
Vertically Federated Learning with Correlated Differential Privacy

Abstract
:1. Introduction
- We propose a vertically federated learning algorithm with correlated differential privacy. A general vertically federated learning framework is constructed, collecting data from the client and jointly training the global model between organizations. Furthermore, by injecting DP noise into the VFL framework, CRDL-FL achieves local differential privacy and provides a strong privacy guarantee for VFL.
- To balance the utility and privacy of CRDP-FL, a utility optimization strategy is proposed, including feature selection and optimization for vertically federated learning, thereby improving the algorithm’s efficiency and the global model’s performance. A quantitatively correlated analysis method and correlated sensitivity in VFL (CS-VFL) are proposed to reduce additional noise injecting from DP operation due to data correlation.
- We analyze and verify the algorithm from theoretical and practical aspects. The privacy and utility analysis is performed theoretically. Comperhanserve experiments based on the ISOLET and Breast Cancer datasets demonstrate that CRDP-FL is superior to existing methods in model accuracy, privacy budget, and data correlation.
2. Related Works
2.1. Federated Learning and Privacy Concern
2.2. Differential Privacy in Machine Learning
2.3. Correlated Differential Privacy
3. Preliminary
3.1. Vertically Federated Learning
3.2. Differential Privacy
3.3. Correlated Differential Privacy
3.4. Problem Statement
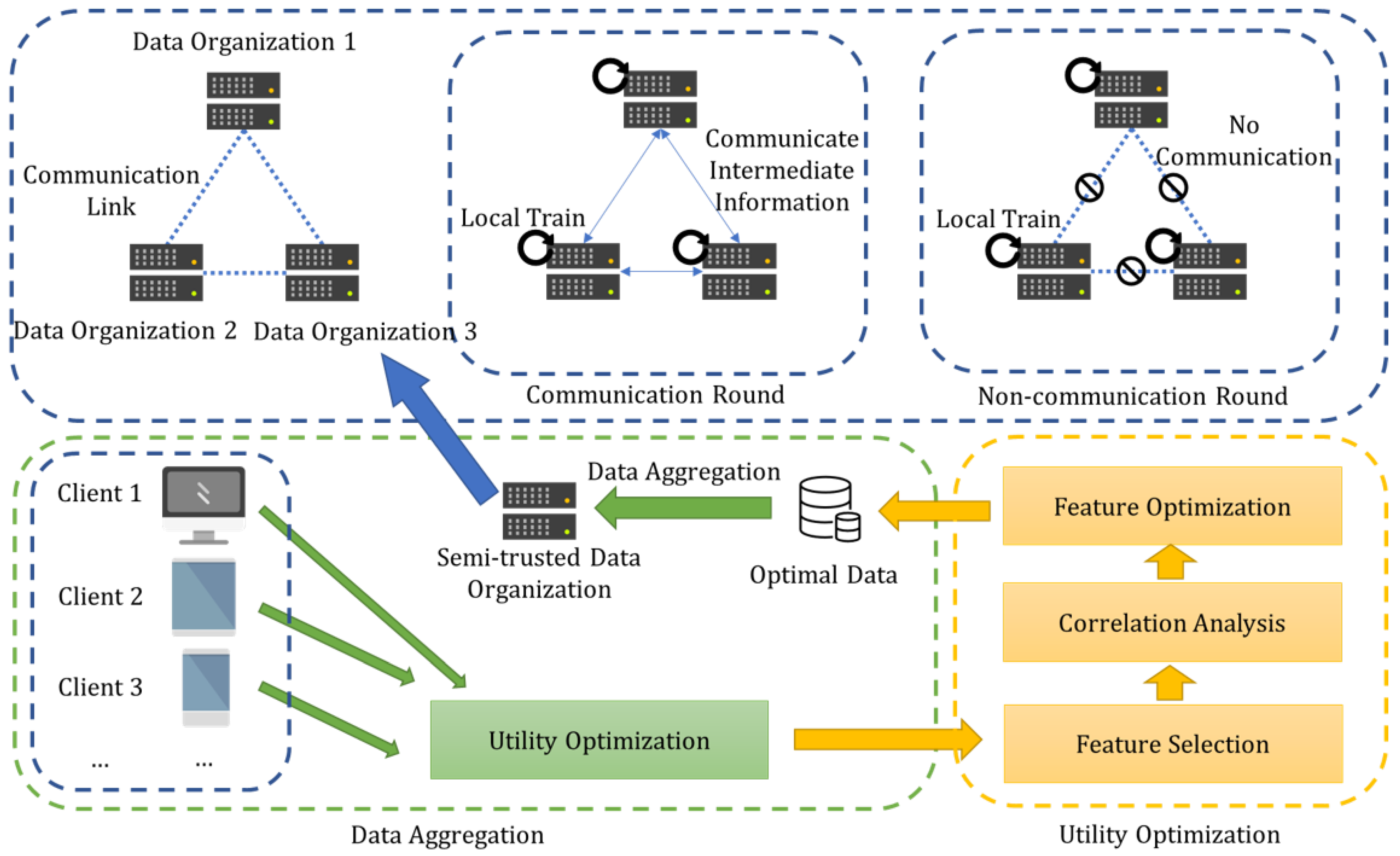
- According to the actual scenarios, there are problems such as network transmission performance differences and insufficient computing power due to network edge devices’ performance differences. Therefore, taking small data nodes (devices) as participants of federated learning significantly impacts global model training, especially for deep learning models with big data volumes. Therefore, different organizations should collect clients’ data, and this method is a feasible utility scheme. Usually, various data organizations, such as large medical service institutions, may collect many downstream units or customer data for model training. Data collected by different organizations are limited in application due to data barriers. So it is necessary to federated train a global model for various organizations. In this paper, we design a two-layer vertically federated learning framework to meet the requirements of federated learning from clients to organizations and between organizations.
