
Leveraging a Heterogeneous Ensemble Learning for Outcome-Based Predictive Monitoring Using Business Process Event Logs



Abstract
:1. Introduction
2. Related Work
3. Problem Definition and Method
3.1. Problem Definition
3.2. Proposed Prediction Model
| Algorithm 1 Procedure to construct a stacked generalization ensemble with an internal for outcome-based predictive monitoring of business process |
Preparation: Event log training dataset, with i rows and j columns, depicted as input matrix and response matrix . Set tuned constituent learning algorithms, i.e., RF, GBM, and XGB. Set the metalearner, e.g., generalized linear model. Training phase: Train each on the training set using stratified . Gather the prediction results, Gather prediction values from models and construct a new matrix Along with original response vector , train and cross-validate metalearner: . Prediction phase: Collect the prediction results from models and feed into metalearner. Collect the final stacked generalization ensemble prediction. |
- (a)
- Random forest (RF) [24]A variant of bagging ensemble, in which a decision tree is employed as the base classifier. It is composed of a set of tree-structured weak classifiers, each of which is formed in response to a random vector , where , are all mutually independent and distributed. Each single tree votes a single unit, voting for the most popular class represented by the input x. The hyperparameters to specify to build a random forest model are the number of trees (), minimum number of samples for a leaf (), maximum tree depth (), number of bins for the histogram to build ( and ), row sampling rate (), column sampling rate as a function of the depth in the tree (), column sample rate per tree (), minimum relative improvement in squared error reduction in order for a split to occur (), and type of histogram to use for finding optimal split ().
- (b)
- Gradient boosting machine (GBM) [25]A forward learning ensemble, where a classification and regression tree (CART) is used as the base classifier. It develops trees in a sequential fashion, with subsequent trees relying on the outcomes of the preceding trees. For a particular sample S, the final estimate is the total of the estimates from each tree. The hyperparameters to specify to build a gradient boosting machine model are the number of trees (), minimum number of samples for a leaf (), maximum tree depth (), number of bins for the histogram to build ( and ), learning rate (), column sampling rate (), row sampling rate (), column sampling rate as a function of the depth in the tree (), column sample rate per tree (), minimum relative improvement in squared error reduction in order for a split to occur (), and type of histogram to use for finding the optimal split ().
- (c)
- Extreme gradient boosting machine (XGB) [26]One of the most popular gradient boosting machine frameworks that implements a process called boosting to produce accurate models. Both gradient boosting machine and extreme gradient boosting machine operate on the same gradient boosting concept. XGB, specifically, employs a more regularized model to prevent overfitting, which is intended to improve the performance. In addition, XGB utilizes sparse matrices with a sparsity-aware algorithm that allows more efficient use of the processor’s cache. Similar to previous classifiers, there are hyperparameters that must be specified when creating an XGB model such as number of trees (), minimum number of samples for a leaf (), maximum tree depth (), learning rate (), column sampling rate (), row sampling rate (), column sample rate per tree (), and minimum relative improvement in squared error reduction in order for a split to happen ().
4. Evaluation
4.1. Datasets
- 1.
- BPIC 2011This log records the events of a process in a Dutch academic hospital over a three-year period. Each process case compiles a patient’s medical history, where operations and therapies are recorded as activities. There are four labeling functions defined for this event log. Each label records whether a trace violates or fulfills linear temporal logic constraints defined over the order and occurrence of specific activities in a trace [27]:
- (“ca-125 using meia”)
- 2.
- BPIC 2012Each case in this event log records the events that occurred in connection with a loan application at a financial institution. Three different labeling functions are defined for this event log, depending on the final result of a case, i.e., whether an application is accepted, rejected, or canceled. In this work, we treat each labeling function as a separate one, which leads us to consider three datasets (, , and ) with a binary label.
- 3.
- BPIC 2013This event log records events of an incident management process at a large European manufacturer in the automotive industry. For each IT incident, a solution should be created in order to restore the IT services with minimal business disruption. An incident is closed after a solution to the problem has been found and the service restored. In this work, we use the same datasets already considered by Marquez et al. [2]. In their work, the authors consider three distinct prediction tasks, depending on the risk circumstances to be predicted. In the first one, a push-to-front scenario considers the situation in which first-line support personnel are responsible for handling the majority of occurrences. A binary label is assigned to each incident depending on whether it was resolved using only the 1st line support team or if it required the intervention of the 2nd or 3rd line support team. As in the original publication [2], for this binary label, a sliding window encoding is considered, leading to five datasets (, with ), where i specifies the number of events. Another situation in this event log concerns the abuse of the wait-user substatus, which should not be utilized by action owners unless they are truly waiting for an end-user, according to company policy. Further in this case, five datasets are available, where i is the size—i.e., number of events—of the window chosen for the encoding. A third situation concerns anticipating the ping-pong behavior, in which support teams repeatedly transfer incidents to one another, increasing the overall lifetime of the incident. Two datasets are defined ( and ) for the window size .
- 4.
- BPIC 2015This dataset contains event logs from five Dutch municipalities regarding the process of obtaining a building permit. We consider each municipality’s dataset as a distinct event log and use the same labeling function for each dataset. As with BPIC 2011, the labeling function is determined by the fulfillment/violation of an LTL constraint. The prediction tasks for each of the five municipalities are designated by the abbreviation , where denotes the municipality’s number. The LTL constraint that is utilized in the labeling functions is
- 5.
