
Feature Selection Techniques for Big Data Analytics


Abstract
:1. Introduction
1.1. Motivation
1.2. Related Work
2. Methodology
- Model creation using the full set of data/attributes.
- Model creation using the reduced set obtained through the random subset.
- Model creation using the reduced set obtained through the random projection.

2.1. Naïve Bayesian
2.2. Bayesian Network
3. Experimental Evaluation
3.1. Rational
3.2. Dataset
3.3. Experimental Setup
4. Evaluation, Results, and Discussion
5. Comparative Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Albattah, W. The role of sampling in big data analysis. In Proceedings of the International Conference on Big Data and Advanced Wireless Technologies, Blagoevgrad, Bulgaria, 10 November 2016; pp. 1–5. [Google Scholar]
- Hilbert, M. Big data for development: A review of promises and challenges. Dev. Policy Rev. 2016, 34, 135–174. [Google Scholar] [CrossRef] [Green Version]
- Reed, D.A.; Dongarra, J. Exascale computing and big data. Commun. ACM 2015, 58, 56–68. [Google Scholar] [CrossRef]
- L’Heureux, A.; Grolinger, K.; Elyamany, H.F.; Capretz, M.A.M. Machine learning with big data: Challenges and approaches. IEEE Access 2017, 5, 7776–7797. [Google Scholar] [CrossRef]
- Singh, K.; Guntuku, S.C.; Thakur, A.; Hota, C. Big data analytics framework for peer-to-peer botnet detection using random forests. Inf. Sci. 2014, 278, 488–497. [Google Scholar] [CrossRef]
- Clarke, R. Big data, big risks. Inf. Syst. J. 2016, 26, 77–90. [Google Scholar] [CrossRef]
- Sullivan, D. Introduction to Big Data Security Analytics in the Enterprise. Available online: https://searchsecurity.techtarget.com/feature/Introduction-to-big-data-security-analytics-in-the-enterprise (accessed on 25 May 2021).
- Tsai, C.-W.; Lai, C.-F.; Chao, H.-C.; Vasilakos, A.V. Big data analytics: A survey. J. Big Data 2015, 2, 21. [Google Scholar] [CrossRef] [Green Version]
- Bello-Orgaz, G.; Jung, J.J.; Camacho, D. Social big data: Recent achievements and new challenges. Inf. Fusion 2016, 28, 45–59. [Google Scholar] [CrossRef]
- Zakir, J.; Seymour, T.; Berg, K. Big data analytics. Issues Inf. Syst. 2015, 16, 81–90. [Google Scholar]
- Sivarajah, U.; Kamal, M.M.; Irani, Z.; Weerakkody, V. Critical analysis of big data challenges and analytical methods. J. Bus. Res. 2017, 70, 263–286. [Google Scholar] [CrossRef] [Green Version]
- Engemann, K.; Enquist, B.J.; Sandel, B.; Boyle, B.; Jørgensen, P.M.; Morueta-Holme, N.; Peet, R.K.; Violle, C.; Svenning, J.-C. Limited sampling hampers ‘big data’ estimation of species richness in a tropical biodiversity hotspot. Ecol. Evol. 2015, 5, 807–820. [Google Scholar] [CrossRef]
- Kim, J.K.; Wang, Z. Sampling techniques for big data analysis. Int. Stat. Rev. 2018, 87, S177–S191. [Google Scholar] [CrossRef]
- Liu, S.; She, R.; Fan, P. How many samples required in big data collection: A differential message importance measure. arXiv 2018, arXiv:1801.04063. [Google Scholar]
