


Feature-Enhanced Document-Level Relation Extraction in Threat Intelligence with Knowledge Distillation


Abstract
1. Introduction
2. Related Work
2.1. Document-Level Relation Extraction
2.2. Threat Intelligence Information Extraction
2.3. Knowledge Distillation
2.4. Threat Intelligence Knowledge Graph
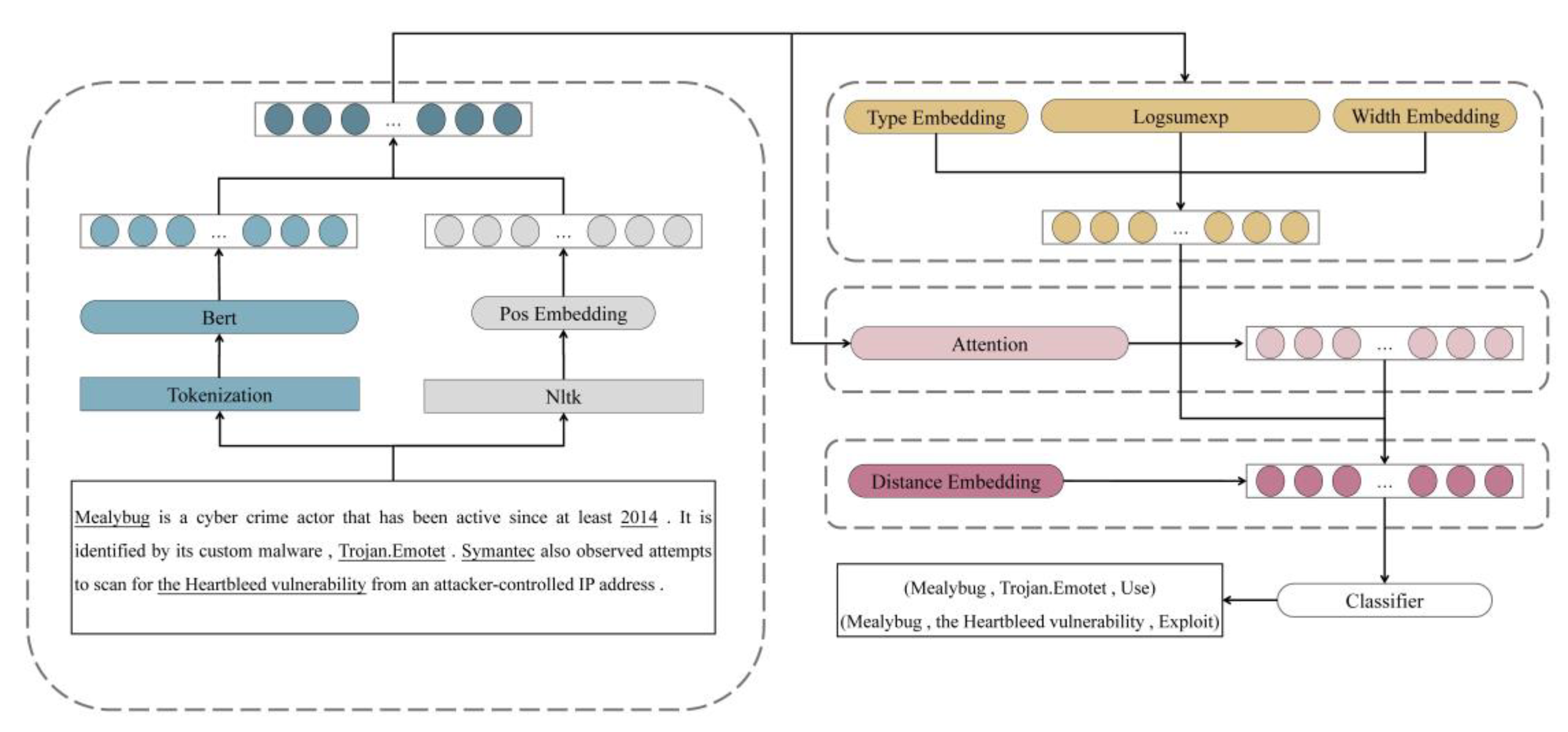
3. Framework Architecture
