
Small Sample Hyperspectral Image Classification Method Based on Dual-Channel Spectral Enhancement Network

Abstract
:1. Introduction
1.1. Related Work
1.2. Contribution and Paper Organization
2. Methodology
2.1. 3D–2D Hybrid Convolution
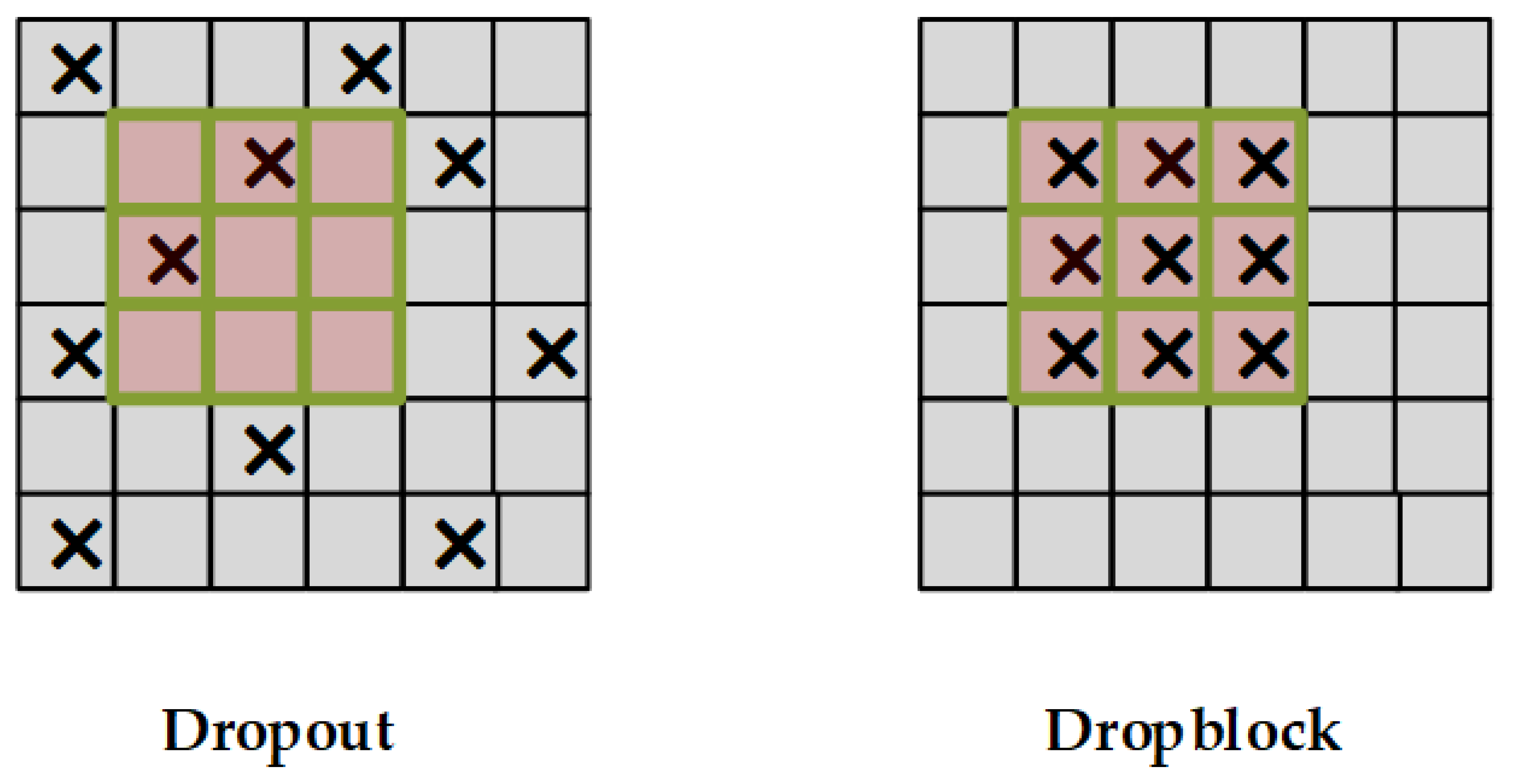
2.2. Dropout and Dropblock
3. Proposed Model
3.1. The Design of DSEN
3.2. Data Preprocessing
3.3. Feature Extraction
3.4. Feature Fusion and Classification
3.5. Parameter Setting
4. Experiments and Discussion
4.1. Experimental Data Sets
4.2. Experimental Setup
4.3. Experimental Results and Analysis
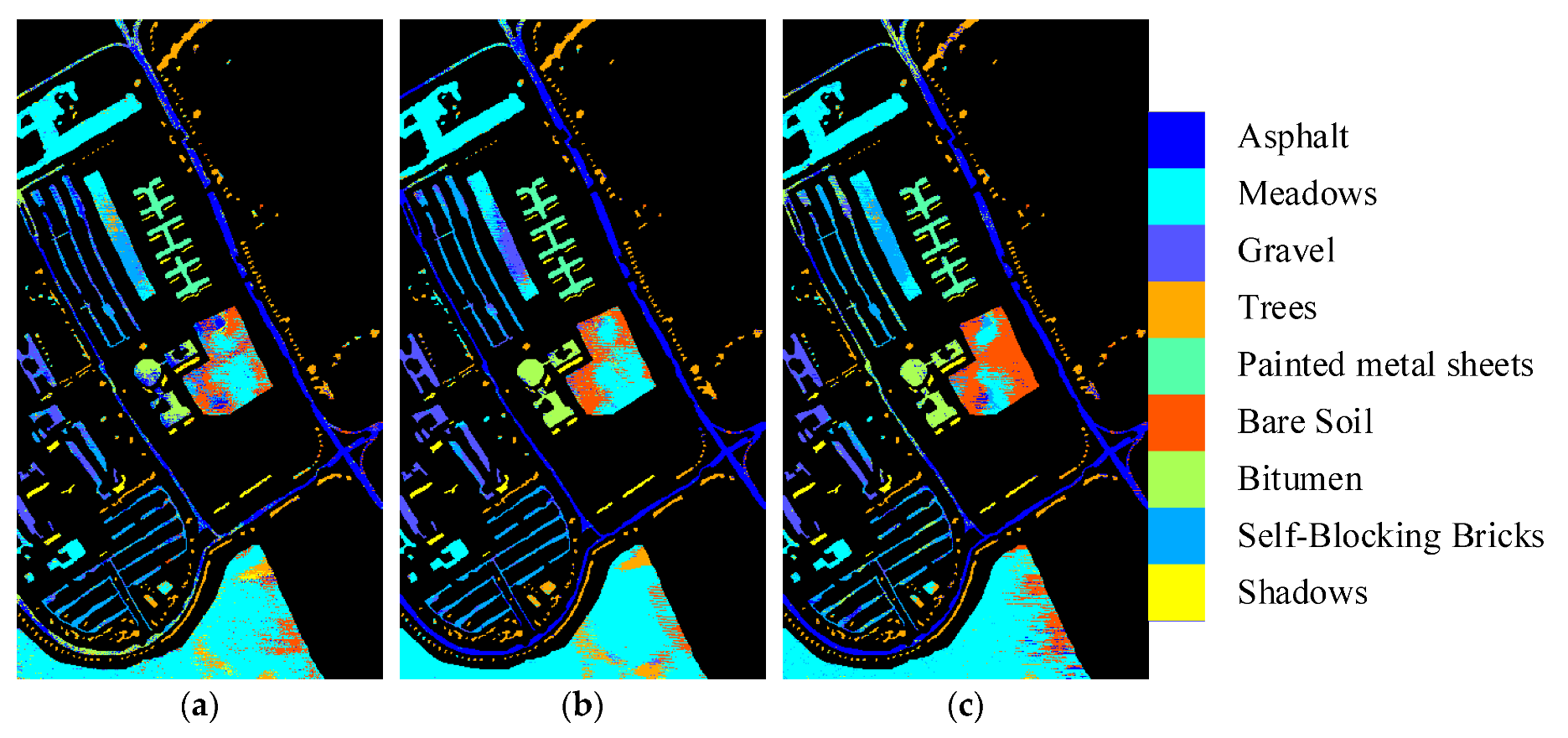
4.3.1. Experimental Result
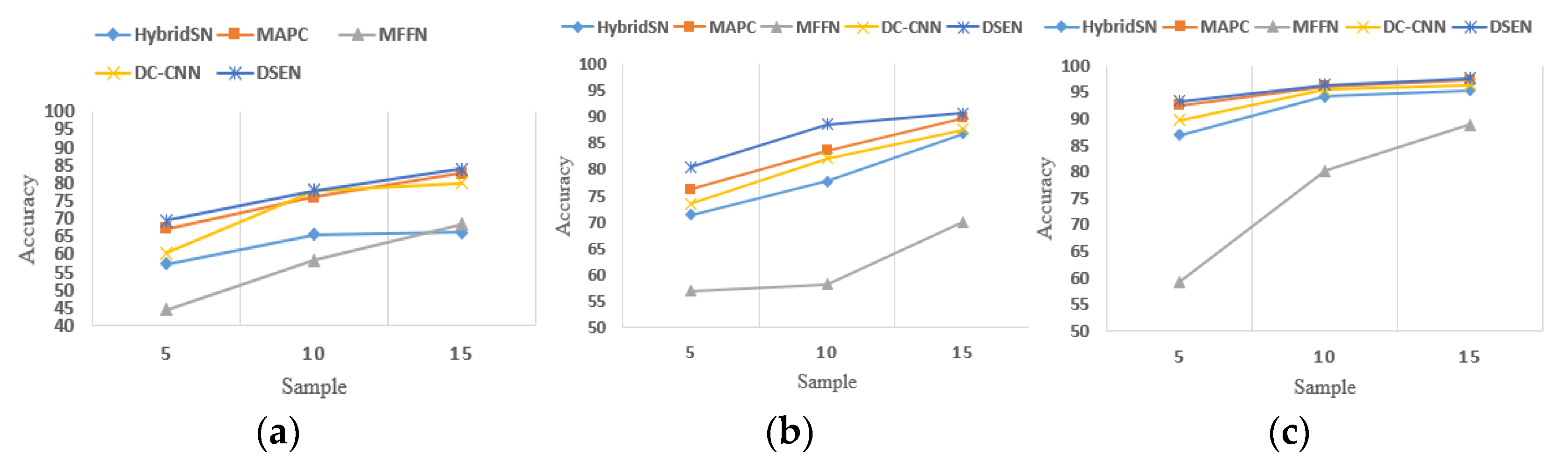
4.3.2. Comparison and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shippert, P. Why Use Hyperspectral Imagery? Photogramm. Eng. Remote Sens. 2004, 70, 377–396. [Google Scholar]
- Yadav, B.K.; Lucieer, A.; Baker, S.C.; Jordan, G.J. Tree crown segmentation and species classification in a wet eucalypt forest from airborne hyperspectral and LiDAR data. Int. J. Remote Sens. 2021, 42, 7952–7977. [Google Scholar] [CrossRef]
- Pacheco, A.; Bannari, A.; Deguise, J.C.; McNairn, H.; Staenz, K. Application of hyperspectral remote sensing for LAI estimation in precision farming. In Proceedings of the 23rd Canadian Remote Sensing Symposium, Sainte-Foy, QC, Canada, 21–24 August 2001; pp. 281–287. [Google Scholar]
- Gevaert, C.M.; Suomalainen, J.; Tang, J.; Kooistra, L. Generation of spectral–temporal response surfaces by combining multispectral satellite and hyperspectral UAV imagery for precision agriculture applications. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3140–3146. [Google Scholar] [CrossRef]
- Dale, L.M.; Thewis, A.; Boudry, C.; Rotar, I.; Dardenne, P.; Baeten, V.; Pierna, J.A.F. Hyperspectral imaging applications in agriculture and agro-food product quality and safety control: A review. Appl. Spectrosc. Rev. 2013, 48, 142–159. [Google Scholar] [CrossRef]
- Gao, Y.; Li, W.; Zhang, M.; Wang, J.; Sun, W.; Tao, R.; Du, Q. Hyperspectral and multispectral classification for coastal wetland using depthwise feature interaction network. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Manolakis, D.; Shaw, G. Detection algorithms for hyperspectral imaging applications. IEEE Signal Process. Mag. 2002, 19, 29–43. [Google Scholar] [CrossRef]