- BPIC 2017This dataset is an updated version of the BPIC 2012 event log containing events captured after the deployment of a new information system in the same loan application request management process at a financial institution. Even for this event log, three labeling functions are defined based on the outcome of a loan application (accepted, canceled, rejected), which leads to the three datasets , , and .
4.2. Experimental Settings and Performance Metrics
- : positive samples that are (correctly) predicted as positive (True Positives).
- : negative samples that are (correctly) predicted as negative (True Negatives).
- : negative samples that are (wrongly) predicted as positive (False Positives).
- : positive samples that are (wrongly) predicted as negative (False Negatives).
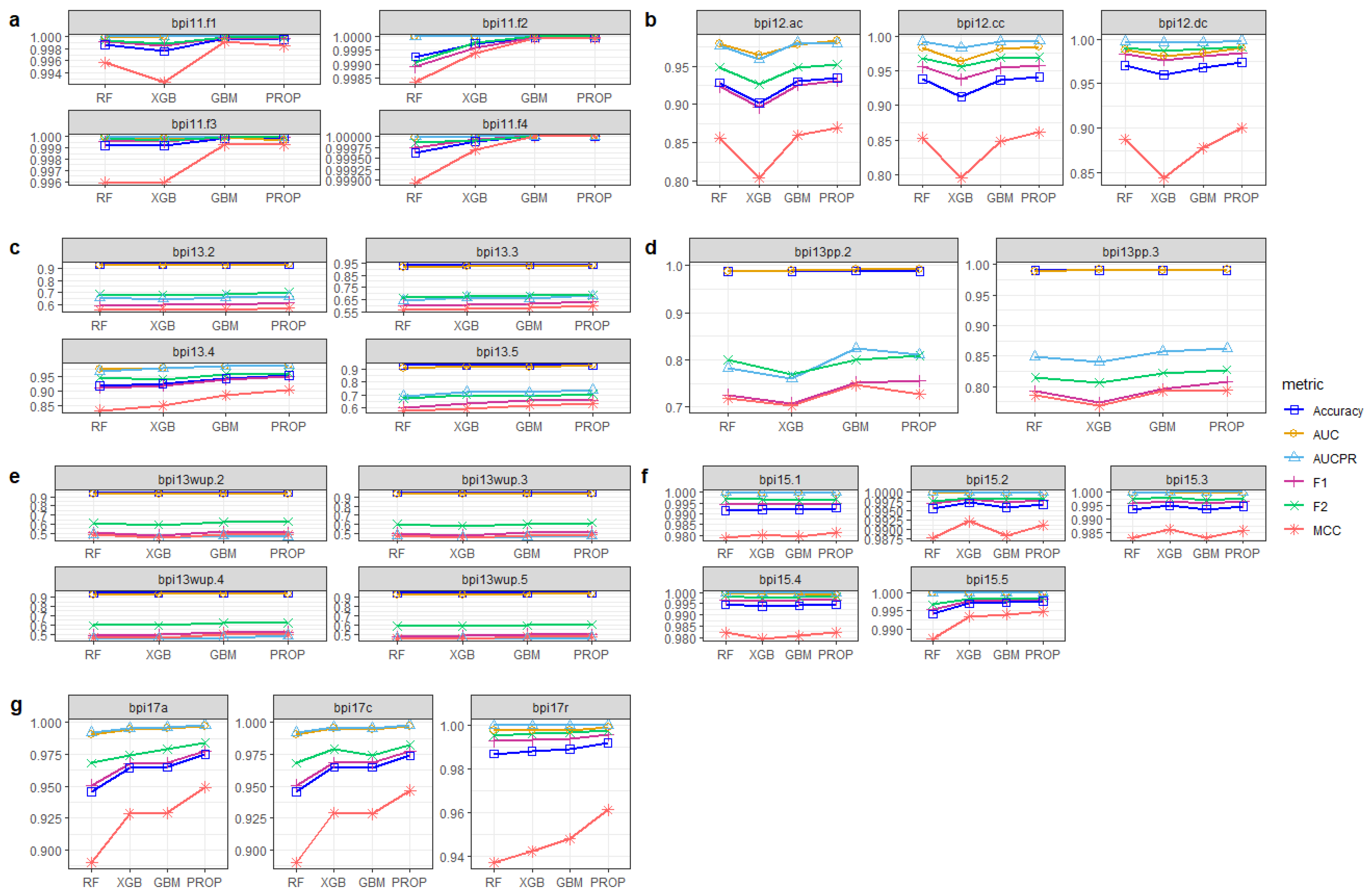
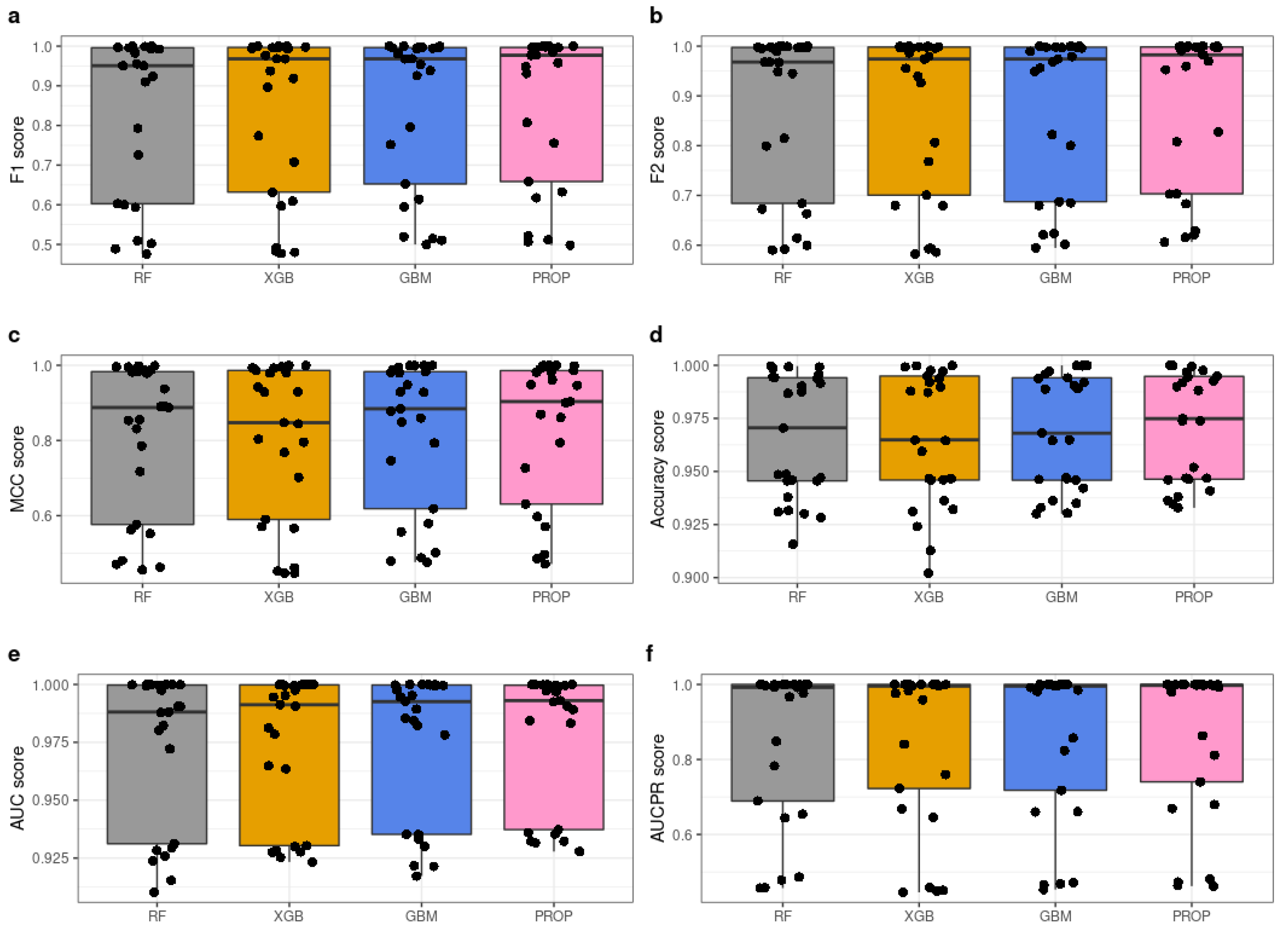
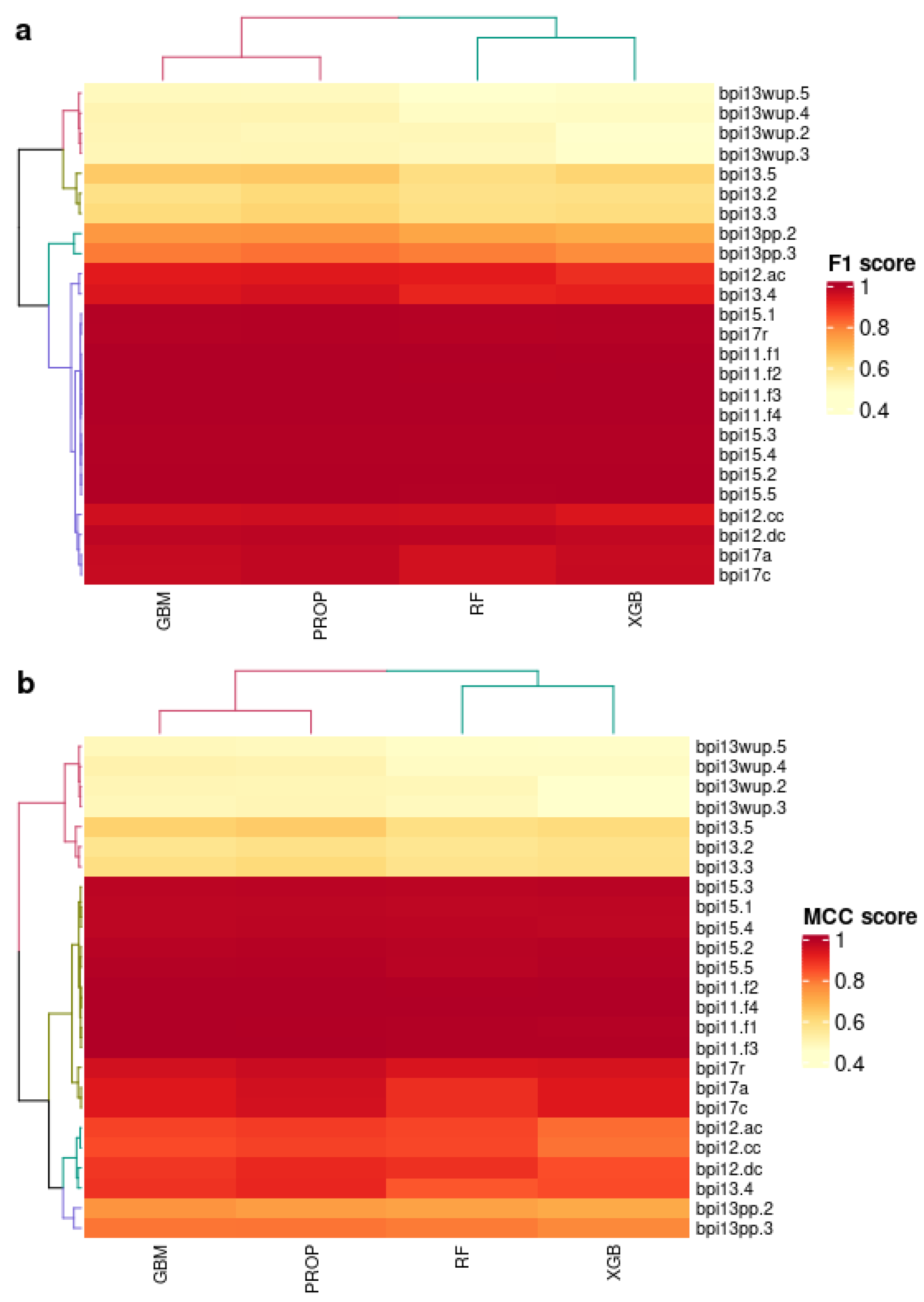
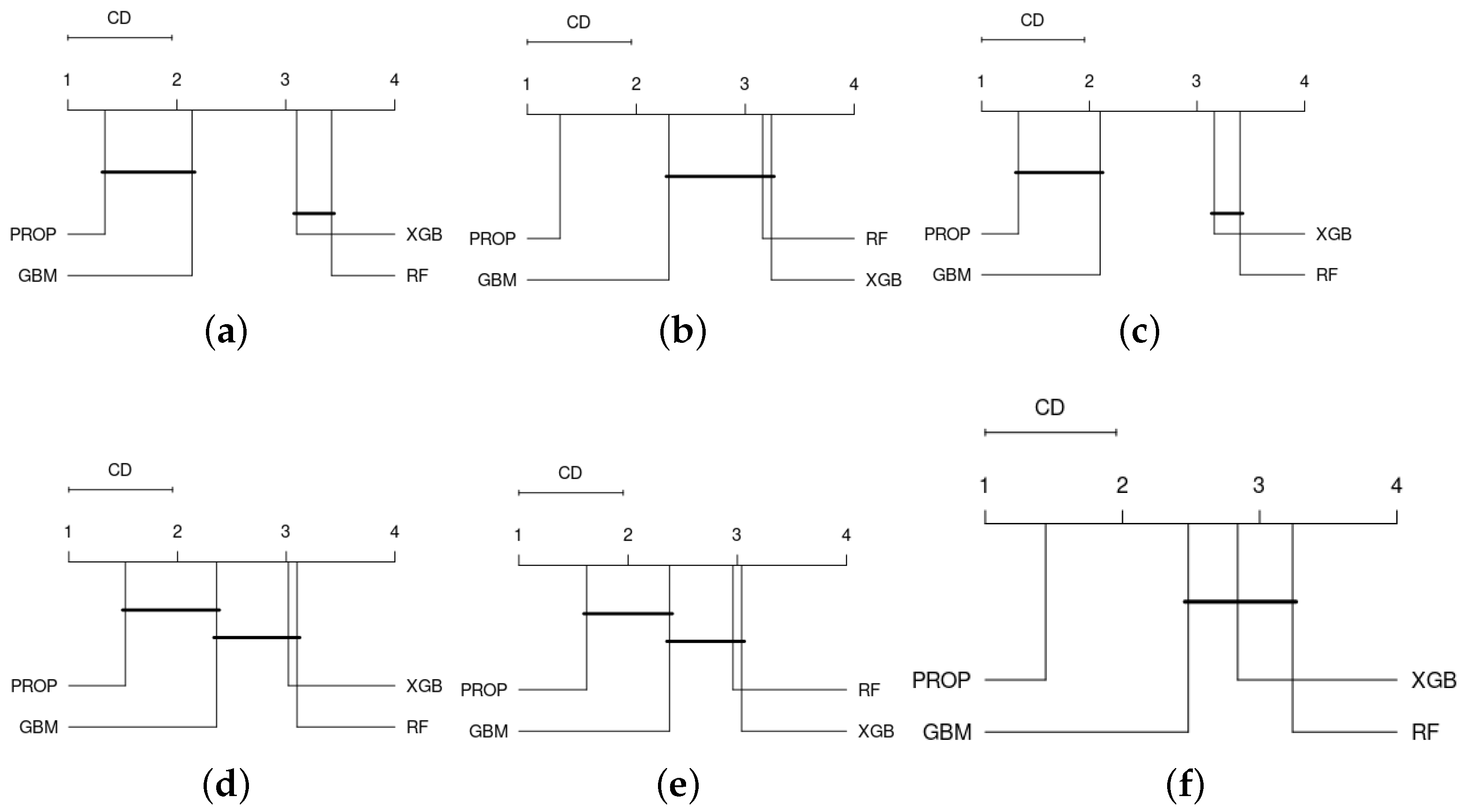
4.3. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
| BPIC 2011 | |||||||||||
| Classifier | |||||||||||
| RF | 2 | 24 | 256 | - | 2048 | na | 0.59 | - | 0.31 | 1.00 × 10 | Quantiles global |
| GBM | 2 | 25 | 128 | 0.05 | 2048 | 0.54 | 0.72 | 1.07 | 0.58 | 1.00 × 10 | Uniform adaptive |
| XGB | 2 | 27 | - | 0.05 | - | 0.73 | 0.8 | - | 0.52 | 1.00 × 10 | - |
| BPIC 2011 | |||||||||||
| Classifier | |||||||||||
| RF | 2 | 26 | 256 | - | 16 | - | 0.85 | 1.06 | 0.34 | 1.00 × 10 | Uniform adaptive |
| GBM | 4 | 24 | 32 | 0.05 | 64 | 0.95 | 0.7 | 1.03 | 0.29 | 1.00 × 10 | Uniform adaptive |
| XGB | 2 | 27 | - | 0.05 | - | 0.58 | 0.78 | - | 0.52 | 1.00 × 10 | - |
| BPIC 2011 | |||||||||||
| Classifier | |||||||||||
| RF | 4 | 26 | 1024 | - | 128 | - | 0.36 | 1.08 | 0.72 | 1.00 × 10 | Quantiles global |
| GBM | 1 | 21 | 512 | 0.05 | 512 | 0.5 | 0.64 | 1.02 | 0.65 | 1.00 × 10 | Round robin |
| XGB | 2 | 12 | - | 0.05 | - | 0.71 | 0.92 | - | 0.71 | 1.00 × 10 | - |
| BPIC 2011 | |||||||||||
| Classifier | |||||||||||
| RF | 4 | 26 | 1024 | - | 64 | - | 0.7 | 1.04 | 0.62 | 1.00 × 10 | Quantiles global |
| GBM | 4 | 16 | 1024 | 0.05 | 512 | 0.75 | 0.5 | 0.99 | 0.8 | 1.00 × 10 | Uniform adaptive |
| XGB | 2 | 25 | - | 0.05 | - | 0.82 | 0.42 | - | 0.39 | 1.00 × 10 | - |
| BPIC 2011 | |||||||||||
