1. Introduction
Recent advances in mobile technologies have revolutionized the smart phone industry. The ability of smart phones to process powerful applications have made them the preference of users over laptops and desktops. Consequently, the number of smart phone users are increasing at a very fast pace. Six billion smart phone subscribers were reported in July 2021 (
https://www.statista.com/statistics/330695/number-of-smartphone-users-worldwide/, accessed on 25 October 2022). The key to the revolution of the smart phone industry lies greatly in the development of modern and efficient operating systems. Various operating systems have been developed over the years such as Android, Symbian, Apple iOS, Blackberry OS, Windows OS, etc. Among these, Android by Google is the most popular one. Android holds a large share of 72.8 percent in the smart phone industry (
https://gs.statcounter.com/os-market-share/mobile/worldwide, accessed on 25 October 2022). The wide scale usage of Android has made the application developers create a large number of applications for the platform. These applications are available on the official Google Play store and other third party stores. These applications benefit the users in their daily routine tasks and are also a source of entertainment. However, malicious program developers take advantage of the high popularity and usage of the Android platform and have developed a significantly large number of applications with malicious functions. The app stores contain many applications that have been characterized as Adware, Trojans, Spyware, and Ransomware by anti virus engines [
1]. Initially, malware mitigation systems worked by generating signatures of known malicious applications. However, signature-based schemes require human expertise and manual update of signature data bases [
2]. To overcome this problem, machine learning based schemes are being used for generating behavior patterns of applications [
3,
4,
5]. In these schemes, an application is analyzed and features related to malicious activity are inspected. A classification system is later trained for these features and a new application is predicted by using them.
The performance of machine learning based schemes is highly dependent on the nature of features selected for analysis [
6]. In case of malware detection, two kinds of features can be used for analysis; static and dynamic. Static features are extracted by analyzing the structure of an application without executing it [
7], whereas dynamic features are extracted by running the application in a controlled environment and recording features that represent the run time activity of the applications. In order to deceive the machine learning schemes based on static features, malware developers use obfuscation techniques [
8]. Obfuscation refers to changing the structure of the code in a way so that the original semantics are camouflaged [
9]. Many obfuscations techniques are available, which perform applications structure transformation in order to change the signature or conceal the malicious behavior. Common obfuscation schemes include Class Encryption, String Encryption, Reflection, Control Flow Modifications, and Junk Code Insertions [
10].
A noticeable rise in the usage of obfuscation techniques for malware generation has been observed recently [
11]. Owing to the rise in the usage of obfuscation in malware generation, the design of obfuscation resilient solutions for malicious application detection is inevitable. Dynamic analysis schemes are more robust in handling the obfuscation effects as they can capture the run time activity [
12]. Regarding the different ways of dynamic analysis, memory-based solutions have gained significant popularity due to their ability to model the masked behavior of applications [
13,
14,
15]. This study proposes a memory-based scheme for Android malware detection. The proposed scheme is a dynamic analysis technique that runs the application in a sandbox environment and captures the kernel task structure for the application under analysis. A kernel task structure is generated for each running process by the Android operating system and contains important information related to the running application. The information includes memory management details, process credentials handling, files access information, and scheduling information. Formally, the information in the kernel task structure can be divided into nine categories, namely; task_state, mem_info, scheduling_info, signal_info, process_credentials, I/O_statistics, openfile_info, CPU_specific_state, and others. The proposed system parses these nine categories of Kernel task structure for extraction of the features. All categories are thoroughly analyzed for their significance in malware detection, and the set of the most significant features is reported. Our work is unique as it is the first work to examine the features present in nine categories of kernel task structure for their significance in Android malware detection. Additionally, the final feature set is tested against four obfuscation schemes in order to evaluate the resilience of the system against obfuscation. It has been found that the run time analysis of applications from the kernel task structure of memory helps to generate a behavior profile, which is independent of the changes made in the application by using obfuscation. Overall, the contributions of the study are listed below:
An obfuscation resilient feature set for Android malware categorization is proposed;
The Kernel Task Structure from process memory is analyzed for nine categories up to a depth of six levels for extraction of the features. To the best of our knowledge, this is the most in-depth extraction of features related to kernel task structure in the domain of Android malware detection. Previous studies have analyzed five categories for a depth of three;
An important contribution is the evaluation of the effectiveness of proposed features against four obfuscation techniques; Class encryption, Reflection, String Encryption, and Junk Code insertion.
