
Wi-CAL: A Cross-Scene Human Motion Recognition Method Based on Domain Adaptation in a Wi-Fi Environment


Abstract
:1. Introduction
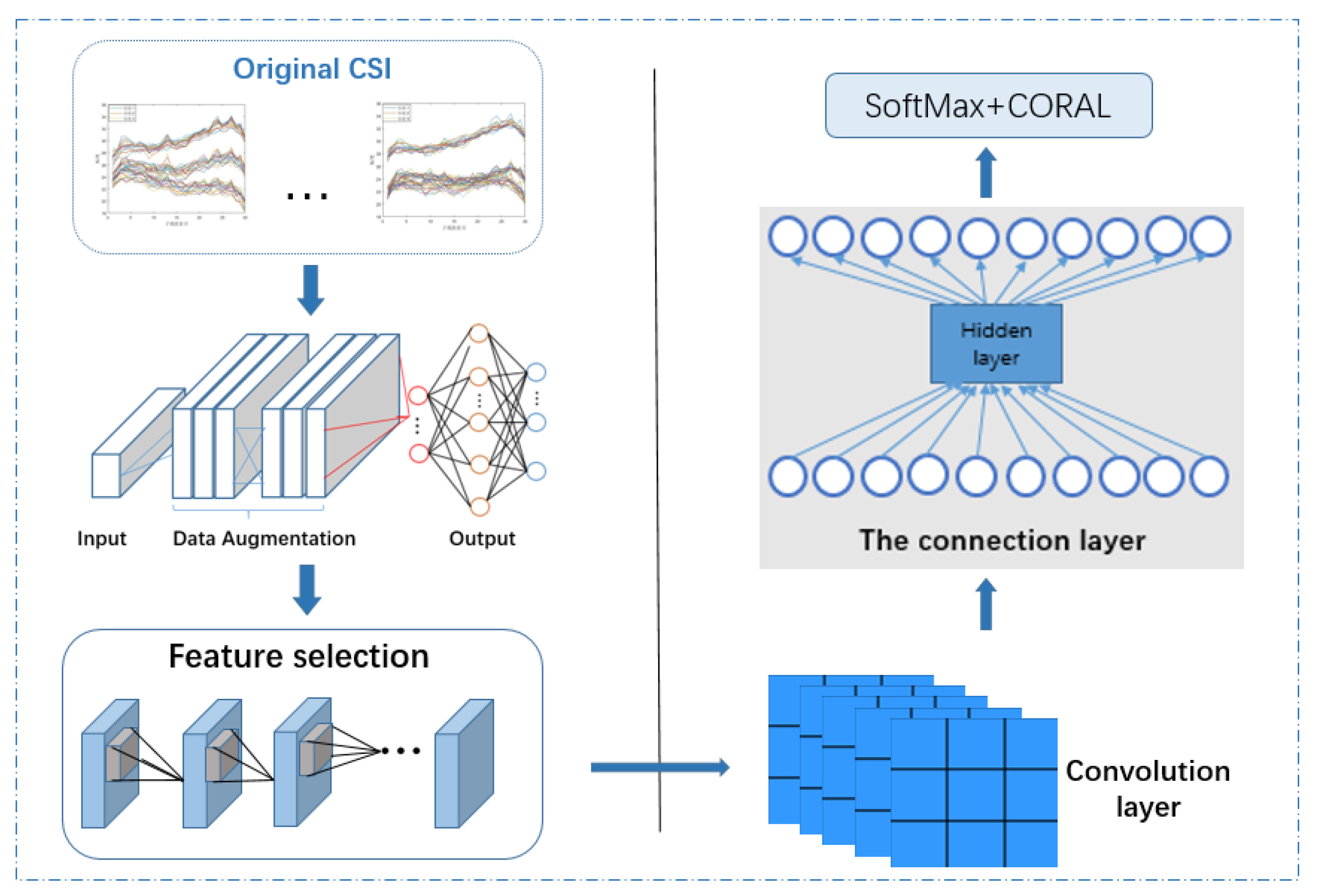
2. Method
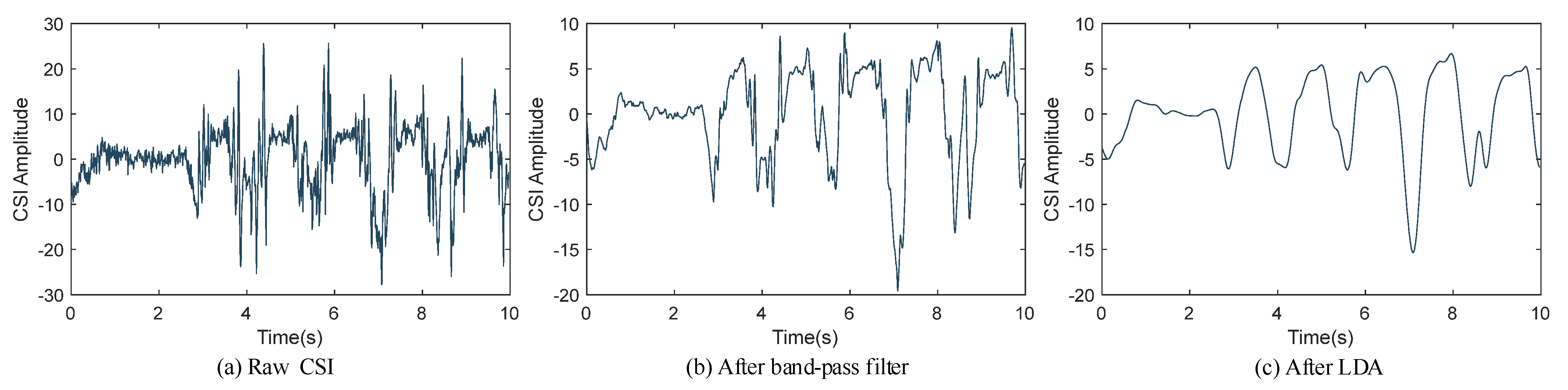
2.1. Data Calibration
2.2. Data Enhancement
- We calculated the DTW between each sequence and the temporary average sequence to be refined to find the correlation between the average series’ coordinates and the sequence set coordinates;
- In the first step, we updated each coordinate of the average sequence to the center of gravity of its associated coordinates.
