1. Introduction
With the emergence of large-scale knowledge graphs, such as Freebase [
1], DBpedia [
2], Wikidata [
3], and corresponding question answering datasets [
4,
5], knowledge graph-based question answering (KGQA) technologies have developed rapidly in accuracy and generalization. The goal of KGQA is to find the answer to the given natural language question from a knowledge graph by way of parsing the question or retrieving knowledge graph information. As a bridge between massive data and practical applications, KGQA provides a convenient way to acquire a wealth of knowledge without mastering any structured query statements [
6,
7], which decreases the threshold of knowledge acquisition and accelerates the information construction of society.
The mainstream KGQA methods are divided into two categories: semantic parsing-based (SP-based) methods and information retrieval-based (IR-based) methods [
8]. Specifically, SP-based methods parse a natural language question into a logical form and then convert the logical form into a knowledge graph query statement. For example, Kwiatkowski et al. [
9] utilized a combinatory categorial grammar (CCG) [
10] to parse a sentence, and Liang et al. [
11] employed dependency-based compositional semantics (DCS) to form a syntax tree. Moreover, Yang et al. [
12] utilized the semantic embedding space for encoding the semantics of words and KG properties to alleviate the problem of limited coverage of lexical triggers. Aiming to solve complex questions, Liang et al. [
13] took advantage of neural networks to construct a manager-programmer-computer framework, where a semantic parser can be effectively learned from weak supervision over a large KG, and Yu et al. [
14] proposed a hierarchical recurrent neural network that was enhanced by entity linking, which achieved outstanding performance in relation detection. Furthermore, Tran et al. [
15] proposed a BERT-based sequence-to-sequence model to translate a natural language into a SPARQL query statement. Although specific semantic information in the question can be well-captured in this way, SP-based methods require large-scale annotation data of formal statements and often suffer from a mismatch between sentence grammatical structure and triplet structure in knowledge [
16].
On the other hand, IR-based methods convert the KGQA task into a text-matching task where answers are found by the generation and ranking of candidate paths. To find an inner connection between natural language questions and KG properties, Bordes et al. [
17] presented a model to learn low-dimensional embeddings of words and knowledge graph constituents. Then, the embeddings were used to score natural language questions against candidate answers for the final answers. Moreover, Yao et al. [
18] improved the relation prediction and answer extraction by exploiting an external dataset, ClueWeb. With the popularization and application of deep neural networks, Dong et al. [
19] proposed a multi-column CNN to jointly learn low-dimensional embeddings of entities and relations in the knowledge graph. The model could learn the representations of different aspects of questions with the question-answer pairs as training data. Additionally, Qu et al. [
20] presented a novel neural network-based approach that leveraged the complementary strength of RNN and CNN to capture semantic and literal relevance information, which obtained outstanding results on single-relation question datasets. Yasunaga et al. [
21] utilized pre-trained language models to infer the final answer through neural graph networks, which exhibited capabilities to perform interpretable and structured reasoning, such as handling negation in questions.
Compared with SP-based methods, IR-based methods are relatively convenient in constructing training data and querying for answers [
22]. However, considering the complexity of semantic information contained in natural language questions and the abundance of entities in knowledge graphs, the accuracy and efficiency of IR-based methods in KGQA tasks are required for further improvements. Specifically, traditional IR-based methods construct candidate paths by expanding topic entities or one-hop paths, which may suffer from candidate path explosion and results in a loss of efficiency. Furthermore, as for a text matching task, traditional text matching paradigms have their drawbacks. For example, representation-based models are more advantageous in computation efficiency but lack the ability to capture interactive textual information, and interaction-based models specialize in capturing interactive textual information, but their computation efficiency is unsatisfactory. Therefore, the trade-off between computation efficiency and the ability to capture interactive textual information is an issue worth studying.
