Abstract
Smoke is translucent and irregular, resulting in a very complex mix between background and smoke. Thin or small smoke is visually inconspicuous, and its boundary is often blurred. Therefore, it is a very difficult task to completely segment smoke from images. To solve the above issues, a multi-scale semantic segmentation for fire smoke based on global information and U-Net is proposed. This algorithm uses multi-scale residual group attention (MRGA) combined with U-Net to extract multi-scale smoke features, and enhance the perception of small-scale smoke. The encoder Transformer was used to extract global information, and improve accuracy for thin smoke at the edge of images. Finally, the proposed algorithm was tested on smoke dataset, and achieves 91.83% mIoU. Compared with existing segmentation algorithms, mIoU is improved by 2.87%, and mPA is improved by 3.42%. Thus, it is a segmentation algorithm for fire smoke with higher accuracy.
1. Introduction
Occurrence of fire not only threatens the safety of human life and property, but also damages the natural environment. According to the World Fire Statistics Center (WFSC), in 2019, there were 3.1 million fires in 34 countries around the world. About 19,000 civilians died in fires, and 68,000 were injured in fires. Moreover, as of 15 August 2020, California fires have destroyed 1.2 million acres of forest and burned a total of 1.4 million acres of fields for the year. Therefore, the segmentation of fire smoke images plays an important role in providing preconditions for fire smoke detection and early warning.
Semantic segmentation is one of the main tasks in the field of computer vision applications. It classifies each pixel in an image, so that the image can be segmented into regions with different semantics. In 2015, Long et al. [1] proposed the segmentation network FCN, which brought semantic segmentation into a new era. The network achieved end-to-end semantic segmentation using transposed convolutions to replace fully connected layers in the network. In the same year, Badrinarayanan et al. [2] proposed SegNet, which uses index information to perform up-sampling in a decoder to save computing power overhead, but this leads to the loss of more feature information. By using spatial pyramid pooling, PSPNet [3] adds local and global information to the feature map, which improves the semantic understanding ability of the network. In order to enhance feature information, Fu et al. [4] proposed DANet, in the form of a dual-path attention channel, to capture global feature dependencies simply and effectively. With the development of semantic segmentation, the semantic relationship between different images is gradually excavated by researchers. For example, Zhou et al. [5] used a graph model to build the semantic dependencies between a set of images, and the graph dropout was used to avoid ignoring isolated objects. Wang et al. [6] proposed a pixel-wise contrastive learning, which used the cross-image pixel-to-pixel relation to learn a well-structured pixel semantic embedding space to replace the traditional image-wise-based training paradigm. Recently, Zhou et al. [7] proposed a novel non-parametric segmentation method based on non-learnable prototypes, and achieved excellent performance.
There are two main types of algorithms for smoke segmentation: one is based on traditional image processing. According to color, texture, and motion characteristics of smoke, algorithms such as thresholding, clustering, and moving object detection are used to segment smoke regions. Appana et al. [8] converted smoke images from RGB color space to HSV color space, and performed thresholding on its saturation and brightness to achieve segmentation of smoke regions. Zhao et al. [9] used fuzzy c-means algorithm (FCM) to segment fire smoke areas based on pixel color information. Reference [10] proposed a multi-scale segmentation algorithm for smoke using a wavelet module based on smoke texture, and experiments show that it is better than traditional edge segmentation algorithms. Peng et al. [11] used background difference method to segregate smoke regions from videos based on a Gaussian mixture model (GMM), which is very effective for slow-moving smoke. Wu et al. [12] found that the optical flow of blue channel can effectively reflect motion characteristics of smoke, and proposed an algorithm based on dense optical flow to segregate smoke. Such methods effectively overcome the interference of smoke-like objects, but there will be a lot of interfering objects in the segmentation result, when some non-smog moving objects exist.
Some other smoke segmentation is performed based on deep learning methods. Compared with traditional image processing algorithms, convolutional neural networks can automatically learn deep-level pixel information in smoke images, which not only reduces the complexity of feature extraction, but also has higher anti-interference capability. Salman et al. [13] used DeepLab v3+ with an encoder and decoder to segment smoke, and the accuracy is significantly improved by 3%. Yuan et al. [14] proposed a dual-classification-assisted gated recurrent network (CGRNet) for smoke segmentation. The results are significantly better than existing algorithms, and satisfactory results are achieved on thin smoke. Considering the visibility of haze in the sky, Taanya et al. [15] adopted the dark channel pre-processing method to reduce the amount of haze in images, and combined dense optical flow with mask R-cnn to improve the anti-interference capability of the segmentation algorithm. Zhu et al. [16] proposed a 3D CNN with an encoder–decoder based on the motion features of smoke, which effectively mitigated the interference of moving objects.
Algorithms for smoke segmentation based on deep learning show significant advantages, but there are still many shortcomings: on the one hand, due to the variable size of smoke, the accuracy of existing algorithms for segmentation of small smoke is not high. On the other hand, the translucent character of thin smoke at the edges results in missed segmentation and wrong segmentation
Therefore, to solve above issues, this paper proposes a high-precision segmentation algorithm for smoke based on multi-scale features and global information of smoke. The main work is as follows: (1) a multi-scale residual group attention was proposed to extract and enhance smoke features of different scales, which improved the accuracy of segmentation in small smoke; (2) the self-attention of Transformer was used to generate global features of smoke and fuse them with multi-scale features to reduce the probability of missed segmentation and wrong segmentation; (3) the effectiveness of the method proposed in this paper was verified by ablation experiments and comparative experiments.
