



Boundary-Aware Salient Object Detection in Optical Remote-Sensing Images


Abstract
:1. Introduction
- We propose a novel boundary-aware saliency model for salient object detection, in which our model tries to introduce the salient boundaries to precisely segment the salient objects from optical RSIs.
- We propose an effective edge module to provide boundary information for saliency detection, where boundary cues and object features are enhanced by the interaction between low-level spatial features and high-level semantic features.
- Extensive experiments are performed on the public dataset ORSSD, and the results show that our model performs better than the state-of-the-art saliency models, which demonstrates the effectiveness of the proposed model.
2. Related Works
2.1. Saliency Detection of Nature-Scene Images
2.2. Saliency Detection of Optical Remote-Scene Images
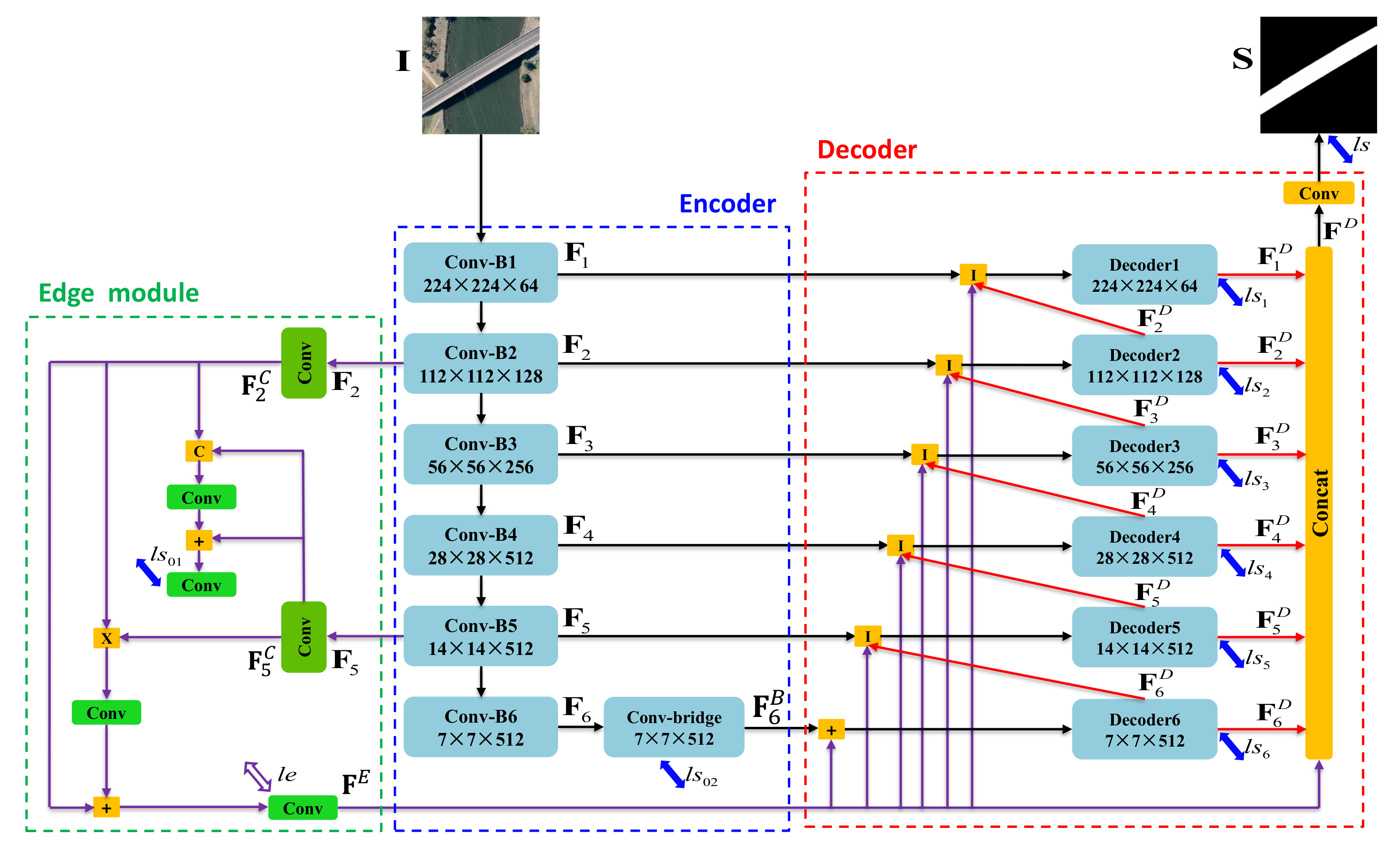
3. The Proposed Method
3.1. Overall Architecture
3.2. Feature Extraction
3.3. Edge Module
3.4. Feature Integration
3.5. Model Learning and Implementation
4. Experimental Results
4.1. Datasets and Evaluation Metrics
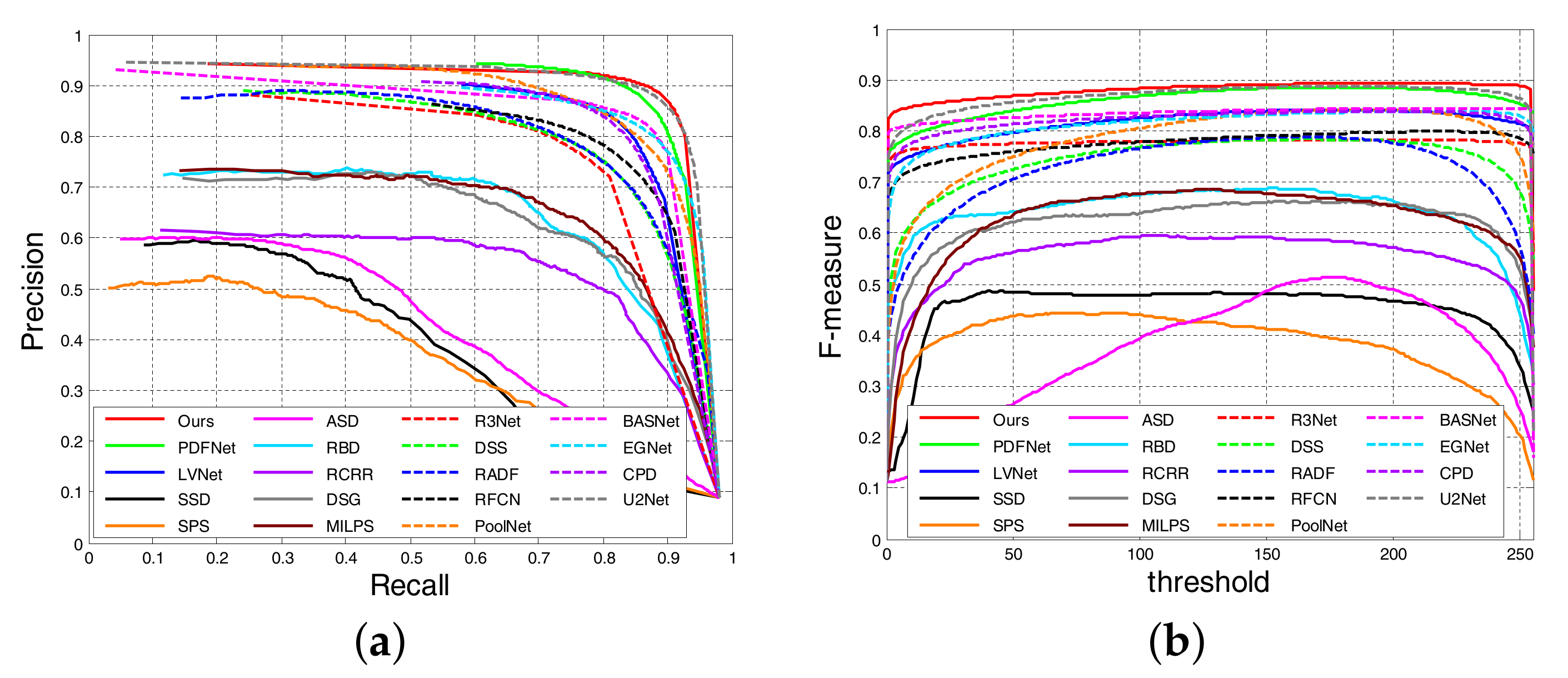
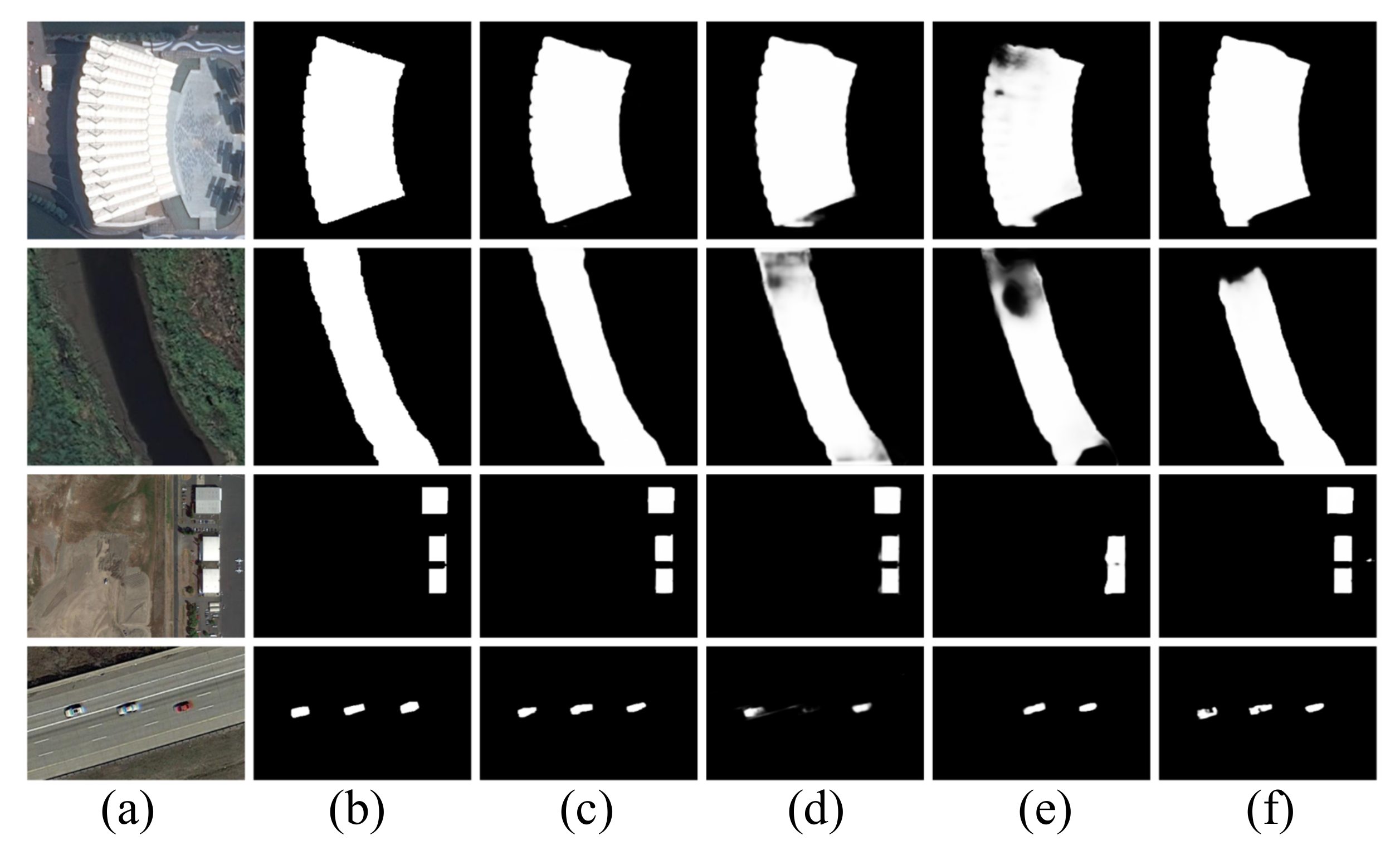
4.2. Comparison with the State of the Art
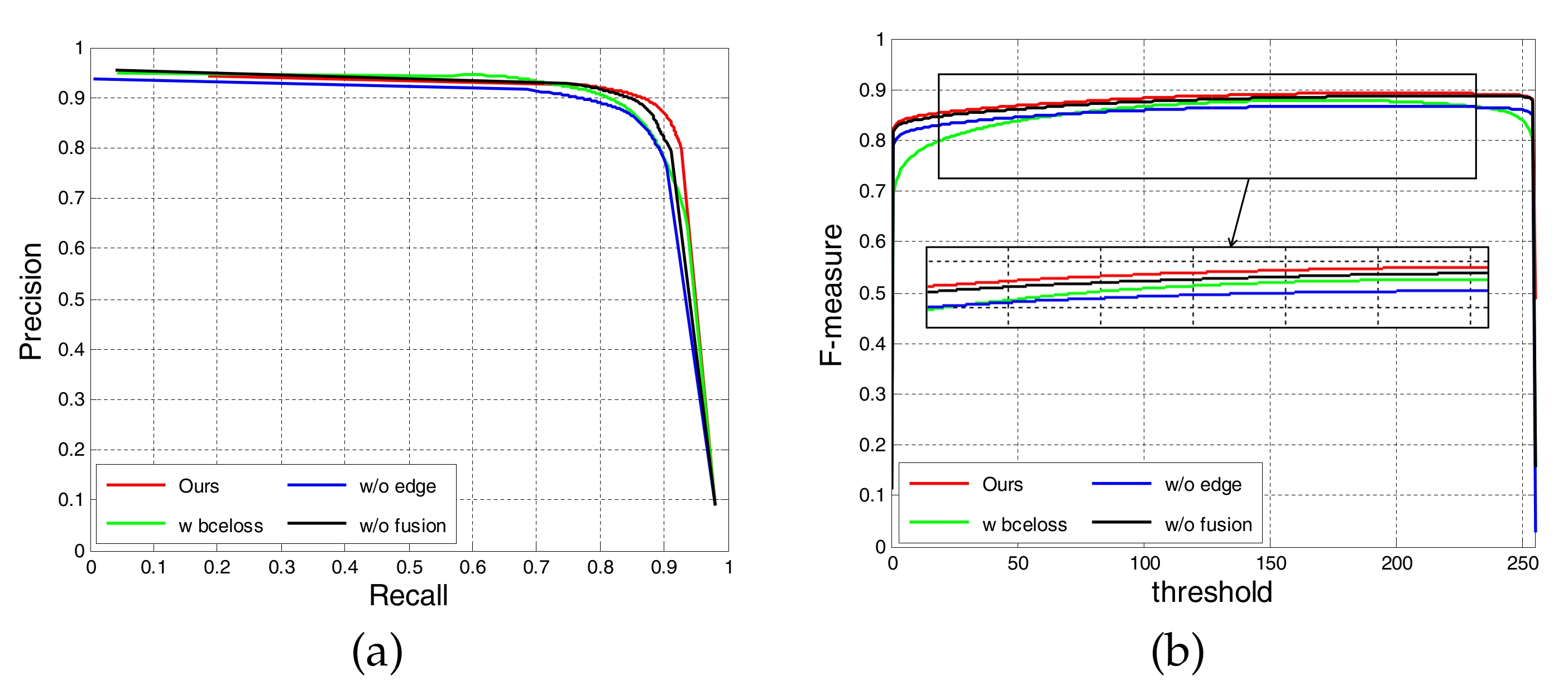
4.3. Ablation Studies
4.4. Failure Cases and Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Borji, A.; Cheng, M.M.; Hou, Q.; Jiang, H.; Li, J. Salient Object Detection: A Survey. Comput. Vis. Pattern Recognit. 2014, 5, 117–150. [Google Scholar] [CrossRef] [Green Version]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef] [Green Version]
- Zhou, X.; Liu, Z.; Sun, G.; Ye, L.; Wang, X. Improving saliency detection via multiple kernel boosting and adaptive fusion. IEEE Signal Process. Lett. 2016, 23, 517–521. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, X.; Ma, L.; Kwong, S.; Zhou, Y. Quaternion representation based visual saliency for stereoscopic image quality assessment. Signal Process. 2018, 145, 202–213. [Google Scholar] [CrossRef]
