
Many-to-Many Data Aggregation Scheduling Based on Multi-Agent Learning for Multi-Channel WSN


Abstract
:1. Introduction
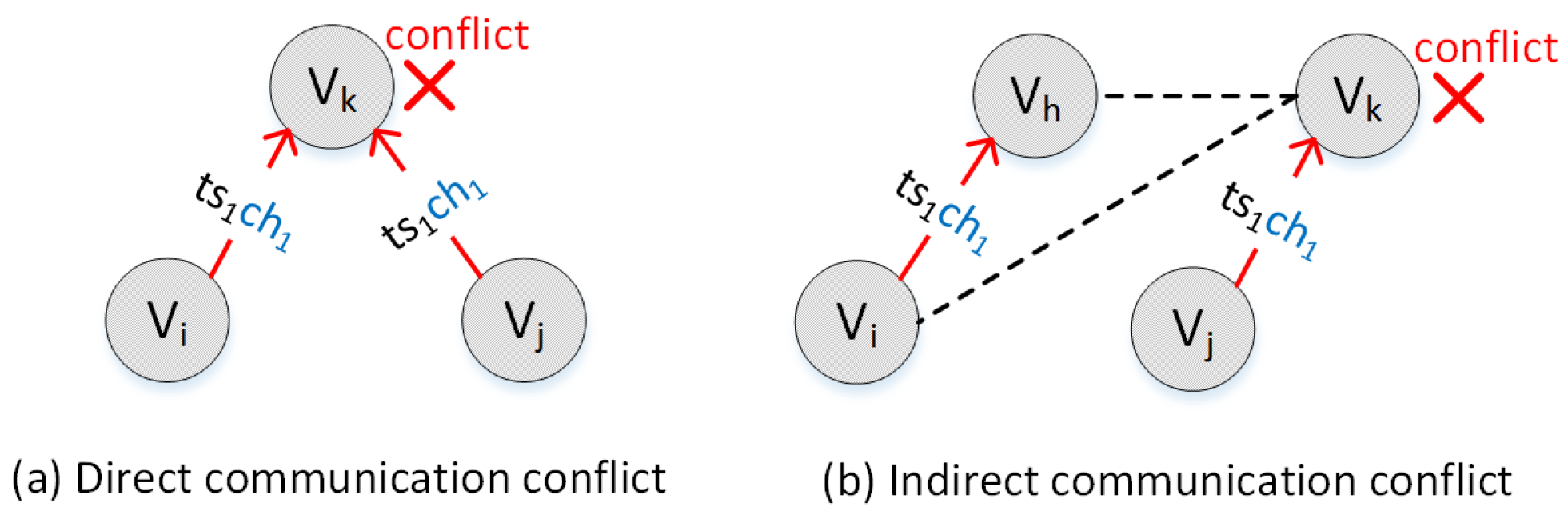
- Multi-channel WSN environment has been, firstly, introduced into the research of many-to-many data aggregation scheduling up to now. The characteristics of this new type of scenario are sufficiently considered in this paper, such as that an intermediate node is probably assigned to multiple transmission times, and some communication conflicts can be avoided by switching channel.
- The scheduling process of many-to-many data aggregation in a multi-channel WSN is formulated to decentralized, partially observable Markov decision process, as a result of summarizing its distinguishing features of wireless communication. A multi-agent is viewed as the nodes participating in wireless communication, and the system state cannot be accurately obtained by agents.
- Cooperative multi-agent learning is introduced to implement a new distributed scheduling method. Thanks to the property of group observability, a group of sensor nodes within one hop can attempt different behaviours and receive corresponding feedback. After accumulating adequate experience, sensor nodes learn the best action strategy and select the most efficient time slot and channel for wireless communication.
2. Related Works
3. System Model and Problem Statement
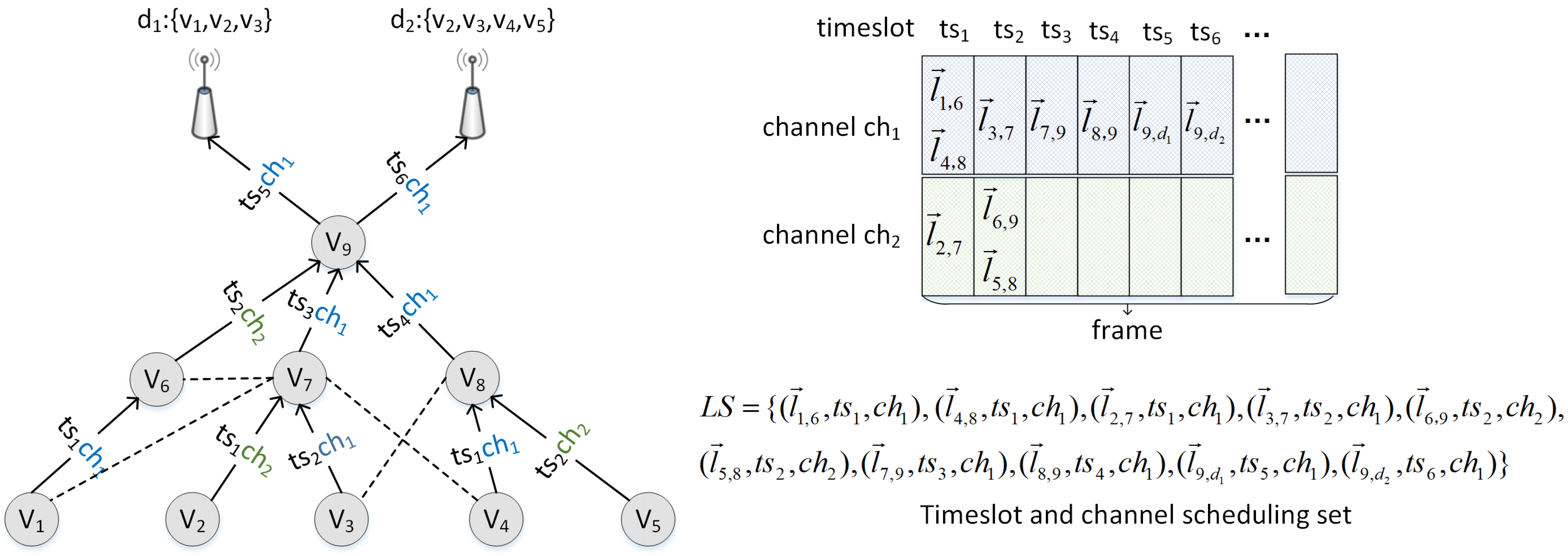
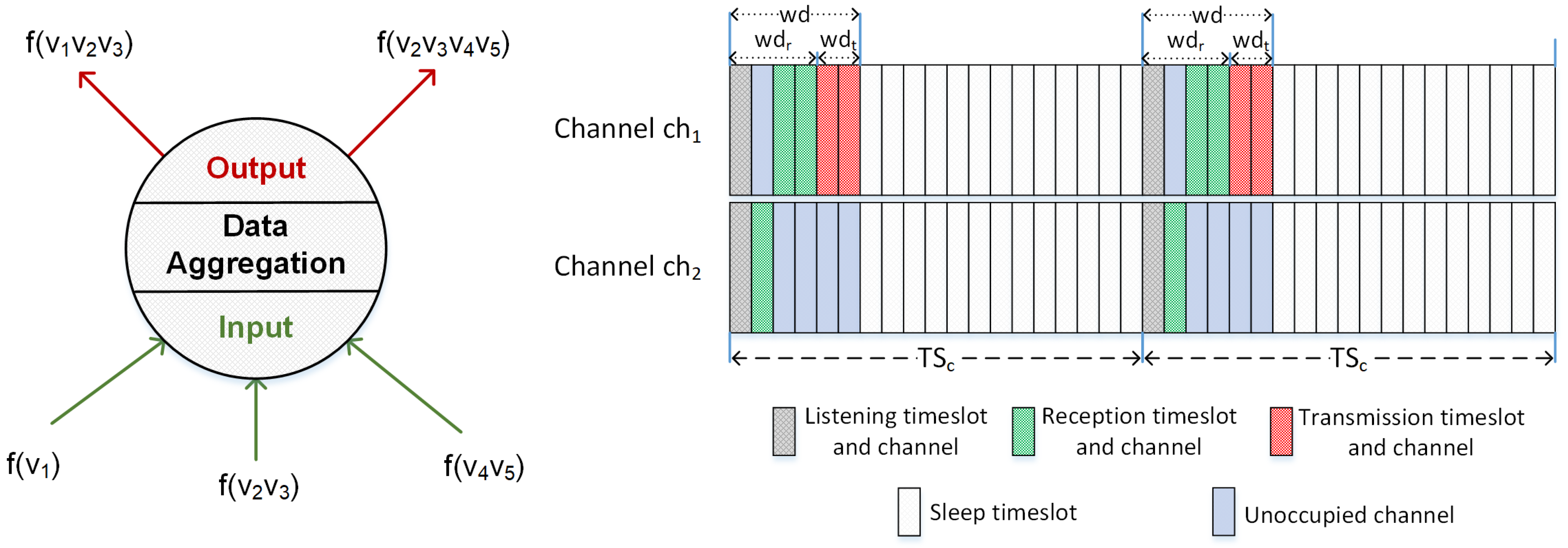
3.1. System Model
3.2. Optimization Objective
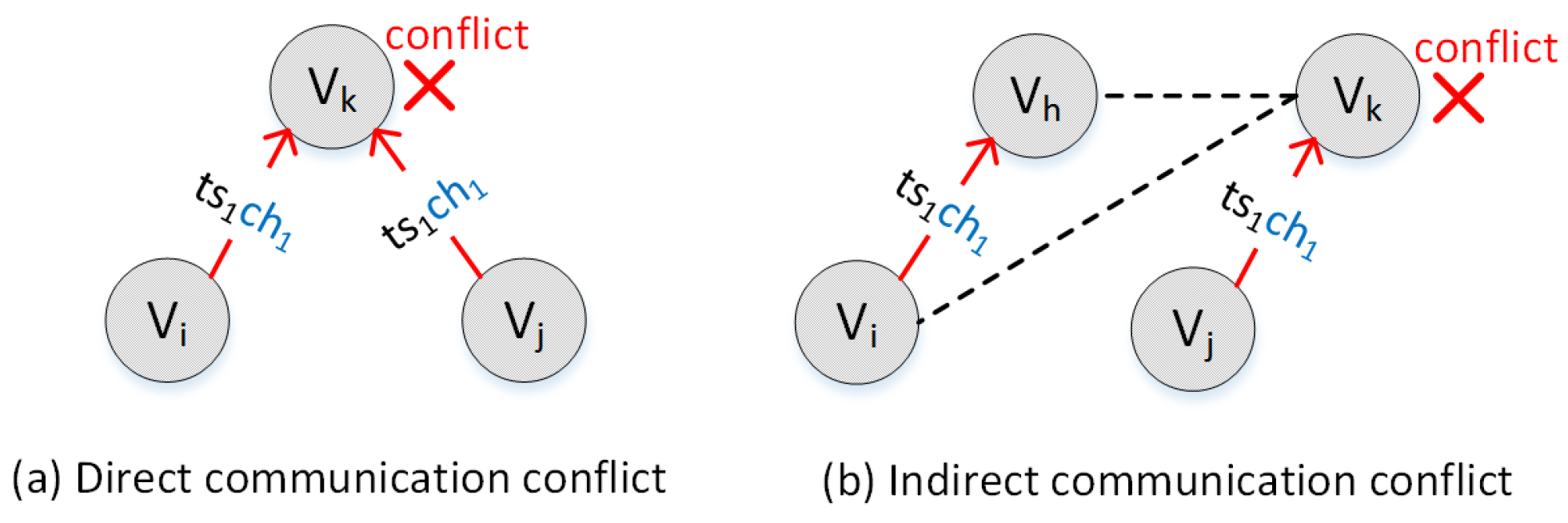
- If , or , then or
- If , and , then or
3.3. Decentralized Partially Observable Markov Decision Process
- is the set of agents; one sensor node participating in communication is viewed as one agent.