2. Related Work
2.1. Neural Attention
An attention mechanism is similar to the way that humans observe objects. More attention is given to locally important information by weighting the feature maps. It is very beneficial to enhance feature representation and reduce noise.
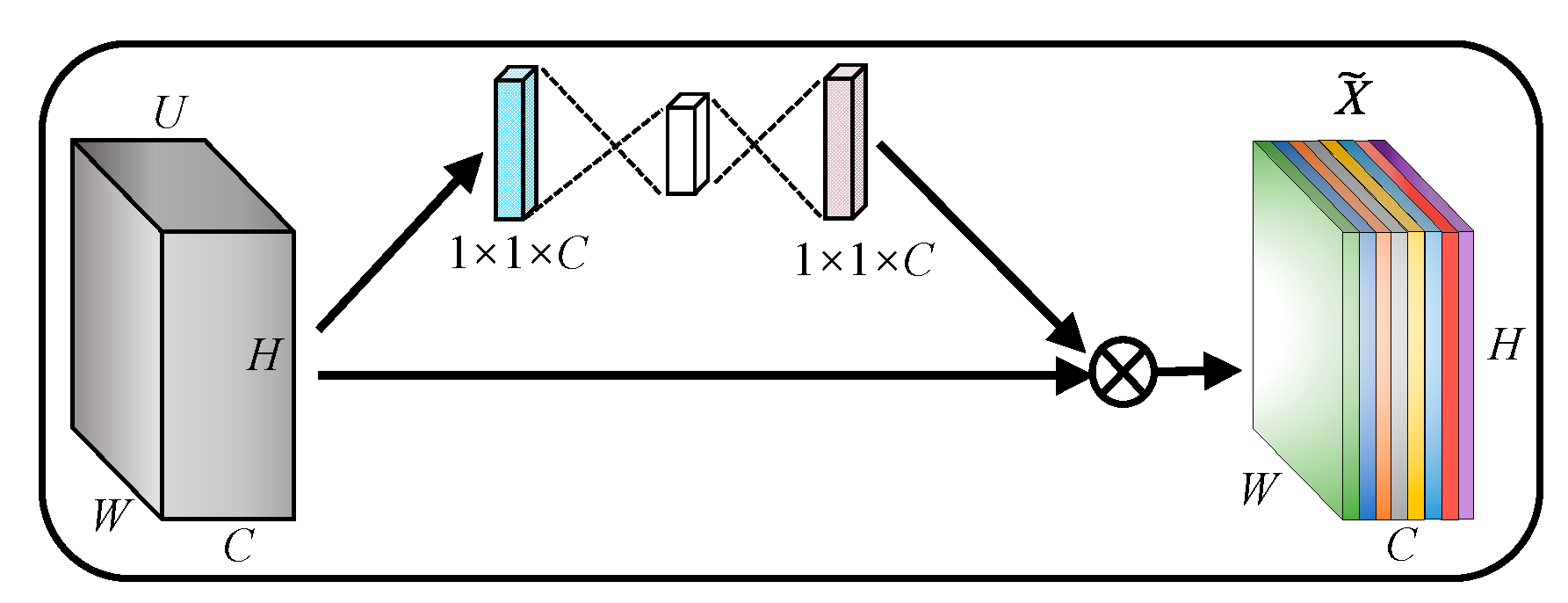
The most representative of existing channel attention is SE-Net [17], as shown in Figure 1. SE-Net generates attention maps by global average pooling, and applies them to input features. The purpose is to suppress useless channels, and enhance beneficial channels by building correlations between channels.
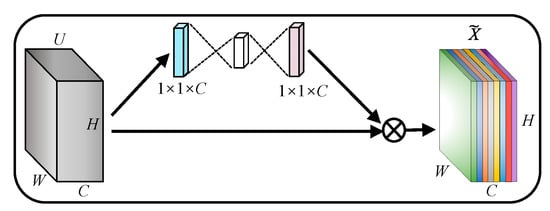
Figure 1.
Channel attention (CA).
