Abstract
Colorization in X-ray material discrimination is considered one of the main phases in X-ray baggage inspection systems for detecting contraband and hazardous materials by displaying different materials with specific colors. The substructure of material discrimination identifies materials based on their atomic number. However, the images are checked and assigned by a human factor, which may decelerate the verification process. Therefore, researchers used computer vision and machine learning methods to expedite the examination process and ascertain the precise identification of materials and elements. This study proposes a color-based material discrimination method for single-energy X-ray images based on the dual-energy colorization. We use a convolutional neural network to discriminate materials into several classes, such as organic, non-organic substances, and metals. It highlights the details of the objects, including occluded objects, compared to commonly used segmentation methods, which do not show the details of the objects. We trained and tested our model on three popular X-ray datasets, which are Korean datasets comprising three kinds of scanners: (Rapiscan, Smith, Astrophysics), SIXray, and COMPASS-XP. The results showed that the proposed method achieved high performance in X-ray colorization in terms of peak-signal-to-noise ratio (PSNR), structural similarity index (SSIM), and learned perceptual image patch similarity (LPIPS). We applied the trained models to the single-energy X-ray images and we compared the results obtained from each model.
1. Introduction
As an alternative to manual inspection, basic X-ray scanner applications display X-ray images to identify the contents of luggage or cargo containers and support the inspection process. Owing to the increased number of air and sea trips between countries in recent years, the inspection process of luggage and cargo containers has increased to ensure countries remain safe from illegal or dangerous materials. Therefore, developing security systems that inspect cargo containers and luggage with high performance and accuracy is crucial.
The X-ray scanner detects objects inside luggage or cargo by emitting X-rays waves from one side of the pass-through objects, which hits the digital detectors on the other side. When the X-ray passes through an object, some of it is absorbed by the objects with lower density, such as organic material, allowing more X-rays to pass through. Additionally, higher-density objects absorb most of the X-ray waves while allowing some of the rays to pass through.
Depending on the number of X-rays that reach the detector, the X-ray scanner generates an image that shows the different objects inside the luggage with different levels of grayscale based on the density and atomic number (Z) of the material. The result is a grayscale image with a different pixel intensity that depends on the X-ray wave observation of the object.
Accurate identification of objects is crucial in the inspection process. However, owing to the significant number of inspections inside airports and ports, the human factor requires assistance to raise the efficiency of the inspection process. Therefore, computer vision is being used to solve these problems and improve performance to prevent any dangerous or smuggled materials from entering the country. However, the detected shape of the object is not enough to recognize the prohibited material or level of danger, considering the smugglers and terrorists can deceive and change the object’s shape, thereby hindering its identification. Furthermore, false alarms occur if the operator (human factor, agent) relies on automatic object detection which depends only on the shape of the objects. Therefore, it is necessary to identify the object’s materials to avoid such cases.
Using material discrimination approaches can significantly enhance the detection rate and reduce false alarms. Visualization of an image in material discrimination can be performed by using four or six colors, depending on the different levels of radiation absorption, to express essential materials during the inspection process. For example, each class of object (light organic, heavy organic, non-organic, metal, heavy metal) is identified by a particular color. Table 1 shows the material pseudo-colors and their classes.

Table 1.
Material pseudo-colors and their classes commonly utilized in X-ray security scanners.
There are two different technologies in X-ray security scanners, single-energy and dual-energy scanners. The difference between these two technologies is that the single-energy uses only a single-energy beam to produce digital images. However, dual-energy technology uses two X-ray beams peaking with different energies (high and low) and passes them through the object under inspection. Few of the high-energy beams are absorbed by the objects; unlike the low-energy beams, the observation of these beams is very high. The results of this absorption rate are compared to show the difference between the component materials of the objects in an image. Colors are also used to distinguish between organic, inorganic, and metallic substances.
In our proposed method, we train our model on colorization using dual-energy datasets. Then, we apply the model to the single-energy images for colorization because the dual-energy images contain much more information than the single-energy images. Additionally, colorization improves the quality of single-energy images in the inspection process by colorizing different materials according to their type so that we can obtain the same level of colorization accuracy as the dual-energy-based method.
The X-ray operation system aims to detect the object under inspection and identify the different objects in the luggage or cargo to prevent any prohibited or illegal items from entering countries. Several researchers have studied X-ray operation systems for classification [1,2,3,4,5,6,7,8,9,10,11,12,13], object detection [14,15,16,17,18,19,20], and segmentation [21,22,23,24,25,26,27,28]. The most important aspect of this procedure is to recognize the objects or materials inside the luggage or container. For example, the operation of material discrimination in object detection or segmentation is performed by the human factor (operator). In other cases, material discrimination operations are automatic depending on material discrimination algorithms.
