
Research Progress on Vision–Language Multimodal Pretraining Model Technology

Abstract
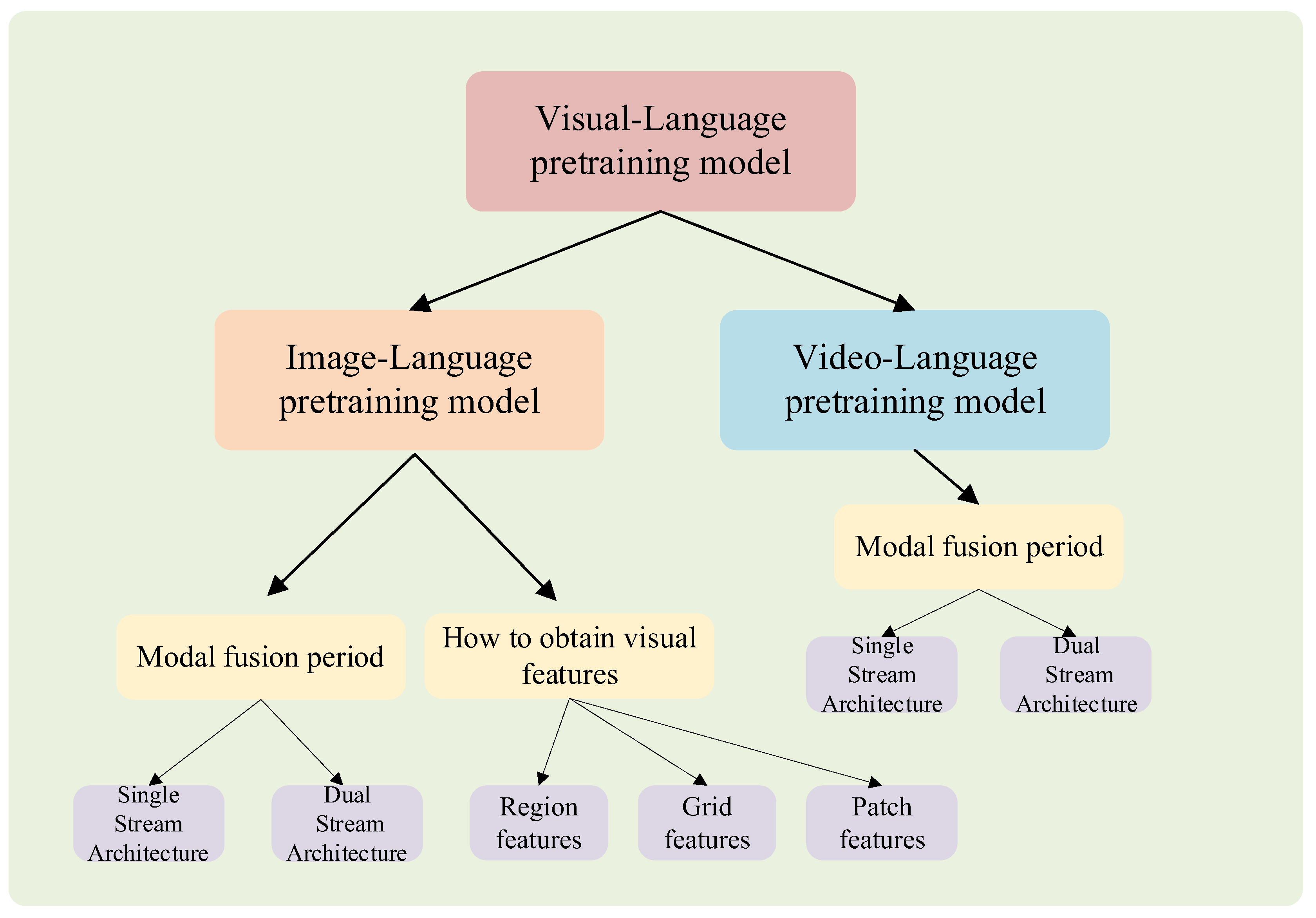
:1. Introduction
2. Image–Language Pretraining Model
2.1. Image–Language Pretraining Datasets
2.2. Image–Language Pretraining Tasks
2.2.1. Masked Language Modeling (MLM)
2.2.2. Masked Region Modeling (MRM)
2.2.3. Image–Text Matching (ITM)
2.2.4. Other Pretraining Tasks
2.3. Single-Stream Architecture Model
2.3.1. Region Feature Single-Stream Model
2.3.2. Grid Feature Single-Stream Model
2.3.3. Patch Feature Single-Stream Model
2.4. Dual Stream Architecture Model
2.4.1. Region Feature Single-Stream Model
2.4.2. Patch Feature Dual-Stream Model
3. Video–Language Pretraining Model
3.1. Video–Language Pretraining Dataset
3.2. Video–Language Pretraining Model
4. Problem Analysis and Development Trends
5. Summary
Author Contributions
Funding
Conflicts of Interest
References
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Tian, H.; Wu, H.; Wang, H. ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding. Proc. AAAI Conf. Artif. Intell. 2020, 34, 8968–8975. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G.E. A Simple Framework for Contrastive Learning of Visual Representations. arXiv 2020. [Google Scholar] [CrossRef]
- Zhai, X.; Kolesnikov, A.; Houlsby, N.; Beyer, L. Scaling Vision Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Jia, D.; Wei, D.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D. VQA: Visual Question Answering. Int. J. Comput. Vis. 2015, 123, 4–31. [Google Scholar]
- Hudson, D.A.; Manning, C.D. GQA: A New Dataset for Real-World Visual Reasoning and Compositional Question Answering. arXiv 2019. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.D.; Girshick, R.B.; Hays, J.; Perona, P.; Ramanan, D.; Doll, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer International Publishing: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hate, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef] [Green Version]