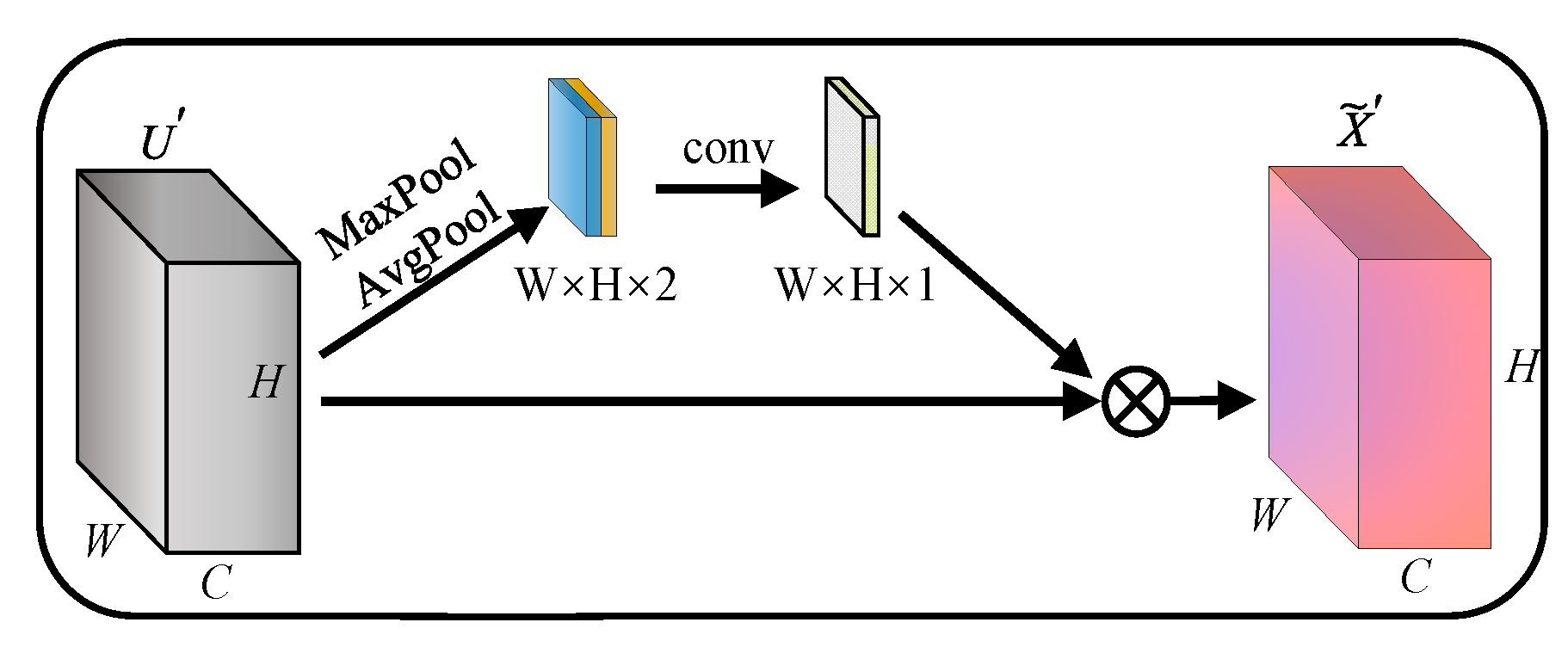
Spatial attention enhances the effective information in the feature map by assigning higher weights to pixels. Spatial attention in CBAM [18] is one of the most representative models. Spatial attention performs maximum pooling and average pooling along the channel. Then, the weight matrix is generated by convolution calculation. Finally, the weight matrix is multiplied with each channel of the feature map to obtain the attentional features, as shown in Figure 2.
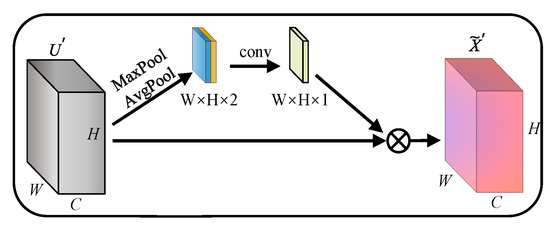
Figure 2.
Spatial attention (SA).
2.2. Transformer
Transformer was first proposed by Vaswani [19] for machine translation and established state-of-the-art technology in many NLP tasks. To make Transformers also applicable for computer vision tasks, several modifications were made. For instance, Alexey et al. [20] proposed Vision Transformer (ViT), and achieved state-of-the-art results in ImageNet classification by directly applying Transformers with global self-attention to full-sized images. Swin Transformer [21] uses sliding windows to improve the computational speed of Transformer, and achieved excellent results in various vision tasks
