1. Introduction
With the advancement of economic globalization and the intensification of mergers between enterprises, the emergence of large-scale or concurrent production makes the pattern of distributed manufacturing necessary [
1,
2]. Distributed manufacturing decentralizes tasks into factories or workshops from different geographical locations. This pattern can help the manufacturers raise productivity, reduce cost, control risks, and adjust marketing policies more flexibly [
3]. As an important part of distributed manufacturing, scheduling directly affects the efficiency and competitiveness of enterprises. Generally speaking, to solve such problems, a problem-specific model with production constraints should be first established to describe the scheduling problem considered. Then, optimization methods (e.g., mathematical programming, intelligent optimization, etc.) of operational research are developed to search for an optimal solution. For systems with large-scale and high complexity, mathematical programming such as integer programming, branch and bound, dynamic programming, or cut plane can rarely find an optimal solution (ranking) in the target space due to enumeration concept, but the efficiency decreases with the increment of the number of jobs/tasks to be scheduled.
At present, most studies use intelligent optimization algorithms to approximate the optimal solution for scheduling problems. The intelligent optimization algorithm, also called the evolutionary optimization algorithm, or metaheuristic, reveals the design principle of optimization algorithm through the understanding of relevant behavior, function, rules, and action mechanism in biological, physical, chemical, social, artistic, and other systems or fields. It refines the corresponding feature model under the guidance of the characteristics of specific problems and designs an intelligent iterative search process. That is, these kinds of algorithms do not rely on the characteristics of problems, but obtain near-optimal solutions through continuous iterations of global and local search. When an intelligent algorithm is applied for scheduling problems, it can express the schedule as a permutation model in the form of coding, and further compress the solution space into a very flat space, so that a large number of different permutations (schedules) correspond to the same target. Hence, the permutation model-based algorithm can search more different schedules in the target space range in tens of milliseconds to tens of seconds, so as to obtain a solution better than the traditional mathematical programming method.
The object of this study is related to the distributed blocking flowshop scheduling problem (DBFSP) [
4].
Figure 1 illustrates DBFSP, which considers
f parallel factories that contain the same machine configurations and technological processes [
5]. The jobs can be assigned to any factories and each job follows the same blocking manufacturing procedure [
6]. Although the machines configured in each distributed factory are the same, the processing time of each operation of each job is assumed to be different, thereby the processing tasks assigned to each distributed factory and their completion time are also different. The idea of solving DBFSP is to reasonably allocate the jobs to the factory through optimization algorithms, and then sequence the jobs in each distributed factory, to optimize the manufacturing objectives of the whole work order. Currently, researchers have made great efforts on solving DBFSP in a static environment, the existing researches mainly focused on the construction of mathematical models and the design of optimization algorithms. Zhang et al. [
7] have established two different mathematical models using forward and reverse recursion approaches. A hybrid discrete differential evolution (DDE) algorithm was proposed to minimize the maximum completion time (makespan). Zhang et al. [
8] constructed the mixed-integer model for DBFSP and developed a discrete fruit fly algorithm (DFOA) with a speed-up mechanism to minimize the global makespan. Additionally, Shao et al. [
9] proposed a hybrid enhanced discrete fruit fly optimization algorithm (HEDFOA) to optimize the makespan. A new assignment rule and an insertion-based improvement procedure were developed to initialize the common central location of different fruit fly swarms. Li et al. [
10] investigated a special case of DBFSP, in which a transport robot was embedded in each factory. The loading and unloading times are considered and different for all of the jobs conducted by the robot. An improved iterated greedy (IIG) algorithm was proposed to improve productivity. Moreover, Zhao et al. [
11] proposed an ensemble discrete differential evolution (EDE) algorithm, in which three initialization heuristics that consider the front delay, blocking time, and idle time were designed. The mutation, crossover, and selection operators are redesigned to assist the EDE algorithm to execute in the discrete domain.