- is a finite set of system or joint states where is the state set of the agent, which reflects whether the reception and transmission of packets on this node is successful, and this information cannot be accurately acquired due to the environment of wireless communication.
- is a finite set of joint actions where is the action set of the agent. The change in scheduling for time slot and channel is realized by modifying the tuple mentioned before .
- is the transition function which denotes the probability of transitioning from the state to the new state when taking the joint action .
- is the reward function which denotes the immediate reward when taking the joint action at the state .
- is a finite set of joint observations, is the individual observation set of the agent, where a joint observation is . One observation contains the size and number information of the successfully received and transmitted packets, and this information is part of the acknowledgement packet.
- is the observation function which denotes the probability of observing when the system state transfers to by taking the joint action . Due to the wireless communication environment, the observation result may not truly reflect the system state, because the reception of ACK cannot ensure no error is contained in transmission data; meanwhile, not receiving ACK also cannot determine whether the receiving node did not obtain data.
- is the initial system state distribution (also called the initial belief), for the system state , where is the initial state distribution over .
- T is the finite horizon or the number of time steps in which an agent can interact with Dec-POMDP model.
4. Many-to-Many Data Aggregation Scheduling Based on Multi-Agent Learning
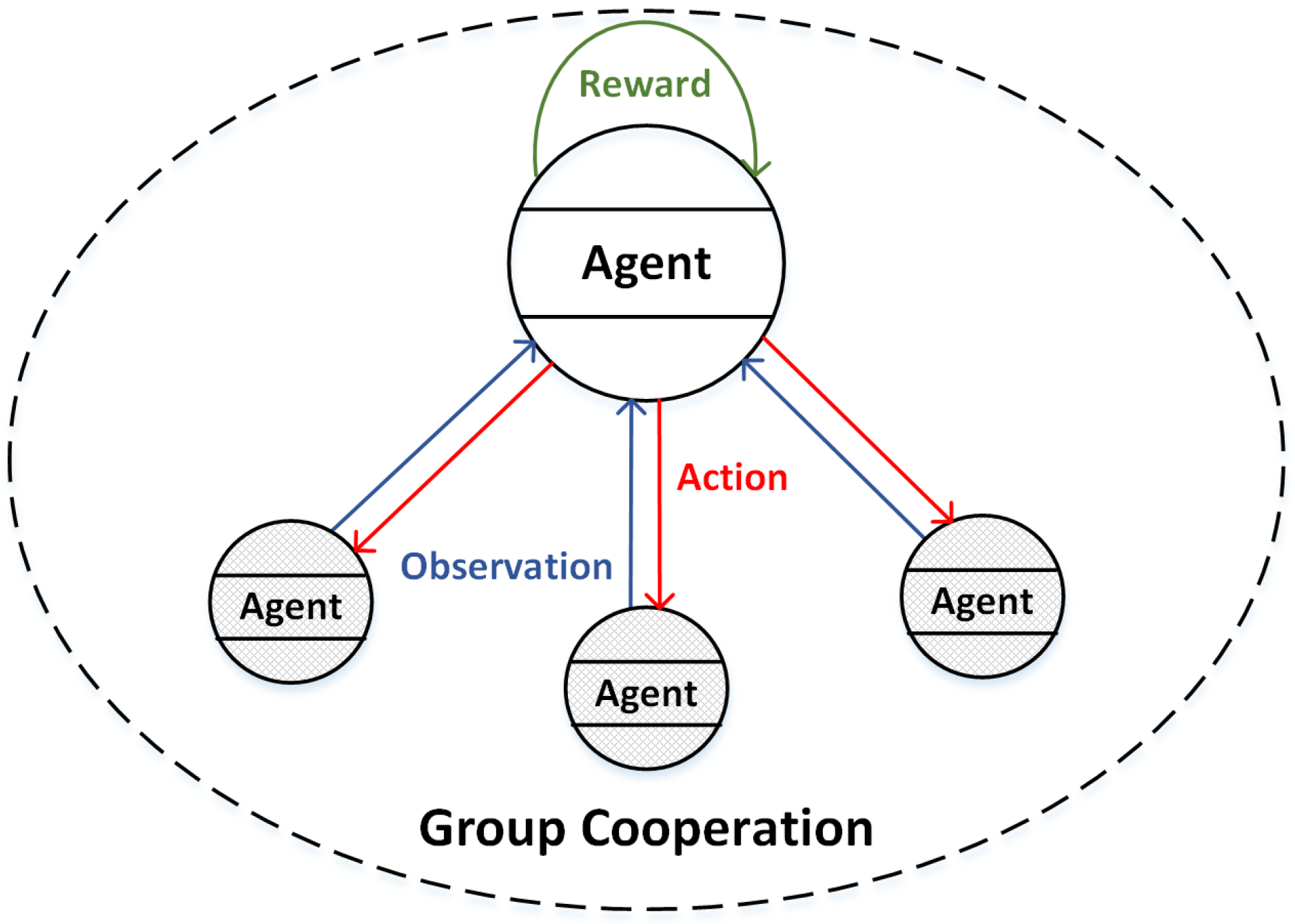
4.1. Group Cooperation
4.2. Reward Function
4.3. Action Policy
4.4. Many-to-Many Data Aggregation Scheduling Procedure
| Algorithm 1 Many-to-many data aggregation scheduling procedure. |
