
Fast CU Partition Decision Algorithm for VVC Intra Coding Using an MET-CNN

Abstract
:1. Introduction
2. Related Works
2.1. Fast Algorithms for Previous Standards
2.2. Fast Algorithms for VVC
3. Proposed Algorithm
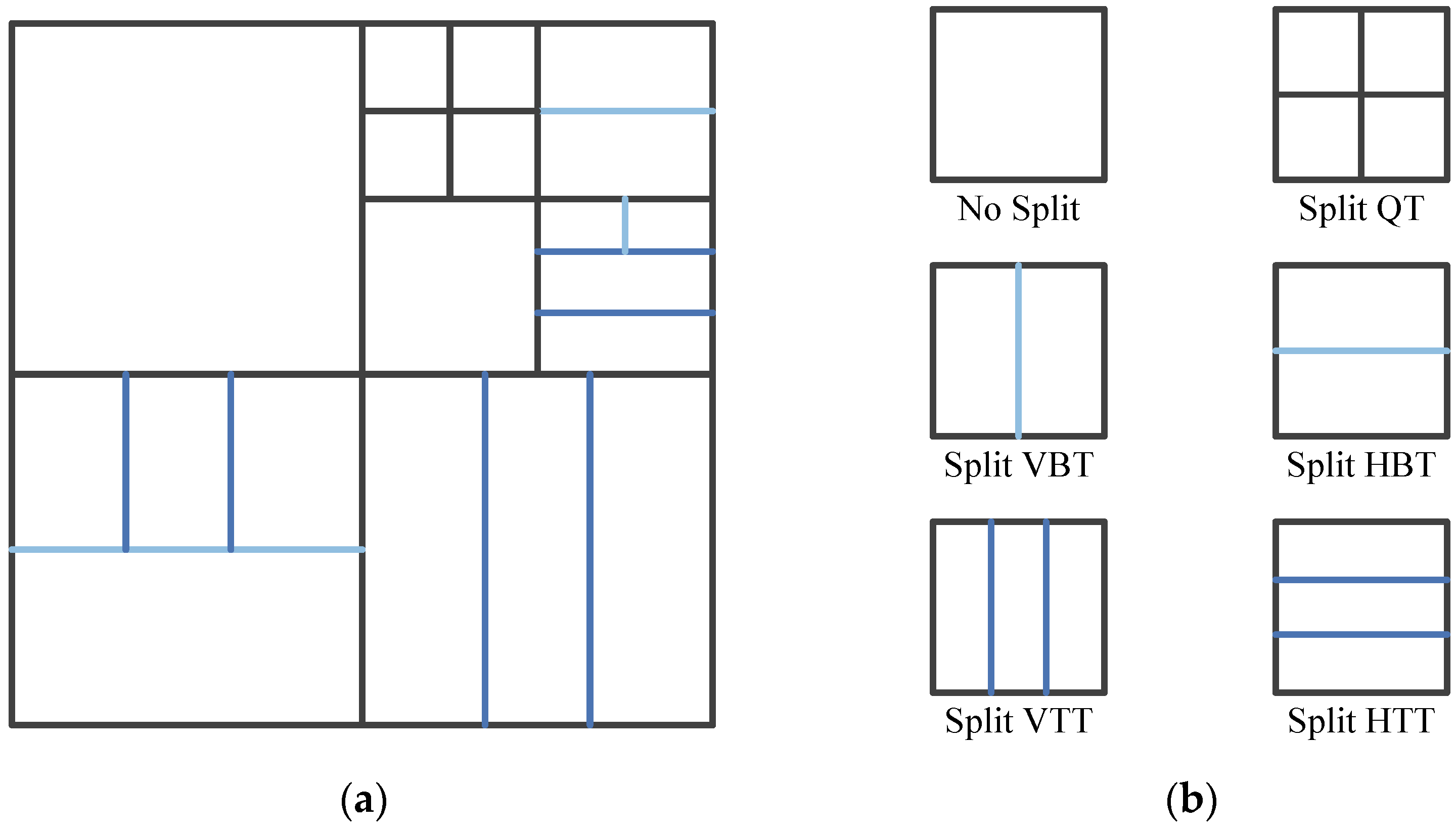
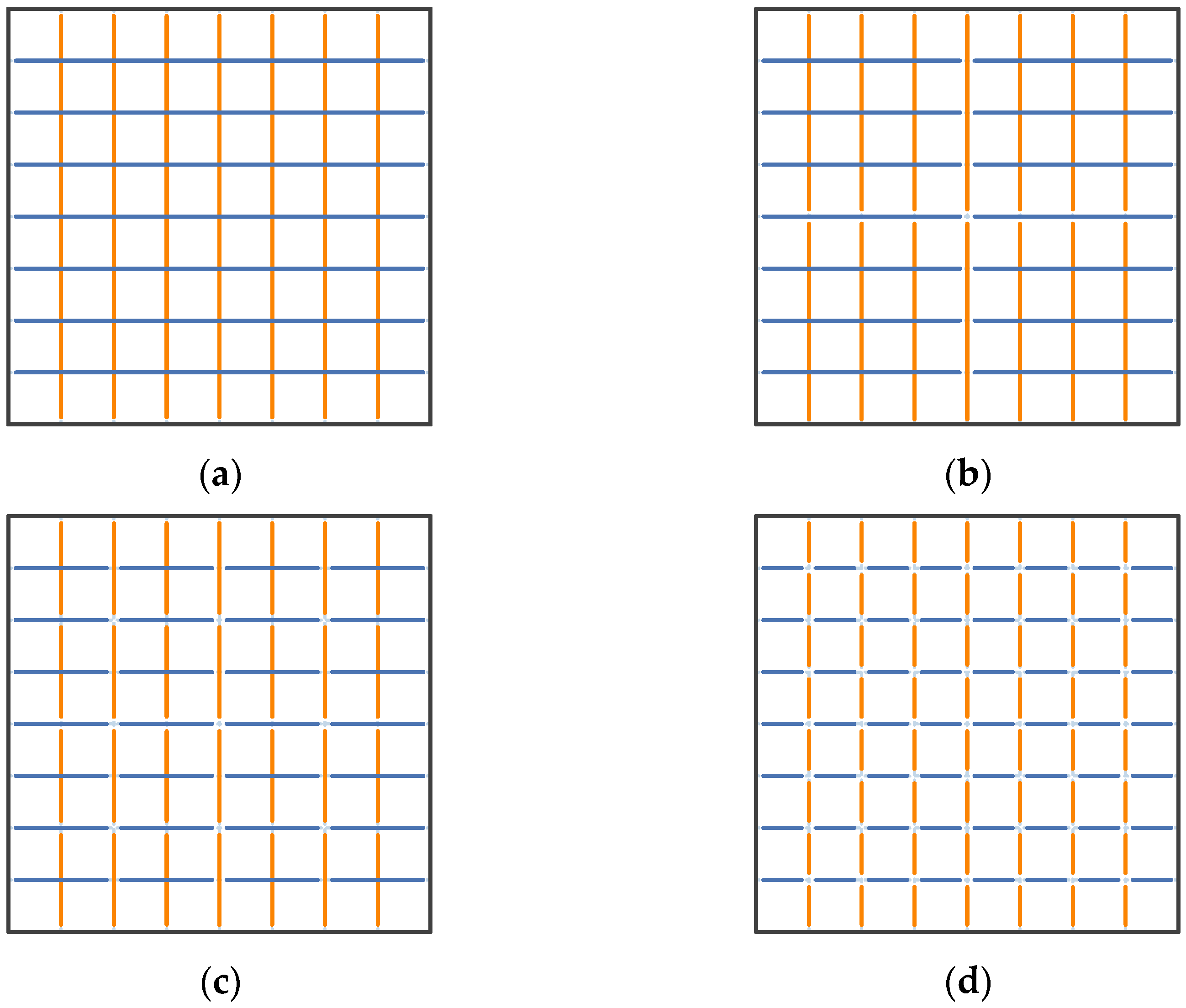
3.1. Stage Grid Map
3.2. Multi-Stage Early Termination CNN
- The backbone of the CNN consists of four stages, each with an output;
- Each stage consists of two set blocks, an average pooling layer with a size of 2 × 2 and a stride of 2, a convolutional layer with a 3 × 3 convolution kernel, a global average pooling layer, and a fully connected layer. The first stage additionally contains a convolutional layer with a 3 × 3 × 16 convolution kernel;
- Each set block contains two convolutional layers with a 3 × 3 × k convolution kernel, a convolutional layer with a 1 × 1 × k convolution kernel, and a shortcut layer. The value of k varies at each stage.