| Algorithm 1 DBA |
| Require: Initial average sequence Require: The first sequence to average Require: The nth sequence to be averaged Let T be the length of sequences Let assocT ab be a table of size containing in each cell a set of coordinates associated with each coordinate of D Let m[T, T] be a temporary DTW (cost,path) matrix assocT ab ← [0, …, 0] for seq in R do m ← i ← j ← while i ≥ 1 and j ≥ 1 do assocT ab[i] ← assocT ab[i] ∪ seq j (i, j) ← second(m[i, j]) end while end for for i = 1 to T do = barycenter(assocT ab[i]) { see Equation (3) } end for return |
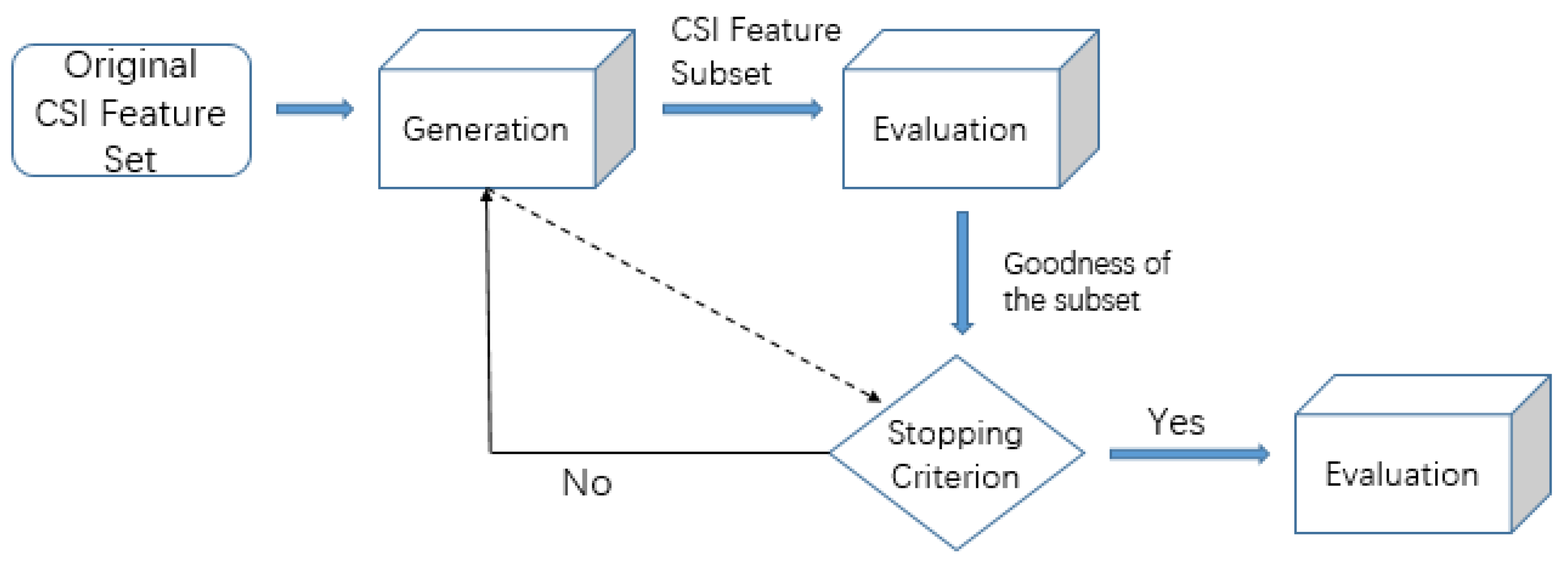
2.3. Feature Extraction and Feature Selection
| Algorithm 2 ReliefF |
| Require: Weight of each feature T. Let all T be 0; for i = 1 to m do Randomly select a sample R; Find the nearest neighbor sample H of the same category as R; Find the nearest neighbor sample m of different categories of R; for A = 1 to N do W(A) = W(A) − diff(A,R,H)/m + diff(A,R,M)/m; for A = 1 to N do If W(A) Add the Ath feature to T end |
2.4. Activity Recognition
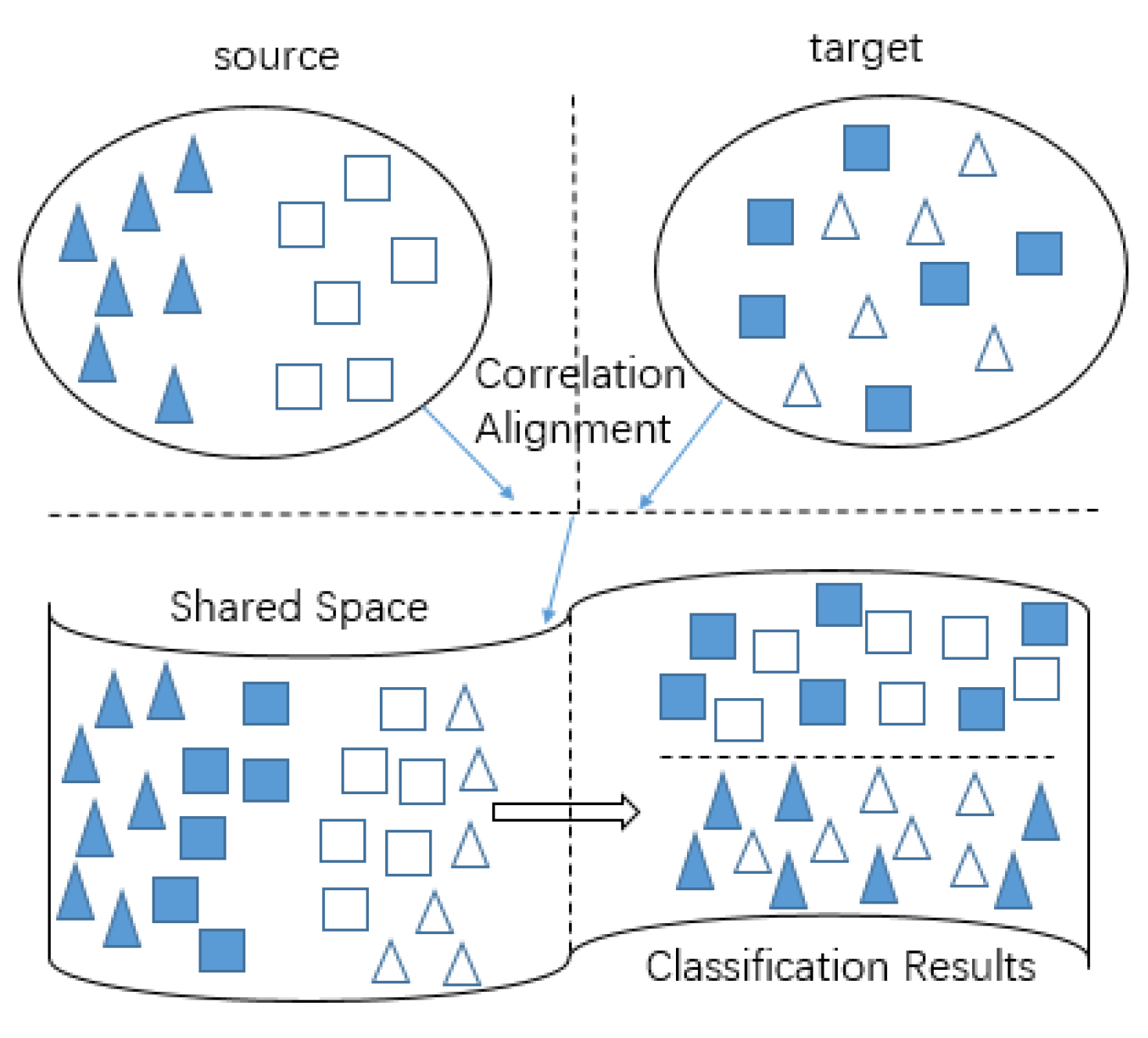
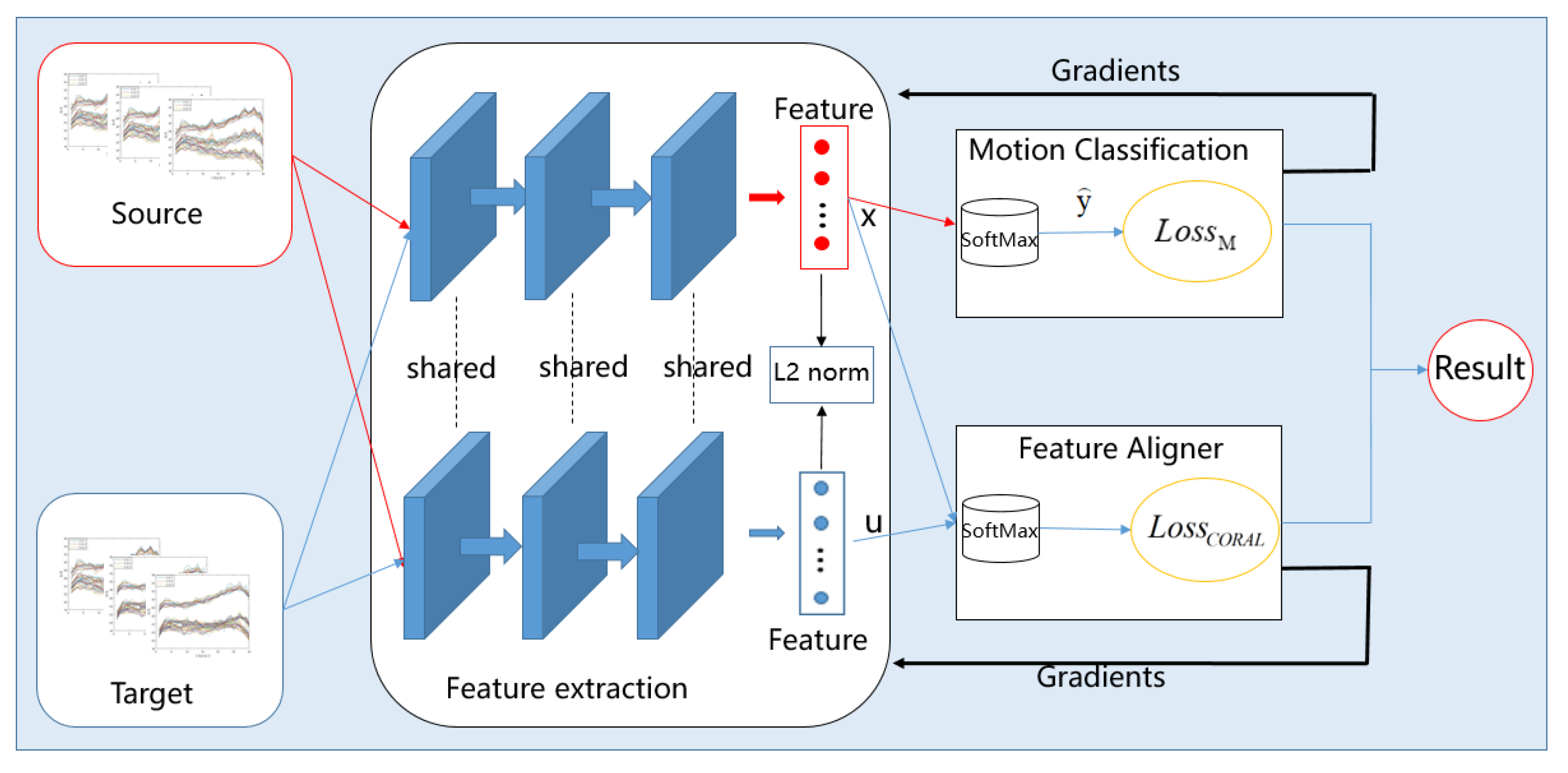
2.4.1. Domain Adaptation Method Based on Divergence
2.4.2. Action Recognition Method Based on Domain Adaptation
3. Discussion
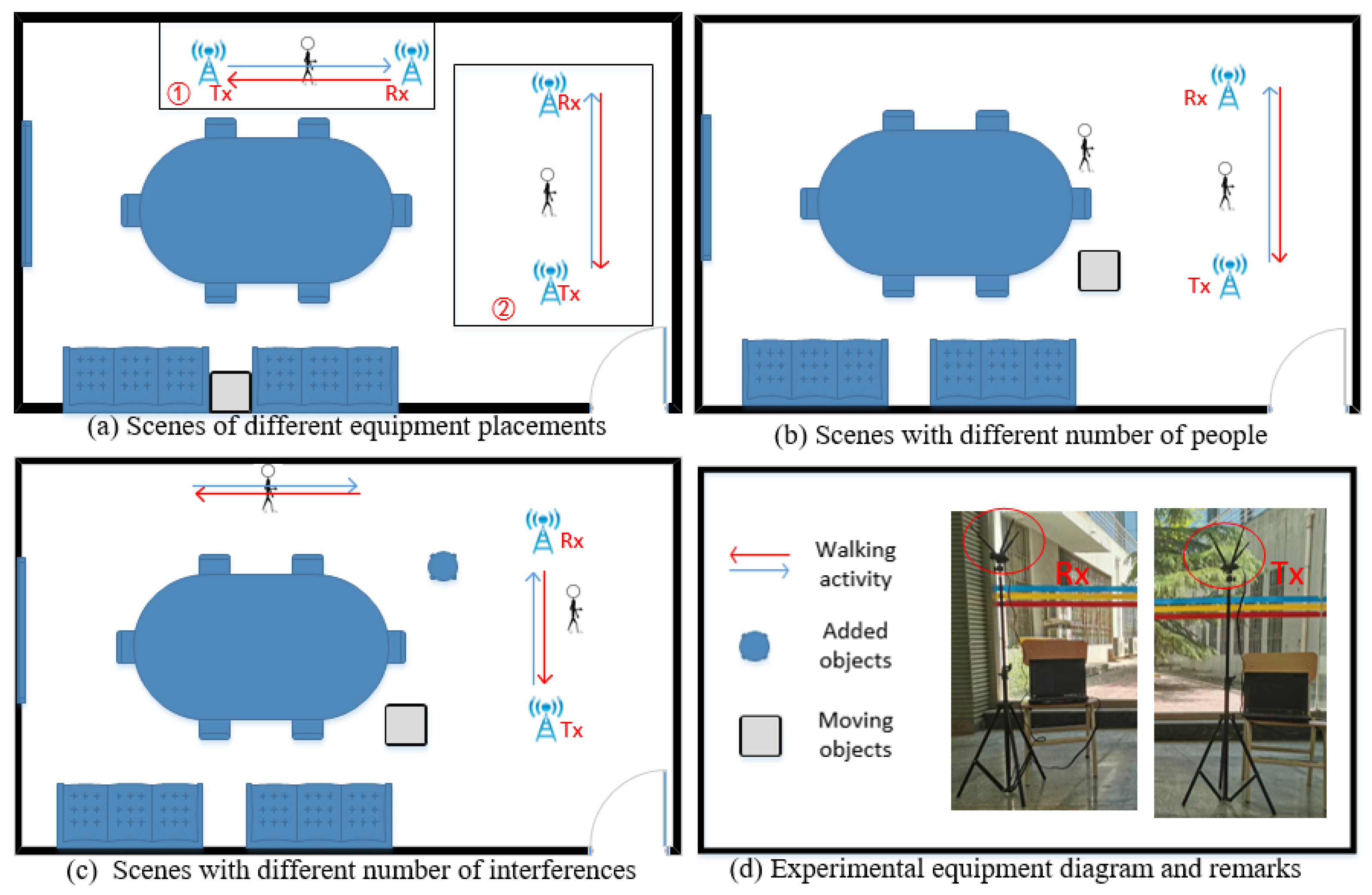
3.1. Experiment Setting
3.2. Experimental Factor Analysis
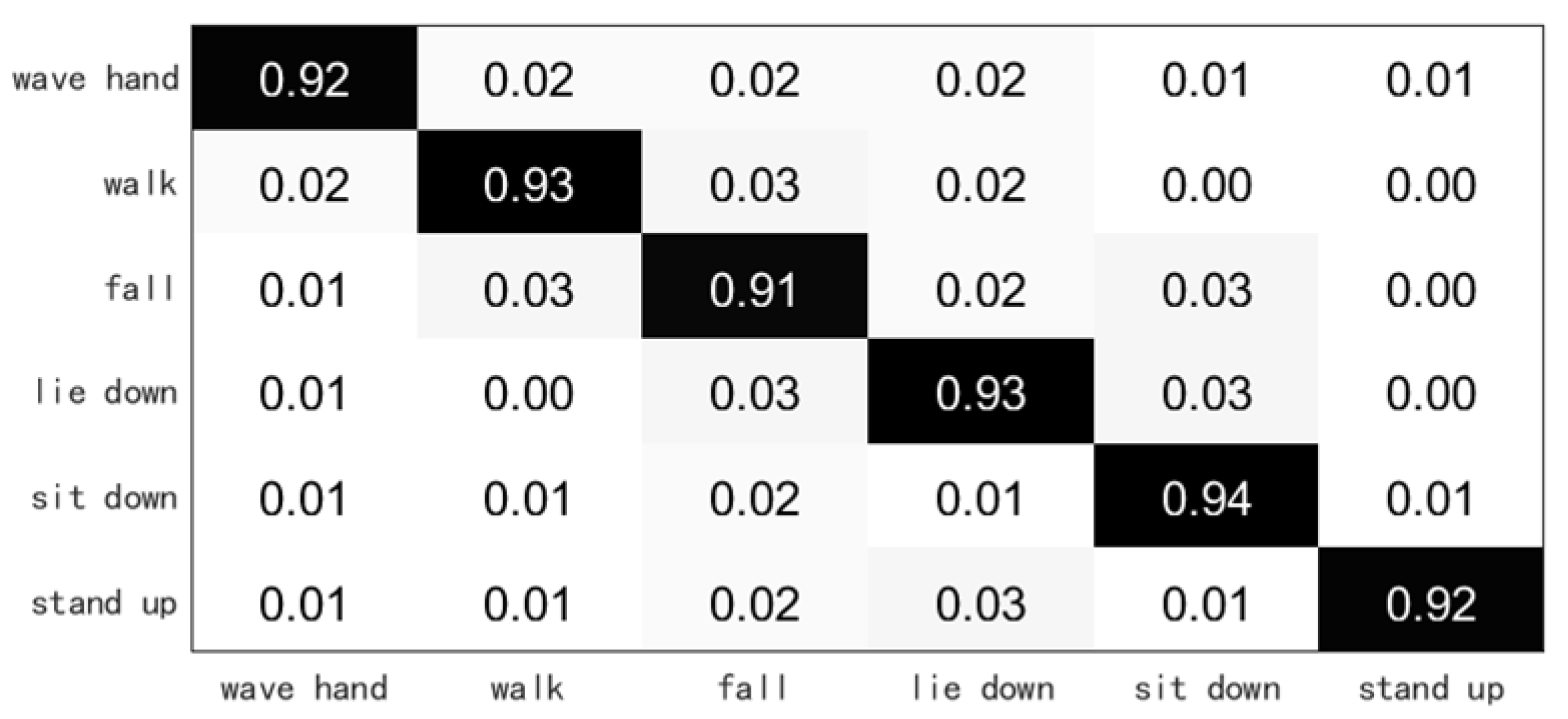
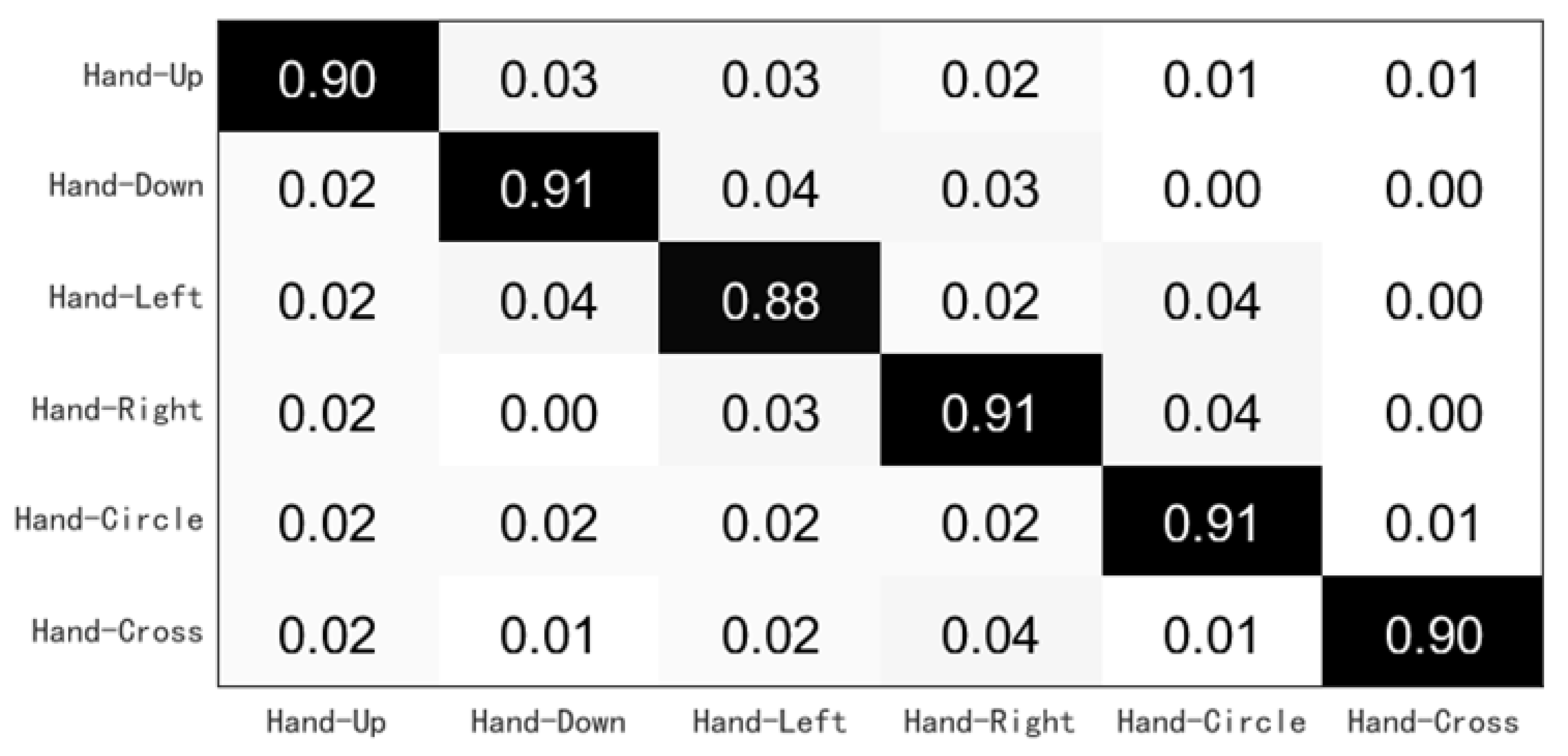
3.2.1. Overall Accuracy
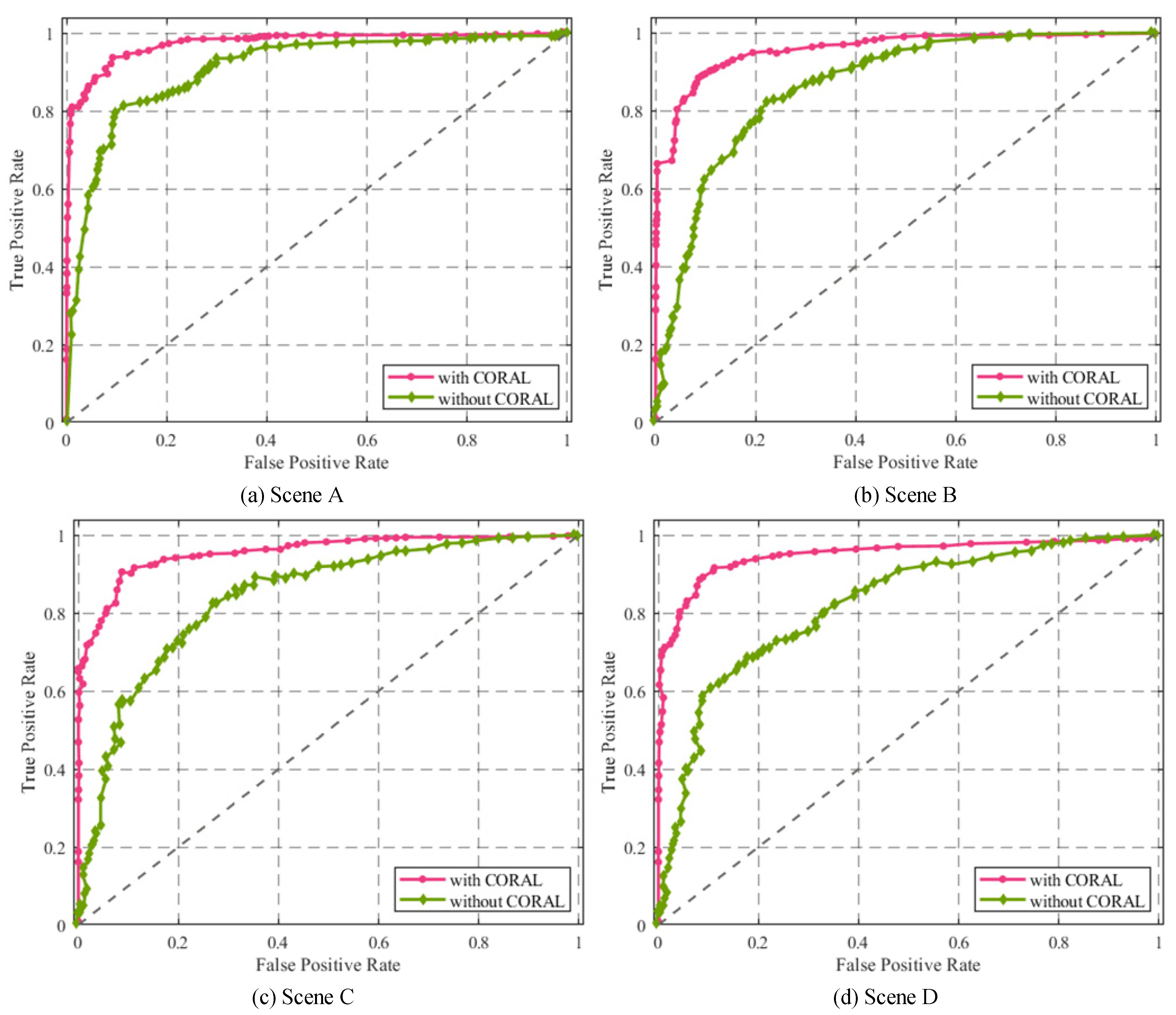
3.2.2. Effect of CORrelation ALignment
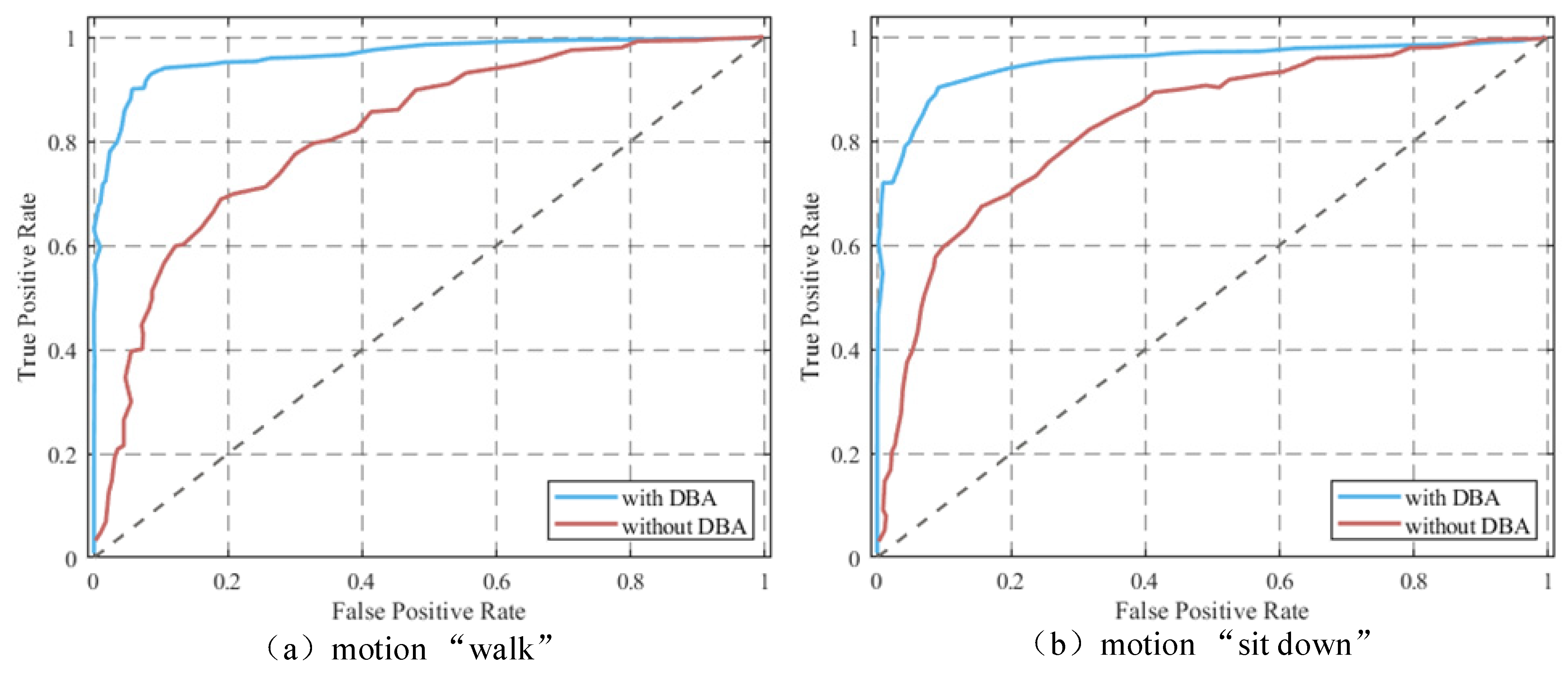
3.2.3. Effect of Data Augmentation
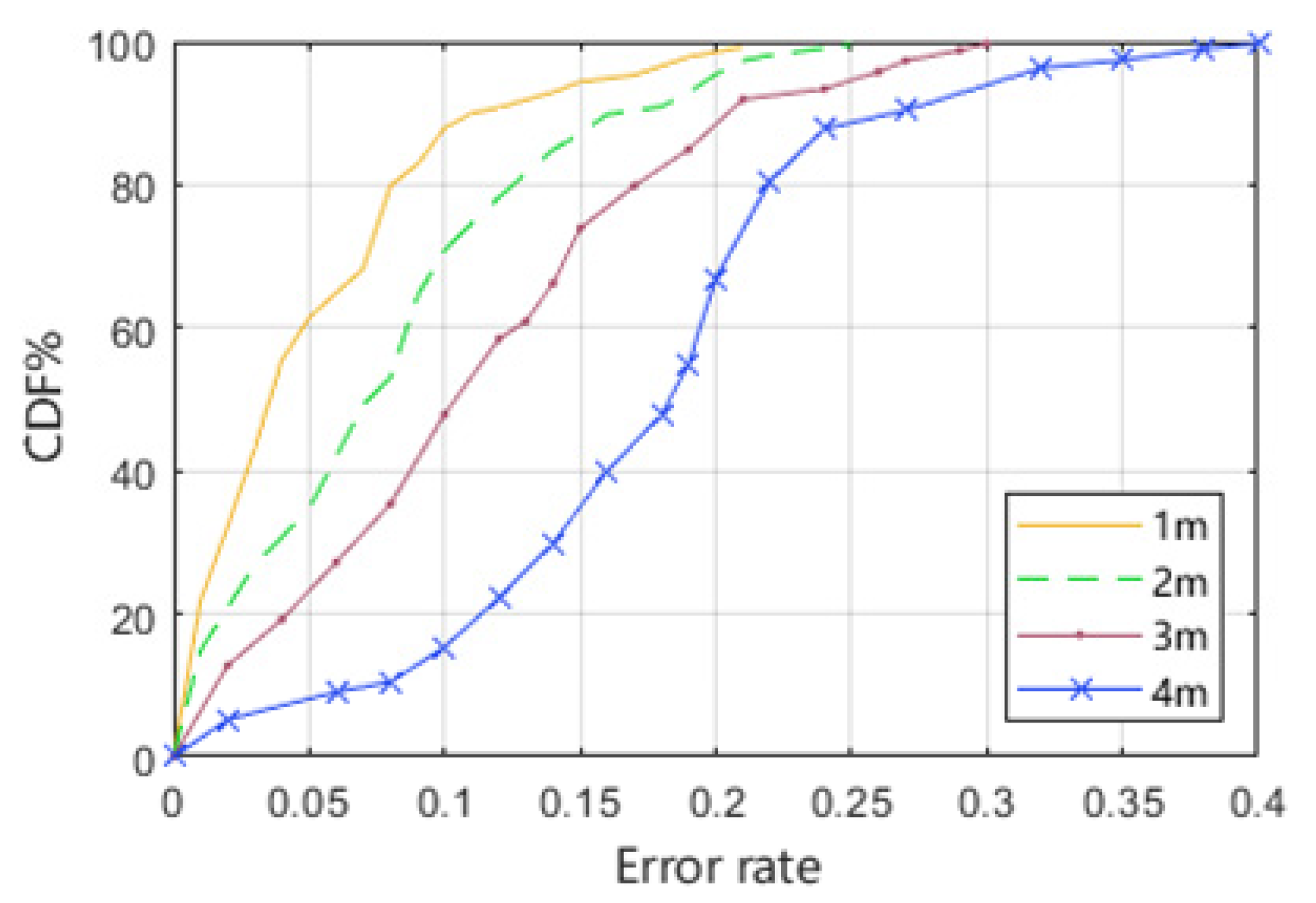
3.2.4. Effect of Distance between Transmitter and Receiver
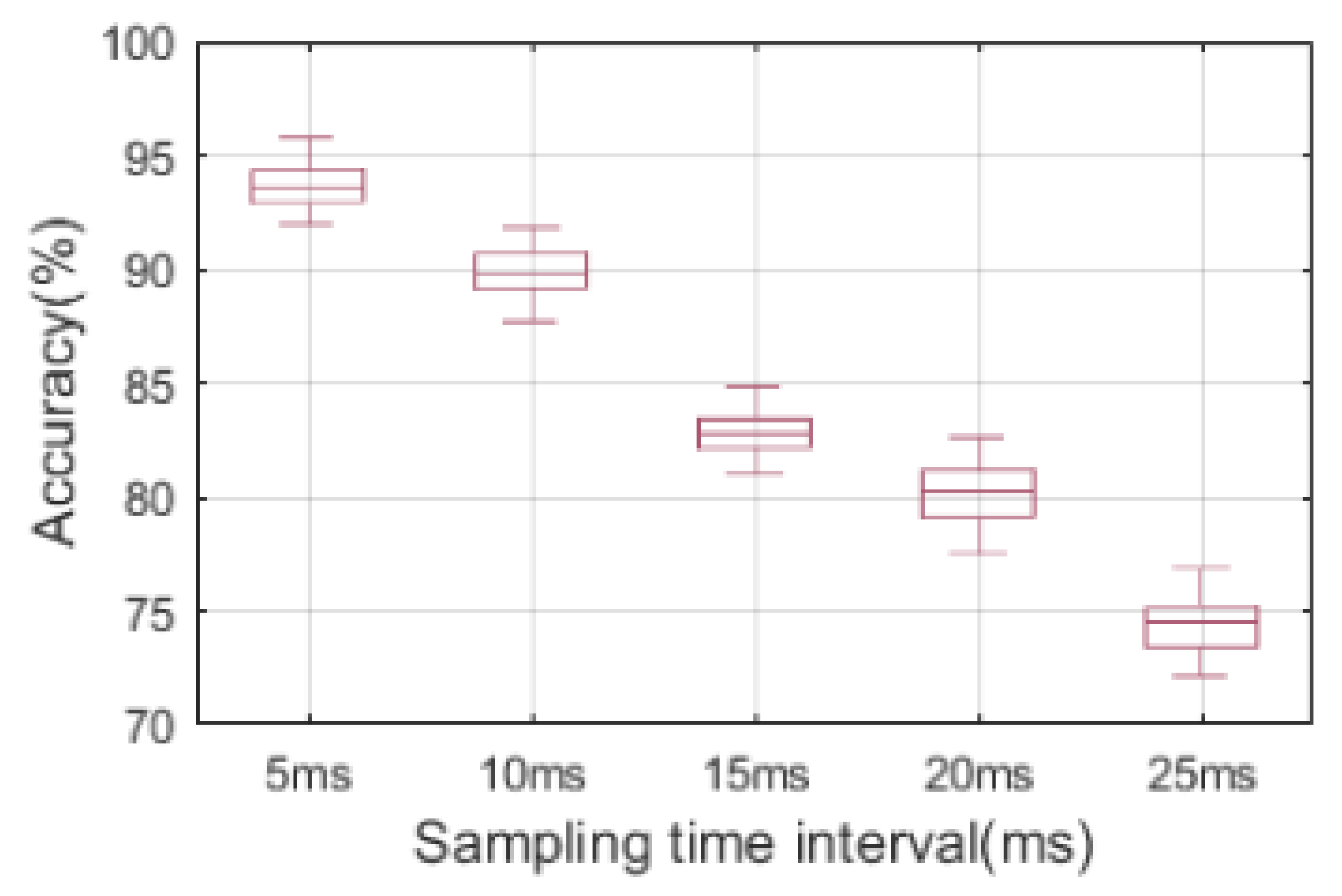
