
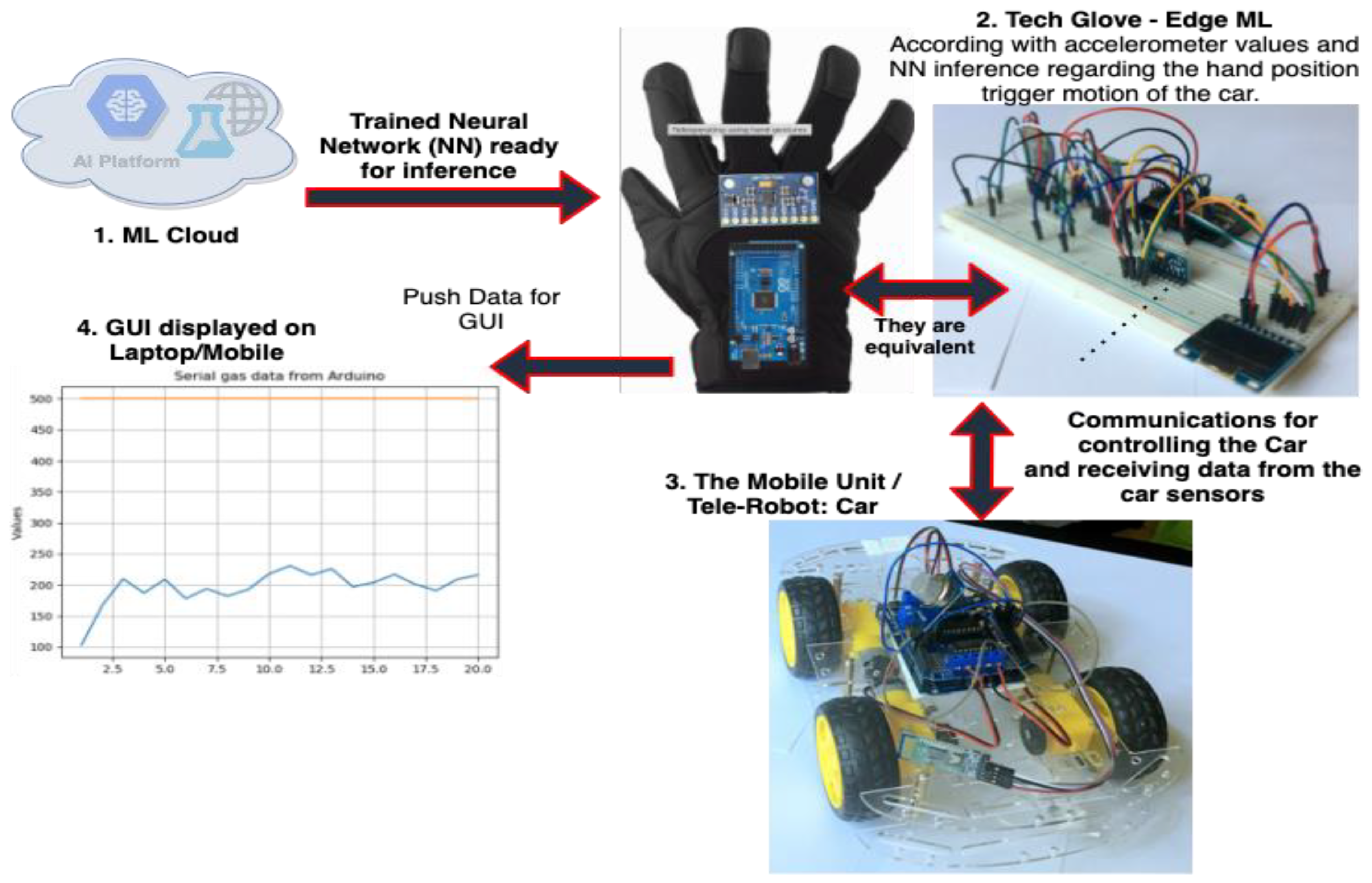
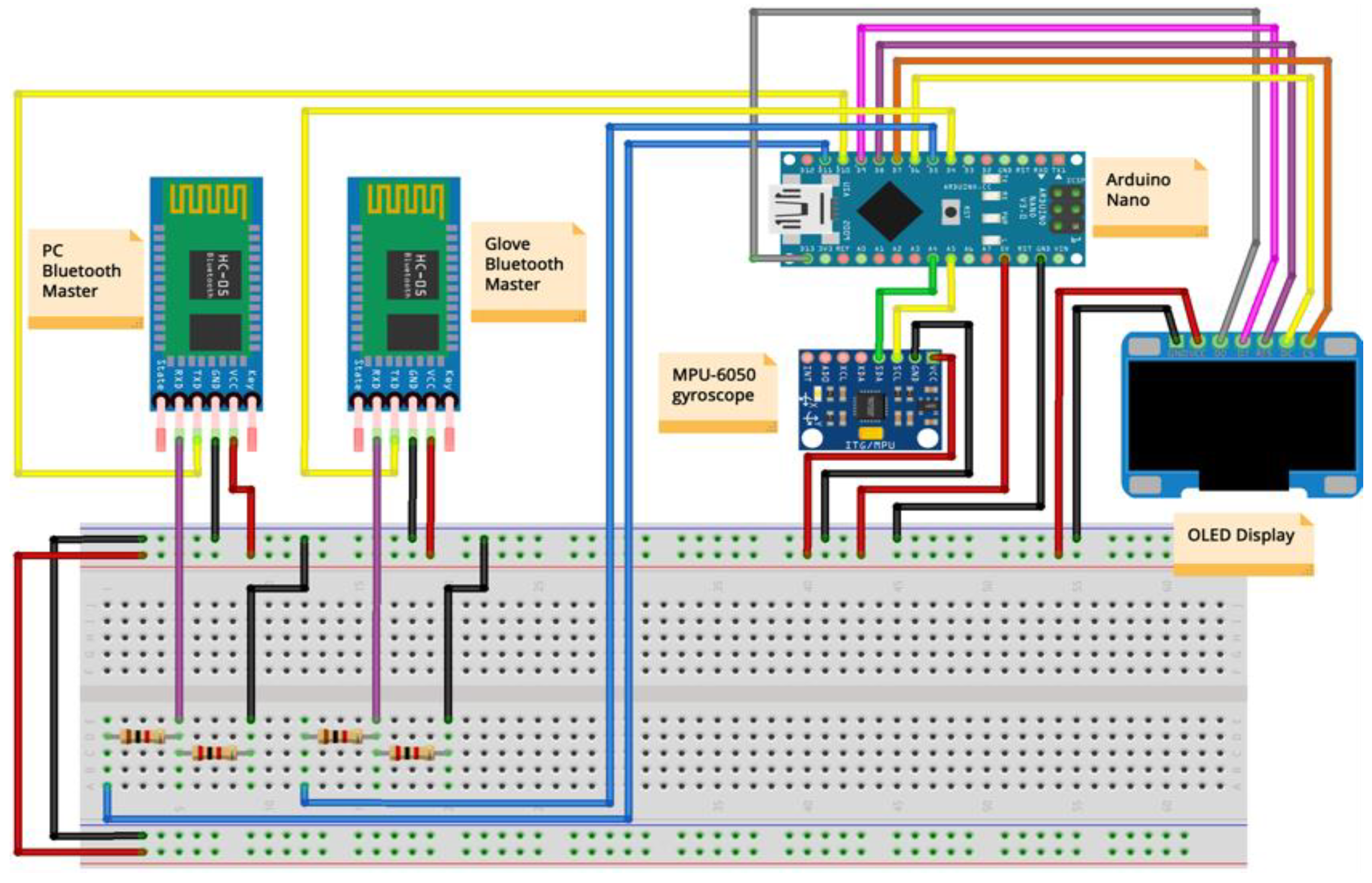
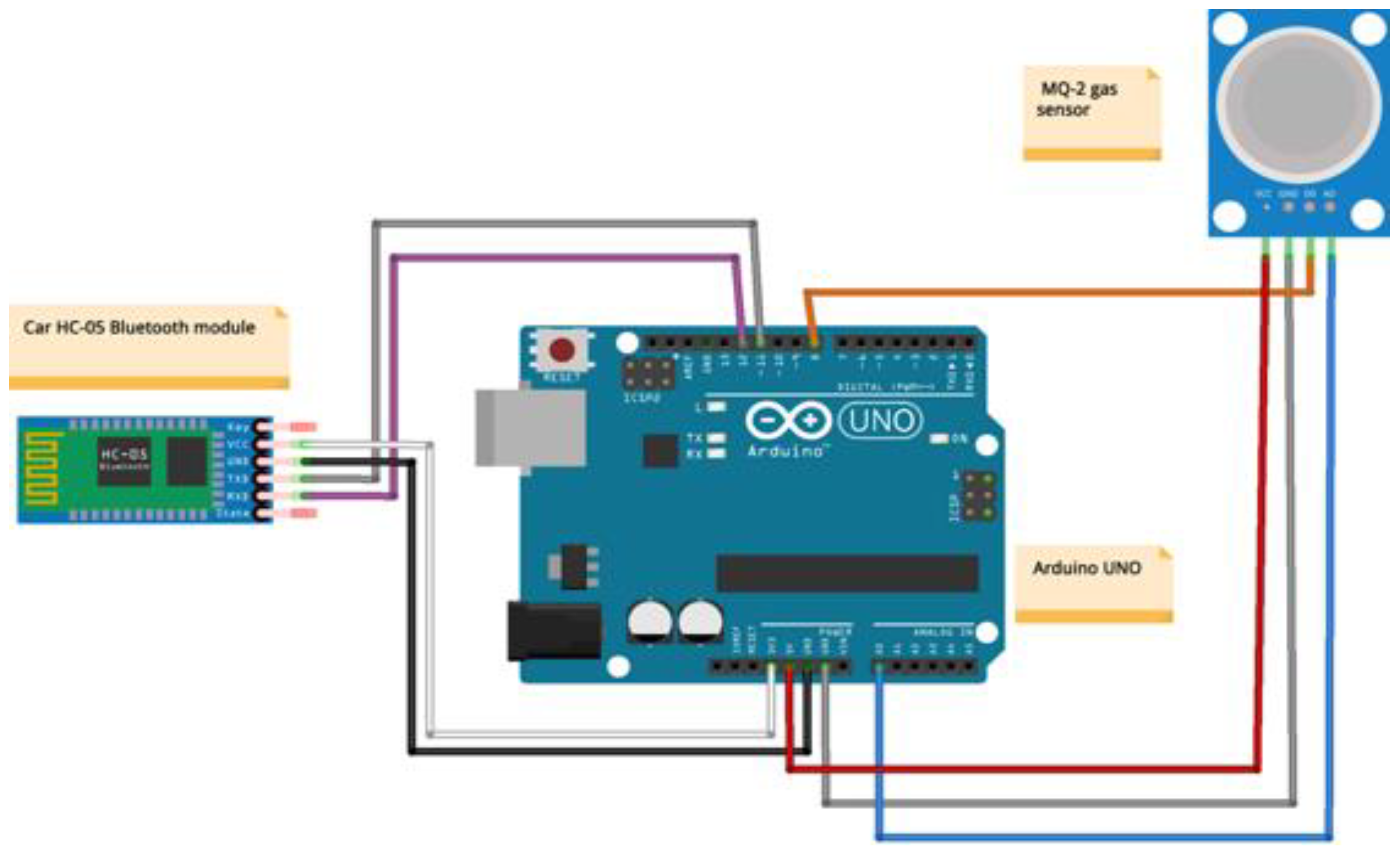
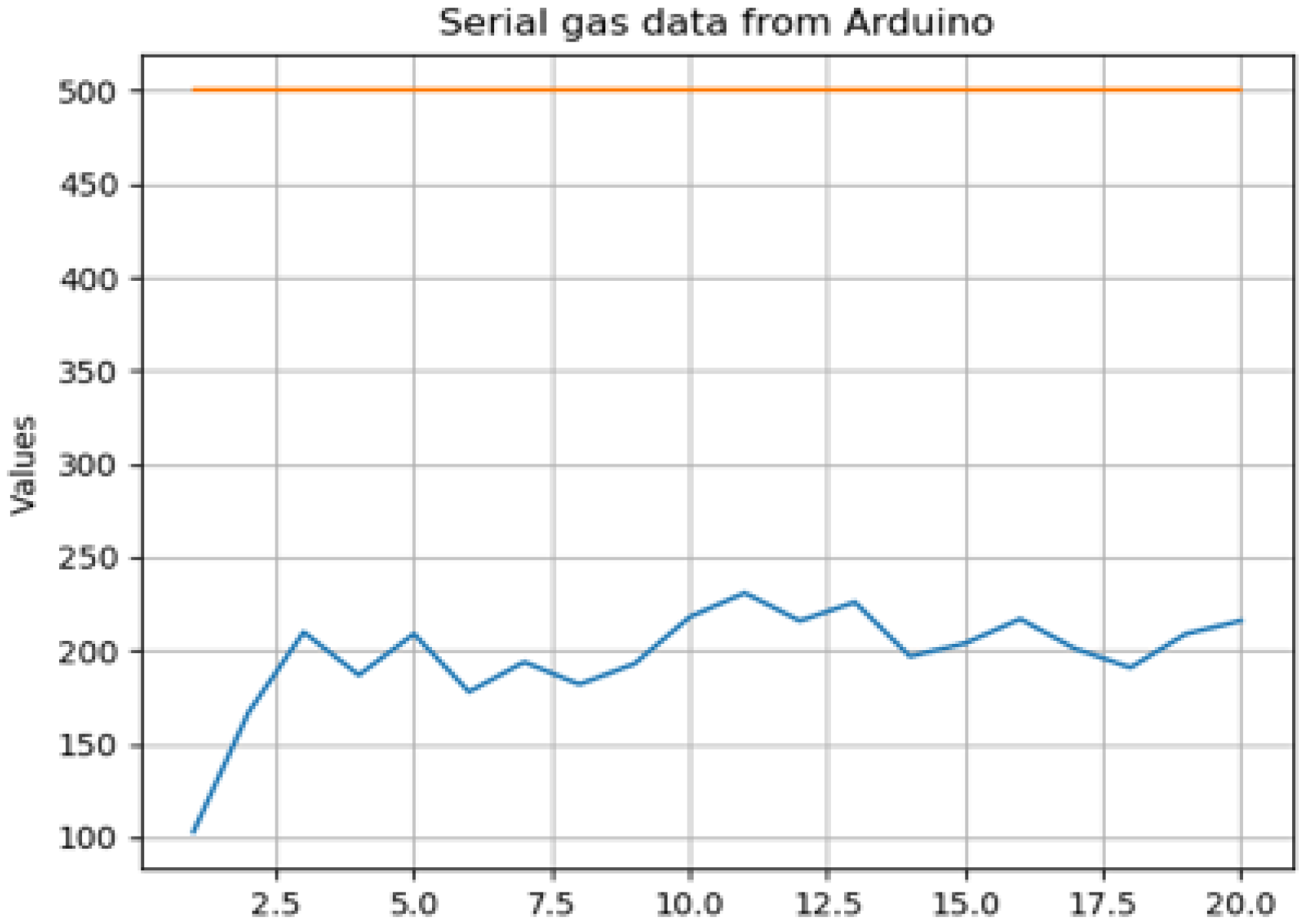
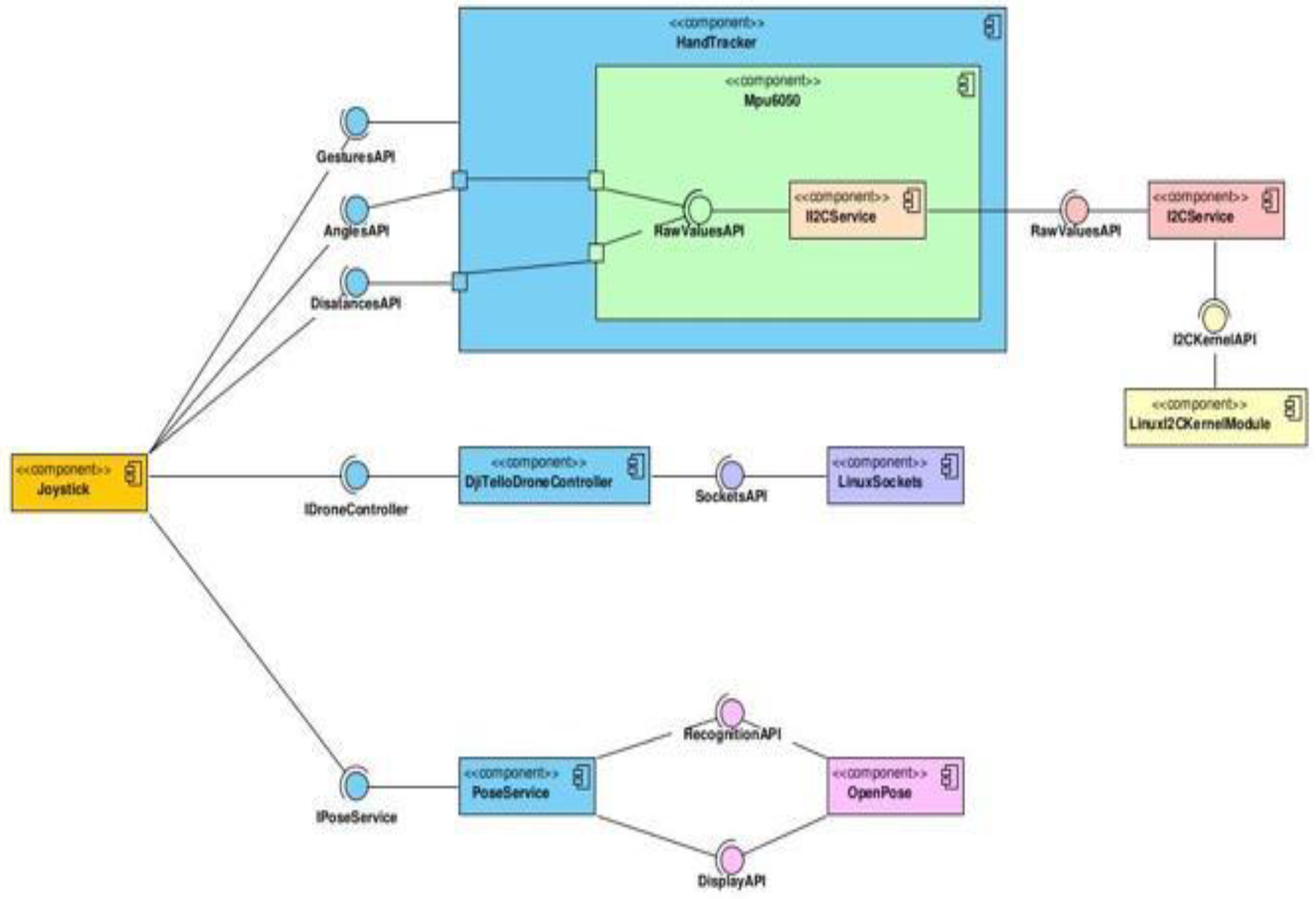
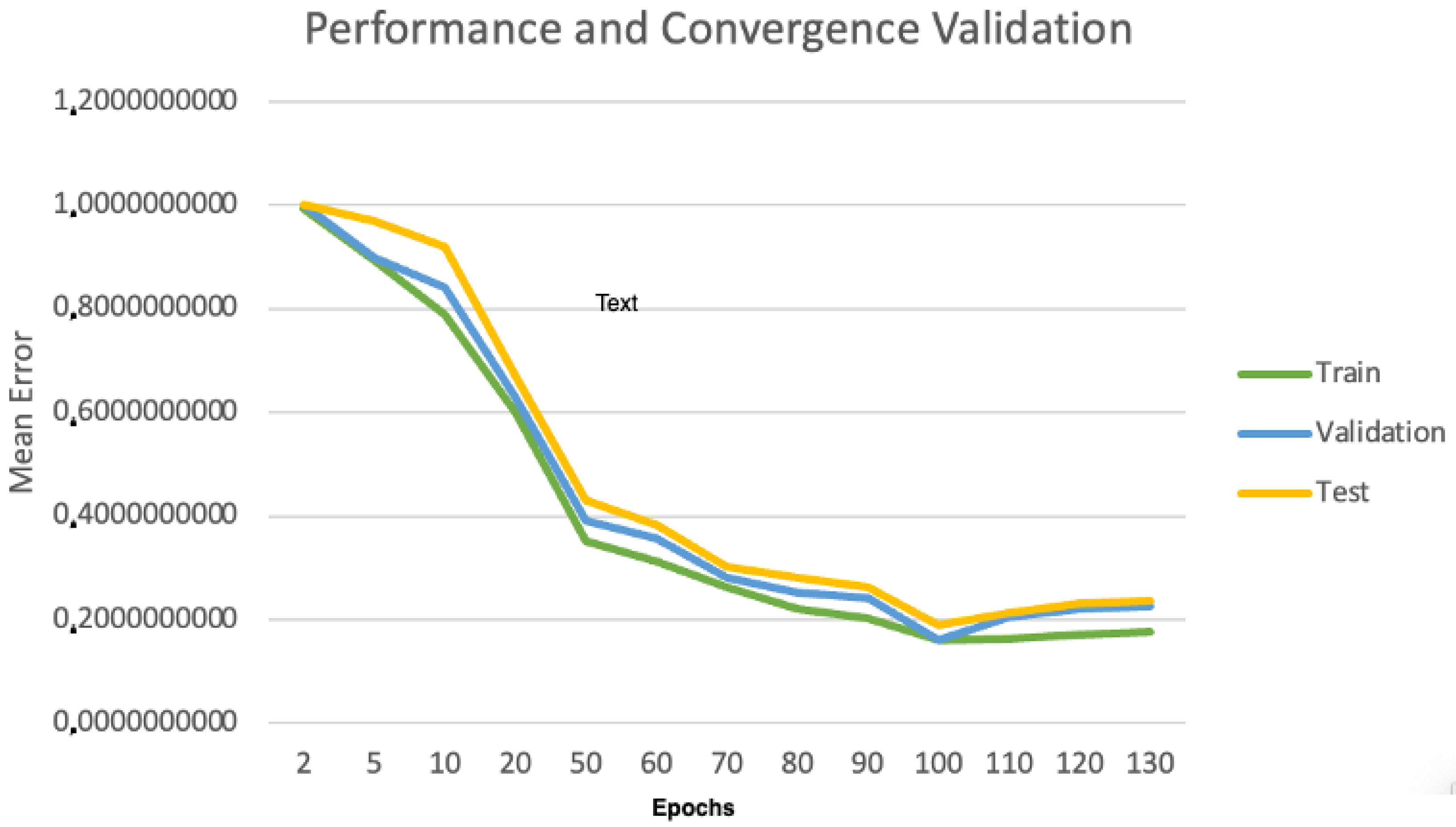
