

Comparing the Robustness of Humans and Deep Neural Networks on Facial Expression Recognition
 , , and
, , and
Abstract
:1. Introduction
- We introduce Distorted-FER (DisFER), a new facial expression recognition (FER) dataset composed of a wide number of distorted images of faces. Note that our dataset will further be publicly released for the community (it will soon be made publicly available at: ftp://ftp.ivc.polytech.univ-nantes.fr/LS2N_IPI_DisFER, last accessed on 30 October 2022).
- We present a large-scale online experiment conducted on a crowdsourcing platform to assess human performance on a FER task on our dataset.
- We compare the human performance to that of pre-trained and fine-tuned open-source deep neural networks.
- Finally, based on the results obtained, we raise a discussion on how to define labels and on the very definition of what is a facial expression ground truth.
2. Related Works
3. Materials and Methods
3.1. Dataset
3.2. Crowdsourcing Experiment
3.3. Deep Neural Networks
4. Results
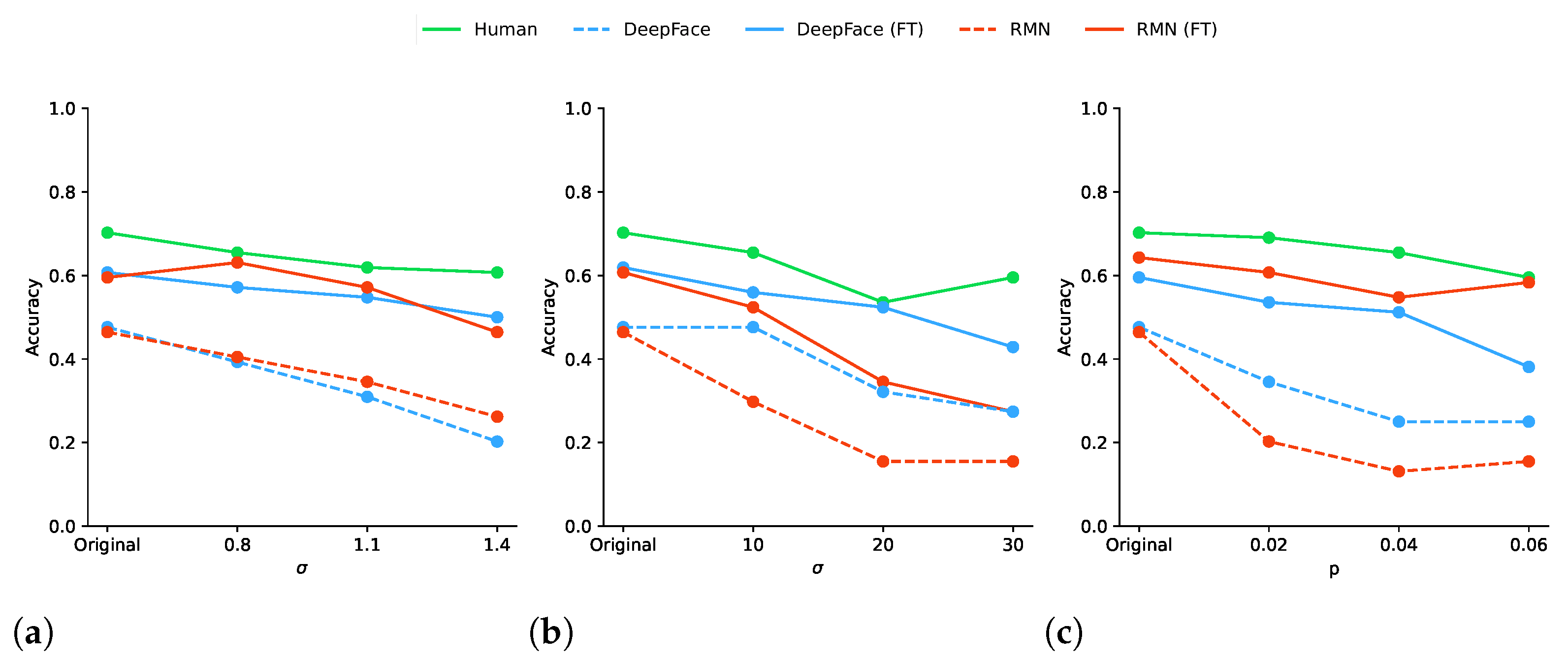
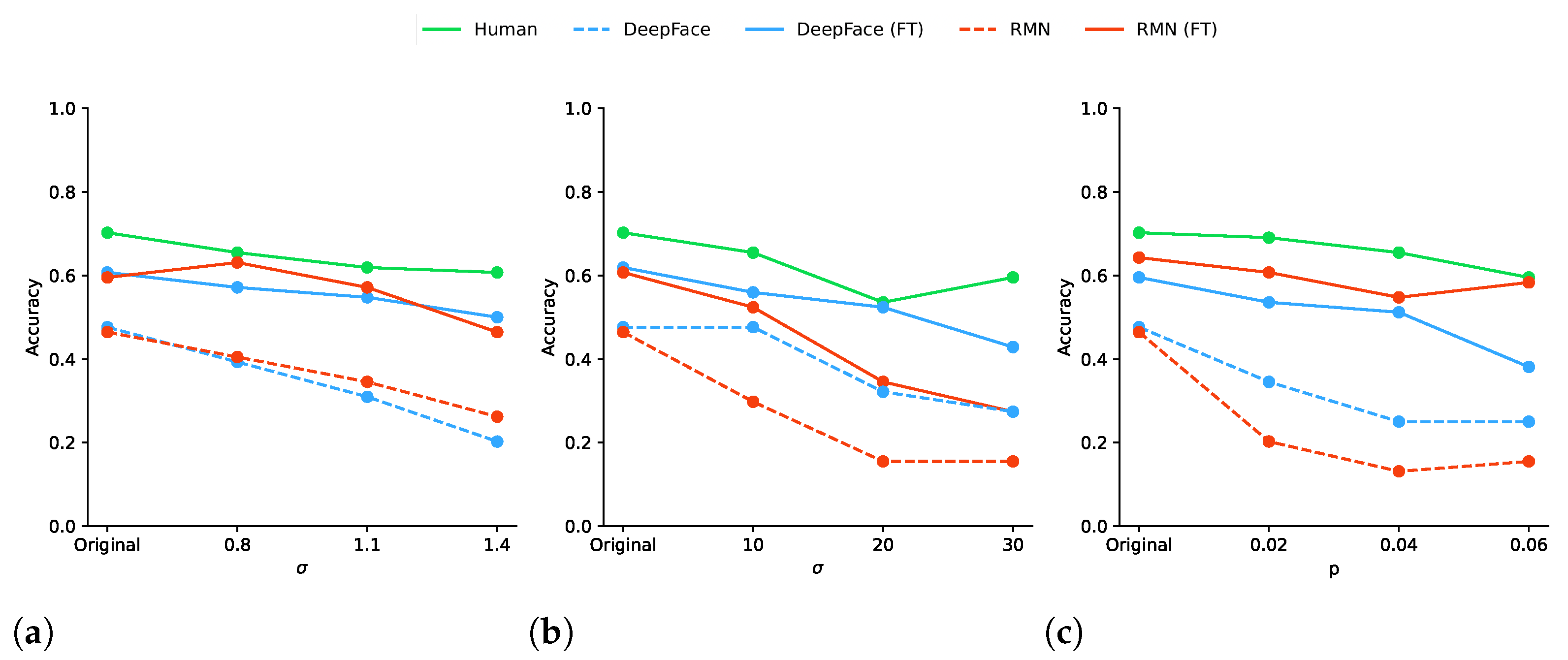
4.1. Overall Accuracy
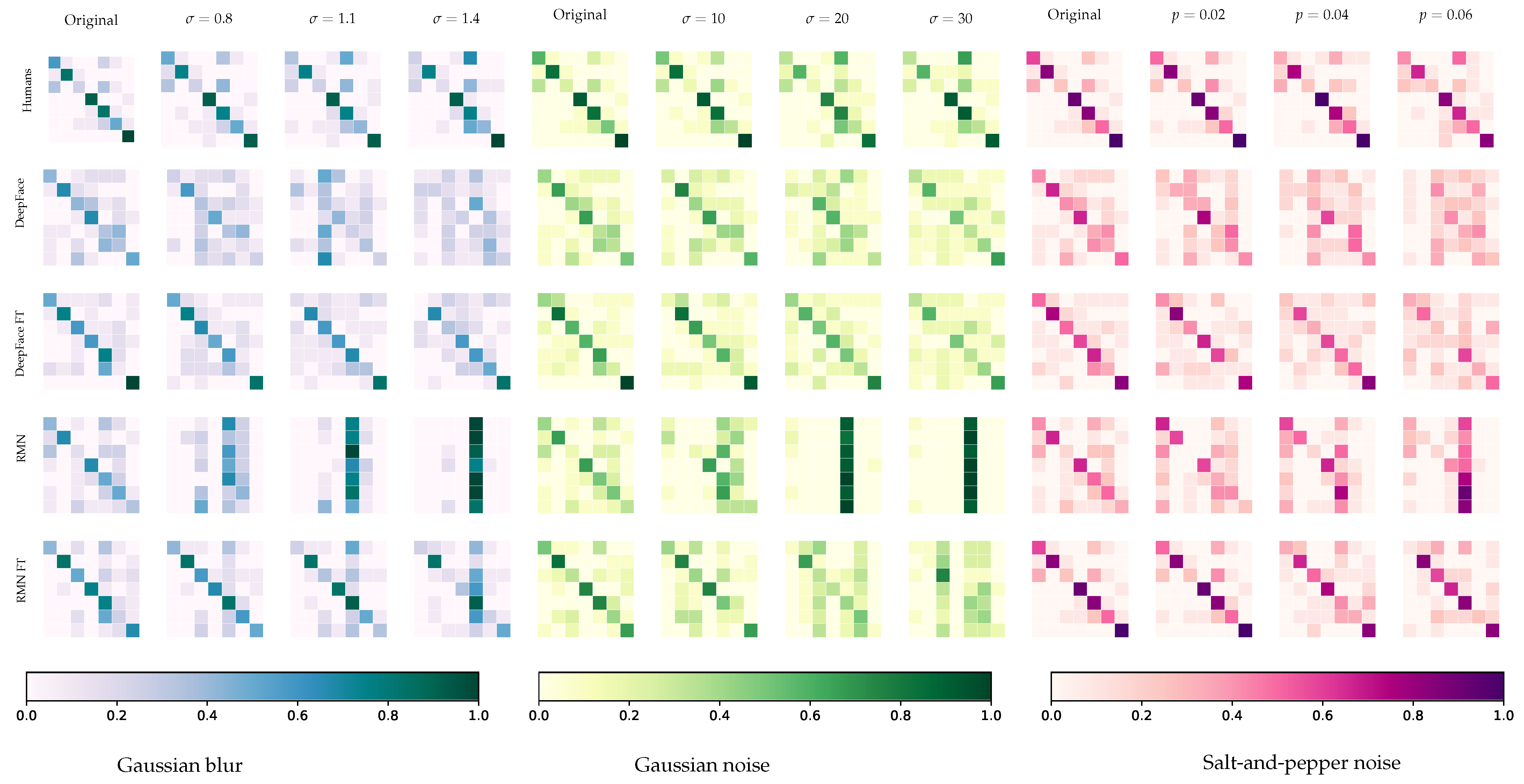
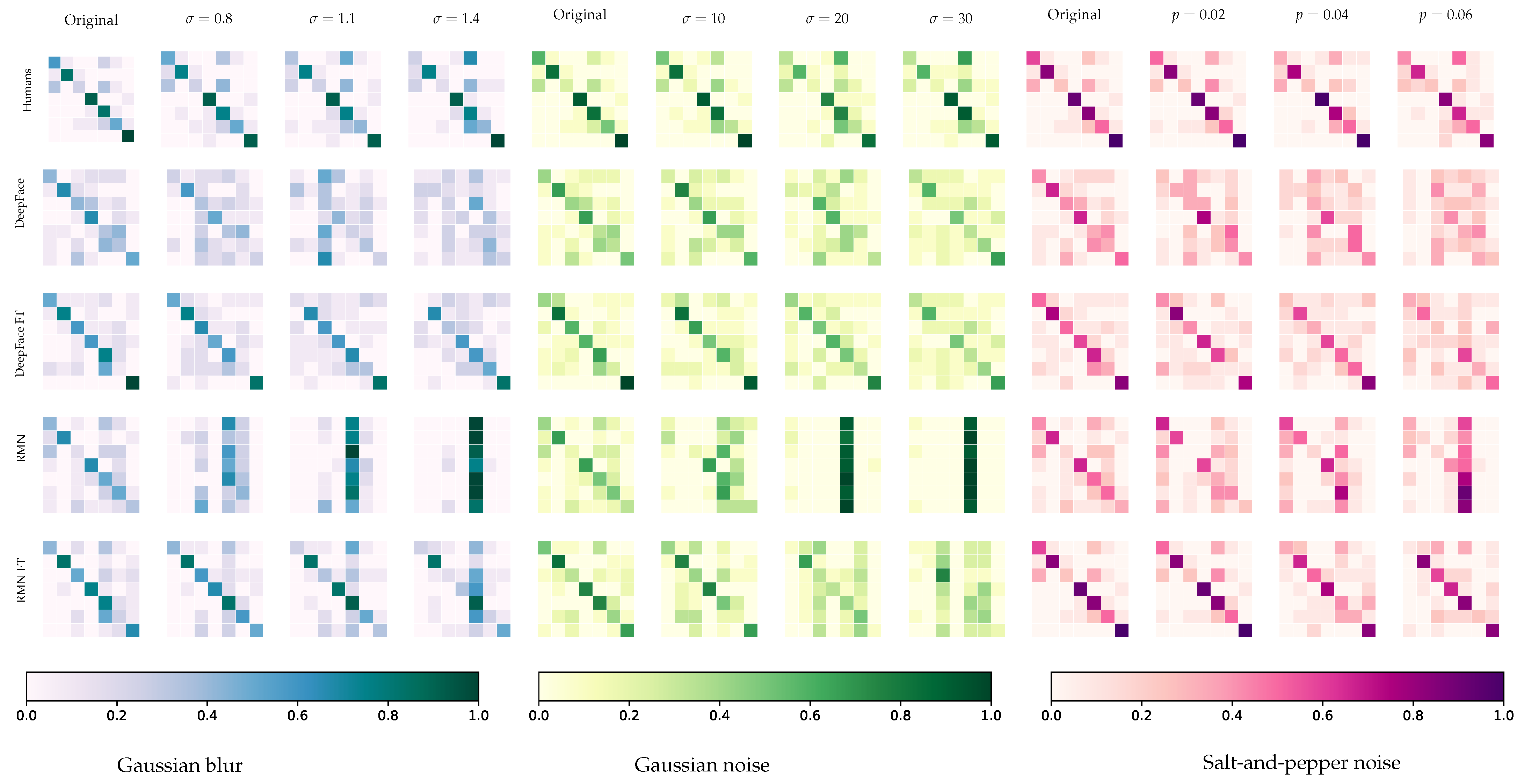