- Bierkens, J.; Fearnhead, P.; Roberts, G. The zig-zag process and super-sufficient sampling for Bayesian analysis of big data. Ann. Stat. 2016, 47, 1288–1320. [Google Scholar]
- Zhao, J.; Sun, J.; Zhai, Y.; Ding, Y.; Wu, C.; Hu, M. A novel clustering-based sampling approach for minimum sample set in big data environment. Int. J. Pattern Recognit. Artif. Intell. 2018, 32, 1850003. [Google Scholar] [CrossRef]
- Zhou, L.; Pan, S.; Wang, J.; Vasilakos, A.V. Machine learning on big data: Opportunities and challenges. Neurocomputing 2017, 237, 350–361. [Google Scholar] [CrossRef] [Green Version]
- Kotzias, D.; Denil, M.; de Freitas, N.; Smyth, P. From group to individual labels using deep features. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10 August 2015; pp. 597–606. [Google Scholar]
- Karegowda, A.G.; Manjunath, A.S.; Jayaram, M.A. Comparative study of attribute selection using gain ratio and correlation based feature selection. Int. J. Inf. Technol. Knowl. Manag. 2010, 2, 271–277. [Google Scholar]
- Holte, R.C. Very simple classification rules perform well on most commonly used datasets. Mach. Learn. 1993, 11, 63–90. [Google Scholar] [CrossRef]
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning hierarchical features for scene labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1915–1929. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 24 May 2012; Volume 1, pp. 1097–1105. [Google Scholar]
- Avila, S.; Thome, N.; Cord, M.; Valle, E.; de Araújo, A. Pooling in image representation: The visual codeword point of view. Comput. Vis. Image Underst. 2013, 117, 453–465. [Google Scholar] [CrossRef]
- Moustafa, M.N. Applying deep learning to classify pornographic images and videos. In Proceedings of the 7th Pacific-Rim Symposium on Image and Video Technology (PSIVT 2015), Auckland, New Zealand, 28 November 2015. [Google Scholar]
- Lopes, A.P.B.; de Avila, S.E.F.; Peixoto, A.N.A.; Oliveira, R.S.; de Coelho, M.; Araújo, A.D.A. Nude detection in video using bag-of-visual-features. In Proceedings of the 2009 XXII Brazilian Symposium on Computer Graphics and Image Processing, Rio de Janeiro, Brazil, 11–15 October 2009; pp. 224–231. [Google Scholar]
- Abadpour, A.; Kasaei, S. Pixel-based skin detection for pornography filtering. Iran. J. Electr. Electron. Eng. 2005, 1, 21–41. [Google Scholar]
- Ullah, R.; Alkhalifah, A. Media content access: Image-based filtering. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 415–419. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Valle, E.; Avila, S.; de Souza, F.; Coelho, M.; de Araújo, A. Content-based filtering for video sharing social networks. In Proceedings of the XII Simpósio Brasileiro em Segurança da Informação e de Sistemas Computacionais—SBSeg, Curitiba, Brazil, 12 January 2011; p. 28. [Google Scholar]
- da Silva Eleuterio, P.M.; de Castro Polastro, M. An adaptive sampling strategy for automatic detection of child pornographic videos. In Proceedings of the Seventh International Conference on Forensic Computer Science, Brasilia, Brazil, 24 September 2012; pp. 12–19. [Google Scholar]
