Abstract
The tracker based on the Siamese network describes the object-tracking task as a similarity-matching problem. The Siamese network is the current mainstream model. It achieves similarity learning by applying correlation filters to the target and search branches’ convolution features. However, because the correlation operation uses a local linear matching process, semantic information is lost, and it is simple to run into the issue of local optimality. Transformer Tracking has recently been proposed using an attention-based feature fusion network instead of the previous correlation operation to achieve excellent results. However, it only uses limited feature space resolution. Because of the limitations of the Transformer module, the network’s convergence is also very slow. We propose Deformable Transformer Tracking (D-TransT) which employs a deformable attention module that pre-filters for prominent key elements among all feature map pixels using a small set of sampling locations, and this module can be naturally extensible to aggregating multi-scale features. D-TransT can have faster convergence and better prediction than Transformer Tracking. D-TransT improves the convergence speed by 29.4% and achieves 65.6%, 73.3%, and 69.1% in AUC, and P, respectively. The experimental results demonstrate that the proposed tracker performs better than the most state-of-the-art algorithm.
1. Introduction
In computer vision, object tracking is a challenging task. It seeks to continuously localize a target in succeeding frames based on the target of interest in the first frame (Figure 1). The tracker based on the Siamese network [1,2,3] is the current mainstream model. It achieves similarity learning by applying correlation filters to the target and search branches’ convolution features. However, semantic information is lost because the correlation operation uses a local linear matching process, and it is easy to fall victim to the problem of local optimality. Some scholars introduce the attention mechanism into the Siamese network to solve this problem. The main idea behind the attention mechanism is to let the tracker learn to focus on key information in the target area and ignore irrelevant information, thereby saving computing resources and obtaining the most helpful information. In 2020, transformer [4] models were first applied to image classification tasks [5,6] and achieved better results than CNN [7] models. Since then, numerous studies have tried to apply the transformer’s potent modeling capabilities to computer vision [8]. In object tracking, Chen Xin et al. proposed Transformer Tracking [9] (TransT). Unlike Siamese-based trackers, Instead of the previous correlation operation, Transformer Tracking uses an attention-based feature fusion network to determine how similar the template and the search region are [10,11,12,13,14,15,16,17]. By combining template and ROI features, this method effectively increases the number of semantic feature mappings. Transformer Tracking has issues even though it produced positive results in the dataset.
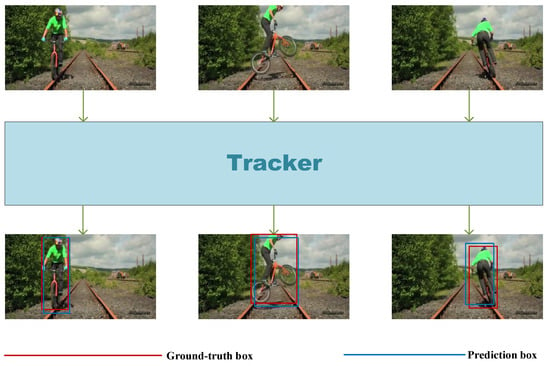
Figure 1.
Example of single object tracking.
- Compared to other object-tracking networks, it takes more training time to converge the network.
- Transformer Tracking ignores multi-scale features, so there is room for further tracking performance improvement.
To increase the convergence speed of the model and introduce multi-scale features, we were inspired by the success of Deformable DETR [18] and proposed D-TransT which uses a deformable attention module. With the help of a cross-feature augment module built on a deformable attention mechanism, D-TransT enables the tracker to achieve better classification and regression results as well as quicker convergence.