The rest of the paper is organized as follows: details of the kernel task structure are discussed in
Section 2.
Section 3 presents the related work. The proposed methodology for feature extraction and selection is presented in
Section 4. The results for the proposed methodology are reported in
Section 5, and finally the conclusion is presented in
Section 6.
2. Overview of Kernel Task Structure
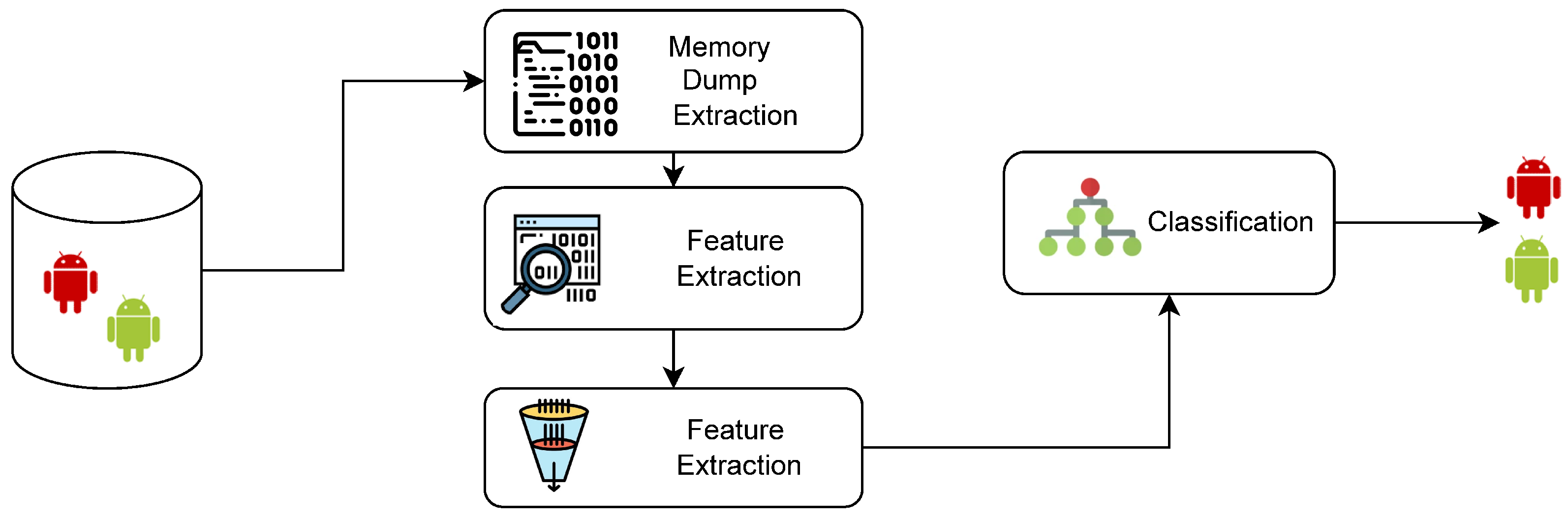
The kernel of the Android operating system stores the list of all running processes in a doubly linked list. Each element in the list is the process descriptor of a certain process, also called its task struct. Kernel task structure is a large structure containing the process management information required by the kernel (
https://elixir.bootlin.com/linux/v4.2/source/include/linux/sched.h#L1344, accessed on 25 October 2022). KTSODroid utilizes the information in this structure for generating features for modeling the behavior of malicious applications. The amount of information in the kernel task structure is huge, however some important information related to application behavior has been selected by KTSOdroid for analysis. This information includes process identification number (pid), name of process, different process states, CPU scheduling information, memory management information, memory limits, I/O statistics, accounting information, signal related information, process ownership information, and information related to opened files and network sockets. Overall, this information is grouped into different categories based on the semantic similarities. These categories are briefly described below:
- (i)
task_struct: It includes information related to the state of the process such as exit code and process execution domain;
- (ii)
mem_info: It is the process memory descriptor and includes information such as the major and minor page faults, heap address of the process, start and end address of code segment and start and end address of data segment;
- (iii)
scheduling_info: It describes the information related to process scheduling such as priority of the process, scheduling state, scheduling policy, execution time, waiting time, snapshot of user, and system CPU time;
- (iv)
I/O_statistics: It describes block I/O delay and I/O statistics such as number of byte read, number of read system call, and number of write system calls;
- (v)
openfiles_info: It contains information of opened files related to the process such as maximum number of file descriptor and opened file descriptor;
- (vi)
CPU_speficic_state: It describes the CPU state of the process, which includes different register states and fault info;
- (vii)
signal_info: It describes information about the signal sources, the signal handler, and timers related to the process;
- (viii)
process_credentials: It defines the security context of the process. It includes information such as ownership and process capabilities;
- (ix)
Others: This includes miscellaneous information about the process such as the age of the process and tracer information.