4.2. Confusion Matrices
4.3. Correlation between Errors
5. Discussion
5.1. On Obtained Results
5.2. On Original Labels
5.3. On a New Ground Truth Definition
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| DNN | Deep Neural Network |
| FER | Facial Expression Recognition |
| FT | Fine-Tuned |
| GB | Gaussian Blur |
| GN | Gaussian Noise |
| RMN | Residual Masking Network |
| SP | Salt-And-Pepper |
References
- Keltner, D.; Tracy, J.; Sauter, D.A.; Cordaro, D.C.; McNeil, G. Expression of emotion. Handb. Emot. 2016, 4, 467–482. [Google Scholar]
- Picard, R.W. Affective Computing; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Calvo, R.A.; D’Mello, S. Affect detection: An interdisciplinary review of models, methods, and their applications. IEEE Trans. Affect. Comput. 2010, 1, 18–37. [Google Scholar] [CrossRef]
- Wang, W.; Xu, K.; Niu, H.; Miao, X. Emotion recognition of students based on facial expressions in online education based on the perspective of computer simulation. Complexity 2020, 2020. Available online: https://pesquisa.bvsalud.org/global-literature-on-novel-coronavirus-2019-ncov/resource/fr/covidwho-852761 (accessed on 1 November 2022). [CrossRef]