- As discussed above, federated learning suffered from privacy issues during training, and differential privacy realizes privacy protection by disturbing the parameters in the training process. Especially in the entirely decentralized federated learning framework, local differential privacy technology further satisfies the privacy protection of third-party untrusted institutions. Therefore, we perform a differential private operation for a decentralized vertically federated learning framework by injecting noise into the information transmission and feature selection process.
- Utility optimization is the most critical for privacy-preserving vertically federated learning. On the one hand, increasing participants in vertically federated learning bring a massive surge in global model dimensions. The vast feature space may cause an increase in computational complexity and cost. Moreover, unrelated features result in the utility decreasing of the global model’s accuracy. Therefore, feature selection is necessary for utility optimization in client data aggregation. On the other hand, introducing differential privacy causes utility decline while protecting privacy. In particular, the data correlation will cause additional utility loss. To address these issues, we propose a correlated differential privacy utility optimization strategy, including feature selection and correlation analysis for VFL. Correlated sensitivity in vertically federated learning, i.e., CS-VFL, is defined to reduce sensitivity to improve the algorithm’s effectiveness.
4. CRDP-FL
4.1. Outline
4.2. Client-Side Data Aggregation
- Feature selection. For selecting the most relevant to the learning task, in CRDP-FL, the stability feature selection is performed. The features are divided into the optimal feature set and the adjusted feature set. We also use Pearson’s correlation coefficient to filter out highly correlated features and move one of the correlated features from the optimal feature set to the adjusted feature set. In the process, DP noise is injected for privacy-preserving.
- Correlation analysis. We proposed correlated sensitivity in VFL to quantitative analysis of the relationship between features and data correlations for performing correlation analysis in VFL. To improve the classic correlated sensitivity, we propose feature-oriented correlation to measure the correlation in VFL and mean correlated degree as the standard of the correlated records.
- Feature optimization. Based on the feature selection results, we generate candidate feature sets from the adjusted feature set. The DP exponential mechanism is used for obtaining the minimum correlated sensitivity with the highest score. Then, we add the features from the best candidate feature solutions to the optimal feature set. The final obtained optimal feature set is relaxed from the initial one since reducing the DP noise is essential for balancing privacy and utility in CRDP-FL.
