1. Introduction
Internet technology, particularly the World Wide Web, has advanced at an astounding rate. With this upgrade, there are new resources on the internet, such as documents, news, or articles to read, movies to stream, or items to purchase. Nowadays, the exponential growth of e-commerce websites and the advancement of the Internet of Things have made it difficult for shoppers to select correctly from the vast amount of offerings sold by these websites. People implicitly benefit from the features of recommender systems [
1].
In this day and age of the information overload, it is quite difficult for users to find content that they are truly interested in. Users base their arguments on which movies to watch on their content, whether expressed in the form of communications data (genre, cast, or story-line) [
2] or the feeling experienced after watching the corresponding movie trailer [
3]. The media content has a significant impact on consumers’ emotional affinity with the movie [
4].
Many of the most extensive commerce platforms, such as Amazon.com, have also been using recommender services to help their clients look for things they want to buy. Many of the world’s leading sites, such as Netflix, have long used recommender services to help their users decide which movies to stream based on their personal preferences [
5]. These programs provide search results that are customized to the user’s preferences. When people visit a website, they are usually searching for things that are of interest to them. These things of interest may include a variety of topics. A recommender framework can also provide users with relevant knowledge about the items they are interested in. The ability to react quickly to changes in user preferences is a valuable advantage for such programs.
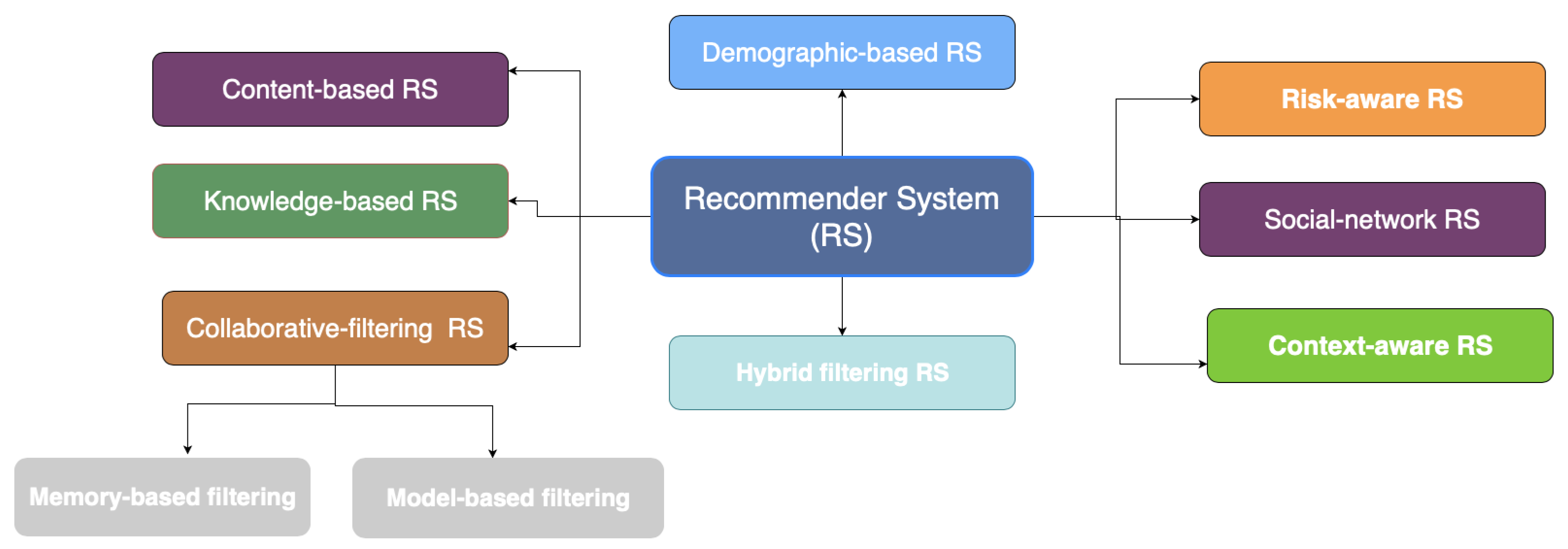
A recommender system is a processing method that measures the likelihood of a particular item being chosen by a specific person. The recommendation approaches are divided into eight categories as mentioned on
Figure 1 based on how the recommendation is generated [
6]: a collaborative filtering system, a content-based filtering system, a hybrid filtering system, a demographic recommender system, a knowledge-based recommender system, a risk-aware recommender system, a social network recommender system, and a context-aware recommender system.
A content-based recommender system creates a user profile by evaluating the characteristics of specific items to predict and produce recommendations [
7]. As a result, the suggested objects are typically identical to items that the customer already enjoyed [
8]. Collaborative filtering (CF) is a tool that focuses on user views being expressed. It is based on the “word of mouth” principle, which humans have historically used to shape an opinion about a good or service about which they are unfamiliar. The basic principle of this methodology is that the views of other users should be used to make a reasonable estimation of an active user’s interest in a non-ranked object [
3]. These methods presume that if users have similar preferences for a set of products, they are likely to have similar preferences for other things they have not yet rated. To produce recommendations, CF employs two distinct mechanisms: memory-based CF and model-based CF. The combination between these two precedent techniques generates the hybrid filtering approach [
9]. A risk-aware recommendation system is one that is aimed at preventing and forecasting risks associated with an activity. The demographic-based technique implies that consumers with similar demographic profiles (e.g., age, gender, and country) would have similar interests. As a result, this recommendation system predicts various things based on demographic status. The knowledge-based recommendation system refers to a form of recommender system that is based on explicit knowledge about user preferences and recommendation criteria, such as which item should be recommended in which context. Social network recommender systems are characterized as a combination of social network data that can influence personal behavior and tag data [
10]. Context-aware recommendations make use of contextual information in novel ways, such as user behavior, changing weather conditions, and cultural habits.
The content-based recommendation system lacks a critical tool for investigating anything unexpected. The system will recommend only objects with a high score as compared to the user profile. It is also known as the serendipity challenge, and it illustrates the limit of content-based advice, i.e., the over-specialization problem [
11]. A “great” content-based methodology would hardly provide anything novel, narrowing the variety of uses in which it would be helpful.
In that context, our focus in this research is on using a genetic algorithm to refine recommendations, add variety, and suggest new things that the user would enjoy. The contributions of this paper include developing a novel genetic algorithm for a content-based recommendation system that aims to select new items that the user will enjoy more. The genetic algorithm (GA) has been used to find the best suggestion list for a single individual based on their preferences. The proposed can solve the major challenge of content-based filtering, which is over-specialization and the limited content problems.
In this work, we attempt to fill several gaps. We present several contributions, including the following:
We introduce the drawback of content-based recommender systems, especially the over-specialization problem.
We provide an overview of genetic algorithms and their use in recommender systems.
We propose a novel Revolutionary Recommender System based on a Genetic Algorithm called that refers to using genetic algorithms to mitigate the limited content recommended to the user.
We aim to demonstrate how genetic algorithms can brings diversity to recommendations being made.
The rest of this article is categorized in the following way:
Section 2 contains our literature review about genetic algorithms and content-based filtering. We discuss our related works in
Section 3. The proposed suggestion method,
, is seen and described in
Section 4.
Section 5 focuses on the testing of
and the analysis of the findings. We mention the discussion of our work in
Section 6. Finally,
Section 7 and
Section 8 bring the article to a close and discusses possible further research.