- Sun, S.; Zhong, P.; Xiao, H.; Liu, F.; Wang, R. An active learning method based on Markov random fields for hyperspectral images classification. In Proceedings of the 2015 7th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Tokyo, Japan, 2–5 June 2015. [Google Scholar]
- Ren, Y.; Zhang, Y.; Li, L. A spectral-spatial hyperspectral data classification approach using random forest with label constraints. In Proceedings of the 2014 IEEE Workshop on Electronics, Computer and Applications, Ottawa, ON, Canada, 8–9 May 2014. [Google Scholar]
- Liu, B.; Guo, W.; Chen, X.; Gao, K.; Zuo, X.; Wang, R.; Yu, A. Morphological attribute profile cube and deep random forest for small sample classification of hyperspectral image. IEEE Access 2020, 8, 117096–117108. [Google Scholar] [CrossRef]
- Agarwal, A.; El-Ghazawi, T.; El-Askary, H.; Le-Moigne, J. Efficient hierarchical-PCA dimension reduction for hyperspectral imagery. In Proceedings of the 2007 IEEE International Symposium on Signal Processing and Information Technology, Giza, Egypt, 15–18 December 2007. [Google Scholar]
- Vaddi, R.; Prabukumar, M. Probabilistic PCA based hyper spectral image classification for remote sensing applications. In International Conference on Intelligent Systems Design and Applications; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Wang, J.; Chang, C.-I. Independent component analysis-based dimensionality reduction with applications in hyperspectral image analysis. IEEE Trans. Geosci. Remote Sens. 2006, 44, 1586–1600. [Google Scholar] [CrossRef]
- Zhang, Z.; Geiger, J.; Pohjalainen, J.; Mousa, A.E.D.; Jin, W.; Schuller, B. Deep learning for environmentally robust speech recognition: An overview of recent developments. ACM Trans. Intell. Syst. Technol. (TIST) 2018, 9, 1–28. [Google Scholar] [CrossRef]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef]