3.3. Model Training
3.4. CU Partition Decision Process
- Step 1: Input a luma block of size 32 × 32;
- Step 2: The luminance block is fed into the MET-CNN as input, and it runs to its i-th stage to get the output vector of this stage;
- Step 3: According to the output vector, the probabilities of the five possible division types at this stage are calculated, and the formula is shown in Equations (5)–(9);
- Step 4: The calculated probabilities of the five division types are compared with the set threshold in the order of , , , , and . The threshold formula is shown in Equation (10). If the probability value of the division type is greater than , the current stage CU performs the division type corresponding to the probability value and moves to the next stage. If the probability values of all division types are not greater than , the division process of the CU at the current stage is terminated in advance. Note that if the division result of the first stage is TT division, the decision-making process of the second stage needs to be judged according to the output vector of the third stage.
4. Experimental Results
4.1. Experimental Environment
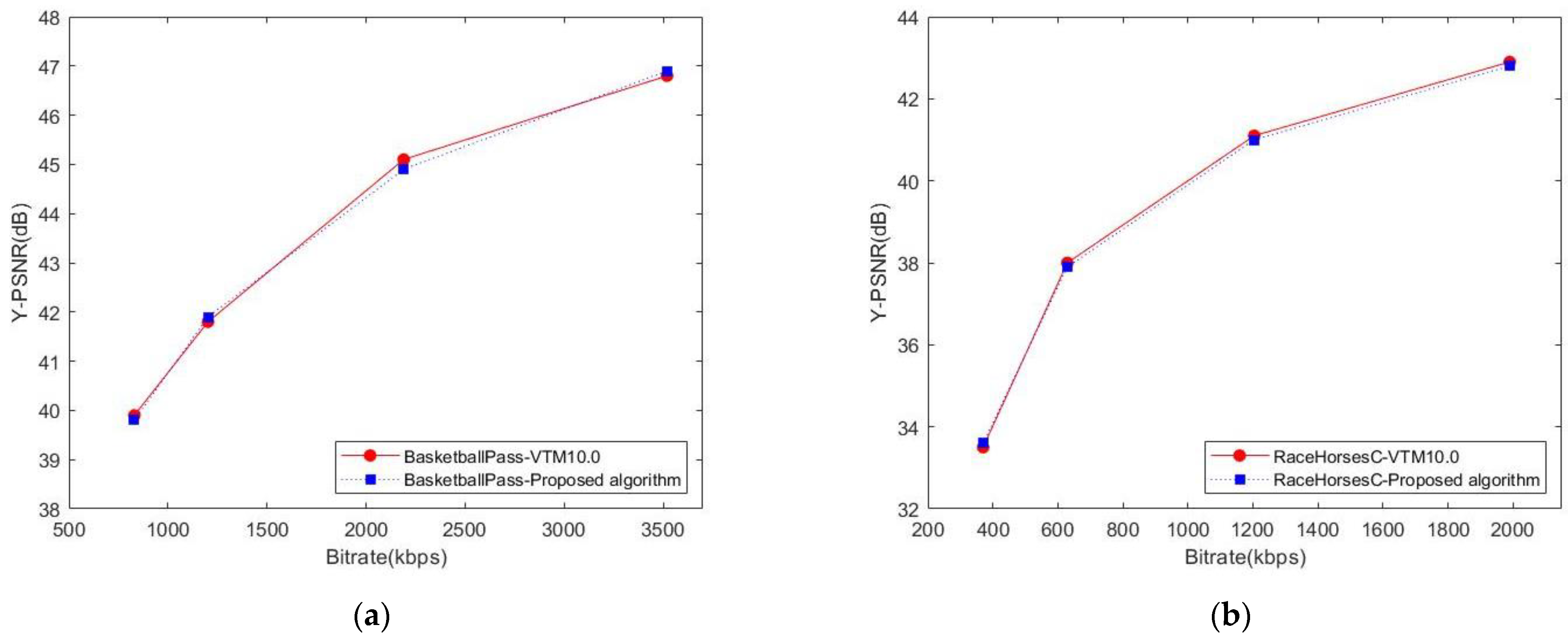
4.2. Analysis of Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Qian, X.; Zeng, Y.; Wang, W.; Zhang, Q. Co-saliency Detection Guided by Group Weakly Supervised Learning. IEEE Trans. Multimed. 2022, 1, 1. [Google Scholar] [CrossRef]
- Oh, K.; So, J.; Kim, J. Low complexity implementation of slim—HEVC encoder design. In Proceedings of the 2016 International Conference on Systems, Signals and Image Processing (IWSSIP), Bratislava, Slovakia, 23–25 May 2016; pp. 1–4. [Google Scholar]
- Filippov, A.; Rufitskiy, V.; Chen, J.; Alshina, E. Intra Prediction in the Emerging VVC Video Coding Standard. In Proceedings of the 2020 Data Compression Conference (DCC), Snowbird, UT, USA, 24–27 March 2020; p. 367. [Google Scholar]
- Versatile Video Coding, Recommendation ITU-T H.266 and ISO/IEC 23090-3 (VVC), ITU-T and ISO/IEC JTC. 1 July 2020. Available online: http://phenix.it-sudparis.eu/jvet/doc_end_user/current_document.php?id=10399 (accessed on 6 August 2022).
- Ye, Y.; Boyce, J.M.; Hanhart, P. Omnidirectional 360° Video Coding Technology in Responses to the Joint Call for Proposals on Video Compression with Capability Beyond HEVC. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1241–1252. [Google Scholar] [CrossRef]
- Huang, Y.-W. Block Partitioning Structure in the VVC Standard. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3818–3833. [Google Scholar] [CrossRef]
