1. Introduction
Over the past decade, machine learning algorithms and applications have contributed to new advances in the field of assistive technology. Researchers are leveraging such advancements to continuously improve human quality of life, especially those with disabilities or alarming health conditions [
1]. Assistive technology (AT) deploy devices, present services or programs to improve functional capabilities of people with disabilities [
2]. The scope of assistive technology research studies comprises hearing impairment, visual impairment, and cognitive impairment, among others [
3,
4,
5].
Vision impairment can vary from mild, moderate, severe vision impairment and total blindness. In the light of the recent advances in machine learning and deep learning, research studies and new solutions for people with visual impairment have gained more popularity. The main goal is to provide people with visual impairment with visual substitution by creating navigation or orientation solutions. Such solutions can ensure self-independence, confidence, and safety for people with visual impairment in the daily tasks [
6]. According to estimates, approximately 253 million individuals suffer from visual impairments: 217 million have low-to-high vision impairments, and 36 million are blind. Figures have also shown that, amongst this population, 4.8% are born with visual deficiencies, such as blindness: for 90% of these individuals, their ailments have different causes, including accidents, diabetes, glaucoma, and macular degeneration.
The world’s population is not only growing, but also getting older, meaning more people will lose their sight due to chronic diseases [
7]. Such impediments can have knock-on effects; for example, individuals with visual impairments who want an education may need specialized help in the form of a helper or equipment. Learners with visual impairments can now make use of course content in different forms, such as audiotapes, Braille, and magnified material [
8]. It is worth noting that these tools read the text instead of images. Technological advancements have been employed in educational environments to assist people with visual impairment, blind people, and special-needs learners, and these developments, particularly concerning machine learning, are ongoing.
The main objective of conducting visual impairment research studies is to achieve visual enhancement, vision replacement, or vision substitution as originally classified by Welsh Richard in 1981 [
9]. Vision enhancement involve acquiring signals from camera which processed to produce an output display through head-mounted device. Vision replacement deals with displaying visual information to the human brain’s visual cortex or the optic nerve. Vision substitution concentrate on delivering nonvisual output in a auditory signals [
10,
11]. In this paper, we focus on vision substitution solution that delivers a vocal description on both printed texts and images to people with visual impairment. There are three main areas of concentration concerning research on people with visual impairment; namely, mobility, object detection and recognition and navigation. In the era of data explosion and information availability, it is imperative to consider means to information access for people with visual impairment specially printed information and images [