- Hinton, G.E.; Ruslan, R.S. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep learning-based classification of hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Ma, X.; Wang, H.; Geng, J. Spectral–spatial classification of hyperspectral image based on deep auto-encoder. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 4073–4085. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, X.; Jia, X. Spectral–spatial classification of hyperspectral data based on deep belief network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2381–2392. [Google Scholar] [CrossRef]
- Fukushima, K. A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 1980, 36, 193–202. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Zhang, M.; Wei, L.; Qian, D. Diverse region-based CNN for hyperspectral image classification. IEEE Trans. Image Process. 2018, 27, 2623–2634. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Bo, D. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Chang, Y.; Yan, L.; Fang, H.; Zhong, S.; Liao, W. HSI-DeNet: Hyperspectral image restoration via convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2018, 57, 667–682. [Google Scholar] [CrossRef]
- Yu, C.; Zhao, M.; Song, M.; Wang, Y.; Li, F.; Han, R.; Chang, C.I. Hyperspectral image classification method based on CNN architecture embedding with hashing semantic feature. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1866–1881. [Google Scholar] [CrossRef]
- He, N.; Paoletti, M.E.; Haut, J.M.; Fang, L.; Li, S.; Plaza, A.; Plaza, J. Feature extraction with multiscale covariance maps for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 57, 755–769. [Google Scholar] [CrossRef]
- Paoletti, M.E.; Haut, J.M.; Plaza, J.; Plaza, A. A new deep convolutional neural network for fast hyperspectral image classification. ISPRS J. Photogramm. Remote Sens. 2018, 145, 120–147. [Google Scholar] [CrossRef]
- Sellami, A.; Farah, M.; Farah, I.R.; Solaiman, B. Hyperspectral imagery classification based on semi-supervised 3-D deep neural network and adaptive band selection. Expert Syst. Appl. 2019, 129, 246–259. [Google Scholar] [CrossRef]
- Liu, H.; Li, W.; Xia, X.G.; Zhang, M.; Gao, C.Z.; Tao, R. Central Attention Network for Hyperspectral Imagery Classification. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D–2-D CNN feature hierarchy for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2019, 17, 277–281. [Google Scholar] [CrossRef]