The above researches on DBFSP have formed a certain system, but they assumed that no explicit disruptions occur during the manufacturing process. In fact, a series of uncertainties often happened during the manufacturing process [
12]. These uncertainties, which are sudden and uncontrollable, can change the state of the system strongly and affect the scheduling activities continuously [
13]. As a result, the original static schedules are no longer suitable for real-time scheduling. To eliminate the impact of sudden uncertainties, rescheduling operations are generally performed in response to disruptions [
14,
15]. Rescheduling refers to the procedure of modifying the existing schedule to obtain a new feasible one after uncertain events occur [
16]. One of the most important rescheduling strategies for traditional flowshop is “predictive-reactive” scheduling [
17]. “predictive-reactive” scheduling defines a two-stage “event-driven” scheduling operation: the first stage generates an initial schedule that provides a baseline reference for other manufactural activities such as procurement and distribution of raw materials [
18]. Influenced by the disruptions, the second stage explicitly quantifies the disruptions, constructs the management model with the disruption information gathered by the cyber-physical smart manufacturing technology [
19,
20,
21], adjusts the initial schedule, and makes an effective trade-off between the initial optimization objective and the disturbance objective [
22]. Since little literature is on the rescheduling of DBFSP, we review only the rescheduling strategies and algorithms developed for traditional and single flowshop. To realize the rescheduling, a suitable strategy should be determined in advance according to the scenario. Framinan et al. [
23] discussed the problem of high system tension caused by continuous rescheduling of multi-stage flow production. A rescheduling strategy was described by estimating the availability of the machines after disruptions and a reordering algorithm based on the critical path was proposed. Katragjini et al. [
24] analyzed eight types of uncertainties and designed rescheduling strategies through the classification of job status, which considers the completed, in processed and unprocessed operations. Iris et al. [
25] designed a recoverable strategy taking the uncertainty of crane arrival to the ship and the fluctuation of loading and unloading speeds into account. The rescheduling strategy used a proactive baseline with reactive costs as the objective. Ma et al. [
26] took the overmatch time (difference between real manufacturing time and the estimated time of the initial schedule) as one of the objectives in the rescheduling model to handle production emergencies in parallel flowshops. Li et al. [
27] discussed both machine breakdown and processing change interruptions for a hybrid flowshop. The authors have proposed a hybrid fruit fly optimization algorithm (HFOA) with processing-delay, cast-break erasing, and right-shift strategy to minimize different rescheduling objectives in a steelmaking-foundry system. Li et al. [
28] also considered five types of interruption events in the flowshop, namely machine breakdown, new jobs arrival, jobs cancellation, job processing change, and job release time change. A rescheduling strategy based on job status was designed for each event. A discrete teaching and learning optimization (DTLO) algorithm was proposed to optimize the makespan and stability. Valledor et al. [
29] applied the Pareto optimum to solve the multi-objective flowshop rescheduling problem with makespan, total weighted tardiness, and steadiness as objectives. Three classes of disruptions (appearance of new jobs, machine faults, and changes in operational times) were discussed and an event management model was constructed. A restarted iterated Pareto greedy (RIPG) metaheuristic is used to find the optimal Pareto front.
From the above review, it can be concluded that current researches focused mostly on the rescheduling of a single flowshop with various constraints. Little literature has considered rescheduling from the distributed manufacturing perspective. Though the Industry 4.0 wireless networks [
30,
31] have quickly developed in recent years, they are involved more in distributed information interconnection rather than decision making in scheduling fields. Likewise, the big data-driven technology [
32,
33] may provide real-time decisions or schedule rules for small-scale manufacturing, but has not formed a sound system. Moreover, big data technology relies strongly on a large amount of historical data, it is difficult to apply to new products due to the highly discrete, stochastic, and distributed properties of scheduling problems. Therefore, with the in-depth application of distributed manufacturing, distributed rescheduling strategies and approaches need to be formulated prudently so that effective references could be provided for modern decision-makers.
On the other hand, the objects of job shop scheduling are usually individual jobs, products, or other resources in the manufacturing process. Such resources have typical discrete characteristics, which need to be marked and expressed through special information carriers, and then obtain new combinations (ranking) by constantly updating the information carriers. These optimization characteristics are similar to the optimization process of the intelligent algorithm based on the permutation model. Therefore, the intelligent algorithm based on the evolution concept is more suitable for solving scheduling problems.