To this end, we propose a joint system based on the information retrieval methods to efficiently handle the KGQA tasks. Firstly, three subsystems are elaborately designed to deal with questions with different hops and different counts of entities. To avoid candidate path explosion, one-hop candidate paths are ranked in advance, and the top-K one-hop paths are expanded for the next-hop path generation. In this way, the wrong candidate paths can be eliminated in advance, and the total amount of candidate paths can be limited, which ensures the efficiency of the KGQA system. Secondly, a new text-matching approach is proposed to solve the problem that traditional IR-based methods cannot take account of both computation efficiency and the ability to capture interactive textual information. On the base of a representation-based model, a relation score factor is introduced to capture interactive textual information by calculating the semantic similarity between the relation in candidate paths and the corresponding char string in the question. As a result, the ability to capture interactive textual information is improved, while the advantage of representation-based models in terms of computation efficiency is retained.
The contributions of this paper are as follows:
(1) A joint system based on information retrieval methods is proposed to efficiently solve complex questions such as multi-hop questions and multi-entity questions.
(2) To avoid candidate path explosions, three subsystems are elaborately designed along with a rank and filter strategy. Additionally, a new text-matching method is proposed to improve the system’s ability to capture interactive textual information.
(3) Extensive experiments are conducted on the CCKS2019 CKBQA dataset, and the experimental results demonstrate our method’s improvements in the efficiency and accuracy of complex questions.
2. Materials and Methods
In this section, our approach is described in three aspects according to the process of question answering. Given a natural language question, the goal of KGQA is to find an entity in the knowledge graph as the answer to the given question. Therefore, topic entity recognition is first implemented to establish the connection between the question and the knowledge graph. After the topic entity is located, candidate path generation is employed to retrieve the entities that are related to the given question. Then, by ranking the candidate paths against the given question through three subsystems, the path with the highest similarity to the question is selected as the final path, and the entity that the final path points to is the final answer to the given question. More details about our approach are elaborated in the following.
2.1. Topic Entity Recognition
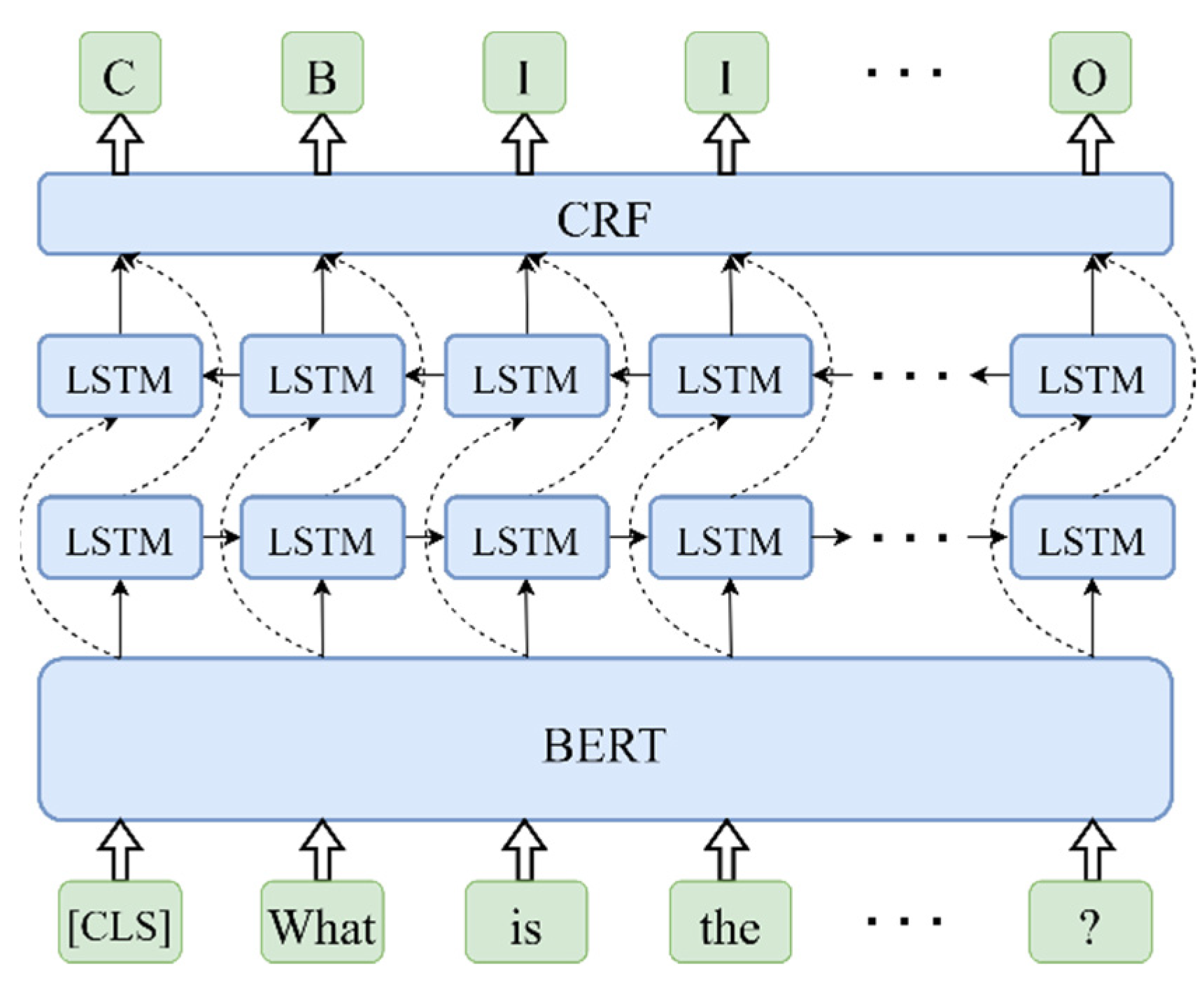
