
Research on Deep Compression Method of Expressway Video Based on Content Value

Abstract
:1. Introduction
2. Deep Compression Method Based on Content Value
2.1. YOLOv4 Target Detection Algorithm
2.2. Fast Algorithm of Intra Prediction CU Partition Based on CNN
2.2.1. Overview
2.2.2. Algorithm Model
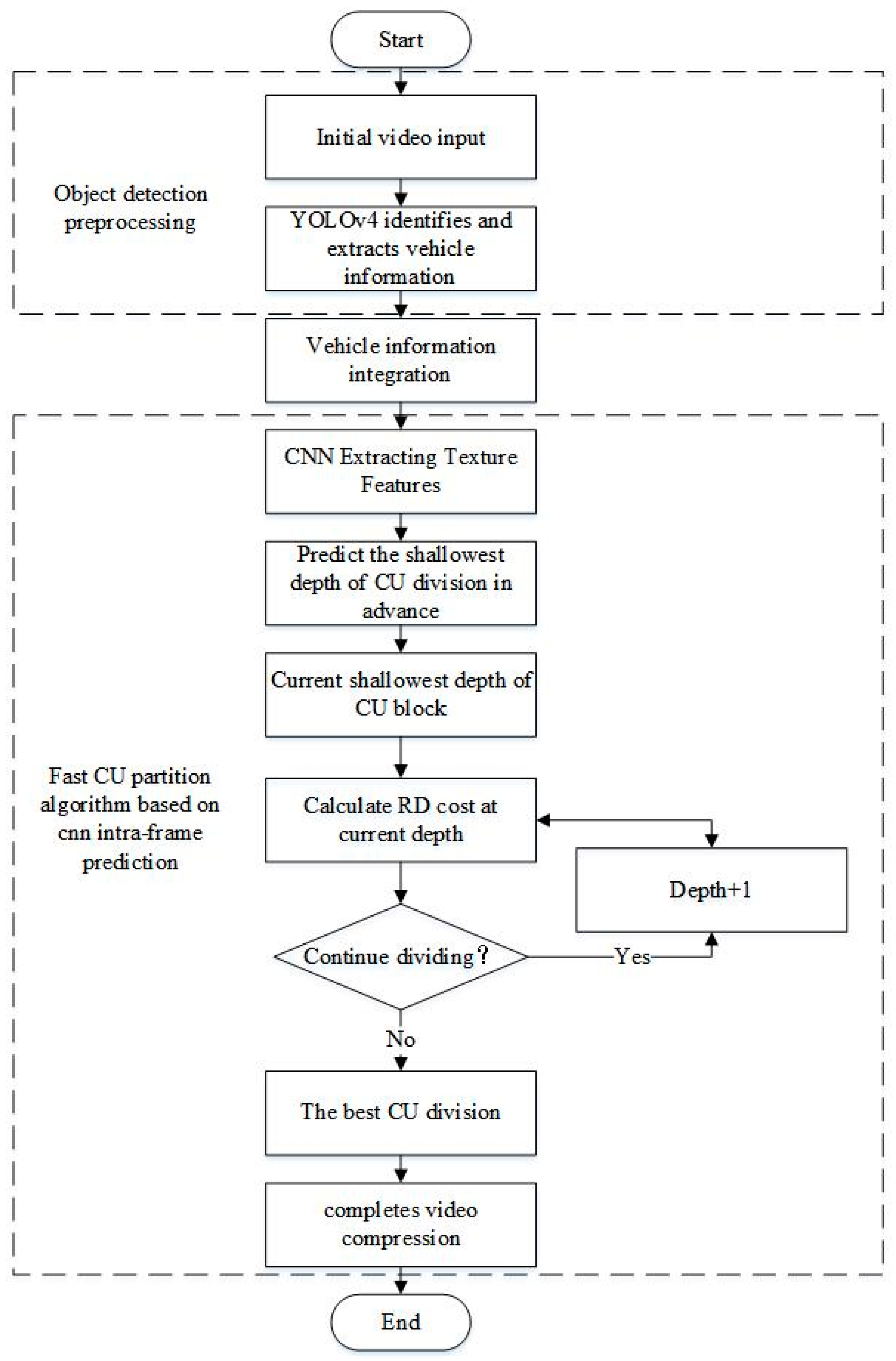
2.2.3. Algorithm Flow Chart
3. Experimental Results and Analysis
3.1. Performance Experiment of Frame Predicting CU Fast Partition Algorithm Based on CNN
3.2. Video Compression Efficiency Experiment Based on YOLOv4
3.3. Video Depth Compression Experiment Based on Content Value
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Qingchun, Y. Analysis and Evaluation of Expressway Intelligent Video Monitoring System. Master’s Thesis, Suzhou University, Suzhou, China, November 2014. [Google Scholar]
- Hua, Y.; Liu, W. Generalized Karhunen-Loeve transform. IEEE Signal Process. Lett. 1998, 5, 141–142. [Google Scholar]
- Bowei, Y. An End-to-End Video Coding Method Based on Convolutional Neural Network. Master’s Thesis, Hebei Normal University, Shijiazhuang, China, May 2022. [Google Scholar]
- Hong, R. Research on Scalable Coding in Video Compression Coding. Presented at the Western China Youth Communication Academic Conference, Chengdu, China, 1 December 2008; pp. 341–345. [Google Scholar]
- Xia, S.; Yang, W.; Hu, Y.; Liu, J. Deep inter prediction via pixel-wise motion oriented reference generation. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1710–1774. [Google Scholar]
- Huo, S.; Liu, D.; Wu, F.; Li, H. Convolutional neural network-based motion compensation refinement for video coding. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; pp. 1–4. [Google Scholar]
- Chen, M.; Goodall, T.R.; Patney, A.; Bovik, A.C. Learningto compress videos without computing motion. arXiv 2020, arXiv:2009.14110. [Google Scholar]
- Wu, C.Y.; Singhal, N.; Krhenbühl, P. Video compression through image interpolation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Lu, G.; Ouyang, W.; Xu, D.; Zhang, X.; Cai, C.; Gao, Z. Dvc: An end-to-end deep video compression framework. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11006–11015. [Google Scholar]
- Djelouah, A.; Campos, J.; Schaub-Meyer, S.; Schroers, C. Neural inter-frame compression for video coding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6421–6429. [Google Scholar]