3. Materials and Methods
3.1. Smoke–U-Net
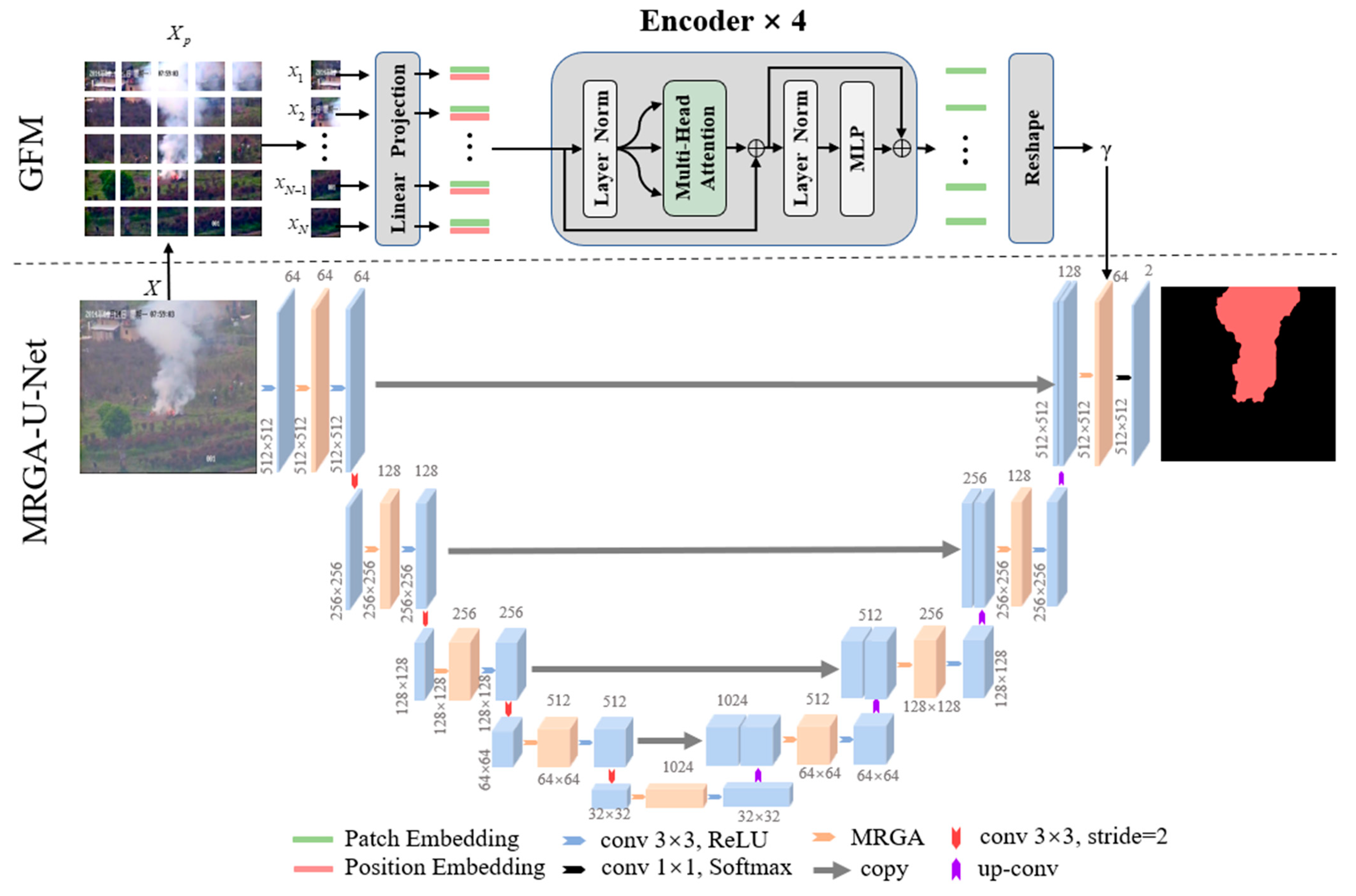
U-Net [22], proposed by Ronneberger, is composed of an encoder and decoder. It is widely used in medical image segmentation. Smoke–U-Net is improved based on U-Net and Transformer, as shown in Figure 3. It mainly contains two parts. The first part is MRGA–U-Net at the bottom of Figure 3, which is improved based on U-Net. MRGA–U-Net replaces the convolution after up-sampling and down-sampling in each layer of U-Net with MRGA. On the one hand, MRGA is used to enhance the representation of smoke features, to make up for the loss of feature information. On the other hand, it can also enhance the perception of a model to multi-scale smoke. The second part is the GFM at the top of Figure 3, which is based on the encoder of Transformer. The input of GFM is an original RGB smoke image and the output is a feature map γ ℝH×W×1, which represents the global information. The global feature γ is fused to MRGA–U-Net by matrix multiplication. Then, the fused features are sent to 1 × 1 convolution and Softmax to obtain the result of segmentation.
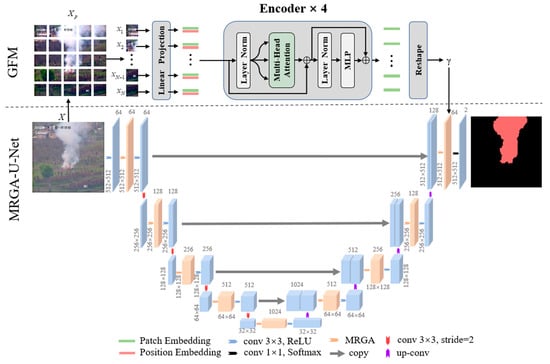
Figure 3.
Smoke–U-Net algorithm.