- Plummer, B.A.; Wang, L. Flickr30k Entities: Collecting Region-to-Phrase Correspondences for Richer Image-to-Sentence Models. Int. J. Comput. Vis. 2017, 123, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Kazemzadeh, S.; Ordonez, V.; Matten, M.; Berg, T.L. ReferItGame: Referring to Objects in Photographs of Natural Scenes. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Zhu, Y.; Groth, O.; Bernstein, M.; Li, F.F. Visual7W: Grounded Question Answering in Images; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Vries, H.D.; Strub, F.; Chandar, S.; Pietquin, O.; Larochelle, H.; Courville, A.C. GuessWhat?! Visual Object Discovery through Multi-Modal Dialogue; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Suhr, A.; Zhou, S.; Zhang, I.; Bai, H.; Artzi, Y. A Corpus for Reasoning about Natural Language Grounded in Photographs. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Huo, Y.; Zhang, M.; Liu, G.; Lu, H.; Gao, Y.; Yang, G.; Wen, J.; Zhang, H.; Xu, B.; Zheng, W.; et al. WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training. arXiv 2021. [Google Scholar] [CrossRef]
- Lin, J.; Men, R.; Yang, A.; Zhou, C.; Ding, M.; Zhang, Y.; Wang, P.; Wang, A.; Jiang, L.; Jia, X.; et al. M6: A Chinese Multimodal Pretrainer. arXiv 2021. [Google Scholar] [CrossRef]
- Huang, Z.; Zeng, Z.; Liu, B.; Fu, D.; Fu, J. Pixel-BERT: Aligning Image Pixels with Text by Deep Multi-Modal Transformers. arXiv 2020. [Google Scholar] [CrossRef]
- Gao, D.; Jin, L.; Chen, B.; Qiu, M.; Li, P.; Wei, Y.; Hu, Y.; Wang, H. FashionBERT: Text and Image Matching with Adaptive Loss for Cross-modal Retrieval. arXiv 2020. [Google Scholar] [CrossRef]
- Li, Z.; Fan, Z.; Tou, H.; Wei, Z. MVP: Multi-Stage Vision-Language Pre-Training via Multi-Level Semantic Alignment. arXiv 2022. [Google Scholar] [CrossRef]
- Wang, Z.; Yu, J.; Yu, A.W.; Dai, Z.; Tsvetkov, Y.; Cao, Y. Simvlm: Simple visual language model pretraining with weak supervision. arXiv 2021. [Google Scholar] [CrossRef]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7373–7382. [Google Scholar]