- Agarwal, N.; Liu, H.; Zhang, J. Blocking objectionable web content by leveraging multiple information sources. ACM SIGKDD Explor. Newsl. 2006, 8, 17–26. [Google Scholar] [CrossRef]
- Jansohn, C.; Ulges, A.; Breuel, T.M. Detecting pornographic video content by combining image features with motion information. In Proceedings of the Seventeen ACM International Conference on Multimedia—MM, Beijing, China, 19–22 October 2009; p. 601. [Google Scholar]
- Wang, J.-H.; Chang, H.-C.; Lee, M.-J.; Shaw, Y.-M. Classifying peer-to-peer file transfers for objectionable content filtering using a web-based approach. IEEE Intell. Syst. 2002, 17, 48–57. [Google Scholar]
- Lee, H.; Lee, S.; Nam, T. Implementation of high performance objectionable video classification system. In Proceedings of the 2006 8th International Conference Advanced Communication Technology, Phoenix Park, Korea, 20–22 February 2006; pp. 962–965. [Google Scholar]
- Liu, D.; Hua, X.-S.; Wang, M.; Zhang, H. Boost search relevance for tag-based social image retrieval. In Proceedings of the 2009 IEEE International Conference on Multimedia and Expo, New York, NY, USA, 28 June–3 July 2009; pp. 1636–1639. [Google Scholar]
- da Silva Júnior, J.A.; Marçal, R.E.; Batista, M.A. Image retrieval: Importance and applications. In Proceedings of the Workshop de Visao Computacional—WVC, Uberlandia, Brazil, 6–8 October 2014. [Google Scholar]
- Badghaiya, S.; Barve, A. Image classification using tag and segmentation based retrieval. Int. J. Comput. Appl. 2014, 103, 20–23. [Google Scholar] [CrossRef]
- Bhute, A.N.; Meshram, B.B. Text based approach for indexing and retrieval of image and video: A review. Adv. Vis. Comput. Int. J. 2014, 1, 27–38. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Hall, M.A.; Smith, L.A. Practical feature subset selection for machine learning. In Proceedings of the 21st Australasian Computer Science Conference ACSC’98, Perth, Australia, 4–6 February 1998; pp. 181–191. [Google Scholar]
- Hall, M.A. Correlation-Based Feature Selection for Machine Learning. Ph.D. Thesis, The University of Waikato, Hamilton, New Zealand, 1999. [Google Scholar]
- Jolliffe, I.T. Choosing a subset of principal components or variables. In Principal Component Analysis; Springer: New York, NY, USA, 1986; pp. 92–114. [Google Scholar]
- Kira, K.; Rendell, L.A. A practical approach to feature selection. Mach. Learn. Proc. 1992, 1992, 249–256. [Google Scholar]
- Kononenko, I. Estimating attributes: Analysis and extensions of RELIEF. In Proceedings of the European Conference on Machine Learning, Catania, Italy, 6–8 April 1994; pp. 171–182. [Google Scholar]
- Albattah, W.; Khan, R.U. Processing sampled big data. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 350–356. [Google Scholar] [CrossRef] [Green Version]
