
Fog Computing: Strategies for Optimal Performance and Cost Effectiveness



Abstract
:1. Introduction
2. Literature Review
2.1. Fog Computing Architecture
2.2. Resource Management
2.3. Redundancy
3. Validation of the Proposed Model
3.1. System Overview
- Cloud layer: this layer is the highest layer and is where the data centers reside. Computing resources for this layer are very powerful in terms of CPU, storage, and connectivity.
- Management layer: this layer consists of fog nodes, called fog managers, responsible of governing communication between the lower layers and clouds. Devices in this layer have computing resources that are less powerful than clouds and similar to the next lower layer.
- Fog nodes layer: devices in this layer can be router, switches, or access points. This layer is the first hub for end users’ requests, and it connects end user devices to upper layers if necessary, which is explained in the next section. In this layer, each fog node has a parent in the management layer.
- End user layer: this layer is the lowest layer in the hierarchy and is the data origin layer. Devices is this layer can be sensors, actuators, mobiles, and IoT devices. Computing capabilities can be very limited in these devices, and they can be in motion. The end users layer has n devices, U = {u1, u2,..., un}. Each user ui ∈ U requests a task T.
3.2. Management Layer
3.3. Implementation Details
- The motion detector is deployed on smart cameras at the lowest layer of the hierarchy. These smart cameras sense motion in their surrounding environment and send video streams of the detected motion to the next module.
- The object detector is placed on the second lowest layer of the hierarchy in fog nodes. This module detects an object from the received video stream and sends a picture of the detected object to the next module, which is the object tracker.
- The object tracker module is placed in the management layer. It calculates the PTZ parameters that are required to track the detected object and sends these parameters to the actuators back in the smart cameras.
- The user interface module is placed on the cloud. It is used only to display the detected object.
4. Results and Analysis
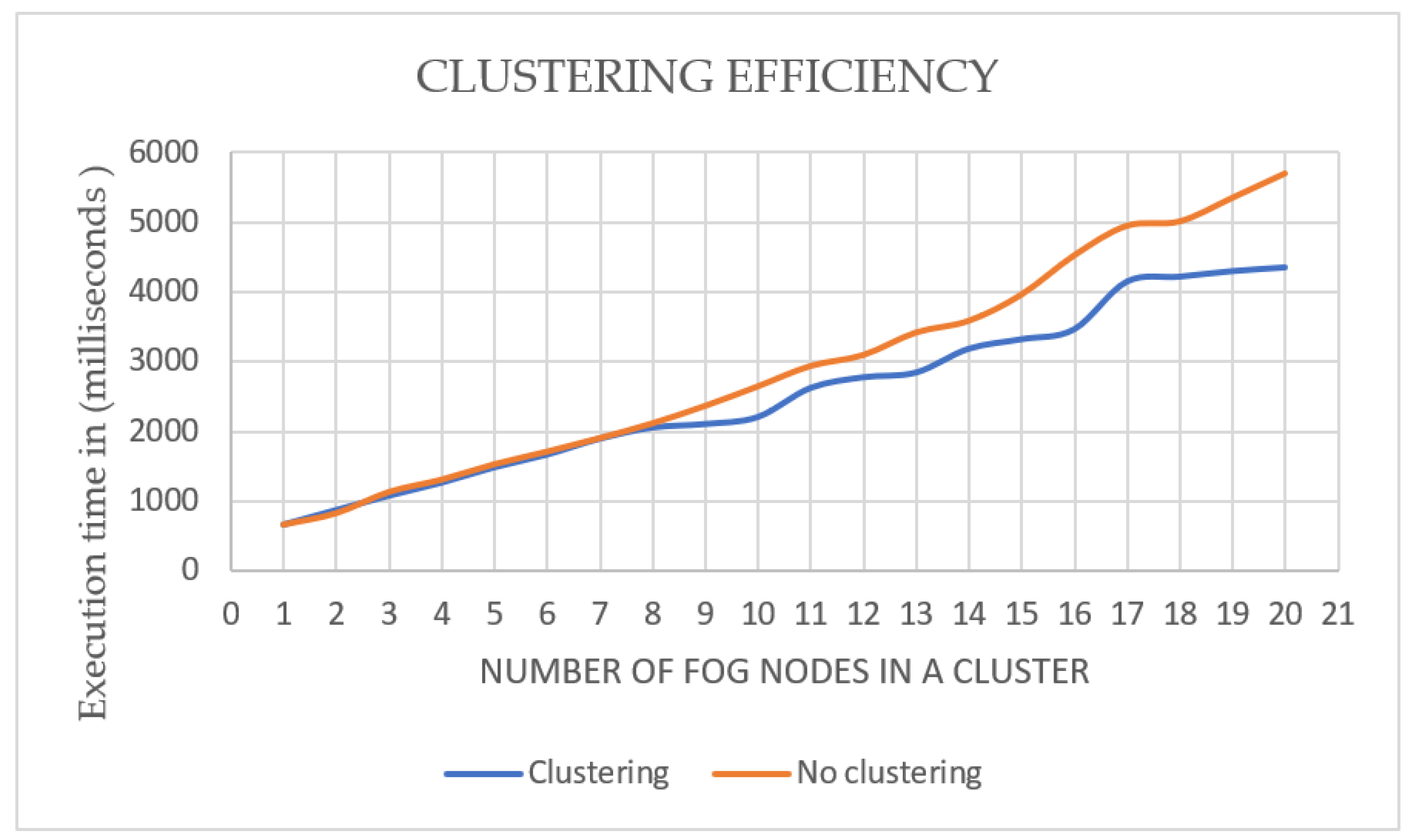
4.1. Execution Time
4.2. Bandwidth Consumption
4.3. Packet Delay
4.4. Cost Effectiveness of the Proposed Model
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bonomi, F.; Milito, R.; Zhu, J.; Addepalli, S. Fog computing and its role in the internet of things. In The First Edition of the MCC Workshop on Mobile Cloud Computing; Association for Computing Machinery: New York, NY, USA, 2012; pp. 13–16. [Google Scholar]
- OpenFog Architecture Workgroup. OpenFog Reference Architecture for Fog Computing. February 2017. Available online: https://site.ieee.org/denver-com/files/2017/06/OpenFog_Reference_Architecture_2_09_17-FINAL-1.pdf (accessed on 8 June 2022).