Based on previous studies, the process of recognizing objects can be divided into classification, object detection, and segmentation. The absorption of X-ray waves by objects depends on the atomic number (Z) and the object’s thickness. However, the thickness significantly influences this process [1]. Some research employed the atomic number (Z) for material classification. For example, Alvarez et al. [2] stated that a constant independent of energy might sum up the energy data for every material. Chuang et al. [3] employed the subregion direct approximation method and used an iso-transmission line to implement more than a nonlinear equation. However, their method is more sensitive to quantum noise than traditional methods. Osipov et al. [4] used radiographic images, statistical analysis, and processing to estimate the atomic number of materials. According to a computational experiment, the aluminum alloy die casting (ADC) digit capacity, mass, thickness, and adequate atomic number of the test-object material can significantly impact the quality of material identification. Benedykciuk et al. [5] employed random forest and support vector machine (SVM) for material discrimination. Brumbaugh et al. [6] proposed a 1D convolution neural network (CNN) and trained it using simulated data. Bunrit et al. [7] proposed a CNN transfer learning for GoogleNet [8] and attained a high accuracy of 95% on the X-ray material classification. Chen et al. [9] proposed a curve calibration and a real-time correction technique by using a curved-based HSL color space image colorization and smoothing strategy to improve the classification performance. Andrews et al. [10] presented an image classification method using a feed-forward neural network-based auto-encoder for threat and anomalous detection in cargo X-ray images based on one-class radial basis function (RBF) and support vector machines (SVM). Jaccard et al. [11] proposed an image classification and threat detection method using an 18-layer CNN architecture with log-transformed input images. Kundegorski et al. [12] proposed a bag-of-visual-word-based method using the FAST-SURF feature descriptor and SVM classifier. Benedykciuk et al. [1] proposed a material classification method based on multiple-scale CNN using different convolutional kernel sizes (9 × 9, 7 × 7, 5 × 5, 3 × 3, 1 × 1). The obtained output was five classes of materials.
Other researchers presented object-detection-based methods that provided the bounding box for the objects of interest on popular x-ray datasets such as SIXray [13]. Roomi et al. [14] proposed an object detection method based on a fuzzy K-NN classifier and evaluated their model using 15 image examples. Akçay et al. [15] proposed a handgun detection method based on the transfer learning of CNN and attained a detection accuracy of 98.92%. Gaus et al. [16] compared different CNN architectures; Faster RCNN [17], Mask RCNN [18], and RetinaNet [19], and used the Durham and SIXray datasets for training and evaluation, respectively. The Faster RCNN achieved the best performance in firearm and firearm components detection. Filtton et al. [20] proposed a 3D object detection method based on local region histogram, 3D-RIFT, and SIFT. Their model achieved a 3D object detection accuracy of 95%. Another group of researchers proposed semantic segmentation for material segmentation. Bhowmik et al. [21] proposed a sub-component-level segmentation using a fine-grain CNN with a discriminative filter bank (DFL) [22] and compared the performance of multiple CNN architectures, such as Faster RCNN, VGG16 [23], SqueezeNet [24], ResNet18, and ResNet50 [25]. The best network attained an accuracy of 97.91%. Stan et al. [26] proposed a material semantic segmentation method using SegNet [27]. Roy et al. [28] presented a material segmentation method based on three multi-scale CNNs to predict scene cues and another multi-scale CNN for dense map prediction.
The contributions of this study can be summarized as follows:
- We propose a deep-learning-based X-ray image colorization method for raw X-ray images and artificially created raw images.
- We propose a single-energy colorization technique based on a CNN model trained on dual-energy colorization.
- We compare five different CNN architectures and select the best CNN model for the X-ray colorization task.
- We train the proposed model on images obtained from five different X-ray scanners, three of which are new datasets with a significant number of training and test images that have not been used in previous research.
- We prove that the artificially created raw image can be used instead of the original raw image, for X-ray colorization application.
2. Proposed Method
Herein, we discuss the proposed CNN architecture (Section 2.1), training details of our model (Section 2.2), and the loss function details (Section 2.3) in detail. The modified UNet architecture is trained for image colorization using a converted grayscale image as an input and the colored image as an output. The trained model is applied directly to the single energy X-ray image (which is a grayscale image) to predict the colored image, with each material having a unique color.
2.1. Proposed CNN Architecture
The proposed CNN architecture is an encoder–decoder architecture inspired by the architecture of UNet [29], which initially performed semantic segmentation and is common in colorization research, as mentioned in [30,31,32,33]. U-Net architecture is employed to perform the task of single-energy X-ray image colorization; however, the original study of UNet [29] has a different objective: image segmentation. In our case, we modify the UNet architecture (modifications to the last few layers to adapt the colorization task) for X-ray image colorization. The encoder stage in the proposed architecture compresses the input image into a miniature spatial representation using convolutional and max-pooling layers. Then, the encoder constructs the output RGB image from the small representation using a sequence of deconvolutional layers. We replaced the last two layers for segmentation in UNet with an image reconstruction layer using 1 × 1 × 3 convolution with a linear activation.
The encoder architecture comprises 5 blocks, wherein each block comprises a convolutional layer, dropout layer, another convolutional layer, and a max-pooling layer, for spatial size down-sampling. However, the 5th block does not have the max-pooling layer. The number of filters of the convolutional layers increases towards the deeper blocks (16 → 32 → 64 → 128 → 256). The decoder architecture comprises 4 blocks. Each block comprises a deconvolutional layer, concatenation layer (which concatenates the output features from the deconvolutional layer with the same size features from the encoder blocks), convolution layer, dropout layer, and another convolutional layer. The filter depth decreases towards the deeper blocks (128 → 64 → 32 → 16). We add a 1 × 1 convolutional layer with 3 filters to construct the final RGB image. Figure 1 shows the network architecture.