2. Related Work
2.1. Siamese-Based Networks
In object tracking, Siamese-based networks have achieved great success. They determine the target and its position by measuring the template and search region similarity. SiamFC [19] (as shown in Figure 2) is the first algorithm to propose the Siamese network. The template z and search region x features are extracted using the convolutional network, and correlation operations are then carried out to produce a response map. The highest point in the response map is the target.
where g is the convolution operation and is the convolution kernel. Based on SiamFC, SiamRPN [20] introduces the RPN [21] structure in object detection into SiamFC. It uses shared parameters to extract features and obtain the target position through the classification branch. The regression branch obtains an accurate estimate of the target scale. Li et al. proposed SiamRPN++ [22] to enhance SiamRPN’s [23] performance by using ResNet [24] as the backbone network rather than Alex-Net and translating the target in the search area at random to ensure translation invariance. Danelljan et al. suggested the PrDimp [25] method as a probability-based regression technique. This method trains the regression network with the least amount of KL divergence and predicts the target state’s conditional probability density. Siam R-CNN [26] is created by combining the Faster R-CNN [27] and Siamese network. Faster R-CNN is used to generate candidate regions, while the Siamese network is used to extract features. Ocean [28], the target-aware anchor-free method, uses various sampling techniques for its classification and regression branches. Although the network based on Siamese has achieved good results, the correlation operation cannot make good use of the global context information. This will lead to the loss of semantic information.
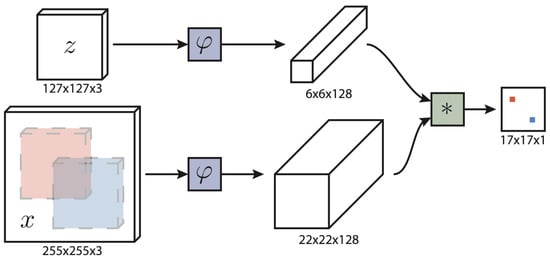
Figure 2.
The structure of the SiamFC [19]. The output of the model is a score map. Its dimensions are the same as the size of the search image x. In this case, the score map’s red and blue pixels contain similarities for the corresponding sub-windows. The symbol * indicates the correlation operation.
2.2. Vision Transformer
The Transformer shines brightly in natural language processing. Many researchers use it in computer vision because of its outstanding context modeling capabilities. Dosovitskiy et al. proposed ViT for the first time, which applies the original Transformer to image classification tasks. It is a pure Transformer structure completely based on the self-attention mechanism. The accuracy rate of 88.55% Top-1 on the ImageNet dataset exceeds ResNet series models, breaks the monopoly of CNN in visual tasks, and has a stronger generalization ability than CNN. ViT has made breakthrough progress, but it also has its defects in Visual tasks. (1) The token input by ViT is of fixed length, but the image scale changes greatly; (2) The computational complexity of ViT is very high, which is not conducive to vision applications with high-resolution images. To solve these problems, Liu et al. [29] put forward Swin Transformer. The Transformer model can flexibly process images of different scales by applying a hierarchical structure similar to CNN. Swin Transformer adopts the window attention mechanism, which only calculates the attention of the pixel area in the window, reducing the computational complexity of the square relationship of the number of ViT tokens to a linear relationship. In object tracking, the Transformer Tracking proposed by Chen Xin et al. [9] achieved excellent results. The network effectively fuses template and search region features through attention to enhance contextual information and generate more semantic maps. However, due to the characteristics of the Transformer, Transformer Tracking converges very slowly. Because it gives each pixel in the feature map nearly identical attention weights, its computational and memory complexity is very high when processing high-resolution feature maps.
2.3. Deformable Attention Modules
The transformer lacks components for processing image feature maps. The attention module initially gives each pixel on the feature map almost the same attention weight. Long training sessions are necessary to develop attentional focus on scarce and advantageous positions. From the other hand, the Transformer encoder’s attention weight calculation is squared in relation to the number of pixels. Therefore, to process high-resolution feature maps, the computational complexity is very high, and the memory complexity is also very high. In the image field, deformable convolution is a powerful and efficient mechanism to deal with sparse spatial positions. It naturally avoids the above problems. Inspired by deformable convolution, Xichou Zhu et al. proposed the Deformable DETR. Deformable DETR proposes the deformable attention module which uses all feature map pixels as a pre-filter, using a small sampling position to identify prominent key elements. Inspired by Deformable DETR, we applied the deformable attention module to Transformer Tracking to increase the convergence speed of Transformer Tracking and aggregate multi-scale features instead of single-scale features.