- Bouaafia, S.; Khemiri, R.; Sayadi, F.E. Rate-Distortion Performance Comparison: VVC vs. HEVC. In Proceedings of the 2021 18th International Multi-Conference on Systems, Signals & Devices (SSD), Monastir, Tunisia, 22–25 March 2021; pp. 440–444. [Google Scholar]
- Chen, Z.; Shi, J.; Li, W. Learned Fast HEVC Intra Coding. IEEE Trans. Image Processing 2020, 29, 5431–5446. [Google Scholar] [CrossRef] [PubMed]
- Lilhore, U.K.; Imoize, A.L.; Lee, C.C.; Simaiya, S.; Pani, S.K.; Goyal, N.; Kumar, A.; Li, C.T. Enhanced convolutional neural network model for cassava leaf disease identification and classification. Mathematics 2022, 10, 580. [Google Scholar] [CrossRef]
- Zhang, G.; Xiong, L.; Lian, X.; Zhou, W. A CNN-based Coding Unit Partition in HEVC for Video Processing. In Proceedings of the 2019 IEEE International Conference on Real-Time Computing and Robotics (RCAR), Irkutsk, Russia, 4–9 August 2019; pp. 273–276. [Google Scholar]
- Liu, Y.; Wei, A. A CU Fast Division Decision Algorithm with Low Complexity for HEVC. In Proceedings of the 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 12–14 June 2020; pp. 1028–1032. [Google Scholar]
- Guo, X.; Wang, Q.; Jiang, J. A Lightweight CNN for Low-Complexity HEVC Intra Encoder. In Proceedings of the 2020 IEEE 15th International Conference on Solid-State & Integrated Circuit Technology (ICSICT), Kunming, China, 3–6 November 2020; pp. 1–3. [Google Scholar]
- Jamali, M.; Coulombe, S.; Sadreazami, H. CU Size Decision for Low Complexity HEVC Intra Coding based on Deep Reinforcement Learning. In Proceedings of the 2020 IEEE 63rd International Midwest Symposium on Circuits and Systems (MWSCAS), Springfield, MA, USA, 9–12 August 2020; pp. 586–591. [Google Scholar]
- Kim, K.; Ro, W.W. Fast CU Depth Decision for HEVC Using Neural Networks. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 1462–1473. [Google Scholar] [CrossRef]
- Heindel, A.; Haubner, T.; Kaup, A. Fast CU split decisions for HEVC inter coding using support vector machines. In Proceedings of the 2016 Picture Coding Symposium (PCS), Nuremberg, Germany, 4–7 December 2016; pp. 1–5. [Google Scholar]
- Zhang, Y.; Kwong, S.; Wang, X.; Yuan, H.; Pan, Z.; Xu, L. Machine Learning-Based Coding Unit Depth Decisions for Flexible Complexity Allocation in High Efficiency Video Coding. IEEE Trans. Image Processing 2015, 24, 2225–2238. [Google Scholar] [CrossRef] [PubMed]
- Javaid, S.; Rizvi, S.; Ubaid, M.T.; Tariq, A. VVC/H.266 Intra Mode QTMT Based CU Partition Using CNN. IEEE Access 2022, 10, 37246–37256. [Google Scholar] [CrossRef]