- Han, J.; Yao, X.; Cheng, G.; Feng, X.; Xu, D. P-CNN: Part-Based Convolutional Neural Networks for Fine-Grained Visual Categorization. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 579–590. [Google Scholar] [CrossRef]
- Khosravan, N.; Celik, H.; Turkbey, B.; Cheng, R.; McCreedy, E.; McAuliffe, M.; Bednarova, S.; Jones, E.; Chen, X.; Choyke, P.; et al. Gaze2Segment: A pilot study for integrating eye-tracking technology into medical image segmentation. In Medical Computer Vision and Bayesian and Graphical Models for Biomedical Imaging; Springer: Berlin/Heidelberg, Germany, 2016; pp. 94–104. [Google Scholar]
- Wang, W.; Lai, Q.; Fu, H.; Shen, J.; Ling, H.; Yang, R. Salient object detection in the deep learning era: An in-depth survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3239–3259. [Google Scholar] [CrossRef]
- Cheng, M.M.; Zhang, G.X.; Mitra, N.J.; Huang, X.; Hu, S.M. Global contrast based salient region detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; IEEE: New York, NY, USA, 2011; pp. 409–416. [Google Scholar]
- Perazzi, F.; Krähenbühl, P.; Pritch, Y.; Hornung, A. Saliency filters: Contrast based filtering for salient region detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; IEEE: New York, NY, USA, 2012; pp. 733–740. [Google Scholar]
- Zhu, W.; Liang, S.; Wei, Y.; Sun, J. Saliency optimization from robust background detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; IEEE: New York, NY, USA, 2014; pp. 2814–2821. [Google Scholar]
- Tong, N.; Lu, H.; Ruan, X.; Yang, M.H. Salient object detection via bootstrap learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; IEEE: New York, NY, USA, 2015; pp. 1884–1892. [Google Scholar]