3. Related Work
Obfuscation refers to changing the structure of code so that the semantics of code are concealed from analysts. It has been stated by Ref. [
16] that modern anti-malware tools are unable to detect obfuscated malicious applications; therefore, analyzing obfuscation is a key challenge in malware detection. Many studies such as Refs. [
16,
17,
18] have estimated the effect of obfuscation on the detection accuracy of anti malware products. It has been stated by Ref. [
10] that the performance of anti-malware tools is downgraded by a significant percentage when the samples are obfuscated. Suarez et al. [
19] highlighted that the rate of obfuscation in Android applications is approaching that of desktop applications. Many commercial and academic tools that facilitate obfuscation for Android applications are now available. These facts clearly highlight that obfuscation is a growing threat and needs to be addressed with new and effective methods. The failure of signature-based schemes against obfuscated malware has compelled the designers of detection systems to formulate machine learning-based solutions. In case of machine learning solutions, two kinds of features can be used; static and dynamic. Static features are extracted by analyzing the application structure without running it. These features include permissions, intents, API calls in the code, and opcode sequences [
20,
21,
22]. Static features are most effected by obfuscation as most obfuscation techniques camouflage the structure in a way that semantics of behavior are hidden by code inspection schemes. It is pertinent to highlight that some applications do not store their malicious payload in application code and it is rather loaded at run-time. In such cases, the static features of API calls and opcode sequences do not contain relevant information about malicious activity [
23]. Similarly, obfuscation techniques such as class encryption completely encrypt the class structure and hence code-based static features cannot be accessed. In contrast to static analysis schemes, dynamic analysis schemes are better able to model the run time behavior of applications [
24,
25]. Many sources of dynamic analysis features can be used for feature extraction such as network, battery usage, API calls, and memory [
26]. Among these, memory-based features have shown promising results specifically in minimizing the effects of obfuscation [
27,
28]. The proposed scheme has focused on the design of features from kernel task structure of memory; therefore, in this section, the schemes based on memory-based features for Android malware classification are discussed.
Refs. [
27,
29] extracted memory dumps from a data set of malicious applications and used them as images for creating a classification system based on the differences in images. However, the complete memory dump contains a number of other processes as well and the analysis is not specific to the application under evaluation.
Refs. [
14,
30,
31] proposed malware detection schemes using process meta data features. The information in the kernel task structure of memory is used for the extraction of process meta data features. The kernel task structure is analyzed up to a maximum of three levels for five categories of features. However, four other categories can also be explored and the depth of structure traversal can be increased for feature extraction.
Memory-based features are used by Keyes et al. [
5] for the classification of an application into 12 distinct categories. Memory features include PssTotal, PssClean, SharedDirty, PrivateDirty, SharedClean, PrivateClean, SwapPssDirty, HeapSize, HeapAlloc, AppContexts, Activities, Assets, AssetManagers, ProxyBinders, ParcelMemory, ParcelCount, DeathRecipients, OpenSSLSockets, and WebViews. These features are used in combination with API and network-based features. Random Forest has been used for classification. The memory-based features used by this study are representative of an entire memory structure. The features are not specific to the process under analysis.
The authors in Ref. [
32] have extracted memory images using LIME and have extracted the use of libraries for a process. The library usage is analyzed with yarascan to find if some malicious library is loaded. The study is not conducted for a data set. A few samples are analyzed with the proposed technique. The proposed approach is rule-based and uses yara rules for identifying the malicious behavior. This makes the approach a rule-based approach and is subject to the problem of constant rule updates. A summary of the related work is presented in
Table 1.
5. Experiments and Results
In this section, the results of the proposed methodology are discussed. The data sets used for this study include AndrooZoo for malicious applications and CICMalDroid 2020 for benign applications. The experiments are run for 800 malicious and 800 benign applications. Each applications is executed in the Android emulator and random events are generated on the application using Monkey. As mentioned earlier, four memory dumps are recorded against an application, therefore the number of records in the data set are 6400. Each record contains 526 features belonging to the 9 categories of the kernel task structure. The large set of features extracted from the kernel task structure are analyzed using variance and information gain for feature selection. This section reports the results of feature selection and classification on the final feature set. The trained classifier is finally tested against four obfuscated schemes and it is demonstrated that the extracted features are independent to the obfuscation applied on the samples.