|
4.5. Theoretical Analysis
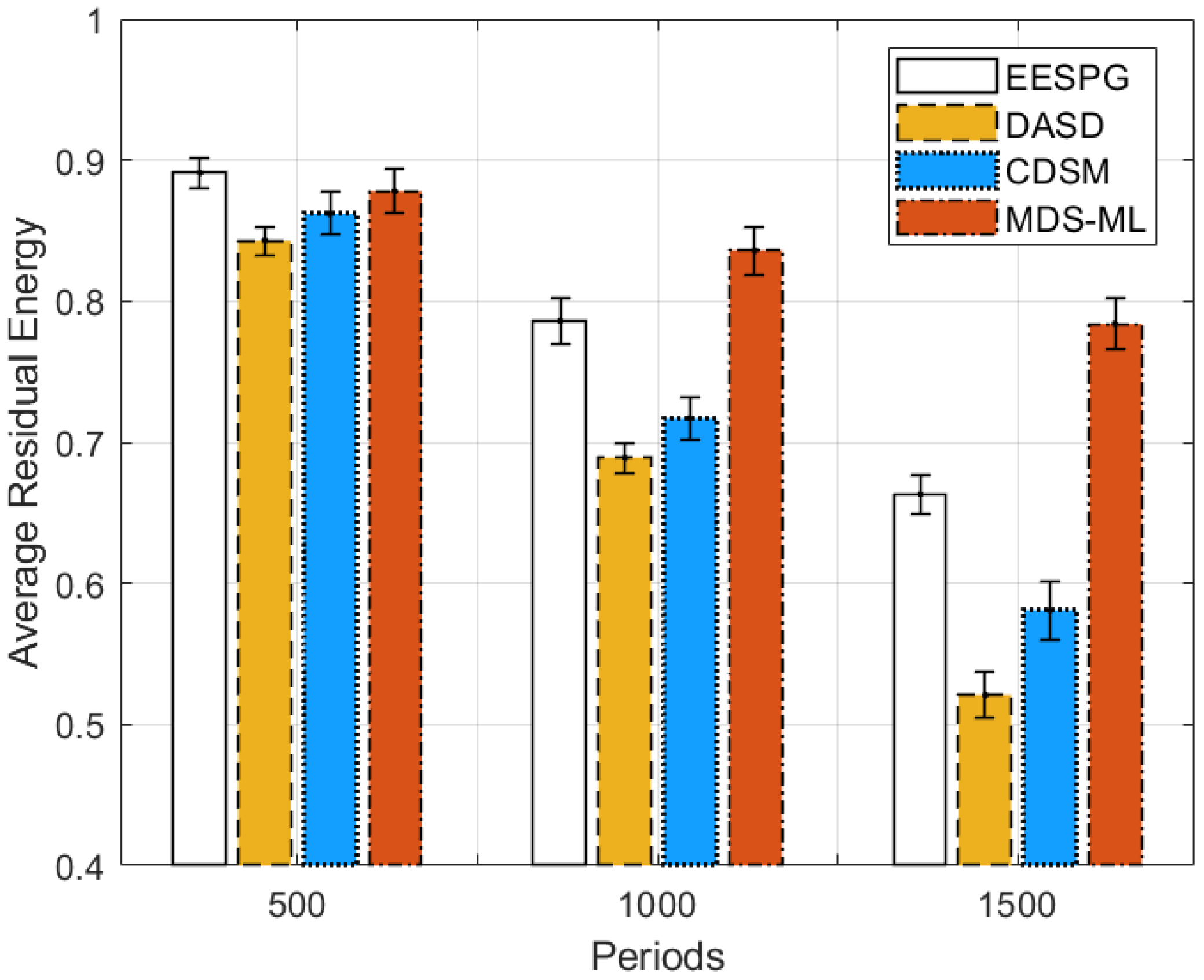
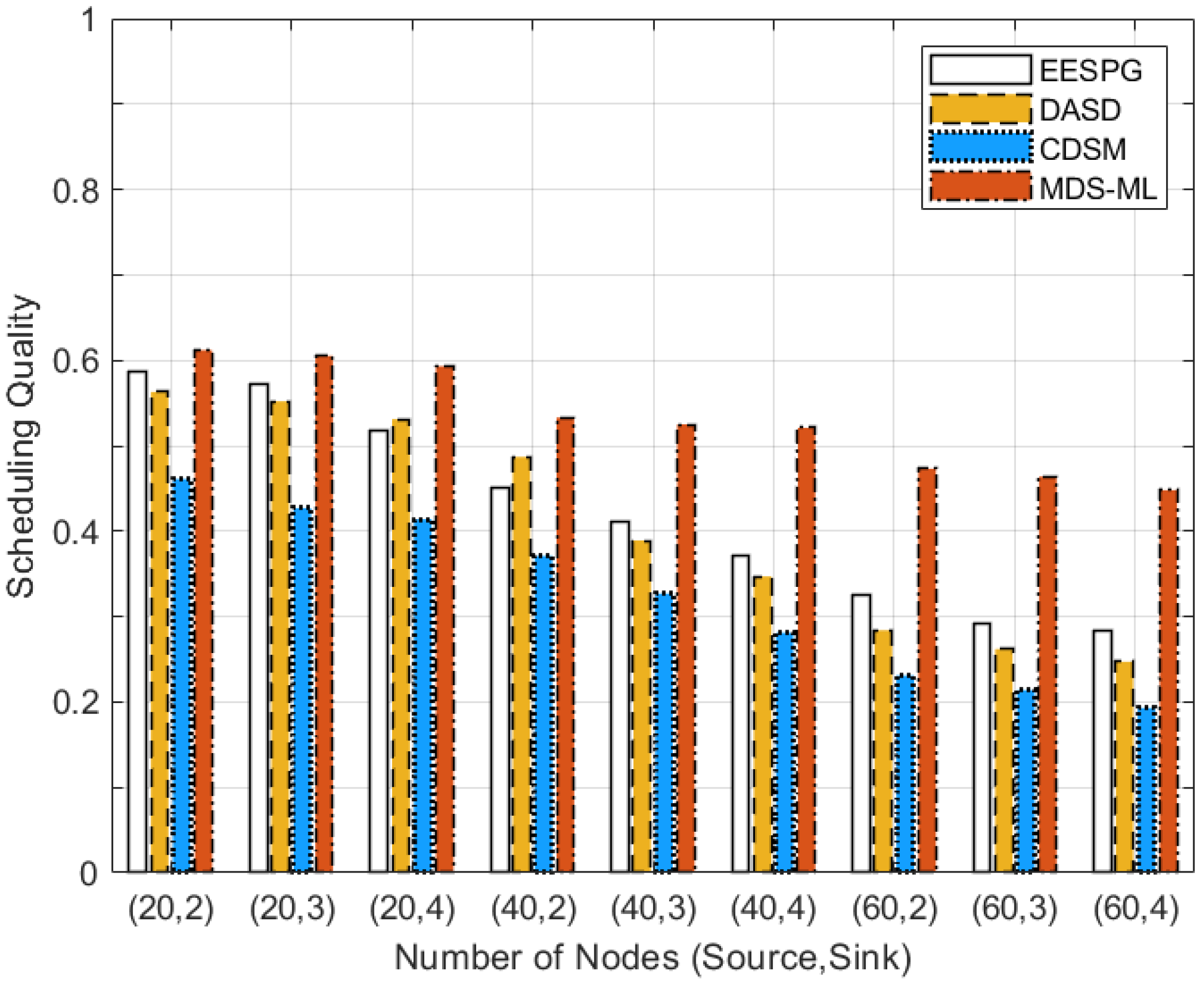
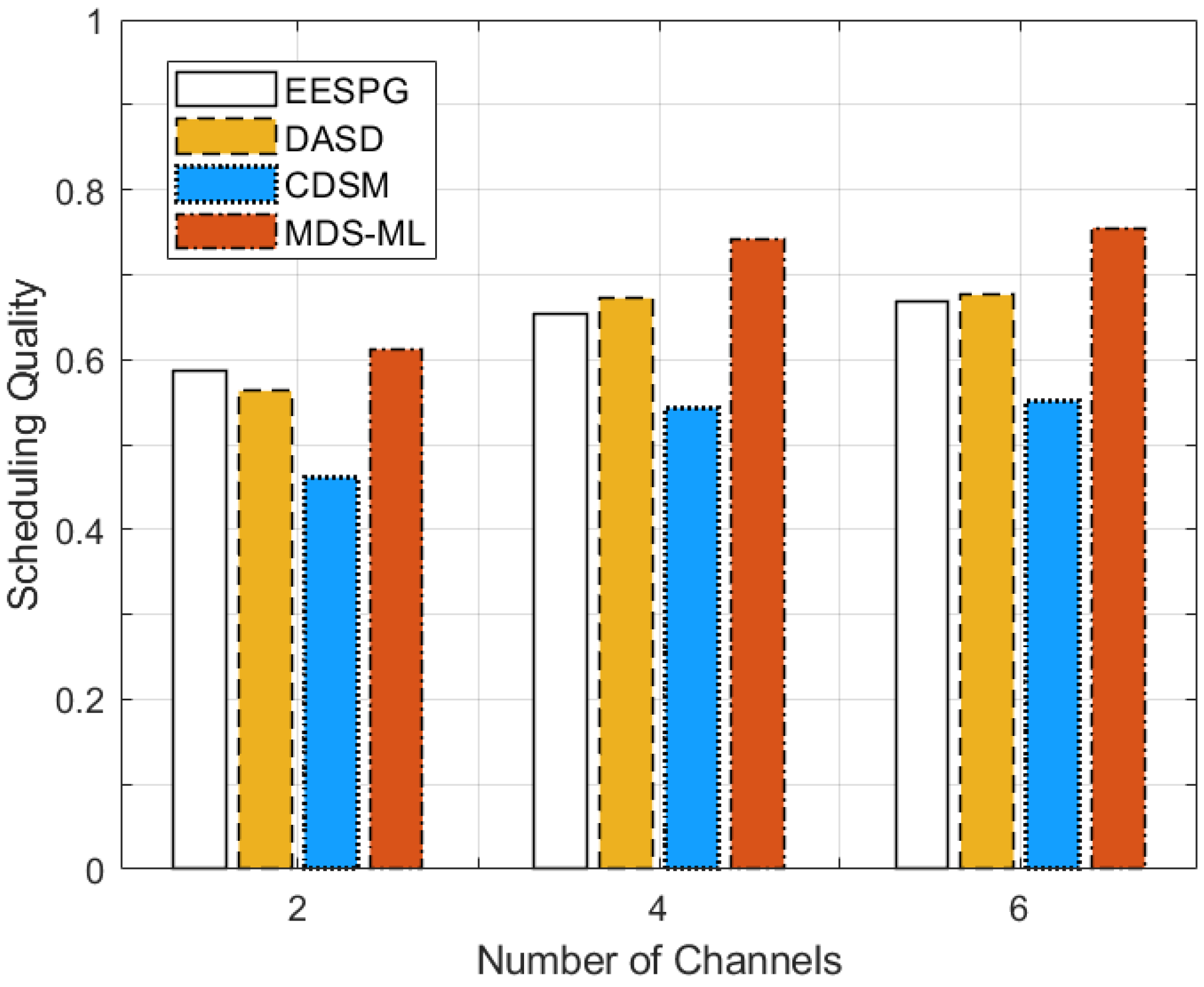
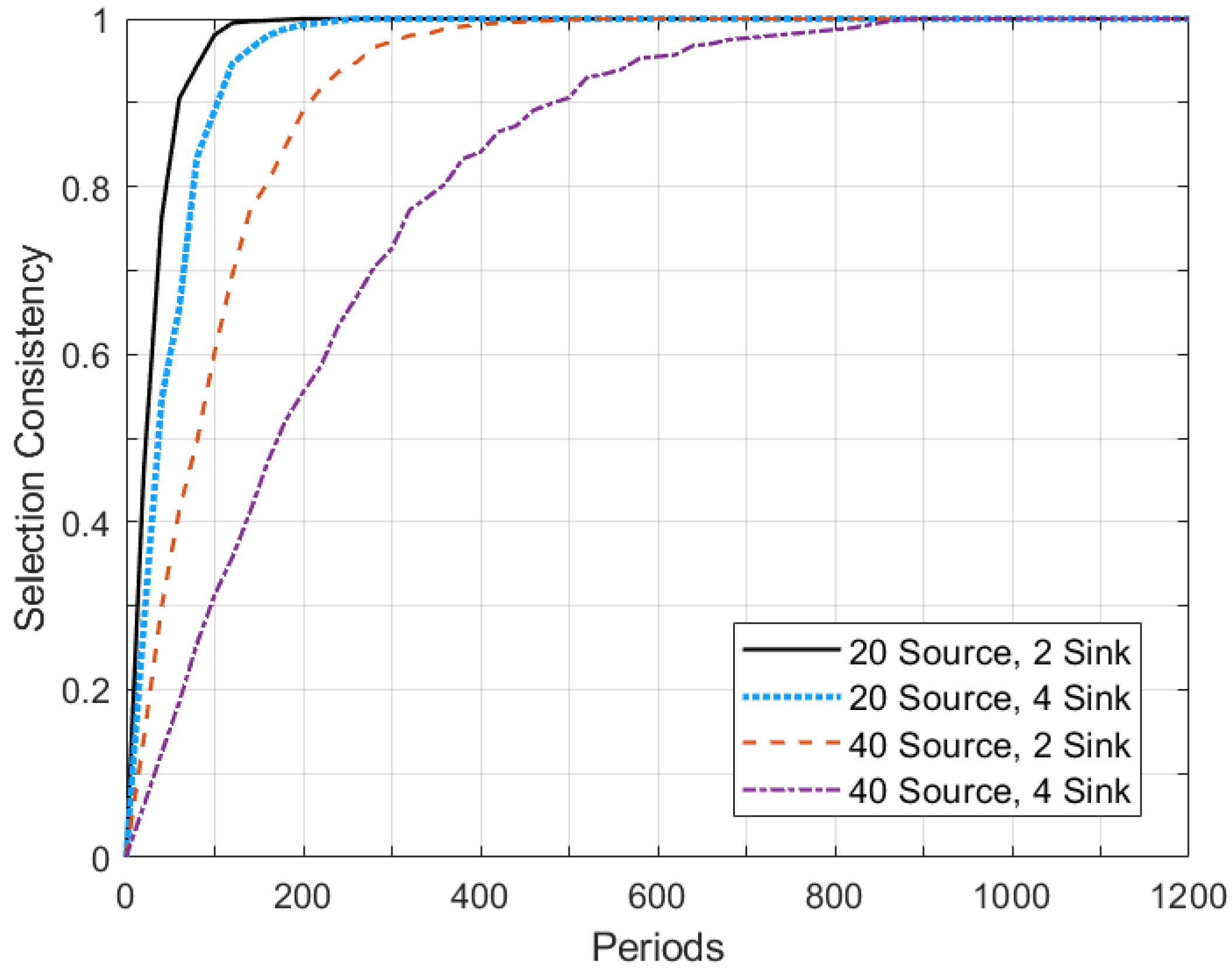
5. Simulation Results and Performance Evaluation
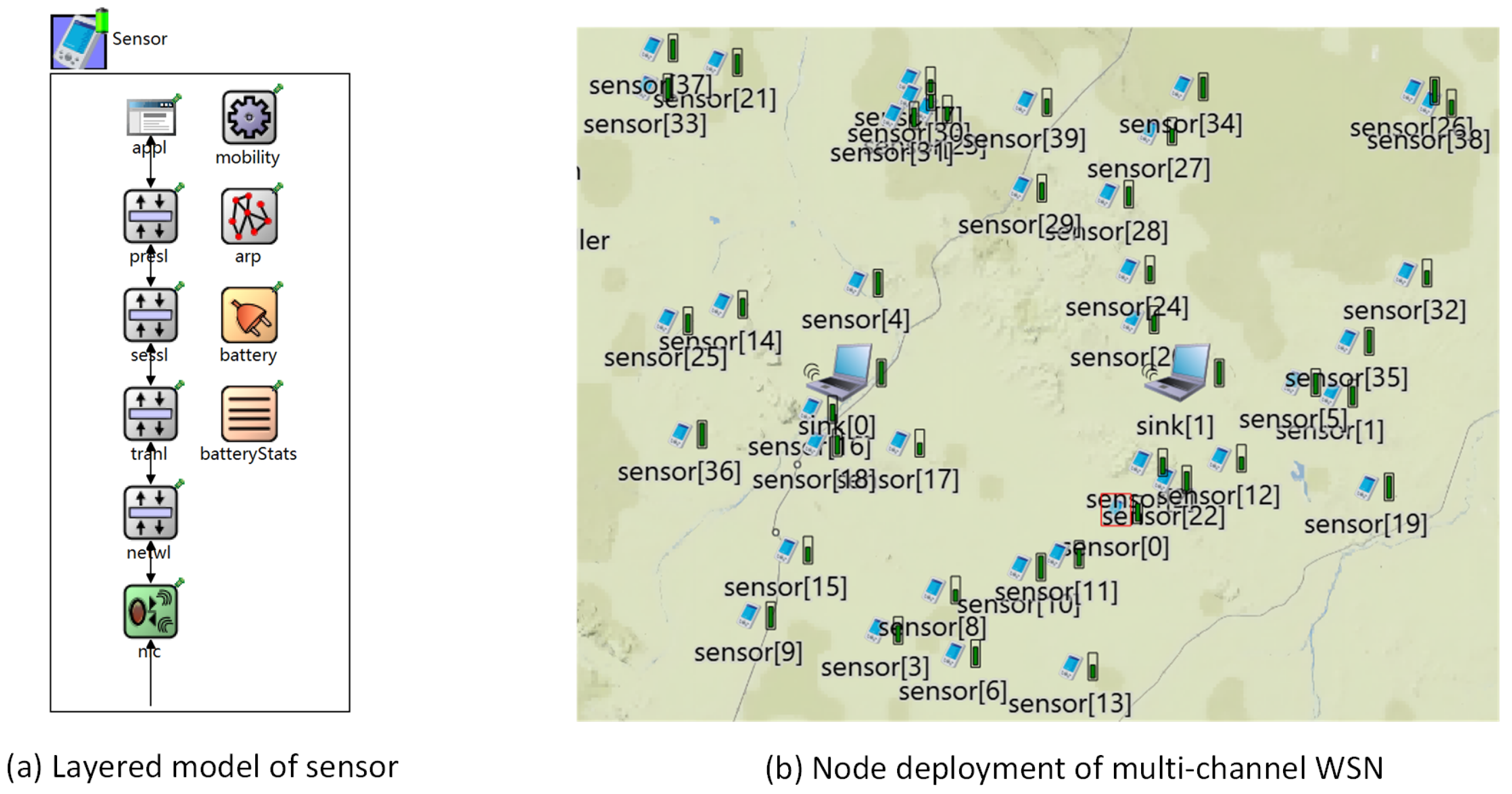
5.1. Simulation Setting
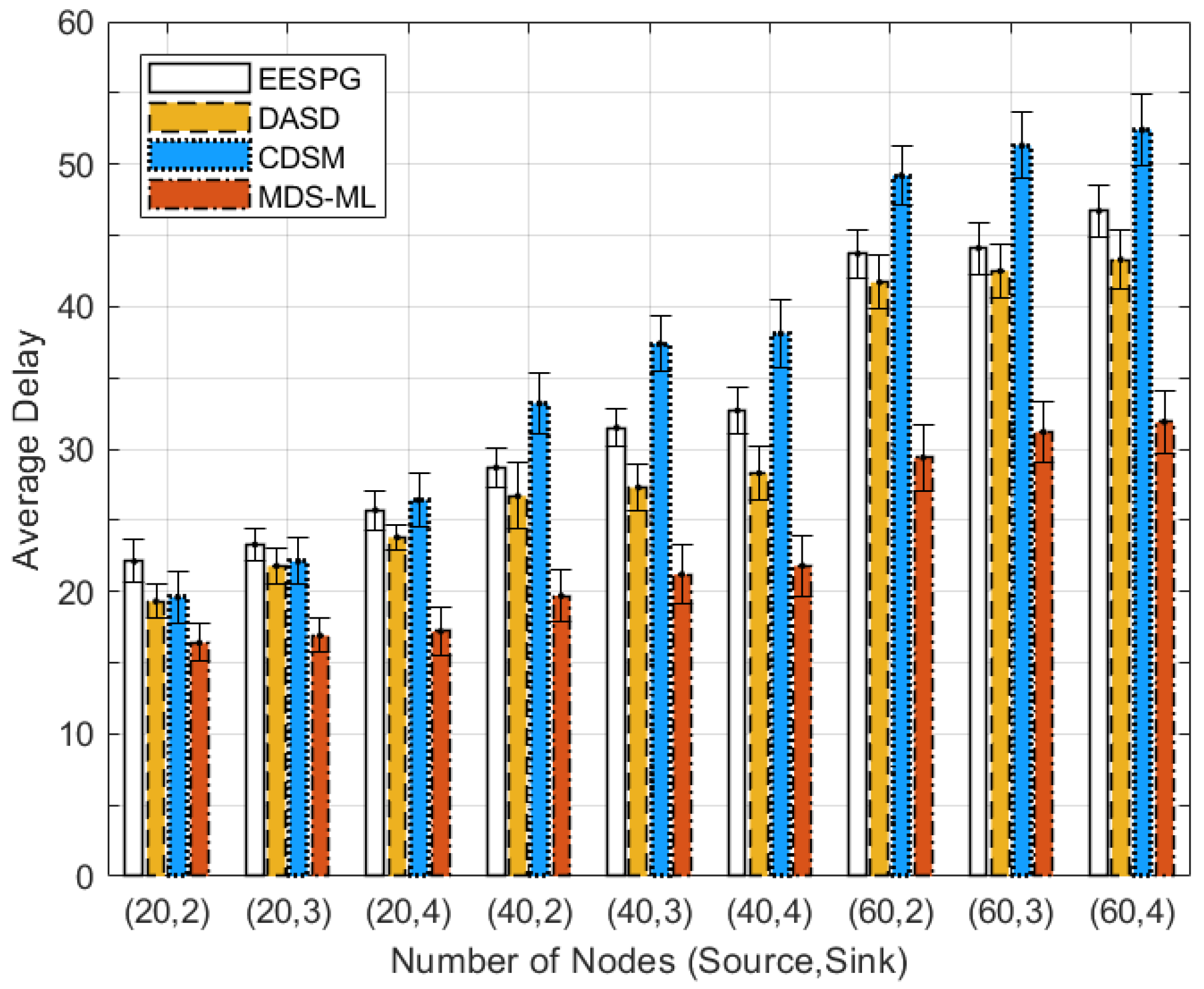
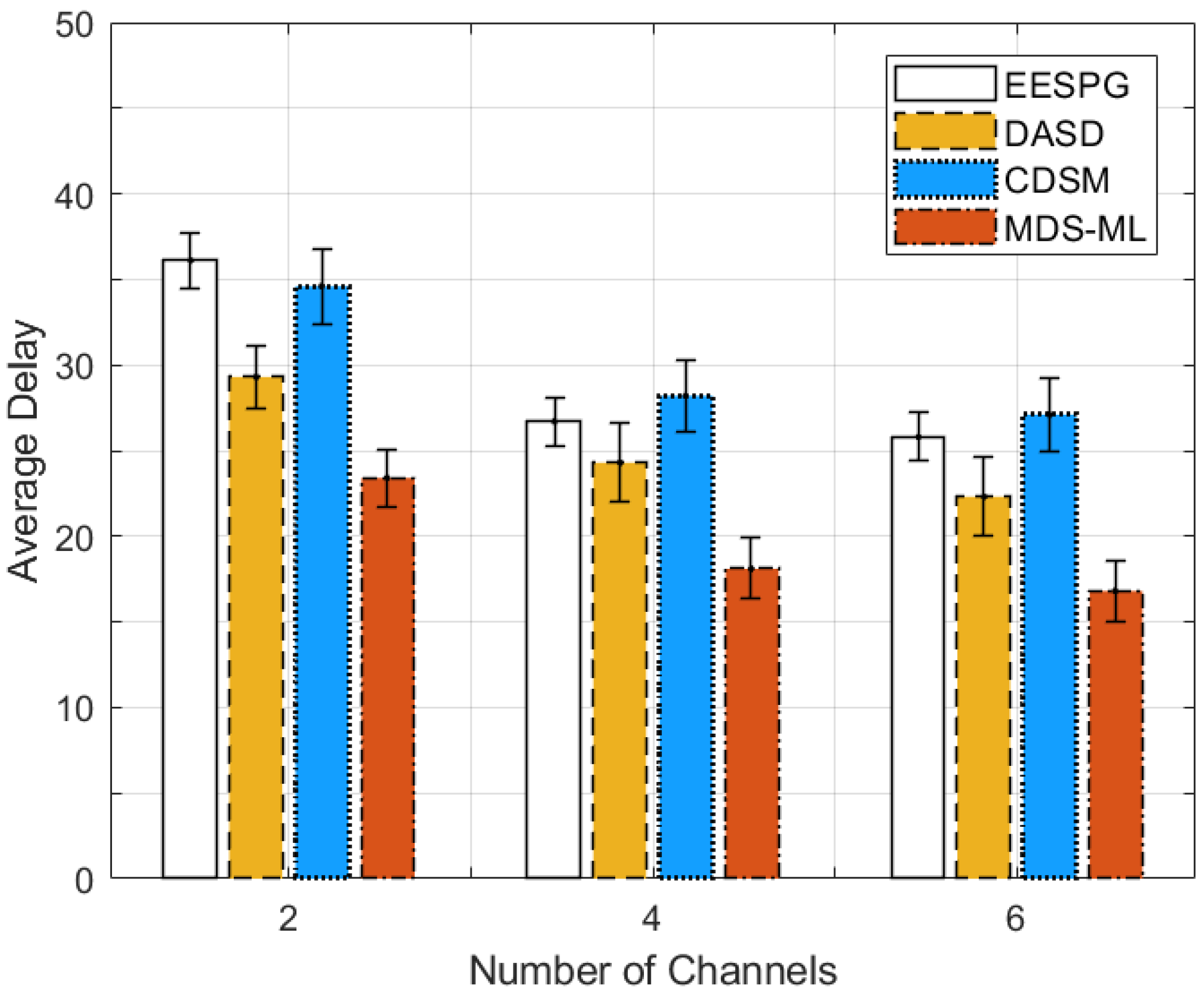
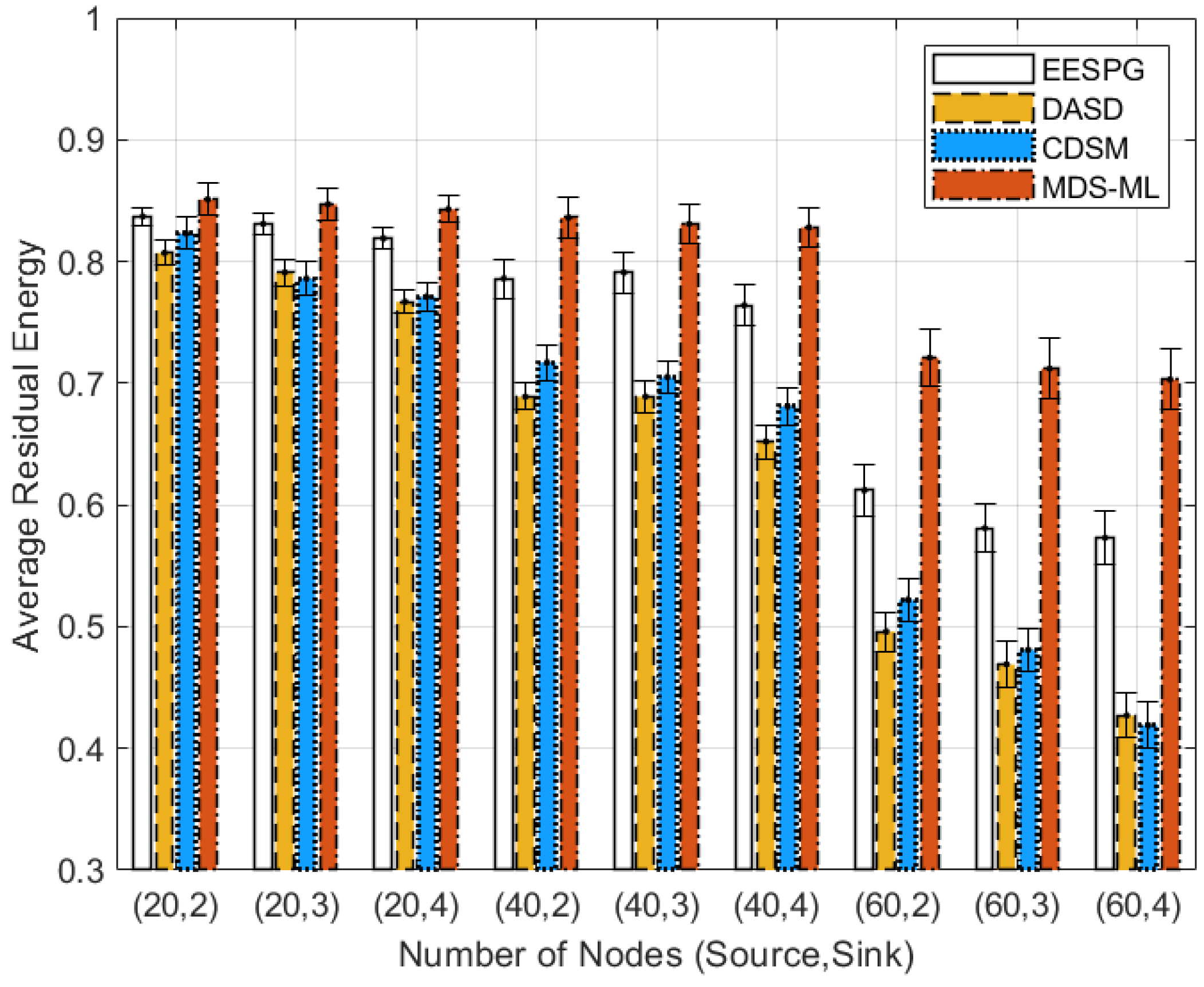
5.2. Performance Evaluation
5.3. Discussion of Simulation Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Description |
|---|---|
| WSN | Wireless sensor network |
| IOT | Internet of Things |
| HVAC | Heating, ventilation, and air conditioning |
| TDMA | Time division multiple access |
| Dec-POMDP | Decentralized partially observable Markov decision process |
| ACK | Acknowledgement |
| DCOP | Distributed constraint optimization |
| MDS-ML | Many-to-many data aggregation scheduling based on multi-agent learning |
| EESPG | Energy efficient scheduling in WSN for periodic data gathering |
| DASD | Data aggregation scheduling method for multi-channel duty cycle WSN |
| CDSM | Cluster-based distributed data aggregation scheduling algorithm |
| with multi-power and multi-channel |
Appendix B
| Symbol | Description |
|---|---|
| V | The set of sensor nodes |
| Sensor node i | |
| The set of communication links | |
| Link from node i to node j | |
| The neighbor nodes of node i | |
| The set of available wireless channels | |
| Channel k | |
| Sink node i | |
| Communication period (or a frame) | |
| Time slot | |
| The upstream nodes of node i | |
| The downstream nodes of node i | |
| The link based scheduling set | |
| The resource allocation set for the link | |
| Working window | |
| Reception slice including the time slots for data reception | |
| Transmission slice including the time slots for data transmission | |
| The objective function | |
| Overall objective function | |