3.2.5. Effect of Sampling Rates
3.2.6. Validation of Different Data Sets
3.2.7. Comparison of Different Classification Algorithms
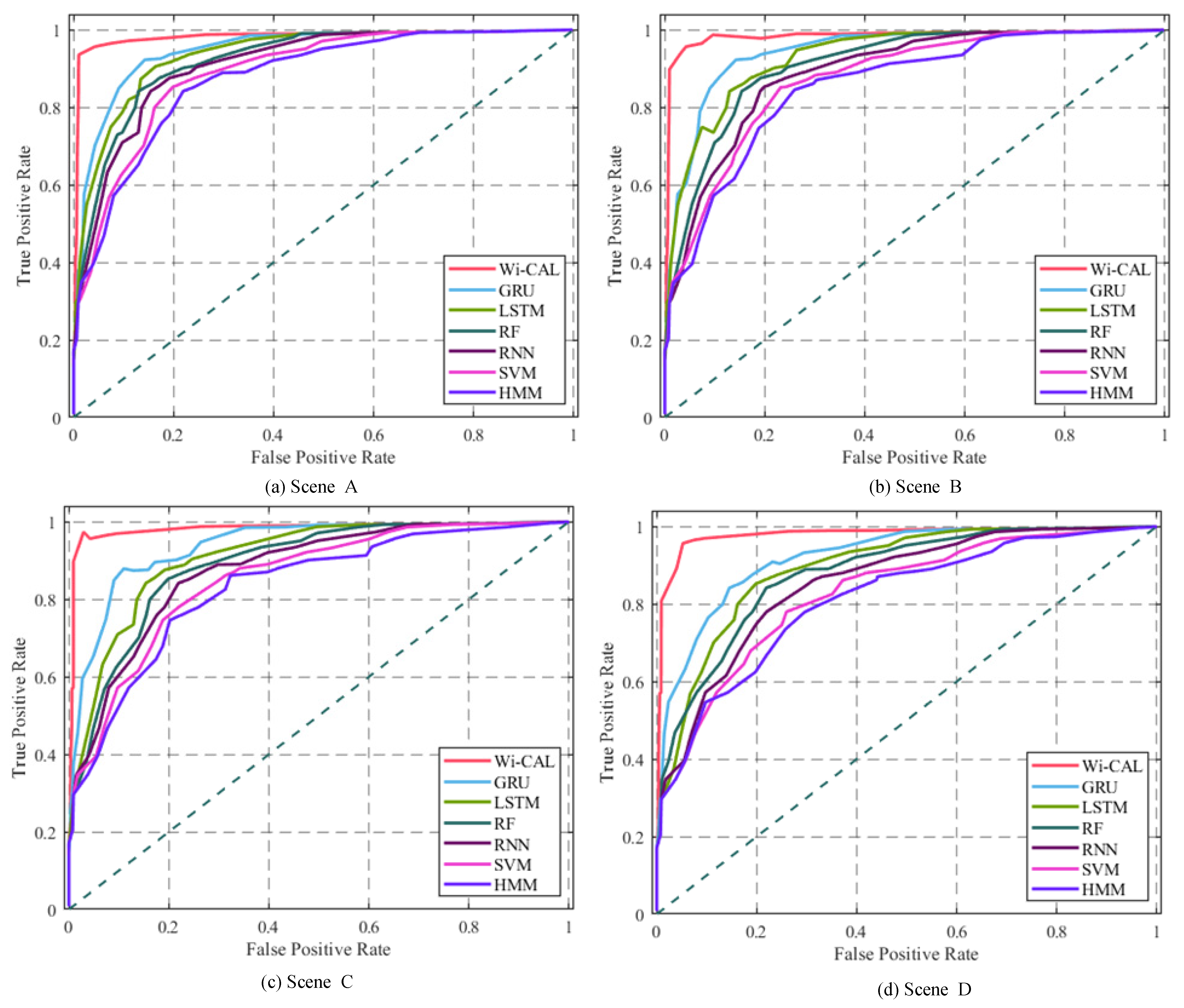
3.2.8. Comparison of Different Motion Recognition Methods
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hsu, Y.; Yang, S.; Chang, H.; Lai, H. Human daily and sport activity recognition using a wearable inertial sensor network. IEEE Access 2018, 6, 31715–31728. [Google Scholar] [CrossRef]
- Wu, D.; Zhang, D. Device-Free Wi-Fi Human Sensing: From Pattern-Based to Model-Based Approaches. IEEE Commun. Mag. 2017, 55, 91–97. [Google Scholar] [CrossRef]
- Zhou, M.; Zhang, Z.; Wang, Y.; Nie, W.; Tian, Z. CSI localization error bound estimation method under indoor Wi-Fi asynchronous effect. Sci. Sin. Inf. 2021, 51, 851–866. [Google Scholar] [CrossRef]
- Zhang, D.; Wang, H.; Wang, Y.; Ma, J. Anti-Fall: A Non-intrusive and Real-time Fall Detector Leveraging CSI from Commodity Wi-Fi Devices; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Savoie, P.; Cameron, J.A.; Kaye, M.E.; Scheme, E.J. Automation of the Timed-Up-and-Go Test Using a Conventional Video Camera. IEEE J. Biomed. Health Inform. 2020, 24, 1196–1205. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Ma, J.; Li, X.; Zhong, A. Hierarchical Multi-Classification for Sensor-based Badminton Activity Recognition. In Proceedings of the 2020 15th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 6–9 December 2020. [Google Scholar]
- Li, J.; Yin, K.; Tang, C. SlideAugment: A Simple Data Processing Method to Enhance Human Activity Recognition Accuracy Based on Wi-Fi. Sensors 2021, 21, 2181. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.; Zhang, W.; Peng, D.; Liu, Y.; Liao, X.; Jiang, H. Adversarial Wi-Fi Sensing for Privacy Preservation of Human Behaviors. IEEE Commun. Lett. 2020, 24, 259–263. [Google Scholar] [CrossRef]