2. Literature Review
This study focuses on a genetic algorithm-based recommendation method [
12] that addresses the issue of over-specialization in content-based algorithms. This literature review aims to provide a summary of the previous research in the subject fields. Recommender systems enable the task of recommending or exposing new and current products to a customer who has never seen them before. Recommender systems use a variety of algorithms and techniques to produce suggestions. The most common systems are collaborative filtering [
13], which considers other users in the scheme [
14], and content-based filtering, which focuses solely on the content. This literature review aims to provide an overview of previous research in these subject fields.
This literature review can broadly be divided into the following categories:
Section 2.1 Content-Based Filtering,
Section 2.2 Content-Based Filtering Limitations, and
Section 2.3 Theoretical Background of Genetic Algorithms.
2.1. Content-Based Filtering
The system learns to make recommendations by analyzing the similarity of features between items [
15]. For example, based on a user’s rating of different movie genres, the system will learn to recommend the genre that is positively rated by the user [
8]. A content-based recommendation system builds a user profile based on the user’s previous ratings. A user profile represents the user’s interests and can adapt to new interests [
4,
5].
Information retrieval, analysis, and filtering are the foundations of the content-based filtering approach [
16]. This method is most often used in areas where content can be read or analyzed, such as news articles, movies, and everything else containing metadata. It also makes suggestions based on what the user has already seen. Labels may be used to classify the contents, and each label is assigned a weight based on how well it describes the article. Nearest-neighbor or clustering algorithms may be used to suggest other articles to the active user based on these labels and user expectations. This system, however, is challenged by new users with limited knowledge and a limited number of labels.
2.2. Content-Based Filtering Limitations
The content-based filtering strategy is most commonly utilized in situations where material can be read or examined, such as news articles, movies, and anything else containing metadata. It also makes suggestions depending on what the user has already watched. Labels can be used to describe the contents, and each label is assigned a weight based on how effectively it describes the item. Nearest-neighbor or clustering algorithms can be used to propose other articles to the active user based on these labels and user preferences. This strategy, however, is challenged by new users who have minimal information and a restricted number of labels. The content-based recommender system has solved the challenges of collaborative systems, but it has some drawbacks, including:
Limited Content: Content-based techniques have a limit on the quantity and kind of characteristics shared with items that they propose manually or automatically. Domain expertise and taxonomies for the specific domain are also required. If the evaluated content lacks sufficient information, the content-based recommender system will be unable to make appropriate suggestions.
Lack of Serendipity: In a content-based recommendation system, there is no crucial technique for discovering anything unexpected. Goods are advised based on their high score while matching the user profile; as a result, the user suggests items that are comparable to previously rated items. This is also known as the over-specialization problem, and it highlights the tendency of content-based systems to offer ideas with a limited degree of inventiveness. To find some innovative and surprising recommendations, a great content-based approach is required.
Over-Specialization: A content-based recommendation system lacks a necessary approach for investigating anything unexpected. Only goods with a high score when compared to the user profile can be recommended by the system. It is also known as the serendipity issue, because it illustrates the limit of content-based suggestions. A “perfect” content-based method would offer little new content, limiting the variety of applications for which it would be useful.
New User: A significant number of ratings must be collected in order to create a recommendation system that can learn about user preferences. Due to the fact that no previous data is available, the system is unable to make trustworthy suggestions to new users.
2.3. Theoretical Background og Genetic Algorithms
2.3.1. Principles: Definition and Vocabulary
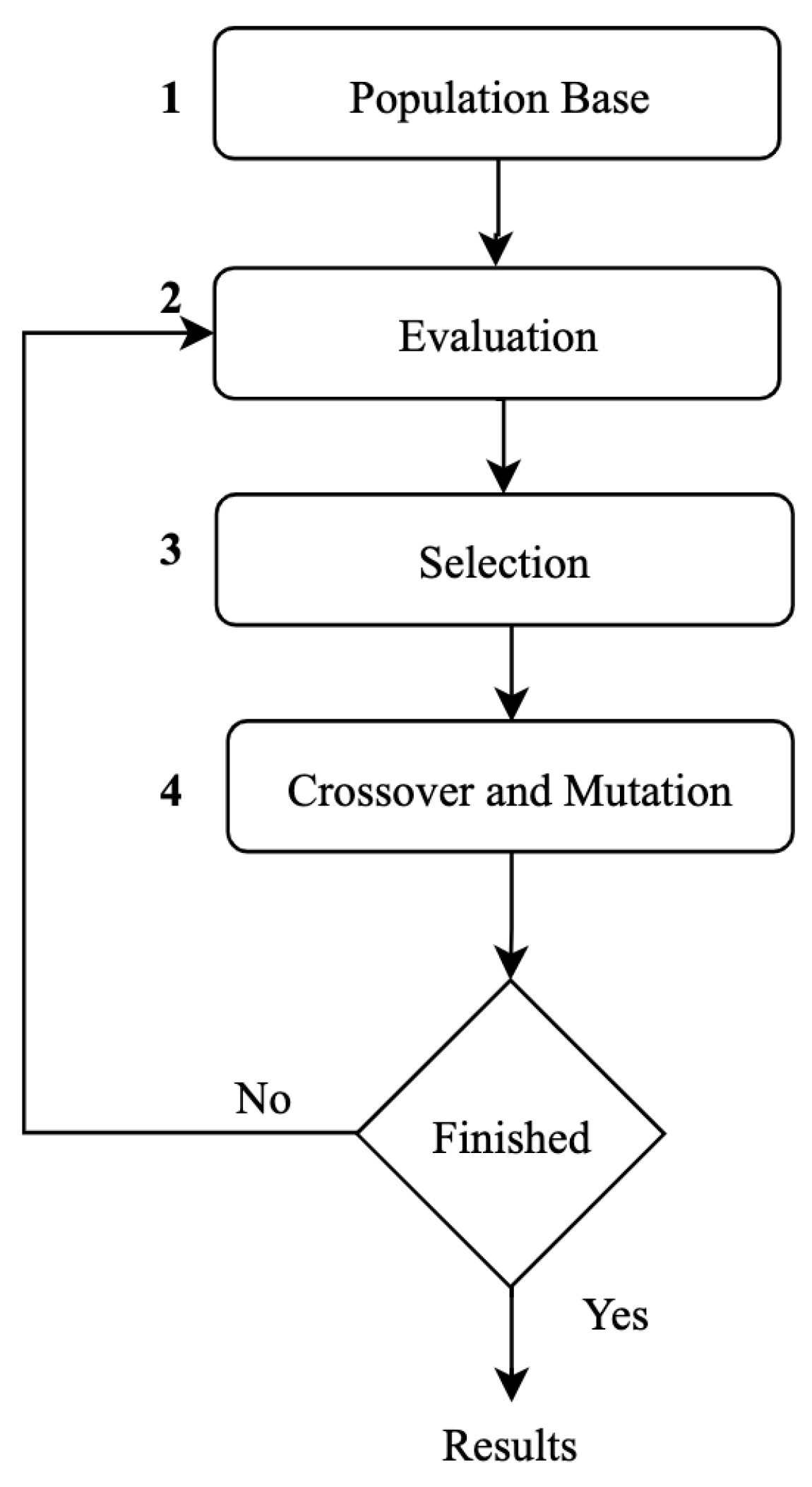
A genetic algorithm attempts to answer the challenge of how a computer can solve a problem without being explicitly told how to solve it. Genetic algorithms attempt to bring ideas from evolution and natural genetics to computers. The goal of genetic algorithms is to construct computer programs that model and reproduce the evolutionary process of nature. Genetic algorithms solve an optimization issue by converting a population of alternative solutions. The algorithms operate on the properties of the issue rather than the problem itself. The values of the solutions are compared, and the greater the value, the more likely that solution is to advance to the next level.