| Routing structure (set) | |
| I | The set of agents |
| S | The set of system or joint states |
| A | The set of joint actions |
| P | The transition function of the state |
| R | Reward function |
| The set of joint observations | |
| O | Observation function |
| b | Initial system state distribution (initial belief) |
| T | Horizon or the number of time steps |
| The action-observation history | |
| Agent policy | |
| The value of a joint policy from state | |
| Q | Q-function or Q-value function |
| Discount factor | |
| Learning rate | |
| g | Agent group |
| Signum function | |
| Alterable parameter of selection probability | |
| Shrinking factor | |
| Selection consistency | |
| Recently observed periods |
References
- Jamshed, M.A.; Ali, K.; Abbasi, Q.; Imran, M.A. Challenges, Applications and Future of Wireless Sensors in Internet of Things: A Review. IEEE Sens. J. 2022, 22, 5482–5494. [Google Scholar] [CrossRef]
- Mohamed, S. Abdalzaher, Lotfy Samy, Osamu Muta, Non-zero-sum game-based trust model to enhance wireless sensor networks security for IoT application. IET Wirel. Sens. Syst. 2019, 9, 218–226. [Google Scholar]
- Ballard, Z.; Brown, C.; Madni, A.M.; Ozcan, A. Machine learning and computation-enabled intelligent sensor design. Nat. Mach. Intell. 2021, 3, 556–565. [Google Scholar] [CrossRef]
- Izhar; Wang, X.; Xu, W.; Tavakkoli, H.; Lee, Y.K. Integrated Predicted Mean Vote Sensing System Using MEMS Multi-Sensors for Smart HVAC Systems. IEEE Sens. J. 2021, 21, 8400–8410. [Google Scholar] [CrossRef]
- Shi, W.; Jie, C.; Quan, Z.; Li, Y.; Xu, L. Edge computing: Vision and challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- El-Sayed, H.; Sankar, S.; Prasad, M.; Puthal, D.; Gupta, A.; Mohanty, M.; Lin, C.-T. Edge of Things: The Big Picture on the Integration of Edge, IoT and the Cloud in a Distributed Computing Environment. IEEE Access 2018, 6, 1706–1717. [Google Scholar] [CrossRef]