- Li, Y.; Xie, W.; Li, H. Hyperspectral image reconstruction by deep convolutional neural network for classification. Pattern Recognit. 2017, 63, 371–383. [Google Scholar] [CrossRef]
- Zhang, T.; Fu, Y.; Wang, L.; Huang, H. Hyperspectral image reconstruction using deep external and internal learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Wang, G.; Ye, J.C.; De Man, B. Deep learning for tomographic image reconstruction. Nat. Mach. Intell. 2020, 2, 737–748. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, W.; Zhang, M.; Qu, Y.; Tao, R.; Qi, H. Topological structure and semantic information transfer network for cross-scene hyperspectral image classification. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef]
- Li, X.; Ding, M.; Aleksandra, P. Deep feature fusion via two-stream convolutional neural network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2615–2629. [Google Scholar] [CrossRef]
- Kong, Y.; Wang, X.; Cheng, Y. Spectral–spatial feature extraction for HSI classification based on supervised hypergraph and sample expanded CNN. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4128–4140. [Google Scholar] [CrossRef]
- Zhang, H.; Li, Y.; Zhang, Y.; Shen, Q. Spectral-spatial classification of hyperspectral imagery using a dual-channel convolutional neural network. Remote Sens. Lett. 2017, 8, 438–447. [Google Scholar] [CrossRef]
- Li, W.; Gao, Y.; Zhang, M.; Tao, R.; Du, Q. Asymmetric Feature Fusion Network for Hyperspectral and SAR Image Classification. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Li, W.; Du, Q.; Gao, L.; Zhang, B. Feature extraction for classification of hyperspectral and LiDAR data using patch-to-patch CNN. IEEE Trans. Cybern. 2018, 50, 100–111. [Google Scholar] [CrossRef]
- Zhang, M.; Li, W.; Tao, R.; Li, H.; Du, Q. Information fusion for classification of hyperspectral and LiDAR data using IP-CNN. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–12. [Google Scholar] [CrossRef]
- Yang, J.; Wu, C.; Du, B.; Zhang, L. Enhanced Multiscale Feature Fusion Network for HSI Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10328–10347. [Google Scholar] [CrossRef]
