
Equivalent Keys: Side-Channel Countermeasure for Post-Quantum Multivariate Quadratic Signatures

Abstract
:1. Introduction
Our Contribution
2. Rainbow
- We restricted the polynomials, omitting the linear and absolute parts of the polynomials in the central map, resulting in quadratic forms. These coefficients are not necessary for Rainbow’s security, but add more complexity. The reference implementation submitted to the standardization process considers these coefficients in the documentation, but they were not implemented in the code. Nevertheless, the countermeasure discussed in this paper can be applied to the original polynomials defined in Equation (1) as well.
- We united the and coefficients into the coefficients for simplicity of notation and also included zero coefficients as described in Equation (2). We did not allow setting any (by definition) zero coefficient to a non-zero value, so there is no change from the original definition.
2.1. Central Map in Matrix Representation
2.2. Signing and Verification Process
3. Equivalent Key
3.1. Composition
3.2. Composition
3.3. Analysis of an Equivalent Key
- Ia (128 bit security): ;
- Vc (256 bit security): and .
4. Efficient Implementation
- Calculation performance;
- Amount of fresh randomness necessary;
- Entropy of the generated equivalent key;
- Implementation size and simplicity;
- Total number of keys equivalent to each public key.
4.1. Justification of the Selected Generators
4.2. Efficient Computation of Equivalent Keys
4.2.1. Algorithm for Upper Triangular Matrices’ Evaluation
| Algorithm 1 Computation of . |
input: matrix as vector upper triangular matrix integers , where output: element
|
5. Performance Evaluation
5.1. Side-Channel Leakage Evaluation