For the given question, topic entity recognition recognizes the subject mentioned in the question by name entity recognition (NER) and locates the corresponding topic entity in the knowledge graph by entity linking. In the NER process, the combination of bidirectional LSTM (BiLSTM) and conditional random field (CRF) has been proven to be a better sequence labeling model in NER tasks than BiLSTM, LSTM, CRF alone or other combinations [
23], and many researchers [
24,
25,
26] also apply it to Chinese NER tasks. Therefore, we chose BiLSTM-CRF to be the sequence labeling model, and BERT [
27] was chosen as the word embedding model to complete the representation of text to embeddings. The architecture of the NER model is shown in
Figure 1, where a special classification token, “CLS,” and the given question are combined and fed into BERT as a char sequence, and the embedding of the final hidden state in BERT that corresponding to the special token is utilized as the aggregate sequence embedding for the given question. Then, the bidirectional LSTM units splice the forward sequence embedding with the backward sequence embedding, and through a full connection layer, the LSTM units output a vector of the same dimension as the size of labels, which is further calculated by a state transition matrix in the CRF layer to predict the tag of the given question. Thanks to a bidirectional LSTM component, the BI-LSTM-CRF model can efficiently utilize both past and future input features, and the CRF layer can use sentence-level tag information, which helps the model to be more independent of word embedding. As a result, the BI-LSTM-CRF model can accurately predict the label of each character in the given question and identifies the subject mentioned as the NER result.
After the subject mention of the question is obtained, entity linking is implemented to link the subject mention to the corresponding topic entity. Considering the polysemy and the textual differences between subject mentions and topic entities, the entity linking process mainly performs text matching tasks. Here, character matching methods like forward maximum matching and backward maximum matching are implemented to match the subject mentioned with the topic entities in the knowledge graph. Meanwhile, an entity linking dictionary is taken as a reference to find the synonyms of the subject mentioned. Finally, a topic entity set is obtained by combining the above two parts.
Table 1 shows the entity linking dictionary, which consists of three parts: the subject mentioned, the corresponding topic entity and their related grade. According to the subject mentioned recognized in the NER stage, the entity linking dictionary is consulted to acquire the corresponding topic entities. Additionally, considering the polysemy in Chinese questions, all the possible topic entities are combined as a topic entity set. Then, the correct topic entity will be further determined by subsequent path ranking.