6]. Over the past decades, authors have leveraged state of the art machine learning algorithms to develop solutions supporting each of the aforementioned areas.
Deep learning has evolved in prominence as a field of study that seeks innovative approaches for automating different tasks depending on input data [
12,
13,
14,
15,
16,
17,
18]. Deep learning is a type of artificial intelligence techniques that can be used for image classification, recognition, virtual assistants, healthcare, authentication systems, natural language processing, fraud detection, and other purposes. The study describes an Intelligent Reader system that employs Deep Learning techniques to help people with visual impairment read and describe images in a printed text book. In the proposed technique, Convolutional Neural Network (CNN) [
19] is utilised to extract features from input images, while Long Short-Term Memory (LSTM) [
20] is used to describe visual information in an image. The intelligent learning system generates a voice message comprising text and graphic information from a printed text book using the text-to-speech approach. Deep learning-based technologies increase image-related task performance and can help people with visual impairment live better lives. The overall architecture of the proposed solution is demonstrated in
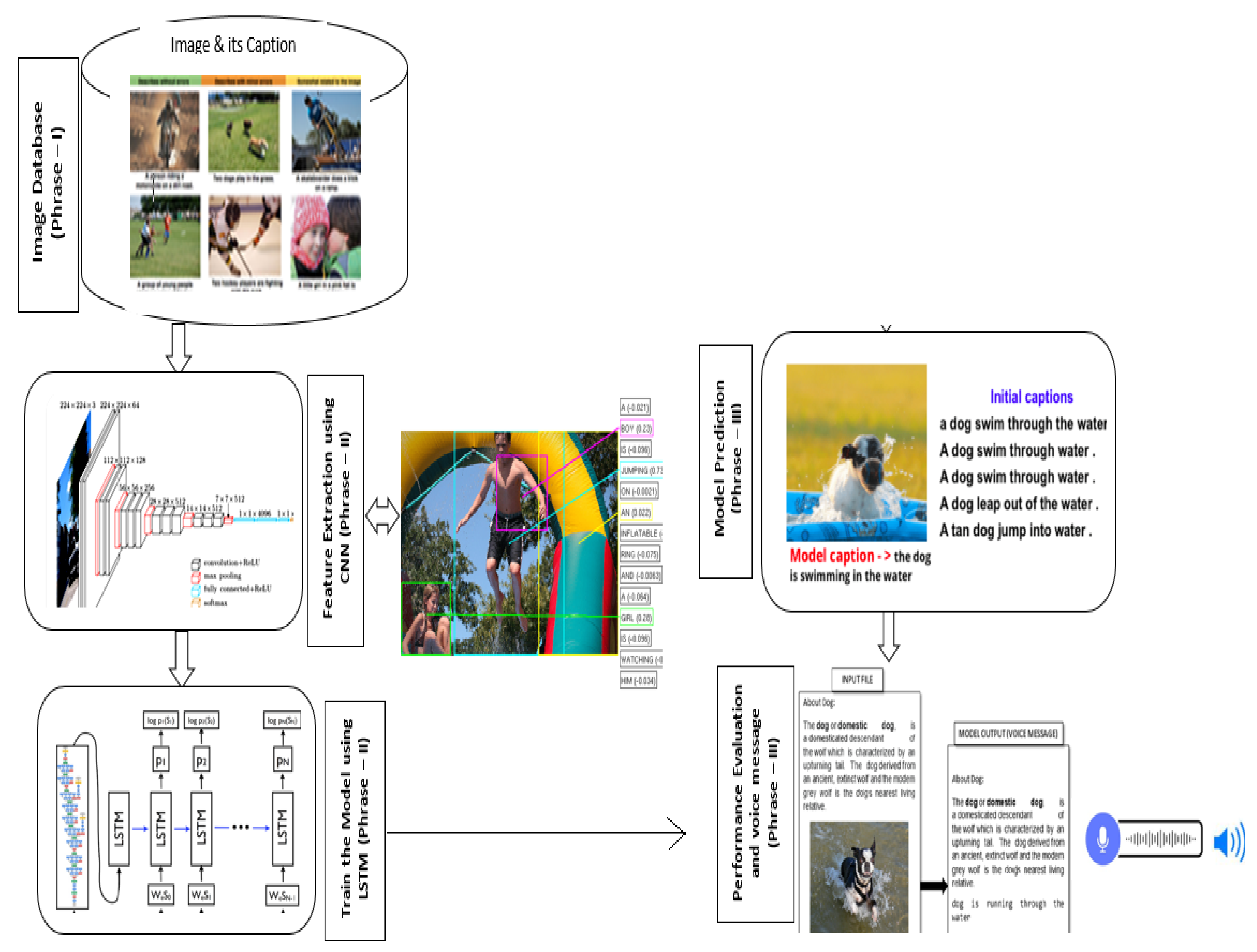
Figure 1.
The proposed intelligent reader system reads text using optical character recognition (OCR) and the Google Text-to-Speech (TTS) approach, which converts textual input into voice messages. The input images were trained with CNN-LSTM model to predicts the appropriate captions of an image and sends them to the intelligent reader system. The reader system transmits all data to visually impaired users in the form of audio messages. The proposed approach divides into three phrases: acquisition of input images, extracting features for training the deep learning model, and assessing performance. The efficiency of the constructed model is evaluated using different deep learning architectures, including ResNet, AlxeNet, GoogleNet, SqueezeNet, and VGG16. The experimental results suggest that the ResNet network design outperforms other architectures in terms of accuracy.
This paper provides the following contributions. First, it delivers an Electronic Travel Aids (ETA) vision substitution solution for people with visual impairment that includes spatial inputs such as photography or visual content. Although many studies have proposed text-to-speech solutions, this paper utilizes deep learning capabilities to describe images as well as text to a person with visually impairment. Second, it briefs the reader about most significant deep learning architectures for image recognition, along with most identified features of each architecture. Finally, this paper proposes and implements a deep learning architecture utilizing CNN and LSTM algorithms. Content is extracted from text and images with the former algorithm, and a captions are predicted with the latter.