| Classifier | |||||||||||
| RF | 4 | 26 | 1024 | - | 64 | - | 0.7 | 1.04 | 0.62 | 1.00 × 10 | Quantiles global |
| GBM | 8 | 28 | 16 | 0.05 | 128 | 0.6 | 0.64 | - | 0.89 | 0 | Uniform adaptive |
| XGB | 8 | 12 | - | 0.05 | - | 0.83 | 0.87 | - | 0.75 | 1.00 × 10 | - |
| BPIC 2011 | |||||||||||
| Classifier | |||||||||||
| RF | 2 | 26 | 256 | - | 16 | - | 0.85 | 1.06 | 0.34 | 1.00 × 10 | Uniform adaptive |
| GBM | 1 | 21 | 512 | 0.05 | 32 | 0.72 | 0.54 | 1.08 | 0.32 | 0 | Uniform adaptive |
| XGB | 1 | 17 | - | 0.05 | - | 0.7 | 0.92 | - | 0.55 | 1.00 × 10 | - |
| BPIC 2011 | |||||||||||
| Classifier | |||||||||||
| RF | 8 | 27 | 512 | - | 256 | - | 0.95 | 1.07 | 0.73 | 1.00 × 10 | Quantiles global |
| GBM | 2 | 24 | 32 | 0.05 | 64 | 0.95 | 0.7 | 1.03 | 0.29 | 1.00 × 10 | Uniform adaptive |
| XGB | 2 | 26 | - | 0.05 | - | 0.71 | 0.92 | - | 0.71 | 1.00 × 10 | - |
References
- Van der Aalst, W.M. Process Mining: Data Science in Action; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Márquez-Chamorro, A.E.; Resinas, M.; Ruiz-Cortés, A. Predictive monitoring of business processes: A survey. IEEE Trans. Serv. Comput. 2017, 11, 962–977. [Google Scholar] [CrossRef]
- Verenich, I.; Dumas, M.; Rosa, M.L.; Maggi, F.M.; Teinemaa, I. Survey and cross-benchmark comparison of remaining time prediction methods in business process monitoring. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–34. [Google Scholar] [CrossRef]
- Evermann, J.; Rehse, J.R.; Fettke, P. Predicting process behaviour using deep learning. Decis. Support Syst. 2017, 100, 129–140. [Google Scholar] [CrossRef]
- Tama, B.A.; Comuzzi, M. An empirical comparison of classification techniques for next event prediction using business process event logs. Exp. Syst. Appl. 2019, 129, 233–245. [Google Scholar] [CrossRef]
- Tama, B.A.; Comuzzi, M.; Ko, J. An Empirical Investigation of Different Classifiers, Encoding, and Ensemble Schemes for Next Event Prediction Using Business Process Event Logs. ACM Trans. Intell. Syst. Technol. 2020, 11, 1–34. [Google Scholar] [CrossRef]
- Teinemaa, I.; Dumas, M.; Rosa, M.L.; Maggi, F.M. Outcome-oriented predictive process monitoring: Review and benchmark. ACM Trans. Knowl. Discov. Data 2019, 13, 17. [Google Scholar] [CrossRef]