Take “佛罗伦萨 (Florence)” in
Table 1 as an example; there are three different topic entities corresponding to the same subject mentioned, “佛罗伦萨”, which are an Italian city, a football club and a plant variety. When the correct topic entity refers to an Italian city, the relation in the given question should be related to Italy, scenic spots or other regional-related information. However, if the correct topic entity refers to a plant variety, the relation in the given question should be related to plant traits or price, etc. Therefore, the correct topic entity can be distinguished according to their semantic differences.
2.2. Candidate Path Generation
Candidate path generation is a core procedure for the information retrieval method. Based on the results of topic entity recognition, the topic entities are expanded to construct candidate paths by the candidate path templates. As shown in
Figure 2, there are three types of path templates, which are one-hop path templates, two-hop path templates and multi-entity path templates. All the templates consist of entity nodes and the relation that connects two entities. In specific, “<T>”, “<?>”, and “<E>” are entity nodes that represent the topic entity, the answer entity and the transition entity, respectively, and “r” is the relation that connects two entities. Noting the digraph characteristics of knowledge graph, the candidate path templates in
Figure 2 cover all entities connected to the topic entity within two hops, which is enough to handle most of the questions in the question answering system. Moreover, the two-hop path templates are divided into two types. The first type treats the tail entity as the answer, while the second type treats the transition entity as the answer, which is duplicated with the answer in one-hop paths.
Before the path generation, the knowledge graph data provided by the CCKS2019 official is stored in Jena in the form of triples. To construct the candidate paths, we query the knowledge graph in Jena by the topic entity, which is “<T>” in
Figure 2, and Jena returns relative triples that contain the topic entity. We replace the underlying answer entity with “<?>” and combine the triple together as the candidate path. Considering the massive amounts of candidate paths, the ranking process will be unsustainable if the above candidate paths are all ranked together. Hence, three types of candidate paths are generated in sequence by taking Beam Search as a reference. Specifically, one-hop paths are generated in the first place, which are ranked in subsystem 1, and the top-
paths with the highest score are expanded for the two-hop paths and multi-entity paths. In this way, the wrong paths can be eliminated in advance, which effectively reduces the computation cost of the subsequent path ranking. Here, the threshold value
is a crucial parameter. For instance, a small
may lead to a decrease in the accuracy for deleting the correct one-hop path in advance, while a large
will cause path explosion due to the increase in candidate paths, reducing the efficiency of the system.
2.3. Candidate Path Ranking
Efficiency is an important indicator of a system’s performance, and predecessors [
28,
29] have done a lot of optimization to improve efficiency. In this section, three subsystems are constructed to rank the above candidate paths to improve the computation efficiency. In specific, subsystem 1 is designed for one-hop path ranking, where the candidate one-hop paths will be ranked against the given question, and the top-
paths will be expanded for the generation of two-hop paths and multi-entity paths. Two-hop paths and multi-entity paths will be ranked in subsystem 2 and subsystem 3. Meanwhile, cosine similarity is used as the semantic similarity of the candidate paths and the given question in the ranking process, and a representation-based BERT model is employed as the basic semantic similarity model in our subsystems. Compared with interaction-based models, representation-based models are more advantageous in computation speed. Thus, they are more suitable for the KGQA tasks.
As shown in
Figure 3, we utilize the representation-based BERT model to be our semantic similarity model, which takes BERT as the encoder to encode the candidate path and the given question, and the embedding of the first position in the last hidden state layer is taken as the embedding of the input text. Then, the cosine similarity of the path embedding and the question embedding is calculated as their semantic similarity score. Although representation-based models are superior in computation efficiency, they lack the ability to capture interactive textual information between the input texts. Therefore, a novel text matching method is proposed, where the representation-based BERT model is utilized to calculate the global semantic information and the interactive textual information simultaneously. In specific, the representation-based BERT model outputs the global semantic information when we take the given question and the candidate paths as the input. The goal of interactive textual information is to detect whether the relation in a candidate path is presented in the given question. Algorithm 1 shows the detail in calculating the interactive textual information.
| Algorithm 1: The calculation method of interactive textual information |
| Input: The relation of the candidate path R, the given question Q; |
| Output: The interactive textual information between the candidate path and the given question M; |
| Variables: The character length of the relation L; |
Define a sliding window W in length L + 1 and a candidate pool P; forslide from. begin() to . end() do Add the char string in the window to ; Calculate the path score between the char string and the relation R by Equation (3); end return the highest score in step 4 as ;
|
It is worth noting that M is a value between 0 and 1; the closer M is to 1, the more likely it is that the relation in this candidate path appears in the given question, which indicates a higher relevance between the candidate path and the given question. Next, we will elaborate on the candidate path ranking in detail from the aspect of three subsystems.