- Jiang, H.; Wang, J.; Yuan, Z.; Wu, Y.; Zheng, N.; Li, S. Salient object detection: A discriminative regional feature integration approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; IEEE: New York, NY, USA, 2013; pp. 2083–2090. [Google Scholar]
- Yuan, Y.; Li, C.; Kim, J.; Cai, W.; Feng, D.D. Reversion correction and regularized random walk ranking for saliency detection. IEEE Trans. Image Process. 2017, 27, 1311–1322. [Google Scholar] [CrossRef] [Green Version]
- Hou, Q.; Cheng, M.M.; Hu, X.; Borji, A.; Tu, Z.; Torr, P.H. Deeply supervised salient object detection with short connections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 3203–3212. [Google Scholar]
- Zhao, J.X.; Liu, J.J.; Fan, D.P.; Cao, Y.; Yang, J.; Cheng, M.M. EGNet: Edge guidance network for salient object detection. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: New York, NY, USA, 2019; pp. 8779–8788. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. Basnet: Boundary-aware salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: New York, NY, USA, 2019; pp. 7479–7489. [Google Scholar]
- Wu, Z.; Su, L.; Huang, Q. Cascaded partial decoder for fast and accurate salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: New York, NY, USA, 2019; pp. 3907–3916. [Google Scholar]
- Wu, Z.; Su, L.; Huang, Q. Stacked cross refinement network for edge-aware salient object detection. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: New York, NY, USA, 2019; pp. 7264–7273. [Google Scholar]
- Chen, C.; Wei, J.; Peng, C.; Zhang, W.; Qin, H. Improved Saliency Detection in RGB-D Images Using Two-Phase Depth Estimation and Selective Deep Fusion. IEEE Trans. Image Process. 2020, 29, 4296–4307. [Google Scholar] [CrossRef]
- Chen, C.; Wang, G.; Peng, C.; Fang, Y.; Zhang, D.; Qin, H. Exploring Rich and Efficient Spatial Temporal Interactions for Real-Time Video Salient Object Detection. IEEE Trans. Image Process. 2021, 30, 3995–4007. [Google Scholar] [CrossRef]