- Cui, W.; Zhang, T.; Zhang, S.; Jiang, F.; Zuo, W.; Wan, Z.; Zhao, D. Convolutional neural networks based intra prediction for HEVC. In Proceedings of the 2017 Data Compression Conference (DCC), Snowbird, UT, USA, 4–7 April 2017. [Google Scholar]
- Jin, Z.; An, P.; Shen, L. Video intra prediction using convolutional encoder decoder network. Neurocomputing 2020, 394, 168–177. [Google Scholar] [CrossRef]
- Agustsson, E.; Mentzer, F.; Tschannen, M.; Cavigelli, L.; Tim-ofte, R.; Benini, L.; van Gool, L. Soft-to-hard vector quantization for end-to-end learning compressible representations. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers: Burlington, MA, USA, 2017; Volume 30. [Google Scholar]
- Balle, J.; Minnen, D.; Singh, S.; Hwang, S.J.; Johnston, N. Variational image compression with a scale hyperprior. arXiv 2018, arXiv:1802.01436. [Google Scholar]
- Mu, L.; Zuo, W.; Gu, S.; Zhao, D.; Zhang, D. Learning convolutional networks for content-weighted image compression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3214–3223. [Google Scholar]
- Toderici, G.; O’Malley, S.M.; Hwang, S.J.; Vincent, D.; Minnen, D.; Baluja, S.; Covell, M.; Sukthankar, R. Variable rate image compression with recurrent neural networks. arXiv 2015, arXiv:1511.06085. [Google Scholar]
- Kumar, V.; Govindaraju, H.; Quaid, M.; Eapen, J. Fast intra mode decision based on block orientation in high efficiency video codec (HEVC). In Proceedings of the 2014 International Symposium on Computer, Consumer and Control, Taichung, Taiwan, 10–12 January 2014; pp. 506–511. [Google Scholar]
- Zhang, T.; Sun, M.-T.; Zhao, D.; Gao, W. Fast Intra-Mode and CU Size Decision for HEVC. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 1714–1726. [Google Scholar] [CrossRef]
- Liu, Z.; Yu, X.; Gao, Y.; Chen, S.; Ji, X.; Wang, D. CU Partition Mode Decision for HEVC Hardwired Intra Encoder Using Convolution Neural Network. IEEE Trans. Image Process. 2016, 25, 5088–5103. [Google Scholar] [CrossRef] [PubMed]
- Lim, L.K.; Lee, J.; Kim, S.; Lee, S. Fast PU Skip and Split Termination Algorithm for HEVC Intra Prediction. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1335–1346. [Google Scholar] [CrossRef]
- Lv, X.; Yu, H.; Zhou, Y.; Liang, L.; Zhang, T.; Wu, J.; Zhang, S. Video data compression method for marine fishery production management based on content value. Ocean Inf. 2020, 35, 58–64. [Google Scholar] [CrossRef]
- Yi, H. Research on Vehicle Detection in Complex Scenes with Improved YOLOv4 Algorithm. Master’s Thesis, Fuyang Normal University, Fuyang, China, June 2022. [Google Scholar]