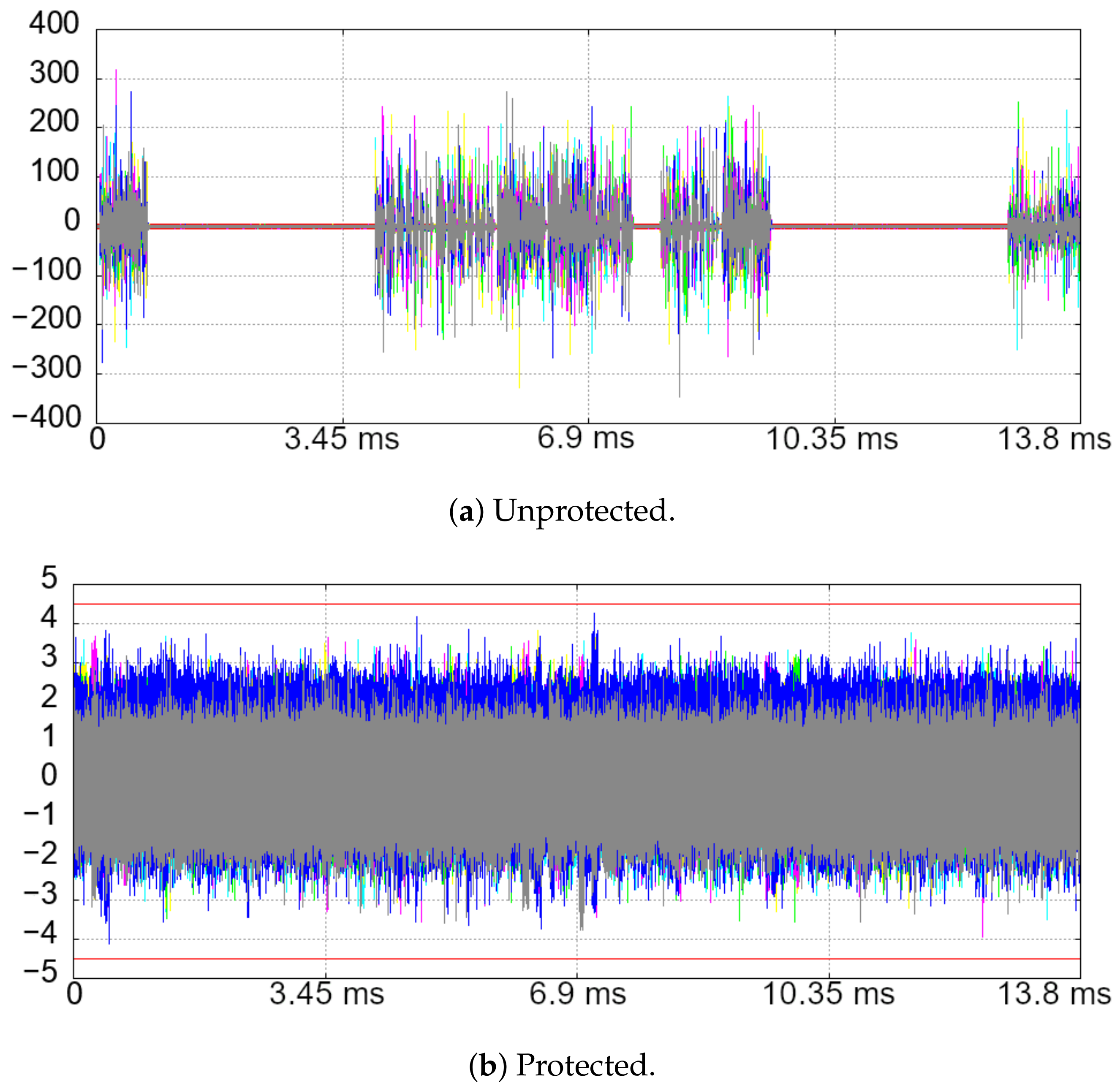
5.1.1. Methodology
5.1.2. Results
5.2. Time Evaluation
- The STM32F303 ARM microcontroller (a single-core Cortex-M4);
- A Raspberry Pi 3 B+ single-board computer equipped with the Broadcom BCM2837 ARM microprocessor (a four-core Cortex-A53);
- A desktop computer equipped with an Intel Core i5-2400 processor (four cores).
5.3. Memory Evaluation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Meneghello, F.; Calore, M.; Zucchetto, D.; Polese, M.; Zanella, A. IoT: Internet of threats? A survey of practical security vulnerabilities in real IoT devices. IEEE Internet Things J. 2019, 6, 8182–8201. [Google Scholar] [CrossRef]
- Daemen, J.; Rijmen, V. The Design of Rijndael; Springer: Berlin/Heidelberg, Germany, 2002; Volume 2. [Google Scholar]
- Rivest, R.L.; Shamir, A.; Adleman, L. A method for obtaining digital signatures and public-key cryptosystems. Commun. ACM 1978, 21, 120–126. [Google Scholar] [CrossRef] [Green Version]
- Koblitz, N. Elliptic curve cryptosystems. Math. Comput. 1987, 48, 203–209. [Google Scholar] [CrossRef]
- Shor, P.W. Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer. SIAM Rev. 1999, 41, 303–332. [Google Scholar] [CrossRef]
- Ducas, L.; Kiltz, E.; Lepoint, T.; Lyubashevsky, V.; Schwabe, P.; Seiler, G.; Stehlé, D. CRYSTALS-Dilithium: Algorithm Specifications and Supporting Documentation. Available online: https://pq-crystals.org/ (accessed on 27 September 2022).
- Fouque, P.A.; Hoffstein, J.; Kirchner, P.; Lyubashevsky, V.; Pornin, T.; Prest, T.; Ricosset, T.; Seiler, G.; Whyte, W.; Zhang, Z. Falcon: Fast-Fourier Lattice-Based Compact Signatures over NTRU. NIST PQC Project Round 2, Documentation. Available online: https://falcon-sign.info/ (accessed on 27 September 2022).