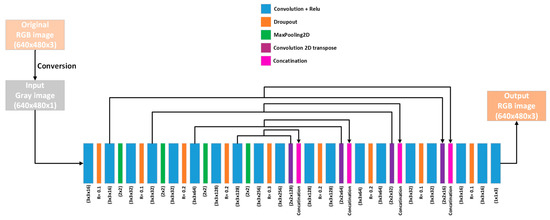
Figure 1.
The CNN architecture of the proposed method (UNet architecture with adding a 1 × 1 convolution layer with 3 output filters). Each layer type is represented with a different color. The original RGB image is converted to grayscale, and the output is an RGB image.
2.2. Training Detail
We downsampled the images while training our model to speed up the training process. For the Korean dataset (Rapiscan, Astrophysics, and Smith), we resized the original image from size 1680 × 1050 to 640 × 480, which is approximately the original image’s aspect ratio. Considering the images’ original size is not fixed and has random aspect ratios for SIXray and COMPASS-XP, we resized the images to a fixed size of 416 × 416. Furthermore, we used the exact sizes for the training while testing.
2.3. Loss Function
The loss function in our training is a combination of the mean absolute error (MAE) and the mean squared error (MSE), given as
where N represents the total number of pixels in the image, is the ground truth pixel value, and is the predict pixel value. This loss is inspired by Elastic net [34]. It has been found empirically that this loss is better than each separately for training. Additionally, both MAE and MSE have disadvantages. Training with MAE loss is slow as the training error values are relatively significant, making it difficult for the model to reduce rapidly. Moreover, MSE is so sensitive to outliers that it usually produces under-fitting. Therefore, the combination has a trade-off between the training speed and excellent fitting.
3. Experiment Preparation and Benchmarks
We measured the accuracy of material discrimination based on the capability of colorization and recognition of different materials in the grayscale image generated by the X-ray scanner. Furthermore, we implemented our proposed model using Tensorflow and Keras libraries. Our training processes were performed on a desktop computer with an intel i7-9700 processor, 32 GB of RAM, and an Nvidia TITAN RTX graphics processing unit.
For training, we used Korean dataset (X-ray images from three scanners), SIXray, and COMPASS-XP.
The Korean Dataset [35] comprises X-ray images of 35 different items of dangerous materials captured from three kinds of scanners: Rapiscan, Astrophysics, and Smith. For each scanner, the data were scanned using four strategies, and each is collected in a file as below.
Single default: This data represented one sample of the relevant item without selecting any item other than the relevant item. The item was scanned from multiple angles. This set represents 15% of the total data of the target image, which were generated considering various angles of the item and entry directions of the luggage.
Single other: This data contained a relevant item generated from different angles and general non-dangerous items (clothes, cables, charger, pen, glasses, etc.) other than the sample. This set represented 15% of the total data of the target image generated while considering the longitudinal direction.
Multiple Categories: This data represented one sample of the relevant item with other dangerous items representing the largest share of the dataset, i.e., 40% of the data, by generating simultaneous images with other samples of the same item. For example, if the target item is a gun, we can find other sharp tools or hazardous items in the same image.
Multiple Other: This data represented multiple samples of the relevant item and general non-dangerous items, representing 30% of the data.
All four types of data were generated by inserting the items into bags, backpacks, suitcases, and baskets. For training we used 75,525 images from multiple categories and single default, for validation we used 11,700 images from multiple others and single.
SIXray: This dataset was gathered from subway stations and released by Miao et al. [13]. Owing to the unknown scanner specifications and this dataset containing 1,059,231 images—including 8929 images in separate files based on six classes: guns, knives, wrenches, pliers, scissors, and hammers—we conducted two separate experiments. First, we trained all images (SIXrayall) for each folder of the SIXray dataset. We selected 80% of the images for training and 20% for validation. Second, we trained all images for positive samples using 8816 positive images and split them into 80% for training and 20% images for validation, respectively. This training aimed to force the model to pay more attention to the prohibited items (SIXraypositive), considering most negative images do not contain prohibited items.
COMPASS-XP: This dataset was introduced by [36]. These images were scanned by a Gilardoni FEP ME 536 mailroom X-ray machine, which comprised 1928 sets with a different single item. This scanner generated several image outputs collected in different files, shown as follows. Low: Contained raw grayscale images scanned by low-energy X-ray channel; High: Contained raw images scanned by high-energy X-ray channel. Grey: A combination of low- and high-energy image channels; Density: This image represented the inferred density of material generated from the low- and high-energy channels; and Color: Colored images represented material discrimination based on density. In addition, there was another image in the Photo file that contained the real images of the scanned set captured by Sony DSC-W800. We split the dataset into 1348 and 580 samples for training and validation, respectively.
GDXray: This dataset [37] was collected by the Machine Intelligence Group (GRIMA) using an X-ray scanner (Canon model CXDI-50G). There are 19,410 X-ray images from five groups, including baggage, castings, welds, natural items, and setting.