3.1. Encode Layer
3.2. Representation Layer
3.3. Relation Classification
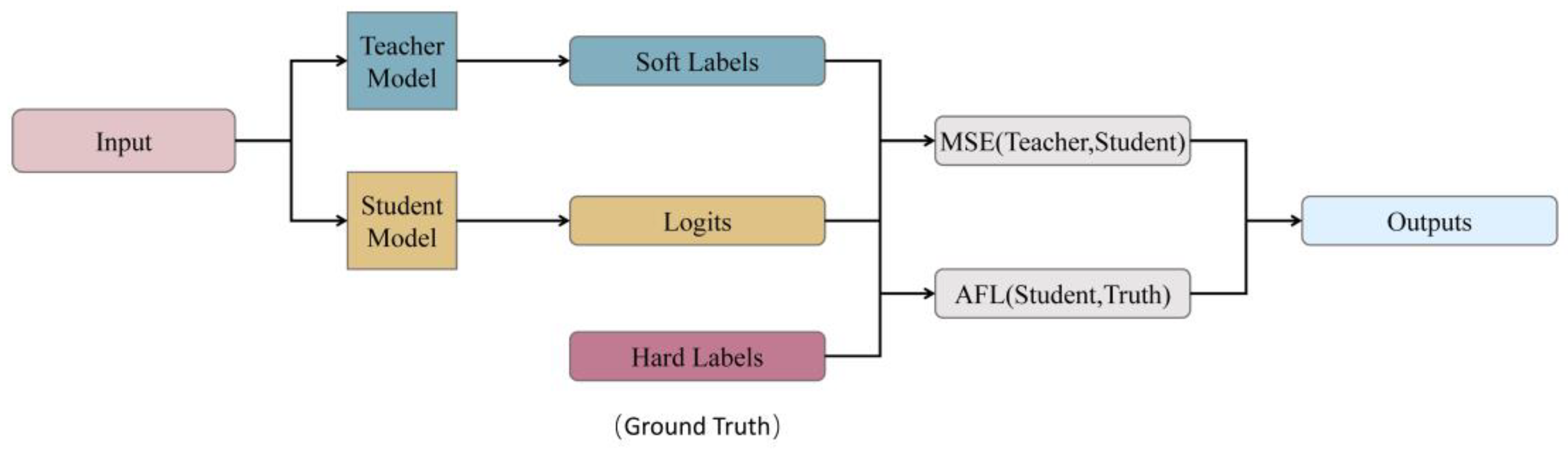
3.4. Knowledge Distillation
4. Experiment
4.1. Dataset
4.2. Experiment Setup
4.3. Result and Analysis
4.3.1. Model Comparison
4.3.2. Ablation Study
4.3.3. Fine-Grained Performance Comparison
4.3.4. Choice of Sampling Technique
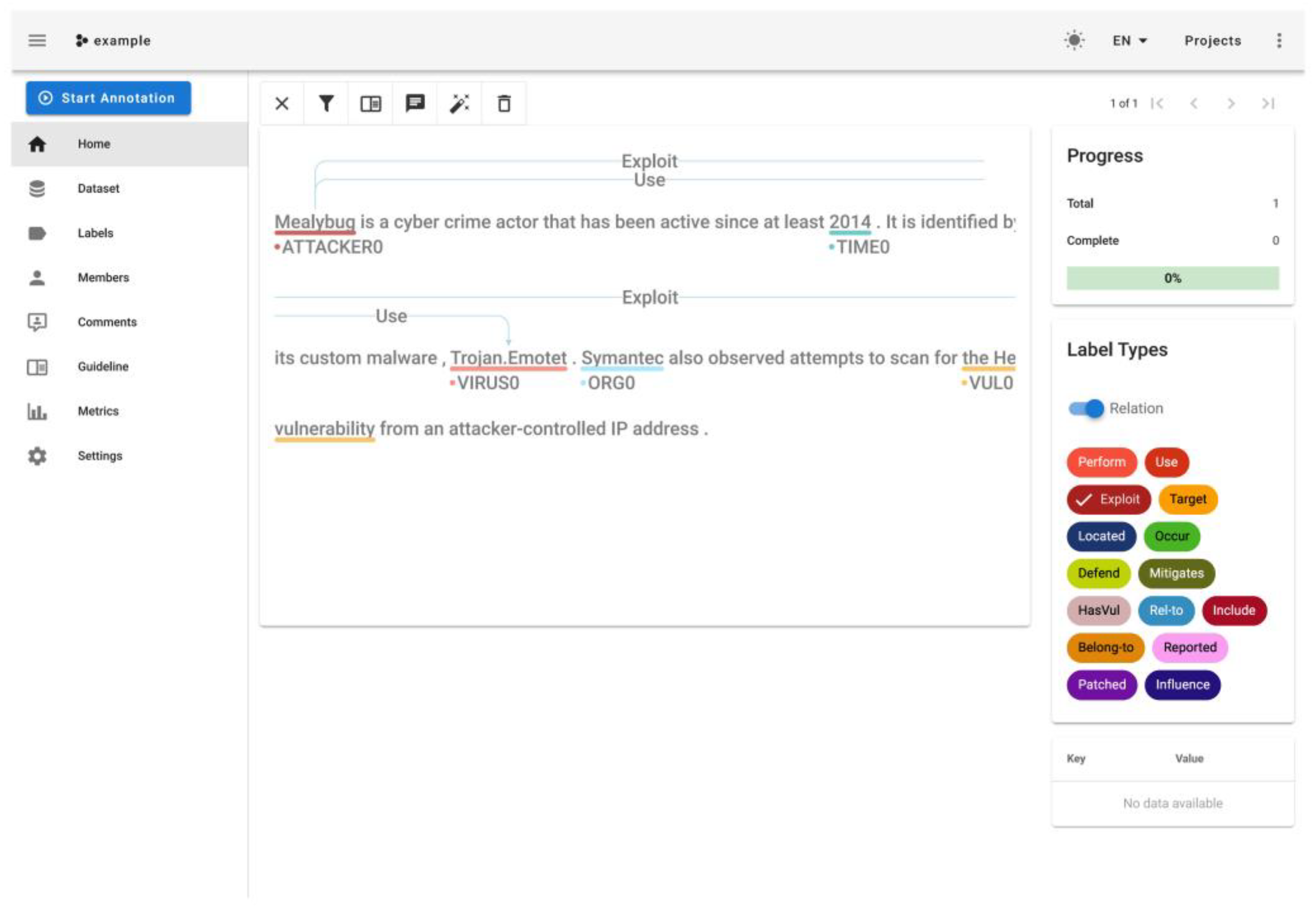
