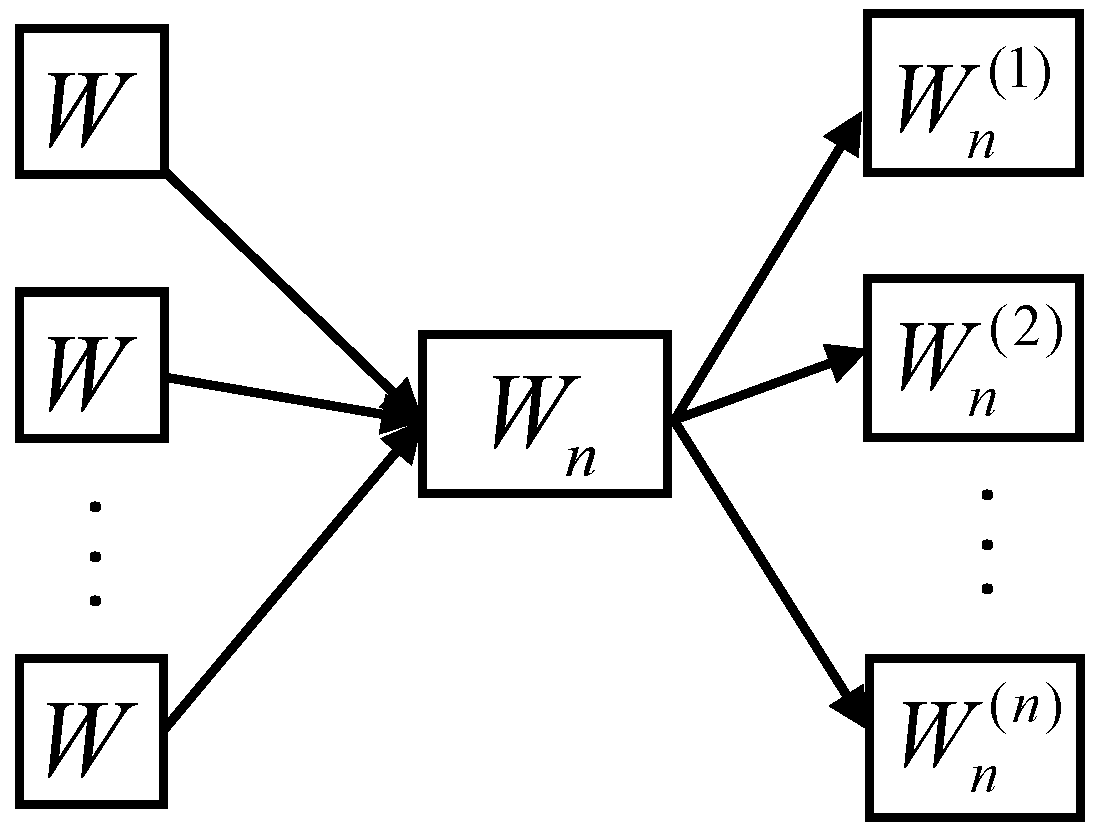
2.1. Channel Combination
2.2. Polar Code Construction in Gaussian Channel
3. Principle and Method of Polar Code Parameter Recognition
3.1. Recognition Principle
3.2. Model System
3.3. Decision Threshold
3.4. Parameter Recognition Steps
| Algorithm 1: Polar code parameter recognition |
| ; ; soft decision sequence ; numbers of code length, ; numbers of code rate, ; execution numbers |
| 1 do |
| 2 ; |
| 3 do |
| 4 ; |
| 5 ; |
| 6 ; |
| 7 ; |
| 8 then |
| 9 ; |
| 10 ; |
| 11 end if |
| 12 end for |
| 13 end for |
| 14 ; |
| 15 do |
| 16 ; |
| 17 then |
| 18 ; |
| 19 else |
| 20 ; |
| 21 end if |
| 22 ; |
| 23 end for |
| 24 ; |
| 25 |
4. Numerical Simulation
4.1. Algorithm-Validity Verification
4.2. Influence of Code Rate
4.3. Influence of Intercepted Codewords
4.4. Influence of Code Length
4.5. Comparison of Recognition Performance
4.6. Algorithm Complexity
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Arikan, E. Channel polarization: A method for constructing capacity-achieving codes for symmetric binary-input memoryless channels. IEEE Trans. Inf. Theory 2009, 55, 3051–3073. [Google Scholar] [CrossRef]
- Gamage, H.; Rajatheva, N.; Latva-Aho, M. Channel coding for enhanced mobile broadband communication in 5G systems. In Proceedings of the 2017 European Conference on Networks and Communications, Oulu, Finland, 12–15 June 2017; pp. 1–6. [Google Scholar]
- Abusabah, I.A.A.; Abdeldafia, M.; Abdelaziz, Y.M.A. Blind Identification of Convolutional Codes Based on Veterbi Algorithm. In Proceedings of the 2020 International Conference on Computer, Control, Electrical, and Electronics Engineering (ICCCEEE), Khartoum, Sudan, 26 February–1 March 2021; pp. 1–4. [Google Scholar]
- Huang, L.; Chen, W.; Chen, E.; Chen, H. Blind recognition of k/n rate convolutional encoders from noisy observation. J. Syst. Eng. Electron. 2017, 28, 235–243. [Google Scholar]
- Li, L.Q.; Huang, Z.; Zhou, J. Blind identification of LDPC codes based on a candidate set. IEEE Commun. Lett. 2021, 25, 2786–2789. [Google Scholar]
- Lei, Y.; Luo, L. Novel Blind Identification of LDPC Code Check Vector Using Soft-decision. In Proceedings of the 2020 IEEE 20th International Conference on Communication Technology (ICCT), Nanning, China, 28–31 October 2020; pp. 1291–1295. [Google Scholar]
- Wu, Z.J.; Zhang, L.M.; Zhong, Z.G.; Liu, R.X. Blind recognition of LDPC codes over candidate set. IEEE Commun. Lett. 2020, 24, 11–14. [Google Scholar] [CrossRef]
- Swaminathan, R.; Madhukumar, A.S.; Wang, G.H. Blind estimation of code parameters for product codes over noisy channel conditions. IEEE Trans. Aerosp. Electron. Syst. 2020, 56, 1460–1473. [Google Scholar] [CrossRef]
- Wu, Z.J.; Zhang, L.M.; Zhong, Z.G. A maximum cosinoidal cost function method for parameter estimation of RSC turbo codes. IEEE Commun. Lett. 2019, 23, 390–393. [Google Scholar]
- Wand, J.; Tang, C.R.; Huang, H.; Wang, H.; Li, J.Q. Blind identification of convolutional codes based on deep learning. Digit Signal Process. 2021, 115, 103086. [Google Scholar]