- Alberti, C.; Ling, J.; Collins, M.; David, R. Fusion of Detected Objects in Text for Visual Question Answering. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Li, L.H.; Yatskar, M.; Yin, D.; Hsieh, C.J.; Chang, K.W. VisualBERT: A Simple and Performant Baseline for Vision and Language. arXiv 2019. [Google Scholar] [CrossRef]
- Su, W.; Zhu, X.; Cao, Y.; Li, B.; Lu, L.; Wei, F.; Dai, J. VL-BERT: Pre-training of Generic Visual-Linguistic Representations. arXiv 2019. [Google Scholar] [CrossRef]
- Chen, Y.C.; Li, L.; Yu, L.; Kholy, A.E.; Ahmed, F.; Gan, Z.; Cheng, Y.; Liu, J. UNITER: Learning UNiversal Image-TExt Representations. arXiv 2019. [Google Scholar] [CrossRef]
- Zhou, L.; Palangi, H.; Zhang, L.; Hu, H.; Corso, J.J.; Gao, J. Unified Vision-Language Pre-Training for Image Captioning and VQA. arXiv 2019. [Google Scholar] [CrossRef]
- Li, G.; Duan, N.; Fang, Y.; Gong, M.; Jiang, D. Unicoder-VL: A Universal Encoder for Vision and Language by Cross-modal Pre-training. arXiv 2019. [Google Scholar] [CrossRef]
- Lample, G.; Conneau, A. Cross-lingual Language Model Pretraining. arXiv 2019. [Google Scholar] [CrossRef]
- Huang, H.; Liang, Y.; Duan, N.; Gong, M.; Shou, L.; Jiang, D.; Zhou, M. Unicoder: A Universal Language Encoder by Pre-training with Multiple Cross-lingual Tasks. arXiv 2019. [Google Scholar] [CrossRef]
- Qi, D.; Su, L.; Song, J.; Cui, E.; Bharti, T.; Sacheti, A. ImageBERT: Cross-modal Pre-training with Large-scale Weak-supervised Image-Text Data. arXiv 2020. [Google Scholar] [CrossRef]
- Li, X.; Yin, X.; Li, C.; Zhang, P.; Hu, X.; Zhang, L.; Wang, L.; Hu, H.; Dong, L.; Wei, F.; et al. Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks. arXiv 2020. [Google Scholar] [CrossRef]
- Zhang, P.; Li, X.; Hu, X.; Yang, J.; Zhang, L.; Wang, L.; Choi, Y.; Gao, J. VinVL: Making Visual Representations Matter in Vision-Language Models. arXiv 2021. [Google Scholar] [CrossRef]
- Krasin, I.; Duerig, T.; Alldrin, N.; Ferrari, V.; Abu-El-Haija, S.; Kuznetsova, A.; Rom, H.; Uijlings, J.; Popov, S.; Kamali, S.; et al. OpenImages: A Public Dataset for Large-Scale Multi-Label and Multi-Class Image Classification. 2017. Available online: https://github.com/openimages (accessed on 10 October 2022).
