Abstract
Because the pretraining model is not limited by the scale of data annotation and can learn general semantic information, it performs well in tasks related to natural language processing and computer vision. In recent years, more and more attention has been paid to research on the multimodal pretraining model. Many vision–language multimodal datasets and related models have been proposed one after another. In order to better summarize and analyze the development status and future trend of vision–language multimodal pretraining model technology, firstly this paper comprehensively combs the category system and related tasks of vision–language multimodal pretraining. Secondly, research progress on vision–language multimodal pretraining is summarized and analyzed from the two dimensions of image–language and video–language models. Finally, problems with and development trends in vision–language multimodal pretraining are discussed.
1. Introduction
Inspired by the fact that human beings can only use a small number of examples to solve problems after learning and accumulating a large amount of knowledge, large-scale pretraining model technology came into being. The pretraining model learns the general knowledge semantic information representation mode from the massive unmarked data, and is fine-tuned based on the general representation mode from small-scale labeled data when applied to downstream tasks. In recent years, the pretraining model has reached the highest level in many downstream tasks in natural language processing and computer vision. For example, in the field of natural language processing, the bidirectional encoder BERT [1], based on the Transformer architecture [2] proposed by Devlin et al., in 2019 had set 11 records in natural language processing. The unidirectional encoder GPT-3 [3] developed by OpenAI in 2020 obtained 9 best results on 12 natural language datasets. ERNIE 2.0 [4], launched by Baidu in 2019, achieved the best results on 16 tasks in Chinese and English. In the field of computer vision, the SimCLR [5] model, studied by Hinton et al. in 2020, and the ViT [6] model, developed by Google Research Institute in 2021, achieved 76.5% and 90.45% best accuracy in image classification tasks on ImageNet [7], respectively. The excellent performance of these pretraining models in natural language processing and computer vision tasks has fully proved the effectiveness of the pretraining model.
Due to the amazing performance of large-scale pretraining model technology in natural language processing and computer vision tasks, people began to explore the application of large-scale pretraining technology in vision–language multimodal data. “Multimodal” refers to multisource modal information, and different modalities mainly refer to different forms of data, such as visual or text data, etc. Due to different forms of data representation, even if the internal semantics are similar, the actual representation is still different. The focus of vision–language pretraining tasks is to learn multimodal joint representation so as to explore the same deep semantics between different representations of visual and text data. Similarly, human beings can learn more abundant knowledge through multimodal data at the same time: multimodal joint learning helps to enhance semantic learning between modalities so as to improve performance on single-modality tasks. Therefore, the pretraining model generated by vision–language data training is better than the single-modality model when performing single-modality downstream tasks.
Common vision–language tasks mainly include visual question answering (VQA), which infers the correct answers to text questions from visual information, visual captioning, which automatically generates text descriptions for images, and image–text retrieval (ITR), which retrieves according to the given images or texts, as shown in Figure 1. Compared with the single-modality task, the vision–language task is more consistent with the human cognitive mode of the real world, so it can make the machine have more interaction modes with the real world so as to significantly improve the intelligence level of the machine. However, compared with the single-modality task, the production of vision–language multimodal datasets is relatively difficult and complex, and because of the addition of other modal data, the parameter space of the model is extremely large and model training needs more computational support. Therefore, research on the construction and training of a multimodal pretraining model, especially a vision–language pretraining model, has become an important focus.

Figure 1.
Vision–language task diagram.
In view of the broad scope of the vision–language pretraining model, this paper designs the classification architecture as shown in Figure 2, i.e., it is divided into image–language and video–language pretraining models according to the different types of input visual data. The image–language pretraining model can be subdivided into single-stream and dual-stream architecture models according to the sequence of modal fusion. According to the different acquisition methods of visual embedding, the single-stream and dual-stream architecture can be further sorted into three types: regional features, grid features, and patch features. On the basis of this classification architecture, research progress on the vision–language pretraining model is summarized in Section 2 and Section 3. Finally, the problems existing in the development of vision–language multimodal pretraining and the development trends are summarized and judged in Section 4 and Section 5.
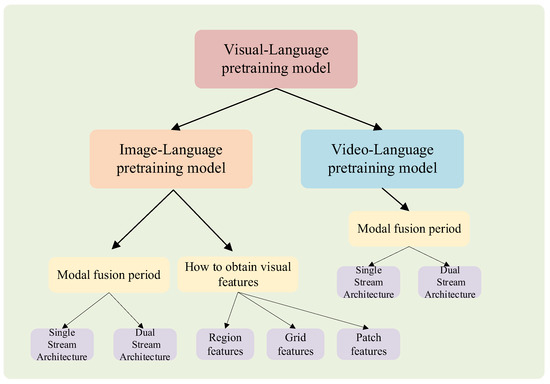
Figure 2.
Classification of vision–language pretraining model.
2. Image–Language Pretraining Model
The image–language pretraining model learns the joint representation of image and text through a large number of image–text pairs and fine-tunes it to adapt to a series of tasks, such as visual question answering (VQA), image caption generation, image–text retrieval (ITR), and so on. According to the sequence of cross-modality information fusion, the image–language pretraining model is divided into single-stream and dual-stream architecture. Single-stream architecture uses only one Transformer module and is applied to multimodal data input at the same time. Dual-stream architecture uses two or more Transformer modules to process the data input of different modalities, and then constructs a cross-modal Transformer to realize multimodal fusion. The early image–language pretraining model often uses the region features obtained through a target detection model, such as Fast R-CNN [8], as the visual features. Because the image region feature acquisition needs to detect the target region of the image, there are some problems, such as model complexity, it is difficult for target region to cover all image regions, resulting in the loss of semantic information, etc. Therefore, many scholars began to study how to replace regional features through grid features and patch features. According to different ways to obtain visual features, the single- and dual-stream architecture models can be further subdivided into regional features—grid features and patch features.
2.1. Image–Language Pretraining Datasets
In image–language pretraining, the datasets used are usually in the form of image–text pairs. Due to the different requirements of the adapted tasks, the text data in the image–text pair can be divided into Q&A and captions. For example, VQA [9], GQA [10], and other datasets used for question answering are mainly in the form of one image and multiple positive and negative Q&A pairs. The dataset used for image–text retrieval or image captioning, such as COCO [11], is mainly in the form of one image and multiple positive and negative image description titles. Table 1 shows some vision–language tasks and their evaluation indicators, Table 2 shows the commonly used datasets for image–language pretraining, and makes a multidimensional comparison from the aspects of pretraining tasks, languages, text type, data volume, etc.