- Ge, Z.; Cao, G.; Li, X.; Fu, P. Hyperspectral image classification method based on 2D–3D CNN and multibranch feature fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5776–5788. [Google Scholar] [CrossRef]
- Sellami, A.; Abbes, A.B.; Barra, V.; Farah, I.R. Fused 3-D spectral-spatial deep neural networks and spectral clustering for hyperspectral image classification. Pattern Recognit. Lett. 2020, 138, 594–600. [Google Scholar] [CrossRef]
- Li, Z.; Wang, T.; Li, W.; Du, Q.; Wang, C.; Liu, C.; Shi, X. Deep multilayer fusion dense network for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1258–1270. [Google Scholar] [CrossRef]
- Gao, K.; Liu, B.; Yu, X.; Qin, J.; Zhang, P.; Tan, X. Deep relation network for hyperspectral image few-shot classification. Remote Sens. 2020, 12, 923. [Google Scholar] [CrossRef]
- He, X.; Chen, Y.; Pedram, G. Heterogeneous transfer learning for hyperspectral image classification based on convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3246–3263. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, W.; Tao, R.; Peng, J.; Du, Q.; Cai, Z. Cross-scene hyperspectral image classification with discriminative cooperative alignment. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9646–9660. [Google Scholar] [CrossRef]
- Hu, W.-S.; Li, H.C.; Pan, L.; Li, W.; Tao, R.; Du, Q. Spatial–spectral feature extraction via deep ConvLSTM neural networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4237–4250. [Google Scholar] [CrossRef]
- Liu, B.; Yu, X.; Zhang, P.; Tan, X.; Wang, R.; Zhi, L. Spectral–spatial classification of hyperspectral image using three-dimensional convolution network. J. Appl. Remote Sens. 2018, 12, 016005. [Google Scholar]
- Mohan, A.; Venkatesan, M. HybridCNN based hyperspectral image classification using multiscale spatiospectral features. Infrared Phys. Technol. 2020, 108, 103326. [Google Scholar] [CrossRef]
- Paul, A.; Sanghamita, B.; Nabendu, C. SSNET: An improved deep hybrid network for hyperspectral image classification. Neural Comput. Appl. 2021, 33, 1575–1585. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Golnaz, G.; Lin, T.-Y.; Le, Q.V. Dropblock: A regularization method for convolutional networks. arXiv 2018, arXiv:1810.12890. [Google Scholar]
