
Handling Missing Values Based on Similarity Classifiers and Fuzzy Entropy Measures

 ,
,
Abstract
1. Introduction
1.1. Missing Data
1.1.1. Missingness Mechanisms
1.1.2. Simple Methods for Handling MVs
1.2. Feature Selection
1.2.1. Similarity-Based Classification
1.2.2. Fuzzy Entropy & Similarity Classifier
1.3. Motivation and Contribution
2. Literature Review
2.1. The Problem of MVs
2.2. FS with MVs
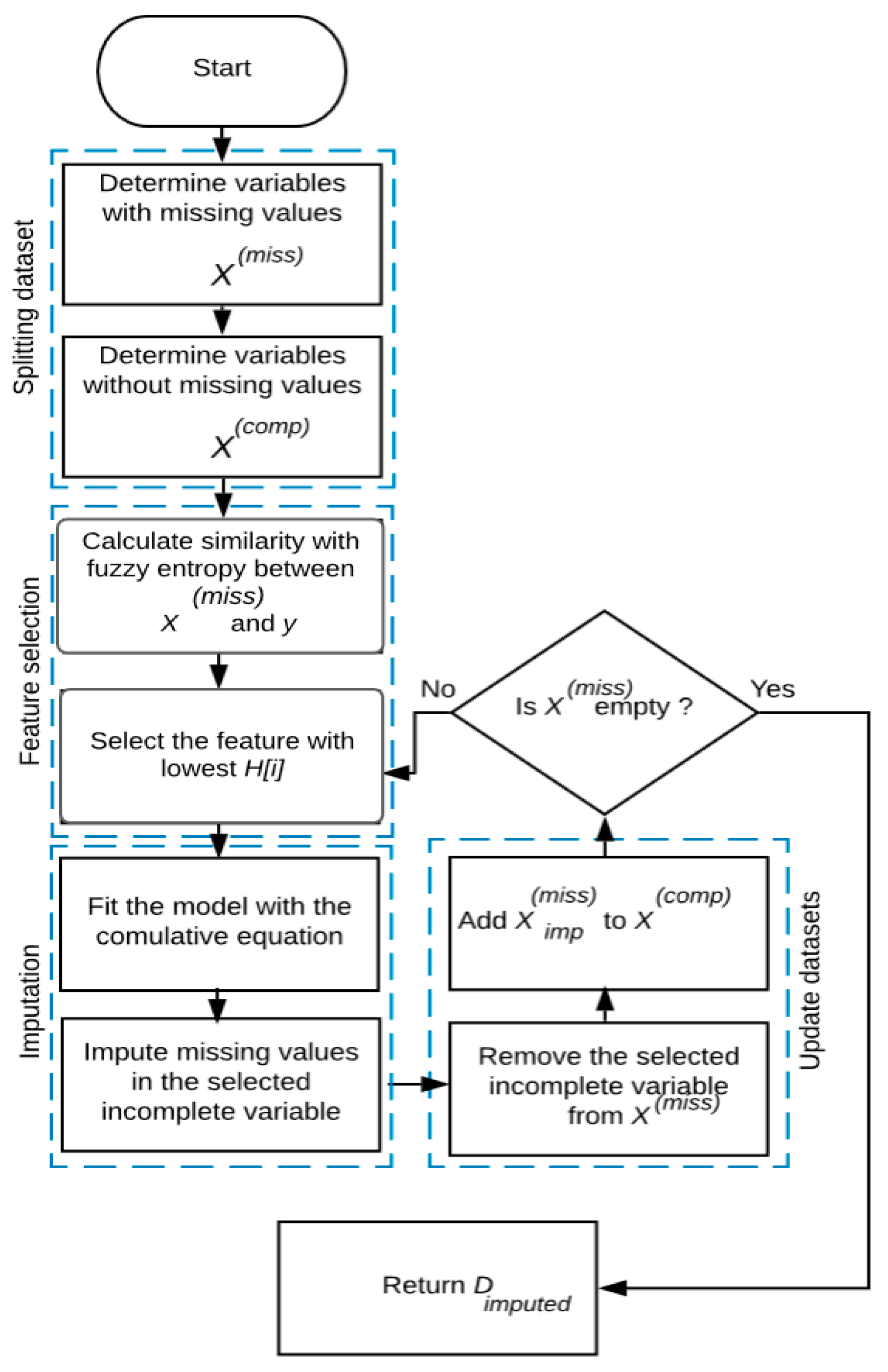
3. Proposed Algorithm
| Algorithm 1: CBRSL |
| 1: Input: 2: D: a dataset with MVs containing n instances. 3: Output: 4: Dimputed: a dataset with all missing features imputed. 5: Definitions: 6: Set of complete features. 7: Set of incomplete features. 8: . 9: Number of features containing MVs. 10: Fuzzy entropy measure with the similarity. 11: Begin 12: . 13: that exhibits #. 14: 15: . 16: 17: with the fitted model. 18: and add to . 19: End While 20: 21: End |
4. Experimental Setup
4.1. Datasets
4.2. Performance Evaluation
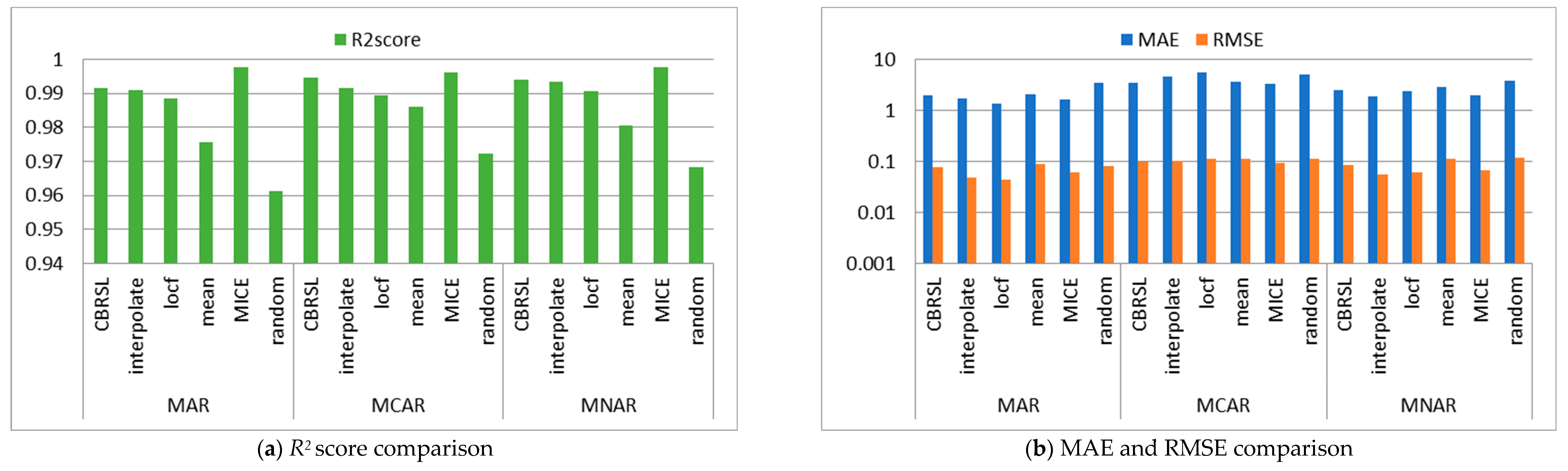
4.3. MAE and RMSE
4.4. R2 Score
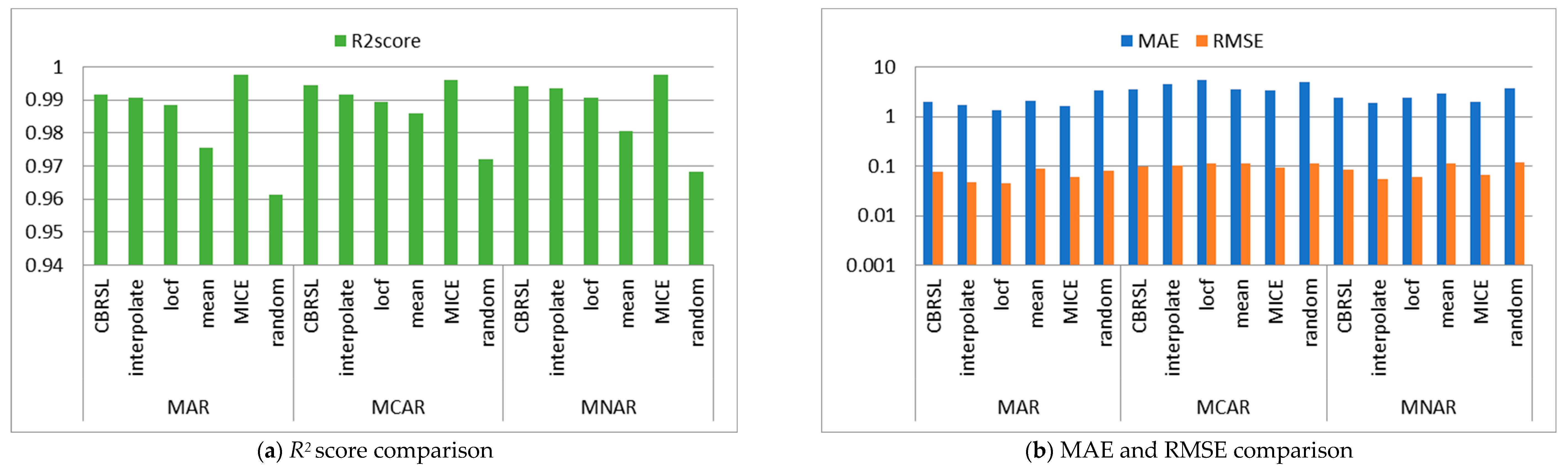
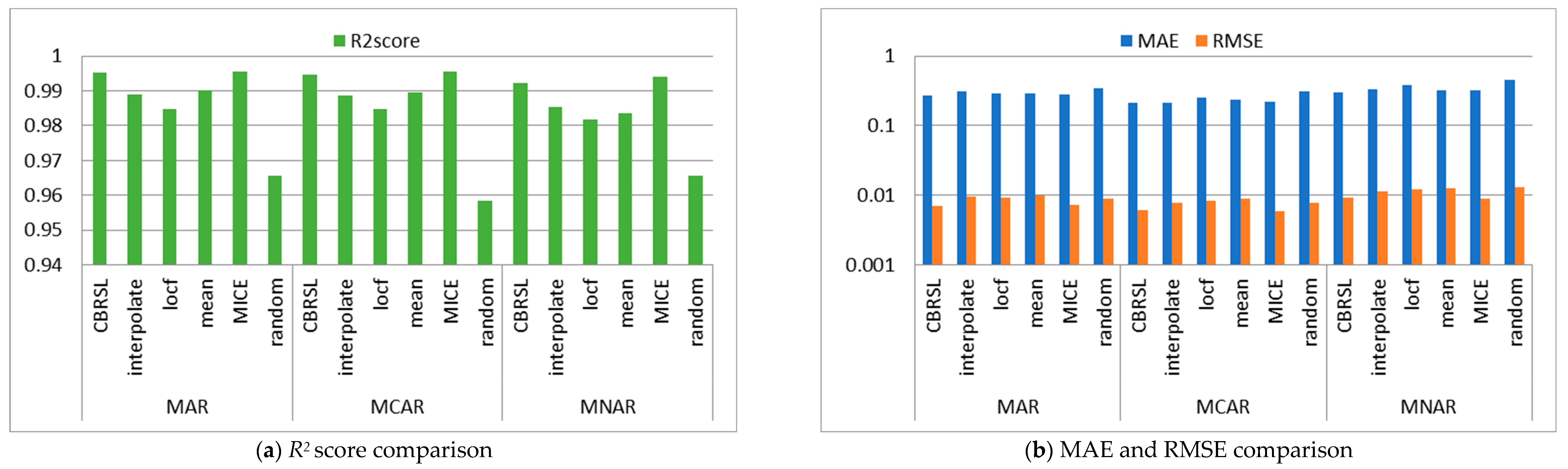
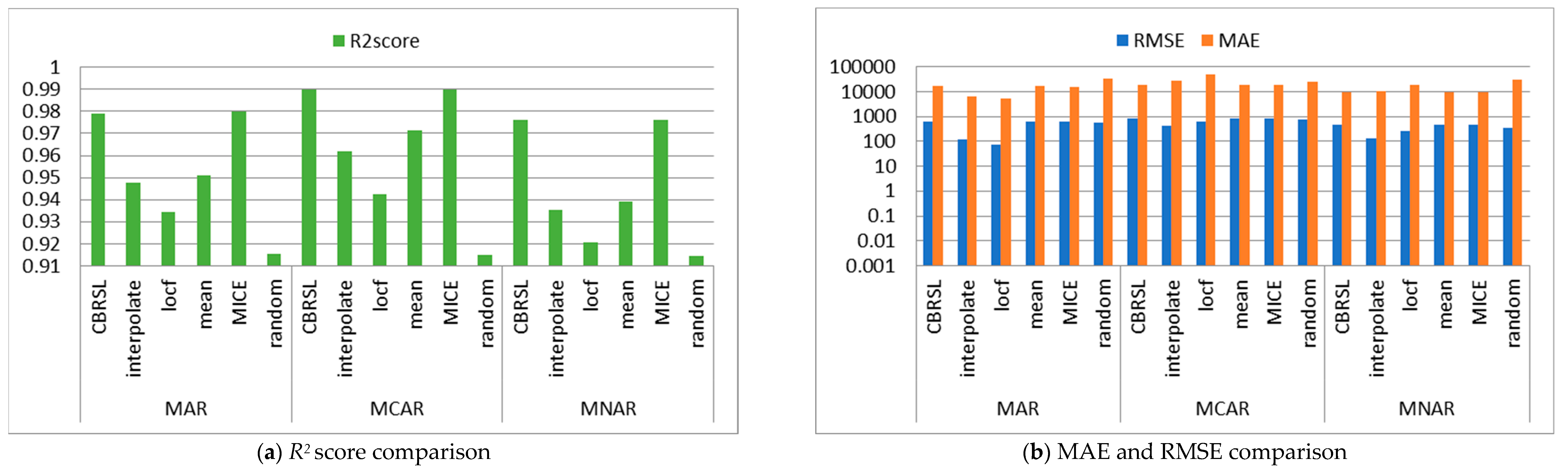
5. Analysis and Discussion
5.1. Error Analysis