- Senderovich, A.; Di Francescomarino, C.; Maggi, F.M. From knowledge-driven to data-driven inter-case feature encoding in predictive process monitoring. Inf. Syst. 2019, 84, 255–264. [Google Scholar] [CrossRef]
- Kim, J.; Comuzzi, M.; Dumas, M.; Maggi, F.M.; Teinemaa, I. Encoding resource experience for predictive process monitoring. Decis. Support Syst. 2022, 153, 113669. [Google Scholar] [CrossRef]
- Van der Laan, M.J.; Polley, E.C.; Hubbard, A.E. Super learner. Stat. Appl. Genet. Mol. Biol. 2007, 6. [Google Scholar] [CrossRef] [PubMed]
- Di Francescomarino, C.; Ghidini, C.; Maggi, F.M.; Milani, F. Predictive Process Monitoring Methods: Which One Suits Me Best? In Proceedings of the International Conference on Business Process Management, Sydney, Australia, 9–14 September 2018; Springer: Cham, Switzerland, 2018; pp. 462–479. [Google Scholar]
- Santoso, A. Specification-driven multi-perspective predictive business process monitoring. In Enterprise, Business-Process and Information Systems Modeling; Springer: Cham, Switzerland, 2018; pp. 97–113. [Google Scholar]
- Verenich, I.; Dumas, M.; La Rosa, M.; Nguyen, H. Predicting process performance: A white-box approach based on process models. J. Softw. Evol. Process 2019, 31, e2170. [Google Scholar] [CrossRef]
- Galanti, R.; Coma-Puig, B.; de Leoni, M.; Carmona, J.; Navarin, N. Explainable predictive process monitoring. In Proceedings of the 2020 2nd International Conference on Process Mining (ICPM), Padua, Italy, 5–8 October 2020; pp. 1–8. [Google Scholar]
- Rama-Maneiro, E.; Vidal, J.C.; Lama, M. Deep learning for predictive business process monitoring: Review and benchmark. arXiv 2020, arXiv:2009.13251. [Google Scholar] [CrossRef]
- Neu, D.A.; Lahann, J.; Fettke, P. A systematic literature review on state-of-the-art deep learning methods for process prediction. Artif. Intell. Rev. 2021, 55, 801–827. [Google Scholar] [CrossRef]
- Kratsch, W.; Manderscheid, J.; Röglinger, M.; Seyfried, J. Machine learning in business process monitoring: A comparison of deep learning and classical approaches used for outcome prediction. Bus. Inf. Syst. Eng. 2020, 63, 261–276. [Google Scholar] [CrossRef]