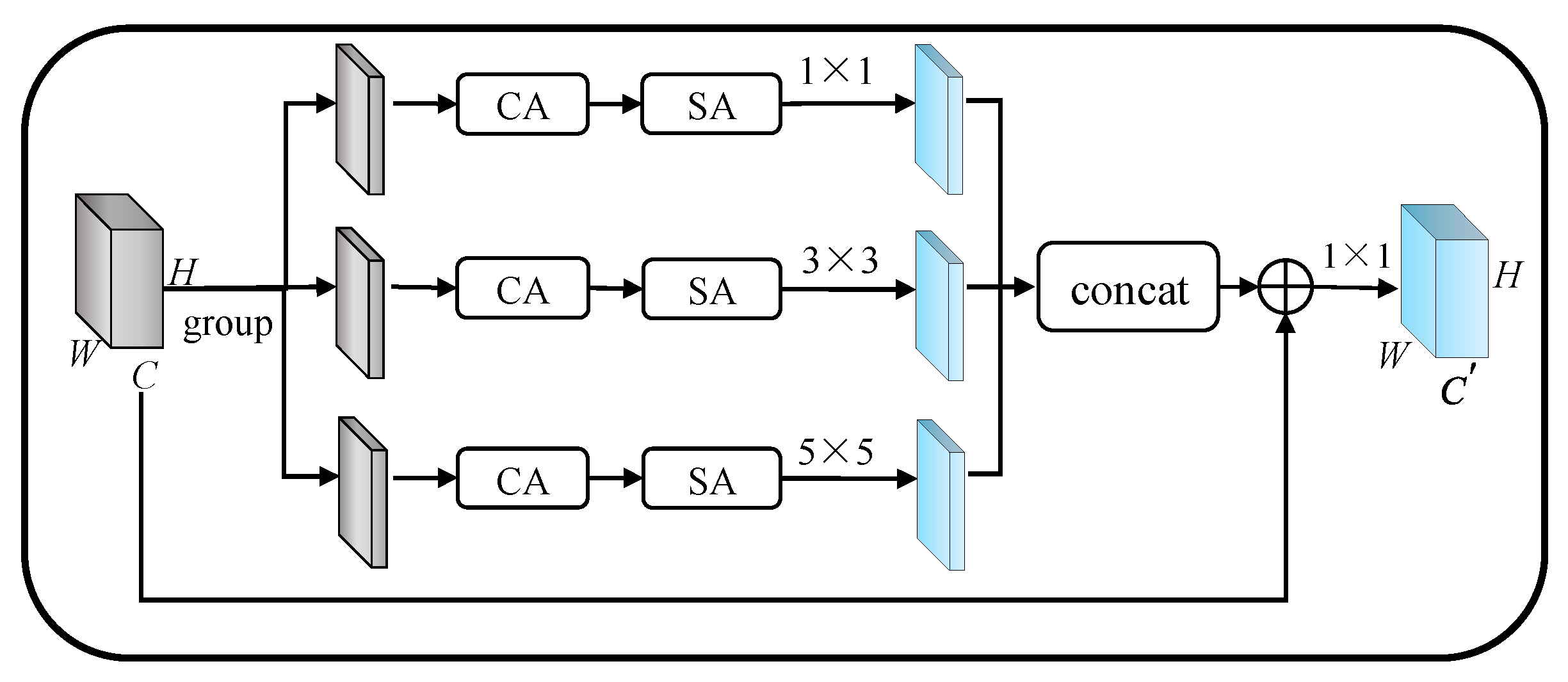
3.2. Multi-Scale Residual Group Attention (MRGA)
Colors, textures, and edges are the main features of smoke. However, in algorithms of smoke segmentation with convolutional neural networks, on the one hand, down-sampling reduces or even removes the feature of small-sized smoke, and the features are difficult to recover during up-sampling, which causes more difficult segmentation on small smoke. To cope with the weakening and loss of information, MRGA uses multi-scale convolution kernels to retain more features without increasing parameters. On the other hand, the higher fusion of small smoke with the background, and the more noise caused by similar pixels, leads to errors in the classification of pixels. To enhance the features of smoke, the MRGA uses channel attention and spatial attention to enhance the representation of features, as shown in Figure 4.
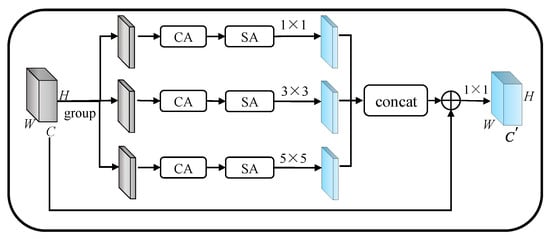
Figure 4.
Multi-scale residual group attention block (MRGA).
MRGA first groups the feature maps, and then extracts multi-scale features of smoke through convolution kernels of different scales. Then, 1 × 1 convolution is used to extract small smoke features, 5 × 5 convolution is used to extract larger smoke features, and 3 × 3 convolution is used to extract regular size features. The extracted multi-scale features are then passed through channel attention and spatial attention to enhance channel features and spatial features, and output a refined feature map. Finally, smoke features at different scales are concatenated. MRGA directly propagates rich, low-frequency information by residual connections, which speeds up the training of the network and alleviates gradient degradation. At the same time, in order to ensure the exchange of information between different grouping features, and enhance the expressiveness of features, MRGA uses 1 × 1 convolution to rearrange output features.
3.3. Global Features Module (GFM)
To solve inaccurate segmentation due to thinness of smoke at the edge, GFM uses the encoder of Transformer to capture global semantic information of the image. We divided the input image into non-overlapping patches , where , p × p denotes the dimension of each patch and is the length of image sequence. Through Linear Projection, we flattened each patch into a K dimensional vector I, where K = C × p × p. To maintain the spatial information of each patch, we added a Positional Embedding Ipos to the Patch Embedding I, in order to preserve positional information T. Finally, we use the encoder of Transformer to encode T and output the image-level global information γ ℝ 1×H×W by Reshape.