5.2. Accuracy Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- García, S.; Ramírez-Gallego, S.; Luengo, J.; Benítez, J.M.; Herrera, F. Big data preprocessing: Methods and prospects. Big Data Anal. 2016, 1, 1–22. [Google Scholar] [CrossRef]
- Mostafa, S.M. Imputing missing values using cumulative linear regression. CAAI Trans. Intell. Technol. 2019, 4, 182–200. [Google Scholar] [CrossRef]
- Mostafa, S.M.; Eladimy, A.S.; Hamad, S.; Amano, H. CBRG: A novel algorithm for handling missing data using bayesian ridge regression and feature selection based on gain ratio. IEEE Access 2020, 8, 216969–216985. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Mostafa, S.M. Missing data imputation by the aid of features similarities. Int. J. Big Data Manag. 2020, 1, 81–103. [Google Scholar] [CrossRef]
- Yadav, M.L.; Roychoudhury, B. Handling missing values: A study of popular imputation packages in R. Knowl.-Based Syst. 2018, 160, 104–118. [Google Scholar] [CrossRef]
- Chen, M.; Zhu, H.; Chen, Y.; Wang, Y. A Novel Missing Data Imputation Approach for Time Series Air Quality Data Based on Logistic Regression. Atmosphere 2022, 13, 1044. [Google Scholar] [CrossRef]