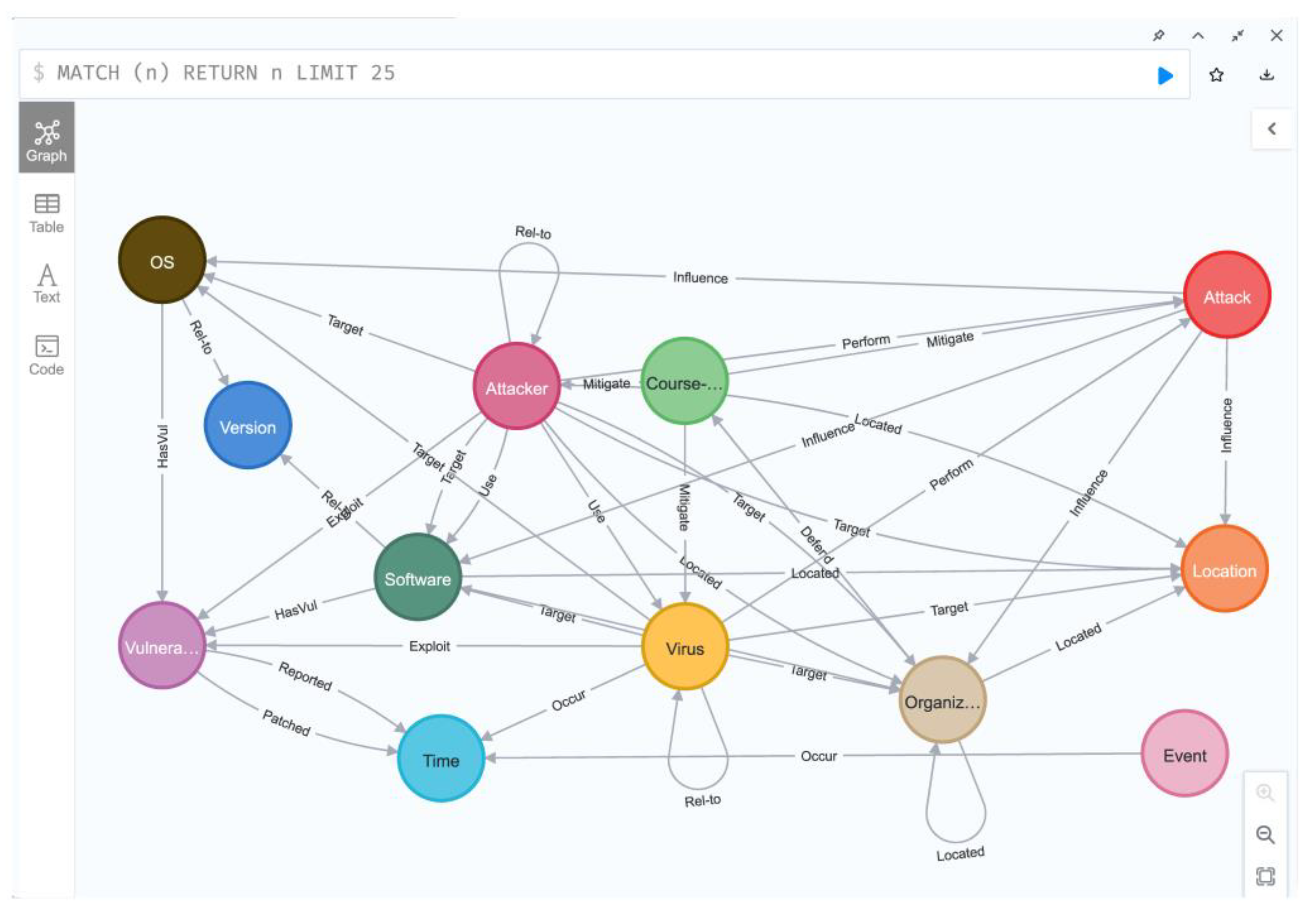
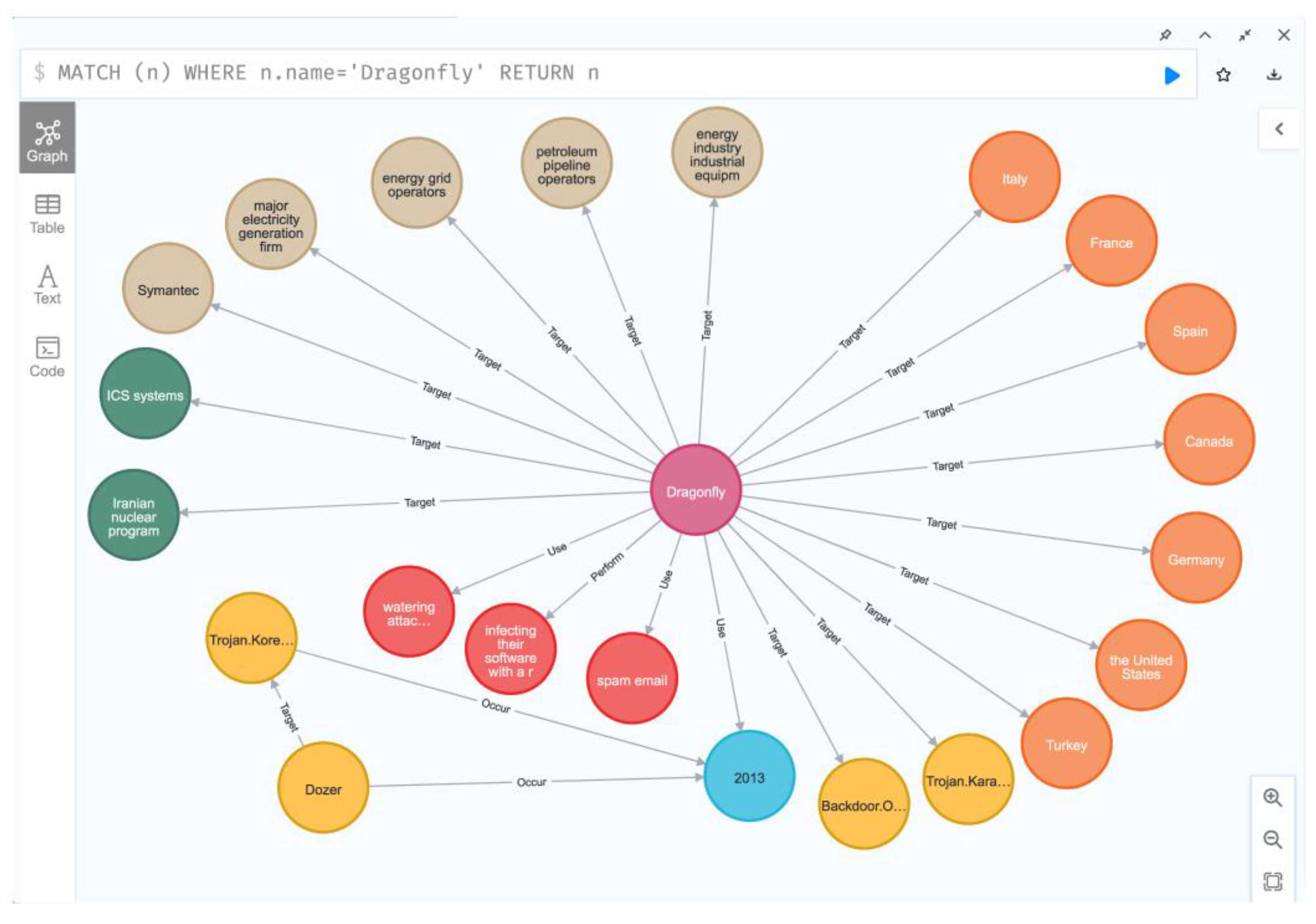
4.4. Threat Intelligence Knowledge Graph Construction
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dohare, I.; Singh, K.; Ahmadian, A.; Mohan, S. Certificateless aggregated signcryption scheme for cloud-fog centric industry 4.0. IEEE Trans. Ind. Inform. 2022, 18, 6349–6357. [Google Scholar] [CrossRef]
- Thirumalai, C.; Mohan, S.; Srivastava, G. An efficient public key secure scheme for cloud and IoT security. Comput. Commun. 2020, 150, 634–643. [Google Scholar] [CrossRef]
- Simonov, N.; Klenkina, O.; Shikhanova, E. Leading Issues in Cybercrime: A Comparison of Russia and Japan. In Proceedings of the 6th International Conference on Social, Economic, and Academic Leadership (ICSEAL-6-2019), Prague, Czech, 13–14 December 2019; pp. 504–510. [Google Scholar]
- Maschmeyer, L.; Dunn Cavelty, M. Goodbye Cyberwar: Ukraine as Reality Check. CSS Policy Perspect. 2022, 10. [Google Scholar] [CrossRef]
- McMillan, R. Definition: Threat Intelligence. March. 2013. Available online: https://www.gartner.com/en/documents/2487216 (accessed on 30 September 2022).