2.3.1. Subsystem 1
In subsystem 1, the global semantic information and the interactive textual information of the candidate one-hop path are calculated by the path score and the relation score. Specifically, the path score consists of text similarity and semantic similarity, where text similarity is the Jaccard similarity, and the semantic similarity is calculated by our semantic similarity model. Additionally, the relation score contains the interactive textual information described in Algorithm 1 and a distance factor. Next, we will describe the calculation of these scores in detail.
- (1)
The path score
In the process of calculating text similarity, the characters that appear in the candidate paths and the given question are counted first. Let
be the set of characters in the candidate path and
be the set of characters in the given question. The text similarity is the ratio of the cardinality in the intersection set between
and
divided by the cardinality in the union set between
and
. The equation of text similarity
is shown as follows:
where
is the character set of the -th candidate path, while is the character set of the given question. The
operation is the cardinality in the intersection set or the union set.
Additionally, the semantic similarity is obtained from the representation-based BERT model, where the given question and the candidate path are converted into vectors, and then cosine similarity is applied to measure the similarity. The semantic similarity
is calculated as follows:
where
and
are the embeddings of the given question and the
-th candidate path.
represents the cosine similarity operation.
Then, the path score
is calculated by a linear combination of text similarity
and semantic similarity
.
where
is introduced as a hyper-parameter to adjust the effect of text similarity and semantic similarity on the final path score.
- (2)
The relation score
To capture the textual interactive information between candidate paths and the given question, the calculation method in Algorithm 1 is employed in the relation score. Moreover, considering the Chinese language rule that the first-hop relation is normally closer to the subject mentioned than the second-hop relation, a distance factor is introduced to the relation score. Firstly, the distance between the relation and the subject mentioned is calculated, and then by operating on an exponent, the distance factor is integrated into the interactive textual information. The relation score
is calculated as follows:
where
is the interactive textual information calculated by the method in Algorithm 1,
and
are the positions of the relation and the subject mentioned in the given question. With a hyper-parameter
and a natural number
as the base to adjust the proportion of the distance factor in the relation score, the interactive textual information that is ignored by the global semantic information is acquired by the relation score.
- (3)
The final score
Finally, by a linear combination of the path score and the relation score, the final score
for ranking candidate one-hop paths is obtained by the following equation.
where
and
are the path score and the relation score, and
is a hyper-parameter.
All the candidate one-hop paths are ranked in this subsystem, and the path with the highest score is chosen as the output of subsystem 1. In the meantime, top- candidate paths with the highest score are stored for the generation of candidate two-hop paths.
2.3.2. Subsystem 2
Subsystem 2 is designed for the rank of candidate two-hop paths, and the path score along with the relation score are employed to rank candidate paths. However, considering the texture complexity in the two-hop paths, a tail entity factor is introduced to replace the distance factor in the relation score. As a result, the path score in subsystem 2 is the same as that in subsystem 1, while the relation score contains the interactive textual information of the relations in the candidate path and a tail entity factor. The specific calculation equation of the relation score
is shown as follows:
where
and
are the textual interactive information of the one-hop relation and two-hop relation in the candidate path calculated by the method in Algorithm 1, and
is the tail entity factor that represents the text similarity score of the tail entity in the
-th candidate two-hop path and the given question.
is utilized as a hyper-parameter to adjust the proportion of the text similarity.
As mentioned above, the candidate two-hop paths are divided into two types. The main difference between those two types is whether the tail entity appears in the candidate path. To be specific, the Type 1 candidate path chooses the tail entity as the answer entity; thus the tail entity is replaced by a placeholder. Conversely, the transition entity is chosen as the answer entity in the Type 2 candidate path; therefore, the tail entity can be detected in the candidate path. In this case, the tail entity factor can help to distinguish these two types of candidate two-hop paths.