- Ding, J.; Schmidt, D. Rainbow, a new multivariable polynomial signature scheme. In Proceedings of the International Conference on Applied Cryptography and Network Security, New York, NY, USA, 7–10 June 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 164–175. [Google Scholar]
- Kipnis, A.; Patarin, J.; Goubin, L. Unbalanced oil and vinegar signature schemes. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Prague, Czech Republic, 2–6 May 1999; Springer: Berlin/Heidelberg, Germany, 1999; pp. 206–222. [Google Scholar]
- Beullens, W.; Preneel, B. Field lifting for smaller UOV public keys. In Proceedings of the International Conference on Cryptology in India, Chennai, India, 10–13 December 2017; Springer: Cham, Switzerland, 2017; pp. 227–246. [Google Scholar]
- Kocher, P.; Jaffe, J.; Jun, B. Differential Power Analysis. In Advances in Cryptology — CRYPTO’ 99; Springer: Berlin/Heidelberg, Germany, 1999; pp. 388–397. [Google Scholar] [CrossRef] [Green Version]
- Boer, B.d.; Lemke, K.; Wicke, G. A DPA attack against the modular reduction within a CRT implementation of RSA. In Proceedings of the International Workshop on Cryptographic Hardware and Embedded Systems, Redwood Shores, CA, USA, 13–15 August 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 228–243. [Google Scholar]
- Brier, E.; Clavier, C.; Olivier, F. Correlation Power Analysis with a Leakage Model. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2004; pp. 16–29. [Google Scholar] [CrossRef] [Green Version]
- Quisquater, J.J.; Samyde, D. Electromagnetic analysis (ema): Measures and counter-measures for smart cards. In Proceedings of the International Conference on Research in Smart Cards, Cannes, France, 19–21 September 2001; Springer: Berlin/Heidelberg, Germany, 2001; pp. 200–210. [Google Scholar]
- Chari, S.; Rao, J.R.; Rohatgi, P. Template attacks. In Proceedings of the International Workshop on Cryptographic Hardware and Embedded Systems, Redwood Shores, CA, USA, 13–15 August 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 13–28. [Google Scholar]
- Rechberger, C.; Oswald, E. Practical template attacks. In Proceedings of the International Workshop on Information Security Applications, Jeju Island, Korea, 23–25 August 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 440–456. [Google Scholar]
- Lerman, L.; Poussier, R.; Markowitch, O.; Standaert, F.X. Template attacks versus machine learning revisited and the curse of dimensionality in side-channel analysis: Extended version. J. Cryptogr. Eng. 2018, 8, 301–313. [Google Scholar] [CrossRef]
- Hettwer, B.; Gehrer, S.; Güneysu, T. Applications of machine learning techniques in side-channel attacks: A survey. J. Cryptogr. Eng. 2020, 10, 135–162. [Google Scholar] [CrossRef]
- Timon, B. Non-profiled deep learning-based side-channel attacks with sensitivity analysis. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2019, 2019, 107–131. [Google Scholar] [CrossRef]
- Park, A.; Shim, K.A.; Koo, N.; Han, D.G. Side-Channel Attacks on Post-Quantum Signature Schemes based on Multivariate Quadratic Equations. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2018, 2018, 500–523. [Google Scholar] [CrossRef]
- Pokorný, D.; Socha, P.; Novotný, M. Side-channel attack on Rainbow post-quantum signature. In Proceedings of the 2021 Design, Automation Test in Europe Conference Exhibition (DATE), Grenoble, France, 1–5 February 2021; pp. 565–568. [Google Scholar] [CrossRef]
- Tiri, K.; Verbauwhede, I. A logic level design methodology for a secure DPA resistant ASIC or FPGA implementation. In Proceedings of the Proceedings Design, Automation and Test in Europe Conference and Exhibition, Paris, France, 16–20 February 2004; Volume 1, pp. 246–251. [Google Scholar]
- Popp, T.; Mangard, S. Masked dual-rail pre-charge logic: DPA-resistance without routing constraints. In Proceedings of the International Workshop on Cryptographic Hardware and Embedded Systems, Edinburgh, UK, 29 August–1 September 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 172–186. [Google Scholar]
- Lu, Y.; O’Neill, M.; McCanny, J. Evaluation of random delay insertion against DPA on FPGAs. ACM Trans. Reconfigurable Technol. Syst. (TRETS) 2010, 4, 1–20. [Google Scholar] [CrossRef]