- Albattah, W.; Albahli, S. Content-based prediction: Big data sampling perspective. Int. J. Eng. Technol. 2019, 8, 627–635. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Wang, C.; Shi, Y.; Fan, X.; Shao, M. Attribute reduction based on k-nearest neighborhood rough sets. Int. J. Approx. Reason. 2019, 106, 18–31. [Google Scholar] [CrossRef]
- Lakshmanaprabu, S.K.; Shankar, K.; Khanna, A.; Gupta, D.; Rodrigues, J.J.P.C.; Pinheiro, P.R.; De Albuquerque, V.H.C. Effective features to classify big data using social internet of things. IEEE Access 2018, 6, 24196–24204. [Google Scholar] [CrossRef]
- Reddy, G.T.; Reddy, M.P.K.; Lakshmanna, K.; Kaluri, R.; Rajput, D.S.; Srivastava, G.; Baker, T. Analysis of dimensionality reduction techniques on big data. IEEE Access 2020, 8, 54776–54788. [Google Scholar] [CrossRef]
- Chen, H.; Li, T.; Cai, Y.; Luo, C.; Fujita, H. Parallel attribute reduction in dominance-based neighborhood rough set. Inf. Sci. 2016, 373, 351–368. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Yang, X.; Song, X.; Li, J.; Wang, P.; Yu, D.-J. Neighborhood attribute reduction: A multi-criterion approach. Int. J. Mach. Learn. Cybern. 2019, 10, 731–742. [Google Scholar] [CrossRef]
- Rostami, M.; Berahmand, K.; Forouzandeh, S. A novel community detection based genetic algorithm for feature selection. J. Big Data 2021, 8, 1–27. [Google Scholar] [CrossRef]
- Rajendran, S.; Khalaf, O.I.; Alotaibi, Y.; Alghamdi, S. MapReduce-based big data classification model using feature subset selection and hyperparameter tuned deep belief network. Sci. Rep. 2021, 11, 1–10. [Google Scholar]
- Rostami, M.; Berahmand, K.; Nasiri, E.; Forouzandeh, S. Review of swarm intelligence-based feature selection methods. Eng. Appl. Artif. Intell. 2021, 100, 104210. [Google Scholar] [CrossRef]
- Song, X.F.; Zhang, Y.; Gong, D.W.; Gao, X.Z. A fast hybrid feature selection based on correlation-guided clustering and particle swarm optimization for high-dimensional data. IEEE Trans. Cybern. 2021, 52, 9573–9586. [Google Scholar] [CrossRef]
- Jain, D.K.; Boyapati, P.; Venkatesh, J.; Prakash, M. An intelligent cognitive-inspired computing with big data analytics framework for sentiment analysis and classification. Inf. Process. Manag. 2022, 59, 102758. [Google Scholar] [CrossRef]
- Abu Khurma, R.; Aljarah, I.; Sharieh, A.; Abd Elaziz, M.; Damaševičius, R.; Krilavičius, T. A review of the modification strategies of the nature inspired algorithms for feature selection problem. Mathematics 2022, 10, 464. [Google Scholar] [CrossRef]
- Dini, P.; Saponara, S. Analysis, design, and comparison of machine-learning techniques for networking intrusion detection. Designs 2021, 5, 9. [Google Scholar] [CrossRef]
- Ferrag, M.A.; Friha, O.; Hamouda, D.; Maglaras, L.; Janicke, H. Edge-IIoTset: A New Comprehensive Realistic Cyber Security Dataset of IoT and IIoT Applications for Centralized and Federated Learning. IEEE Access 2022, 10, 40281–40306. [Google Scholar] [CrossRef]