- Liu, C.; Wang, J.; Chen, X. Threat intelligence ATT&CK extraction based on the attention transformer hierarchical recurrent neural network. Appl. Soft Comput. 2022, 122, 108826. [Google Scholar]
- Nguyen, T.H.; Grishman, R. Relation Extraction: Perspective from Convolutional Neural Networks. In Proceedings of the Proceedings of the 1st Workshop on Vector Space Modeling for Natural Language Processing, Denver, CO, USA, 5 June 2015; pp. 39–48. [Google Scholar]
- Zhou, W.; Huang, K.; Ma, T.; Huang, J. Document-Level Relation Extraction with Adaptive Thresholding and Localized Context Pooling. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021; pp. 14612–14620. [Google Scholar]
- Peng, H.; Gao, T.; Han, X.; Lin, Y.; Li, P.; Liu, Z.; Sun, M.; Zhou, J. Learning from Context or Names? An Empirical Study on Neural Relation Extraction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Virtual Event, 16–20 November 2020; pp. 3661–3672. [Google Scholar]
- Soares, L.B.; Fitzgerald, N.; Ling, J.; Kwiatkowski, T. Matching the Blanks: Distributional Similarity for Relation Learning. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2895–2905. [Google Scholar]
- Guo, Z.; Zhang, Y.; Lu, W. Attention Guided Graph Convolutional Networks for Relation Extraction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 241–251. [Google Scholar]
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced Language Representation with Informative Entities. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1441–1451. [Google Scholar]
- Wang, D.; Hu, W.; Cao, E.; Sun, W. Global-to-Local Neural Networks for Document-Level Relation Extraction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Virtual Event, 16–20 November 2020; pp. 3711–3721. [Google Scholar]
- Zhang, L.; Cheng, Y. A Densely Connected Criss-Cross Attention Network for Document-level Relation Extraction. arXiv 2022, arXiv:2203.13953. [Google Scholar]
- Xu, B.; Wang, Q.; Lyu, Y.; Zhu, Y.; Mao, Z. Entity Structure Within and Throughout: Modeling Mention Dependencies for Document-Level Relation Extraction. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021; pp. 14149–14157. [Google Scholar]
- Yuan, C.; Huang, H.; Feng, C.; Shi, G.; Wei, X. Document-level relation extraction with entity-selection attention. Inf. Sci. 2021, 568, 163–174. [Google Scholar] [CrossRef]
- Xie, Y.; Shen, J.; Li, S.; Mao, Y.; Han, J. Eider: Evidence-enhanced Document-level Relation Extraction. arXiv 2021, arXiv:2106.08657. [Google Scholar]
- Long, Z.; Tan, L.; Zhou, S.; He, C.; Liu, X. Collecting indicators of compromise from unstructured text of cybersecurity articles using neural-based sequence labelling. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 4–19 July 2019; pp. 1–8. [Google Scholar]
- Gasmi, H.; Laval, J.; Bouras, A. Information extraction of cybersecurity concepts: An lstm approach. Appl. Sci. 2019, 9, 3945. [Google Scholar] [CrossRef]
- Wang, W.; Ning, K.; Song, H.; Lu, M.; Wang, J. An Indicator of Compromise Extraction Method Based on Deep Learning. J. Comput. 2021, 44, 15. [Google Scholar]
- Satyapanich, T.; Ferraro, F.; Finin, T. Casie: Extracting cybersecurity event information from text. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 8749–8757. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. Fitnets: Hints for thin deep nets. arXiv 2014, arXiv:1412.6550. [Google Scholar]
- Zhang, Z.; Shu, X.; Yu, B.; Liu, T.; Zhao, J.; Li, Q.; Guo, L. Distilling knowledge from well-informed soft labels for neural relation extraction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 9620–9627. [Google Scholar]