Genetic algorithms do not employ variables but rather associate them with a specific coding; variables are considered using characters representing a sequence of codes. Each variable is converted into a gene, which can include one or more codes that can express various characteristics. An individual is represented by the code sequence. In other words, a chromosome is a possible solution. The goal of the treated problem is described using a function that permits assessing the likelihood that an individual will be picked or not in order to recreate new solutions. The fitness function is the name of this function. Limitations are considered in the fitness function by punishing people who disobey the problem’s constraints. The exploration of the space of potential solutions is based on two techniques that aim to create new solutions at random from the beginning population. The genetic operators consist of crossing and mutation mechanisms. The selection process aims to guide the investigation by identifying the individuals who have the best chance of getting selected.
In order to explain how genetic algorithms work,
Figure 2 presents the different steps of a simple genetic algorithm.
2.3.2. Initial Population
Any genetic algorithm [
17] is built around a solution represented by its chromosomes [
18] which are then passed on to their offspring [
19]. In GAs [
20], it is common to represent each solution with a binary string [
21]. Each bit indicates whether the solution has a particular characteristic or not and uses numbers to denote the strength of a function in a solution. Using numbers rather than single bits to show the existence of a feature has the advantage of allowing one to identify a solution as being better than others by using more than just the feature’s presence.
In Equation (
1) we present a possible solution by describing the strengths of each feature. The solution contains five genes, each one represents a specific movie.
2.3.3. Fitness Function
The fitness function is a function that assigns a score to a given individual. We found that an individual with a high chance of being closest to the perfect solution will receive a higher score than others [
22]. In GA, the fitness function is crucial, because it determines whether a solution is successful or not, and a poorly constructed fitness function can result in less-than-ideal solutions.
In fitness algorithms, utility functions or simple mathematical functions, such as number and average, can be used. Utility functions measure the importance of something to an individual, rather than just plugging it into an algorithm.
2.3.4. Genetic Algorithm Operators
Crossover, mutation, and selection are the three operators that make up a genetic algorithm. Each operator has a distinct and equally essential function to play.
Crossover
Crossover is a technique for changing chromosome programming from one generation to the next by producing children or offspring. These offspring are generated using parent chromosomes (generated chromosomes). There are many methods for producing offspring, including a single-point crossover operator, a multi-point crossover operator, and a uniform crossover operator:
Single-point crossover: A crossover point is created at random in a single-point crossover, determining how parents share information to form children. The crossover point is 2.
Multi-point crossover: Multiple crossover points are randomly generated in a multi-point crossover, determining the points for knowledge sharing between parents to form children. As a consequence, information is exchanged between the crossover points.
Uniform crossover operator: Knowledge is exchanged between parents in the uniform crossover depending on specific probability values. A probability matrix of the same length as the parents is created at random. If the probability value at one or more of the indexes approaches a predefined threshold, knowledge is shared between parents at such indexes to form children.
Mutation
In the genetic algorithm, the mutation operator is a widespread technique. Using hybridization, it has made its way into other heuristic and meta-heuristic strategies. Its potential to bypass local optima and seek a larger solution area is the main reason for this.
Random Mutation: Random numbers are used to modify genes on a chromosome at one or more positions.
Flip Mutation: The maximum values of all genes are used to modify genes from a chromosome at all positions. The maximum value for a binary chromosome is 1.
Bit-String Mutation: This is a flip mutation variation in which random numbers calculate gene alteration for one or more roles.
Boundary Mutation: If the value of a gene falls below the given lower bound or exceeds the given upper bound, the gene is updated.
Swap Mutation: Two genes on the same chromosome switch positions, i.e., gene values are swapped.
Inverse Mutation: This is a swap mutation variant. Genes that are equally spaced around the middle of a chromosome are exchanged, causing the chromosome to reverse.
Insert Mutation: A chromosome gene is cropped from one location and inserted into another. Alternatively, more than one gene may be cropped at various locations and placed at a different location.
Shift Mutation: By transferring genes to the left or right N times, one or more genes on a chromosome are changed.
Increment or Decrement Mutation: The values of genes on a chromosome can be changed using ratios to increase or decrease their values.
Selection
Selection determines which individuals between the old and offspring populations will form the next population, which will be used for crossover and mutation to create the next generation of offspring. The selection operator represents the main pillar of genetic algorithms. There are many methods use to describe the selection step: elitist selection, random selection, and tournament selection.
Elitist selection: This is a selection method that only selects individuals with the best (highest) fitness values. A small number of individuals with the highest fitness values is chosen to pass on to the next generation while avoiding the crossover and mutation operators. Elitism avoids the random elimination of individuals with good genetics by crossover or mutation operators. The population should not have too many elite individuals, or else the population will tend to degenerate.
Random selection: This method combines the populations and randomly chooses N item to obtain the new population. Tournament selection is also a popular literary technique since it may function with negative fitness values.
Tournament selection: Tournament selection is a selection strategy used in a genetic algorithm to choose the fittest candidates from the current generation. These chosen candidates are then handed on to the following generation. K individuals are chosen and a competition is run among them in a K-way tournament selection. Only the fittest candidate among those selected is picked and handed down to the next generation.
4. Proposed Approach
4.1. Over-Specialization Problem
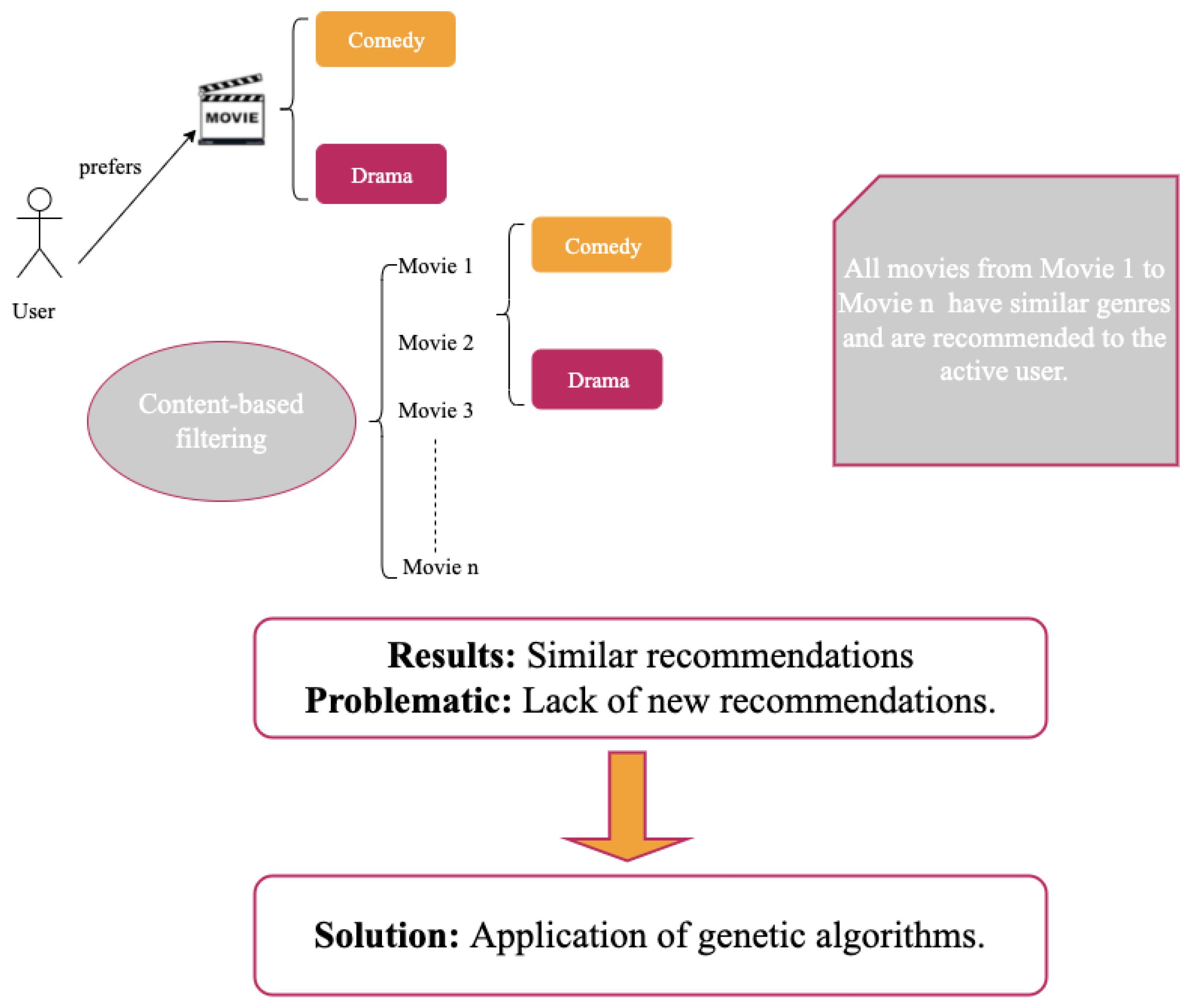
All recommendation systems will inevitably face the over-specialization problem. The over-specialization issue is described as having restricted content and producing suggestions with a low level of novelty and a lack of a method for discovering something unexpected to recommend to the user. When a user likes a new object, the algorithm only recommends related things that the user has already enjoyed as illustrated in
Figure 3.