Unlike subsystem 1, the path score and the relation score are employed in sequence rather than being combined in a linear way. Due to the candidate two-hop paths being expanded from the candidate one-hop paths, the amount of candidate two-hop paths is too large to be ranked at once. Therefore, the path score is employed first to rank the candidate two-hop paths, and top- paths with the highest score are then ranked by the relation score. Finally, the path with the highest relation score is the answer of subsystem 2.
2.3.3. Subsystem 3
Subsystem 3 is built for a particular case of questions that contains two or more subject mentions in the given question. To take advantage of the connection between the entities that appear in the same question, paths that share a common entity are picked out first, and then the path score is utilized to rank those paths to get the final answer.
Figure 4 shows the workflow of subsystem 3. After the topic entities are acquired from topic entity recognition, the candidate one-hop paths of each topic entity are generated in the first place. On the one hand, a common entity is searched among all the candidate one-hop paths of different topic entities. If two different paths share the same entity, they will be combined as one candidate path and added to the candidate paths pool. On the other hand, the candidate one-hop paths of different topic entities are inputted to subsystem 1 to select the top-
paths for the generation of candidate two-hop paths. Then, a common entity is searched among all the candidate two-hop paths as well, and the paths that share the same entity will be combined and added to the candidate paths pool. At last, the path score
is employed to rank the paths in the candidate path pool, and the path with the highest path score is chosen as the output of subsystem 3. However, noting that this subsystem is built for a special case, the answer in subsystem 3 may not exist if the given question contains only one subject mentioned.
2.3.4. Path Fusion
As mentioned above, there are two or three answers obtained by our three subsystems, but only one answer can be used as the prediction for our joint system. Therefore, a path fusion procedure is proposed to determine the final answer.
As shown in
Figure 5, the output of subsystem 3 has the highest priority to be the final answer, but considering the case that subsystem 3 does not have an answer, the path score and relation score are utilized to rank the answers from subsystem 1 and subsystem 2. The path score
is the same as in subsystem 1, while the relation score only contains the interactive textual information. The equation of the relation score
is shown as follows:
where
is the textual interactive information of the
-th relation in the
-th candidate path, and variable
is taken as the label to distinguish the candidate one-hop path and the candidate two-hop path. In specific,
represents the relation score of the one-hop path, and
represents the relation score of the two-hop path. Finally, the final score
is obtained by a linear combination of the path score
and the relation score
.
where
is the same hyper-parameter as in subsystem 1.
In the path fusion stage, the final answer is chosen from the output of the above subsystems. Reviewing the candidate path ranking procedures in the subsystems and the path fusion stage, the path score and the relation score are the most important measurements, where the path score represents the global semantic similarity between the candidate path and the given question, and the relation score reveals subtle textual interactive information.
3. Results
In this section, the experiments are introduced from three aspects. Firstly, the dataset of CCKS 2019 that is used in our experiments is explained. Secondly, the experimental setup is described in detail, which includes the evaluation metrics and the experimental environment settings. At last, the superiority of the proposed method is verified by analyzing the experimental results and comparing them with others.
3.1. Dataset
The dataset that was used in our experiments was published by the China Conference on Knowledge Graph and Semantic Computing in 2019. The Computer Technology Research Institute of Peking University provided 3000 open-domain question-answer pairs, and Hundsun Technologies Incorporated provided an extra 1000 financial-domain question-answer pairs. Three parts were split from this dataset: the training set contained 2298 samples, and both the validation set and test set contained 766 samples. As for the complexity of the questions, the dataset contains both complex questions and simple questions in a ratio of 1:1. A triplet file provided by the competition official is utilized to construct the knowledge graph, which contains about 41,007,385 triplets. Furthermore, the competition official also offers a mention-entity file (entity linking dictionary) that contains 13,930,029 samples and an entity-type file that contains 25,182,627 samples.