- Sergey, I.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International Conference on Machine Learning; PMLR: New York, NY, USA, 2015. [Google Scholar]
- Available online: https://www.microsoft.com/zh-cn/windows?r=1 (accessed on 2 August 2022).
- Available online: https://www.python.org/ (accessed on 2 August 2022).
- Available online: https://www.tensorflow.org/?hl=zh-cn (accessed on 2 August 2022).
- Available online: https://developer.nvidia.com/cuda-toolkit (accessed on 2 August 2022).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spatial–Spectral Channel | Spectral Channel | Fully Connected Layers | ||||||
|---|---|---|---|---|---|---|---|---|
| Layer | Channels/P | Size | Layer | Channels/P | Size | Layer | Type | Parameter |
| 3DConv_1 | 16 | 1 × 1 × 5 | 3DConv_1 | 32 | 3 × 3 × 3 | Dropout | Dropout | 0.2 |
| AvgPool_1 | / | 1 × 1 × 2 | AvgPool_1 | / | 2 × 2 × 2 | Dense_1 | Fullyconnected + ReLU | 128 |
| DropBlock_1 | 0.15 | 1 × 1 × 3 | DropBlock_1 | 0.25 | 3 × 3 × 3 | Dropout | Dropout | 0.2 |
| 3DConv_2 | 32 | 1 × 1 × 3 | 3DConv_2 | 32 | 3 × 3 × 5 | Output | Fullyconnected + softmax | C |
| AvgPool_2 | / | 1 × 1 × 2 | AvgPool_2 | / | 2 × 2 × 2 | |||
| DropBlock_2 | 0.15 | 1 × 1 × 3 | DropBlock_2 | 0.25 | 3 × 3 × 3 | |||
| 3DConv_3 | 64 | 1 × 1 × 1 | 3DConv_3 | 64 | 3 × 3 × 3 | |||
| Dropout | 0.2 | / | Dropout | 0.2 | / | |||
| 2DConv_1 | 256 | 1 × 1 | 2DConv_1 | 128 | 1 × 1 | |||
| 2DConv_2 | 128 | 1 × 1 | 2DConv_2 | 64 | 1 × 1 | |||
| Flatten | / | / | Flatten | / | / | |||
| Dropout | 0.2 | / | Dropout | 0.2 | / | |||
| Plastic | / | 256 | Plastic | / | 256 | |||
| Indian Pines Dataset | University of Pavia Dataset | Salinas Scene Dataset | |||
|---|---|---|---|---|---|
| Land Cover Type | Samples | Land Cover Type | Samples | Land Cover Type | Samples |
| Alfalfa | 46 | Asphalt | 6631 | Brocoli_green_weeds_1 | 2009 |
| Corn-notill | 1428 | Meadows | 18,649 | Brocoli_green_weeds_2 | 3726 |
| Corn-min | 830 | Gravel | 2099 | Fallow | 1976 |
| Corn | 237 | Trees | 3064 | Fallow_rough_plow | 1394 |
| Grass/Pasture | 483 | Painted metal sheets | 1345 | Fallow_smooth | 2678 |