- Simcock, G.; McLoughlin, L.T.; De Regt, T.; Broadhouse, K.M.; Beaudequin, D.; Lagopoulos, J.; Hermens, D.F. Associations between facial emotion recognition and mental health in early adolescence. Int. J. Environ. Res. Public Health 2020, 17, 330. [Google Scholar] [CrossRef] [Green Version]
- Mehrabian, A. Some referents and measures of nonverbal behavior. Behav. Res. Methods Instrum. 1968, 1, 203–207. [Google Scholar] [CrossRef] [Green Version]
- Borji, A.; Itti, L. Human vs. Computer in Scene and Object Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 113–120. [Google Scholar] [CrossRef]
- Dodge, S.; Karam, L. A study and comparison of human and deep learning recognition performance under visual distortions. In Proceedings of the 26th IEEE International Conference on Computer Communication and Networks (ICCCN), Vancouver, BC, Canada, 31 July–3 August 2017; pp. 1–7. [Google Scholar]
- Yang, K.; Wang, C.; Sarsenbayeva, Z.; Tag, B.; Dingler, T.; Wadley, G.; Goncalves, J. Benchmarking commercial emotion detection systems using realistic distortions of facial image datasets. Vsisual Comput. 2021, 37, 1447–1466. [Google Scholar] [CrossRef]