3.4. Loss Function
Segmentation results depends not only on network structure, but also on the choice of loss function. Dice loss function is proposed for the problem of low segmentation accuracy due to small target. It is derived from binary classification, which essentially measures the overlap of two regions. In this paper, a loss function combining binary cross entropy (BCE) and Dice loss function was used to alleviate the inaccurate prediction effect caused by the difference in the proportion of foreground and background, as shown in Equations (2)–(4).
where y represents the true label, p represents the predicted result, and N represents the set of all pixels. In order to prevent the numerator and denominator of Dice from being extremely small during the training process, which may exceed the computer’s storage range for the float number, a minimum value ε is set, and ε takes 1 × 10−5 in the experiment.
4. Results
4.1. Experimental Platform
Our experiment used PyTorch framework to build the proposed model. Training and testing were performed on a computer with an Intel Core i7-9700 CPU and 4× NVIDIA Tesla V100 GPU/32G.
Parameters were updated by Adam optimizer with a learning rate of 0.001, a momentum of 0.99, and a decay factor of 0.9 for the learning rate. Batch size was 16.
4.2. Dataset
The smoke dataset comes from The State Key Laboratory of Fire Science, University of Science and Technology of China. The url is http://smoke.ustc.edu.cn/datasets.htm (accessed on 7 July 2021). It is a public dataset that only has raw smoke images, and does not contain label images for model training. Therefore, we organized and annotated 2300 smoke images (3 × 512 × 512) with labelme software to obtain the corresponding binary label maps. It not only includes multiple scenes such as forests, fields, indoors, playgrounds, urban buildings, and roads, but also includes large, medium, and small smoke of different scales. Some samples are shown in Figure 5. During training, the dataset was divided into training set, validation set, and test set, according to the ratio of 7:2:1.

Figure 5.
(a) samples of smoke images; (b) labels of smoke images.
4.3. Evaluation Index
Our experiment adopted mean intersection over union (mIoU), mean pixel accuracy (mPA), and the frames per second (FPS) as evaluation indicators.
mIoU indicates the average of overlap between the segmentation result and real label. It is commonly used to evaluate the accuracy of algorithms, and its calculation formula is as follows:
where k is the number of classes of objects in the foreground, and pij is the number of pixels belonging to class i that are classified as class j.
mPA, shown in Equation (6), indicates the proportion of correctly classified pixels to all pixels:
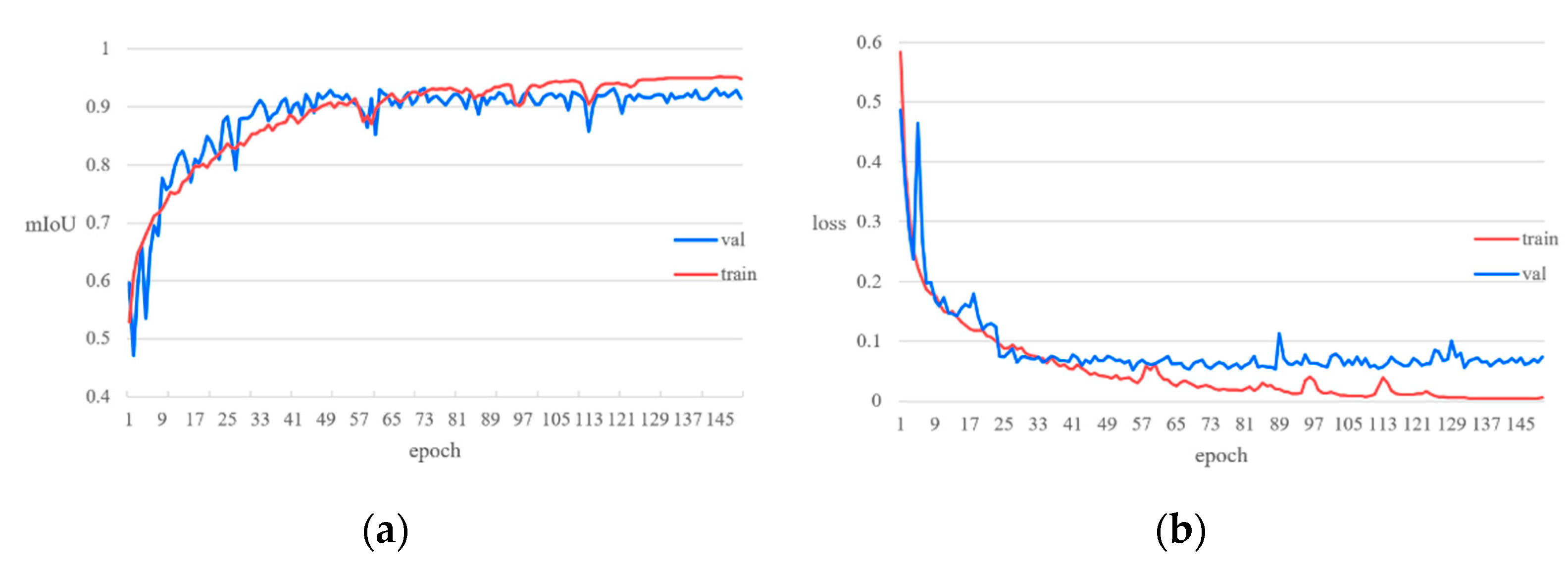
4.4. Results of Train and Validation
In this experiment, the method proposed in this paper was trained and verified for 145 epoch in a smoke dataset, and then the mIoU curve and loss curve were drawn, as shown in Figure 6.