- Baddam, K.; Zwolinski, M. Evaluation of dynamic voltage and frequency scaling as a differential power analysis countermeasure. In Proceedings of the 20th International Conference on VLSI Design held jointly with 6th International Conference on Embedded Systems (VLSID’07), Bangalore, India, 6–10 January 2007; pp. 854–862. [Google Scholar]
- Nikova, S.; Rechberger, C.; Rijmen, V. Threshold implementations against side-channel attacks and glitches. In Proceedings of the International Conference on Information and Communications Security, Raleigh, NC, USA, 4–7 December 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 529–545. [Google Scholar]
- Bilgin, B.; Gierlichs, B.; Nikova, S.; Nikov, V.; Rijmen, V. Higher-order threshold implementations. In Proceedings of the International Conference on the Theory and Application of Cryptology and Information Security, Kaoshiung, Taiwan, 7–11 December 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 326–343. [Google Scholar]
- Gross, H.; Mangard, S.; Korak, T. Domain-Oriented Masking: Compact Masked Hardware Implementations with Arbitrary Protection Order. In Proceedings of the 2016 ACM Workshop on Theory of Implementation Security, Vienna, Austria, 24 October 2016; p. 3. [Google Scholar]
- Shim, K.A.; Park, C.M.; Baek, Y.J. Lite-Rainbow: Lightweight Signature Schemes Based on Multivariate Quadratic Equations and Their Secure Implementations. In Proceedings of the Progress in Cryptology–INDOCRYPT 2015; Biryukov, A., Goyal, V., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 45–63. [Google Scholar]
- Beullens, W. Breaking Rainbow Takes a Weekend on a Laptop. Cryptology ePrint Archive, Report 2022/214. 2022. Available online: https://ia.cr/2022/214 (accessed on 27 September 2022).
- Wolf, C.; Preneel, B. Equivalent keys in Multivariate Quadratic public key systems. J. Math. Cryptol. 2011, 4, 375–415. [Google Scholar] [CrossRef]
- PQCRainbow.org. Available online: https://www.pqcrainbow.org/ (accessed on 27 September 2022).
- Andrews, G.E.; Berndt, B. Ramanujan’s Lost Notebook; Springer: New York, NY, USA, 2005. [Google Scholar] [CrossRef]
- Suprunenko, D.; Hirsch, K.; Society, A.M. Matrix Groups; Translations of Mathematical Monographs; American Mathematical Society: Providence, RI, USA, 1976. [Google Scholar]
- Schneider, T.; Moradi, A. Leakage assessment methodology. J. Cryptogr. Eng. 2016, 6, 85–99. [Google Scholar] [CrossRef]
- O’Flynn, C.; Chen, Z. Synchronous sampling and clock recovery of internal oscillators for side-channel analysis and fault injection. J. Cryptogr. Eng. 2015, 5, 53–69. [Google Scholar] [CrossRef]
- Standaert, F.X. How (not) to use welch’s t-test in side-channel security evaluations. In Proceedings of the International Conference on Smart Card Research and Advanced Applications, Montpellier, France, 12–14 November 2018; Springer: Cham, Switzerland, 2018; pp. 65–79. [Google Scholar]


{kind=link}
{kind=link}
| Generator | of Number of Equivalent Keys | |||
|---|---|---|---|---|
| Single Generated Key | Transitively Reachable | |||
| Ia | Vc | Ia | Vc | |
| General | 38,976 | 273,664 | 38,976 | 273,664 |
| Efficient | 656 | 2368 | 21,567 | 160,000 |
| Implementation | Unprotected | Protected | Slowdown |
|---|---|---|---|
| Our countermeasure (STM32F303) | 1 | ||
| Our countermeasure (RPi) | 1 | ||
| Our countermeasure (PC) | 1 | ||
| Countermeasure from [29] | cycles | cycles |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pokorný, D.; Socha, P.; Novotný, M. Equivalent Keys: Side-Channel Countermeasure for Post-Quantum Multivariate Quadratic Signatures. Electronics 2022, 11, 3607. https://doi.org/10.3390/electronics11213607
Pokorný D, Socha P, Novotný M. Equivalent Keys: Side-Channel Countermeasure for Post-Quantum Multivariate Quadratic Signatures. Electronics. 2022; 11(21):3607. https://doi.org/10.3390/electronics11213607
Chicago/Turabian StylePokorný, David, Petr Socha, and Martin Novotný. 2022. "Equivalent Keys: Side-Channel Countermeasure for Post-Quantum Multivariate Quadratic Signatures" Electronics 11, no. 21: 3607. https://doi.org/10.3390/electronics11213607