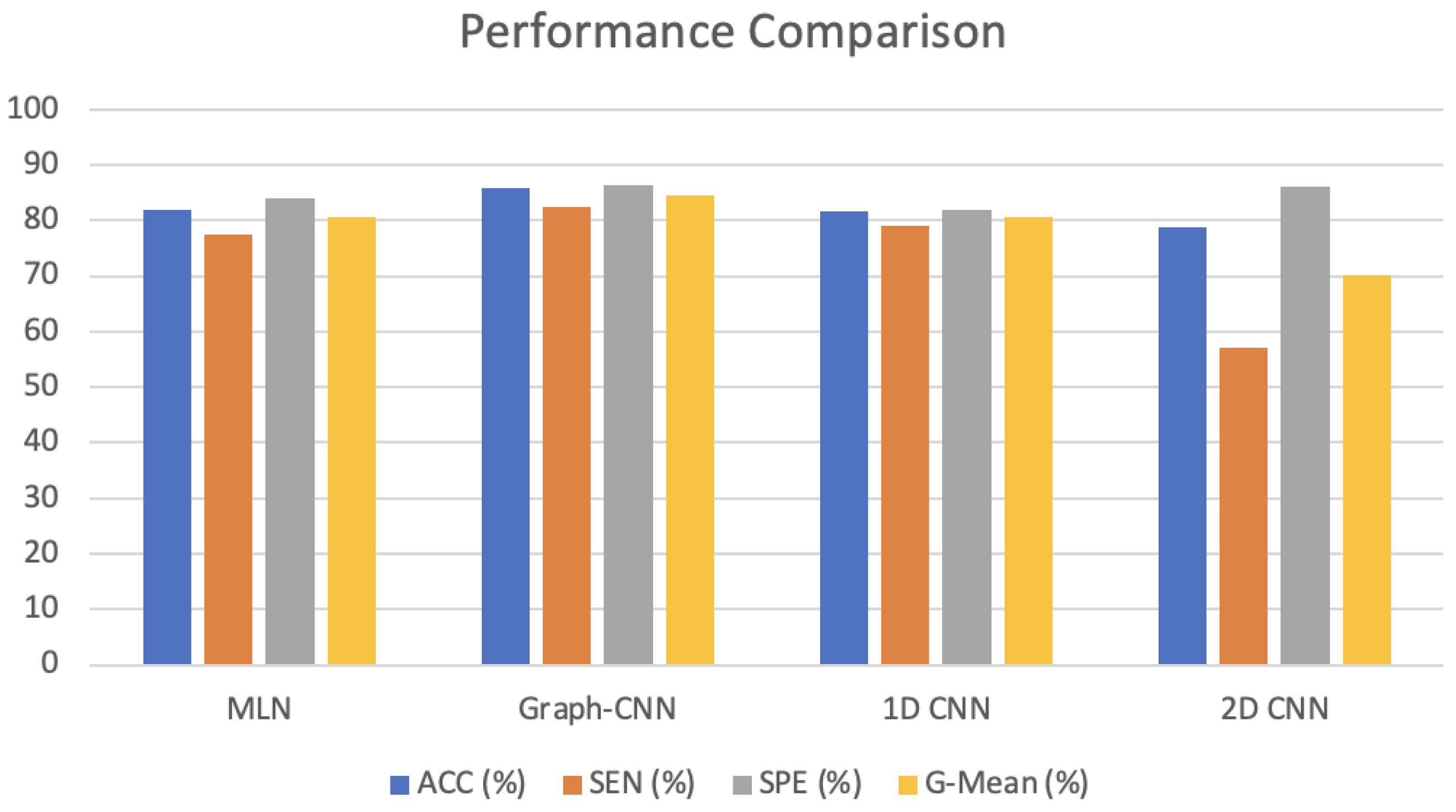
Edge Machine Learning for the Automated Decision and Visual Computing of the Robots, IoT Embedded Devices or UAV-Drones

 , ,
, ,  ,
, 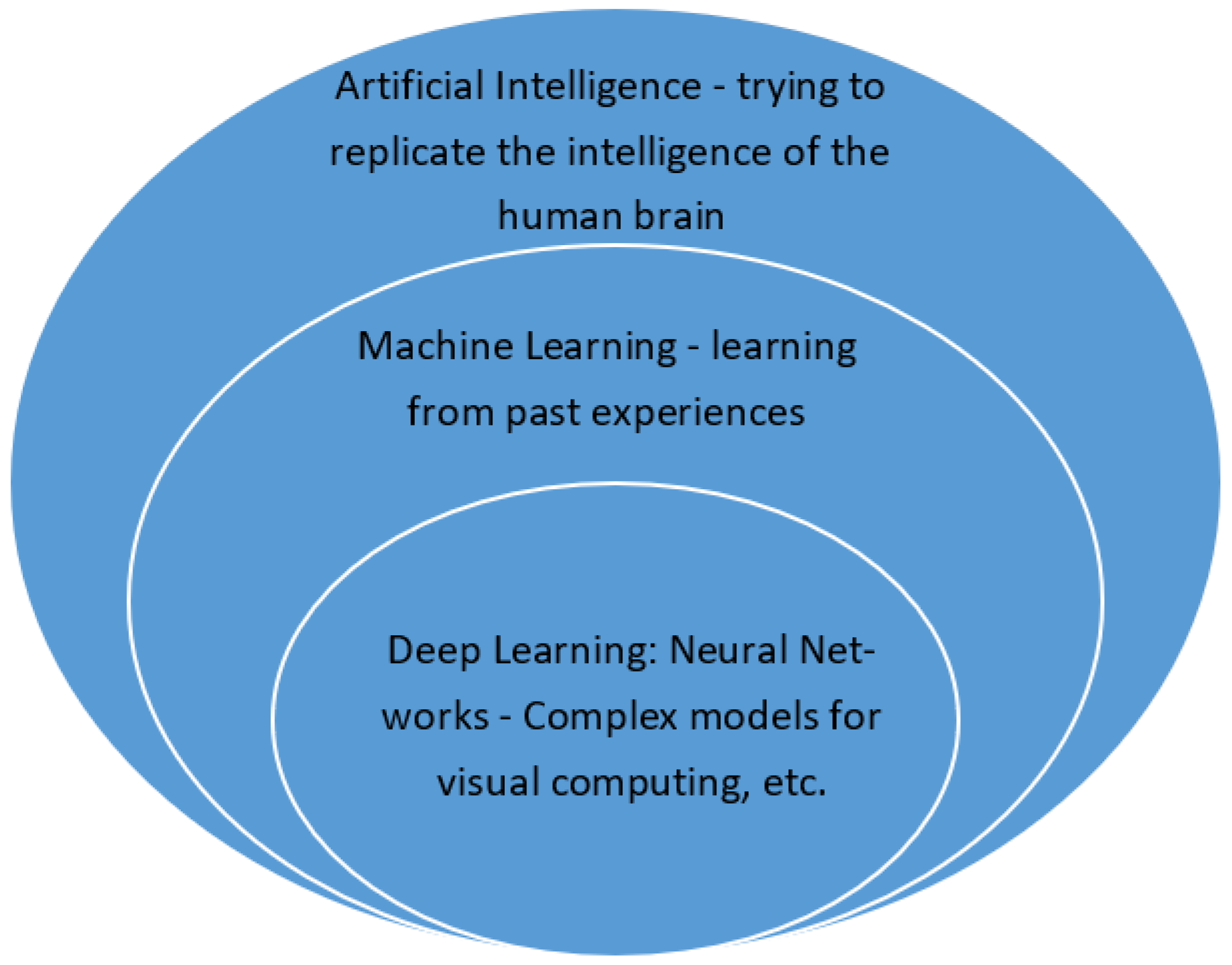{kind=link}