3. Deformable Transformer Tracking
This chapter will elaborate on our model D-TransT (as shown in Figure 3). Our model consists of three parts:
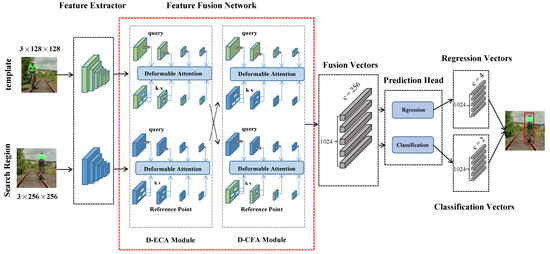
Figure 3.
Architecture for Deformable Transformer Tracking. It consists of three parts: feature extraction, feature fusion, and prediction head. The deformable attention module pre-filters for influential key elements among all feature map pixels using a small set of sampling points.
- Feature extraction module: Used to extract the search region’s and template’s features.
- Feature fusion module: Instead of the traditional correlation operation, the cross-attention mechanism is used for feature fusion.
- Prediction head module: Classification and bounding box regression is performed based on the feature fusion module to generate tracking results.
We provided descriptions and discussions after providing an introduction to each D-TransT component and the Deformable attention module in the feature fusion network.
3.1. Overall Architecture
3.1.1. Feature Extraction Module
Like other Siamese networks, D-TransT uses Resnet as the network’s backbone. It uses the characteristics of different semantic feature expression capabilities of different layers in deep-feature aggregated multi-scale features. In this paper, the third, fourth, and fifth stages of Resnet are extracted and downsampled to obtain the output of the feature extraction module (as shown in Figure 4). The search region image patch () and the template image patch () serve as the backbone network’s inputs. D-TransT performs 1 × 1, 1 × 1, and 3 × 3 convolution operations on the features of the third, fourth, and fifth layers extracted by Resnet to obtain feature representations with the same channel size.
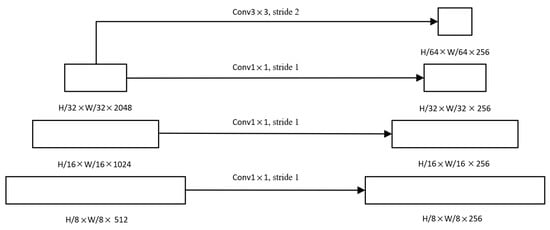
Figure 4.
Multi-scale feature maps for Deformable Transformer Tracking.
At this time, the features of the image patches of the template and the search region are, respectively, represented: and . , , and .
3.1.2. Feature Fusion Module
The feature fusion network takes the four feature stages extracted from the above template and the search region as input. In contrast to the correlation operation of traditional object tracking algorithms, it uses deformable multi-head cross-attention to fuse two feature maps.
The process of the Feature Fusion Network is as follows: First, to improve feature representation, the two deformable ego-context augment (D-ECA) modules efficiently focus on the relevant semantic context through the deformable attention module. Then, using the multi-head cross-attention mechanism, two cross-feature augment (D-CFA) modules fuse the two feature maps they received simultaneously from one branch and another. As such, the problem of semantic information loss caused by the traditional tracker’s local linear matched correlation filter is solved.
Compared with the ego-context augment (ECA) and cross-feature augment (CFA) modules, D-ECA and D-CFA modules can improve the convergence speed of the model and aggregate multi-scale features.
ECA module:Figure 5 depicts the ECA structure. Inspired by the encoder structure in the transformer structure, ECA used the residual form of a multi-head self-attention mechanism to adaptively integrate the information from different locations of the feature map to enhance the feature representation of the network.