- Zhang, Y.; Thorburn, P.J. Handling missing data in near real-time environmental monitoring: A system and a review of selected methods. Future Gener. Comput. Syst. 2022, 128, 63–72. [Google Scholar] [CrossRef]
- Rubin, D.B. Multiple Imputation for Nonresponse in Surveys; Wiley: Hoboken, NJ, USA, 1987. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Seijo-Pardo, B.; Alonso-Betanzos, A.; Bennett, K.P.; Bolón-Canedo, V.; Josse, J.; Saeed, M.; Guyon, I. Biases in feature selection with missing data. Neurocomputing 2019, 342, 97–112. [Google Scholar] [CrossRef]
- Jain, A.; Zongker, D. Feature selection: Evaluation, application, and small sample performance. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 153–158. [Google Scholar] [CrossRef]
- Lewin, D.I. Getting clinical about neural networks. IEEE Intell. Syst. Appl. 2000, 15, 2–5. [Google Scholar] [CrossRef][Green Version]
- Jain, A.K.; Chandrasekaran, B. 39 Dimensionality and sample size considerations in pattern recognition practice. Handb. Stat. 1982, 2, 835–855. [Google Scholar]
- de Luca, A.; Termini, S. A definition of a nonprobabilistic entropy in the setting of fuzzy sets theory. Inf. Control 1972, 20, 301–312. [Google Scholar] [CrossRef]