- Shao, S.; Li, Z.; Zhang, T.; Peng, C.; Yu, G.; Zhang, X.; Li, J.; Sun, J. Objects365: A Large-Scale, High-Quality Dataset for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Gan, Z.; Chen, Y.C.; Li, L.; Zhu, C.; Cheng, Y.; Liu, J. Large-Scale Adversarial Training for Vision-and-Language Representation Learning. arXiv 2020. [Google Scholar] [CrossRef]
- Li, W.; Gao, C.; Niu, G.; Xiao, X.; Liu, H.; Liu, J.; Wu, H.; Wang, H. UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning. arXiv 2020. [Google Scholar] [CrossRef]
- Baevski, A.; Zhou, H.; Mohamed, A.; Auli, M. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. arXiv 2020. [Google Scholar] [CrossRef]
- Liu, J.; Zhu, X.; Liu, F.; Guo, L.; Zhao, Z.; Sun, M.; Wang, W.; Lu, H.; Zhou, S.; Zhang, J.; et al. OPT: Omni-Perception Pre-Trainer for Cross-Modal Understanding and Generation. arXiv 2021. [Google Scholar] [CrossRef]
- Johnson, M.; Schuster, M.; Le, Q.V.; Krikun, M.; Wu, Y.; Chen, Z.; Thorat, N.; Viegas, F.B.; Wattenberg, M.; Carrado, G.; et al. Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation. Trans. Assoc. Comput. Linguist. 2016, 5, 339–351. [Google Scholar] [CrossRef]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-Shot Text-to-Image Generation. arXiv 2021. [Google Scholar] [CrossRef]
- Ding, M.; Yang, Z.; Hong, W.; Zheng, W.; Zhou, C.; Yin, D.; Lin, J.; Zou, X.; Shao, Z.; Yang, H.; et al. CogView: Mastering Text-to-Image Generation via Transformers. arXiv 2021. [Google Scholar] [CrossRef]
- Kim, W.; Son, B.; Kim, I. ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision. arXiv 2021. [Google Scholar] [CrossRef]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks. arXiv 2019. [Google Scholar] [CrossRef]
- Tan, H.; Bansal, M. LXMERT: Learning Cross-Modality Encoder Representations from Transformers. arXiv 2019. [Google Scholar] [CrossRef]
- Lu, J.; Goswami, V.; Rohrbach, M.; Parikh, D.; Lee, S. 12-in-1: Multi-Task Vision and Language Representation Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Yu, F.; Tang, J.; Yin, W.; Sun, Y.; Tian, H.; Wu, H.; Wang, H. ERNIE-ViL: Knowledge Enhanced Vision-Language Representations through Scene Graph. arXiv 2020. [Google Scholar] [CrossRef]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R.B. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020. [Google Scholar] [CrossRef]
- Lin, J.; Yang, A.; Zhang, Y.; Liu, Y.; Zhou, J.; Yang, H. InterBERT: Vision-and-Language Interaction for Multi-modal Pretraining. arXiv 2020. [Google Scholar] [CrossRef]
- Dou, Z.Y.; Xu, Y.; Gan, Z.; Wang, J.; Wang, S.; Wang, L.; Zhu, C.; Zhang, P.; Yuan, L.; Peng, N.; et al. An empirical study of training end-to-end vision-and-language transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 18166–18176. [Google Scholar]
- Miech, A.; Zhukov, D.; Alayrac, J.B.; Tapaswi, M.; Laptev, I.; Sivic, J. HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Lei, J.; Yu, L.; Bansal, M.; Berg, T. TVQA: Localized, Compositional Video Question Answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar]
- Xu, J.; Tao, M.; Yao, T.; Rui, Y. MSR-VTT: A Large Video Description Dataset for Bridging Video and Language. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Zhou, L.; Xu, C.; Corso, J.J. Towards Automatic Learning of Procedures from Web Instructional Videos. arXiv 2017. [Google Scholar] [CrossRef]