In the recent decades, many researchers have developed an assistive device/system to read text books for people with visual impairment, which helps them enhance their learning skills without the assistance of a tutor. Reading image content is a challenging task for visually impaired students. The proposed system is unique in that it incorporates the intelligence of two deep learning approaches, CNN and LSTM, to assist people with visual impairment in reading a text book (both text and image content) without the assistance of a human. The proposed approach reads the text content in the book using OCR and then provides an audio message. If any images are presented in the text book between the texts, the system uses the CNN model to extract the features of the image, and the LSTM model to describe the captions of the images. Following that, the image captions are translated into voice messages. As a result, visually challenged persons understand the concept of the text book without any ambiguity. The suggested method combines the benefits of OCR, CNN, LSTM, and TTS to read and describe the complete book content through audio/voice message.
The rest of the paper is structured as follows:
Section 2 covers previous proposed solutions available for visual impairment. The preliminaries of various architectures in Deep learning approach is explained in
Section 3. Then, the empirical findings and model evaluation are detailed in
Section 4. We conclude this endeavour in
Section 5 with concluding remarks and future work.
4. The Proposed CNN-LSTM Design
The proposed approach involves feeding the input file into the intelligent reader system, which utilizes an Optical Character Recognition (OCR) tool that scrutinizes the file’s contents and Google Text-to-Speech (TTS) technique adapts written input into voice responses. When a file has images, the trained CNN-LSTM model predicts the related captions, which are forwarded to the intelligent reader system. The reader system passes on all data in the form of voice messages. The proposed system is divided into three phases: collecting input images, extracting features for training the deep learning model, and evaluating performance. Such an approach aims to ease concerns over predicting sequences, including spatial inputs such as photography or visual content.