- Luukka, P. Feature selection using fuzzy entropy measures with similarity classifier. Expert Syst. Appl. 2011, 38, 4600–4607. [Google Scholar] [CrossRef]
- Dougherty, G. Feature extraction and selection. In Pattern Recognition and Classification: An Introduction; Springer: New York, NY, USA, 2013; pp. 157–176. [Google Scholar]
- Venables, W.N.; Ripley, B.D. Classification. In Modern Applied Statistics with S-PLUS, Statistics and Computing; Springer: New York, NY, USA, 2002; pp. 331–351. [Google Scholar]
- Kurama, O. Similarity Based Classification Methods with Different Aggregation Operators. Ph.D. Thesis, Lappeenranta University of Technology, Lappeenranta, Finland, 2017. [Google Scholar]
- Luukka, P.; Saastamoinen, K.; Kononen, V. A classifier based on the maximal fuzzy similarity in the generalized Lukasiewicz-structure. In Proceedings of the 10th IEEE International Conference on Fuzzy Systems. (Cat. No.01CH37297), Melbourne, VIC, Australia, 2–5 December 2001; pp. 195–198. [Google Scholar]
- Zadeh, L.A. Fuzzy Sets and Information Granularity. Advances in Fuzzy Set Theory and Applications. 1979, pp. 3–18. Available online: https://www2.eecs.berkeley.edu/Pubs/TechRpts/1979/ERL-m-79-45.pdf (accessed on 15 August 2022).