- Zhou, Q.; Wu, C.; Xing, J.; Li, J.; Yang, Z.; Yang, Q. Wi-Dog: Monitoring School Violence with Commodity Wi-Fi Devices; Springer: Cham, Switzerland, 2017; Volume 10251, pp. 47–59. [Google Scholar]
- Zhang, D.; Hu, Y.; Chen, Y.; Zeng, B. BreathTrack: Tracking Indoor Human Breath Status via Commodity Wi-Fi. IEEE Internet Things J. 2019, 6, 3899–3911. [Google Scholar] [CrossRef]
- Kotaru, M.; Joshi, K.; Bharadia, D.; Katti, S. Spotfi: Decimeter level localization using Wi-Fi. In Proceedings of the 2015 ACM Conference on Special Interest Group on Data Communication, London, UK, 17–21 August 2015; pp. 269–282. [Google Scholar]
- Korany, B.; Cai, H.; Mostofi, Y. Multiple People Identification Through Walls Using Off-The-Shelf Wi-Fi. IEEE Internet Things J. 2020, 8, 6963–6974. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, D.; Wang, Y.; Ma, J.; Wang, Y.; Li, S. RT-Fall: A real-time and contactless fall detection system with commodity Wi-Fi devices. IEEE Trans. Mob. Comput. 2017, 16, 511–526. [Google Scholar] [CrossRef]
- Yan, H.; Zhang, Y.; Wang, Y.; Xu, K. WiAct: A passive Wi-Fi-based human activity recognition system. IEEE Sens. J. 2019, 20, 296–305. [Google Scholar] [CrossRef]
- Li, C.; Liu, M.; Cao, Z. WiHF: Gesture and User Recognition with Wi-Fi. IEEE Trans. Mob. Comput. 2020, 99, 1. [Google Scholar]
- Pokkunuru, A.; Jakkala, K.; Bhuyan, A.; Wang, P.; Sun, Z. NeuralWave: Gait-based user identification through commodity Wi-Fi and deep learning. In Proceedings of the IECON 2018–44th Annual Conference of the IEEE Industrial Electronics Society, Piscataway, NJ, USA, 20–23 October 2018; pp. 758–765. [Google Scholar]