- Tang, B.; Chen, Z.; Hefferman, G.; Wei, T.; He, H.; Yang, Q. A hierarchical distributed fog computing architecture for big data analysis in smart cities. In Proceedings of the ASE BigData & SocialInformatics; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1–6. [Google Scholar]
- Chiang, M.; Ha, S.; Risso, F.; Zhang, T.; Chih-Lin, I. Clarifying Fog Computing and Networking: 10 Questions and Answers. IEEE Commun. Mag. 2017, 55, 18–20. [Google Scholar] [CrossRef] [Green Version]
- Aazam, M.; Huh, E.-N. Fog Computing Micro Datacenter Based Dynamic Resource Estimation and Pricing Model for IoT. In Proceedings of the 2015 IEEE 29th International Conference on Advanced Information Networking and Applications, Gwangju, Korea, 24–27 March 2015. [Google Scholar]
- Zhang, T.; Jin, J.; Zheng, X.; Yang, Y. Rate adaptive fog service platform for heterogeneous iot applications. IEEE Internet Things J. 2020, 7, 176–188. [Google Scholar] [CrossRef]
- Zamani, A.R.; Zou, M.; Diaz-Montes, J.; Petri, I.; Rana, O.; Parashar, M. A computational model to support in-network data analysis in federated ecosystems. Future Gener. Comput. Syst. 2018, 80, 342–354. [Google Scholar] [CrossRef]
- Karagiannis, V.; Schulte, S. Comparison of Alternative Architectures in Fog Computing. In Proceedings of the 2020 IEEE 4th International Conference on Fog and Edge Computing (ICFEC), Melbourne, VIC, Australia, 11–14 May 2020. [Google Scholar]
- Gu, K.; Tang, L.; Jiang, J.; Jia, W. Resource Allocation Scheme for Community-Based Fog Computing Based on Reputation Mechanism. IEEE Trans. Comput. Soc. Syst. 2020, 7, 1246–1263. [Google Scholar] [CrossRef]
- Aldossary, M.; Alharbi, H.A. Towards a Green Approach for Minimizing Carbon Emissions in Fog-Cloud Architecture. IEEE Access 2021, 9, 131720–131732. [Google Scholar] [CrossRef]
- Kadhim, A.J.; Naser, J.I. Proactive load balancing mechanism for fog computing supported by parked vehicles in IoV-SDN. China Commun. 2021, 18, 271–289. [Google Scholar] [CrossRef]
- Lera, I.; Guerrero, C.; Juiz, C. Availability-Aware Service Placement Policy in Fog Computing Based on Graph Partitions. IEEE Internet Things J. 2018, 6, 3641–3651. [Google Scholar] [CrossRef]
- Godinho, N.; Silva, H.; Curado, M.; Paquete, L. A reconfigurable resource management framework for fog environments. Future Gener. Comput. Syst. 2022, 133, 124–140. [Google Scholar] [CrossRef]
- Benchikh, L.; Louail, L. Task scheduling approaches for fog computing. In Proceedings of the 2021 30th Wireless and Optical Communications Conference (WOCC), Taipei, Taiwan, 7–8 October 2021. [Google Scholar]