3.2. Experimental Setup
In our experiments, macro precision, macro recall and average F
1 score are utilized to evaluate the performance of our joint system. Macro precision and macro recall are the averages of the accuracy and recall of all individual questions, and the average F1 score is the average of the F
1 score of all individual questions. The details of each evaluation metric are shown in Equations (9)–(11).
here,
is the predicted answer to the
-th question,
is the gold answer of the
-th question, and
is the number of questions.
In the aspect of experimental environments, PyTorch is utilized as the framework of our experiments, and Adam is employed as the optimizer. Moreover, we employ an early stopping paradigm [
30] to retrieve the model with a maximum validation F1 score. The hardware and software environments are shown in
Table 2.
3.3. Training Details
As shown in
Table 3, the CCKS2019 dataset provides three types of information: a natural language question, the corresponding SPARQL query statement and the answer to the question. Firstly, we tagged the question based on the topic entity that appeared in the SPARQL query statement to generate the training set for the NER model. To better adapt to the Chinese language environment, we took Bert-Base-Chinese as the pre-trained language model, which was also utilized in the representation-based BERT model during the candidate path ranking stage. After being finetuned in the training set, the BERT-BiLSTM-CRF model was applicable to tagging the inputted texts to find the subject mentions. Meanwhile, according to the topic entity that appeared in the SPARQL query statement, we constructed the training set of candidate paths by querying the knowledge graph to train the representation-based BERT model. Considering that the traditional learning method can easily cause classification overfitting in a limited training set [
31], the training data were constructed by a dynamic sampling of negative examples method proposed by Wu [
32]. Specifically, for every positive example in the training set, we constructed a negative example pool to generate enough negative examples for the model training, which enriches the relations in the training set and helps to improve the performance of the semantic similarity model.
3.4. Results and Analysis
To verify the effectiveness of our method, four experiments were conducted here. Firstly, the influence of the variable on the performance in the final system was measured by macro precision, macro recall and average F1 score. Then, the effect of the relation score in the subsystems and path fusion stage was analyzed in the second part. Thirdly, an ablation study was conducted to verify the effectiveness of the relation score on the performance of our final joint system. At last, a case study was employed to illustrate the workflow of our joint system.
3.4.1. The Variable in Subsystem 1
At the end of subsystem 1, top- candidate paths with the highest score were expanded for the generation of two-hop paths. The variable determines whether the correct one-hop path can be preserved until the next hop or be deleted in advance and thus reducing the accuracy of the final system. On the other hand, also determines the number of candidate paths for the next hop, which affects the efficiency of the system.
As shown in
Figure 6, the performance of the joint system rises with the increase in
, but the computation efficiency is decreased since the amount of candidate two-hop paths grows exponentially. Therefore, we took 5 as the value of
to be the experimental parameter to balance the performance and the computation efficiency, where the joint system achieves an average F1 score of 74.2. Additionally, the computation cost, in this case, was less than half of that in the case when
equals 10.
3.4.2. The Relation Score and Subsystems
The performances of individual subsystems were tested to verify the impact of the relation score. As shown in
Figure 7a,c, the relation score improves the performance in all three evaluation metrics, which means the relation score is helpful to subsystem 1 and path fusion. However, the data in
Figure 7b shows the opposite result.
Therefore, we analyzed the types of prediction paths of subsystem 2, and
Figure 8 shows the difference in the proportion of each type in all predicted paths.
Figure 8a,b describes the ratio of two different types of two-hop paths predicted by subsystem 2. As shown in
Figure 8a, the Type 1 two-hop path accounts for 83.42% of the total predicted paths when ranking with the relation score, and the ratio drops to 50.52% when ranking without the relation score. Noting that the answer of the Type 2 two-hop path is duplicated with the prediction of subsystem 1, the increase in the proportion in the second type of two-hop paths would improve the accuracy of the prediction in subsystem 2, which explains the abnormality in
Figure 7b. In fact, subsystem 2 ought to make the prediction from a different aspect than subsystem 1 to improve the generalization of the joint system, which demands it to pay more attention to the first type.