- Data aggregation. Aggregate data into data organizations based on the final optimal feature set.
| Algorithm 1: DataAggregation |
Input: distributed dataset ; private budget for Pearson’s correlation ; private budget for feature optimization ; important feature threshold ; Pearson’s correlation threshold ; initial ; adjusting coefficient b Output: optimal
|
4.2.1. Feature Selection
| Algorithm 2: FeatureSelection |
 |
4.2.2. CS-VFL
| Algorithm 3: CalculateCorrelationThreshold |
 |
4.2.3. Feature Optimization
| Algorithm 4: FeatureOptimization |
 |
4.3. Differentially Private VFL
- Data aggregation. The bottom layer is client-side data aggregation and has been shown in Section 4.2. Since the data organization is semi-trustworthy to the clients it owns, each client will only send the data that is determined to be the optimal set of features and formed after utility optimization to the data organization. The data organization does not know the feature space of the training data until it gets the optimal dataset resulting from the data aggregation process.
- Model initialization. Each organization forms its local data after data aggregation. Then, the data organization initializes the model parameters according to the feature space of local data. Overall, the data owned by each data organization is feature partitioned. Additionally, in federated learning, no exchange of local data occurs. All data organizations maintain a part of the model, so the value calculated by the local model with the local data is also not the predicted value of the whole model but a part of the predicted value, which is called intermediate information. For a sample to be inferred, only the intermediate information computed by all data organizations is accumulated to be the actual predicted value.
- Intermediate information synchronization. The FedBCD algorithm sets a local training round R to reduce communication costs. When the number of iterations is (e.g., ), information can be passed between data organizations. These rounds are collectively referred to as communication rounds, while other rounds are not available for information transfer. At the beginning of the communication round, each data organization agrees that the next R non-communication rounds are used to update the R-group minibatch, compute the R-group intermediate information and broadcast it, and receive the intermediate information from all other data organizations. These messages are used for the next R rounds of local updates. In addition, since data organizations do not trust each other, differential privacy protection of the intermediate information is required before data organizations broadcast their own intermediate information by perturbing the intermediate information to avoid privacy leakage due to inference attacks.
- Local model updates. Data organizations update the local model according to Equation (14) whether it is an exchange round or not. When performing local updates, the intermediate information from other data organizations is calculated in the most recent synchronization round, except for the latest intermediate information calculated from the part of the model owned by itself. Since the data organization only updates a portion of the parameters belonging to itself by using coordinate descent, it is a biased estimation, which may impact the training accuracy. However, the study by Liu [14] et al. demonstrates that even biased estimates can converge with sufficient training rounds.
| Algorithm 5: CRDP-FL |
 |
5. Utility Analysis
5.1. Privacy Analysis
- In the feature selection process, assuming that D and differ by one data record and is a query about the Pearson’s correlation coefficient between any two features of the proximity database, we have the following equation. . When x, y denote the adjacent dataset variables, respectively, and the random variable , the adjacent dataset probability density ratio is shown as the following equation.Thus, the process satisfies -differential privacy, and the algorithm requires only a small injection of noise since the sensitivity .
- In the feature optimization process, the candidate feature set is selected by the exponential mechanism. For D and , the privacy level is analyzed as follows.For the left-hand side, the first part can be analyzed as follows.By symmetry, the other part can be analyzed as follows.Therefore, the feature optimization process for candidate feature set selection by the exponential mechanism satisfies -differential privacy, where m is the number of . However, it should be noted that the exponential mechanism does not actually add noise and therefore has no effect on the accuracy of the model.
- During the differentially private vertically federated learning, the data organization performs the exchange of intermediate information by adding Laplace noise with a privacy budget of each training round. Similar to feature selection, it holds -differential privacy.
5.2. Correlation Analysis
6. Evaluation
6.1. Experimental Setting
- Datasets. The common datasets in ML are selected for our experiments. We chose these two datasets because they contain enough feature spaces, which will simulate the federated learning scenarios of feature-partitioned distributed data more realistically. We divide vertically according to the feature space in the experiments. ISOLET [56,57] is a word-and-language phonetic recognition dataset that contains the features of the name of each letter of the English alphabet from 150 volunteers. We retained the records, totaling 7797. The audio data in each entry is quantified as 617 additional features, each of which is a numeric type. Because of its ample feature space, it is suitable for this experiment’s dataset. Breast Cancer [58] consists of 570 entries with 30 features, where M represents malignancy and B represents benignity. It is one of the most commonly used datasets in ML. This dataset contains cytological features of Breast Cancer biopsies that can be used to diagnose breast cancer.