Table 1.
Some vision–language tasks and evaluation indicators.
Table 2.
Common datasets for image–language pretraining.
2.2. Image–Language Pretraining Tasks
2.2.1. Masked Language Modeling (MLM)
Masked language modeling refers to masking part of the input words , using a special token [mask] instead. The goal is that the model can predict the masked word by analyzing the surrounding words and the visual regions . The specific loss function is:
where represents the trainable parameters, the whole training set, and the masked words.
2.2.2. Masked Region Modeling (MRM)
Similar to MLM, masked region modeling refers to masking part of the input visual feature , replaced by zeros. The goal is that the model can predict the masked word by analyzing the remaining regions and the input words . The loss function is:
where represents the masked visual features.
2.2.3. Image–Text Matching (ITM)
An ITM task is to input a sentence and some regional features and output the matching scores so as to learn the semantic relationship between image and text modalities. The loss function is:
where is the matching score and is the label indicating if the sampled pair is a match.
2.2.4. Other Pretraining Tasks
In addition to the above general pretraining tasks, some models try to use novel pretraining tasks to adapt the model architecture and improve the pretraining effect. Pixel-BERT [20] proposes pixel random sampling, referring to randomly sampling feature pixels during pretraining. FashionBERT [21] proposes masked patch modeling (MPM), similar to MRM, masking the input visual patched, and try to predict the masked patched. MVPTR [22] proposes masked concept recovering (MCR), which refers to masking the text modality concept caption of the visual region and predicting the masked concept. SimVLM [23] proposes prefix language modeling, referring to prepending an image feature sequence to the text sequence and enforcing the model to sample a prefix of length.
Some models [20,21] regard multimodal downstream tasks, such as visual question answering (VQA) and image captioning, as pretraining tasks and predict the results to improve the external supervision information during pretraining.
2.3. Single-Stream Architecture Model
As BERT showed its strong semantic learning ability in the field of natural language processing in 2019, some scholars began to study how to apply its architecture to vision–language tasks. The most direct way is to use single-stream architecture, i.e., try to transform the image into a form that can be directly input into the Transformer module. Only one Transformer module is used to uniformly process image and text modalities. According to different ways of obtaining visual embedding, the single-stream architecture model can be divided into region features, grid features, and patch features.
2.3.1. Region Feature Single-Stream Model
With the progress of deep learning technology, using it to find all objects of interest in the image and obtain their location, size, and category has become the mainstream technology of image target detection. It is worth mentioning that with the Transformer widely used in image target detection tasks, the image target detection performance has been improved to a new level. For example, Microsoft proposed dynamic head [24], which uses an attention mechanism for detection head and reached 60.6 AP on COCO, setting a new record.
Researchers have found that multimodal tasks such as VQA and image captioning often depend on the results of image target detection. Therefore, early researchers usually used the region features obtained by image target detection as visual embedding. B2T2 [25], proposed by the Google Research Institute in 2019, found the effectiveness of premodal fusion, and fused images and text at a token representation level. VisualBERT [26], proposed by the University of California in 2019, connects the language modality to the visual area without any explicit supervision, and achieves the best level in VQA and natural language reasoning. VL-BERT [27], proposed by the relevant teams of the University of Science and Technology of China and Microsoft Research in 2019, believes that image–sentence relationship prediction will introduce too many mismatched image–text pairs of noise and reduce the accuracy of other tasks, and hence abandoned it as a pretraining task, pretraining VL-BERT on multimodal vision–language datasets and monomodal text datasets, which improved the generalization ability of the model when dealing with complex text. UNITER [28], proposed by Microsoft Cloud in 2019, creatively uses conditional masked modeling tasks in the pretraining process, i.e., only one modality is masked while the other is not polluted. UniVLP [29], proposed by the University of Michigan and Microsoft Research Institute in 2019, is the first model to uniformly deal with vision–language understanding and generation tasks, using VQA and image captioning as downstream tasks. Peking University put forward Unicoder-VL [30], inspired by XLM [31] and Unicoder [32], in 2020, and achieved the best results in image–text retrieval and visual common reasoning tasks. Microsoft proposed ImageBERT [33] in 2020, the brief architecture of which is shown in Figure 3, for input image–text pairs, ImageBERT processed through the BERT, and the target detection model. After obtaining the image features from the target detection model, it is input into the multilayer Transformer together with text information as an unordered token so as to obtain its cross-modality joint representation. Table 3 shows a comparison of these models in the dimensions of pretraining datasets, pretraining tasks, and downstream tasks. Table 4 shows the evaluation results of the models on some public datasets.
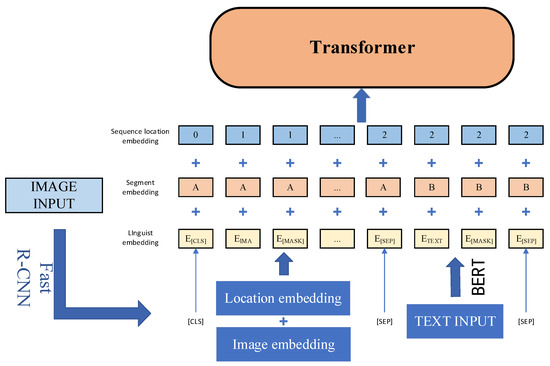
Figure 3.
Schematic diagram of ImageBERT architecture.
Table 3.
Evaluation results of regional feature image–language pretraining model on some public datasets.
Table 4.
Comparison of Regional Feature Image–Language Single Stream Models.
The above single-stream region feature image–language pretraining model is similar in model architecture and acquisition visual embedding mode, and the main differences are pretraining datasets, pretraining tasks, and fine-tuning downstream tasks. In order to improve the effect, efficiency, and applicability of the model, more scholars optimize the region feature model of early single-stream architecture from the aspects of module performance, confrontation learning, and model architecture.