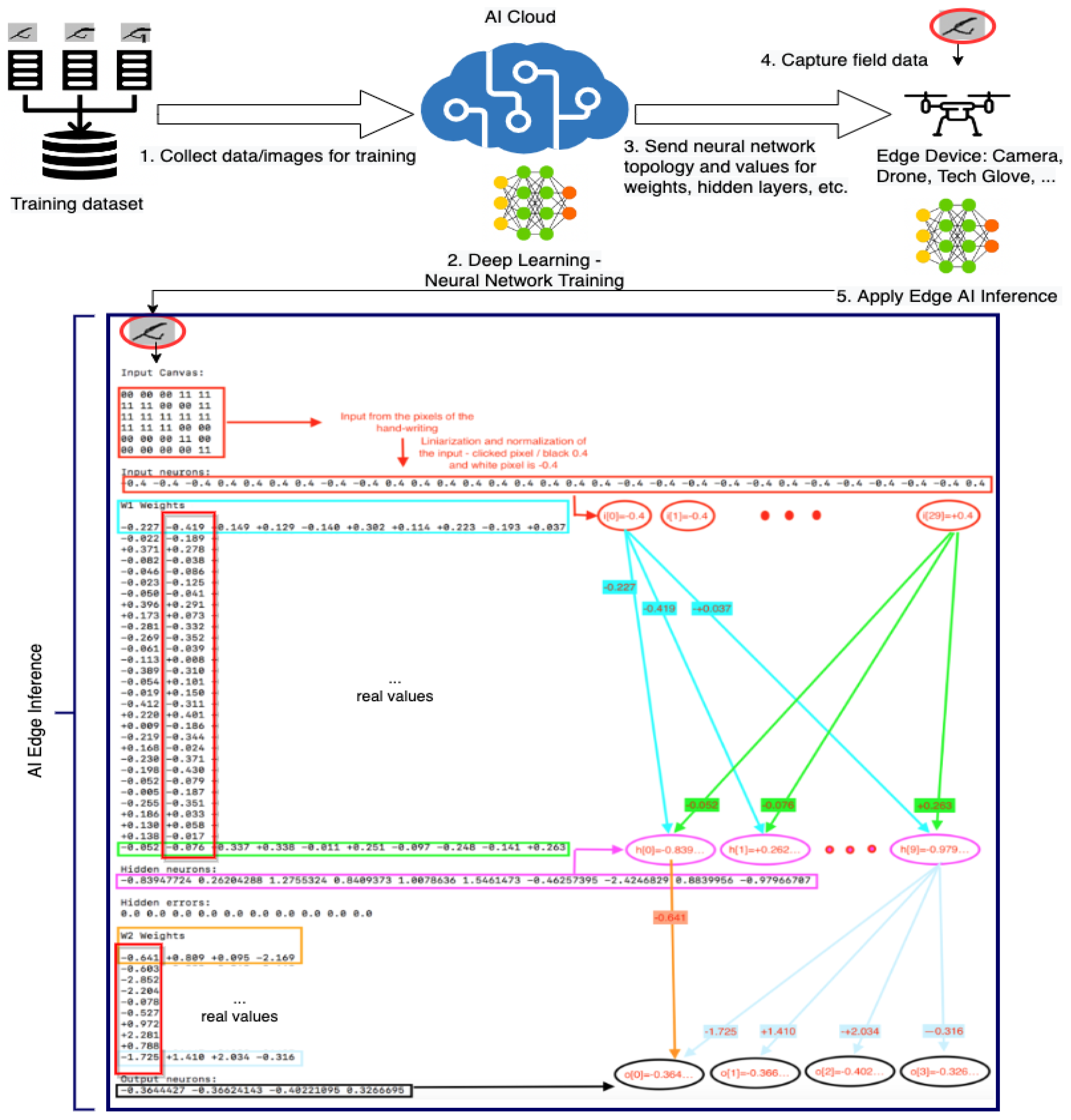{kind=link}
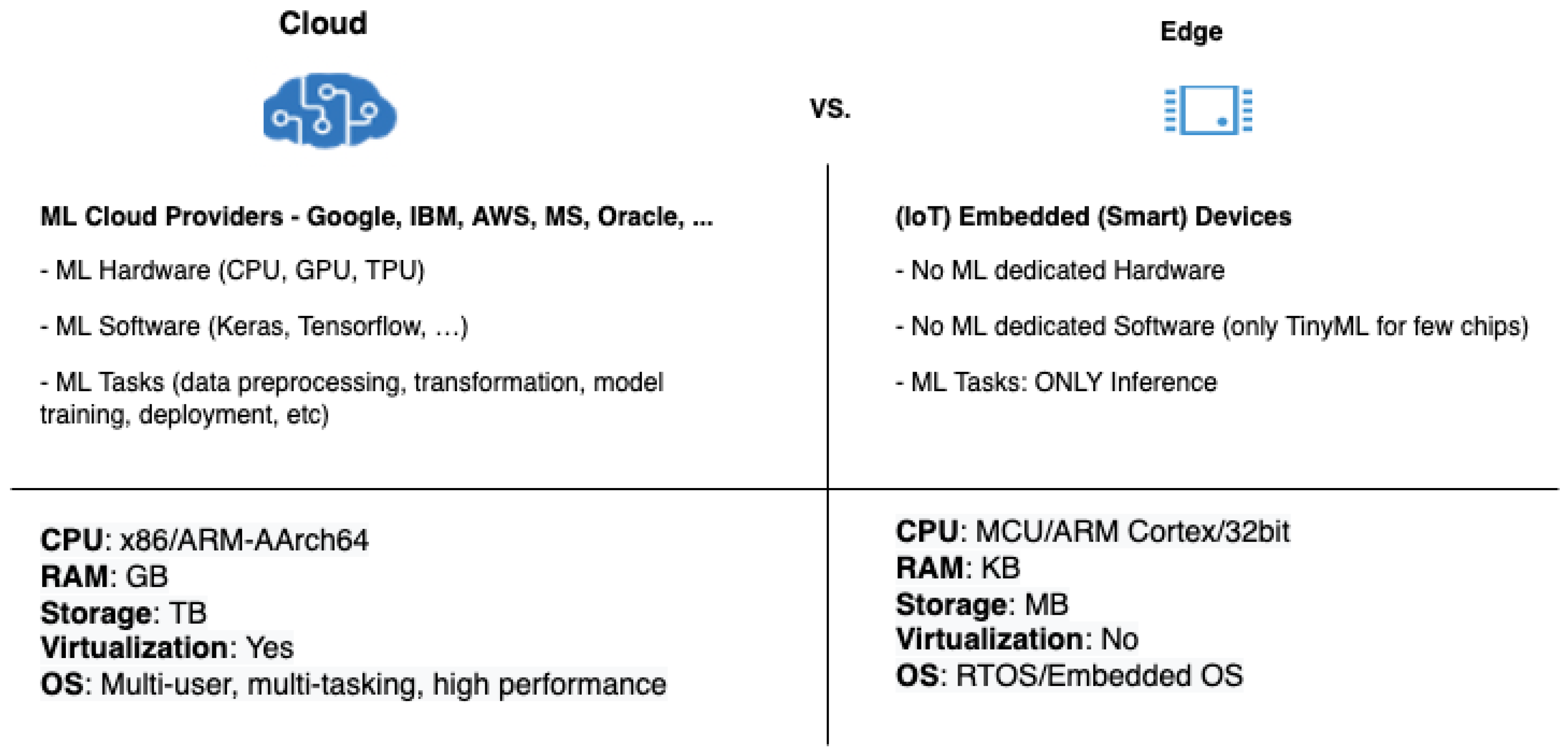{kind=link}
{kind=link}
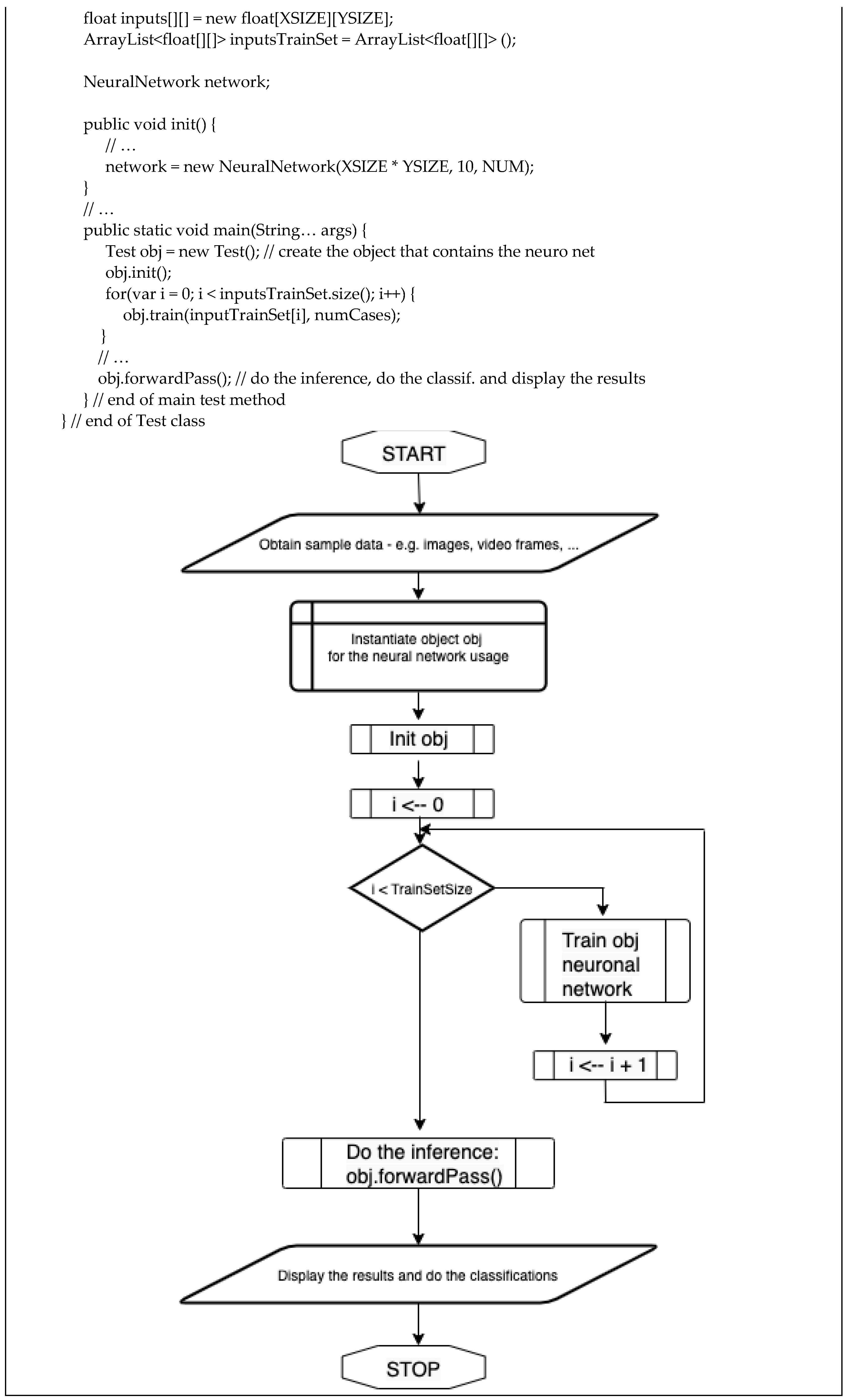{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