Figure 5 depicts the suggested CNN-LSTM model’s architecture.
Phase 1 (Input Image Collection): The input images are collected and preprocessed. In this research, Flickr 8K dataset, which comprises images and associated human descriptions, is utilised for model training.
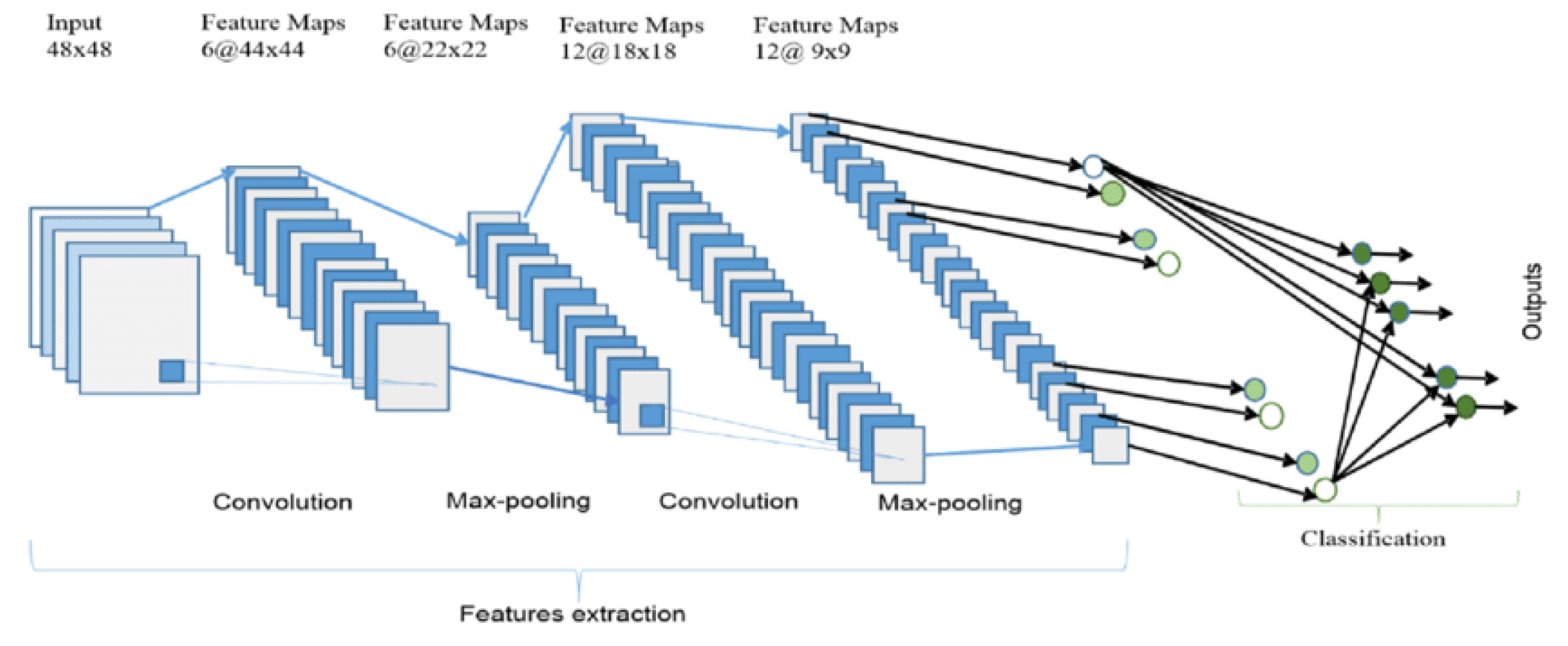
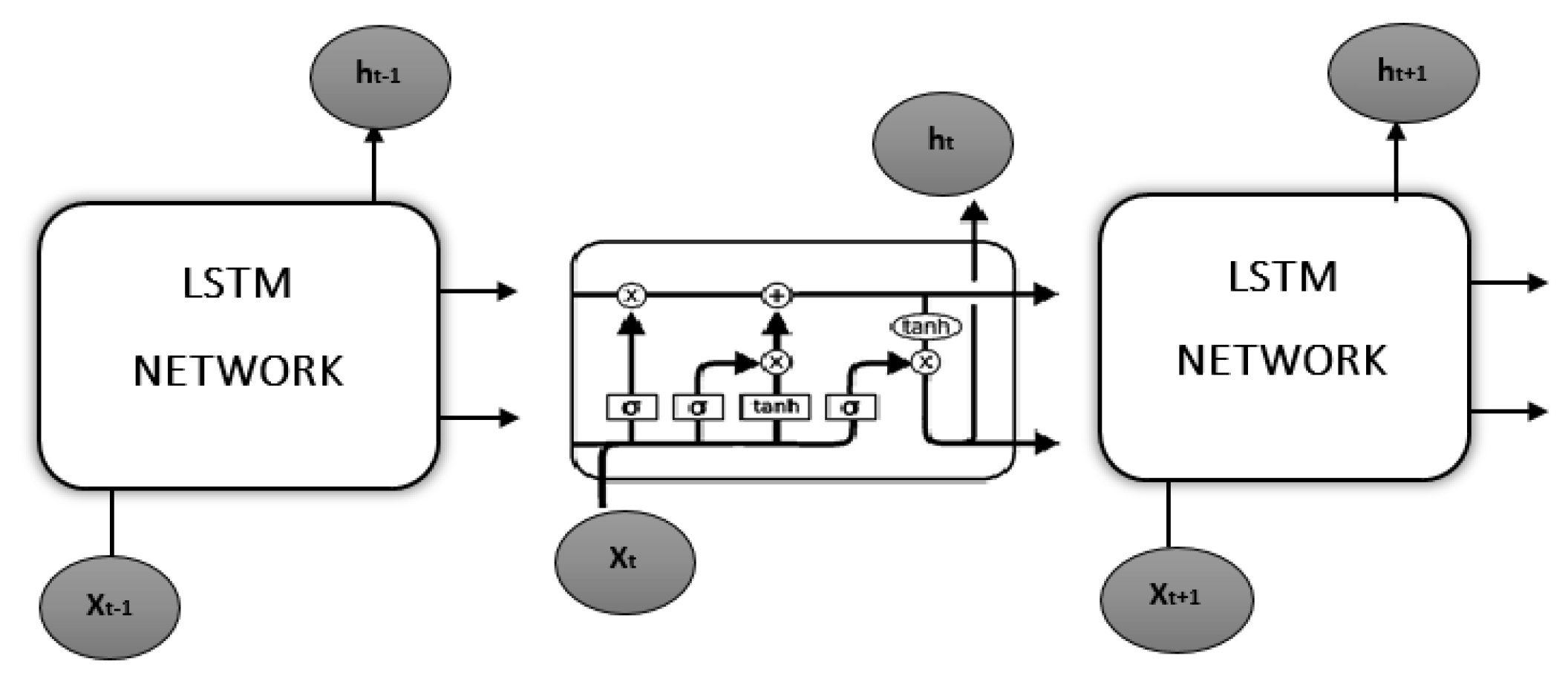
Phase 2 (Model Training): It consists of two main parts: feature extraction and a language prediction model built with two deep learning techniques: Convolutional Neural Network (CNN) and Long Short Term Memory (LSTM). CNN is a sub component of the Deep Learning approach and customized deep neural networks that are used for image classification and recognition. Images in CNN model are represented as a 2D matrix that can be scaled, translated, and rotated. The CNN model analyses the images from top to bottom and left to right, extracting salient features for image categorization. In this network architecture the convolutional layer with 3 × 3 kernels is utilised for feature extraction with ReLU active function. To minimise the dimensions of an input picture, the max-pooling layer with a size of 2 × 2 kernels is utilised. The extracted features will be put into the LSTM model, which will provide the image caption. LSTM is a subsection of Recurrent Neural Networks (RNN) that was created to solve sequence prediction issues. The output from the last hidden state of the CNN (Encoder) is fed as the input of the decoder. Let
= <START> vector and the required label
= first word in the sequence. In the same way consider
= word vector of the first word and expect the network to identify the next word. Lastly,
= last word, and
= <END> token. The visualization of language prediction model is depicted in
Figure 6.