- Liu, Q.; Li, Y.; Duan, H.; Liu, Y.; Qin, Z. Knowledge Graph Construction Techniques. J. Comput. Res. Dev. 2016, 53, 582–600. [Google Scholar] [CrossRef]
- Lv, X.; Han, X.; Hou, L.; Li, J.; Liu, Z.; Zhang, W.; Zhang, Y.; Kong, H.; Wu, S. Dynamic Anticipation and Completion for Multi-Hop Reasoning over Sparse Knowledge Graph. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Virtual Event, 16–20 November 2020; pp. 5694–5703. [Google Scholar]
- Zhou, K.; Zhao, W.X.; Bian, S.; Zhou, Y.; Wen, J.-R.; Yu, J. Improving conversational recommender systems via knowledge graph based semantic fusion. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, San Diego, CA, USA, 6–10 July 2020; pp. 1006–1014. [Google Scholar]
- Gao, P.; Liu, X.; Choi, E.; Soman, B.; Mishra, C.; Farris, K.; Song, D. A System for Automated Open-Source Threat Intelligence Gathering and Management. In Proceedings of the 2021 International Conference on Management of Data, Xi’an, China, 20–25 June 2021; pp. 2716–2720. [Google Scholar]
- Piplai, A.; Mittal, S.; Abdelsalam, M.; Gupta, M.; Joshi, A.; Finin, T. Knowledge enrichment by fusing representations for malware threat intelligence and behavior. In Proceedings of the 2020 IEEE International Conference on Intelligence and Security Informatics (ISI), Arlington, VA, USA, 9–10 November 2020; pp. 1–6. [Google Scholar]
- Mittal, S.; Joshi, A.; Finin, T. Cyber-all-intel: An ai for security related threat intelligence. arXiv 2019, arXiv:1905.02895. [Google Scholar]
- Zeng, S.; Xu, R.; Chang, B.; Li, L. Double Graph Based Reasoning for Document-level Relation Extraction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Virtual Event, 16–20 November 2020; pp. 1630–1640. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Entity Type | Definition | Training Set | Test Set |
|---|---|---|---|
| ATTACK | Technique | 298 | 135 |
| ORG | Organization/Vendor | 261 | 136 |
| TIME | Time | 233 | 97 |
| VIRUS | Virus/Script | 210 | 83 |
| LOCATION | Country/Region | 206 | 89 |
| SOFTWARE | Legitimate Software | 125 | 57 |
| ATTACKER | Attacker | 79 | 28 |
| OS | Operation System | 61 | 25 |
| VULNERABILITY | Vulnerability | 50 | 23 |
| VERSION | Version | 40 | 12 |
| Course-of-action | Defense Strategy | 31 | 24 |
| EVENT | Attack Event | 16 | 7 |
| Total | / | 1610 | 716 |
| Relation Type | Definition | Training Set | Test Set |
|---|---|---|---|
| Target | Target of Attack/Attacker | 239 | 116 |
| Perform | Perform Attack | 203 | 69 |
| Rel-to | Associated | 138 | 48 |
| Use | Use Software/Virus | 82 | 28 |
| Occur | Occurred Time | 59 | 22 |
| Influence | Influence by Attack | 59 | 34 |
| HasVul | Contain Vulnerability | 49 | 17 |
| Mitigate | Defend Against an Attacker | 35 | 21 |
| Located | Located in | 33 | 21 |
| Exploit | Exploit Vulnerability | 20 | 8 |
| Reported | Reporting Time | 11 | 4 |
| Patched | Patching Time | 7 | 5 |
| Defend | Carry out Defense Strategy | 7 | 16 |
| Total | / | 942 | 409 |
| Model | P (%) | R (%) | F1 (%) | Overhead (h) |
|---|---|---|---|---|
| SSAN [15] | 50.57 | 46.86 | 48.64 | 2.85 |
| GAIN [31] | 50.77 | 48.58 | 49.65 | 2.80 |
| ATLOP [8] | 51.36 | 36.71 | 42.82 | 2.68 |
| FEDRE | 72.37 | 59.32 | 65.20 | 2.28 |
| FEDRE-KD | 79.60 | 62.00 | 69.71 | 2.00 |
| Model | P (%) | R (%) | F1 (%) | Overhead (h) |
|---|---|---|---|---|
| FEDRE | 72.37 | 59.32 | 65.20 | 2.28 |
| NoPOS | 63.19 | 49.06 | 55.24 | 1.81 |