According to the above analysis and good applicability of the intelligent algorithm, we use an intelligent algorithm to reschedule the distributed blocking flowshop scheduling problem in a dynamic environment (DDBFSP). In the last decade, the application of intelligent algorithms for solving scheduling problems has been extensively investigated. Memetic algorithm (MA), also called the Lamarckian evolutionary algorithm, is attracting increasing concern. The concept of “meme” refers to contagious information patterns proposed by Dawkins in 1976 [
34]. “Memes” are similar to genes in GA, but there are differences: Memetic evolution is characterized by Lamarckism, while genetic evolution is characterized by Darwinism. Meanwhile, neural system-based memetic information is more malleable than genetic information, so memes are more likely to change and spread more quickly than genes. In evolutionary computing, MA can combine various global and local strategies to construct different search frameworks, which possess the characteristics of GA but with stronger merit-seeking ability. MA was widely applied in many engineering problems, such as vehicle path planning [
35], home care routing [
36], bin packing problem [
37], broadcast resource allocation [
38], and production scheduling optimization [
39,
40,
41]. Until now, MA has not been applied to solve DBFSP in a dynamic environment(DDBFSP), it will be of significance to extend MA as a solver for DDBFSP.
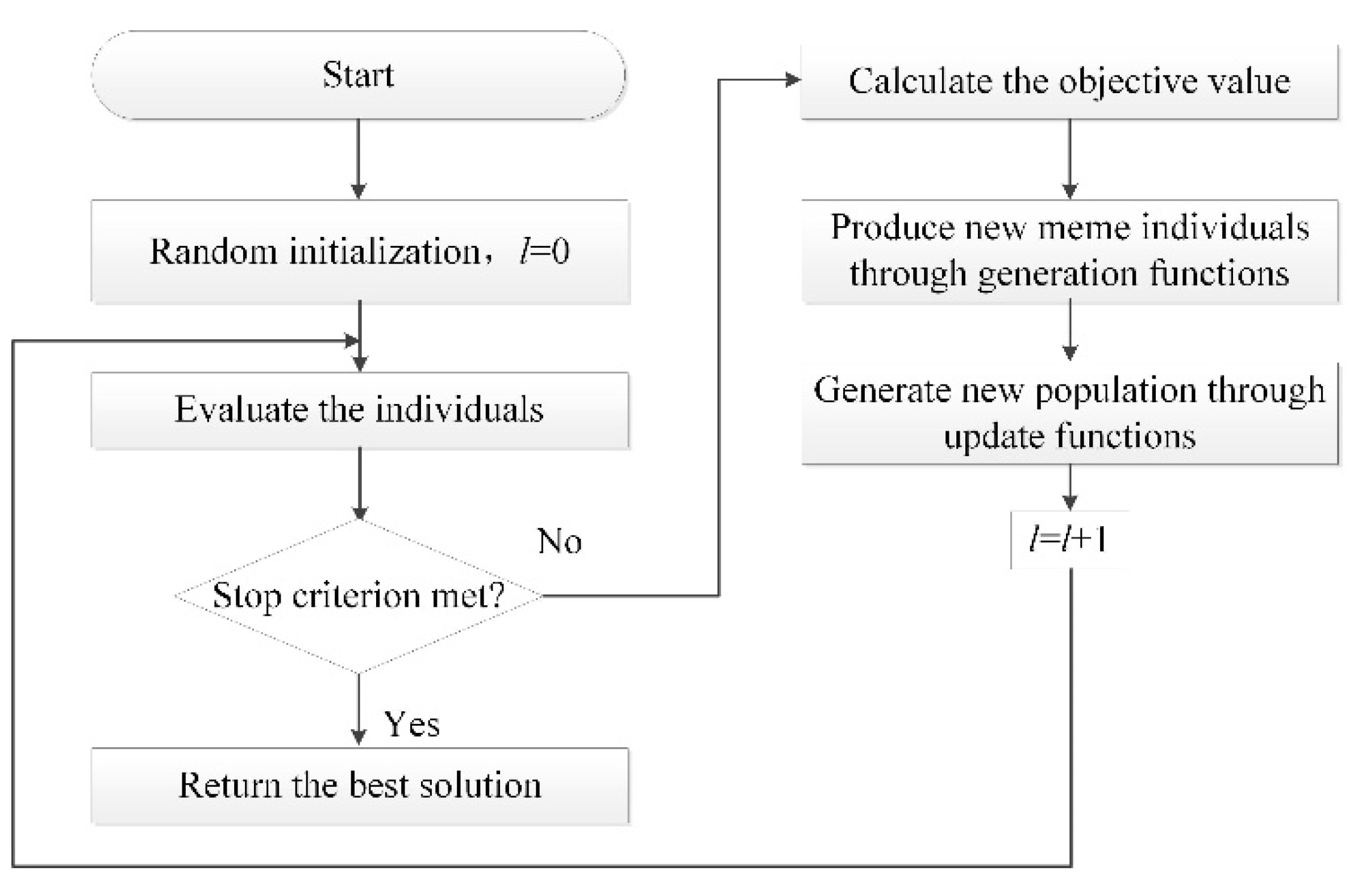