- Deng, Z.; Hu, X.; Zhu, L.; Xu, X.; Qin, J.; Han, G.; Heng, P.A. R3net: Recurrent residual refinement network for saliency detection. In Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI), Stockholm, Sweden, 13–19 July 2018; AAAI Press: Menlo Park, CA, USA, 2018; pp. 684–690. [Google Scholar]
- Tu, Z.; Xia, T.; Li, C.; Wang, X.; Ma, Y.; Tang, J. RGB-T Image Saliency Detection via Collaborative Graph Learning. IEEE Trans. Multimed. 2020, 22, 160–173. [Google Scholar] [CrossRef] [Green Version]
- Cong, R.; Lei, J.; Fu, H.; Huang, Q.; Cao, X.; Hou, C. Co-saliency Detection for RGBD Images Based on Multi-constraint Feature Matching and Cross Label Propagation. IEEE Trans. Image Process. 2017, 27, 568–579. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Piao, Y.; Li, X.; Zhang, M.; Yu, J.; Lu, H. Saliency Detection via Depth-Induced Cellular Automata on Light Field. IEEE Trans. Image Process. 2020, 29, 1879–1889. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Cong, R.; Hou, J.; Zhang, S.; Qian, Y.; Kwong, S. Nested network with two-stream pyramid for salient object detection in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9156–9166. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Cong, R.; Guo, C.; Li, H.; Zhang, C.; Zheng, F.; Zhao, Y. A parallel down-up fusion network for salient object detection in optical remote sensing images. Neurocomputing 2020, 415, 411–420. [Google Scholar] [CrossRef]
- Zhao, D.; Wang, J.; Shi, J.; Jiang, Z. Sparsity-guided saliency detection for remote sensing images. J. Appl. Remote Sens. 2015, 9, 095055. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Du, B.; Chen, H.; Soomro, N.Q. Region-of-interest detection via superpixel-to-pixel saliency analysis for remote sensing image. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1752–1756. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhang, L.; Shi, W.; Liu, Y. Airport extraction via complementary saliency analysis and saliency-oriented active contour model. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1085–1089. [Google Scholar] [CrossRef]