Oscar [34], proposed by the team at the University of Washington and Microsoft in 2020, takes the target tag obtained by the Fast R-CNN as the anchor on the basis of obtaining visual embedding by using the region features, the image region features also obtained by the Fast R-CNN, word tokens and target tag obtained through the BERT, organized in the form of triples as input, as shown in Figure 4. Because the target detection model can accurately detect the target object in the image, and this object is usually mentioned frequently in the text, Oscar directly introduces the target label as the input, which can strengthen the semantic learning between modalities, which is 3–5 percentage points higher than that of UNITER, Unicoder-VL, and other models in the task of ITR. VinVL [35], released by Microsoft in 2021, optimizes the Oscar by improving the accuracy of the target detection module. In the process of pretraining, Microsoft pretrained a large-scale target detection model that can obtain more diversified visual objects and concept sets by using ResNeXt-152 C4 on multiple public target detection datasets, including COCO, OpenImages [36], Objects365 [37], Visual Genome, etc., so that VinVL can be improved from Oscar in various downstream tasks.
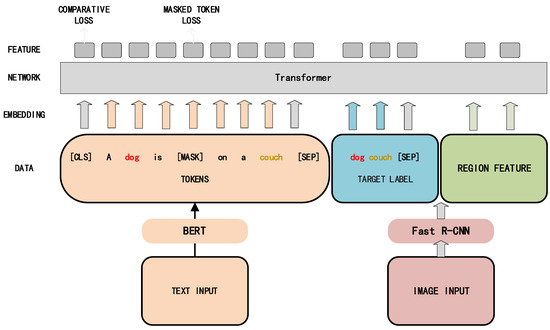
Figure 4.
Schematic diagram of Oscar.
Due to the limited amount of labeled data used in the pretraining model for the fine-tuning of downstream tasks, it is easy to cause excessive fine-tuning, resulting in serious overfitting. However, adversarial learning has shown good performance in improving the robustness of fine-tuning. Inspired by this, Microsoft and the University of Maryland first introduced large-scale adversarial training in vision–language representation learning in 2020, and then proposed VILLA [38]. VILLA adversarial training includes two training stages: the first is adversarial pretraining without specific tasks, and the second is adversarial fine-tuning for specific tasks. Adversarial pretraining can uniformly improve the model performance of all downstream tasks, and adversarial fine-tuning can further enhance the model effect by using task-specific supervision signals. After introducing large-scale adversarial training, VILLA is significantly better than VL-BERT, UNITER, Oscar, and other models on many tasks, such as natural language reasoning, VQA, ITR, VCR, and so on.
Most of the models that learn the cross-modality representation of image and text through image–text matching or masked language modeling tasks, only learn the specific representation of image–text pairs, which cannot be extended to single-modality scenes. In order to solve this problem, relevant Baidu teams put forward UNIMO [39] model that can handle single-modality and multimodal tasks at the same time by optimizing single-stream architecture in 2020. The model architecture is shown in Figure 5. Compared with the common image–language pretraining model, UNIMO can use additional single-modality data for pretraining. At the same time, UNIMO uses a series of text-rewriting techniques to improve the diversity of modality information of cross-languages and promote the semantic alignment between vision and language.
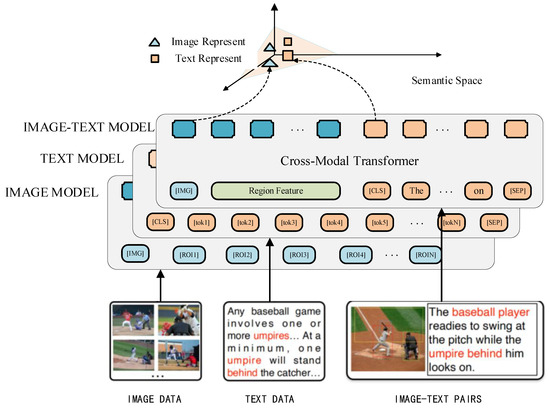
Figure 5.
Overview of UNIMO architecture.
In 2021, the Chinese Academy of Sciences and the University of the Chinese Academy of Sciences introduced wav2vec 2.0 [40] to optimize single-stream architecture, and proposed OPT [41]. The model architecture is shown in Figure 6. Firstly, WordPieces [42], Fast R-CNN, and wav2vec 2.0 are used to obtain text, visual, and audio features, respectively, and then input them into the cross-modality Transformer module for multimodal fusion. Thus, the model can deal with the task of vision–language–audio modality understanding generation.
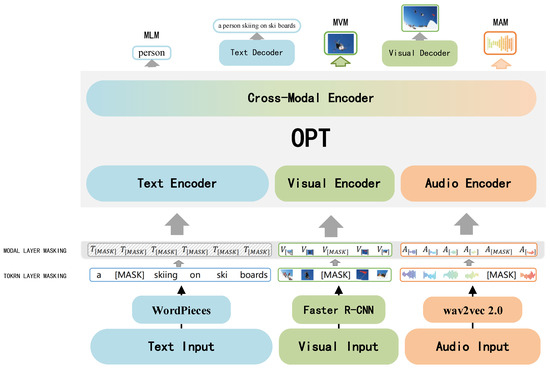
Figure 6.
Overview of OPT architecture.
At the beginning of 2021, based on the GPT-3, OpenAI used about 400 million image–text pairs to train Dall·E [43], and demonstrated strong zero sample image generation ability. Tsinghua University proposed CogView [44], also based on GPT-3, in 2021. In addition to zero sample image generation tasks, CogView has good performance in style learning, superresolution, image captioning, text–image reordering, and other aspects, and is better than Dall E in image generation tasks. Figure 7 shows its training process.
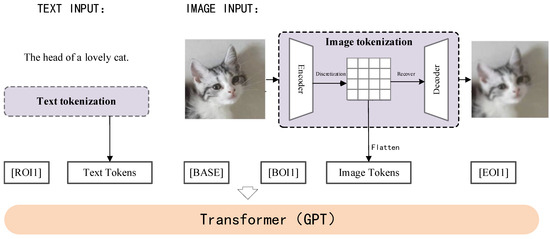
Figure 7.
Overview of CogView training architecture.
2.3.2. Grid Feature Single-Stream Model
The visual embedding mechanism for obtaining region features through the target detection model is mainly designed for specific visual tasks, such as target detection. In image–language understanding, important visual factors, such as the shape of objects and the spatial relationship between overlapping objects, are often lost, resulting in the reduction in accuracy of understanding tasks. At the same time, acquiring regional features requires a long time for interest region selection, which greatly increases the training cost. In order to solve these problems, some researchers are committed to embedding grid features as visual embedding so as to avoid prolonged region selection when obtaining region features. At the same time, aligning image grid pixels with text can obtain deeper semantic alignment between visual and language information.