The language model takes the image pixels i and the input word vectors is denoted as (
,
,…,
), and determines the series of hidden states (
,
,…,
) that produce the outputs (
,
,…,
). As the initial hidden state ht, the image feature vectors are only transmitted once. As a result, the image vector I the previously hidden state
, and the current input
are used to determine the next hidden state. A softmax layer is used on the specified hidden state activation function to generate the current output
.
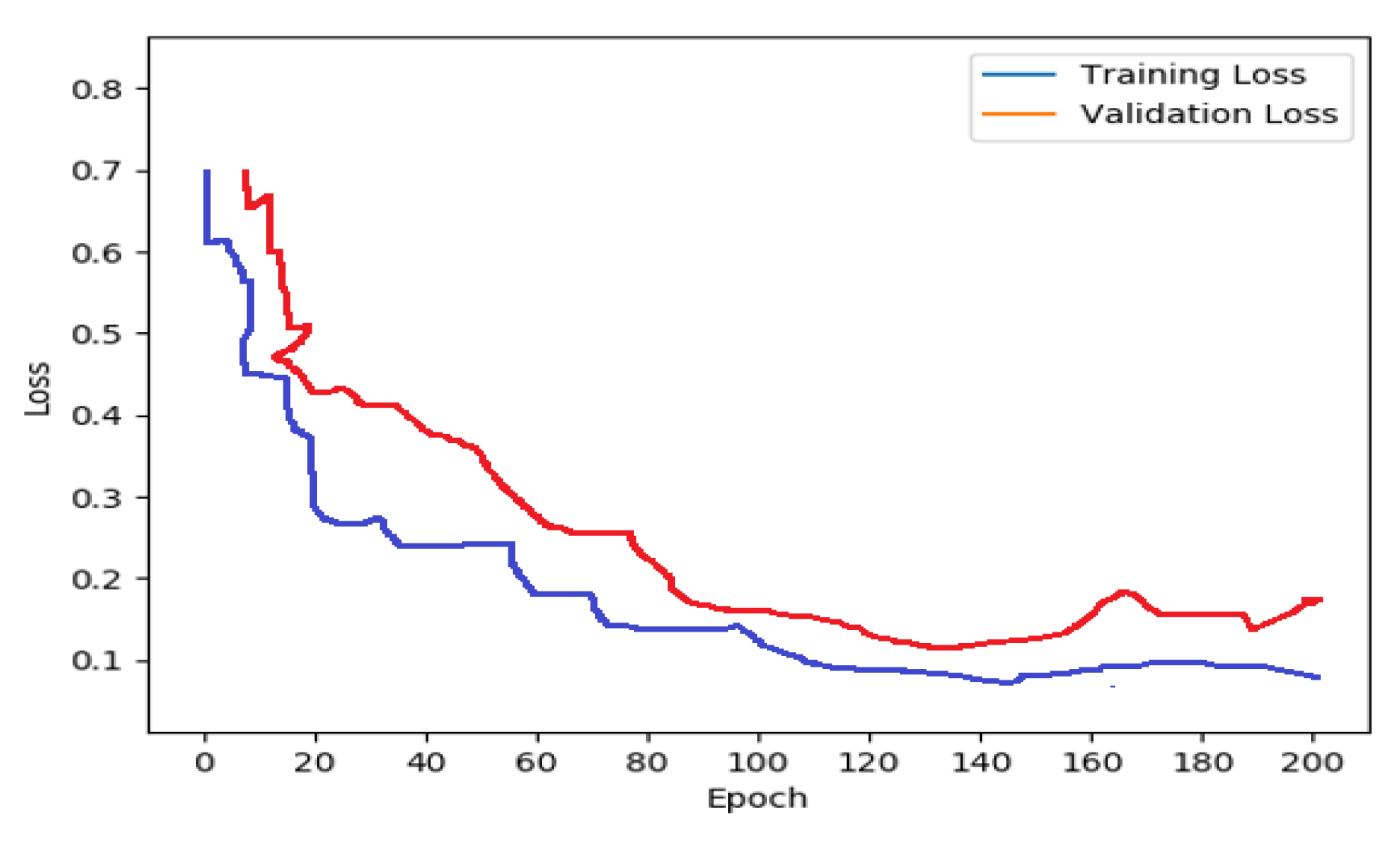
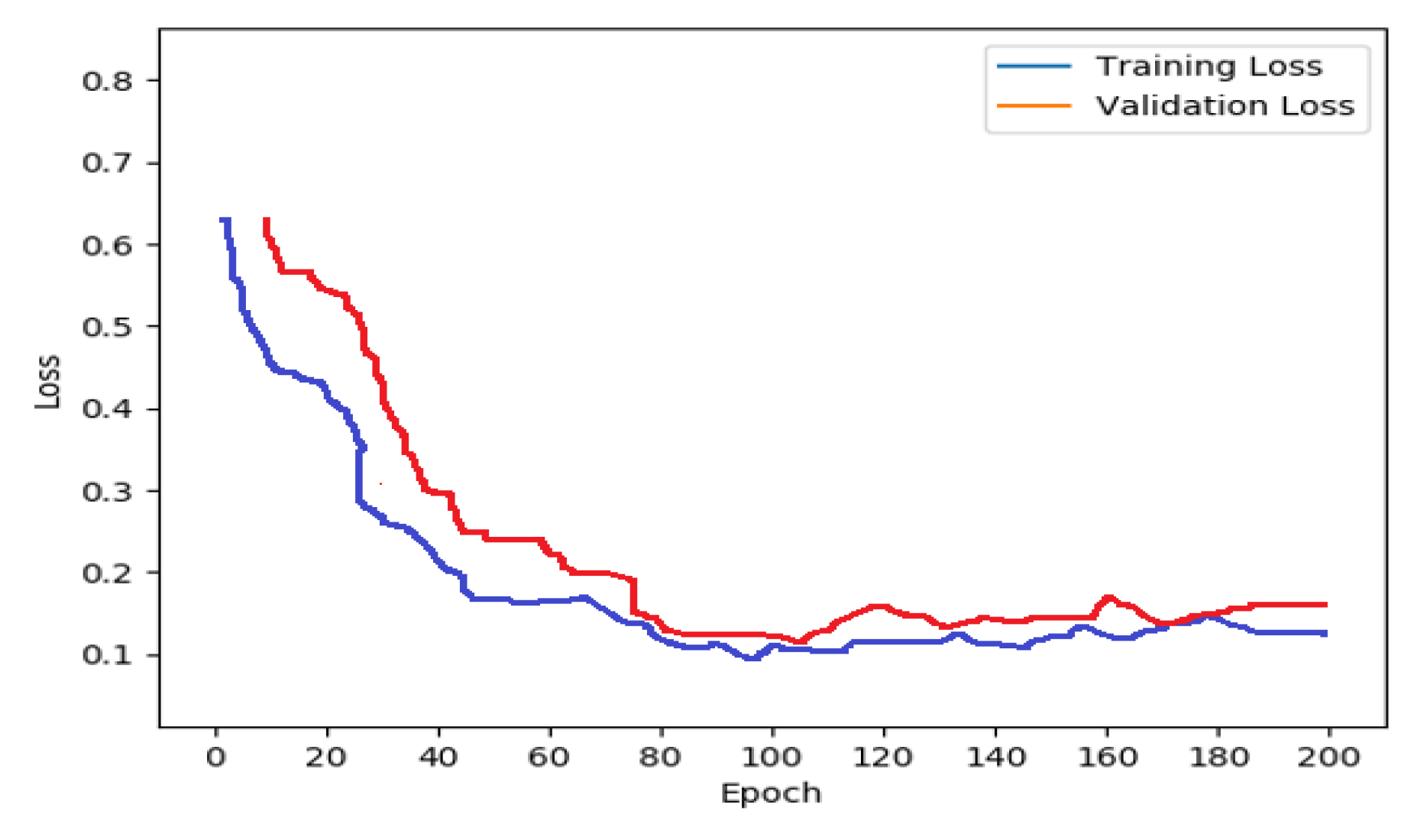
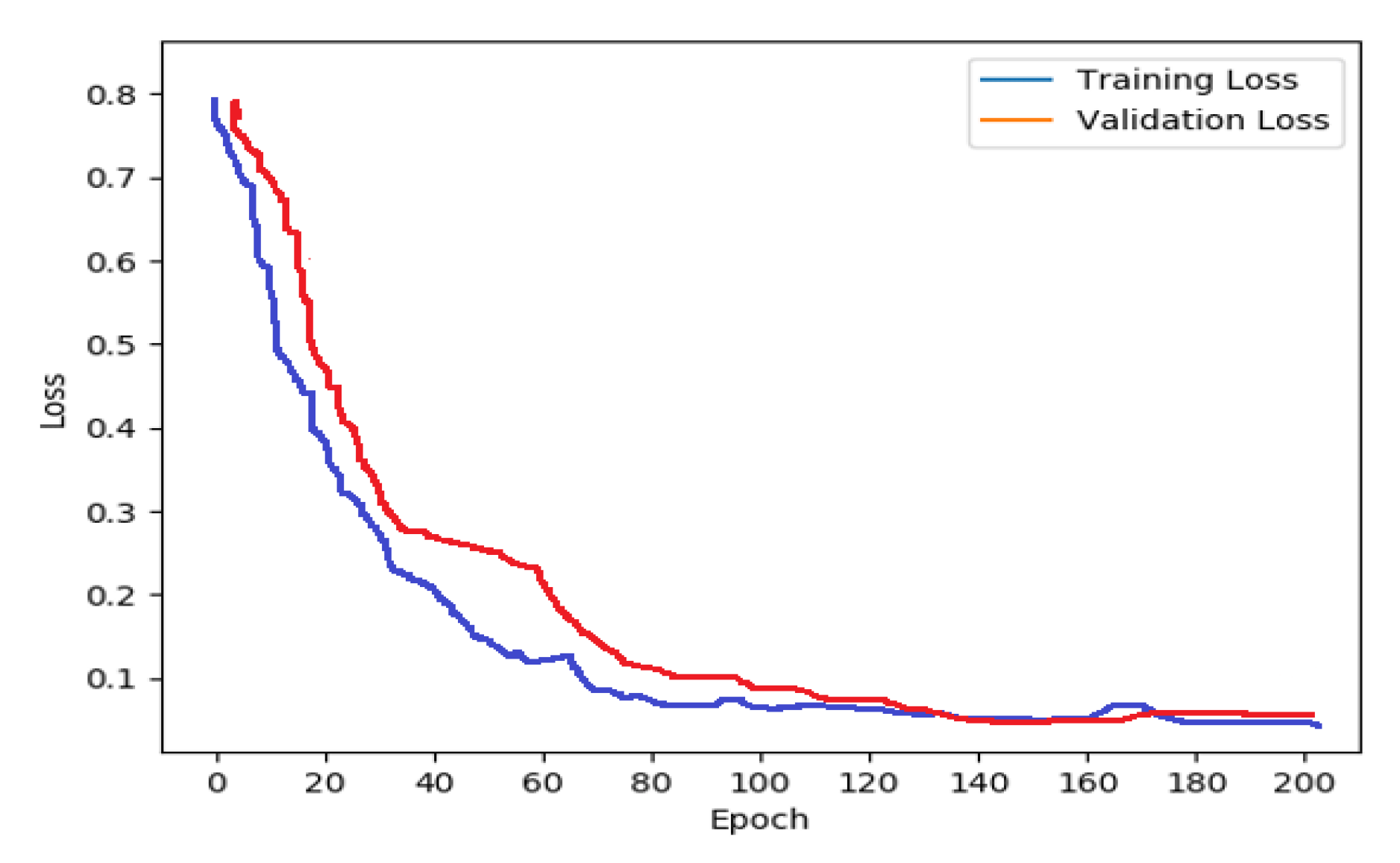
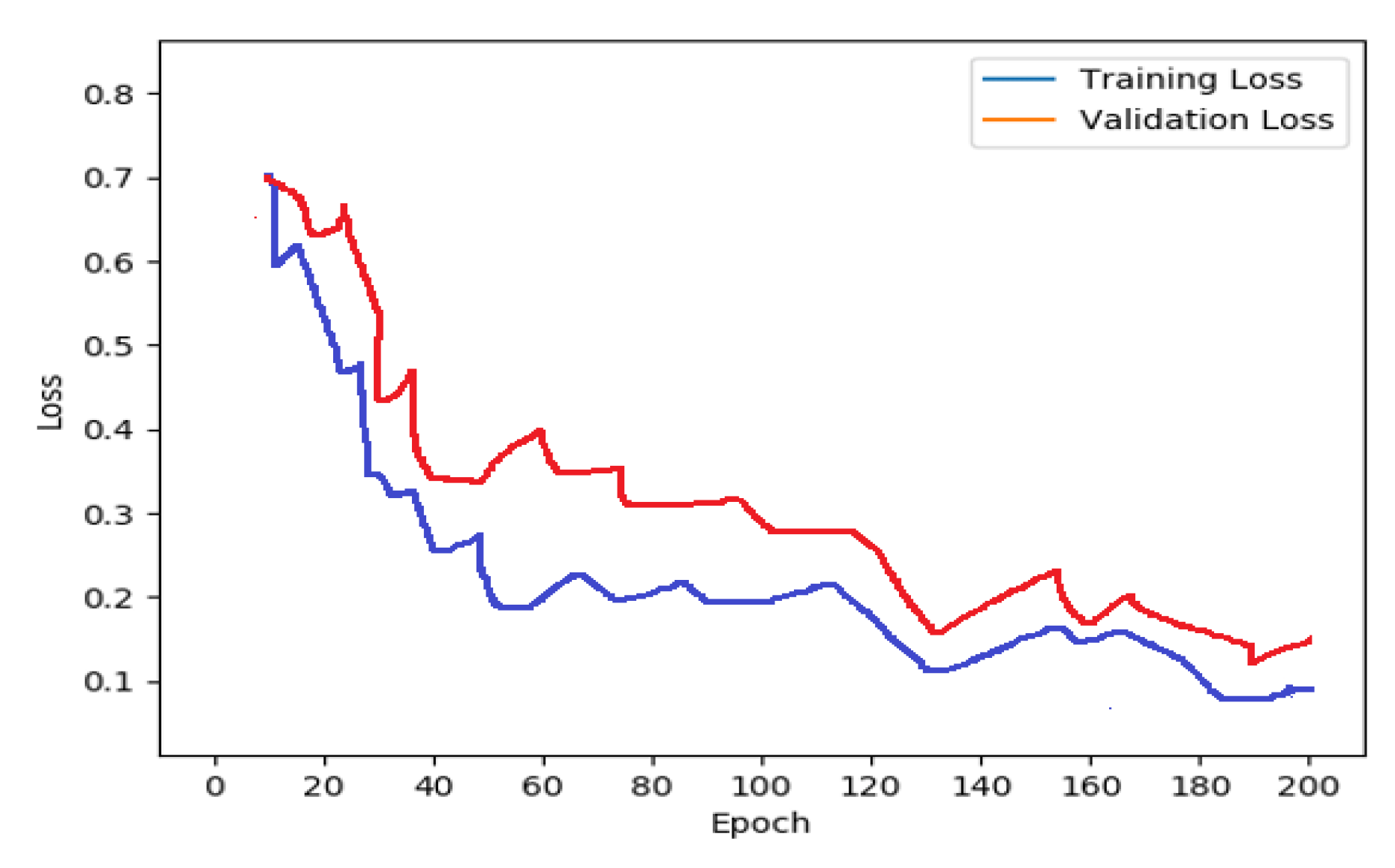
The CNN-LSTM is a deep learning architecture that combines two algorithms: CNN and LSTM. The salient features of the input images are extracted to predict sequences, and the latter predicts captions. The developed deep network model is evaluated using various architectures including ResNet, AlexNet, GoogleNet, SqueezeNet, and VGG16. Phase 3 (Testing): In phase 3, the trained model is tested using the test dataset. The CNN-LSTM model predicts the caption sequence from the test image. The proposed approach’s efficiency is determined using metrics such as BLEU, precision, recall, and accuracy. Using Google Text-to-Speech API, the output captions are turned into audio messages. The intelligent reader system based on deep learning enables people with visual impairment to easily understand text as well as images displayed in text content.


 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