- Lei, J.; Yu, L.; Berg, T.L.; Bansal, M. TVR: A Large-Scale Dataset for Video-Subtitle Moment Retrieval. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Tang, Y.; Ding, D.; Rao, Y.; Zheng, Y.; Zhang, D.; Zhao, L.; Liu, J.; Zhou, J. COIN: A Large-scale Dataset for Comprehensive Instructional Video Analysis. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Zhukov, D.; Alayrac, J.B.; Cinbis, R.G.; Fouhey, D.F.; Laptev, I.; Sivic, J. Cross-task weakly supervised learning from instructional videos. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Liu, J.; Chen, W.; Cheng, Y.; Gan, Z.; Yu, L.; Yang, Y.; Liu, J. VIOLIN: A Large-Scale Dataset for Video-and-Language Inference. arXiv 2020. [Google Scholar] [CrossRef]
- Sun, C.; Myers, A.; Vondrick, C.; Murphy, K.; Schmid, C. VideoBERT: A Joint Model for Video and Language Representation Learning. arXiv 2019. [Google Scholar] [CrossRef]
- Zhu, L.; Yang, Y. ActBERT: Learning Global-Local Video-Text Representations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Li, L.; Chen, Y.C.; Cheng, Y.; Gan, Y.; Yu, L.; Liu, J. HERO: Hierarchical Encoder for Video+Language Omni-representation Pre-training. arXiv 2020. [Google Scholar] [CrossRef]
- Lei, J.; Yu, L.; Berg, T.L.; Bansal, M. TVQA+: Spatio-Temporal Grounding for Video Question Answering. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar]
- Luo, H.; Ji, L.; Shi, B.; Huang, H.; Duan, N.; Li, T.; Chen, X.; Zhou, M. UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation. arXiv 2020. [Google Scholar] [CrossRef]
- Lin, X.; Bertasius, G.; Wang, J.; Chang, S.F.; Parikh, D.; Torresani, L. VX2TEXT: End-to-End Learning of Video-Based Text Generation From Multimodal Inputs. arXiv 2021. [Google Scholar] [CrossRef]
- Fu, T.J.; Li, L.; Gan, Z.; Lin, K.; Wang, W.Y.; Wang, L.; Liu, Z. VIOLET: End-to-end video-language transformers with masked visual-token modeling. arXiv 2021. [Google Scholar] [CrossRef]
- Han, X.; Zhang, Z.; Ding, N.; Gu, Y.; Liu, X.; Huo, Y.; Qiu, J.; Yao, Y.; Zhang, A.; Zhang, L.; et al. Pre-Trained Models: Past, Present and Future. arXiv 2021. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tasks | Index | Formula |
|---|---|---|
| Visual Question Answering (VQA) | Precision | |
| Image–Text Retrieval (ITR) | Precision Recall F1 score | |
| Image Generation | IS FID | |
| Natural Language for Visual Reasoning (NLVR2) | Precision | |
| Visual Commonsense Reasoning (VCR) | Precision |
| Datasets | Task | Languages | Text Type | Image(K) | Text(K) | Image Size | Text Size |
|---|---|---|---|---|---|---|---|
| VQA | VQA | ENGLISH | Q&A | 270 | 3760 | - | - |
| VQA v2.0 | 203 | 7684 | - | - | |||
| GQA | 113 | 22,000 | - | - | |||
| Visual Genome [12] | CAPTION | 108 | 8856 | - | - | ||
| COCO | ITR | 328 | 2500 | - | - | ||
| Flickr30k [13] | 31 | 158 | - | - | |||
| RefCOCO [14] | REFERRING | 20 | 130 | - | - | ||
| Visual 7W [15] | 47 | 139 | - | - | |||
| GuessWhat [16] | 66 | 800 | - | - | |||
| NLVR2 [17] | NLVR2 | 127 | 30 | - | - | ||
| RUC-CAS-WenLan [18] | IMAGE CAPTION | CHINESE | 30,000 | 30,000 | - | - | |
| M6-Corpus [19] | IMAGE GENERATING | - | - | 1.9 TB | 292 GB |
| Model | VCR | VQA2.0 | NLVR2 | Flicker30k | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Q-A | QA-R | Q-AR | Test Dev | Test Std | Dev | Test-P | Test-U | Cons | Sentence Retrieval | Image Retrieval | ||||||||
| Val | Test | Val | Test | Val | Test | - | - | - | - | - | - | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |
| B2T2 | 73.2 | 74.0 | 77.1 | 77.1 | 56.6 | 57.1 | - | - | - | - | - | - | - | - | - | - | - | - |
| VisualBERT | 70.8 | 71.6 | 73.2 | 73.2 | 52.2 | 52.4 | 70.80 | 71.00 | 67.4 | 67.0 | 67.3 | 26.9 | - | - | - | - | - | - |