- Gholami, N.; Moghim, N.; Ghazvini, M.; Haghani, S. Utilizing Non-Orthogonal Multiple Access for Both Latency and Energy Efficiency Improvement in TSCH-Based WSNs. IEEE Access 2022, 10, 28922–28937. [Google Scholar] [CrossRef]
- Cheng, L.; Kong, L.; Gu, Y.; Niu, J.; Zhu, T.; Liu, C.; Mumtaz, S.; He, T. Collision-Free Dynamic Convergecast in Low-Duty-Cycle Wireless Sensor Networks. IEEE Trans. Wirel. Commun. (TWC) 2022, 21, 1665–1680. [Google Scholar] [CrossRef]
- Boubiche, S.; Boubiche, D.E.; Bilami, A.; Toral-Cruz, H. Big Data Challenges and Data Aggregation Strategies in Wireless Sensor Networks. IEEE Access 2018, 6, 20558–20571. [Google Scholar] [CrossRef]
- Saginbekov, S.; Jhumka, A. Many-to-many data aggregation scheduling in wireless sensor networks with two sinks. Comput. Netw. 2017, 123, 184–199. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Zhang, Y.; Song, W.-Z. A new data aggregation technique in multi-sink wireless sensor networks. In Proceedings of the International Conference on Smart Computing Workshops, Hong Kong, China, 5 November 2014; pp. 99–104. [Google Scholar]
- Huang, Y.; Zhao, C.; Tang, B.; Fu, H. Beacon Synchronization-Based Multi-Channel with Dynamic Time Slot Assignment Method of WSNs for Mechanical Vibration Monitoring. IEEE Sens. J. 2022, 22, 13659–13667. [Google Scholar]
- Terauchi, T.; Suto, K.; Wakaiki, M. Harvest-Then-Transmit-Based TDMA Protocol with Statistical Channel State Information for Wireless Powered Sensor Networks. In Proceedings of the 93rd IEEE Vehicular Technology Conference (VTC), Helsinki, Finland, 25–28 April 2021; pp. 1–5. [Google Scholar]
- Abdalzaher, M.S.; Muta, O. Employing Game Theory and TDMA Protocol to Enhance Security and Manage Power Consumption in WSNs-Based Cognitive Radio. IEEE Access 2019, 7, 132923–132936. [Google Scholar] [CrossRef]
- Abdalzaher, M.S.; Muta, O. A Game-Theoretic Approach for Enhancing Security and Data Trustworthiness in IoT Applications. IEEE Internet Things J. 2020, 7, 11250–11261. [Google Scholar] [CrossRef]