- Chen, J.J. Research and Implementation of Closed Set Recognition of Error Correction Coding Based on Deep Learning. Master’s Thesis, University of Electronic Science and Technology of China, Chengdu, China, 2020. [Google Scholar]
- Chen, C. Recognition of Closed Set Turbo Codes Based on Machine Learning. Master’s Thesis, University of Electronic Science and Technology of China, Chengdu, China, 2020. [Google Scholar]
- Liu, J.; Zhang, L.M.; Zhong, Z.G. Blind parameter identification of RS code based on binary field equivalence. Acta Electron. Sin. 2018, 46, 2888–2894. [Google Scholar]
- Zhang, T.Q.; Hu, Y.P.; Feng, J.X.; Zhang, X.Y. Blind algorithm of polarization code parameters based on null space matrix matching. J. Electr. Eng. Technol. 2020, 42, 2953–2959. [Google Scholar]
- Wu, Z.J.; Zhong, Z.G.; Zhang, L.M.; Dan, B. Recognition of non-drilled polar codes based on soft decision. J. Commun. 2020, 41, 60–71. [Google Scholar]
- Wang, Y.; Wang, X.; Yang, G.D.; Huang, Z. Recognition algorithm of non punctured polarization codes based on structural characteristics of coding matrix. J. Commun. 2022, 43, 22–33. [Google Scholar]
- Xu, J.; Yuan, Y.F. Channel Coding for New Radio of 5th Generation Mobile Communications; Posts & Telecom Press: Beijing, China, 2018. [Google Scholar]
- John, W.B. Kronecker Products and matrix calculus in system theory. IEEE Trans. Circuits Syst. 1978, 25, 772–781. [Google Scholar]
- Melnikov, N.B.; Reser, B.I. Gaussian Approximation. In Dynamic Spin-Fluctuation Theory of Metallic Magnetism, 1st ed.; Springer International Publishing AG: Cham, Switzerland, 2018; pp. 101–108. [Google Scholar]
- Proakis, J.G. Digital Communications; McGraw Hill: New York, NY, USA, 1995. [Google Scholar]
- Trifonov, P. Efficient design and decoding of polar codes. IEEE Trans. Commun. 2012, 60, 3221–3227. [Google Scholar] [CrossRef]
- Zimaglia, E.; Riviello, D.G.; Garello, R.; Fantini, R. A Deep Learning-based Approach to 5G-New Radio Channel Estimation. In Proceedings of the 2021 Joint European Conference on Networks and Communications & 6G Summit, Porto, Portugal, 8–11 June 2021; pp. 1–6. [Google Scholar]
- Pauluzzi, D.R.; Beaulieu, N.C. A comparison of SNR estimation techniques for the AWGN channel. IEEE Trans. Commun. 2000, 48, 1681–1691. [Google Scholar] [CrossRef]
- 3GPP. Study on New Radio Access Technology Physical Layer Aspects (Release 14), TR 38.802 V14.1.0[R]. 2017, pp. 14–43. Available online: http://www.3gpp.org (accessed on 27 April 2007).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Wu, Z.; Zhang, L.; Yan, W. Polar Code Parameter Recognition Algorithm Based on Dual Space. Electronics 2022, 11, 2511. https://doi.org/10.3390/electronics11162511
Liu H, Wu Z, Zhang L, Yan W. Polar Code Parameter Recognition Algorithm Based on Dual Space. Electronics. 2022; 11(16):2511. https://doi.org/10.3390/electronics11162511
Chicago/Turabian StyleLiu, Hengyan, Zhaojun Wu, Limin Zhang, and Wenjun Yan. 2022. "Polar Code Parameter Recognition Algorithm Based on Dual Space" Electronics 11, no. 16: 2511. https://doi.org/10.3390/electronics11162511