- Wang, F.; Duan, P.; Cao, Y.; Kong, J.; Li, H. Human Activity Recognition Using MSHNet Based on Wi-Fi CSI; Springer: Cham, Switzerland, 2020; Volume 338, pp. 47–63. [Google Scholar]
- Shang, S.; Luo, Q.; Zhao, J.; Xue, R.; Sun, W.; Bao, N. LSTM-CNN network for human activity recognition using Wi-Fi CSI data. J. Phys. Conf. Ser. 2021, 1883, 012139. [Google Scholar] [CrossRef]
- Li, H.; Chen, X.; Du, H.; He, X.; Qian, J.; Wan, P.; Yang, P. Wi-Motion: A Robust Human Activity Recognition Using Wi-Fi Signals. IEEE Access 2019, 7, 153287–153299. [Google Scholar] [CrossRef]
- Sun, B.; Saenko, K. Deep CORAL: Correlation Alignment for Deep Domain Adaptation; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; Volume 9915, pp. 443–450. [Google Scholar]
- Zhang, T.; Song, T.; Chen, D.; Zhuang, J. WiGrus: A Wifi-Based Gesture Recognition System Using Software-Defined Radio. IEEE Access 2019, 7, 131102–131113. [Google Scholar] [CrossRef]
- Pearson, R.; Neuvo, Y.; Astola, J.; Gabbouj, M. The class of generalized hampel filters. In Proceedings of the 23rd European Signal Processing Conference (EUSIPCO), Nice, France, 31 August–4 September 2015; pp. 2501–2505. [Google Scholar]
- Fawaz, H.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P. Data augmentation using synthetic data for time series classification with deep residual networks. arXiv 2018, arXiv:1808.02455. [Google Scholar]
- Zhang, J.; Wei, B.; Wu, F.; Dong, L.; Hu, W.; Kanhere, S.; Luo, C.; Yu, S.; Cheng, J. Gate-ID: WiFi-Based Human Identification Irrespective of Walking Directions in Smart Home. IEEE Internet Things J. 2021, 8, 7610–7624. [Google Scholar] [CrossRef]
- Wang, F.; Feng, J.; Zhao, Y.; Zhang, X.; Han, J. Joint Activity Recognition and Indoor Localization with Wi-Fi Fingerprints. IEEE Access 2019, 7, 80058–80068. [Google Scholar] [CrossRef]