- Zhang, Q.; Cong, R.; Li, C.; Cheng, M.M.; Fang, Y.; Cao, X.; Zhao, Y.; Kwong, S. Dense Attention Fluid Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Image Process. 2020, 30, 1305–1317. [Google Scholar] [CrossRef]
- Wei, Y.; Wen, F.; Zhu, W.; Sun, J. Geodesic saliency using background priors. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 29–42. [Google Scholar]
- Liu, T.; Yuan, Z.; Sun, J.; Wang, J.; Zheng, N.; Tang, X.; Shum, H.Y. Learning to detect a salient object. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 353–367. [Google Scholar]
- Huang, F.; Qi, J.; Lu, H.; Zhang, L.; Ruan, X. Salient object detection via multiple instance learning. IEEE Trans. Image Process. 2017, 26, 1911–1922. [Google Scholar] [CrossRef] [PubMed]
- Abdusalomov, A.; Mukhiddinov, M.; Djuraev, O.; Khamdamov, U.; Whangbo, T.K. Automatic salient object extraction based on locally adaptive thresholding to generate tactile graphics. Appl. Sci. 2020, 10, 3350. [Google Scholar] [CrossRef]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Wang, L.; Wang, L.; Lu, H.; Zhang, P.; Ruan, X. Salient object detection with recurrent fully convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1734–1746. [Google Scholar] [CrossRef]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Feng, J.; Jiang, J. A simple pooling-based design for real-time salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: New York, NY, USA, 2019; pp. 3917–3926. [Google Scholar]
- Li, E.; Xu, S.; Meng, W.; Zhang, X. Building extraction from remotely sensed images by integrating saliency cue. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 10, 906–919. [Google Scholar] [CrossRef]