In addition, the GDXray dataset contains single-energy X-ray grayscale images, and all the other datasets previously mentioned contain dual-energy X-ray images.
4. Evaluation Metric
The peak-signal-to-noise ratio (PSNR) was used as the evaluation metric for evaluating the proposed method. PSNR can be defined mathematically as
where MSE is the mean squared error between the predicted pixels and ground truth pixels. MAXI is the maximum value of the pixels, which is 255 in the case of RGB. Furthermore, we employed the structural similarity index (SSIM) [38], which uses various window sizes (8 × 8 is commonly used) to compare the structure of two images as
where and are the mean values of and , and are the variance values of x and y, respectively, and is the covariance of x and y. , are variables for stabilizing the division with a weak denominator, L is the dynamic range of the pixel-value, and k1 = 0.01 and k2 = 0.03 by default.
We also used LPIPS [39] to measure the perceptual patch similarity between the images using their features that are estimated using vgg16. The L2 distance is measured between the features obtained from each image under comparison:
where , , and are the height, width, and number of channels of the estimated 2D feature maps, respectively. are the estimated features using the VGG16 model employed to estimate features up to the final convolutional layer.
5. Ablation Study
We compared the original proposed network UNet [29] with four different architectures for colorization. First, we modified the original UNet to UNet-22, which is a UNet architecture with 22 layers, considering we removed two blocks (a UNet encoding block contains Conv2D → Relu → DropOut → Conv2D → Relu → Maxpooling2D) from the encoder and the corresponding two blocks from the decoder (a UNet decoding block contains Conv2DTranspose → Concatenate → Conv2D → Relu + Dropout → Conv2D → Relu). Second, UNet-54 is a UNet architecture with 54 layers, considering we added two encoding and decoding blocks each to the original UNet. Third, Xception–UNet [40] is an encoder–decoder architecture with Xception encoding and decoding blocks. The Xception block was proposed by Chollet et al. [41], and it comprises depthwise separable convolution (depthwise convolution + pointwise convolution). Note that this architecture does not have connections between the encoder and decoder as in the case of the original UNet. Nonetheless, it adopts residual connections from each block and the following block. An encoder Xception block comprises Conv2D → BatchNormalization → Relu → Depthwise SeparableConv2D → Maxpooling2D, whereas a decoder Xception block comprises Relu → Conv2Dtranspose → BatchNormalization → Relu → Conv2Dtranspose → BatchNormalization → Upsampling2D. Figure 2 shows the Xception–UNet architecture. Lastly, the dense convolution neural network (DCNN) is widely adopted in dense prediction tasks such as colorization [42] and denoising [43,44]. The DCNN comprises seven stacked Conv2D + Relu layers without any pooling or downsampling operations to preserve the image’s spatial size, except for the last Conv2D which has a linear activation. Figure 3 shows the DCNN architecture.
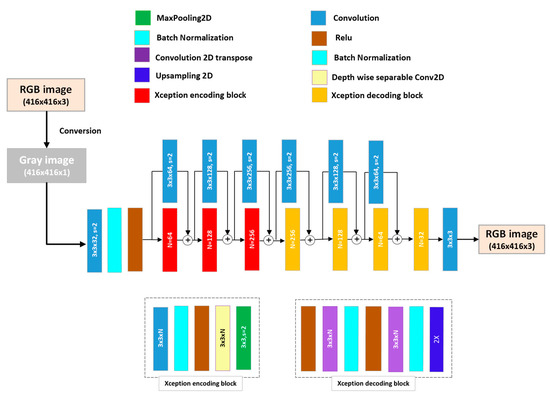
Figure 2.
Xception–UNet convolutional neural network (CNN) architecture. The architecture consists of three encoding blocks in the encoder part and four decoding blocks in the decoder part. Below the architecture are detailed drawings of the encoding and decoding blocks.
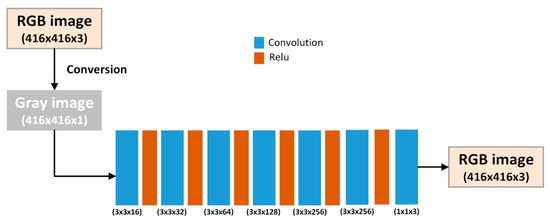
Figure 3.
Dense convolutional neural network (DCNN) architecture. The architecture only consists of a sequence of 3 × 3 Convolution and Relu layers.
To compare the performance of the above-mentioned networks, we trained them using the same dataset (Compass-XP). We reported the PSNR, SSIM, and LPIPS for each of the previously mentioned architectures, as shown in Table 2. Xception–UNet showed the worst performance with the lowest PSNR (23.302), SSIM (0.7906) values, and highest LPIPS (0.2828) value. Conversely, UNet achieved the best performance considering it attained the highest PSNR (33.637) and lowest LPIPS (0.0144). DCNN attained the best SSIM (0.9706), which was slightly better than UNet (the difference is 0.0026); DCNN and UNET can be considered similar in terms of SSIM. Overall, UNet had the best average performance in all three metrics. DCNN and UNet-22 exhibited similar performances with close PSNR, SSIM, and LPIPS values. UNet-54, unexpectedly, exhibited the worst PSNR, SSIM, and LPIPS values compared to UNET and UNet-22, which proves that UNet has the optimal number of layers for this task and increasing or decreasing the depth of the network can reduce the performance.