- Training Models. Both of our experiment datasets are textual data that belong to the classification task. Furthermore, the ISOLET dataset is more complex than Breast Cancer. Therefore, in the process of FL, the former uses the full connect neural network (DNN) model for training and inference, and the latter uses the logistic regression (LR) model to classify.
- Comparison Algorithms. We verify the validity of CRDP-FL with different comparison algorithms, including training with a single-party dataset (single), non-private vertically federated learning (Non-private FL) [33], non-private vertically FL with feature selection (FS-FL) [33], and federated learning with a correlation analysis of global sensitivity by calculating the number of correlated records (GDP-FL) [59]. Among them, the training with a single-party dataset refers to non-federated learning. FS-FL is the algorithm that adds feature selection based on non-private vertically federated learning.
6.2. Different Parameter Effect on Accuracy
6.2.1. Organization Number VS Accuracy
6.2.2. Feature Selection Threshold
6.3. Accuracy Evaluation
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ML | Machine learning |
| AI | Artificial intelligence |
| FL | Federated learning |
| VFL | Vertically federated learning |
| DP | Differential privacy |
| LDP | Local differential privacy |
| CRDP | Correlated differential privacy |
| CRDP-FL | Correlated differentially private federated learning |
| DP-SGD | Differentially private stochastic gradient descent algorithm |
| FedAvg | Federated averaging |
| FedBCD | Federated stochastic block coordinate descent |
| CS-VFL | Correlated sensitivity in VFL |
| GS | Global Sensitivity |
| CS | Correlated Sensitivity |
References
- Hatcher, W.G.; Yu, W. A survey of deep learning: Platforms, applications and emerging research trends. IEEE Access 2018, 6, 24411–24432. [Google Scholar] [CrossRef]
- Song, Y.; Cai, X.; Zhou, X.; Zhang, B.; Chen, H.; Li, Y.; Deng, W.; Deng, W. Dynamic hybrid mechanism-based differential evolution algorithm and its application. Expert Syst. Appl. 2023, 213, 118834. [Google Scholar] [CrossRef]
- Deng, W.; Zhang, L.; Zhou, X.; Zhou, Y.; Sun, Y.; Zhu, W.; Chen, H.; Deng, W.; Chen, H.; Zhao, H. Multi-strategy particle swarm and ant colony hybrid optimization for airport taxiway planning problem. Inf. Sci. 2022, 612, 576–593. [Google Scholar] [CrossRef]
- Xue, X.; Liu, W. Integrating heterogeneous ontologies in asian languages through compact genetic algorithm with annealing re-sample inheritance mechanism. Trans. Asian Low-Resour. Lang. Inf. Process. 2022. [Google Scholar] [CrossRef]
- Huang, C.; Zhou, X.; Ran, X.; Liu, Y.; Deng, W.; Deng, W. Co-evolutionary competitive swarm optimizer with three-phase for large-scale complex optimization problem. Inf. Sci. 2022, 619, 2–18. [Google Scholar] [CrossRef]
- Piper, D. Data protection laws of the world: Full handbook. DLA Piper 2017, 1, 1–50. [Google Scholar]
- General Data Protection Regulation. GDPR. 2019. Available online: Https://gdpr-info.eu (accessed on 15 May 2022).