In summary, this paper aims to optimize DDBFSP with both makespan and stability measures as the objectives. The machine breakdown is defined as the disruption and assumed to happen stochastically in any distributed factories. To handle such dynamic events, a problem-specific disruption management model is constructed. A rescheduling framework that includes a job status-oriented classification strategy and a reordering algorithm-discrete Memetic algorithm (DMA) is proposed. For DMA, the differential evolution (DE) operators have been embedded to execute the neighborhood search. A simulated annealing (SA)-based reference local search framework is designed to help the algorithm escape from local optimums. Finally, the effectiveness of DMA is validated through comparative experiments. It is expected that the effect after rescheduling is to highly maintain the level of optimization of the original manufacturing objective (makespan) while ensuring the stability of the newly generated schedules.
The remainder of the paper is organized as follows.
Section 2 states DDBFSP and constructs the mathematical model and objective function for DDBFSP.
Section 3 designs the corresponding rescheduling framework.
Section 4 elaborates the details of the DMA reordering algorithm.
Section 5 verifies the performance of DMA and analyzes the results;
Section 6 summarizes the research content of this paper.
6. Conclusions
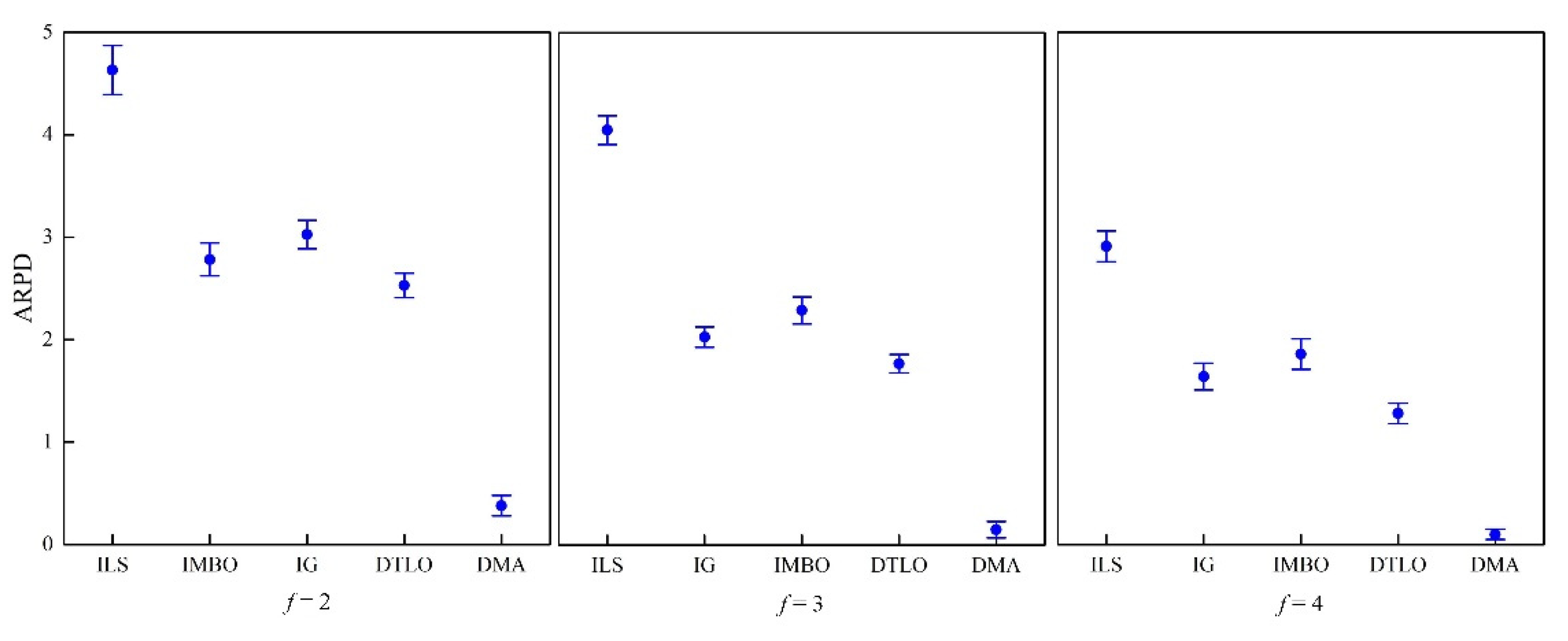
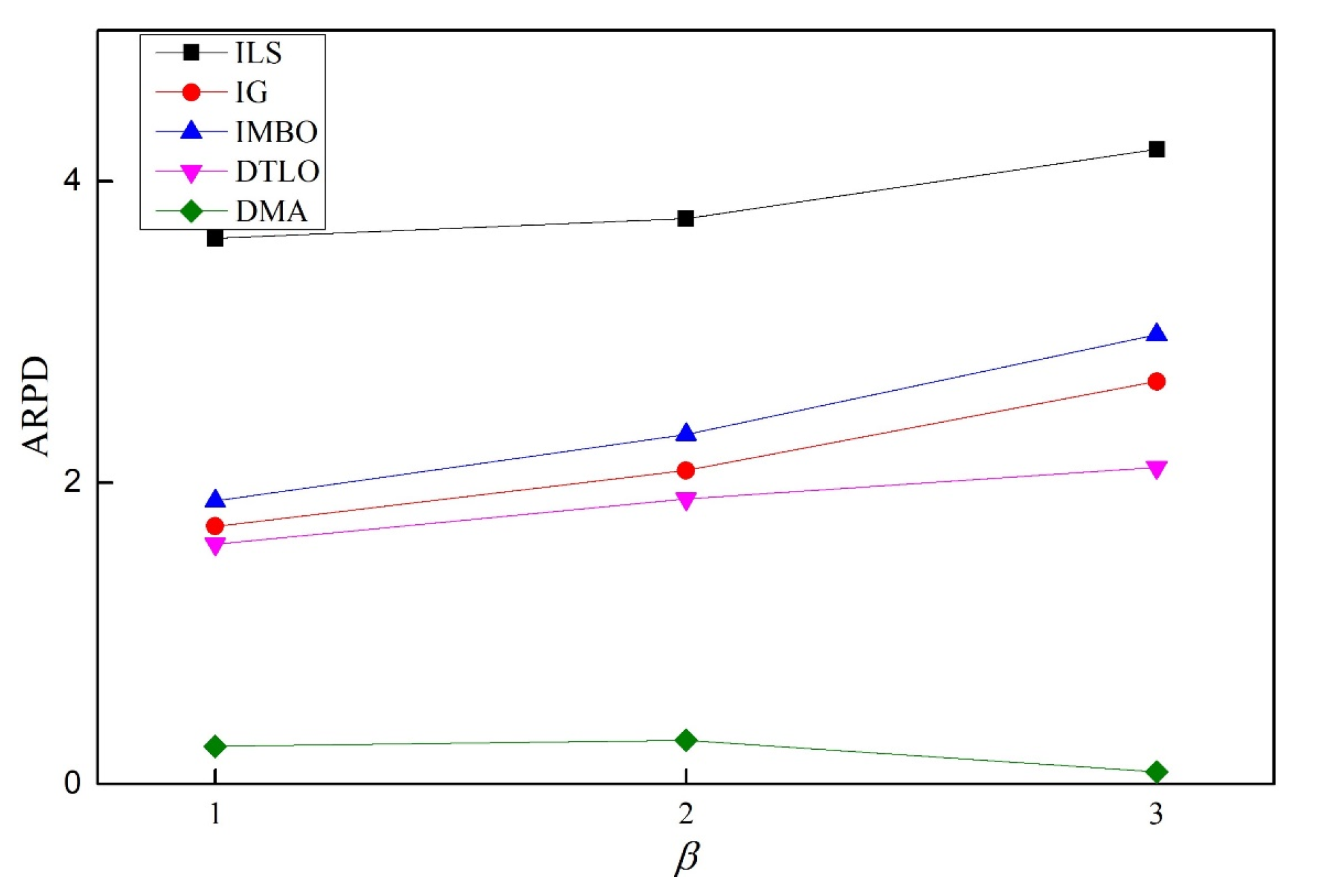
Building rescheduling optimization models and designing effective optimization methods according to the characteristics of distributed manufacturing are of significance to promote the research of the dynamic scheduling theory of distributed