- Abate, A.F.; Cimmino, L.; Mocanu, B.C.; Narducci, F.; Pop, F. The limitations for expression recognition in computer vision introduced by facial masks. Multimed. Tools Appl. 2022, 1–15. [Google Scholar] [CrossRef]
- Poux, D.; Allaert, B.; Ihaddadene, N.; Bilasco, I.M.; Djeraba, C.; Bennamoun, M. Dynamic facial expression recognition under partial occlusion with optical flow reconstruction. IEEE Trans. Image Process. 2021, 31, 446–457. [Google Scholar] [CrossRef]
- Dupré, D.; Krumhuber, E.G.; Küster, D.; McKeown, G.J. A performance comparison of eight commercially available automatic classifiers for facial affect recognition. PLoS ONE 2020, 15, e0231968. [Google Scholar] [CrossRef] [Green Version]
- Krumhuber, E.G.; Küster, D.; Namba, S.; Shah, D.; Calvo, M.G. Emotion recognition from posed and spontaneous dynamic expressions: Human observers versus machine analysis. Emotion 2021, 21, 447. [Google Scholar] [CrossRef]
- Monaro, M.; Maldera, S.; Scarpazza, C.; Sartori, G.; Navarin, N. Detecting deception through facial expressions in a dataset of videotaped interviews: A comparison between human judges and machine learning models. Comput. Hum. Behav. 2022, 127, 107063. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A. Challenges in Representation Learning: A Report on Three Machine Learning Contests. In Proceedings of the Neural Information Processing, Daegu, South Korea, 3–7 November 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 117–124. [Google Scholar]
- Ekman, P. An argument for basic emotions. Cogn. Emot. 1992, 6, 169–200. [Google Scholar] [CrossRef]
- Estellés-Arolas, E.; González-Ladrón-de Guevara, F. Towards an integrated crowdsourcing definition. J. Inf. Sci. 2012, 38, 189–200. [Google Scholar] [CrossRef] [Green Version]
- Redi, J.; Siahaan, E.; Korshunov, P.; Habigt, J.; Hossfeld, T. When the crowd challenges the lab: Lessons learnt from subjective studies on image aesthetic appeal. In Proceedings of the Fourth International Workshop on Crowdsourcing for Multimedia, Brisbane, Australia, 30 October 2015; pp. 33–38. [Google Scholar]
- Reimann, M.; Wegen, O.; Pasewaldt, S.; Semmo, A.; Döllner, J.; Trapp, M. Teaching Data-driven Video Processing via Crowdsourced Data Collection, 2021. Available online: https://www.researchgate.net/publication/351483537_Teaching_Data-driven_Video_Processing_via_Crowdsourced_Data_Collection (accessed on 1 November 2022).