- Metzger, A.; Neubauer, A.; Bohn, P.; Pohl, K. Proactive Process Adaptation Using Deep Learning Ensembles. In Proceedings of the International Conference on Advanced Information Systems Engineering, Rome, Italy, 3–7 June 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 547–562. [Google Scholar]
- Wang, J.; Yu, D.; Liu, C.; Sun, X. Outcome-oriented predictive process monitoring with attention-based bidirectional LSTM neural networks. In Proceedings of the 2019 IEEE International Conference on Web Services (ICWS), Milan, Italy, 8–13 June 2019; pp. 360–367. [Google Scholar]
- Folino, F.; Folino, G.; Guarascio, M.; Pontieri, L. Learning effective neural nets for outcome prediction from partially labelled log data. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; pp. 1396–1400. [Google Scholar]
- Pasquadibisceglie, V.; Appice, A.; Castellano, G.; Malerba, D.; Modugno, G. ORANGE: Outcome-oriented predictive process monitoring based on image encoding and cnns. IEEE Access 2020, 8, 184073–184086. [Google Scholar] [CrossRef]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Di Francescomarino, C.; Dumas, M.; Maggi, F.M.; Teinemaa, I. Clustering-based predictive process monitoring. IEEE Trans. Serv. Comput. 2016, 12, 896–909. [Google Scholar] [CrossRef]
- Saito, T.; Rehmsmeier, M. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef] [PubMed]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef]
- Shwartz-Ziv, R.; Armon, A. Tabular data: Deep learning is not all you need. Inf. Fusion 2022, 81, 84–90. [Google Scholar] [CrossRef]
- Borisov, V.; Leemann, T.; Seßler, K.; Haug, J.; Pawelczyk, M.; Kasneci, G. Deep neural networks and tabular data: A survey. arXiv 2021, arXiv:2110.01889. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Event Log | #Input Features | ||||
|---|---|---|---|---|---|---|
| BPIC 2011 | 67,480 | 53,841 | 13,639 | 22 | 0.253 | |
| 149,730 | 50,051 | 99,679 | 22 | 0.502 | ||
| 70,546 | 62,981 | 7565 | 22 | 0.120 | ||
| 93,065 | 71,301 | 21,764 | 22 | 0.305 | ||
| BPIC 2012 | 186,693 | 86,948 | 99,745 | 14 | 0.872 | |
| 186,693 | 129,890 | 56,803 | 14 | 0.437 | ||
| 186,693 | 156,548 | 30,145 | 14 | 0.193 | ||
| BPIC 2013 | 33,861 | 30,452 | 3409 | 23 | 0.112 | |
| 35,548 | 32,140 | 3408 | 34 | 0.106 | ||
| 7301 | 3893 | 3408 | 45 | 0.875 | ||