- Elwekeil, M.; Abdalzaher, M.S.; Seddik, K. Prolonging smart grid network lifetime through optimising number of sensor nodes and packet length. IET Commun. 2019, 13, 2478–2484. [Google Scholar] [CrossRef]
- Liu, D.; Wu, X.; Cao, Z.; Liu, M.; Li, Y.; Hou, M. CD-MAC: A contention detectable MAC for low duty-cycled wireless sensor networks. In Proceedings of the 12th Annual IEEE International Conference on Sensing, Communication, and Networking (SECON), Seattle, WA, USA, 22–25 June 2015; pp. 37–45. [Google Scholar]
- Nguyen, N.-T.; Liu, B.-H.; Pham, V.-T.; Liou, T.-Y. An Efficient Minimum-Latency Collision-Free Scheduling Algorithm for Data Aggregation in Wireless Sensor Networks. IEEE Syst. J. 2018, 12, 2214–2225. [Google Scholar] [CrossRef]
- Kang, B.; Nguyen, P.K.H.; Zalyubovskiy, V.; Choo, H. A Distributed Delay-Efficient Data Aggregation Scheduling for Duty-Cycled WSNs. IEEE Sens. J. 2017, 17, 3422–3437. [Google Scholar] [CrossRef]
- Kumar, S.; Kim, H. Energy Efficient Scheduling in Wireless Sensor Networks for Periodic Data Gathering. IEEE Access 2019, 7, 11410–11426. [Google Scholar] [CrossRef]
- Ma, J.; Lou, W.; Li, X. Contiguous Link Scheduling for Data Aggregation in Wireless Sensor Networks. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 1691–1701. [Google Scholar] [CrossRef] [Green Version]
- Yao, B.; Gao, H.; Chen, Q.; Li, J. Energy-Adaptive and Bottleneck-Aware Many-to-Many Communication Scheduling for Battery-Free WSNs. IEEE Internet Things J. 2021, 8, 8514–8529. [Google Scholar] [CrossRef]
- Bagaa, M.; Younis, M.; Ksentini, A.; Badache, N. Reliable Multi-channel Scheduling for timely dissemination of Aggregated data in Wireless Sensor Networks. J. Netw. Comput. Appl. 2014, 46, 293–304. [Google Scholar] [CrossRef]