- Chen, Y.; Wang, Y.; Zhang, Y.; Guo, Y. PANet: A Context Based Predicate Association Network for Scene Graph Generation. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019. [Google Scholar]
- Shaoming, L.; Jun, C.; Lu, L.; Xuji, T. Scale estimation based on IOU and center point distance prediction in target tracking. Autom. Equip. 2021, 1–14. [Google Scholar] [CrossRef]
- Zeqi, F. Research on HEVC Based Coding Technology with Low Complexity and Strong Network Adaptability. Master’s Thesis, Beijing University of Technology, Beijing, China, May 2019. [Google Scholar]
- Jun, M. Design and Implementation of Full HD Video Compression, Storage and Forwarding System. Master’s Thesis, Central North University, Taiyuan, China, June 2021. [Google Scholar]
- Yuansong, L. Research on Fast Algorithm of Video Coding. Master’s Thesis, Guangdong University of Technology, Guangzhou, China, May 2022. [Google Scholar]
- Yue, L. Research on Intra Prediction Coding Technology Based on Deep Learning. Ph.D. Thesis, University of Science and Technology of China, Hefei, China, May 2019. [Google Scholar]
- Xuan, D. Research on Video Coding and Decoding Technology Based on Deep Learning. Master’s Thesis, University of Electronic Science and Technology of China, Chengdu, China, March 2020. [Google Scholar]
- Huanchen, Z. Research on Fast Intra frame Algorithm of Video Coding Standard H.266/VVC. Master’s Thesis, Huazhong University of Science and Technology, Wuhan, China, May 2021. [Google Scholar]
- Wei, Y. Research on Automatic Extraction Algorithm of Texture Samples Based on Depth Learning. Master’s Thesis, Shenzhen University, Shenzhen, China, May 2020. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Encoding Configuration | |
|---|---|
| GOP Size | 1 |
| QPs | 22, 27, 32, 37 |
| Max CU Size | 64 × 64 |
| Min CU Size | 8 × 8 |
| Max Partition Depth | 3 |
| Min Partition Depth | 0 |
| Sequence | Frame Number | CTU Number per Frame | Total CTU Number per Sequence |
|---|---|---|---|
| PeopleOnStreet, Traffic | 1 | 1000 | 1000 |
| BQTerrace, Cactus | 1, 2 | 480 | 960 |
| RaceHorses, BQMall | 1–10 | 91 | 910 |
| BasketballPass, RaceHorses | 1–50 | 18 | 900 |
| FourPeople | 1–5 | 220 | 1100 |
| Class | Resolution | Sequence | Frame Rate |
|---|---|---|---|
| A | 2560 × 1600 | PeopleOnStreet, Traffic | 30/30 fps |
| B | 1920 × 1080 | BQTerrace, Cactus | 50/50 fps |
| C | 832 × 480 | RaceHorses, BQMall | 50/50 fps |