- Revanasiddappa, M.B.; Harish, B.S. A New feature selection method based on intuitionistic fuzzy entropy to categorize text documents. Int. J. Interact. Multimed. Artif. Intell. 2018, 5, 106–117. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Mostafa, S.M.; Eladimy, A.S.; Hamad, S.; Amano, H. CBRL and CBRC: Novel algorithms for improving missing value imputation accuracy based on bayesian ridge regression. Symmetry 2020, 12, 1594. [Google Scholar] [CrossRef]
- Doquire, G.; Verleysen, M. Feature selection with missing data using mutual information estimators. Neurocomputing 2012, 90, 3–11. [Google Scholar] [CrossRef]
- Farhangfar, A.; Kurgan, L.A.; Pedrycz, W. A Novel framework for imputation of missing values in databases. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2007, 37, 692–709. [Google Scholar] [CrossRef]
- Horton, N.J.; Lipsitz, S.R. Multiple imputation in practice: Comparison of software packages for regression models with missing variables. Am. Stat. 2001, 55, 244–254. [Google Scholar] [CrossRef]
- Fichman, M.; Cummings, J.N. Multiple imputation for missing data: Making the most of what you know. Organ. Res. Methods 2003, 6, 282–308. [Google Scholar] [CrossRef]
- Graham, J.W. Missing data analysis: Making it work in the real world. Annu. Rev. Psychol. 2009, 60, 549–576. [Google Scholar] [CrossRef] [PubMed]
- Bertsimas, D.; Pawlowski, C.; Zhuo, Y.D. From predictive methods to missing data imputation: An optimization approach. J. Mach. Learn. Res. 2018, 18, 1–39. [Google Scholar]
- Ma, Z.; Chen, G. Bayesian methods for dealing with missing data problems. J. Korean Stat. Soc. 2018, 47, 297–313. [Google Scholar] [CrossRef]
- Razavi-Far, R.; Cheng, B.; Saif, M.; Ahmadi, M. Similarity-learning information-fusion schemes for missing data imputation. Knowledge-Based Systems 2020, 187, 104805. [Google Scholar] [CrossRef]
- Do, C.B.; Batzoglou, S. What is the expectation maximization algorithm? Nat. Biotechnol. 2008, 26, 897–899. [Google Scholar] [CrossRef]
- Jiang, H. Defect features recognition in 3D Industrial CT Images. Informatica 2018, 42, 477–482. [Google Scholar] [CrossRef]
- Royston, P. Multiple imputation of missing values. Stata J. 2004, 4, 227–241. [Google Scholar] [CrossRef]
- Acock, A.C. Working with missing values. J. Marriage Fam. 2004, 67, 1012–1028. [Google Scholar] [CrossRef]
- Sahri, Z.; Yusof, R.; Watada, J. FINNIM: Iterative imputation of missing values in dissolved gas analysis dataset. IEEE Trans. Ind. Inform. 2014, 10, 2093–2102. [Google Scholar] [CrossRef]
- Lee, K.J.; Carlin, J.B. Multiple imputation for missing data: Fully conditional specification versus multivariate normal imputation. Am. J. Epidemiol. 2010, 171, 624–632. [Google Scholar] [CrossRef]
- Khalid, S.; Khalil, T.; Nasreen, S. A survey of feature selection and feature extraction techniques in machine learning. In Proceedings of the 2014 Science and Information Conference, London, UK, 27–29 August 2014; pp. 372–378. [Google Scholar]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Zaffalon, M.; Hutter, M. Robust feature selection by mutual information distributions. In Proceedings of the Eighteenth Conference on Uncertainty in Artificial Intelligence (UAI2002), Edmonton, AB, Canada, 1–4 August 2002; pp. 577–584. [Google Scholar]
- Meesad, P.; Hengpraprohm, K. Combination of knn-based feature selection and knn based missing-value imputation of microarray data. In Proceedings of the International Conference on Innovative Computing, Information and Control, Dalian, China, 18–20 June 2008; p. 341. [Google Scholar]
- Van Buuren, S. MICE: Multivariate Imputation by Chained Equations. 2021. Available online: https://cran.r-project.org/web/packages/mice/index.html (accessed on 1 August 2022).