| Grass/Trees | 730 | Bare Soil | 5029 | Stubble | 3959 |
| Grass/Pasture-mowed | 28 | Bitumen | 1330 | Celery | 3579 |
| Hay-windrowed | 478 | Self-Blocking Bricks | 3682 | Grapes_untrained | 11,271 |
| Oats | 20 | Shadows | 947 | Soil_vinyard_develop | 6203 |
| Soybeans-notill | 972 | Corn_senesced_green_weeds | 3278 | ||
| Soybeans-min | 2455 | Lettuce_romaine_4wk | 1068 | ||
| Soybeans-clean | 693 | Lettuce_romaine_5wk | 1927 | ||
| Wheat | 205 | Lettuce_romaine_6wk | 916 | ||
| Woods | 1265 | Lettuce_romaine_7wk | 1070 | ||
| Bldg-Grass-Tree-Drives | 386 | Vinyard_untrained | 7268 | ||
| Stone-steel towers | 93 | Vinyard_vertical_trellis | 1807 | ||
| Total | 10,349 | Total | 42,776 | Total | 54,129 |
| Dataset | 4:1 | 3:1 | 2:1 | 1:1 | 1:2 | 1:3 | 1:4 |
|---|---|---|---|---|---|---|---|
| IP | 75.31 | 76.49 | 77.02 | 77.94 | 76.61 | 75.15 | 74.61 |
| UP | 85.19 | 86.66 | 87.51 | 88.53 | 86.18 | 85.35 | 84.02 |
| SA | 94.45 | 95.41 | 95.98 | 96.35 | 95.45 | 94.13 | 93.06 |
| Dataset | 21 × 21 | 23 × 23 | 25 × 25 | 27 × 27 |
|---|---|---|---|---|
| IP | 71.80 | 75.23 | 77.75 | 77.89 |
| UP | 79.41 | 84.50 | 88.05 | 88.84 |
| SA | 92.18 | 94.06 | 96.31 | 96.01 |
| Dataset | 21 × 21 | 23 × 23 | 25 × 25 | 27 × 27 |
|---|---|---|---|---|
| IP | 87.03 | 93.04 | 99.12 | 120.68 |
| UP | 52.18 | 52.75 | 57.00 | 73.56 |
| SA | 74.47 | 79.41 | 85.70 | 98.31 |
| Model | Indian Pines | University of Pavia | Salinas Scene |
|---|---|---|---|
| HybridSN | 90.20 | 34.18 | 54.43 |
| MAPC | 706.67 | 1541.16 | 1469.79 |
| MFFN | 171.88 | 102.36 | 136.21 |
| DC-CNN | 32.33 | 30.44 | 30.46 |
| DSEN | 98.10 | 58.12 | 87.32 |
| Sample | Spatial-Spectral | Spectral | Dual-Channel | ||||||
|---|---|---|---|---|---|---|---|---|---|
| IP | UP | SA | IP | UP | SA | IP | UP | SA | |
| 5 | 61.59 | 75.77 | 91.87 | 45.21 | 61.27 | 72.31 | 69.47 | 80.54 | 93.24 |
| 10 | 71.01 | 83.80 | 94.17 | 50.19 | 68.35 | 75.51 | 77.94 | 88.53 | 96.35 |
| 15 | 78.55 | 87.69 | 95.71 | 54.03 | 72.91 | 84.51 | 83.94 | 90.64 | 97.61 |
| Training Sample | Model | Indian Pines | University of Pavia | Salinas Scene | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| OA (%) | AA (%) | Kappa | OA (%) | AA (%) | Kappa | OA (%) | AA (%) | Kappa | ||