| 30,916 | 27,508 | 3408 | 56 | 0.124 | ||
| 65,530 | 61,659 | 3871 | 23 | 0.063 | ||
| 65,530 | 61,659 | 3871 | 34 | 0.063 | ||
| 65,529 | 61,659 | 3871 | 45 | 0.063 | ||
| 65,528 | 61,659 | 3871 | 56 | 0.063 | ||
| 61,135 | 59,619 | 1516 | 45 | 0.025 | ||
| 61,135 | 59,619 | 1516 | 67 | 0.025 | ||
| BPIC 2015 | 28,775 | 20,635 | 8140 | 31 | 0.394 | |
| 41,202 | 31,653 | 9549 | 31 | 0.302 | ||
| 57,488 | 43,667 | 13,821 | 32 | 0.317 | ||
| 24,234 | 19,878 | 4356 | 29 | 0.219 | ||
| 54,562 | 34,948 | 19,614 | 33 | 0.561 | ||
| BPIC 2017 | 1,198,366 | 665,182 | 533,184 | 25 | 0.802 | |
| 1,198,366 | 677,682 | 520,684 | 25 | 0.768 | ||
| 1,198,366 | 1,053,868 | 144,498 | 25 | 0.137 |
| Dataset | Event Logs | Classifier | Classifier | F1 | F2 | MCC | Accuracy | AUCPR | AUC |
|---|---|---|---|---|---|---|---|---|---|
| BPIC11 | bpi11.f1 | PROP | RF | 0.056 | 0.041 | 0.275 | 0.089 | 0.002 | 0.005 |
| XGB | 0.121 | 0.099 | 0.597 | 0.193 | 0.001 | 0.002 | |||
| GBM | −0.014 | −0.007 | −0.069 | −0.022 | −0.001 | −0.005 | |||
| bpi11.f2 | PROP | RF | 0.105 | 0.094 | 0.158 | 0.070 | 0.001 | 0.000 | |
| XGB | 0.035 | 0.020 | 0.053 | 0.023 | 0.000 | 0.000 | |||
| GBM | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||
| bpi11.f3 | PROP | RF | 0.036 | 0.014 | 0.335 | 0.064 | −0.008 | −0.030 | |
| XGB | 0.036 | 0.027 | 0.335 | 0.064 | −0.006 | −0.019 | |||
| GBM | 0.000 | 0.000 | 0.000 | 0.000 | −0.008 | −0.032 | |||
| bpi11.f4 | PROP | RF | 0.025 | 0.014 | 0.105 | 0.038 | 0.000 | 0.000 | |
| XGB | 0.007 | 0.008 | 0.030 | 0.011 | 0.000 | 0.000 | |||
| GBM | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||
| BPIC12 | bpi12.ac | PROP | RF | 0.813 | 0.398 | 1.570 | 0.697 | 0.361 | 0.308 |
| XGB | 3.890 | 2.822 | 8.186 | 3.620 | 2.158 | 1.903 | |||
| GBM | 0.575 | 0.399 | 1.149 | 0.505 | −0.180 | 0.511 | |||
| bpi12.cc | PROP | RF | 0.246 | 0.244 | 0.911 | 0.320 | 0.096 | 0.217 | |
| XGB | 2.176 | 1.509 | 8.233 | 3.084 | 1.041 | 2.161 | |||
| GBM | 0.351 | 0.171 | 2.551 | 0.602 | 0.162 | 0.624 | |||
| bpi12.dc | PROP | RF | 0.196 | 0.133 | 1.431 | 0.337 | 0.065 | 0.270 | |
| XGB | 0.861 | 0.478 | 6.651 | 1.499 | 0.192 | 0.947 | |||
| GBM | 0.351 | 0.171 | 2.551 | 0.602 | 0.162 | 0.624 | |||
| BPIC13 | bpi13.2 | PROP | RF | 4.077 | 2.726 | 3.315 | 0.209 | 2.341 | 0.922 |