- Nasr, M.; Shokri, R.; Houmansadr, A. Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 739–753. [Google Scholar]
- Deng, W.; Xu, J.; Gao, X.; Zhao, H. An Enhanced MSIQDE Algorithm with Novel Multiple Strategies for Global Optimization Problems. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 1578–1587. [Google Scholar] [CrossRef]
- Ramu, S.P.; Boopalan, P.; Pham, Q.V.; Maddikunta, P.K.R.; Huynh-The, T.; Alazab, M.; Nguyen, T.T.; Gadekallu, T.R. Federated learning enabled digital twins for smart cities: Concepts, recent advances, and future directions. Sustain. Cities Soc. 2022, 79, 103663. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated Machine Learning: Concept and Applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Alazab, M.; Priya, R.M.S.; Parimala, M.; Maddikunta, P.K.R.; Gadekallu, T.R.; Pham, Q. Federated Learning for Cybersecurity: Concepts, Challenges, and Future Directions. IEEE Trans. Ind. Inform. 2022, 18, 3501–3509. [Google Scholar] [CrossRef]
- Yang, S.; Ren, B.; Zhou, X.; Liu, L. Parallel distributed logistic regression for vertical federated learning without third-party coordinator. arXiv 2019, arXiv:1911.09824. [Google Scholar]
- Liu, Y.; Kang, Y.; Zhang, X.; Li, L.; Cheng, Y.; Chen, T.; Hong, M.; Yang, Q. A communication efficient collaborative learning framework for distributed features. arXiv 2019, arXiv:1912.11187. [Google Scholar] [CrossRef]
- Asad, M.; Moustafa, A.; Yu, C. A Critical Evaluation of Privacy and Security Threats in Federated Learning. Sensors 2020, 20, 7182. [Google Scholar] [CrossRef] [PubMed]
- Aono, Y.; Hayashi, T.; Wang, L.; Moriai, S.; Phong, L.T. Privacy-preserving deep learning via additively homomorphic encryption. IEEE Trans. Inf. Forensics Secur. 2017, 13, 1333–1345. [Google Scholar]
- Yuan, J.; Yu, S. Privacy preserving back-propagation neural network learning made practical with cloud computing. IEEE Trans. Parallel Distrib. Syst. 2013, 25, 212–221. [Google Scholar] [CrossRef]
- Riazi, M.S.; Weinert, C.; Tkachenko, O.; Songhori, E.M.; Schneider, T.; Koushanfar, F. Chameleon: A hybrid secure computation framework for machine learning applications. In Proceedings of the 2018 on Asia Conference on Computer and Communications Security, Incheon, Republic of Korea, 4–8 June 2018; pp. 707–721. [Google Scholar]
- Ouadrhiri, A.E.; Abdelhadi, A. Differential Privacy for Deep and Federated Learning: A Survey. IEEE Access 2022, 10, 22359–22380. [Google Scholar] [CrossRef]
- Cao, T.; Huu, T.T.; Tran, H.; Tran, K. A federated deep learning framework for privacy preservation and communication efficiency. J. Syst. Archit. 2022, 124, 102413. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, X.; Feng, J.; Yang, X. A Comprehensive Survey on Local Differential Privacy toward Data Statistics and Analysis. Sensors 2020, 20, 7030. [Google Scholar] [CrossRef] [PubMed]
- Xiao, Y.; Xiong, L. Protecting locations with differential privacy under temporal correlations. In Proceedings of the Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1298–1309. [Google Scholar]
- Lv, D.; Zhu, S. Achieving correlated differential privacy of big data publication. Comput. Secur. 2019, 82, 184–195. [Google Scholar] [CrossRef]
- Chen, R.; Fung, B.; Yu, P.S.; Desai, B.C. Correlated network data publication via differential privacy. VLDB J. 2014, 23, 653–676. [Google Scholar] [CrossRef]
- Zhu, T.; Xiong, P.; Li, G.; Zhou, W. Correlated differential privacy: Hiding information in non-IID data set. IEEE Trans. Inf. Forensics Secur. 2014, 10, 229–242. [Google Scholar]
- Yang, B.; Sato, I.; Nakagawa, H. Bayesian differential privacy on correlated data. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, Melbourne, VIC, Australia, 31 May–4 June 2015; pp. 747–762. [Google Scholar]
- Lian, X.; Zhang, C.; Zhang, H.; Hsieh, C.J.; Zhang, W.; Liu, J. Can decentralized algorithms outperform centralized algorithms? A case study for decentralized parallel stochastic gradient descent. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Muñoz-González, L.; Co, K.T.; Lupu, E.C. Byzantine-robust federated machine learning through adaptive model averaging. arXiv 2019, arXiv:1909.05125. [Google Scholar]
- Jiang, Z.; Balu, A.; Hegde, C.; Sarkar, S. Collaborative deep learning in fixed topology networks. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Daily, J.; Vishnu, A.; Siegel, C.; Warfel, T.; Amatya, V. Gossipgrad: Scalable deep learning using gossip communication based asynchronous gradient descent. arXiv 2018, arXiv:1803.05880. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics. PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- McMahan, H.B.; Moore, E.; Ramage, D.; y Arcas, B.A. Federated learning of deep networks using model averaging. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- Das, A.; Patterson, S. Multi-tier federated learning for vertically partitioned data. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 3100–3104. [Google Scholar]
- Chaudhuri, K.; Monteleoni, C. Privacy-Preserving Logistic Regression. Available online: https://proceedings.neurips.cc/paper/2008/file/8065d07da4a77621450aa84fee5656d9-Paper.pdf (accessed on 15 May 2022).