- HoangVan, X.; NguyenQuang, S.; DinhBao, M.; DoNgoc, M.; Trieu Duong, D. Fast QTMT for H.266/VVC Intra Prediction using Early-Terminated Hierarchical CNN model. In Proceedings of the 2021 International Conference on Advanced Technologies for Communications (ATC), Ho Chi Minh City, Vietnam, 14–16 October 2021; pp. 195–200. [Google Scholar]
- Zhao, J.C.; Wang, Y.H.; Zhang, Q.W. Fast CU Size Decision Method Based on Just Noticeable Distortion and Deep Learning. Sci. Program. 2021, 2021, 3813116. [Google Scholar] [CrossRef]
- Li, T.; Xu, M.; Tang, R.; Chen, Y.; Xing, Q. DeepQTMT: A Deep Learning Approach for Fast QTMT-Based CU Partition of Intra-Mode VVC. IEEE Trans. Image Processing 2021, 30, 5377–5390. [Google Scholar] [CrossRef] [PubMed]
- Fu, P.-C.; Yen, C.-C.; Yang, N.-C.; Wang, J.-S. Two-phase Scheme for Trimming QTMT CU Partition using Multi-branch Convolutional Neural Networks. In Proceedings of the 2021 IEEE 3rd International Conference on Artificial Intelligence Circuits and Systems (AICAS), Washington, DC, USA, 6–9 June 2021; pp. 1–6. [Google Scholar]
- Tang, G.; Jing, M.; Zeng, X.; Fan, Y. Adaptive CU Split Decision with Pooling-variable CNN for VVC Intra Encoding. In Proceedings of the 2019 IEEE Visual Communications and Image Processing (VCIP), Sydney, NSW, Australia, 1–4 December 2019; pp. 1–4. [Google Scholar]
- Tissier, A.; Hamidouche, W.; Vanne, J.; Galpin, F.; Menard, D. CNN Oriented Complexity Reduction Of VVC Intra Encoder. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 3139–3143. [Google Scholar]
- Zhang, Q.; Guo, R.; Jiang, B.; Su, R. Fast CU Decision-Making Algorithm Based on DenseNet Network for VVC. IEEE Access 2021, 9, 119289–119297. [Google Scholar] [CrossRef]
- Huang, Y.-H.; Chen, J.-J.; Tsai, Y.-H. Speed Up H.266/QTMT Intra-Coding Based on Predictions of ResNet and Random Forest Classifier. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 10–12 January 2021; pp. 1–6. [Google Scholar]
- Abdallah, B.; Belghith, F.; Ben Ayed, M.A.; Masmoudi, N. Low-complexity QTMT partition based on deep neural network for Versatile Video Coding. Signal Image Video Processing 2021, 15, 1153–1160. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Agustsson, E.; Timofte, R. NTIRE 2017 Challenge on Single Image Super-Resolution: Dataset and Study. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1122–1131. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Sequence | CU (32 × 32) | Number of All Possible Combinations of CU Partitions |
|---|---|---|---|
| A1 | Campfire | 8160 | 2156 |