The content-based filtering algorithm has no built-in mechanism for discovering anything unpredictable, which gives rise to the over-specialization problem. Compared to the user’s profile, the algorithm recommends objects with high ratings, implying that the user would be offered items that are close to those that have already been scored.
This limitation is also known as the serendipity issue, and it refers to the inability of content-based systems to generate suggestions with a low level of novelty. For example, if a user has only rated Stanley Kubrick films, only such films would be recommended. A “great” content-based approach will hardly discover something different, limiting the number of applications it could be used for.
Content-based systems suffer from the over-specialization problem, because they only suggest products close to those that users have already scored. The implementation of any randomness may be one solution to this problem [
30]. Furthermore, over-specialization is not simply the problem that content-based programs cannot suggest things that are not similar to what the user has already seen. Things that are very close to what the user has already encountered, such as a separate news reports explaining the same incident, should not be suggested in certain situations.
Serendipity in a recommender system is the idea of getting an unlikely and serendipitous article recommendation. It is a way to diversify recommendations [
16]. Although people depend on chance and experimentation to discover new articles they did not know they needed, content-based programs lack an essential method of delivering serendipitous suggestions due to over-specialization. In conclusion, the adoption of strategies for realizing operational serendipity is an effective way to extend the capabilities of content-based recommender systems to mitigate the over-specialization problem by providing the user with surprising suggestions.
On the one hand, limited content analysis indicates that the system can only provide a small amount of knowledge about its users or the content of its products. On the other hand, over-specialization results from the way content-based programs recommend new items. A user’s expected ranking for an item is high if the item is close to the ones the user enjoys. For example, in a movie suggestion system, the system may suggest a movie to a user in the same genre or that stars the same actors as ones that the user has already seen. As a result, the system can miss out on unique and attractive objects to the user.
In that regard, our aim in this study is to use an optimization method, especially the genetic algorithm in content-based filtering, to achieve the aforementioned aim. A genetic algorithm aims to solve how a machine can solve a problem without being specifically told how to solve it. Genetic algorithms try to apply biology and natural genetics to programming. This encourages one to let genetic programming build the framework to solve the problem rather than specifying it.
Genetic algorithms work similarly to genetic programming, only that, instead of dealing with whole systems, GAs only work with constructs that need to be streamlined. A population of possible solutions is converted into an optimization problem by genetic algorithms.
Our strategy was to create a flexible recommendation system that can provide recommendations to users based on a their preferences. We developed a revolutionary algorithm based on the idea that recommender systems should help users find products that are outside of their immediate inclinations and novel items that they did not know of before. That is, we provide recommendations based on the interest of the user using genetic algorithms.
This will allow us to produce recommendations to the user with a high degree of novelty based on their preferences. Our algorithm will learn and evolve from the user preferences easily in the early stages to alleviate the over-specialization issue as demonstrated in
Figure 4.
4.2. The Proposed Genetic-Based Recommender System
Instead of choosing specific products to form a recommendation list,
focuses on the overall content of the recommendation list. The main principle is to review the entire suggestion list hierarchically and show new products to the customers that may interest them. Algorithm 1 presents the main procedure of
.
| Algorithm 1: The main procedure of . |
| Input: List of film genre. |
| Output: Recommendation List. |
- 1:
Generate the initial population (initPop) that contains M individuals. Each chromosome contains N random genotype where each of those genotype is a movie id. - 2:
Get the genre of the movie. - 3:
Get the genre score. - 4:
for elem in population do: - 5:
for item in elem do: - 6:
Call getGenre function. - 7:
Call GetScore function. - 8:
Select the scores of the entire population. - 9:
Apply crossover operator with uniform method. - 10:
Apply mutation operator with random method. - 11:
end - 12:
Select the best individual and recommended its items to the user.