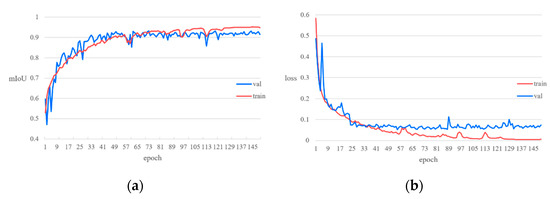
Figure 6.
(a) Mean value of mIoU at convergence of train and validation is 93.51% and 91.82%, respectively; (b) mean value of DBLoss at convergence of train and validation is 0.033 and 0.078%, respectively.
5. Discussion
5.1. Ablation Experiment
In order to validate the effectiveness of MRGA and GFM, we performed ablation experiments to compare and analyze the impact of each improvement on the algorithm. The results are shown in Table 1.

Table 1.
Results of ablation experiments. √ means the current module is included in the method.
The results show that the model with MRGA has a 2.31% improvement in mIoU and a 2.34% improvement in mPA compared with the model without MRGA. It illustrates that MRGA can effectively reduce the negative effect caused by information loss and improve the accuracy of segmentation. Compared with the model without GFM, the mIoU and mPA of the model with GFM improve by 2.59% and 2.48%, respectively. Meanwhile, we can see that GFM slightly outperforms MRGA on mIoU and mPA, however, GFM has a lower FPS. This is related to the fact that GFM has more parameters.
5.2. Comparative Experiment of Multi-Scale Segmentation
To evaluate the effectiveness of Smoke–U-Net, four representative algorithms of segmentation, including SegNet, PSPNet, DeepLab v3+ [23], and U-Net, were selected for experiments on smoke datasets. Firstly, the validation set was divided into three subsets of large, medium, and small, according to the size of the smoke. Then, each algorithm was tested on the subsets to compare the capability of segmentation of smoke of different sizes. The results of different algorithms are shown in Table 2. Compared with other algorithms, Smoke-U-Net significantly improves the accuracy of segmentation for multi-scale smoke, and the average mIoU reaches 91.82%. From these results, it is shown that Smoke-U-Net achieves state-of-the-art results on all three subsets. In particular, in the results of small smoke, the mIoU of Smoke–U-Net increases by 3.11% and 4.54%, compared with DeepLab v3+ and U-Net, respectively.
Table 2.
Comparison of mIoU for segmentation at multi-scale smoke and bold font indicates best grade.
Figure 7 shows the results of segmentation of different sized smoke by each algorithm. Combined with the definition of mIoU, the performance of each method for segmentation can be visualized from the degree of overlap between the red markers and smoke. It can be seen that Smoke–U-Net effectively reduces the wrong segmentation for small smoke and the missed segmentation for thin smoke at the edge. In summary, for different size smoke, the results of Smoke–U-Net are more complete, and the boundary is clearer, compared with the other algorithms.

Figure 7.
Comparison of segmentation results on multi-scale smoke.
5.3. Comprehensive Experiments
As shown in Table 3, eight semantic segmentation models, including Smoke–U-Net, are selected for comparison of comprehensive performance. FCN and SegNet are representatives of the semantic segmentation models with an encoder–decoder. PSPNet and DeepLab v3+ are representatives of semantic segmentation models that perform feature fusion on the basis of an encoder–decoder. DANet is a representative of semantic segmentation models that utilize the parallel attention mechanism to capture semantic features. Vision transformer is a typical representative of self-attention. Comprehensive experiments are performed on all smoke datasets.
Table 3.
Comprehensive performance of each algorithm and bold font indicates best grade.
Experiments show that Smoke–U-Net achieves the highest scores on mIoU and mPA, reaching 91.83% and 96.62%, respectively. It benefits from the accuracy of feature extraction for small-scale smoke by MRGA, and the fusion of global smoke information by GFM. With the increase in sampling times, the receptive field of traditional convolution becomes larger and larger, which causes the small target feature to be larger than its original size when mapped back to original image. MRGA uses 1 × 1 convolution with a smaller receptive field to pass and enhance small features, which makes the feature extraction of small targets more accurate. At the same time, GFM constructs the global information of smoke concentration changes, which improves the recognition ability of thin smoke at the edge of images. Therefore, the higher score achieved by Smoke–U-Net is expected. In terms of frame rate, SegNet and U-Net are two simple encoder–decoder structures, and have significant advantage in computation. In contrast, the encoder of GFM has more parameters and computation. Therefore, Smoke–U-Net is second only to U-Net and SegNet in speed. However, compared to the increase in mIOU (2.70%) and mPA (2.44%), the slightly decrease in speed is acceptable. Vision transformer is more complex, and has a large amount of parameters in the encoder and decoder, so it achieves a lower FPS. Figure 8 shows the results of the comprehensive experiment. Taking into account the speed and accuracy of Smoke–U-Net, it is more applicable to the actual requirements for smoke segmentation than other models.