- Chen, J.; Liu, K.; Chen, M.; Ma, J.; Zeng, X. Recognition method of ship’s officer duty behavior based on channel state information. J. Dalian Marit. Univ. 2020, 46, 68–75. [Google Scholar]
- Dang, X.; Ru, C.; Hao, Z. An indoor positioning method based on CSI and SVM regression. Comput. Eng. Sci. 2021, 43, 853–861. [Google Scholar]
- Dang, X.; Cao, Y.; Hao, Z.; Liu, Y. WiGId: Indoor Group Identification with CSI-Based Random Forest. Sensors 2020, 20, 4607. [Google Scholar] [CrossRef]
- Shalaby, E.; ElShennawy, N.; Sarhan, A. Utilizing deep learning models in CSI-based human activity recognition. Neural Comput. Appl. 2022, 43, 5993–6010. [Google Scholar] [CrossRef] [PubMed]
- Moshiri, P.F.; Shahbazian, R.; Nabati, M.; Ghorashi, S.A. A CSI-Based Human Activity Recognition Using Deep Learning. Sensors 2021, 21, 7225. [Google Scholar] [CrossRef] [PubMed]
- Ding, J.Y.; Wang, Y. WiFi CSI-Based Human Activity Recognition Using Deep Recurrent Neural Network. IEEE Access 2019, 7, 174257–174269. [Google Scholar] [CrossRef]
- Dang, X.; Liu, Y.; Hao, Z.; Tang, X.; Shao, C. Air Gesture Recognition Using WLAN Physical Layer Information. Wirel. Commun. Mob. Comput. 2020, 2020, 8546237. [Google Scholar] [CrossRef]
- Wang, D.; Yang, J.; Cui, W.; Xie, L.; Sun, S. Multimodal CSI-based Human Activity Recognition using GANs. IEEE Internet Things J. 2021, 8, 17345–17355. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, L.; Jiang, C.; Cao, Z.; Cui, W. WiFi CSI Based Passive Human Activity Recognition Using Attention Based BLSTM. IEEE Trans. Mob. Comput. 2019, 18, 2714. [Google Scholar]
- Sheng, B.; Fang, Y.; Xiao, F.; Sun, L. An Accurate Device-Free Action Recognition System Using Two-stream Network. IEEE Trans. Veh. Technol. 2020, 69, 7930–7939. [Google Scholar] [CrossRef]