|
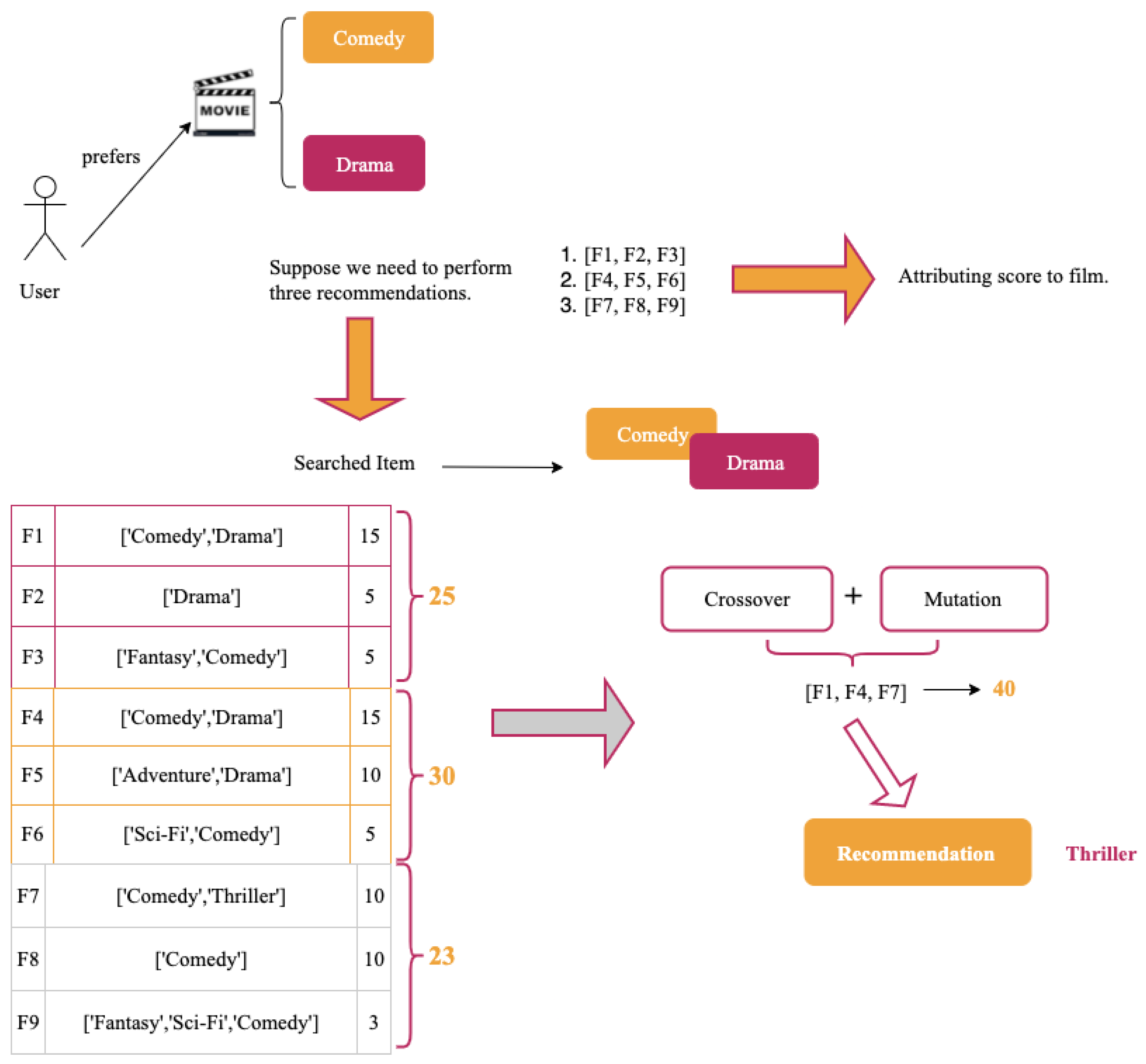
Initialize population (Line 1). Initially, fills the population with M randomly generated lists, initPop. Each chromosome contains N random genotypes where each of those genotypes is a movie ID.
Fitness function definition (Lines 2–10).
Step 1: Obtain genre of the movie
Select the genre based on movie ID.
Step 2: Obtain genre score
The core idea of this phase is to attribute a score for each solution. For that, if the searched item has, for example, “Action” as the first genre and “Sci-Fi” as the second genre, a similar solution will gain 15 points as a score. Otherwise, the solution which matching the first genre gains ten points, and the process continues in that same way.
Step 3: Fitness values
In this step, we generate the scores by looping over a chromosome. At the end of this phase, we will obtain the scores of the entire population.
For example, if individual in Equation (
2) generates scores of Equation (
3), the sum of the scores would be 44. If we ran through the same process on the other members of the population, the results would differ.
Apply genetic algorithm operators (Lines 9–10).
Crossover
In the crossover step of the algorithm, the offspring are generated with features from both parents. This allows for the development of offspring with higher affinity qualities for those genres. For this step, we use the uniform crossover method. Each parent’s section would have a matching segment of the same length and size as the other parent. The child would then receive elements from one of the parents at random. The chosen elements are joined together to make the offspring. The child will be the same length as both parents but will have different characteristics.
Mutation
We added a little variety into the population via the mutation mechanism. A mutation is a process of altering the offspring generated by existing solutions to add new and valuable features while removing neither worthwhile nor helpful features. For this step, we use the random mutation method.
Selection
We chose the elitist selection method as it defines which individuals from the old and offspring generations make up the next population.
Select the optimal recommendation list (Line 12). captures the items of the selected individual and recommends it to the user.
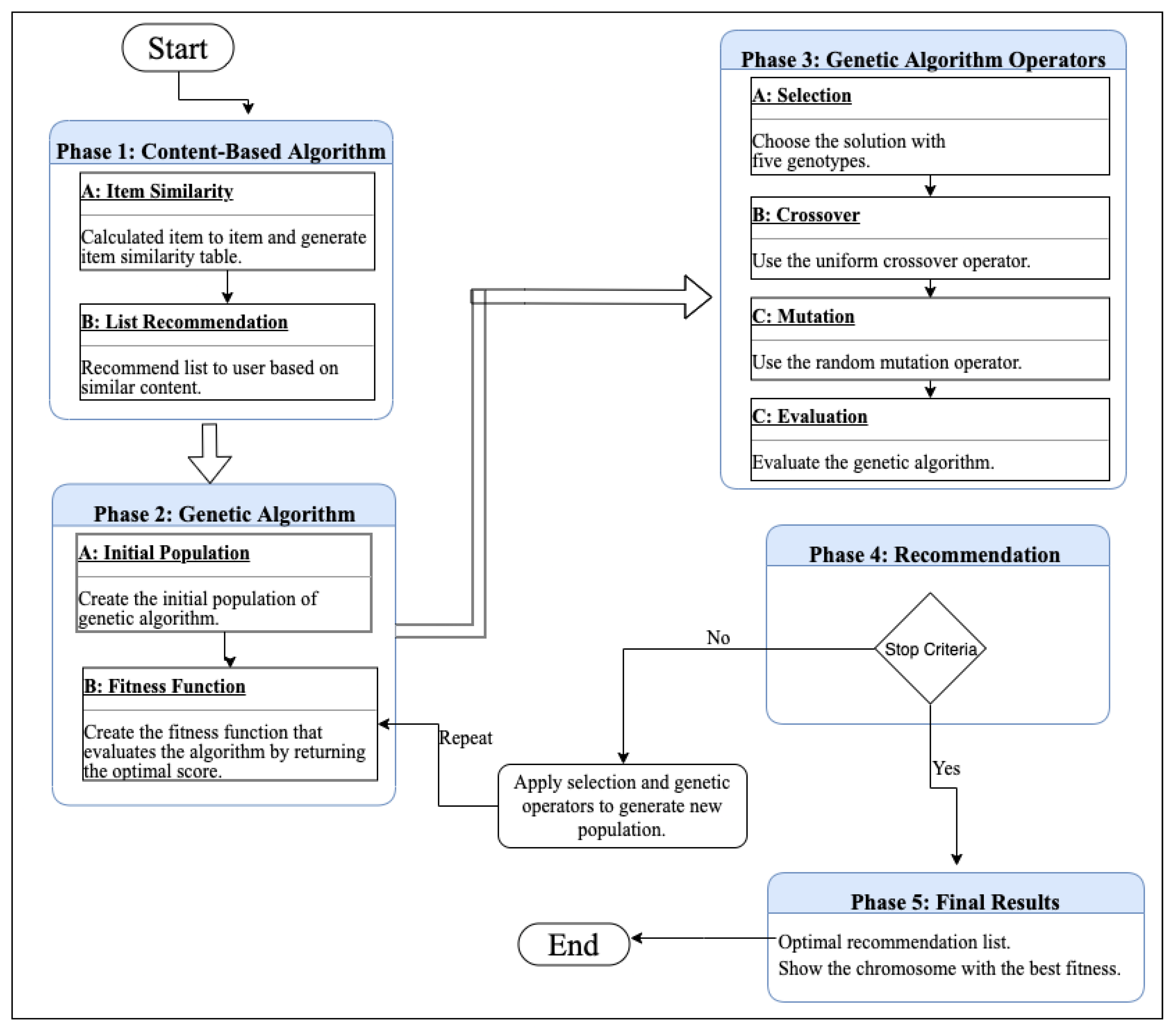
4.3. Methodology and Overall Approach
We started with a basic recommendation engine that lists all similar movies based on what the user wants. It performs the primary recommendation using a content-based filtering algorithm. For example, if the user already liked a specific film from the “Action” genre, the principal content-based recommendation recommends all films that have a similar genre to the user.