- Palan, S.; Schitter, C. Prolific. ac—A subject pool for online experiments. J. Behav. Exp. Financ. 2018, 17, 22–27. [Google Scholar] [CrossRef]
- Peer, E.; Brandimarte, L.; Samat, S.; Acquisti, A. Beyond the Turk: Alternative platforms for crowdsourcing behavioral research. J. Exp. Soc. Psychol. 2017, 70, 153–163. [Google Scholar] [CrossRef] [Green Version]
- Ak, A.; Goswami, A.; Hauser, W.; Le Callet, P.; Dufaux, F. RV-TMO: Large-Scale Dataset for Subjective Quality Assessment of Tone Mapped Images. IEEE Trans. Multimed. 2022, 1–12. [Google Scholar] [CrossRef]
- Sampaio, E.V.B.; Lévêque, L.; Silva, M.P.D.; Le Callet, P. Are Facial Expression Recognition Algorithms Reliable in the Context of Interactive Media? A New Metric to Analyse Their Performance. In Proceedings of the EmotionIMX: Considering Emotions in Multimedia Experience Workshop, ACM International Conference on Interactive Media Experiences (IMX), Aveiro, Portugal, 22-24 June 2022; pp. 97–115. [Google Scholar] [CrossRef]
- Pham, L.; Vu, T.H.; Tran, T.A. Facial Expression Recognition Using Residual Masking Network. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 4513–4519. [Google Scholar] [CrossRef]
- Serengil, S.I.; Ozpinar, A. HyperExtended LightFace: A Facial Attribute Analysis Framework. In Proceedings of the International Conference on Engineering and Emerging Technologies (ICEET), Istanbul, Turkey, 27–28 October 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Dodge, S.; Karam, L. Quality resilient deep neural networks. arXiv 2017, arXiv:1703.08119. [Google Scholar]
- Dietterich, T.G. Approximate statistical tests for comparing supervised classification learning algorithms. Neural Comput. 1998, 10, 1895–1923. [Google Scholar] [CrossRef]
- Steven, M. Ground truth an underview. Int. J. Remote Sens. 1987, 8, 1033–1038. [Google Scholar] [CrossRef]