3.4.3. Ablation Study
To verify the effectiveness of the relation score on the whole system, an ablation study was conducted by testing the performance of our joint system when ranking with/without the relation score, and
Table 4 shows the results of the ablation study in the average F1 score.
As shown in
Table 4, our joint system achieves an average F1 score of 71.72 when the relation score is excluded in all subsystems, and with the relation score combined with subsystem 1, the average F1 score is improved by 0.33. Moreover, after combining subsystem 2 and path fusion with the relation score, the performance of the joint system is further improved, achieving an average F1 score of 72.57 and 73.37, respectively. With the relation score applied in all subsystems, the joint system achieves the highest average F1 score of 74.2. This demonstrates the effectiveness of the relation score in improving the performance of the joint system.
Moreover, our experimental results were compared with other researchers who also utilize CCKS2019 CKBQA dataset as the experimental dataset, including the winning teams in the CCKS2019 competition. The average F1 score was utilized as the evaluation standard for the competition. Comparison results are shown in
Table 5.
Compared with the CCKS2019 winning teams’ works in
Table 5, our approach does not rely on any additional data or hand-crafted rules, three subsystems are designed to handle different types of questions, and the combination of the path score and the relation score can accurately find the most similar path to the question. Additionally, our work is a modification of Wu’s research, which took BERT-BiLSTM as the NER model and a representation-based BERT model as the semantic similarity model. We optimized the NER process by adding the CRF layer and improved the accuracy of the path ranking process by dispersing questions into three subsystems and introducing a relation score factor. The relation factor makes up for the shortcoming that the representation-based models cannot capture the interactive textual information, which leads to an enhanced performance of the question-answering system. Finally, our joint system achieves an average F1 score of 74.20 and surpasses the best team in the competition.
3.4.4. Case Study
In this section, the question “薛宝钗的哥哥外号叫什么?” (What’s the nickname of Xue Baochai’s brother?) is taken as an example to illustrate the workflow of our joint system.
As shown in
Figure 9, topic entity recognition is first performed for the given question, which contains NER and entity linking. The commonality between the NER result and the topic entity simplifies the entity-linking process. Then, subsystem 1 expands the topic entity to generate candidate one-hop paths and ranks these paths by the path score and the relation score. From the result of path ranking in subsystem 1, the correct one-hop path ranks only fifth here, but with the help of subsystem 2, the generation and ranking of candidate two-hop paths reveal the final correct path. In specific, the path score and relation score are successively utilized to rank the candidate two-hop paths in subsystem 2, and the path with the highest score along with the output path of subsystem 1 is input to the path fusion for the final answer. It is worth noting that subsystem 3 is not utilized here since there is only one topic entity recognized from the given question. Finally, the combination of the path score and relation score finds the path that is most similar to the given question in the path fusion stage. Here, the path “<薛宝钗>-<妹妹>-<别名>-<E>”(<Xue Baochai>-<Sister>-<E>) beats other paths at last, and the entity “<呆霸王>”(Dai Bawang) of the winner path is the predicted answer of our joint system.
4. Discussion
The core idea of information retrieval-based methods is to transform the KGQA task into a text matching task, which stresses the importance of the text matching model. There are two kinds of mainstream text-matching models, interaction-based models and representation-based models. In the interaction-based models, two texts are entered into the encoder together, which allows them to exchange information during the process of encoding; then, the encoder output the final result. The representation-based models utilize one encoder to encode two texts and then calculate the final result according to the output of the encoder. Compared with each other, the interaction-based models are advantageous in the accuracy of the text matching result, but the representation-based model has a huge advantage in computation efficiency. Considering the real application scenario of the question-answering system, the impact of computing speed on user experience is significant, which is why we chose a representation-based model for the text matching task, and the relation score factor was designed to improve the performance of the question-answering system.
However, there are still limitations to our proposed method. The main question is that there are a few types of natural language questions that cannot be answered properly by our joint system. As shown in
Figure 2, path templates are utilized to generate candidate paths. We assume that only one candidate path points to the correct answer, but under some special circumstances, the answer to the given question may contain multiple entities, which corresponds to multiple candidate paths. This results in our joint system not being able to answer the question completely, which is the direction of our future work.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}