- Mohamed, N.; Al-Jaroodi, J.; Jawhar, I. Towards Fault Tolerant Fog Computing for IoT-Based Smart City Applications. In Proceedings of the 2019 IEEE 9th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 7–9 January 2019. [Google Scholar]
- Xu, F.; Yin, Z.; Gu, A.; Zhang, F.; Li, Y. A Service Redundancy Strategy and Ant Colony Optimization Algorithm for Multi- service Fog Nodes. In Proceedings of the IEEE 6th International Conference on Computer and Communications, Chengdu, China, 11–14 December 2020. [Google Scholar]
- Ghanavati, S.; Abawajy, J.; Izadi, D. Automata-Based Dynamic Fault Tolerant Task Scheduling Approach in Fog Computing. IEEE Trans. Emerg. Top. Comput. 2022, 10, 488–499. [Google Scholar] [CrossRef]
- Gupta, H.; Vahid Dastjerdi, A.; Ghosh, S.K.; Buyya, R. IFogSim: A Toolkit for Modeling and Simulation of Resource Management Techniques in the Internet of Things, Edge and Fog Computing Environments. Software: Practice and Experience 2017, 47, 1275–1296. [Google Scholar] [CrossRef]
- Hoque, M.A.; Siekkinen, M.; Nurminen, J.K. Energy Efficient Multimedia Streaming to Mobile Devices—A Survey. IEEE Commun. Surv. Tutor. 2014, 16, 579–597. [Google Scholar] [CrossRef]
- Zhou, S.; Sun, Y.; Jiang, Z.; Niu, Z. Exploiting Moving Intelligence: Delay-Optimized Computation Offloading in Vehicular Fog Networks. IEEE Commun. Mag. 2019, 57, 49–55. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Structure | Figure | Number of Layers | Clustering | Management Layer |
|---|---|---|---|---|
| A | 5 | 4 | Single | Yes |
| B | 6 | 3 | Single | Non |
| C | 7 | 3 | Multi | Yes |
| D | 8 | 2 | Multi | Non |
| E | 9 | 3 | Non | Yes |
| F | 10 | 2 | Non | Non |
| Structure | Figure | Execution Time | Bandwidth Consumption | Packet Delay |
|---|---|---|---|---|
| A | 5 | 1553 | 12,560.92 | 3.54940738 |
| B | 6 | 2027.3 | 12,675.3 | 0.5 |
| C | 7 | 1600.6 | 12,814.36 | 3.54962706 |
| D | 8 | 2013.1 | 1267.692 | 0.5 |
| E | 9 | 1626.1 | 12,779.34 | 3.549627055 |
| F | 10 | 1969.8 | 12,655.93 | 0.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alraddady, S.; Soh, B.; AlZain, M.A.; Li, A.S. Fog Computing: Strategies for Optimal Performance and Cost Effectiveness. Electronics 2022, 11, 3597. https://doi.org/10.3390/electronics11213597
Alraddady S, Soh B, AlZain MA, Li AS. Fog Computing: Strategies for Optimal Performance and Cost Effectiveness. Electronics. 2022; 11(21):3597. https://doi.org/10.3390/electronics11213597
Chicago/Turabian StyleAlraddady, Sara, Ben Soh, Mohammed A. AlZain, and Alice S. Li. 2022. "Fog Computing: Strategies for Optimal Performance and Cost Effectiveness" Electronics 11, no. 21: 3597. https://doi.org/10.3390/electronics11213597
APA StyleAlraddady, S., Soh, B., AlZain, M. A., & Li, A. S. (2022). Fog Computing: Strategies for Optimal Performance and Cost Effectiveness. Electronics, 11(21), 3597. https://doi.org/10.3390/electronics11213597