Pixel-BERT, jointly proposed by the University of Science and Technology of Beijing, Sun Yat sen University, and Microsoft Research Institute in 2020, is the first vision–language pretraining model using ResNeXt-152 instead of a target detection module. The model architecture is shown in Figure 8. On the basis of using grid features as visual embedding, Pixel-BERT uses random pixel sampling to improve the robustness of visual feature learning. It has achieved excellent results: 2–4 percentage points precision better than VisualBERT, UNITER, and other models in VQA.
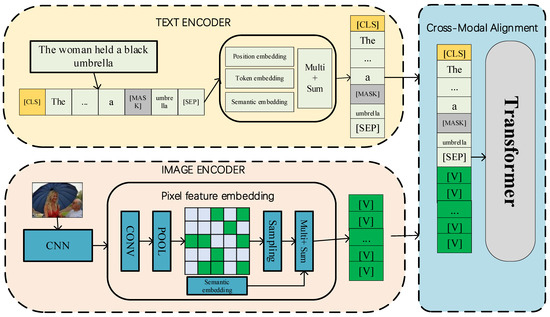
Figure 8.
Overview of Pixel-BERT architecture.
2.3.3. Patch Feature Single-Stream Model
Although the use of grid features saves a lot of time for region selection compared with the use of region features, the deep convolution network still occupies most of the computing resources. In order to solve the problem that pretraining takes too long due to the use of the deep convolution neural network to obtain regional or grid features, FashionBERT, proposed by the Alibaba team in 2020, cuts each image into patches with the same pixels and treats them as image markers, embeds the spatial position of the patches as position embedding, and finally embeds the sum of the image patch features, location embedding, and segmentation embedding as patch features. Among them, FashionBERT, using ResNeXt-101 as the backbone of the patch network, has achieved 91.09% accuracy on image retrieval tasks.
ViLT [45], proposed by Wonjae Kim et al. in 2021, uses the simplest visual embedding scheme, as shown in Figure 9, transforming the input image to 32 × 32 patch projection, and only 2.4 m parameters are required. ViLT reduces the training cost without greatly sacrificing its effect on downstream tasks, and is generally superior to UNITER, ImageBERT, and other models in zero sample retrieval.
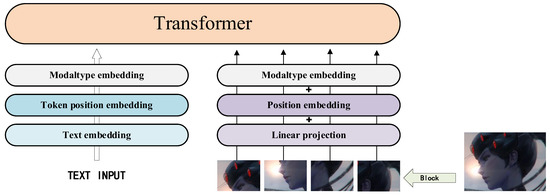
Figure 9.
Overview of ViLT framework.
SimVLM, proposed by Wang et al. in 2022, uses a large-scale, weak-label dataset to predict the pretraining task using only prefix language tasks for end-to-end training, relieving the requirement for object detection, and performs well on multiple downstream tasks with strong generalization and migration capabilities.
Table 5 summarizes the comparison of each single-stream architecture image–language pretraining model in the dimensions of pretraining tasks and downstream tasks. Table 6 shows the comparison of results of single-stream image–language pretraining models on some public datasets. The evaluation results presented in this paper all come from these related works.
Table 5.
Comparison of image–language pretraining models in single-stream architecture.
Table 6.
Comparison of results of single-stream architecture image–language pretraining models on selected datasets.
2.4. Dual Stream Architecture Model
The core idea of the dual-stream architecture model is to use multiple Transformer modules to process the data input of different modalities and then input the cross-modality Transformer for multimodal fusion. As such, dual-stream architecture can adapt to the different processing requirements of each modality and interact in different representation depths. Similarly to the classification of the single-stream architecture model, the dual-stream architecture model can be subdivided into region feature, patch feature, and dual-stream models according to visual embedding acquisition.
2.4.1. Region Feature Single-Stream Model
In 2019, teams at the Georgia Institute of Technology, Facebook Artificial Intelligence Research Institute, and Oregon State University proposed ViLBERT [46] by modeling image and language modalities. Firstly, text data is input into the text’s single-modality Transformer encoder after passing through the text embedding layer to extract context information. Secondly, the Fast R-CNN is used to extract the features of the input image and send them to the image embedding layer. Finally, the obtained text and image embedding are fused through the Co-attention Transformer to obtain the joint representation of image and text.
LXMERT [47], proposed by the University of North Carolina at Chapel Hill in 2019, uses a similar model architecture and has achieved the best results in VQA, GQA, and other visual question answering datasets. ViLBERT and LXMERT are the earliest dual-stream architecture image–language pretraining models. Table 7 shows a comparison between them in the dimensions of pretraining datasets, pretraining tasks, and fine-tuning downstream tasks, and Table 8 shows the evaluation results of them on selected public datasets.
Table 7.
Comparison between ViLBERT and LXMERT.
Table 8.
Evaluation results of ViLBERT and LXMERT on selected public datasets.
Facebook, Oregon State University, and Georgia Institute of technology jointly trained 12 datasets in different visual task directions (VQAv2, GQA, Visual Genome, COCO, Flickr30K, RefCOCO, Visual7W, GuessWhat, NLVR2, and SNLI-VE) in 2019 so as to put forward 12-in-1 [48], which can perform almost all tasks. Firstly, 12-in-1 adopts the training architecture based on ViLBERT, but when masking the visual area, it also masks other areas with significant overlap to avoid leaking visual information. Secondly, when the negative samples of multimodal alignment prediction are sampled, the masked multimodal modeling loss is not enforced so to effectively remove the noise introduced by the negative samples. Finally, dynamic training scheduler, task dependency tokens, and hyperparametric heuristic methods are introduced to better jointly train different datasets.
Pretraining tasks based on random masking, such as masked language modeling, do not add higher masking weight to the text describing semantics, resulting in that the trained model not being able to display the fine-grained semantics required by the real scene well. In order to solve this problem, ERNIE-ViL [49], proposed by the Baidu research team in 2020, constructs the target, attribute, and relationship prediction tasks by introducing the scene graph parser. The knowledge masking strategy of ERNIE 2.0 is used to learn more structured knowledge by masking phrases and named entities so as to obtain more detailed multimodal semantic alignment.