Figure 5 presents the architecture of
.
For that, our proposed technique contains a four-phase process to deal with this problem.
Phase 1: Content-based algorithm
We created a similarity matrix using a cosine similarity function between movies, and then we recommended the most similar movies by searching on the matrix table for all movies with a score of more than 0.80.
Phase 2: Genetic algorithm
We needed to incorporate additional hacks and take care of randomness to suggest novel and serendipitous items alongside common items, which could be accomplished by leveraging genetic algorithms that carry a variety of recommendations.
Initial Population
The movies in our MovieLens dataset are divided into 18 distinct genres. Since we only want five recommendations, the vector size should have five values, each of which corresponds to a different movie ID to reflect each individual. Firstly, we need a sample population for our genetic approach. The sample population in the GA is chosen from the whole population as N random solutions. The solution is chosen at random, since each chromosome comprises five movie IDs. As a result, the algorithm starts with actual data and finds the best solutions. Our initial population should be based on existing movies, since we will need to find neighbors between them. We will construct the initial population randomly. The size of the initial population will be 1947. We will have a population of 1947 individuals with preferences for the five different movies in the system. The reasoning behind choosing our population in this way is that our ultimate goal is to find the best individual who will find neighbors who have the same preferences requested by the user with a new element that will create serendipity. Individuals will be used to illustrate how our initial population will look. For this reason, the table only includes five individuals. The individual’s representation will be of format mentioned in Equation (
4) to indicate the different possible movies in the system.
Fitness Function
In our example (see
Table 2), we assume the user liked a movie with “Adventure” as the first genre and “Animation” as the last one.
Regarding the first individual described in Equation (
5): The first movie in this individual is 574, and it has the genres Adventure, Animation, and Children. They both preferred Adventure as the first genre and Animation as the second so that the score could be set at 10.
Table 2 below shows a representative sample of people and the health ratings assigned to them.
Phase 3: Genetic algorithm operators
- –
Crossover: The algorithm’s crossover process is the process by which the offspring are created with characteristics from both parents. For that step, we will use the random crossover method. Each gene (bit) is chosen at random from one of the parent chromosomes’ corresponding genes. To make the offspring, the chosen segments are joined together. For crossover, we use a uniform crossover method with an N/10 probability, as we want only N recommendations. For example if we assume that we need five recommendations, we would use a uniform crossover method with a 5/10 probability.
- –
Mutation: We added a little variety into the population via the mutation mechanism. For mutation, we will use the random mutation method. For mutation, we could have a chance that after crossover one of the genes is randomly selected and changed to a random movie ID number. At the end of this step, we obtained the new offspring population, and we again calculated their fitness scores, and then we retained the best performing individuals between the old and new populations.
- –
Selection: We used the elitist selection method, as it defines which individuals from the old and offspring generations make up the next population.
Phase 4: Recommendation
This phase is the last one to provide the optimal recommendation list, it show the chromosome with the best fitness. This final step suggests an unexpected and fortuitous thing to the user. The active user has a good luck in finding new items that are likely to be of their interest.
5. Evaluation and Results
Addressing a problem and using an evaluation method to see how the problem has been solved is part of evaluating feedback systems. Recommender systems must have a solution to a problem in order to be helpful. The problem must be clearly described to determine whether it has been solved or not.
This section explains how the suggested RS, , was put to the test. Several tests were carried out to compare the suggested RS to other suggestion techniques:
- –
Content-based filtering: This recommendation technique generated the recommendations based on the cosine similarity.
- –
The use of clustering: In reference [
7], they use Clustering, especially the k-means algorithm to enhance the recommendation.
The section below contains information about the datasets that were used in the tests.
Section 4.2 goes into the experimental approach that was used and the measurement criteria that were used. Finally, in
Section 4.3, the findings are presented and discussed.
5.1. Experimental Data
The benchmark and synthetic datasets have been used in all experiments. MovieLens [
31] is a dataset acquired by the GroupLens study group at the University of Minnesota for use in recommender method research. To secure the identities of the users, the data is anonymized. Movies, users, and movie ratings are all included in the information. The dataset in question was selected because it is widely used in the field for benchmarking recommender systems [
32]. There are approximately 6040 users, 3900 movies, and 100,000,209 reviews in the dataset.
Table 3 summarizes the statistics of the experimental data. The potential scores are 1, 2, 3, 4, and 5, with 5 suggesting that the user enjoyed the film the most, and 1 indicating that the user enjoyed the film the least.
5.2. Experimental Design
The evaluation process consists of four different experiments that were conducted using a MacBook Pro 16GB RAM (Apple, Cupertino, CA, USA). The first experiment aimed to evaluate first the content-based recommendation algorithm. The second experiment examined the data to evaluate the selected recommendation list of . In both cited experiments, we considered the obtained results using the MovieLens dataset. The third experiment compared the results of the proposed approach with the results found by the content-based filtering algorithm. The CPU time needed by to predict the recommendation was compared with the required CPU time of the content-based technique. The last experiment assessed the in terms of recommendation quality using the criteria of , , , , and .
In all content-based applications, the recommendation system does not predict the user’s preferences of items, such as movie ratings, but tries to recommend items to users that they may prefer and use [
33]. In this case we were not interested in whether the system properly predicts the ratings of these movies, but rather whether the system properly predicts that the user will add these movies to their queue (i.e., use the items).
When recommending items to users, various metrics must be considered, not only the accuracy of a recommendation prediction. There are several measures and metrics for evaluating recommendations.
Recall: The recall is the percentage of the favorite recommended items to the total favorite items of the active user, where
is true positive and
is false negative (Equation (
6)).
Precision: The precision is the ratio fraction of the interesting recommended items to the total number of recommended items, where
is false positive (Equation (
7)). Both recall and accuracy are affected by the number of recommended items (N). As a result, the recommendation quality metrics were computed using a different number of suggested items.
Diversity: Diversity refers to the inclusion of several types of items in a user’s recommendation that vary from their previous preferences. The center list similarity metric is used to calculate diversity. The diversity metric is a measure of how distinct and various recommendations differ from one another. Consider a consumer who just finished watching the first movie of a trilogy on Netflix. A low diversity recommender would recommend only the following movies of the trilogy or films directed by the same director. High diversity, on the other hand, can be accomplished by suggesting items at random, which is why the use of genetic algorithms is beneficial in bringing diversification to the recommendations (Equation (
8)).
Serendipity: Serendipity is a metric that measures how unexpected or relevant recommendations are provided to the user. This equation is divided into two parts: the degree of surprise and the user’s relevancy. Surprise is calculated as the difference between the likelihood that an item
i is recommended for a user and the likelihood that an item
i is suggested for any user. The chance of a recommendation is just a function of its overall rank among
n items (Equation (
9)):
A recommendation is considered meaningful to the user if the user evaluated it highly. When we put all of the information together for a user, we generate Equation (
10):
Global serendipity is just the average serendipity across all users. The most challenging part of this equation is determining relevance. If a user does not rate a significant number of things, an even lower number of things will be represented in the test set, resulting in a low level of serendipity.