- Dini, P.; Begni, A.; Ciavarella, S.; De Paoli, E.; Fiorelli, G.; Silvestro, C.; Saponara, S. Design and Testing Novel One-Class Classifier Based on Polynomial Interpolation with Application to Networking Security. IEEE Access 2022, 10, 67910–67924. [Google Scholar] [CrossRef]
- Hall, M. Correlation-based Feature Selection for Machine Learning. Methodology 1999, 21i195-i20, 1–5. [Google Scholar]
- Reservoir Sampling—ORIE 6125: Computational Methods in Operations Research 3.0.1 Documentation. 2022. Available online: https://people.orie.cornell.edu/snp32/orie_6125/algorithms/reservoir-sampling.html (accessed on 18 September 2022).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Selection | |||
|---|---|---|---|
| Random Subset | Random Projection | ||
| ML Model | Naïve Bayes | Combination 1 | Combination 2 |
| Bayesian Network | Combination 3 | Combination 4 | |
| Percentage | F-Measure Naïve Bayesian (Random Subset) |
|---|---|
| 10 | 0.721 |
| 20 | 0.693 |
| 30 | 0.707 |
| 40 | 0.708 |
| 50 | 0.727 |
| 60 | 0.717 |
| 70 | 0.722 |
| 80 | 0.729 |
| 90 | 0.721 |
| 100 | 0.721 |
| Percentage | F-Measure Naïve Bayesian (Random Projection) |
|---|---|
| 10 | 0.675 |
| 20 | 0.714 |
| 30 | 0.724 |
| 40 | 0.731 |
| 50 | 0.749 |
| 60 | 0.748 |
| 70 | 0.747 |
| 80 | 0.754 |
| 90 | 0.748 |
| 100 | 0.721 |
| Percentage | F-measure Bayesian Network (Random Subset) |
|---|---|
| 10 | 0.647 |
| 20 | 0.741 |
| 30 | 0.756 |
| 40 | 0.757 |
| 50 | 0.759 |
| 60 | 0.763 |
| 70 | 0.766 |
| 80 | 0.762 |
| 90 | 0.767 |
| 100 | 0.77 |
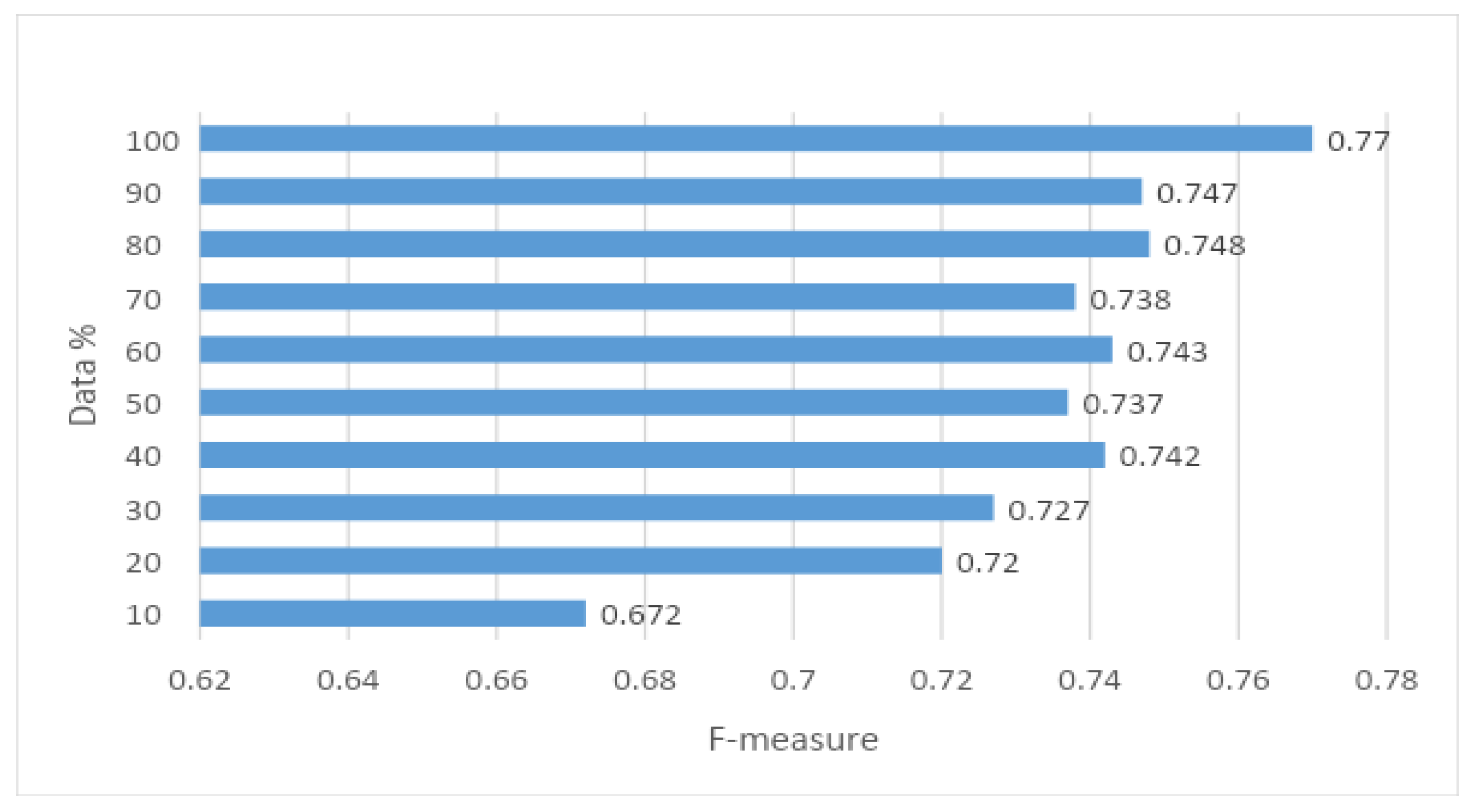
| Percentage | F-measure Bayesian Network (Random Projection) |
|---|---|
| 10 | 0.672 |
| 20 | 0.72 |
| 30 | 0.727 |
| 40 | 0.742 |
| 50 | 0.737 |
| 60 | 0.743 |
| 70 | 0.738 |
| 80 | 0.748 |
| 90 | 0.747 |
| 100 | 0.77 |
| Proposed Approach (BN-RP) | 0.759 |
|---|---|
| Reservoir sampling | 0.751222222 |
| Pure random sampling | 0.749922222 |
| Subset Evaluation | 0.7498 |
| Correlation Evaluation | 0.7392 |
| Gain Ratio Evaluation | 0.735 |
| Info Gain Evaluation | 0.751 |
| OneR Evaluation | 0.7387 |
| Principal Components | 0.753 |
| Relief Evaluation | 0.751 |
| Symmetrical Uncertain. Evaluation | 0.73 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Albattah, W.; Khan, R.U.; Alsharekh, M.F.; Khasawneh, S.F. Feature Selection Techniques for Big Data Analytics. Electronics 2022, 11, 3177. https://doi.org/10.3390/electronics11193177
Albattah W, Khan RU, Alsharekh MF, Khasawneh SF. Feature Selection Techniques for Big Data Analytics. Electronics. 2022; 11(19):3177. https://doi.org/10.3390/electronics11193177
Chicago/Turabian StyleAlbattah, Waleed, Rehan Ullah Khan, Mohammed F. Alsharekh, and Samer F. Khasawneh. 2022. "Feature Selection Techniques for Big Data Analytics" Electronics 11, no. 19: 3177. https://doi.org/10.3390/electronics11193177
APA StyleAlbattah, W., Khan, R. U., Alsharekh, M. F., & Khasawneh, S. F. (2022). Feature Selection Techniques for Big Data Analytics. Electronics, 11(19), 3177. https://doi.org/10.3390/electronics11193177