Based on the RUC-CAS-Wenlan dataset, the Wenlan team developed the BriVL in 2021. By introducing the cross-modality comparative learning framework, the model uses the image or language modality to construct the missing samples of the image–text pair for a given specific image–text pair, and provides a mechanism for constructing a dynamic dictionary of comparative learning based on MoCo [50]. Then, the number of negative samples is expanded and the representation ability of neural network is improved so as to merge more negative samples in limited GPU resources.
In 2022, Fudan University proposed a multilevel semantic alignment for vision–language pretraining called MVPTR. In order to simplify the learning of multimodal multilevel input, MVPTR is divided into two stages. The first stage focuses on multilevel representation learning within the modality, and the second stage strengthens the interaction between modalities through coarse and fine-grained semantic alignment tasks.
2.4.2. Patch Feature Dual-Stream Model
The performance of the target detection module highly affects the final effect of the pretraining model, which obtains region features through the target detection module. At the same time, due to the occlusion overlap in the image, different objects in the same image may have similar visual features, resulting in oversampling and noise in the visual area. These problems will lead to ambiguity in the extracted visual embedding and seriously affect the training effect. Alibaba and relevant teams of Tsinghua University obtained the visual embedding method based on VIT [51] and FashionBERT. Firstly, the image was segmented into patches and features were extracted. Secondly, the patches were arranged into sequences according to location. Finally, the combination of patch features, location embedding, and segmentation embedding was used as visual embedding. The team also optimized the model architecture, designed All-attention instead of Co-attention, and realized the combination of Self-attention and Co-attention to generate more context representations. A dual-stream extraction module is designed using Self-attention and feedforward neural network to separate the fused information again, so that the model can deal with single-modality and multimodal tasks at the same time. Based on its novel model architecture and M6 corpus dataset, the team launched InterBERT [52] and M6 models. Among them, M6-100B with 100 billion parameters is the largest known Chinese pretraining model with the ability of single-modality and multimodal understanding and generation.
METER [53], proposed by Dou et al. in 2022, specifically analyzed the effects of different visual encoders, text encoders, multimodal fusion modules, architectural design, and pretraining objectives on multimodal vision–language pretraining models, providing insights on how to train a vision–language model based on Transformer.
Table 9 shows the comparison of dual-stream image–language pretraining models in visual embedding mode, supporting datasets, pretraining tasks, and other dimensions.
Table 9.
Comparison of Dual Stream Architecture Image–Language Pretraining Models.
3. Video–Language Pretraining Model
The video–language pretraining model seeks internal semantic relationships between video and language modalities. Compared with the image–language pretraining model, the biggest difference of the video–language pretraining model is mainly reflected in the processing of input. For video input, the model extracts each frame of the video picture and extracts the features of continuous frames as segments. For text input, it obtains from video subtitles or uses automatic speech recognition extraction and uses LSTM network and WordPieces to break sentences and words.
3.1. Video–Language Pretraining Dataset
The datasets used for video–language pretraining are usually composed of video and text, in which the text data exists in the form of subtitles or supporting descriptions in the video. Similarly to the image–language dataset, the text data in the video–language dataset also has three forms: caption, Q&A, and description. Video–language datasets are mainly collected from YouTube or TV programs, and some datasets are directly trawled from the network. Table 10 shows the datasets commonly used in video–language pretraining and their main attributes.
Table 10.
Common datasets for video–language pretraining.
3.2. Video–Language Pretraining Model
VideoBERT [62], developed by Google Research Institute in 2019, was the first to study the video–language multimodal pretraining model. Its model architecture is shown in Figure 10. Its core idea is to treat the continuous frame as a segment, extract the features of the segment to obtain the feature vector, and finally cluster the feature vector through hierarchical vector quantization. However, the simple use of a clustering mechanism will lead to the loss of local detail information, which makes it difficult for the model to obtain the fine-grained semantic association between video and text, thus affecting the effectiveness of the model. In order to overcome this problem, ActBERT [63], studied by the University of Science and Technology of Sydney and the Baidu research team in 2020, designed a Tangled Transformer, as shown in Figure 11, to process three different inputs, i.e., the global behavior, regional target object, and text description, aggregated into a joint framework. Compared with VideoBERT in the video caption task, each measurement index has been improved to a certain extent.
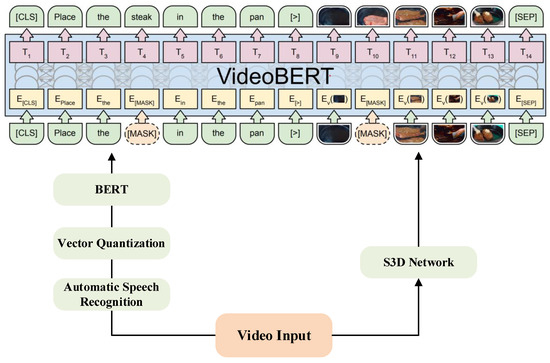
Figure 10.
Overview of VideoBERT architecture.
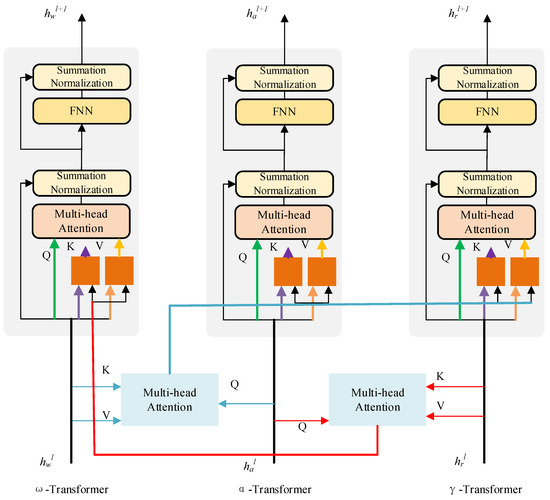
Figure 11.
Tangled Transformer architecture in ActBERT.
HERO [64], developed by Microsoft in 2020, uses a novel multilevel model architecture. Firstly, cross-modality Transformer is used to integrate text description and video frame representation; Secondly, the Temporal Transformer is input to obtain the sequential context embedding of video frames so that the surrounding frames are used as the global context. Finally, the task of video subtitle matching and frame sequence modeling, which pay more attention to multimodal time alignment, is used in training. HERO achieved 3.28% and 0.75% better results than STAGE [65] and multistream in-video question answering and video–language reasoning tasks on TVQA and VIOLIN datasets, respectively.