Share and Cite
Toma, C.; Popa, M.; Iancu, B.; Doinea, M.; Pascu, A.; Ioan-Dutescu, F. Edge Machine Learning for the Automated Decision and Visual Computing of the Robots, IoT Embedded Devices or UAV-Drones. Electronics 2022, 11, 3507. https://doi.org/10.3390/electronics11213507
Toma C, Popa M, Iancu B, Doinea M, Pascu A, Ioan-Dutescu F. Edge Machine Learning for the Automated Decision and Visual Computing of the Robots, IoT Embedded Devices or UAV-Drones. Electronics. 2022; 11(21):3507. https://doi.org/10.3390/electronics11213507
Chicago/Turabian StyleToma, Cristian, Marius Popa, Bogdan Iancu, Mihai Doinea, Andreea Pascu, and Filip Ioan-Dutescu. 2022. "Edge Machine Learning for the Automated Decision and Visual Computing of the Robots, IoT Embedded Devices or UAV-Drones" Electronics 11, no. 21: 3507. https://doi.org/10.3390/electronics11213507
APA StyleToma, C., Popa, M., Iancu, B., Doinea, M., Pascu, A., & Ioan-Dutescu, F. (2022). Edge Machine Learning for the Automated Decision and Visual Computing of the Robots, IoT Embedded Devices or UAV-Drones. Electronics, 11(21), 3507. https://doi.org/10.3390/electronics11213507