Furthermore, this definition of relevance will exclude things that were not evaluated but would still be good recommendations for the user. Different algorithms’ serendipity can still be compared within the same dataset, but this should be seen as a lower constraint on the system’s overall serendipity.
Novelty: Novelty is one of the fundamental aspects of a recommendation system since it increases efficacy and adds a new item to the suggestion list, contributing to superior accuracy. Novelty determines how unknown recommended items are recommended to a user. The capability of a recommender system to offer unique and surprising things that a user is unlikely to be aware of already is measured by novelty. It takes the suggested item’s self-information to generate the mean self-information per the top N recommended list and averages it across all users. This metric can be extracted from the feedback, which represent the discovery of new items. This is relevant as one of the goals of our approach was to provide novel, serendipitous items to the user. We propose a simple metric to evaluate this: the discovery index, to be computed by dividing the number of recommended items unknown to the user by the total number of provided recommendations (Equation (
11)).
Some recommender systems provide recommendations that are very accurate and have adequate coverage, yet are worthless for practical use [
34]. One of the main indicators for studying recommender systems that assess a recommendation’s “non-obviousness” is novelty. The term “novel recommendations” refers to suggestions of things that the user is unfamiliar with [
16]. It is challenging to design metrics to assess novelty, since novelty is a measure of the degree to which recommendations deliver things that are both appealing to users and surprising to them. In reality, traditional ways of judging quality are fundamentally opposed to originality. To assess this measure, we will refer to the research of [
35,
36]. Reference [
35] compared different novelty metrics in two larger datasets of movies (MoviesLens and Netflix), using different recommender methods: random, topN popularity recommendations; the probability of items being liked (PL); the probability of items being liked and dissimilarity (LD); and the probability of items being liked, dissimilarity, and satisfaction (LDS). The second article [
36] introduced a formal framework for defining novelty and diversity measures, which unifies and generalizes various state-of-the-art metrics. The authors established a set of methodologies for measuring originality and variety based on the combination of ground components. The measures linked to the novelty (EPC and EPD) of a relevance-aware form of the content-based algorithm were used in their method.
5.3. Results
The results of all experiments are mentioned in this section. In addition, the collected results are discussed and utilized to compare those experiments’ approaches.
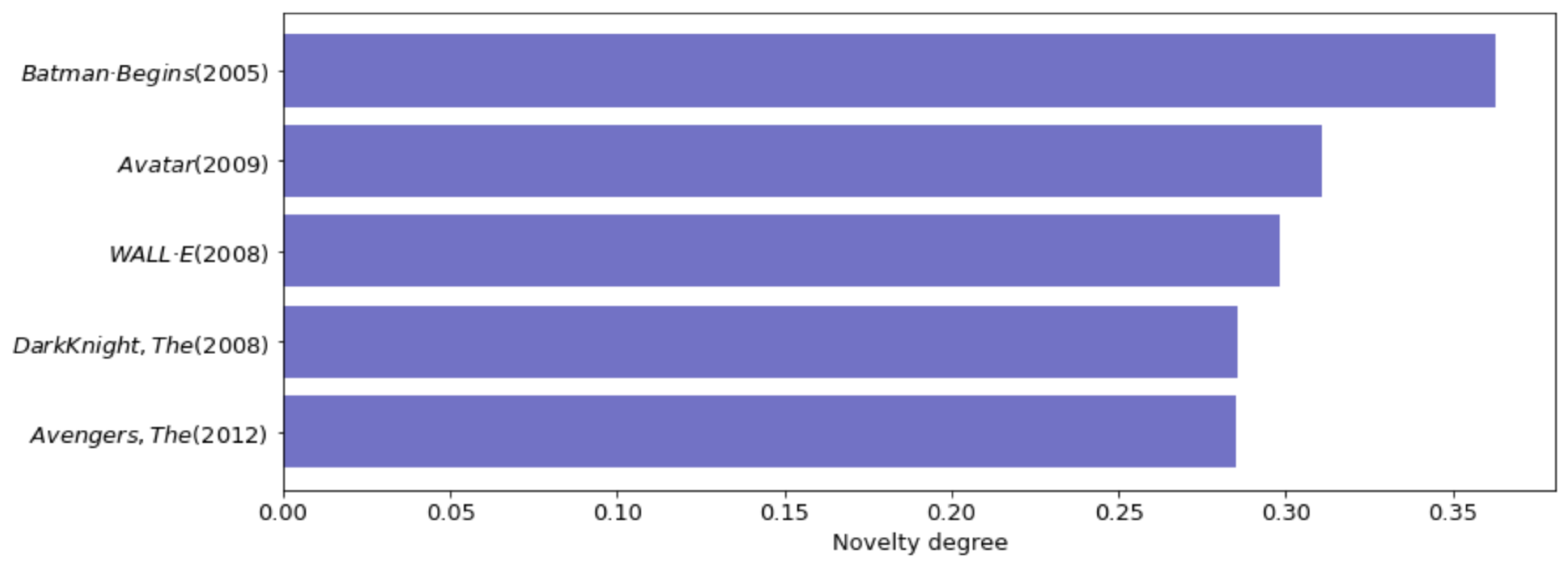
Figure 6 presents the degree of novelty using content-based filtering. The reader can observe that the classic content-based recommender system algorithm has lower and minimal improvements when compared with other recommendation approaches illustrated in
Figure 7 and
Figure 8.
Figure 7 presents the top five movie recommendations with the degree of novelty regarding the first initial population. The searched movie has Action, Adventure, Sci-Fi, Thriller, and IMAX as genres. All recommendation are performed based on the genre criteria, for example the movie
An American Tail is the highly similar one with a degree of
, which presents the similar Adventure genre and proposes the other new genres of Animation, Children, Comedy, which may be enjoyed by all users who like the searched movie.