UniVL [66], proposed by the research team of Southwest Jiaotong University in 2020, is the first video–language pretraining model that can unify multimodal understanding and generation tasks. Its architecture includes two single-modality encoders, a cross-encoder and a decoder. The team designed two pretraining strategies during model training, namely, StagedP and EnhancedV. In the first stage of training, only the video–text joint task is used to pretrain the encoder. Secondly, the five tasks of video–text joint, masked language modeling, masked frame modeling, video–text alignment and language reconstruction are pretrained uniformly; Finally, the overall masking strategy is used to enhance the video representation. UniVL fine-tunes five downstream tasks: video retrieval, multimodal video subtitle, action segmentation, action positioning, and multimodal emotion analysis, and achieves the best performance in video retrieval and multimodal video subtitles. The other three tasks also achieve results much higher than the baseline.
VX2TEXT [67], proposed by Columbia University in 2021, can obtain more information from additional adjoint modal inputs (such as audio and speech) so as to better complete multimodal alignment. Its core idea is to map different modalities to the public semantic space, directly use text coding to realize fusion multimodality, and in-video question answering, video caption generation, and audiovisual scene dialogue has achieved a high level, which proves the effectiveness of simple fusion means.
VIOLET [68], proposed by Fu et al. in 2022, uses video transformers to explicitly model the temporal dynamics of video input, and designed a new pretraining task, namely, mask visual marker modeling (MVM), which refers to quantizing video inputs into masked prediction targets and then reconstructing the original visual scene based on discrete visual tokens.
Table 11 shows the comparison of video–language pretraining models in datasets, pretraining tasks, and other dimensions.
Table 11.
Comparison of video–language pretraining models.
4. Problem Analysis and Development Trends
Although the vision–language pretraining model has shown its ability to learn the joint representation of vision and language in many downstream tasks, it still faces many problems restricting its development, mainly in the following areas.
(a) Difficult deployment. Most vision–language pretraining models have huge structures and many parameters. For example, M6-100B developed by Alibaba has 100 billion parameters. Although the high number of parameters ensures the model effectiveness, the cost is too high to be deployed in reality.
(b) Single architecture. The Transformer module mainly used in the vision–language pretraining model has proved its effectiveness in the fields of natural language processing, computer vision, and even multimodality, but it still has some shortcomings, such as complexity calculation and limited length of input token, which are not conducive to the expansion of a multimodal pretraining model.
(c) Insufficient dataset. The collection and development of high-quality multimodal data is more difficult than single-modality data. Firstly, the total amount of multimodal data is larger. Secondly, it is difficult to effectively judge whether the visual and text data are aligned in data cleaning, which seriously affects the quality of multimodal datasets. At the same time, the mainstream vision–language datasets are mainly based on English, while the multimodal datasets of Chinese and other languages are seriously insufficient, which limits the general ability of vision–language model training.
(d) Insufficient interpretability and high uncertainty. Firstly, the decision-making process of the vision–language pretraining model is highly unknowable, so it is difficult to understand the actual reasoning process. Secondly, the model finds it difficult to detect the abnormality of the problem. For questions outside the setting, it usually outputs highly counterintuitive wrong answers.
In order to solve these problems, vision–language pretraining can be studied in the following directions in the future.
(a) Multitask high-quality model research. Research has proved that the effect of a single task of a pretraining model trained by multiple different domain tasks is better than that being trained by single domain tasks. At the same time, novel and efficient pretraining tasks, such as text-based image feature generation and cross-language self-coding, also greatly optimize the training process. For the existing models, how to use more efficient pretraining tasks and higher-quality datasets in the pretraining process so as to improve its accuracy in downstream tasks will be a research hotspot in the next stage.
(b) Model compression research. The huge architecture of the pretraining model seriously increases the cost of its deployment. Future work should focus on how to reduce the architecture and parameters without affecting the effectiveness of the model. Many researchers have tried to compress the model by means of model pruning, parameter sharing, knowledge extraction, and model quantization, and achieved considerable results. Model pruning refers to selectively discarding the Transformer module and self-attention head or reducing the weight of the attention layer and linear layer in the training process. Parameter sharing is reducing the number of parameters of the model by sharing parameters with similar module units. Knowledge extraction is devoted to training small models to reproduce the performance of a large model. Model quantization compresses high-precision floating-point parameters into low-precision floating-point parameters so as to reduce the number of parameters [69].
(c) Modality expansion research. This is similar to the work of OPT and UNIMO in expanding the number of modalities and unifying single-modality and multimodal tasks. For the vision–language pretraining model, how to seek its joint representation for more modalities and how to unify single and multimodal tasks with a more efficient and streamlined architecture is also an urgent problem to be studied in the future.
(d) Interpretability research. Due to the general deep nonlinear architecture of the pretraining model, the decision-making process is highly unknown. At present, there is no research to prove why linking different modalities can achieve such a great improvement, and whether multimodal joint training will affect the individual learning and training of each modality. These theoretical problems still need to be proved by future research.
5. Summary
The vision–language pretraining model obtains its joint representation by seeking the internal semantic relationship under different representations between vision and language modalities. The results far exceed the baseline in each vision–language downstream task, which fully proves the effectiveness of pretraining in multimodal tasks. Firstly, taking the classification architecture of vision–language multimodal pretraining models as the clue, this paper comprehensively expounds on the model architecture, pretraining work, and downstream tasks of vision–language pretraining models, and finally discusses the existing problems and possible research directions in the future. As a hot research direction in the last two years, vision–language pretraining models have shown their advantages in exploring the deep semantic alignment of vision–language multiple modalities. This area is worthy of more research and investment of more energy in exploration so as to provide important technical support for the realization of more general artificial intelligence.