Table 2.
Comparison between UNet, UNet-22, UNet-54, Xception–UNet, and DCNN based on the PSNR, SSIM, and LPIPS in the colorization task. The best values of PSNR are 33.637, SSIM is 0.9706, and LPIPS is 0.0144.
6. Results and Discussion
Herein, we discuss the results obtained by measuring the PSNR for each dataset.
In X-rays, six primary colors represent materials of different objects. The brightness of the color is insignificant, considering our main task is to visually recognize the category of the material under the scanner, such as organic, inorganic, metal, etc.
As shown in Table 3, the model attained the best PSNR (33.6374) and LPIPS (0.0144) on the COMPASS-XP dataset for several reasons: COMPASS-XP contains clear images without any noise, and only a simple single object exists in the image, making it easy for the model to predict the colorization output. Concerning the multiple object colorization, the results obtained on the Rapiscan benchmark were the best in terms of PSNR and SSIM, considering Rapiscan, Astrophysics, Smith, and SIXray contain complex images with multiple objects that are difficult to learn precisely. The PSNR, SSIM, and LPIPS for Astrophysics and Rapiscan were similar, with Rapiscan exhibiting slightly lower values. Additionally, the model attained the best (lowest) LPIPS on Astrophysics (0.0253), which indicated that the predicted color images, in that case, exhibit features that best match the ground truth color image.
Table 3.
Comparison of the colorization performance between Rapiscan, Astrophysics, Smith, SIXrayall, SIXrayPositive, and COMPASS-XP datasets in terms of PSNR, SSIM, and LPIPS. The best values of PSNR are 33.6374, SSIM is 0.9772, and LPIPS is 0.0144.
Considering the SIXray dataset, we evaluated two kinds of training: first, with all samples of the SIXray dataset, including positive and negative samples (SIXrayall), as shown in Figure 4; and second, with only the SIXray positive images (SIXraypositive), as shown in Figure 4a. The PSNR in the case of SIXraypositive was 27.1444, which was significantly higher than SIXrayall, which was 22.6113. Additionally, SSIM and LPIPS were better for SIXraypositive (LPIPS = 0.1149, SSIM = 0.9428) compared to SIXrayall (LPIPS = 0.1801, SSIM = 0.9243). However, a slight difference showed that the model was capable of constructing the structure of the objects in both experiments. This is because the type of image in the first training with SIXrayall contained negative and few positive images, whereas most of those images contained several occluded and complex objects. However, in positive images, the images were uncomplex, and prohibited objects appeared, owing to which the model attained high PSNR.
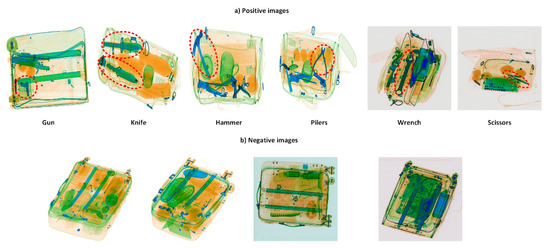
Figure 4.
Example images of the (a) positive and (b) negative images from the SIXray dataset. Positive images contain at least one of the prohibited objects, whereas negative images do not contain any prohibited objects.
Although the SIXray dataset was collected from different unknown sources and the collected data were different, the proposed model performed well on this dataset and learned the general colorization regardless of the source of the input image.
Furthermore, we validated the effectiveness of the proposed method by comparing the colorization performance between the converted artificial image and a real raw image obtained from a real scanner using COMPASS-XP [36] dataset. The raw images in this dataset were a mixture of low- and high-power images, and the ground truth RGB color images are provided in the dataset.
We trained two models on each input image and compared the evaluation results. Figure 5 shows a quality comparison between the images obtained using the raw images and the artificial images. Table 4 shows the models’ PSNR, SSIM, and LPIPS when trained using the two types of images. The results showed that the PSNR, SSIM, and LPIPS were too similar with minimal differences (1.82, 0.001, and 0.0078 differences in PSNR, SSIM, and LPIPS, respectively), which proves that in the proposed method, the artificial image is approximately similar to the raw image obtained from the real scanner. Additionally, as shown in Figure 6, the produced color images from both inputs are very similar with minimal differences.
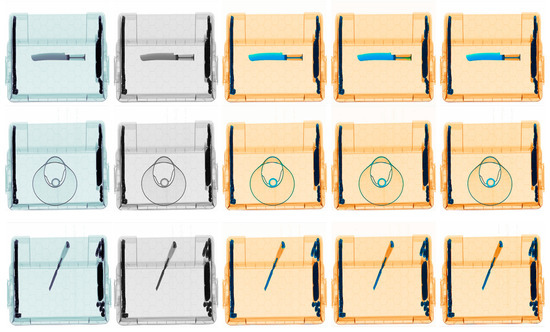
Figure 5.