| D | 416 × 240 | BasketballPass, RaceHorses | 30/50 fps |
| E | 1280 × 720 | FourPeople | 60 fps |
| Class | Sequence | BD-BR /% | BD-PSNR /dB | QP = 22 | QP = 27 | QP = 32 | QP = 37 | ΔTime% |
|---|---|---|---|---|---|---|---|---|
| A | PeopleOnStreet | 6.45 | −0.07 | −61.43 | −60.13 | −61.96 | −61.21 | −61.20 |
| Traffic | 7.04 | −0.10 | −59.98 | −62.12 | −62.44 | −61.79 | −61.60 | |
| B | BQTerrace | 5.23 | −0.30 | −61.42 | −61.45 | −62.43 | −61.22 | −61.63 |
| Cactus | 6.87 | −0.46 | −61.76 | −62.12 | −60.23 | −61.70 | −61.50 | |
| C | RaceHorses | 4.67 | −0.09 | −64.32 | −59.23 | −60.30 | −60.42 | −61.06 |
| BQMall | 5.87 | −0.21 | −60.12 | −60.99 | −60.21 | −60.69 | −60.49 | |
| D | RaceHorses | 4.12 | −0.15 | −56.23 | −55.98 | −56.78 | −55.69 | −56.17 |
| BasketballPass | 6.09 | −0.19 | −56.56 | −56.61 | −57.45 | −56.95 | −56.90 | |
| E | FourPeople | 7.34 | −0.14 | −67.34 | −66.88 | −66.23 | −66.98 | −66.85 |
| Average | 5.96 | −0.19 | −61.01 | −60.61 | −60.89 | −60.73 | −60.82 | |
| Initial Video /G | YOLOv4 Pretreatment | FLV Code | MPEG Code | Compressed Video Size/G | Compression Ratio |
|---|---|---|---|---|---|
| 54.23 | NO | YES | NO | 40.78 | 23% |
| 54.23 | NO | NO | YES | 36.45 | 33% |
| 54.23 | YES | YES | NO | 35.86 | 34% |
| 54.23 | YES | NO | YES | 26.74 | 50% |
| Algorithm | BD-BR /% | BD-PSNR /dB | ΔTime /% | Content Retention Ratio | Compression Ratio |
|---|---|---|---|---|---|
| VVC | 0.99 | −0.12 | −26.56 | 1 | 35% |
| IPCNN | 7.78 | −0.36 | −57.73 | 1 | 59% |
| IPCED | 1.21 | −0.05 | −32.54 | 1 | 43% |
| Proposed | 5.96 | −0.19 | −62.82 | 0.98 | 64% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, Y.; Lu, J.; Zhu, L.; Deng, F. Research on Deep Compression Method of Expressway Video Based on Content Value. Electronics 2022, 11, 4024. https://doi.org/10.3390/electronics11234024
Shen Y, Lu J, Zhu L, Deng F. Research on Deep Compression Method of Expressway Video Based on Content Value. Electronics. 2022; 11(23):4024. https://doi.org/10.3390/electronics11234024
Chicago/Turabian StyleShen, Yang, Jinqin Lu, Li Zhu, and Fangming Deng. 2022. "Research on Deep Compression Method of Expressway Video Based on Content Value" Electronics 11, no. 23: 4024. https://doi.org/10.3390/electronics11234024
APA StyleShen, Y., Lu, J., Zhu, L., & Deng, F. (2022). Research on Deep Compression Method of Expressway Video Based on Content Value. Electronics, 11(23), 4024. https://doi.org/10.3390/electronics11234024