| 5 | HybridSN | 57.25 | 72.54 | 0.53 | 71.38 | 72.24 | 0.67 | 86.93 | 89.06 | 0.86 |
| MAPC | 67.27 | 78.32 | 0.63 | 76.20 | 79.33 | 0.69 | 92.57 | 94.84 | 0.89 | |
| MFFN | 44.44 | 57.75 | 0.39 | 56.94 | 59.97 | 0.51 | 59.25 | 59.43 | 0.56 | |
| DC-CNN | 60.33 | 72.77 | 0.54 | 73.52 | 74.76 | 67.59 | 89.70 | 90.72 | 0.88 | |
| DSEN | 69.47 | 81.11 | 0.66 | 80.54 | 83.63 | 0.78 | 93.24 | 94.09 | 0.93 | |
| 10 | HybridSN | 65.50 | 76.49 | 0.61 | 77.72 | 79.86 | 0.75 | 94.18 | 94.87 | 0.94 |
| MAPC | 76.14 | 80.59 | 0.75 | 83.58 | 86.65 | 0.81 | 96.04 | 97.01 | 0.96 | |
| MFFN | 58.24 | 73.06 | 0.54 | 58.22 | 64.34 | 0.53 | 80.15 | 82.80 | 0.79 | |
| DC-CNN | 77.88 | 85.61 | 0.75 | 82.14 | 85.20 | 0.80 | 95.42 | 93.51 | 0.92 | |
| DSEN | 77.94 | 86.82 | 0.75 | 88.53 | 90.00 | 0.87 | 96.35 | 97.10 | 0.96 | |
| 15 | HybridSN | 66.06 | 79.24 | 0.62 | 86.88 | 89.05 | 0.85 | 95.31 | 95.98 | 0.95 |
| MAPC | 82.71 | 90.06 | 0.80 | 89.78 | 92.35 | 0.89 | 97.24 | 97.09 | 0.96 | |
| MFFN | 68.32 | 79.67 | 0.65 | 70.08 | 75.89 | 0.66 | 88.87 | 90.32 | 0.88 | |
| DC-CNN | 79.94 | 90.12 | 0.78 | 87.57 | 89.58 | 0.86 | 96.28 | 96.95 | 0.96 | |
| DSEN | 83.94 | 91.55 | 0.82 | 90.64 | 91.45 | 0.89 | 97.61 | 97.96 | 0.97 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pei, S.; Song, H.; Lu, Y. Small Sample Hyperspectral Image Classification Method Based on Dual-Channel Spectral Enhancement Network. Electronics 2022, 11, 2540. https://doi.org/10.3390/electronics11162540
Pei S, Song H, Lu Y. Small Sample Hyperspectral Image Classification Method Based on Dual-Channel Spectral Enhancement Network. Electronics. 2022; 11(16):2540. https://doi.org/10.3390/electronics11162540
Chicago/Turabian StylePei, Songwei, Hong Song, and Yinning Lu. 2022. "Small Sample Hyperspectral Image Classification Method Based on Dual-Channel Spectral Enhancement Network" Electronics 11, no. 16: 2540. https://doi.org/10.3390/electronics11162540
APA StylePei, S., Song, H., & Lu, Y. (2022). Small Sample Hyperspectral Image Classification Method Based on Dual-Channel Spectral Enhancement Network. Electronics, 11(16), 2540. https://doi.org/10.3390/electronics11162540