Author Contributions
Conceptualization, H.W. and R.H.; formal analysis, H.W. and R.H.; investigation, H.W., R.H. and J.Z.; data curation, H.W.; writing—original draft preparation, H.W.; writing—review and editing, H.W., R.H. and J.Z.; supervision, R.H. and J.Z.; funding acquisition, J.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China, grant 62002384.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Tian, H.; Wu, H.; Wang, H. ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding. Proc. AAAI Conf. Artif. Intell. 2020, 34, 8968–8975. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G.E. A Simple Framework for Contrastive Learning of Visual Representations. arXiv 2020. [Google Scholar] [CrossRef]
- Zhai, X.; Kolesnikov, A.; Houlsby, N.; Beyer, L. Scaling Vision Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Jia, D.; Wei, D.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D. VQA: Visual Question Answering. Int. J. Comput. Vis. 2015, 123, 4–31. [Google Scholar]
- Hudson, D.A.; Manning, C.D. GQA: A New Dataset for Real-World Visual Reasoning and Compositional Question Answering. arXiv 2019. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.D.; Girshick, R.B.; Hays, J.; Perona, P.; Ramanan, D.; Doll, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer International Publishing: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hate, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef]
- Plummer, B.A.; Wang, L. Flickr30k Entities: Collecting Region-to-Phrase Correspondences for Richer Image-to-Sentence Models. Int. J. Comput. Vis. 2017, 123, 1–20. [Google Scholar] [CrossRef]
- Kazemzadeh, S.; Ordonez, V.; Matten, M.; Berg, T.L. ReferItGame: Referring to Objects in Photographs of Natural Scenes. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Zhu, Y.; Groth, O.; Bernstein, M.; Li, F.F. Visual7W: Grounded Question Answering in Images; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Vries, H.D.; Strub, F.; Chandar, S.; Pietquin, O.; Larochelle, H.; Courville, A.C. GuessWhat?! Visual Object Discovery through Multi-Modal Dialogue; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Suhr, A.; Zhou, S.; Zhang, I.; Bai, H.; Artzi, Y. A Corpus for Reasoning about Natural Language Grounded in Photographs. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Huo, Y.; Zhang, M.; Liu, G.; Lu, H.; Gao, Y.; Yang, G.; Wen, J.; Zhang, H.; Xu, B.; Zheng, W.; et al. WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training. arXiv 2021. [Google Scholar] [CrossRef]
- Lin, J.; Men, R.; Yang, A.; Zhou, C.; Ding, M.; Zhang, Y.; Wang, P.; Wang, A.; Jiang, L.; Jia, X.; et al. M6: A Chinese Multimodal Pretrainer. arXiv 2021. [Google Scholar] [CrossRef]
- Huang, Z.; Zeng, Z.; Liu, B.; Fu, D.; Fu, J. Pixel-BERT: Aligning Image Pixels with Text by Deep Multi-Modal Transformers. arXiv 2020. [Google Scholar] [CrossRef]
- Gao, D.; Jin, L.; Chen, B.; Qiu, M.; Li, P.; Wei, Y.; Hu, Y.; Wang, H. FashionBERT: Text and Image Matching with Adaptive Loss for Cross-modal Retrieval. arXiv 2020. [Google Scholar] [CrossRef]
- Li, Z.; Fan, Z.; Tou, H.; Wei, Z. MVP: Multi-Stage Vision-Language Pre-Training via Multi-Level Semantic Alignment. arXiv 2022. [Google Scholar] [CrossRef]
- Wang, Z.; Yu, J.; Yu, A.W.; Dai, Z.; Tsvetkov, Y.; Cao, Y. Simvlm: Simple visual language model pretraining with weak supervision. arXiv 2021. [Google Scholar] [CrossRef]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7373–7382. [Google Scholar]
- Alberti, C.; Ling, J.; Collins, M.; David, R. Fusion of Detected Objects in Text for Visual Question Answering. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Li, L.H.; Yatskar, M.; Yin, D.; Hsieh, C.J.; Chang, K.W. VisualBERT: A Simple and Performant Baseline for Vision and Language. arXiv 2019. [Google Scholar] [CrossRef]
- Su, W.; Zhu, X.; Cao, Y.; Li, B.; Lu, L.; Wei, F.; Dai, J. VL-BERT: Pre-training of Generic Visual-Linguistic Representations. arXiv 2019. [Google Scholar] [CrossRef]
- Chen, Y.C.; Li, L.; Yu, L.; Kholy, A.E.; Ahmed, F.; Gan, Z.; Cheng, Y.; Liu, J. UNITER: Learning UNiversal Image-TExt Representations. arXiv 2019. [Google Scholar] [CrossRef]
- Zhou, L.; Palangi, H.; Zhang, L.; Hu, H.; Corso, J.J.; Gao, J. Unified Vision-Language Pre-Training for Image Captioning and VQA. arXiv 2019. [Google Scholar] [CrossRef]
- Li, G.; Duan, N.; Fang, Y.; Gong, M.; Jiang, D. Unicoder-VL: A Universal Encoder for Vision and Language by Cross-modal Pre-training. arXiv 2019. [Google Scholar] [CrossRef]
- Lample, G.; Conneau, A. Cross-lingual Language Model Pretraining. arXiv 2019. [Google Scholar] [CrossRef]
- Huang, H.; Liang, Y.; Duan, N.; Gong, M.; Shou, L.; Jiang, D.; Zhou, M. Unicoder: A Universal Language Encoder by Pre-training with Multiple Cross-lingual Tasks. arXiv 2019. [Google Scholar] [CrossRef]
- Qi, D.; Su, L.; Song, J.; Cui, E.; Bharti, T.; Sacheti, A. ImageBERT: Cross-modal Pre-training with Large-scale Weak-supervised Image-Text Data. arXiv 2020. [Google Scholar] [CrossRef]
- Li, X.; Yin, X.; Li, C.; Zhang, P.; Hu, X.; Zhang, L.; Wang, L.; Hu, H.; Dong, L.; Wei, F.; et al. Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks. arXiv 2020. [Google Scholar] [CrossRef]
- Zhang, P.; Li, X.; Hu, X.; Yang, J.; Zhang, L.; Wang, L.; Choi, Y.; Gao, J. VinVL: Making Visual Representations Matter in Vision-Language Models. arXiv 2021. [Google Scholar] [CrossRef]
- Krasin, I.; Duerig, T.; Alldrin, N.; Ferrari, V.; Abu-El-Haija, S.; Kuznetsova, A.; Rom, H.; Uijlings, J.; Popov, S.; Kamali, S.; et al. OpenImages: A Public Dataset for Large-Scale Multi-Label and Multi-Class Image Classification. 2017. Available online: https://github.com/openimages (accessed on 10 October 2022).