- Lin, H.; Shi, Z.; Zou, Z. Fully convolutional network with task partitioning for inshore ship detection in optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1665–1669. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, Y.; Zhang, J. Saliency detection based on self-adaptive multiple feature fusion for remote sensing images. Int. J. Remote Sens. 2019, 40, 8270–8297. [Google Scholar] [CrossRef]
- Liu, Z.; Zhao, D.; Shi, Z.; Jiang, Z. Unsupervised Saliency Model with Color Markov Chain for Oil Tank Detection. Remote Sens. 2019, 11, 1089. [Google Scholar] [CrossRef] [Green Version]
- Dong, C.; Liu, J.; Xu, F.; Liu, C. Ship Detection from Optical Remote Sensing Images Using Multi-Scale Analysis and Fourier HOG Descriptor. Remote Sens. 2019, 11, 1529. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Cheng, M.M.; Zhang, X.Y.; Nie, G.Y.; Wang, M. DNA: Deeply supervised nonlinear aggregation for salient object detection. arXiv 2021, arXiv:1903.12476. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NA, USA, 27–30 June 2016; IEEE: New York, NY, USA, 2016; pp. 770–778. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. Med. Image Comput. Comput. Assist. Interv. 2015, 9351, 234–241. [Google Scholar]
- Liu, N.; Han, J.; Yang, M.H. PiCANet: Learning Pixel-wise Contextual Attention for Saliency Detection. Comput. Vis. Pattern Recognit. 2017, 3089–3098. [Google Scholar]
- Xie, S.; Tu, Z. Holistically-Nested Edge Detection. Int. J. Comput. Vis. 2015, 1395–1403. [Google Scholar]
- Fan, D.P.; Cheng, M.M.; Liu, Y.; Li, T.; Borji, A. Structure-measure: A new way to evaluate foreground maps. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4548–4557. [Google Scholar]
- Fan, D.P.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.M.; Borji, A. Enhanced-alignment Measure for Binary Foreground Map Evaluation. In Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI), Stockholm, Sweden, 13–19 July 2018; AAAI Press: Menlo Park, CA, USA, 2018; pp. 698–704. [Google Scholar]