manufacturing. This study investigated the rescheduling strategy and algorithm for DDBFSP, in which machine breakdown events are considered as the disruption in the manufacturing site. Firstly, the mathematical model of DDBFSP including the event simulation mechanism is constructed. We consider makespan and stability as the objectives. The goal of this study is to optimize the bi-objective when the stochastic breakdown occurs in any distributed factories. We apply the “event-driven” policy in response to the disruption. A two-stage “predictive-reactive” rescheduling strategy is proposed. In the first stage, a static environment (DBFSP) without machine breakdown is considered, and the global initial schedules are generated; in the second stage, after machine breakdown occurs, the initial schedule is locally optimized by a hybrid repair policy based on “right-shift repair + local reorder”, and the DMA reordering algorithm based on DE is proposed for local reorder operation. For DMA, a WPNEH initialization method is designed to generate a high-quality population. In the neighborhood search phase, DE is embedded to improve the neighborhood structure and expand the target space by using mutation and crossover operators; in the local search phase, the BRRLS framework is proposed to perturb the high-quality solutions. To maintain the diversity, BRRLS has combined with the SA mechanism to receive the worse solutions with a certain probability. To obtain the best performance of DMA, the DOE method is used to calibrate three key parameters. The effectiveness of the proposed optimization strategy for DMA is verified through comparative experiments. Finally, DMA is compared with other algorithms on different test instances. The statistical analysis using ANOVA has verified the superiority of DMA.
Although the proposed rescheduling strategy has shown effectiveness, there still exist shortcomings. In this study, we only considered the breakdown event as the disruption. Real-life manufacturing suffers from far more than one disruption. The other common disruptions such as job cancellations and their interaction mechanism should be deeply investigated. Therefore, future works will concentrate on the construction of a more refined model that can manage more disruptions simultaneously.
This study attempts to explore the dynamic scheduling problem from the perspective of operational research optimization. With the development of the Industrial 4.0 network and big data, other artificially intelligent technologies play increasingly important roles in smart manufacturing. Combining data-driven technology with intelligent algorithms could adopt their respective advantages, and create more advanced optimization frameworks. For example, intelligent optimization can provide a large amount of historical scheduling data, which can be aggregated with other industrial information as a sample source for data-driven and machine learning. Therefore, the scheduling decision-making function can be deployed hierarchically and decoupled according to different scenarios and environments, thus making rational use of computing resources and improving the flexibility and stability of the system.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}