5.1. Feature Selection
Since a rich set of features is extracted by the feature extraction process, a two-step feature selection process is applied for selecting effective features. The results of both steps are presented in the subsequent subsections.
5.1.1. Constant Feature Elimination
Constant features are the ones that have the same values for all output classes. In order to find constant features, variance has been calculated against all features in the data set. If the value of variance is zero for a feature, it is grouped into the set of constant features and is removed from the set of effective features. Out of 526 extracted features, 241 features are found to be constant in nature. These features are removed from the set of effective features. The remaining set of 285 features is passed to the next phase of feature selection, i.e., for calculating the information gain score.
5.1.2. Information Gain for Feature Selection
Information gain is calculated for all non-constant features selected by the previous phase. The value of information gain reflects the influence of the feature on the prediction of the output. In order to select features important for classification, a threshold estimation approach is used. The features are selected at different values of information gain by measuring the performance measure against the selected features.
Table 3 shows the results against different threshold values.
It can be observed that initially the threshold value is set to 0.0 and at each step the value is increased by 0.1. The increase in value is stopped when the performance starts degrading. It can be seen that the best performance is achieved at an IG threshold of 0.4 and the performance degrades when increasing the value of the threshold. Therefore, the features at a threshold value of 0.4 are reported as the final selected features.
Figure 3 shows the information gain scores of the selected features. There are a total of 28 features and all of the them have significant values for the information score. These features belong to mem_info, process_credentials and signal_info categories of the kernel task structure. These features represent the final feature set and will now be used for classification.
5.2. Classification
Features selected using information gain are now evaluated for a different number of tress in Random Forest in order to report the best configuration for maximum performance. The performance at a different number of trees is shown in
Figure 4.
It can be observed that the reduced feature set is able to classify the applications with high performance. The number of trees in Random Forest also affect the performance of the classification system. A different number of trees is tested and it is observed that maximum performance is achieved for nine trees.
The performance is estimated using the F1-Score, which in turn is dependent on precision and recall. The formulas are shown in Equations (
3)–(
5). Precision is the ratio of the correctly predicted positive observations (
TP) to the total predicted positive observations (
TP +
FP). Recall is the ratio of correctly predicted true positives (
TP) to the total number of observations in a class (
TP +
FN). F1-score is the weighted average of precision and recall and is considered a better estimator for performance as compared to accuracy because it considers the cost of both false positives and false negatives for performance estimation.
The final results of classification are shown in
Table 4.
5.3. Testing on Obfuscated Applications
The proposed system is now tested for obfuscated applications. The following obfuscation schemes have been tested by the study.
Android Manifest Transformation: Changes in the Manifest file by inserting permissions or intents for bypassing signature-based detection schemes ([
10]);
Junk code insertion: Adding some code into the application that does not effect the working of an application ([
10]);
String encryption: Strings in classes.dex file are encrypted to bypass products that look for suspicious strings ([
43]);
Control-flow manipulation: Control flow modifications include adding branch and iterative statements. This changes the control flow of an application ([
44]);
Reflection: Reflective calls allow programs to change their behavior at run time ([
45]);
Class Encryption: This is the most powerful obfuscation technique, where the complete code or part of the code is encrypted ([
46]).
It can be seen that the system is able to classify obfuscated applications. These results highlight the resilience of memory-based features against obfuscation techniques.
6. Conclusions and Future Work
The presence of obfuscated malicious applications for the Android platform has made dynamic analysis-based solutions replace static analysis solutions. This study has proposed a dynamic analysis-based malware detection system that extracts volatile memory-based artifacts for malicious Android application detection. The kernel task structure of memory was traversed for nine categories, six levels deep for the exploration of features. A large number of process-specific features were extracted, which were then thoroughly analyzed to find the most significant features. The proposed system is able to classify malicious applications with high performance. The system was also tested for different obfuscation techniques and it was observed that the features designed from memory were able to model the behavior of obfuscated applications.
In the future, we propose to test the effectiveness of the features for categorizing the application into their respective classes such as Adware, Trojans, and Spyware, etc. We also propose to formulate the environment of the experiment in a way to handle malicious applications, which stop executing themselves in a sandbox.






{kind=link}
{kind=link}
{kind=link}
{kind=link}