| XGB | 3.465 | 3.379 | 0.722 | 0.177 | 3.804 | 0.752 | |||
| GBM | 3.915 | 2.227 | 2.525 | 0.274 | 1.330 | 1.144 | |||
| bpi13.3 | PROP | RF | 5.452 | 3.014 | 6.289 | 0.691 | 5.522 | 1.365 | |
| XGB | 3.874 | 0.586 | 4.663 | 0.199 | 1.754 | 0.487 | |||
| GBM | 0.287 | 2.366 | 1.551 | 0.016 | 1.074 | 0.232 | |||
| bpi13.4 | PROP | RF | 6.653 | 4.868 | 7.473 | 0.040 | 5.144 | 0.968 | |
| XGB | 6.157 | 4.549 | 7.712 | 0.024 | 6.809 | 0.746 | |||
| GBM | 0.475 | −0.326 | −0.885 | 0.008 | 3.454 | 0.221 | |||
| bpi13.5 | PROP | RF | 4.707 | 2.702 | 3.450 | −0.105 | 1.555 | 0.679 | |
| XGB | 3.168 | 3.513 | 4.121 | −0.065 | 1.379 | 0.248 | |||
| GBM | −0.324 | 1.980 | −1.052 | 0.016 | 2.424 | 0.226 | |||
| bpi13wup.2 | PROP | RF | −0.494 | 2.428 | 1.012 | −0.185 | −4.976 | 0.517 | |
| XGB | 6.165 | 6.141 | 8.639 | 0.089 | 3.712 | 0.844 | |||
| GBM | −1.506 | 1.368 | −0.431 | −0.024 | −2.088 | 0.094 | |||
| bpi13wup.3 | PROP | RF | 1.943 | 2.728 | 3.542 | −0.201 | −1.004 | 0.653 | |
| XGB | 6.612 | 5.765 | 8.989 | 0.024 | 5.328 | 0.834 | |||
| GBM | 0.287 | 2.366 | 1.551 | 0.016 | 1.074 | 0.232 | |||
| bpi13wup.4 | PROP | RF | 6.653 | 4.868 | 7.473 | 0.040 | 5.144 | 0.968 | |
| XGB | 6.157 | 4.549 | 7.712 | 0.024 | 6.809 | 0.746 | |||
| GBM | 0.475 | −0.326 | −0.885 | 0.008 | 3.454 | 0.221 | |||
| bpi13wup.5 | PROP | RF | 4.707 | 2.702 | 3.450 | −0.105 | 1.555 | 0.679 | |
| XGB | 3.168 | 3.513 | 4.121 | −0.065 | 1.379 | 0.248 | |||
| GBM | −0.324 | 1.980 | −1.052 | 0.016 | 2.424 | 0.226 | |||
| bpi13pp.2 | PROP | RF | 4.136 | 1.087 | 1.315 | 0.075 | 3.654 | 0.498 | |
| XGB | 6.713 | 5.204 | 3.569 | 0.108 | 6.804 | 0.249 | |||
| GBM | 0.459 | 1.010 | −2.629 | −0.058 | −1.459 | 0.043 | |||
| bpi13pp.3 | PROP | RF | 1.850 | 1.544 | 1.012 | −0.033 | 1.740 | 0.469 | |
| XGB | 4.380 | 2.657 | 3.299 | 0.025 | 2.689 | 0.128 | |||
| GBM | 1.447 | 0.650 | 0.067 | −0.058 | 0.697 | 0.320 | |||
| BPIC15 | bpi15.1 | PROP | RF | 0.073 | −0.005 | 0.271 | 0.107 | 0.003 | 0.007 |
| XGB | 0.039 | 0.009 | 0.119 | 0.053 | 0.007 | 0.015 | |||
| GBM | 0.050 | 0.058 | 0.179 | 0.071 | 0.004 | 0.011 | |||
| bpi15.2 | PROP | RF | 0.080 | 0.061 | 0.351 | 0.123 | −0.001 | −0.003 | |