Quality comparison between the colorization result from the raw image and the artificial image. (a–e) refer to the input raw image, input artificial image, predicted colored image using the artificial image, and ground truth RGB image, respectively.
Table 4.
Comparison of the colorization performance of the artificial image and raw-image-based models on the COMPASS-XP dataset in terms of PSNR, SSIM, and LPIPS.
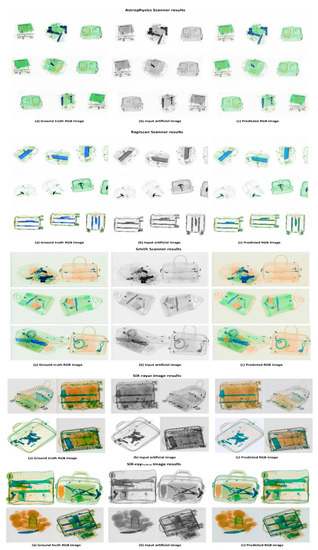
Figure 6.
Quality results were obtained from Rapiscan, Astrophysics, Smith, as well as SIXrayall and SIXraypositive. The result obtained from each scanner is shown in a label above each group of images. Each row consists of (a) a Ground truth image, (b) an artificial input image, and (c) a predicted RGB image.
7. Application of the Proposed Method in Single-Energy X-ray Image Colorization
We applied our trained model on different datasets, which are the Korean dataset (Rapiscan, Astrophysics, and Smith) and SIXray on the single-energy image from GDXray dataset for the colorization task based on convolution neural network, and we compared the results. We use gamma correction for the images to improve the colorization result, and Gamma correction is a method of non-linear mathematical operation applied to the pixels to change the saturation value of each one [45]. A visual comparison of some samples of the predicted images are shown in Figure 7. In Figure 7, the first column contains the inputs from the GDXray single-energy images, and the rest of the columns contain the predicted images in two cases first with gamma = 1, meaning without any gamma correction, and second with the optimal gamma correction value for each trained model. This is because not all the manufacturers of X-ray scanners use the same colorization technique [46], so the colored materials that may not be similar in the different scanners, e.g., low inorganic and high inorganic materials, but are close in terms of atomic number, can in some cases be assigned the same color in some scanners. For example, some X-ray scanners assign the green or orange color to both low organic and high inorganic materials. Also, in the case of light metal and heavy metal materials, some X-ray scanners assign the same color, which is green or blue for both materials. Since each scanner uses a different method of colorization for material discrimination, the predicted image from each trained model will be different. For that reason, we noticed that the brightness of the artificial raw image used in each training differs depending on the scanner type; each dataset has its own brightness levels, and the GDXray images used in this application are different in terms of brightness. We can see that in the case of gamma = 1, there are some errors in the predicted images. For that, we used gamma correction to display the input images in the same form of those used in the training process. By changing the gamma correction value, we empirically chose the best gamma values by visually comparing the results of the predicted images. This helped us reduce the error in the predicted images and obtain more accurate colorization results.

Figure 7.
Quality results were obtained by applying the proposed models on single-energy X-ray images. Each row consists of input single-energy image (grayscale), Rapiscan-, Astrophysics-, Smith-, and SIXray-based colorization results with a gamma value of 1. and the best gamma value for each scanner.
By visual comparison in Figure 7, we can observe that gamma correction has a huge impact on the colorization result as the GDXray images are naturally dark, and they need correction to be displayed in the same brightness as the artificial images in training. One can observe that Rapiscan and Astrophysics scanners have similar colorization techniques, as can be noticed from the color levels before and after gamma correction. In the Smith scanner, it is obvious that it has a different colorization style as the scanner mixes the colorization of the low (orange color) and high (green color) inorganic materials in some cases. However, this problem does exist in the ground truth data itself. The results predicted by the model trained on SIXray dataset images look the best (after gamma correction, gamma = 1.7). The proposed model trained on SIXray can be considered a general colorization model because it is trained on X-ray images collected from different types of X-ray scanners. The results obtained from SIXray without gamma correction have some pink pixels, which represent error pixels; those error pixels originally appear in the ground truth images of the SIXray dataset, usually when the X-ray beam cannot penetrate the object.
8. Limitations and Future Work
Despite the excellent colorization ability of the proposed model, there is a drawback: a low number of training samples results in low colorization performance and material discrimination. In this case, the model produces the wrong colorization for some occluded materials and several details owing to some color mixing between the materials, which the network is not trained for. Another challenge is the noisy X-ray images where the model fails to predict the true color of the noisy pixels, and hence, sometimes propagates those error pixels in the output owing to the strong interpolation ability of the CNN network, which further increases the error.
Our future work will include validating our colorization method using the popular classification, object detection, and semantic segmentation methods to compare the accuracy in each task between the RGB images and the predicted color images. Furthermore, we will compare the performance of the classification, object detection, and semantic segmentation on the raw X-ray image and colored image using the proposed method.