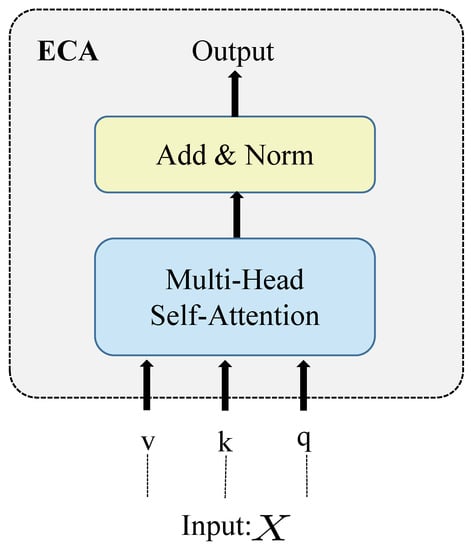
Figure 5.
The structure of the ECA module.
CFA module:Figure 6 depicts the structure of CFA. The decoder module in the transformer is referred to as CFA. CFA fuses eigenvectors from two inputs in the form of residuals using multi-head cross-attention. Furthermore, the FFN module, a fully connected feedforward network composed of two linear transformations, is used to improve the model’s fitting ability.
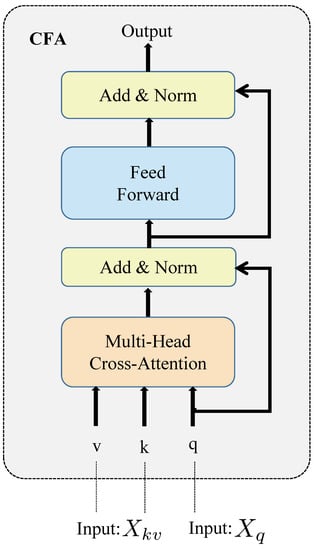
Figure 6.
The structure of the CFA module. The input receives the feature from the branch, and the input receive the feature from the other branch.
Deformable Attention: In Transformer, the multi-head attention module is as follows (Some symbols refer to Table 1):
where is the query element, which is generated by a linear transformation of the vector x, q is the corresponding index, k indexes the key element, is all set of k, m represents the index of the attention head, is the output result obtained by applying attention to the value and then performing the linear transformation, is used to transform into the value, represents the normalized attention weight. Assuming that the number of key elements is , if the parameter initialization is reasonable, the attention weight ; when is large, we need a longer training time to focus the attention weight on specific keys. In object tracking, the key element is the image pixel, where is enormous, so the network convergence is very slow. Unlike the self-attention mechanism, the query element in this paper does not calculate the attention weight with the key elements of each position in the global. It only samples the key elements of some positions, and the value element is also sampled and interpolated based on these positions. Finally, the local sparse attention weight is applied to the corresponding value, which significantly accelerates the convergence speed of the model. It also reduces the computational complexity and required space resources, as shown in Figure 7.

Table 1.
The table for notation.
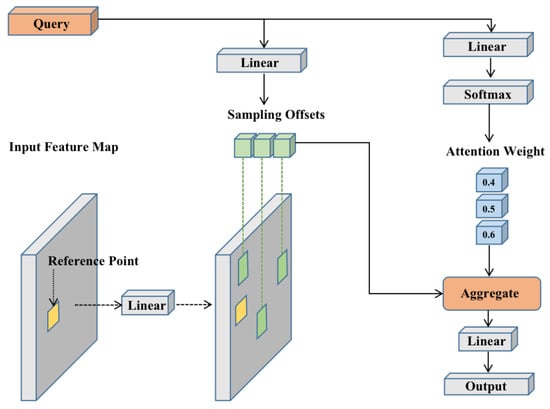
Figure 7.
The structure of the deformable attention module.