- Hao, Z.; Duan, Y.; Dang, X.; Liu, Y.; Zhang, D. Wi-SL: Contactless Fine-Grained Gesture Recognition Uses Channel State Information. Sensors 2020, 20, 4025. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sence | Person 1 | Person 2 | Person 3 | Person 4 | Person 5 | Person 6 | |
|---|---|---|---|---|---|---|---|
| Lobby | A | 80 | 80 | 80 | 80 | 80 | 80 |
| B | 60 | 60 | 60 | 60 | 60 | 60 | |
| C | 60 | 60 | 60 | 60 | 60 | 60 | |
| D | 60 | 60 | 60 | 60 | 60 | 60 | |
| Meeting Room | A | 80 | 80 | 80 | 80 | 80 | 80 |
| B | 60 | 60 | 60 | 60 | 60 | 60 | |
| C | 60 | 60 | 60 | 60 | 60 | 60 | |
| D | 60 | 60 | 60 | 60 | 60 | 60 | |
| Project | Activity | Algorithm | Feature | Average Accuracy | Advantage | Disadvantage |
|---|---|---|---|---|---|---|
| Wi-CAL | wave hand, walk, fall, lie down, sit down, and stand up | DBA, ReliefF, and CORAL | CSI Amplitude | 93.57% | The migration capability of models in different scenarios is realized. | The migration capability of the model in more environments is not discussed. |
| WiNum [32] | Gesture number “1–9” | DTW and SVM | CSI Amplitude and phase | 91.06% | It improves the utilization of CSI and effectively recognizes handwritten digits. | There are too few application scenarios, and the actual use is limited. |
| MCBAR [33] | running, walking, falling down, boxing, circling arms, and cleaning floor | Generative Adversarial Networks | CSI Amplitude | 90.79% | It overcomes the performance degradation of different environment models. | Unlabeled data cannot be effectively used to solve the degradation of model performance. |