9. Conclusions
The obtained results and evaluation values in this study proved that the proposed method could efficiently perform the X-ray colorization task. Although the X-ray colorization of different materials is a complex task, considering the color depends on several factors, the proposed CNN model learned this task and produced highly detailed images with precise colors of the object materials. Therefore, the proposed method can be considered the essential step in the X-ray image discrimination task in the single-energy X-ray scanners, considering material recognition by color is the primary goal of the X-ray inspection process. Finally, the results obtained on the five different datasets collected from different X-ray scanners verified that the proposed model achieved general modeling of the X-ray colorization process, which was a big challenge in X-ray research in the past.
Author Contributions
Conceptualization, B.Y., H.I. and A.S.; methodology, B.Y and H.I.; software, B.Y. and H.I.; validation, B.Y. formal analysis, B.Y. and H.-S.K.; investigation, B.Y.; resources, H.-S.K.; data curation, B.Y.; writing—original draft preparation, B.Y.; writing—review and editing, B.Y. and H.I.; visualization, B.Y.; supervision, H.-S.K.; project administration, H.-S.K.; funding acquisition, H.-S.K. All authors have read and agreed to the published version of the manuscript.
Funding
This work was conducted as a part of the research projects of Development of automatic screening and hybrid detection system for hazardous material detecting in port container funded by the Ministry of Oceans and Fisheries (Grant number: 20200611).
Data Availability Statement
The datasets used in this paper are public datasets.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Benedykciuk, E.; Denkowski, M.; Dmitruk, K. Material classification in X-ray images based on multi-scale CNN. Signal Image Video Process. 2021, 15, 1285–1293. [Google Scholar] [CrossRef]
- Alvarez, R.; Macovski, A. Energy-selective reconstructions in x-ray computerized tomography. Phys. Med. Biol. 1976, 21, 733–744. [Google Scholar] [CrossRef] [PubMed]
- Chuang, K.-S.; Huang, H.K. Comparison of four dual energy image decomposition methods. Phys. Med. Biol. 1988, 33, 455–466. [Google Scholar] [CrossRef]
- Osipov, S.; Usachev, E.; Chakhlov, S.; Shchetinkin, S.; Song, S.; Zhang, G.; Batranin, A.; Osipov, O. Limit capabilities of iden-tifying materials by high dual- and multi-energy methods. Rus. J. Nondestr. Test. 2019, 55, 687–699. [Google Scholar] [CrossRef]
- Benedykciuk, E.; Denkowski, M.; Dmitruk, K. Learning-Based Material Classification in X-Ray Security Images. In Proceedings of the 15th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Volume 4: VISAPP, Valletta, Malta, 27–29 February 2020; Farinella, G.M., Radeva, P., Braz, J., Eds.; SciTePress: Setúbal Municipality, Portugal, 2020; Volume 4, pp. 284–291. [Google Scholar]
- Brumbaugh, K.; Royse, C.; Gregory, C.; Roe, K.; Greenberg, J.A.; Diallo, S.O. Material classification using convolution neural network (CNN) for x-ray based coded aperture diffraction system. In Anomaly Detection and Imaging with X-rays (ADIX) IV; SPIE: Bellingham, WA, USA, 2019; Volume 10999. [Google Scholar] [CrossRef]
- Bunrit, S.; Kerdprasop, N.; Kerdprasop, K. Evaluating on the Transfer Learning of CNN Architectures to a Construction Material Image Classification Task. Int. J. Mach. Learn. Comput. 2019, 9, 201–207. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Chen, Z.-Q.; Zhao, T.; Li, L. A curve-based material recognition method in MeV dual-energy X-ray imaging system. Nucl. Sci. Tech. 2016, 27, 25. [Google Scholar] [CrossRef]
- Andrews, J.; Morton, E.; Griffin, L. Detecting anomalous data using auto-encoders. Int. J. Mach. Learn. Comput. 2016, 6, 21. [Google Scholar]
- Jaccard, N.; Rogers, T.W.; Morton, E.J.; Griffin, L.D. Detection of concealed cars in complex cargo X-ray imagery using Deep Learning. J. X-Ray Sci. Technol. 2017, 25, 323–339. [Google Scholar] [CrossRef]
- Kundegorski, M.; Akcay, S.; Devereux, M.; Mouton, A.; Breckon, T. On using Feature Descriptors as Visual Words for Object Detection within X-ray Baggage Security Screening. In Proceedings of the 7th International Conference on Imaging for Crime Detection and Prevention, Madrid, Spain, 23–25 November 2016. [Google Scholar] [CrossRef]
- Miao, C.; Xie, L.; Wan, F.; Su, C.; Liu, H.; Jiao, J.; Ye, Q. SIXray: A Large-Scale Security Inspection X-Ray Benchmark for Prohibited Item Discovery in Overlapping Images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2119–2128. [Google Scholar]
- Roomi, M.M. Detection of Concealed Weapons in X-Ray Images Using Fuzzy K-NN. Int. J. Comput. Sci. Eng. Inf. Technol. 2012, 2, 187–196. [Google Scholar] [CrossRef]
- Akcay, S.; Breckon, T. Towards automatic threat detection: A survey of advances of deep learning within X-ray security imaging. arXiv 2020, arXiv:2001.01293. [Google Scholar] [CrossRef]