The multi-head attention formula we adopted is as follows:
is the position of , means the position offset of the sampling set point relative to the reference point (obtained by learning). K represents the K positions that query element samples in each attention head, an is the value interpolated from these sampling point positions. To solve the problem that multi-scale features are not introduced in Transformer Tracking, this paper applies attention to multi-scale features:
represents multi-scale features, represents the features of the l-th layer. is an unnormalized 2D coordinate of in the feature level. Each query element will sample K points in each feature layer, and the attention weight is also normalized between these points.
3.1.3. Prediction Head Network
Classification and regression branches are present in the prediction head network. The regression branch is used to indicate the offset of the search area at the center point, and the classification branch is used to predict the classification result of each bounding box to determine the foreground or background. To determine the results of the foreground/background and offset relative to the center position classifications, respectively, the prediction head network predicts the fusion vector created by the feature fusion network.
3.2. Training Loss
For classification, we use binary cross-entropy, and the loss is given by:
is the ground-truth bounding box of the j-th sample, represents the foreground, and means the probability of prospects. For the regression module, we use norm loss and IoU loss , the regression loss is defined as follows:
where is the positive sample, is the j-th predicted bounding box, represents the ground-truth bounding box, , and are the regularization parameters.
4. Experiments
4.1. Implementation Details
For training, we use COCO [30], LaSOT [31], GOT-10K [32], and TrackingNet [33]. Furthermore, we use some data augmentation methods to enlarge our dataset, such as geometric transformation, adding noise, etc. We use ResNet-50 as our backbone network and set the learning rate of the backbone network to and weight decay to . The backbone is initialized with the weights that are pre-trained on ImageNet. We train our network on two NVIDIA (Santa Clara, California, USA) GeForce RTX 3090 GPUs. We set the batch size to 38. We train the model for a total of 1000 epochs. After 500 epochs, the learning rate is reduced by a factor of 10.
4.2. State-of-the-Art Comparison
We compared the D-TransT proposed in this paper with recent related works (SiamFC, ATOM [34], SiamRPN, DaSiamRPN [35], SiamRPN++, DiMP [36], PrDimp, SiamR-CNN, Ocean) on OTB100 and LaSOT, respectively. Our model has achieved good results. Compared with the state-of-the-art TransT, our model performs better (as shown in Figure 8).

Figure 8.
A comparison of our approach with TransT.
OTB100: OTB100 is the standard dataset proposed by Wu et al. [37] in 2013. It has a total of more than 29,000 frames of images. We use the EAO, robustness, and accuracy scores to compare the tracking performance of state-of-the-art algorithms on the OTB dataset. As shown in Table 2 (Refer to Table 3 for evaluation indicators), our network offers the best performance, mainly because the network obtains more robust semantic expression through multi-scale feature fusion and uses the feature fusion network based on the attention mechanism to replace the previous correlation operation. Compared to algorithms based on correlation operation, our method performs better than PrDiMP, SiamR-CNN, etc. Compared to Transformer Tracking, which does not exploit multi-scale features, our method also performs well. The performance comparison of each state-of-art algorithm is shown in Figure 9.
Table 2.
State-of-the-art comparison on LaSOT and OTB100.
Table 3.
The table for evaluation metrics.
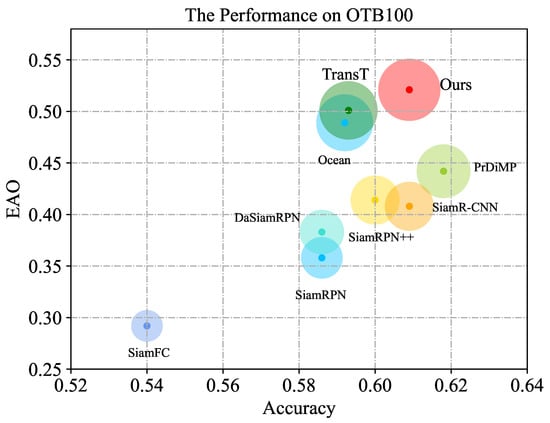
Figure 9.