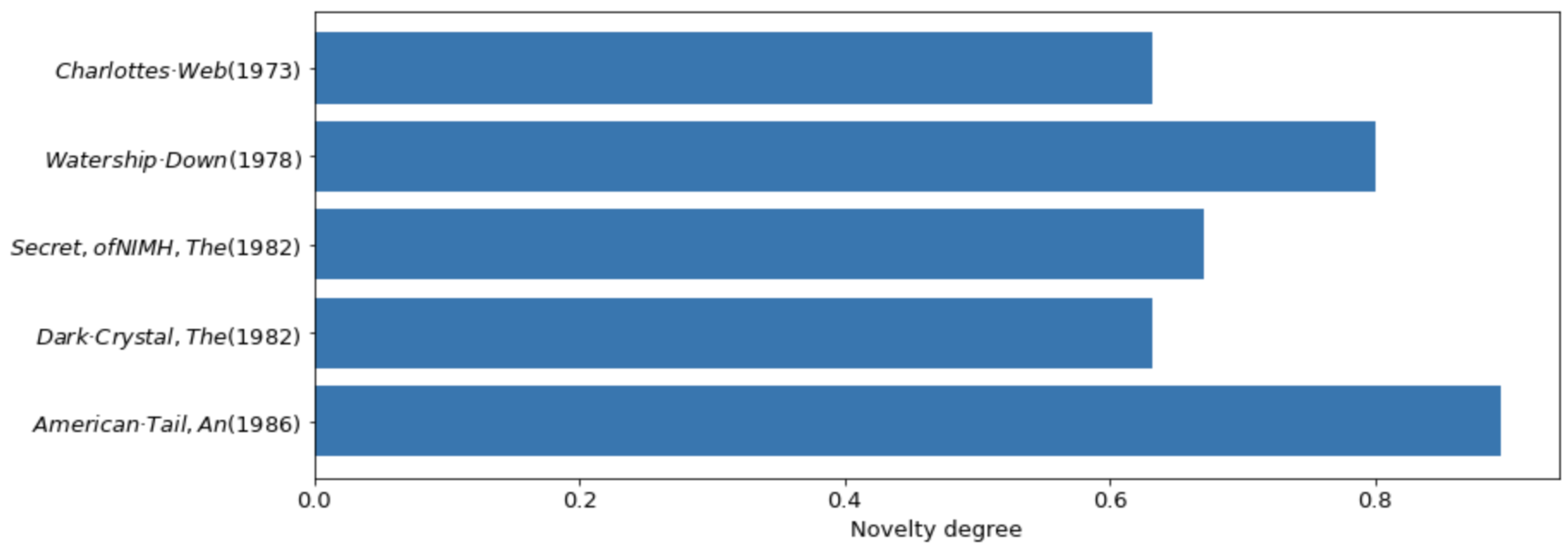
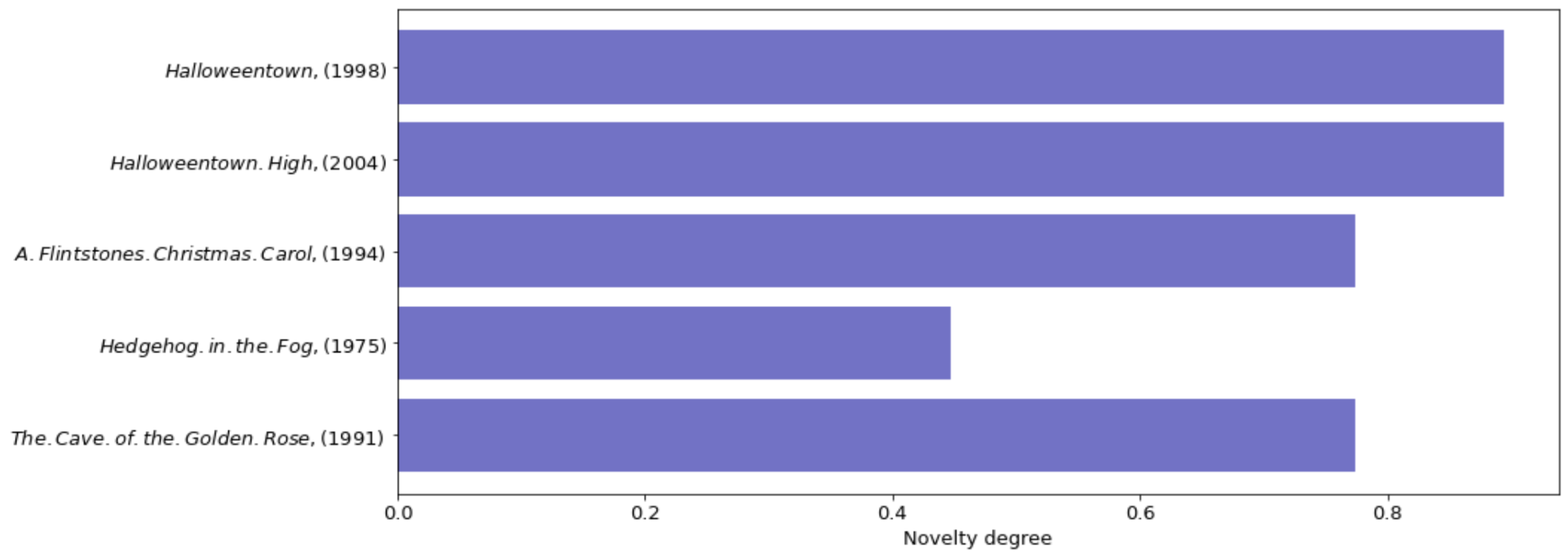
Figure 8 shows the top five movie recommendations for the last population. In this histogram we can compare between new and serendipitous items that are recommended to users. As we can see in
Figure 8, both of the first movies have Adventure, Children, Comedy, and Fantasy as genres and have
as a degree of novelty because they offer three new genre that could be liked by the users.
The authors conclude that the performance of all recommendations improved from the initial to the last given results. The authors deduce that the higher the degree of novelty, the more novel and serendipitous the recommended element is, and the lower the degree of novelty, the more similar the recommended item is to the one sought.
The serendipity in
Figure 7 and
Figure 8 can easily be seen on lines, with a high degree of novelty in the experience of receiving an unexpected and fortuitous item recommendation, therefore it is a way to diversify recommendations. While users rely on exploration and luck to find new items that they did not know they wanted, as an example a person may not know they likes watching
Halloweentown until it is accidentally recommended to them. All recommendation are serendipitous, because they help the user to find a surprisingly interesting item that they might not otherwise have discovered. In conclusion, implementing operational serendipity techniques is an excellent way to enhance the capabilities of content-based recommender systems in order to reduce the over-specialization problem by providing the user with unexpected ideas.
A sensitivity analysis was conducted to determine the suitable values that lead to the best GA performance.
Table 4 presents the selected values of the parameters.
Table 5 describes the comparison between our proposed method and other recommender system approaches in terms of the diversity of the results, which is less if we use the classic content-based filtering and becomes higher when using the genetic algorithm that creates unexpected and fortuitous items in recommendation lists. Moreover, the effect of over-specialization is less in our suggested approach.
Table 6 shows the gathered novelty results. The reader can observe that
shows remarkable improvements when compared with other recommendation approaches. The novelty of
reaches its best case at Top 1 and Top 3, then begins to decrease. The obtained results demonstrate the superiority of the proposed method. Otherwise, on average,
achieved
better novelty results than the content-based recommendation method.
Table 7 and
Table 8 present the precision and recall results of the recommendation methods. From these tables, the authors conclude that the performance of all recommendation methods with the increasing of the number of Top-N recommendation improved. This is because recall represents the percentage of the favorite recommended items out of all favorite items in the collection. Thus, increasing the number of recommended items leads to an increase in the probability of recommending interesting items for users.
6. Discussion
The fundamental idea behind this study is to analyze potential recommendation lists rather than examining things and then building a recommendation list. As a result, looks for a suggestion list that fits three key features:
The suggested items are semantically correlated with the searched item.
The recommended goods represent a variety of what the user wants.
Unexpected and fortuitous items should be recommended to users.
To find a list that meets those features, adopts the revolutionary algorithms to have diversification in the recommendation list. The authors conclude that the size of the dataset and the number of recommended items impact ’s performance (i.e., size of the individual). Thus, the Top N should be chosen carefully and experimentally with a feasible dataset size to achieve the best possible performance. The results demonstrate ’s extraordinary progress in terms of prediction accuracy and suggestion quality.
The key obstacle affecting content-based filtering is over-specialization. As a result, intends to address the over-specialization issue in order to increase suggestion quality and RS accuracy. was tested on the MovieLens dataset. The improvements percentage achieved by when using Movielens was higher than those achieved by more classical methods.
Regarding the over-specialization issue, the outperforms the other RSs in terms of novelty, suggestion quality, and number of serendipitous items suggested to the user. Overall, made a significant improvement with respect to the recommendation quality. This demonstrates its effectiveness in alleviating the over-specialization problem faced by content-based filtering.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}