- Mangasarian, O.L.; Wild, E.W.; Fung, G.M. Privacy-preserving classification of vertically partitioned data via random kernels. ACM Trans. Knowl. Discov. Data (TKDD) 2008, 2, 1–16. [Google Scholar] [CrossRef]
- Song, S.; Chaudhuri, K.; Sarwate, A.D. Stochastic gradient descent with differentially private updates. In Proceedings of the 2013 IEEE Global Conference on Signal and Information Processing, Austin, TX, USA, 3–5 December 2013; pp. 245–248. [Google Scholar]
- Truex, S.; Liu, L.; Chow, K.H.; Gursoy, M.E.; Wei, W. LDP-Fed: Federated learning with local differential privacy. In Proceedings of the Third ACM International Workshop on Edge Systems, Analytics and Networking, Heraklion, Greece, 27 April 2020. [Google Scholar] [CrossRef]
- Li, J.; Khodak, M.; Caldas, S.; Talwalkar, A. Differentially private meta-learning. arXiv 2019, arXiv:1909.05830. [Google Scholar]
- Wang, Y.; Tong, Y.; Shi, D. Federated latent Dirichlet allocation: A local differential privacy based framework. In Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 6283–6290. [Google Scholar]
- Kifer, D.; Machanavajjhala, A. No free lunch in data privacy. In Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data, Athens, Greece, 12–16 June 2011; pp. 193–204. [Google Scholar]
- He, X.; Machanavajjhala, A.; Ding, B. Blowfish privacy: Tuning privacy-utility trade-offs using policies. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014; pp. 1447–1458. [Google Scholar]
- Zhang, T.; Zhu, T.; Xiong, P.; Huo, H.; Tari, Z.; Zhou, W. Correlated differential privacy: Feature selection in machine learning. IEEE Trans. Ind. Inform. 2019, 16, 2115–2124. [Google Scholar] [CrossRef]
- Zhu, T.; Li, G.; Xiong, P.; Zhou, W. Answering differentially private queries for continual datasets release. Future Gener. Comput. Syst. 2018, 87, 816–827. [Google Scholar] [CrossRef]
- Chen, J.; Ma, H.; Zhao, D.; Liu, L. Correlated differential privacy protection for mobile crowdsensing. IEEE Trans. Big Data 2017, 7, 784–795. [Google Scholar] [CrossRef]
- Cao, Y.; Yoshikawa, M.; Xiao, Y.; Xiong, L. Quantifying differential privacy in continuous data release under temporal correlations. IEEE Trans. Knowl. Data Eng. 2018, 31, 1281–1295. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Song, S.; Wang, Y.; Chaudhuri, K. Pufferfish privacy mechanisms for correlated data. In Proceedings of the 2017 ACM International Conference on Management of Data, Chicago, IL, USA, 14–19 May 2017; pp. 1291–1306. [Google Scholar]
- Wang, H.; Wang, H. Correlated tuple data release via differential privacy. Inf. Sci. 2021, 560, 347–369. [Google Scholar] [CrossRef]
- Wang, H.; Xu, Z.; Jia, S.; Xia, Y.; Zhang, X. Why current differential privacy schemes are inapplicable for correlated data publishing? World Wide Web 2021, 24, 1–23. [Google Scholar] [CrossRef]
- Ou, L.; Qin, Z.; Liao, S.; Hong, Y.; Jia, X. Releasing correlated trajectories: Towards high utility and optimal differential privacy. IEEE Trans. Dependable Secur. Comput. 2018, 17, 1109–1123. [Google Scholar] [CrossRef]
- Tang, P.; Chen, R.; Su, S.; Guo, S.; Ju, L.; Liu, G. Differentially Private Publication of Multi-Party Sequential Data. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; pp. 145–156. [Google Scholar]