Figure 8.
Comparison of comprehensive performance of the algorithms (Chinese characters in the picture have no meaning).
The method proposed in this paper is effective in multi-scale smoke segmentation. However, the method is not always highly accurate, as shown in Figure 9. When blurred background is almost integrated with the low-concentration smoke, or there are some solid-color interfering objects in the background, sometimes wrong segmentation occurs. Therefore, we still have a lot of work to do in terms of smoke segmentation.

Figure 9.
Some failure cases of the method in this paper (Chinese characters in the picture have no meaning).
6. Conclusions
In this paper, we analyzed and discussed the current difficulties of smoke segmentation from the demand of detection of fire smoke. To solve these difficulties, an algorithm called Smoke–U-Net was proposed. This algorithm improves U-Net, and proposes a multi-scale residual group attention module, which not only reduces the loss of semantic information, but also enhances the smoke features through channel attention and spatial attention. In addition, the encoder Transformer was used to extract the global information of smoke, and establish the relationship of smoke concentration, so as to improve the segmentation accuracy of thin smoke. Finally, the effectiveness of Smoke–U-Net for smoke segmentation at multiple scales was experimentally verified. It achieves 91.82% mIoU and 96.62% mPA.
Author Contributions
Writing—original draft, Y.Z. and Z.W.; writing—review and editing, Y.Z. and Z.W.; Data curation, B.X.; project administration, Y.N.; software, B.X. and Y.N. All authors have read and agreed to the published version of the manuscript.
Funding
This study was financially supported by the Science and Technology Key Project of Henan Province (Grant No. 202102210180).
Data Availability Statement
The data presented in this study are available on request from the corresponding author. The data are not publicly available, as the research group’s fire smoke semantic segmentation related research is still being carried on, the later work will also rely on the current dataset.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society Press: Los Alamitos, CA, USA, 2017; pp. 2881–2890. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 5–20 June 2019; IEEE Computer Society Press: Los Alamitos, CA, USA, 2019; pp. 3141–3149. [Google Scholar]
- Zhou, T.; Li, L.; Li, X.; Feng, C.M.; Li, J.; Shao, L. Group-wise learning for weakly supervised semantic segmentation. IEEE Trans. Image Processing 2021, 31, 799–811. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Zhou, T.; Yu, F.; Dai, J.; Konukoglu, E.; Van Gool, L. Exploring cross-image pixel contrast for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Zhou, T.; Wang, W.; Konukoglu, E.; Van Gool, L. Rethinking Semantic Segmentation: A Prototype View. arXiv 2022, arXiv:2203.15102v2. [Google Scholar]
- Appana, D.K.; Islam, R.; Khan, S.A.; Kim, J.M. A video-based smoke detection using smoke flow pattern and spatial-temporal energy analyses for alarm systems. Inf. Sci. 2017, 418, 91–101. [Google Scholar] [CrossRef]
- Zhao, Z.M.; Zhu, Z.L.; Liu, M. Fuzzy c-means clustering method for image segmentation insensitive to class size. Laser Optoelectron. Prog. 2020, 57, 56–65. [Google Scholar]
- Wang, R.; Yao, A.; Yang, R. Application of multi-scale image edge detection based on wavelet transform modulus maxima in smoke image. Foreign Electron. Meas. Technol. 2020, 39, 63–67. [Google Scholar]
- Peng, Y.; Wang, Y. Real-time forest smoke detection using hand-designed features and deep learning. Comput. Electron. Agric. 2019, 167, 105029. [Google Scholar] [CrossRef]
- Wu, Y.; Chen, M.; Wo, Y.; Han, G. Video smoke detection base on dense optical flow and convolutional neural network. Multimed. Tools Appl. 2021, 80, 35887–35901. [Google Scholar] [CrossRef]
- Khan, S.; Muhammad, K.; Hussain, T.; Del Ser, J.; Cuzzolin, F.; Bhattacharyya, S.; Akhtar, Z.; de Albuquerque, V.H. DeepSmoke: Deep learning model for smoke detection and segmentation in outdoor environments. Expert Syst. Appl. 2021, 182, 115125. [Google Scholar] [CrossRef]
- Yuan, F.; Zhang, L.; Xia, X.; Huang, Q.; Li, X. A gated recurrent network with dual classification assistance for smoke semantic segmentation. IEEE Trans. Image Processing 2021, 30, 4409–4422. [Google Scholar] [CrossRef] [PubMed]
- Gupta, T.; Liu, H.; Bhanu, B. Early Wildfire Smoke Detection in Videos. In Proceedings of the 25th International Conference on Pattern Recognition, Milan, Italy, 10–15 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 8523–8530. [Google Scholar]
- Zhu, G.; Chen, Z.; Liu, C.; Rong, X.; He, W. 3D video semantic segmentation for wildfire smoke. Mach. Vis. Appl. 2020, 31, 50. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018; p. 00745. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018; pp. 8–14. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Redhook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16 × 16 Words: Transformers For Image Recognition At Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 801–818. [Google Scholar]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).