| VL-BERT | 75.5 | 75.8 | 77.9 | 78.4 | 58.9 | 59.7 | 71.79 | 72.22 | - | - | - | - | - | - | - | - | - | - |
| UNITER | - | - | - | - | - | - | - | - | - | - | - | - | 84.7 | 97.1 | 99.0 | 71.5 | 91.2 | 95.2 |
| Unicoder-VL | 72.6 | 73.4 | 74.5 | 74.4 | 54.5 | 54.9 | - | - | - | - | - | - | 86.2 | 96.3 | 99.0 | 71.5 | 90.9 | 94.9 |
| ImageBERT | - | - | - | - | - | - | - | - | - | - | - | - | 87.0 | 97.6 | 96.0 | 73.1 | 92.6 | 96.0 |
| Model | Proposed Year | Pretraining Datasets | Pretraining Tasks | Downstream Tasks | Visual–Text Joint |
|---|---|---|---|---|---|
| B2T2 | 2019 | Conceptual Captions | Image text alignment, Masked language modeling | VCR | Integrating BERT and target detection model to process text and visual input. After the image features obtained from the target detection model are input into the Transformer as unordered tokens and supporting text information to obtain its cross-modality joint representation. |
| VisualBERT | 2019 | COCO Captions | Image text alignment, Masked language modeling | VQA, VCR, NLVR2, Phrase generation | |
| VL-BERT | 2019 | Conceptual Captions BooksCorpus English Wikipedia | Masked language modeling, Masked visual feature classification | VQA, VCR, Phrase generation | |
| UNITER | 2019 | COCO Captions Visual Genome Conceptual Captions SBU Captions | Masked language modeling, Masked region modeling, Image–text matching | VQA, VCR, NLVR2, Visual entailment, ITR, Referring expression comprehension | |
| UniVLP | 2019 | COCO Captions Flickr30k Captions VQA 2.0 | Seq2seq inference, Masked vision–language prediction | VQA, Image caption generation | |
| Unicoder -VL | 2020 | Conceptual Captions | Image text alignment, Masked language modeling, Masked visual feature classification | ITR | |
| ImageBERT | 2020 | LAIT Conceptual Captions SBU Captions | Masked language modeling, Masked objects classification, Masking region feature regression Image–text matching | ITR |
| Model | Proposed Year | Visual Features | Pretraining Datasets | Pretraining Tasks | Downstream Tasks | Adversarial |
|---|---|---|---|---|---|---|
| Oscar | 2020 | Region Feature | COCO Captions Conceptual Captions SBU Captions Flickr30k Captions GQA | Masked token loss, Cross-entropy loss | ITR, Image captioning, VQA, NLVR2, GQA | N |
| VinVL | 2021 | Region Feature | COCO Captions Conceptual Captions SBU Captions Flickr30k Captions GQA VQA VG-QAs OpenImages | Masked token loss, Cross-entropy loss | VQA, VCR, Image captioning, ITR, NLVR2 | N |
| VILLA | 2020 | Region Feature | COCO Visual Genome Conceptual Captions SBU Captions | Masked language modeling, Masked region modeling, Image–text matching | VQA, VCR, ITR, NLVR2 | Y |
| UNIMO | 2020 | Region Feature | BookWiki OpenWebText OpenImages COCO Visual Genome Conceptual Captions SBU Captions | Random region sampling, Masked feature modeling | VQA, Image captioning, ITR, Visual entailment | N |
| OPT | 2021 | Region Feature | OpenImages Visual Genome Conceptual Captions | Masked language modeling, Masked visual modeling, Masked audio modeling, Modality layer masked modeling, Noisy text reconstruction, Noise image reconstruction | Cross-modality classification, Cross-modality retrieval, Audio recognition, Text generation, Traditional visual–text task | Y |
| DALL·E | 2021 | Region Feature | COCO Conceptual Captions | - | Image Generation | Y |
| CogView | 2021 | Region Feature | COCO Wudao Corpora Conceptual Captions | - | Style learning, Image captioning, Self-reordering, Industrial fashion design | Y |