| XGB | −0.024 | −0.006 | −0.102 | −0.037 | 0.000 | −0.001 | |||
| GBM | 0.064 | 0.010 | 0.280 | 0.099 | 0.001 | 0.002 | |||
| bpi15.3 | PROP | RF | 0.070 | 0.041 | 0.285 | 0.105 | 0.002 | 0.006 | |
| XGB | −0.011 | −0.039 | −0.051 | −0.017 | −0.001 | −0.002 | |||
| GBM | 0.069 | 0.071 | 0.286 | 0.105 | 0.001 | 0.004 | |||
| bpi15.4 | PROP | RF | −0.001 | −0.031 | 0.009 | 0.000 | −0.021 | −0.026 | |
| XGB | 0.052 | 0.083 | 0.281 | 0.085 | −0.020 | −0.024 | |||
| GBM | 0.025 | 0.041 | 0.152 | 0.042 | −0.017 | −0.014 | |||
| bpi15.5 | PROP | RF | 0.275 | 0.179 | 0.762 | 0.350 | 0.005 | 0.009 | |
| XGB | 0.051 | 0.014 | 0.139 | 0.064 | 0.001 | 0.001 | |||
| GBM | 0.029 | 0.032 | 0.080 | 0.037 | 0.003 | 0.004 | |||
| BPIC17 | bpi17a | PROP | RF | 2.808 | 1.631 | 6.608 | 3.097 | 0.540 | 0.679 |
| XGB | 0.967 | 0.989 | 2.244 | 1.069 | 0.206 | 0.262 | |||
| GBM | 0.923 | 0.481 | 2.176 | 1.034 | 0.159 | 0.192 | |||
| bpi17c | PROP | RF | 2.769 | 1.486 | 6.327 | 2.986 | 0.536 | 0.639 | |
| XGB | 0.928 | 0.846 | 1.975 | 0.960 | 0.201 | 0.223 | |||
| GBM | 0.884 | 0.338 | 1.906 | 0.926 | 0.155 | 0.153 | |||
| bpi17r | PROP | RF | 0.288 | 0.205 | 2.561 | 0.510 | 0.016 | 0.117 | |
| XGB | 0.227 | 0.143 | 2.011 | 0.403 | 0.015 | 0.112 | |||
| GBM | 0.158 | 0.081 | 1.404 | 0.281 | 0.015 | 0.106 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tama, B.A.; Comuzzi, M. Leveraging a Heterogeneous Ensemble Learning for Outcome-Based Predictive Monitoring Using Business Process Event Logs. Electronics 2022, 11, 2548. https://doi.org/10.3390/electronics11162548
Tama BA, Comuzzi M. Leveraging a Heterogeneous Ensemble Learning for Outcome-Based Predictive Monitoring Using Business Process Event Logs. Electronics. 2022; 11(16):2548. https://doi.org/10.3390/electronics11162548
Chicago/Turabian StyleTama, Bayu Adhi, and Marco Comuzzi. 2022. "Leveraging a Heterogeneous Ensemble Learning for Outcome-Based Predictive Monitoring Using Business Process Event Logs" Electronics 11, no. 16: 2548. https://doi.org/10.3390/electronics11162548
APA StyleTama, B. A., & Comuzzi, M. (2022). Leveraging a Heterogeneous Ensemble Learning for Outcome-Based Predictive Monitoring Using Business Process Event Logs. Electronics, 11(16), 2548. https://doi.org/10.3390/electronics11162548