The performance on OTB100. Expected average overlap (EAO) is the expected value of the non-reset overlap of each tracker on a short-term image sequence.
LaSOT: LaSOT is a high-standard data set recently proposed by Fan et al. [31]. It contains 70 categories and 1400 videos that are all manually labeled. It is divided into training sets and test sets, and the two do not overlap. The average video length of the group is approximately 2500 frames, and the algorithm training is challenging. At the same time, the author also proposed the corresponding evaluation criteria and tested the performance of the most current leading target tracking algorithms. As shown in Table 2, our method achieves 65.6%, 73.3%, and 69.1% in AUC, and P, respectively. It is better than other trackers. The normalized precision plots of OPE on LaSOT are shown in Figure 10.
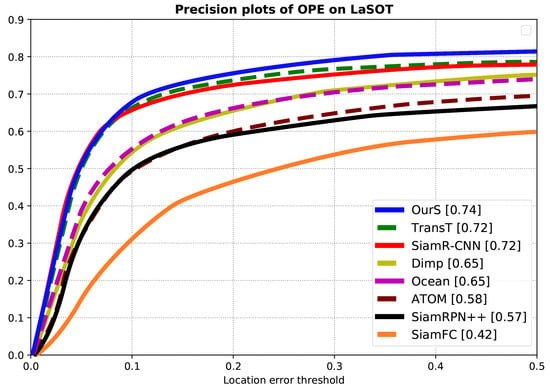
Figure 10.
Normalized precision plots of OPE on LaSOT. The abscissa is the location error threshold, and the ordinate is precision.
4.3. Ablation Analysis
Transformer Tracking achieved excellent results. The network effectively fuses the template and search region features through attention to enhance the contextual information and generate more semantic maps. However, because it almost uniformly applies attention weights to every pixel in the feature map, Transformer Tracking converges very slowly. Furthermore, it ignores multi-scale features. We conduct experiments to explore the impact of D-ECA and D-CFA modules on tracker performance. We compare the ECA and CFA modules in Transformer Tracking; the comparison results are shown in Table 4 and Table 5. The comparison results show that using D-ECA to replace the ECA module improves the tracker performance. Using the CFA module instead of the D-CFA module will decrease the performance. Simultaneously using the D-ECA and D-CFA modules can achieve better results and faster convergence. It is obvious from Table 4 and Table 5 that using the Deformable DETR model can greatly reduce the time of model training. The above can prove the effectiveness of the D-ECA and D-CFA modules.
Table 4.
Ablation study on LaSOT.
Table 5.
Ablation study on OTB100.
5. Conclusions
This study builds a multi-scale attention mechanism-based object-tracking algorithm. In order to replace the previous correlation operation and add more feature spatial resolution, it employs a feature fusion network of an attention mechanism. It further improves the network’s ability to express the global context and helps the tracker more effectively track the target. Thanks to the deformable attention module, its convergence speed is faster. The experimental results of this paper on the OTB100 and LaSOT datasets show that compared with TransT, SiameseRPN, and other methods, D-TransT further improve the tracker performance. Furthermore, the effectiveness and feasibility of the method are verified. D-TransT improves the convergence speed by 29.4% and achieves 65.6%, 73.3%, and 69.1% in AUC, and P, respectively. The experimental results show that the performance of the proposed tracker is better than that of the state-of-the-art algorithm. Although the introduction of a deformable attention module can greatly increase the convergence time of the tracking model, there is still much room for improvement compared with the tracker based on correlation operations, which is also the research direction of our future work.