| ABLSTM [34] | Lie down, Fall, Walk, Run, Sit down, and Stand up | Bidirectional long short term memory neural network | CSI Amplitude and phase | 90.24% | It can focus on more representative features, making feature learning richer information. | Data labeling is difficult, and unmarked data cannot be used efficiently. |
| Sheng et al. [35] | bend, box, clap, pull, throw, and wave | Deep CNN | CSI Amplitude and phase | 88.85% | It can learn higher-level features and make full use of CSI information. | The system does not discuss the recognition performance under various scenarios and cannot judge the practicability of the system. |
| Wi-SL [36] | 12 sign language actions | K-means, Bagging, and SVM | CSI Amplitude and phase | 86.90% | It realizes efficient recognition of fine-grained sign language gestures. | There is no discussion of two-handed sign language gestures, and the recognition performance of the model is different in different scenarios. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hao, Z.; Niu, J.; Dang, X.; Feng, D. Wi-CAL: A Cross-Scene Human Motion Recognition Method Based on Domain Adaptation in a Wi-Fi Environment. Electronics 2022, 11, 2607. https://doi.org/10.3390/electronics11162607
Hao Z, Niu J, Dang X, Feng D. Wi-CAL: A Cross-Scene Human Motion Recognition Method Based on Domain Adaptation in a Wi-Fi Environment. Electronics. 2022; 11(16):2607. https://doi.org/10.3390/electronics11162607
Chicago/Turabian StyleHao, Zhanjun, Juan Niu, Xiaochao Dang, and Danyang Feng. 2022. "Wi-CAL: A Cross-Scene Human Motion Recognition Method Based on Domain Adaptation in a Wi-Fi Environment" Electronics 11, no. 16: 2607. https://doi.org/10.3390/electronics11162607
APA StyleHao, Z., Niu, J., Dang, X., & Feng, D. (2022). Wi-CAL: A Cross-Scene Human Motion Recognition Method Based on Domain Adaptation in a Wi-Fi Environment. Electronics, 11(16), 2607. https://doi.org/10.3390/electronics11162607