| A1 | CatRobot | 8160 | 5948 |
| B | BQTerrace | 2040 | 1710 |
| C | PartyScene | 390 | 390 |
| D | BQSquare | 110 | 106 |
| E | FourPeople | 920 | 641 |
| (a, b) | BDBR (%) | ΔT (%) |
|---|---|---|
| (0.9, 0.1) | 0.73 | 39.29 |
| (0.9, 0.2) | 0.99 | 49.36 |
| (0.9, 0.3) | 1.32 | 55.64 |
| (0.8, 0.1) | 0.95 | 54.58 |
| (0.8, 0.2) | 0.98 | 50.69 |
| (0.8, 0.3) | 1.09 | 53.23 |
| (0.7, 0.1) | 0.96 | 49.69 |
| (0.7, 0.2) | 1.10 | 54.12 |
| (0.7, 0.3) | 1.14 | 56.31 |
| Test Sequence | [26] | [21] | Proposed | ||||
|---|---|---|---|---|---|---|---|
| BDBR (%) | ΔT (%) | BDBR (%) | ΔT (%) | BDBR (%) | ΔT (%) | ||
| Class A1 4K | FoodMarket4 | 3.35 | 27.09 | 0.22 | 29.94 | 0.57 | 40.62 |
| Campfire | 2.81 | 25.71 | 0.81 | 45.62 | 0.82 | 55.78 | |
| Class A2 4K | Catrobot1 | 2.50 | 28.34 | 0.80 | 44.50 | 1.35 | 53.63 |
| DaylightRoad2 | 2.59 | 32.96 | 0.72 | 45.95 | 0.75 | 50.21 | |
| ParkRunning3 | 1.96 | 21.93 | 0.47 | 43.84 | 0.95 | 54.58 | |
| Class B 1920 × 1080 | Cactus | 3.99 | 22.78 | 0.72 | 46.77 | 1.31 | 56.87 |
| BasketballDrive | 6.79 | 20.67 | 0.67 | 48.98 | 0.83 | 54.23 | |
| BQTerrace | 4.80 | 25.91 | 0.60 | 41.75 | 0.91 | 50.67 | |
| Class C 832 × 480 | BasketballDrill | 2.95 | 28.37 | 1.40 | 37.63 | 1.17 | 44.39 |
| BQMall | 5.70 | 21.69 | 0.89 | 41.72 | 1.12 | 49.47 | |
| PartyScene | 2.80 | 20.89 | 0.28 | 38.73 | 0.98 | 47.02 | |
| RaceHorsesC | 3.70 | 21.43 | 0.61 | 43.39 | 0.67 | 48.15 | |
| Class D 416 × 240 | BasketballPass | 5.46 | 22.29 | 0.62 | 38.06 | 1.01 | 49.11 |
| BQsquare | 2.36 | 26.62 | 0.44 | 32.56 | 0.87 | 40.61 | |
| BlowingBubbles | 2.69 | 27.78 | 0.32 | 36.97 | 1.16 | 48.91 | |
| RaceHorses | 3.32 | 25.71 | 0.45 | 36.86 | 0.68 | 44.28 | |
| Class E 1280 × 720 | FourPeople | 6.73 | 21.82 | 1.08 | 42.57 | 0.88 | 46.82 |
| KristenAndSara | 8.82 | 23.68 | 1.00 | 45.53 | 1.53 | 50.94 | |
| Average | 4.07 | 24.76 | 0.67 | 41.18 | 0.97 | 49.24 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Dai, P.; Zhao, J.; Zhang, Q. Fast CU Partition Decision Algorithm for VVC Intra Coding Using an MET-CNN. Electronics 2022, 11, 3090. https://doi.org/10.3390/electronics11193090
Wang Y, Dai P, Zhao J, Zhang Q. Fast CU Partition Decision Algorithm for VVC Intra Coding Using an MET-CNN. Electronics. 2022; 11(19):3090. https://doi.org/10.3390/electronics11193090
Chicago/Turabian StyleWang, Yanjun, Pu Dai, Jinchao Zhao, and Qiuwen Zhang. 2022. "Fast CU Partition Decision Algorithm for VVC Intra Coding Using an MET-CNN" Electronics 11, no. 19: 3090. https://doi.org/10.3390/electronics11193090