Author Contributions
Conceptualization, J.Z. and R.Y.; methodology, J.Z. and R.Y.; software, J.Z.; validation, J.Z., Y.Y. and Y.X.; formal analysis, Y.Y. and J.Z.; investigation, Y.Y.; resources, Y.Y. and Y.X.; data curation, J.Z. and Y.Y.; writing—original draft preparation, J.Z., Y.Y., R.Y. and Y.X.; writing—review and editing, J.Z. and Y.Y.; supervision, Y.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Guo, D.; Wang, J.; Cui, Y.; Wang, Z.; Chen, S. SiamCAR: Siamese fully convolutional classification and regression for visual tracking. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Zhang, Z.; Peng, H. Deeper and wider siamese networks for real-time visual tracking. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Chen, Z.; Chen, Z.; Zhong, B.; Li, G.; Zhang, S.; Ji, R. Siamese box adaptive network for visual tracking. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, L. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. arXiv 2021, arXiv:2105.05537. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. In The Handbook of Brain Theory and Neural Networks; MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
- Dong, X.; Bao, J.; Chen, D.; Zhang, W.; Yu, N.; Yuan, L.; Chen, D.; Guo, B. Cswin transformer: A general vision transformer backbone with cross-shaped windows. In Proceedings of the 2022 IEEE/CVF International Conference on Computer Vision, New Orleans, LA, USA, 19–20 June 2022. [Google Scholar]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 11–17 October 2021. [Google Scholar]
- Danelljan, M.; Robinson, A.; Khan, F.; Felsberg, M. Beyond correlation filters: Learning continuous convolution operators for visual tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Danelljan, M.; Bhat, G.; Shahbaz, k.; Felsberg, M. Eco: Efficient convolution operators for tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ma, C.; Huang, J.; Yang, X.; Yang, M. Hierarchical convolutional features for visual tracking. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Jiang, B.; Luo, R.; Mao, J. Acquisition of localization confidence for accurate object detection. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Bolme, D.S.; Beveridge, J.; Draper, B.; Lui, Y. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Henriques, J.F.; Gaseiro, R.; Martins, P.; Batista, J. Exploiting the circulant structure of tracking-by-detection with kernels. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef] [PubMed]
- LuNežič, A. Discriminative correlation filter TracNer with channel and spatial reliability. Int. J. Comput. Vis. 2018, 126, 671–688. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. In Proceedings of the 2020 International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.; Vedaldi, A.; Torr, P. Fully-convolutional siamese networks for object tracking. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Li, B.; Yan, J.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Li, B.; Wu, W.; Wang, Q. Siamrpn++: Evolution of siamese visual tracking with very deep networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 2012 Advances in Neural Information Processing Systems 25, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Danelljan, M.; Van Gool, L.; Timofte, R. Probabilistic regression for visual tracking. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Voigtlaender, P.; Luiten, J.; Torr, P.; Leibe, B. Siam r-cnn: Visual tracking by re-detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Zhang, Z.; Peng, H.; Fu, J.; Li, B.; Hu, W. Ocean: Object-aware anchor-free tracking. In Proceedings of the 2020 European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; 17 October 2021. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Fan, H.; Lin, L.; Yang, F.; Chu, P.; Deng, G.; Yu, S.; Bai, H.; Xu, Y.; Liao, C.; Ling, H. Lasot: A high-quality benchmark for large-scale single object tracking. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Huang, L.; Xin, Z.; Kaiqi, H. Got-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1562–1577. [Google Scholar] [CrossRef] [PubMed]
- Muller, M.; Bibi, A.; Giancola, S.; Alsubaihi, S.; Ghanem, B. Trackingnet: A large-scale dataset and benchmark for object tracking in the wild. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.; Felsbeg, M. Atom: Accurate tracking by overlap maximization. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zha, Y.; Wu, M.; Qiu, Z.; Dong, S.; Yang, F.; Zhang, P. Distractor-aware visual tracking by online Siamese network. IEEE Access 2019, 7, 89777–89788. [Google Scholar] [CrossRef]
- Bhat, G.; Danelljan, M.; Gool, L.; TimoFte, R. Learning discriminative model prediction for tracking. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wu, Y.; Jongwoo, L.; Yang, M. Online object tracking: A benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]










Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).