- Gaus, Y.F.A.; Bhowmik, N.; Breckon, T.P. On the Use of Deep Learning for the Detection of Firearms in X-ray Baggage Security Imagery. In Proceedings of the 2019 IEEE International Symposium on Technologies for Homeland Security (HST), Greater Boston, MA USA, 5–6 November 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar] [CrossRef]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Flitton, G.; Breckon, T.; Megherbi, N. A comparison of 3D interest point descriptors with application to airport baggage object detection in complex CT imagery. Pattern Recognit. 2013, 46, 2420–2436. [Google Scholar] [CrossRef]
- Bhowmik, N.; Gaus, Y.F.A.; Akçay, S.; Barker, J.W.; Breckon, T.P. On the impact of object and sub-component level seg-mentation strategies for supervised anomaly detection within x-ray security imagery. In Proceedings of the 2019 18th IEEE International Conference On Machine Learning And Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; Wani, M.A., Khoshgoftaar, T.M., Wang, D., Wang, H., Seliya, N., Eds.; IEEE: Piscataway, NJ, USA, 2019; pp. 986–991. [Google Scholar]
- Wang, Y.; Morariu, V.I.; Davis, L.S. Learning a Discriminative Filter Bank Within a CNN for Fine-Grained Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4148–4157. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Stan, T.; Thompson, Z.T.; Voorhees, P.W. Optimizing convolutional neural networks to perform semantic segmentation on large materials imaging datasets: X-ray tomography and serial sectioning. Mater. Charact. 2020, 160, 110119. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Roy, A.; Todorovic, S. A multi-scale CNN for affordance segmentation in RGB images. In ECCV (4). Lecture Notes in Computer Science; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; Volume 9908, pp. 186–201. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Goel, D.; Jain, S.; Vishwakarma, D.K.; Bansal, A. Automatic Image Colorization using U-Net. In Proceedings of the 12th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 6–8 June 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Billaut, V.; Rochemonteix, M.D.; Thibault, M. ColorUNet: A convolutional classification approach to colorization. arXiv 2018, arXiv:1811.03120. [Google Scholar]
- Nguyen-Quynh, T.-T.; Kim, S.-H.; Do, N.-T. Image Colorization Using the Global Scene-Context Style and Pixel-Wise Semantic Segmentation. IEEE Access 2020, 8, 214098–214114. [Google Scholar] [CrossRef]
- Di, Y.; Zhu, X.; Jin, X.; Dou, Q.; Zhou, W.; Duan, Q. Color-UNet++: A resolution for colorization of grayscale images using improved UNet++. Multimedia Tools Appl. 2021, 80, 35629–35648. [Google Scholar] [CrossRef]
- Zou, H.; Trevor, H. Regularization and Variable Selection via the Elastic Net. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2005, 67, 301–320. [Google Scholar] [CrossRef]
- X-ray Images of Hazardous Items. Available online: https://aihub.or.kr/aidata/33 (accessed on 25 March 2021).
- Griffin, L.D.; Caldwell, M.; Andrews, J.; Bohler, H. ‘Unexpected Item in the Bagging Area’: Anomaly Detection in X-Ray Security Images. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1539–1553. [Google Scholar] [CrossRef]
- Mery, D.; Riffo, V.; Zscherpel, U.; Mondragon, G.; Lillo, I.; Zuccar, I.; Lobel, H.; Carrasco, M. GDXray: The Database of X-ray Images for Nondestructive Testing. J. Nondestruct. Eval. 2015, 34, 42. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.; Sheikh, A.; Simoncelli, E. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar] [CrossRef]
- Chollet, F. Deep Learning with Python; Manning Publications: New York, NY, USA, 2017; ISBN 9781617294433. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Anwar, S.; Tahir, M.; Li, C.; Mian, A.; Khan, F.S.; Muzaffar, A.W. Image colorization: A survey and dataset. arXiv 2020, arXiv:2008.10774. [Google Scholar]
- Yagoub, B.; Ibrahem, H.; Salem, A.; Suh, J.-W.; Kang, H.S. X-ray image denoising for Cargo Dual Energy Inspection System. In Proceedings of the 2021 International Conference on Electronics, Information, and Communication (ICEIC), Jeju, Republic of Korea, 31 January–3 February 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Wang, H.W.; Xue, Y.J.; Ma, Y.L.; Hua, N.; Ma, H.Y. Determination of quantum toric error correction codethreshold using convolutional neural network decoders. Chin. Phys. B 2021, 31, 010303. [Google Scholar] [CrossRef]
- Rahman, S.; Rahman, M.; Abdullah-Al-Wadud, M.; Al-Quaderi, G.D.; Shoyaib, M. An adaptive gamma correction for image enhancement. EURASIP J. Image Video Process. 2016, 2016, 35. [Google Scholar] [CrossRef]
- Liu, D.; Liu, J.; Yuan, P.; Yu, F. A Data Augmentation Method for Prohibited Item X-Ray Pseudocolor Images in X-Ray Security Inspection Based on Wasserstein Generative Adversarial Network and Spatial-and-Channel Attention Block. Comput. Intell. Neurosci. 2022, 2022, 8172466. [Google Scholar] [CrossRef]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).