| Pixel-BERT | 2020 | Grid Feature | MS-COCO Visual Genome | Masked language modeling, Image–text matching, Pixel random sampling | VQA, NLVR2, ITR | N |
| Fashion BERT | 2020 | Patch Feature | Fashion-Gen | Image–text matching, Cross-modality retrieval | Image–text matching, Cross-modality retrieval | N |
| ViLT | 2021 | Patch Feature | MSCOCO Visual Genome SBU Captions Conceptual Captions | Image–text matching, Masked language modeling | ITR, VQA, NLVR2 | N |
| SimVLM | 2022 | Patch Feature | Align | Prefix Language Modeling | ITR, VQA, NLVR2, Image captioning, | N |
| Model | VQA (Dev) | GQA (Dev) | NLVR2 | COCO Captions | MSCOCO | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Test-p | Dev | BLUE4 | CIDEr | IR | TR | |||||||
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |||||||
| OSCAR | 73.61 | 61.58 | 80.05 | 79.12 | - | - | 57.5 | 82.8 | 89.8 | 73.5 | 92.2 | 96.0 |
| VinVL | 76.52 | 65.05 | 83.98 | 82.67 | - | - | 58.8 | 83.5 | 90.3 | 75.4 | 92.9 | 96.2 |
| Pixel-BERT | 74.45 | - | 77.2 | 76.5 | - | - | - | - | - | - | - | - |
| ViLT | 71.26 | - | 76.13 | 75.70 | - | - | 42.7 | 72.9 | 83.1 | 61.5 | 86.3 | 92.7 |
| VILLA | 74.69 | - | 81.47 | 79.76 | - | - | - | - | - | - | - | - |
| OPT | 72.38 | - | - | - | 40.2 | 133.8 | - | - | - | - | - | - |
| UNIMO | 75.06 | - | - | - | 39.6 | 127.7 | - | - | - | - | - | - |
| SimVLM | 80.03 | - | 85.15 | 84.53 | 40.6 | 143.3 | - | - | - | - | - | - |
| Pretraining Datasets | Pretraining Tasks | Downstream Tasks | |
|---|---|---|---|
| VilBERT | Conceptual Captions | Image sentence alignment, Masked language modeling, Masked visual feature classification | VQA, VCR, Phrase Generation, Image Retrieval |
| LXMERT | COCO VQA GQA VG-QA VG Captions | Image sentence alignment, Masked language modeling, Masked visual feature classification, VQA | VQA, NLVR2 |
| VQA | VCR | RefCOCO+ | GQA | NLVR2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Q-A | QA-R | Q-AR | Val | TestA | TestB | Binary | Open | Accu | Cons | ACCU | ||
| ViLBERT | 70.55 | 72.42 | 74.47 | 54.05 | 72.34 | 78.52 | 62.61 | - | - | - | - | - |
| LXMERT | 72.5 | - | - | - | - | - | - | 77.8 | 45.0 | 60.3 | 42.1 | 76.2 |
| Model | Proposed Year | Visual Features | Pretraining Datasets | Pretraining Tasks | Downstream Tasks | Innovation | Adversarial |
|---|---|---|---|---|---|---|---|
| 12-in-1 | 2019 | Region Feature | VQA v2.0, GQA, Visual Genome, COCO, Flickr30K, RefCOCO, Visual 7W, GuessWhat, NLVR2, SNLI-VE, | Visual Question Answering, Image Retrieval, Reference expression, Multimodal verification | Visual Question Answering, NLVR2 | Multitasking Training | N |
| ERNIE-ViL | 2020 | Region Feature | Conceptual Captions, SBU Captions, | Scene Graph Prediction | Visual Commonsense Reasoning, Visual Question Answering, Image–Text Retrieval | Import Scene Graph | N |
| BriVL | 2021 | Region Feature | RUC-CAS-WenLan | Image–Text Retrieval | Image–Text Retrieval | Joint Training Image and Text Encoder | Y |
| MVPTR | 2022 | Region Feature | MSCOCO, Flirck30k, GQA, Conceptual Captions, SBU Captions, OpenImages, Flickr30K | Masked Concept Recovering, Masked Language Model, Image–Text Matching | Image–Text Retrieval, Multimodal Classification, Visual Grounding | Enable Multilevel Alignments | N |
| InterBERT | 2020 | Patch Feature | M6-Corpus | Masked Group Modeling, Image–Text Matching | Image Retrieval, Visual Commonsense Reasoning | Y | |
| M6 | 2021 | Patch Feature | Masked Language Modeling, Image Captioning, Multimodal verification | Image–text Generation, Visual Question Answering, Image captioning Poetry Generation, Image–Text Matching | |||