- Jiao, X.; Lou, W.; Feng, X.; Wang, X.; Yang, L.; Chen, G. Delay Efficient Data Aggregation Scheduling in Multi-channel Duty-Cycled WSNs. In Proceedings of the IEEE 15th International Conference on Mobile Ad Hoc and Sensor Systems (MASS), Chengdu, China, 9–12 October 2018; pp. 326–334. [Google Scholar]
- Lu, Y.; Zhang, T.; He, E.; Ioan-Sorin, C. Self-learning-based data aggregation scheduling policy in wireless sensor networks. J. Sens. 2018, 2018, 9647593. [Google Scholar] [CrossRef] [Green Version]
- Ren, M.; Li, J.; Guo, L.; Cai, Z. Distributed Data Aggregation Scheduling in Multi-channel and Multi-power Wireless Sensor Networks. IEEE Access 2017, 5, 27887–27896. [Google Scholar] [CrossRef]
- Lee, J.; Jeong, W. Multi-channel TDMA link scheduling for wireless multi-hop sensor networks. In Proceedings of the International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Korea, 28–30 October 2015; pp. 630–635. [Google Scholar]
- Yu, B.; Li, J. Minimum-time aggregation scheduling in multi-sink sensor networks. In Proceedings of the 8th Annual IEEE Communications Society Conference on Sensor, Mesh and Ad Hoc Communications and Networks, Jeju, Korea, 28–30 October 2011; pp. 422–430. [Google Scholar]
- Mottola, L.; Picco, G.P. MUSTER: Adaptive Energy-Aware Multisink Routing in Wireless Sensor Networks. IEEE Trans. Mob. Comput. 2011, 10, 1694–1709. [Google Scholar] [CrossRef] [Green Version]
- Yu, J.; Yu, W.; Gu, J. Online Vehicle Routing with Neural Combinatorial Optimization and Deep Reinforcement Learning. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3806–3817. [Google Scholar] [CrossRef]
- Amato, C.; Konidaris, G.; Kaelbling, L.P.; How, J.P. Modeling and planning with macro-actions in Decentralized POMDPs. J. Artif. Intell. Res. 2019, 64, 817–859. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, C.; Lesser, V.R. Coordinated Multi-Agent Reinforcement Learning in Networked Distributed POMDPs. In Proceedings of the Twenty-Fifth AAAI Conference on Artificial Intelligence (AAAI), San Francisco, CA, USA, 7–11 August 2011; pp. 7–11. [Google Scholar]