- Wi, H. Wolberg, Breast Cancer Wisconsin. 1992. Available online: https://archive.ics.uci.edu/ml/datasets/breast+cancer+wisconsin+(original) (accessed on 1 August 2022).
- Ilter, M.D.N.; Guvenir, H.A. Dermatology. 1998. Available online: https://archive.ics.uci.edu/ml/datasets/dermatology (accessed on 4 August 2022).
- Max Little, Parkinsons. 2008. Available online: https://archive.ics.uci.edu/ml/datasets/parkinsons (accessed on 4 August 2022).
- Rossi, R.A.; Nesreen, K. Ahmed, Pima Indians Diabetes. 1990. Available online: http://networkrepository.com/pima-indians-diabetes.php (accessed on 2 August 2022).
- Donders, A.R.T.; van der Heijden, G.J.M.G.; Stijnen, T.; Moons, K.G.M. Review: A gentle introduction to imputation of missing values. J. Clin. Epidemiol. 2006, 59, 1087–1091. [Google Scholar] [CrossRef] [PubMed]
- Kearney, J.; Barkat, S. Autoimpute. 2019. Available online: https://autoimpute.readthedocs.io/en/latest/ (accessed on 2 August 2022).
- Law, E. Impyute. 2017. Available online: https://impyute.readthedocs.io/en/master/ (accessed on 1 August 2022).
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | References | #Instances | #Features | Missingness Mechanism | ||
|---|---|---|---|---|---|---|
| MAR | MCAR | MNAR | ||||
| Breast Cancer Wisconsin | [44] | 699 | 10 | √ | √ | √ |
| Dermatology | [45] | 366 | 33 | √ | √ | √ |
| Parkinson’s | [46] | 197 | 23 | √ | √ | √ |
| Pima Indians Diabetes | [47] | 768 | 8 | √ | √ | √ |
| Package (Function Name) | Description |
|---|---|
| Impyute (MICE) [43,48] | Handles MVs through the use of multivariate imputation using the chained equations algorithm. |
| Autoimpute (interpolate) [49] | Imputes MVs using linear interpolation. |
| Autoimpute (locf) [49] | Imputes MVs by carrying the last observation moving forward. |
| SimpleImputer (mean) [49] | Imputes MVs using the mean for each feature. |
| Impyute (random) [50] | Imputes MVs using a randomly selected value from the same feature. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karim, F.K.; Elmannai, H.; Seleem, A.; Hamad, S.; Mostafa, S.M. Handling Missing Values Based on Similarity Classifiers and Fuzzy Entropy Measures. Electronics 2022, 11, 3929. https://doi.org/10.3390/electronics11233929
Karim FK, Elmannai H, Seleem A, Hamad S, Mostafa SM. Handling Missing Values Based on Similarity Classifiers and Fuzzy Entropy Measures. Electronics. 2022; 11(23):3929. https://doi.org/10.3390/electronics11233929
Chicago/Turabian StyleKarim, Faten Khalid, Hela Elmannai, Abdelrahman Seleem, Safwat Hamad, and Samih M. Mostafa. 2022. "Handling Missing Values Based on Similarity Classifiers and Fuzzy Entropy Measures" Electronics 11, no. 23: 3929. https://doi.org/10.3390/electronics11233929
APA StyleKarim, F. K., Elmannai, H., Seleem, A., Hamad, S., & Mostafa, S. M. (2022). Handling Missing Values Based on Similarity Classifiers and Fuzzy Entropy Measures. Electronics, 11(23), 3929. https://doi.org/10.3390/electronics11233929