- Wu, X.; Dou, W.; Ni, Q. Game theory based privacy preserving analysis in correlated data publication. In Proceedings of the Australasian Computer Science Week Multiconference, Geelong, Australia, 31 January–3 February 2017; pp. 1–10. [Google Scholar]
- Zhao, J.Z.; Wang, X.W.; Mao, K.M.; Huang, C.X.; Su, Y.K.; Li, Y.C. Correlated Differential Privacy of Multiparty Data Release in Machine Learning. J. Comput. Sci. Technol. 2022, 37, 231–251. [Google Scholar] [CrossRef]
- Dwork, C. Differential Privacy: A Survey of Results. In Theory and Applications of Models of Computation. TAMC 2008; Agrawal, M., Du, D., Duan, Z., Li, A., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2021; Volume 4978. [Google Scholar] [CrossRef]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Proceedings of the Theory of Cryptography Conference; Springer: Berlin/Heidelberg, Germany, 2006; pp. 265–284. [Google Scholar]
- McSherry, F.; Talwar, K. Mechanism design via differential privacy. In Proceedings of the 48th Annual IEEE Symposium on Foundations of Computer Science (FOCS’07), Providence, RI, USA, 21–23 October 2007; pp. 94–103. [Google Scholar]
- Fanty, M.; Cole, R. Spoken letter recognition. Adv. Neural Inf. Process. Syst. 1990, 3. [Google Scholar] [CrossRef]
- Dietterich, T.G.; Bakiri, G. Solving multiclass learning problems via error-correcting output codes. J. Artif. Intell. Res. 1994, 2, 263–286. [Google Scholar] [CrossRef] [Green Version]
- Dietterich, T.G.; Bakiri, G. Error-correcting output codes: A general method for improving multiclass inductive learning programs. In Proceedings of the AAAI. Citeseer, Anaheim, CA, USA, 14–19 July 1991; pp. 572–577. [Google Scholar]
- Xu, R.; Baracaldo, N.; Zhou, Y.; Anwar, A.; Joshi, J.; Ludwig, H. FedV: Privacy-Preserving Federated Learning over Vertically Partitioned Data. In Proceedings of the AISec@CCS 2021: Proceedings of the 14th ACM Workshop on Artificial Intelligence and Security, Virtual Event, Republic of Korea, 15 November 2021; Carlini, N., Demontis, A., Chen, Y., Eds.; ACM: New York, NY, USA, 2021; pp. 181–192. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Symbols | ISOLET | Breast Cancer |
|---|---|---|---|
| Epoch | - | 2000 | 500 |
| Local Training Epoch | R | 10 | 10 |
| Size of Minibatch | - | 256 | 256 |
| Learning Rate | 0.01 | 0.001 | |
| Number of Organizations | N | 1/4/10–150 | 1/3/5/7/9/11/13/15 |
| Feature Selection Threshold | 0.2/0.4/0.6/0.8 | 0.3/0.5/0.7 | |
| Linear Threshold | 0.9 | 0.9 | |
| Feature Selection Privacy Budget | 1 | 1 | |
| Feature Optimization Privacy Budget | 1 | 1 | |
| Communication Privacy Budget | 0.2/0.4/0.6/0.8/1 | 0.2/0.4/0.6/0.8/1 | |
| Initial Sensitivity Threshold | 0.4 | 0.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, J.; Wang, J.; Li, Z.; Yuan, W.; Matwin, S. Vertically Federated Learning with Correlated Differential Privacy. Electronics 2022, 11, 3958. https://doi.org/10.3390/electronics11233958
Zhao J, Wang J, Li Z, Yuan W, Matwin S. Vertically Federated Learning with Correlated Differential Privacy. Electronics. 2022; 11(23):3958. https://doi.org/10.3390/electronics11233958
Chicago/Turabian StyleZhao, Jianzhe, Jiayi Wang, Zhaocheng Li, Weiting Yuan, and Stan Matwin. 2022. "Vertically Federated Learning with Correlated Differential Privacy" Electronics 11, no. 23: 3958. https://doi.org/10.3390/electronics11233958