| METER | 2022 | Patch Feature | SBU Captions, Visual Genome, COCO, Conceptual Captions, | Masked Language Modeling, Image–Text Matching | Visual Question Answering, Image Retrieval, NLVR2, Visual Entailment | Dissect the Model Designs along Multiple Dimensions | N |
| Datasets | Clips | Dialogues | Videos | Duration (h) | Tasks | Text Type |
|---|---|---|---|---|---|---|
| HowTo100M [54] | 136.6 M | 136 M | 1.221 M | 134,472 | MLM | Caption |
| How2 | 185 K | 185 K | 13,168 | 298 | VQA | Caption |
| TVQA [55] | 21 K | 152.5 K | - | 460 | Q&A | |
| MSR-VTT [56] | 10 K | 200 K | 7180 | 40 | Video Retrieval | Caption |
| YouCook2 [57] | 14 K | 14 K | 2000 | 176 | Caption | |
| TVC [58] | 108 K | 262 K | - | - | Video Captioning | Q&A |
| COIN [59] | 12 K | - | - | 476 | Action segmentation | Describe |
| CrossTask [60] | 4.7 K | - | - | 376 | Action Location | Describe |
| VIOLIN [61] | 1.5 K | 95 K | 582 | Video language reasoning | Describe |
| Model | Proposed Year | Model Architecture | Pretraining Datasets | Pretraining Tasks | Downstreams Tasks | Innovation |
|---|---|---|---|---|---|---|
| VideoBERT | 2019 | Single Stream | YouCook II | Masked Language Modeling, Text–Visual Sequence Matching | Video Captioning, Image–Text Prediction | First visual–text pretraining work |
| ActBERT | 2020 | Single Stream | HowTo100M | Masked Language Modeling, Masked Action Modeling, Masked Target Modeling, Cross-Modality Matching | Action Positioning, Action Segmentation, Video–Text Retrieval, Video Captioning, Visual Question Answering | Tangled Transformer |
| HERO | 2020 | Single Stream | TV Dataset HowTo100M How2QA How2R | Masked Language Modeling, Masked Frame Modeling, Video–Subtitle Matching, Frame Sequence Modeling | Video Captioning, Video Retrieval Visual Question Answering | Design multilayer model architecture |
| UniVL | 2020 | Dual Stream | Howto100M YouCookII MSR-VTT COIN CrossTask CMU-MOSI | Video–Text Joint, Masked Language Modeling, Masked Frame Modeling, Video–Text Alignment, Language Reconstruction | Text–Video Retrieval, Multimodal Video Captioning, Action Segmentation, Action Positioning, Multimodal Emotion Analysis | Unified understanding and generation task |
| VX2TEXT | 2021 | Dual Stream | TVQA AVSD TVC | Visual Question Answering, Video Captioning | Visual Question Answering, Video Captioning, Audio Visual Scene Perception Dialogue | Text coding is directly used to realize the fusion of multiple modalities |
| VIOLET | 2022 | Dual Stream | YT-Temporal WebVid Conceptual Captions | Masked Language Modeling, Mask Visual Marker Modeling | Text–Video Retrieval, Video Question Qnswering | Designed a new pretraining task |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Huang, R.; Zhang, J. Research Progress on Vision–Language Multimodal Pretraining Model Technology. Electronics 2022, 11, 3556. https://doi.org/10.3390/electronics11213556
Wang H, Huang R, Zhang J. Research Progress on Vision–Language Multimodal Pretraining Model Technology. Electronics. 2022; 11(21):3556. https://doi.org/10.3390/electronics11213556
Chicago/Turabian StyleWang, Huansha, Ruiyang Huang, and Jianpeng Zhang. 2022. "Research Progress on Vision–Language Multimodal Pretraining Model Technology" Electronics 11, no. 21: 3556. https://doi.org/10.3390/electronics11213556
APA StyleWang, H., Huang, R., & Zhang, J. (2022). Research Progress on Vision–Language Multimodal Pretraining Model Technology. Electronics, 11(21), 3556. https://doi.org/10.3390/electronics11213556