- Chen, Y.; Joo, J. Understanding and mitigating annotation bias in facial expression recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 14980–14991. [Google Scholar]
- Fleiss, J.L. Measuring nominal scale agreement among many raters. Psychol. Bull. 1971, 76, 378. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mollahosseini, A.; Hasani, B.; Mahoor, M.H. Affectnet: A database for facial expression, valence, and arousal computing in the wild. IEEE Trans. Affect. Comput. 2017, 10, 18–31. [Google Scholar] [CrossRef] [Green Version]
- Cabitza, F.; Campagner, A.; Mattioli, M. The unbearable (technical) unreliability of automated facial emotion recognition. Big Data Soc. 2022, 9, 20539517221129549. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
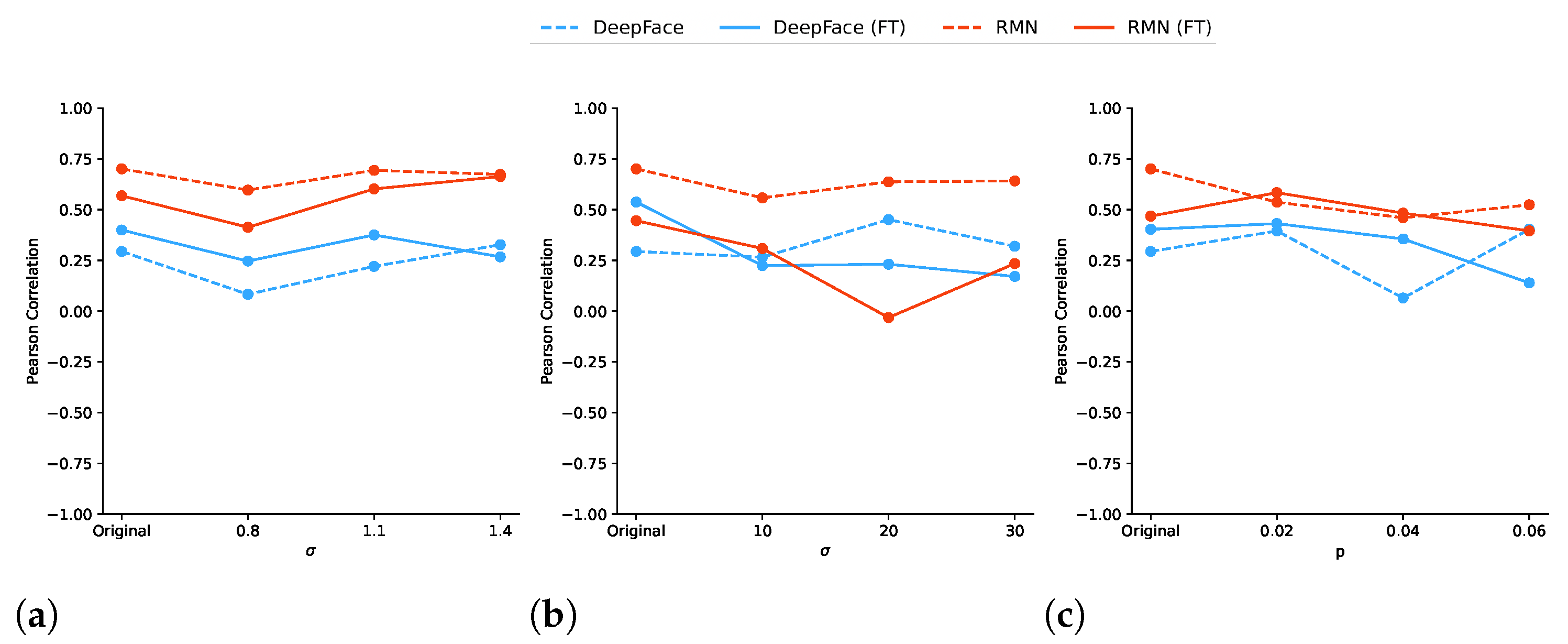
| Figure 6a | Figure 6b | Figure 6c | Figure 6d | |
|---|---|---|---|---|
| Mean | 0.34 | 0.41 | 0.54 | 0.38 |
| Standard dev. | 0.11 | 0.13 | 0.09 | 0.07 |
| Minimum | 0.30 | 0.30 | 0.42 | 0.27 |
| Maximum | 0.43 | 0.49 | 0.70 | 0.53 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lévêque, L.; Villoteau, F.; Sampaio, E.V.B.; Perreira Da Silva, M.; Le Callet, P. Comparing the Robustness of Humans and Deep Neural Networks on Facial Expression Recognition. Electronics 2022, 11, 4030. https://doi.org/10.3390/electronics11234030
Lévêque L, Villoteau F, Sampaio EVB, Perreira Da Silva M, Le Callet P. Comparing the Robustness of Humans and Deep Neural Networks on Facial Expression Recognition. Electronics. 2022; 11(23):4030. https://doi.org/10.3390/electronics11234030
Chicago/Turabian StyleLévêque, Lucie, François Villoteau, Emmanuel V. B. Sampaio, Matthieu Perreira Da Silva, and Patrick Le Callet. 2022. "Comparing the Robustness of Humans and Deep Neural Networks on Facial Expression Recognition" Electronics 11, no. 23: 4030. https://doi.org/10.3390/electronics11234030