- Shao, S.; Li, Z.; Zhang, T.; Peng, C.; Yu, G.; Zhang, X.; Li, J.; Sun, J. Objects365: A Large-Scale, High-Quality Dataset for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Gan, Z.; Chen, Y.C.; Li, L.; Zhu, C.; Cheng, Y.; Liu, J. Large-Scale Adversarial Training for Vision-and-Language Representation Learning. arXiv 2020. [Google Scholar] [CrossRef]
- Li, W.; Gao, C.; Niu, G.; Xiao, X.; Liu, H.; Liu, J.; Wu, H.; Wang, H. UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning. arXiv 2020. [Google Scholar] [CrossRef]
- Baevski, A.; Zhou, H.; Mohamed, A.; Auli, M. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. arXiv 2020. [Google Scholar] [CrossRef]
- Liu, J.; Zhu, X.; Liu, F.; Guo, L.; Zhao, Z.; Sun, M.; Wang, W.; Lu, H.; Zhou, S.; Zhang, J.; et al. OPT: Omni-Perception Pre-Trainer for Cross-Modal Understanding and Generation. arXiv 2021. [Google Scholar] [CrossRef]
- Johnson, M.; Schuster, M.; Le, Q.V.; Krikun, M.; Wu, Y.; Chen, Z.; Thorat, N.; Viegas, F.B.; Wattenberg, M.; Carrado, G.; et al. Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation. Trans. Assoc. Comput. Linguist. 2016, 5, 339–351. [Google Scholar] [CrossRef]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-Shot Text-to-Image Generation. arXiv 2021. [Google Scholar] [CrossRef]
- Ding, M.; Yang, Z.; Hong, W.; Zheng, W.; Zhou, C.; Yin, D.; Lin, J.; Zou, X.; Shao, Z.; Yang, H.; et al. CogView: Mastering Text-to-Image Generation via Transformers. arXiv 2021. [Google Scholar] [CrossRef]
- Kim, W.; Son, B.; Kim, I. ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision. arXiv 2021. [Google Scholar] [CrossRef]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks. arXiv 2019. [Google Scholar] [CrossRef]
- Tan, H.; Bansal, M. LXMERT: Learning Cross-Modality Encoder Representations from Transformers. arXiv 2019. [Google Scholar] [CrossRef]
- Lu, J.; Goswami, V.; Rohrbach, M.; Parikh, D.; Lee, S. 12-in-1: Multi-Task Vision and Language Representation Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Yu, F.; Tang, J.; Yin, W.; Sun, Y.; Tian, H.; Wu, H.; Wang, H. ERNIE-ViL: Knowledge Enhanced Vision-Language Representations through Scene Graph. arXiv 2020. [Google Scholar] [CrossRef]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R.B. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020. [Google Scholar] [CrossRef]
- Lin, J.; Yang, A.; Zhang, Y.; Liu, Y.; Zhou, J.; Yang, H. InterBERT: Vision-and-Language Interaction for Multi-modal Pretraining. arXiv 2020. [Google Scholar] [CrossRef]
- Dou, Z.Y.; Xu, Y.; Gan, Z.; Wang, J.; Wang, S.; Wang, L.; Zhu, C.; Zhang, P.; Yuan, L.; Peng, N.; et al. An empirical study of training end-to-end vision-and-language transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 18166–18176. [Google Scholar]
- Miech, A.; Zhukov, D.; Alayrac, J.B.; Tapaswi, M.; Laptev, I.; Sivic, J. HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Lei, J.; Yu, L.; Bansal, M.; Berg, T. TVQA: Localized, Compositional Video Question Answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar]
- Xu, J.; Tao, M.; Yao, T.; Rui, Y. MSR-VTT: A Large Video Description Dataset for Bridging Video and Language. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Zhou, L.; Xu, C.; Corso, J.J. Towards Automatic Learning of Procedures from Web Instructional Videos. arXiv 2017. [Google Scholar] [CrossRef]
- Lei, J.; Yu, L.; Berg, T.L.; Bansal, M. TVR: A Large-Scale Dataset for Video-Subtitle Moment Retrieval. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Tang, Y.; Ding, D.; Rao, Y.; Zheng, Y.; Zhang, D.; Zhao, L.; Liu, J.; Zhou, J. COIN: A Large-scale Dataset for Comprehensive Instructional Video Analysis. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Zhukov, D.; Alayrac, J.B.; Cinbis, R.G.; Fouhey, D.F.; Laptev, I.; Sivic, J. Cross-task weakly supervised learning from instructional videos. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Liu, J.; Chen, W.; Cheng, Y.; Gan, Z.; Yu, L.; Yang, Y.; Liu, J. VIOLIN: A Large-Scale Dataset for Video-and-Language Inference. arXiv 2020. [Google Scholar] [CrossRef]
- Sun, C.; Myers, A.; Vondrick, C.; Murphy, K.; Schmid, C. VideoBERT: A Joint Model for Video and Language Representation Learning. arXiv 2019. [Google Scholar] [CrossRef]
- Zhu, L.; Yang, Y. ActBERT: Learning Global-Local Video-Text Representations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Li, L.; Chen, Y.C.; Cheng, Y.; Gan, Y.; Yu, L.; Liu, J. HERO: Hierarchical Encoder for Video+Language Omni-representation Pre-training. arXiv 2020. [Google Scholar] [CrossRef]
- Lei, J.; Yu, L.; Berg, T.L.; Bansal, M. TVQA+: Spatio-Temporal Grounding for Video Question Answering. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar]
- Luo, H.; Ji, L.; Shi, B.; Huang, H.; Duan, N.; Li, T.; Chen, X.; Zhou, M. UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation. arXiv 2020. [Google Scholar] [CrossRef]
- Lin, X.; Bertasius, G.; Wang, J.; Chang, S.F.; Parikh, D.; Torresani, L. VX2TEXT: End-to-End Learning of Video-Based Text Generation From Multimodal Inputs. arXiv 2021. [Google Scholar] [CrossRef]
- Fu, T.J.; Li, L.; Gan, Z.; Lin, K.; Wang, W.Y.; Wang, L.; Liu, Z. VIOLET: End-to-end video-language transformers with masked visual-token modeling. arXiv 2021. [Google Scholar] [CrossRef]
- Han, X.; Zhang, Z.; Ding, N.; Gu, Y.; Liu, X.; Huo, Y.; Qiu, J.; Yao, Y.; Zhang, A.; Zhang, L.; et al. Pre-Trained Models: Past, Present and Future. arXiv 2021. [Google Scholar] [CrossRef]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).