- Farinelli, A.; Rogers, A.; Jennings, N.R. Agent-based decentralised coordination for sensor networks using the max-sum algorithm. Auton. Agents -Multi-Agent Syst. 2014, 28, 337–380. [Google Scholar] [CrossRef]
- Jin, C.; Allen-Zhu, Z.; Bubeck, S.; Jordan, M.I. Is Q-learning provably efficient. In Proceedings of the 32nd International Conference on Neural Information Processing Systems (NIPS’18), Red Hook, NY, USA, 3–8 December 2018; pp. 4868–4878. [Google Scholar]




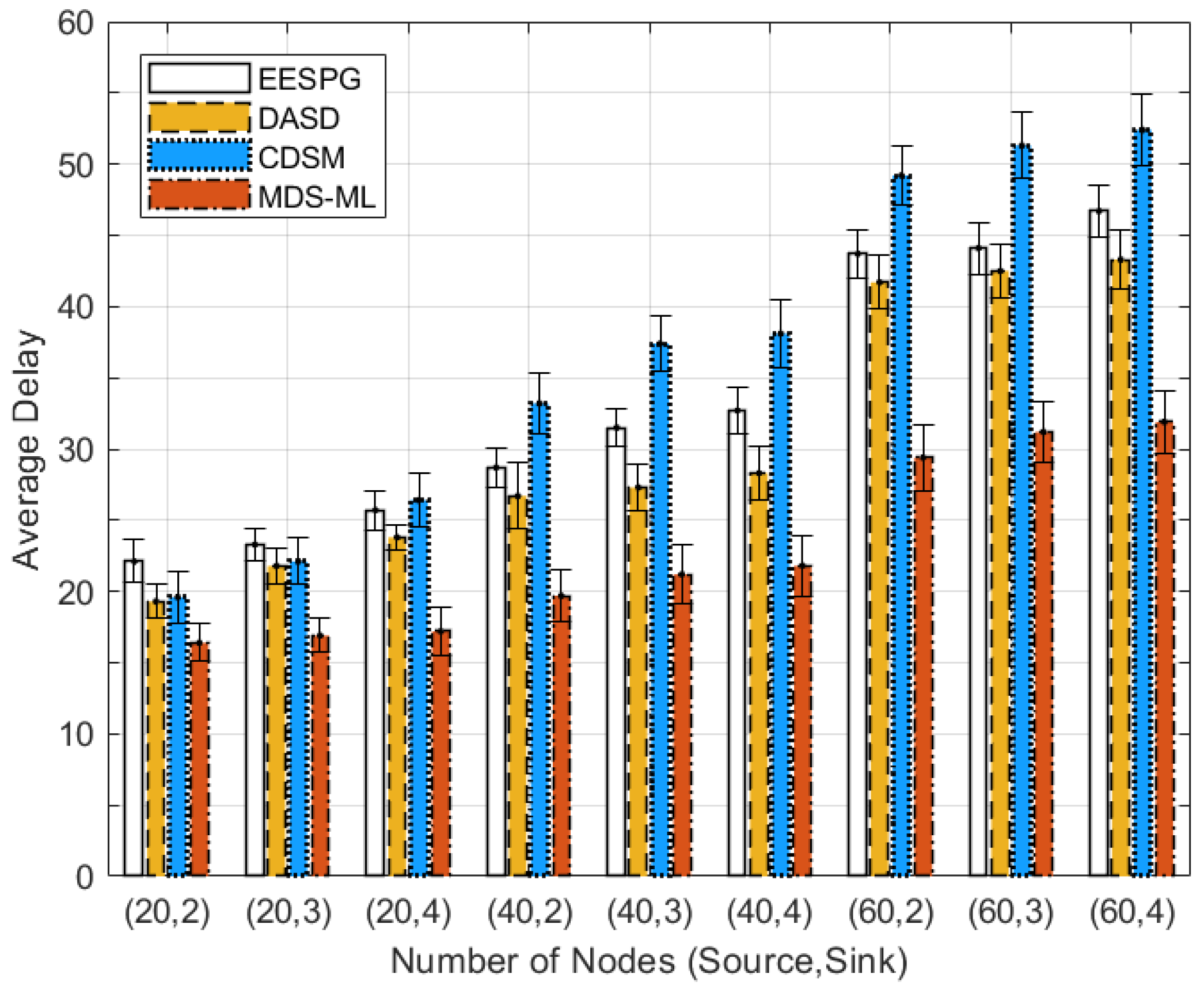

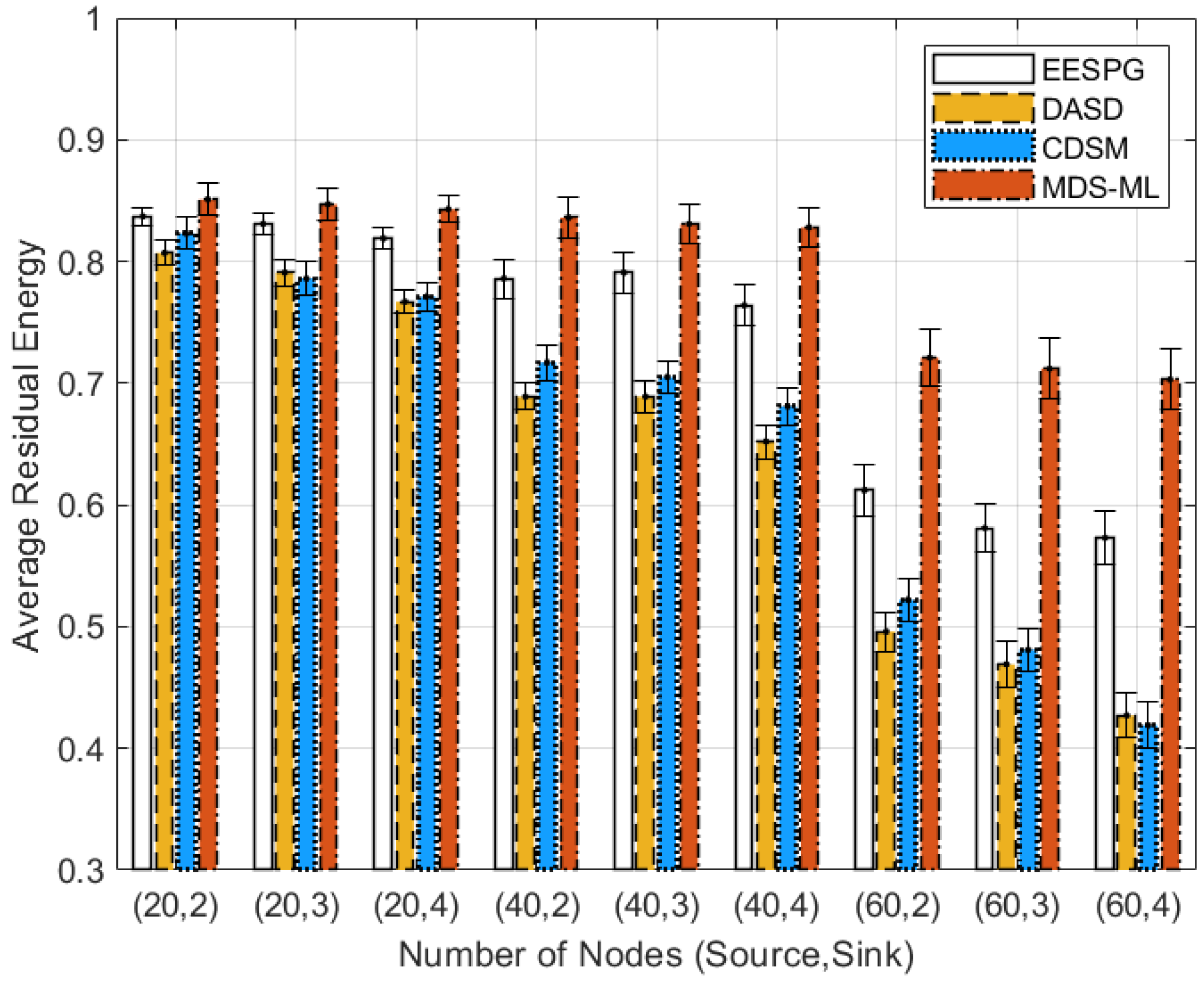
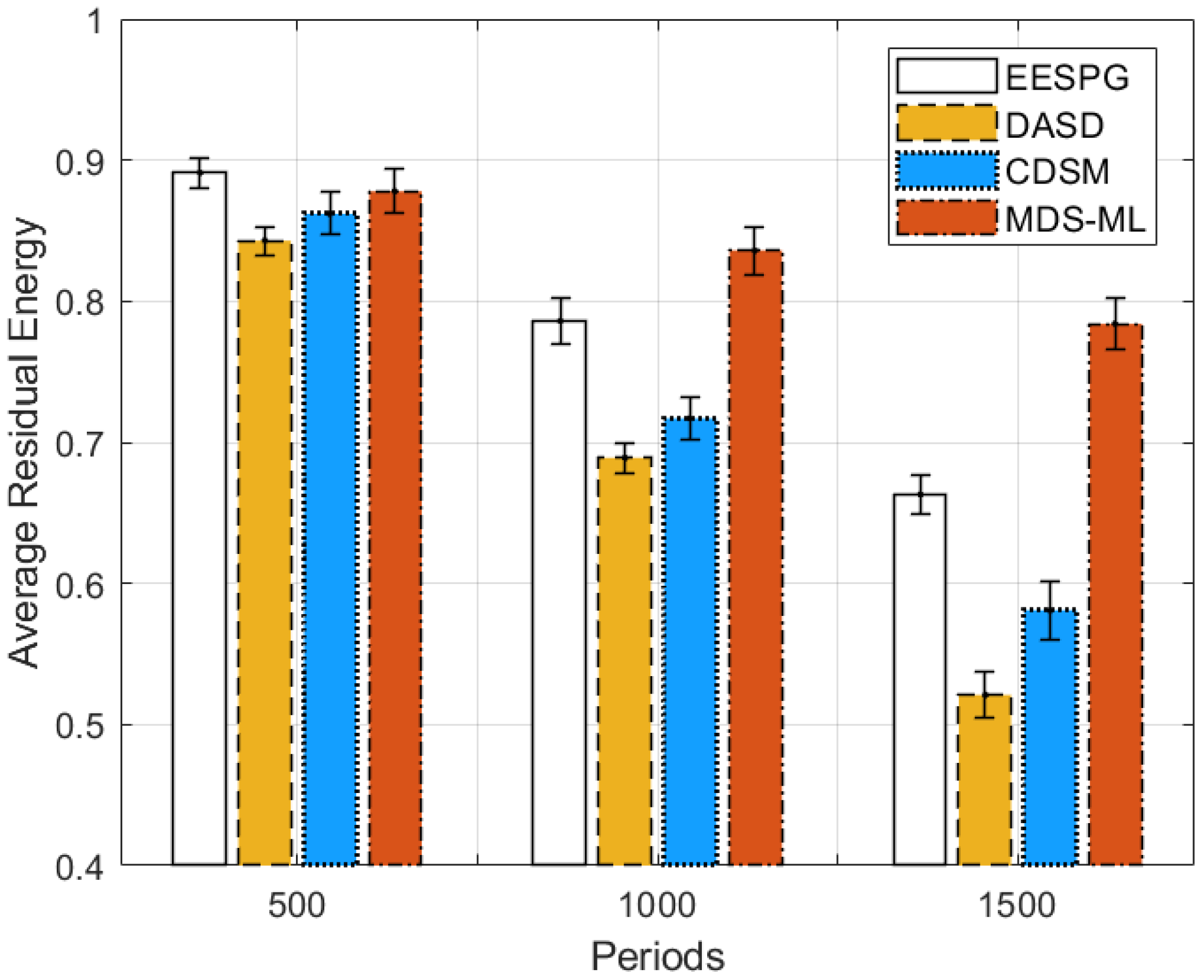

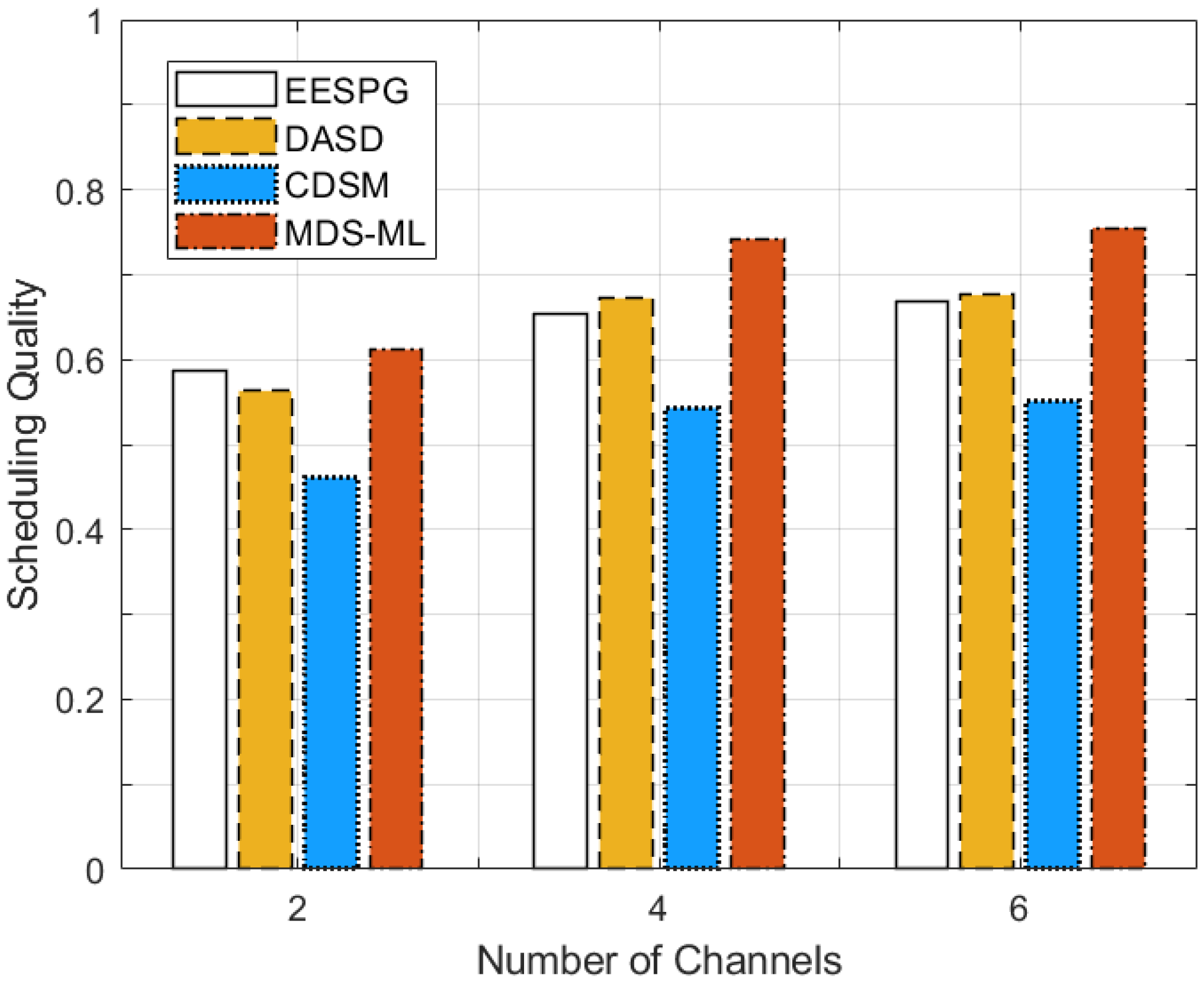
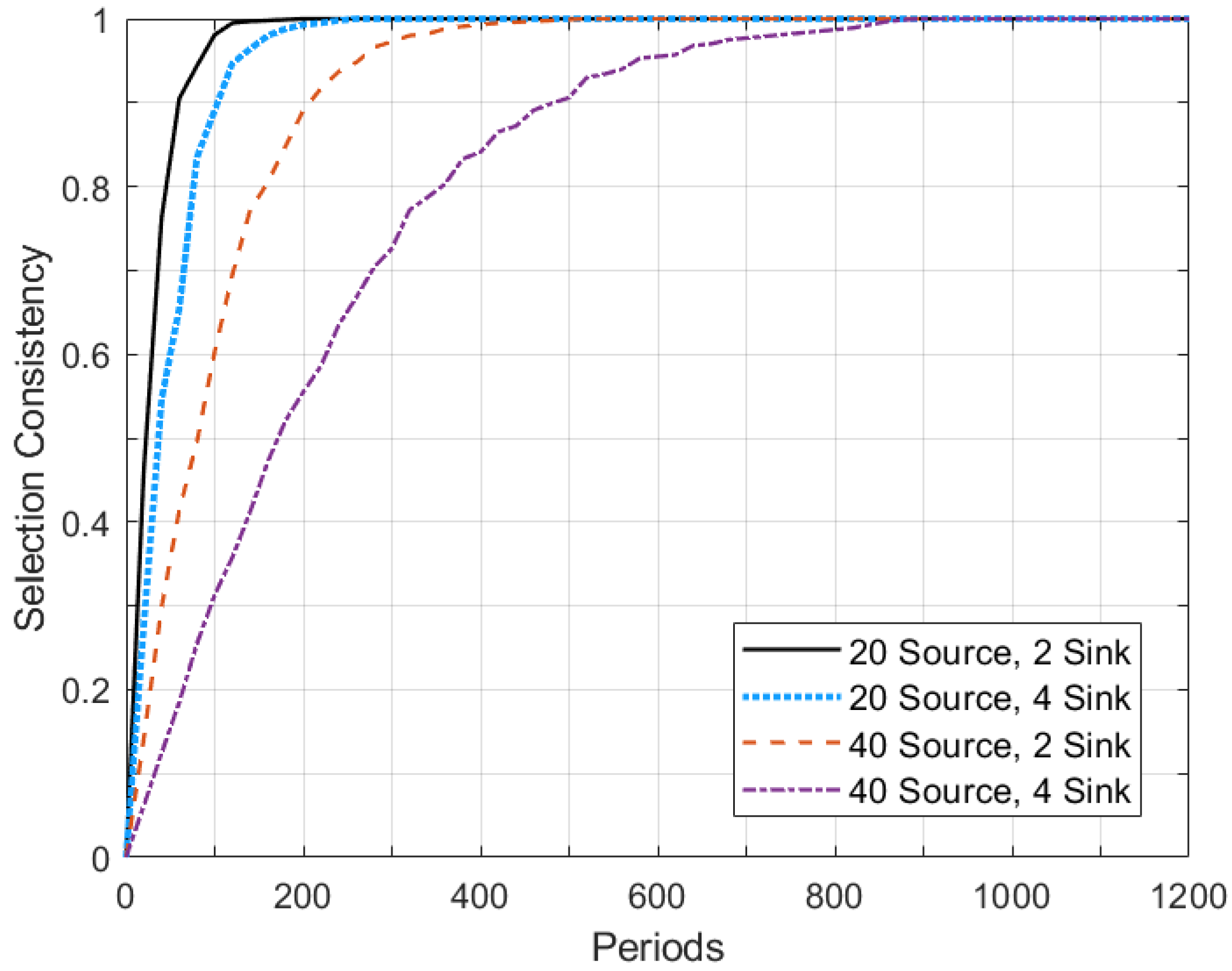

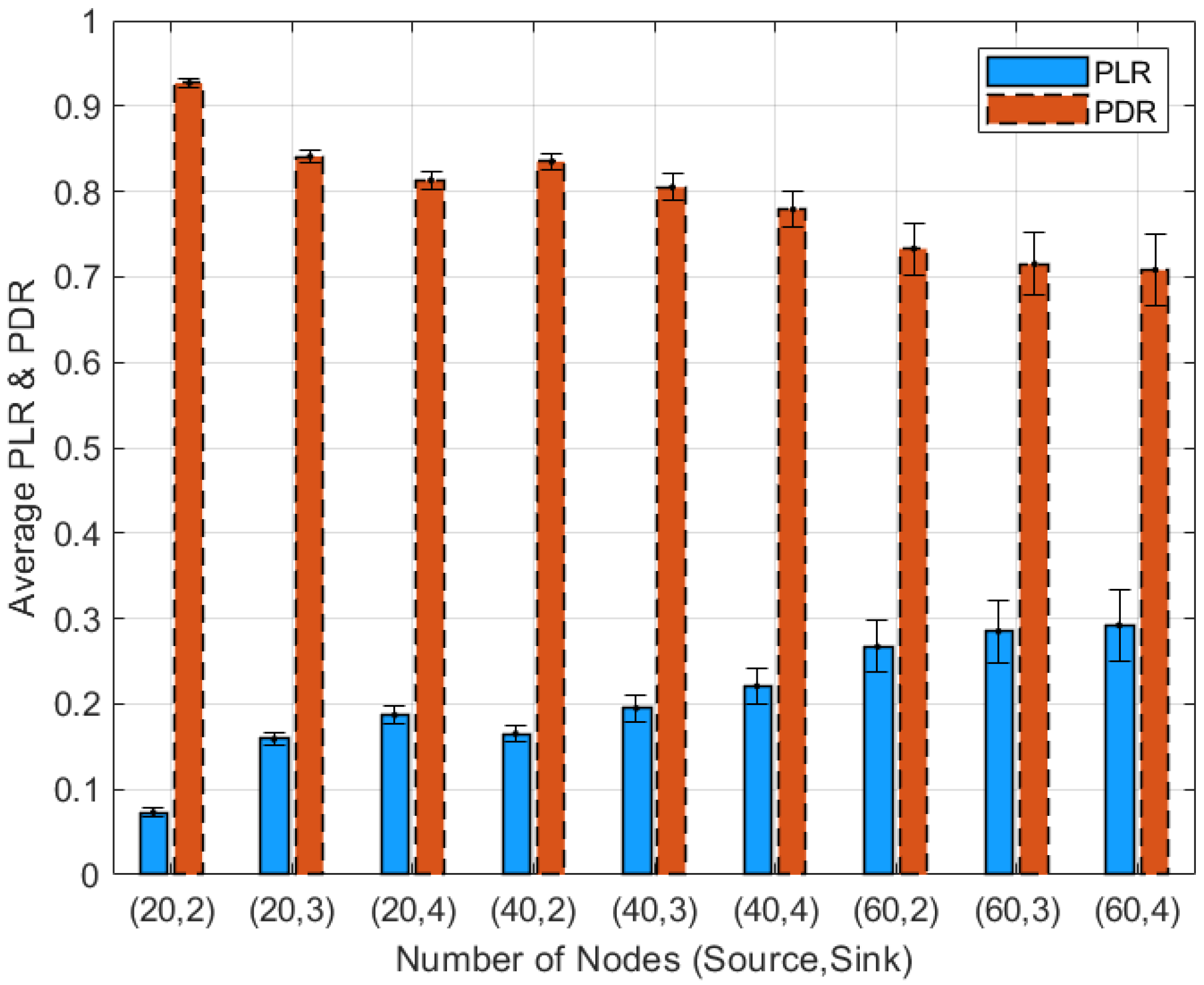
| Periods | = 0.05 | = 0.1 | = 0.2 |
|---|---|---|---|
| 500 | 0.13 | 0.39 | 0.73 |
| 1000 | 0.21 | 0.67 | 0.78 |
| 1500 | 0.37 | 0.85 | 0.81 |
| Periods | = 2 | = 4 | = 6 | = 8 |
|---|---|---|---|---|
| 500 | 0.41 | 0.39 | 0.35 | 0.32 |
| 1000 | 0.55 | 0.67 | 0.58 | 0.48 |
| 1500 | 0.63 | 0.85 | 0.78 | 0.69 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, Y.; Wang, K.; He, E. Many-to-Many Data Aggregation Scheduling Based on Multi-Agent Learning for Multi-Channel WSN. Electronics 2022, 11, 3356. https://doi.org/10.3390/electronics11203356
Lu Y, Wang K, He E. Many-to-Many Data Aggregation Scheduling Based on Multi-Agent Learning for Multi-Channel WSN. Electronics. 2022; 11(20):3356. https://doi.org/10.3390/electronics11203356
Chicago/Turabian StyleLu, Yao, Keweiqi Wang, and Erbao He. 2022. "Many-to-Many Data Aggregation Scheduling Based on Multi-Agent Learning for Multi-Channel WSN" Electronics 11, no. 20: 3356. https://doi.org/10.3390/electronics11203356
APA StyleLu, Y., Wang, K., & He, E. (2022). Many-to-Many Data Aggregation Scheduling Based on Multi-Agent Learning for Multi-Channel WSN. Electronics, 11(20), 3356. https://doi.org/10.3390/electronics11203356