| NoWidth | 57.74 | 48.50 | 52.72 | 1.81 |
| NoType | 62.63 | 47.01 | 53.71 | 1.96 |
| NoDistance | 60.40 | 48.38 | 53.73 | 1.68 |
| Model | SSAN [15] | GAIN [31] | ATLOP [8] | ||||||
| P (%) | R (%) | F1(%) | P (%) | R (%) | F1(%) | P (%) | R (%) | F1(%) | |
| Target | 62.74 | 60.29 | 61.49 | 59.52 | 56.99 | 58.23 | 61.02 | 59.55 | 60.28 |
| Perform | 48.19 | 53.09 | 50.52 | 42.48 | 59.13 | 49.44 | 46.53 | 41.88 | 44.08 |
| Rel-to | 58.77 | 40.56 | 48.00 | 42.92 | 37.08 | 39.79 | 48.25 | 24.38 | 32.39 |
| Use | 58.30 | 60.00 | 59.14 | 52.87 | 76.43 | 62.50 | 44.52 | 51.07 | 47.57 |
| Occur | 20.56 | 16.36 | 18.22 | 26.61 | 30.91 | 28.60 | 42.88 | 26.36 | 32.65 |
| Influence | 30.36 | 20.69 | 24.61 | 51.17 | 25.88 | 34.37 | 46.87 | 15.00 | 22.73 |
| HasVul | 72.16 | 59.22 | 65.05 | 50.23 | 23.53 | 32.05 | 74.11 | 18.82 | 30.02 |
| Mitigate | 30.78 | 53.97 | 39.20 | 40.70 | 50.48 | 45.07 | 43.50 | 12.38 | 19.27 |
| Located | 45.57 | 33.65 | 38.71 | 47.68 | 24.76 | 32.59 | 50.94 | 27.14 | 35.41 |
| Exploit | 46.03 | 67.92 | 54.87 | 50.50 | 20.00 | 28.65 | 24.76 | 12.50 | 16.61 |
| Reported | 34.02 | 27.50 | 30.41 | 16.12 | 25.00 | 19.60 | 43.43 | 22.50 | 29.64 |
| Patched | 44.71 | 48.67 | 46.61 | 41.33 | 36.00 | 38.48 | 68.45 | 52.00 | 59.10 |
| Defend | 35.05 | 9.79 | 15.31 | 21.33 | 7.50 | 11.10 | 90.00 | 5.62 | 10.58 |
| Model | FEDRE | FEDRE-KD | |||||||
| P (%) | R (%) | F1 (%) | P (%) | R (%) | F1 (%) | ||||
| Target | 69.72 | 62.81 | 66.08 | 82.86 | 63.97 | 72.20 | |||
| Perform | 64.47 | 62.82 | 63.63 | 71.88 | 73.40 | 72.63 | |||
| Rel-to | 89.86 | 68.13 | 77.50 | 92.79 | 73.57 | 82.07 | |||
| Use | 55.32 | 92.86 | 69.33 | 58.54 | 85.71 | 69.57 | |||
| Occur | 50.00 | 50.00 | 50.00 | 78.57 | 50.00 | 61.11 | |||
| Influence | 61.54 | 23.53 | 34.04 | 71.43 | 14.71 | 24.40 | |||
| HasVul | 92.31 | 80.00 | 85.72 | 88.46 | 76.67 | 82.14 | |||
| Mitigate | 84.62 | 52.38 | 64.71 | 66.67 | 38.10 | 48.49 | |||
| Located | 60.00 | 14.29 | 23.08 | 62.50 | 23.81 | 34.48 | |||
| Exploit | 61.26 | 40.25 | 48.58 | 62.50 | 45.45 | 52.63 | |||
| Reported | 54.12 | 47.67 | 50.69 | 75.00 | 60.00 | 66.67 | |||
| Patched | 68.91 | 60.71 | 64.55 | 85.71 | 85.71 | 85.71 | |||
| Defend | 58.99 | 14.14 | 22.81 | 57.13 | 16.55 | 25.67 | |||
| Sample Technique | P (%) | R (%) | F1 (%) |
|---|---|---|---|
| None | 58.46 | 48.67 | 53.12 |
| Under Sampling | 59.06 | 46.43 | 51.99 |
| Under Sampling + Over Sampling | 76.44 | 50.70 | 60.96 |
| Over Sampling | 72.37 | 59.32 | 65.20 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Guo, Y.; Fang, C.; Hu, Y.; Liu, Y.; Chen, Q. Feature-Enhanced Document-Level Relation Extraction in Threat Intelligence with Knowledge Distillation. Electronics 2022, 11, 3715. https://doi.org/10.3390/electronics11223715
Li Y, Guo Y, Fang C, Hu Y, Liu Y, Chen Q. Feature-Enhanced Document-Level Relation Extraction in Threat Intelligence with Knowledge Distillation. Electronics. 2022; 11(22):3715. https://doi.org/10.3390/electronics11223715
Chicago/Turabian StyleLi, Yongfei, Yuanbo Guo, Chen Fang, Yongjin Hu, Yingze Liu, and Qingli Chen. 2022. "Feature-Enhanced Document-Level Relation Extraction in Threat Intelligence with Knowledge Distillation" Electronics 11, no. 22: 3715. https://doi.org/10.3390/electronics11223715
APA StyleLi, Y., Guo, Y., Fang, C., Hu, Y., Liu, Y., & Chen, Q. (2022). Feature-Enhanced Document-Level Relation Extraction in Threat Intelligence with Knowledge Distillation. Electronics, 11(22), 3715. https://doi.org/10.3390/electronics11223715