- Zhou, L.; Yang, Z.; Zhou, Z.; Hu, D. Salient region detection using diffusion process on a two-layer sparse graph. IEEE Trans. Image Process. 2017, 26, 5882–5894. [Google Scholar] [CrossRef]
- Hu, X.; Zhu, L.; Qin, J.; Fu, C.W.; Heng, P.A. Recurrently aggregating deep features for salient object detection. In Proceedings of the Thirty-second AAAI conference on Artificial Intelligence (AAAI), New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ORSSD Dataset | ||||
|---|---|---|---|---|
| PDFNet [27] | 0.9112 | 0.8726 | 0.9608 | 0.0149 |
| LVNet[26] | 0.8815 | 0.8263 | 0.9456 | 0.0207 |
| SSD[28] | 0.5838 | 0.4460 | 0.7052 | 0.1126 |
| SPS[29] | 0.5758 | 0.3820 | 0.6472 | 0.1233 |
| ASD[30] | 0.5477 | 0.4701 | 0.7448 | 0.2119 |
| RBD [11] | 0.7662 | 0.6579 | 0.8501 | 0.0626 |
| RCRR [14] | 0.6849 | 0.5591 | 0.7651 | 0.1277 |
| DSG [51] | 0.7195 | 0.6238 | 0.7912 | 0.1041 |
| MILPS [34] | 0.7361 | 0.6519 | 0.8265 | 0.0913 |
| R3Net [22] | 0.8141 | 0.7456 | 0.8913 | 0.0399 |
| DSS [15] | 0.8262 | 0.7467 | 0.8860 | 0.0363 |
| RADF [52] | 0.8259 | 0.7619 | 0.9130 | 0.0382 |
| RFCN [37] | 0.8437 | 0.7742 | 0.9157 | 0.0293 |
| PoolNet [38] | 0.8551 | 0.8229 | 0.9368 | 0.0293 |
| BASNet [17] | 0.8963 | 0.8282 | 0.9346 | 0.0204 |
| EGNet [16] | 0.8774 | 0.8187 | 0.9165 | 0.0308 |
| CPD [18] | 0.8627 | 0.8033 | 0.9115 | 0.0297 |
| SCRN [19] | 0.9061 | 0.8846 | 0.9647 | 0.0157 |
| U2Net [36] | 0.9162 | 0.8738 | 0.9539 | 0.0166 |
| Ours | 0.9233 | 0.8786 | 0.9581 | 0.0120 |
| Model | ||||
|---|---|---|---|---|
| 0.8980 | 0.0182 | 0.9482 | 0.8612 | |
| 0.9054 | 0.0160 | 0.9501 | 0.8523 | |
| 0.9142 | 0.0149 | 0.9514 | 0.8690 | |
| Ours | 0.9233 | 0.0120 | 0.9581 | 0.8786 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, L.; Zhou, X.; Wang, L.; Zhang, J. Boundary-Aware Salient Object Detection in Optical Remote-Sensing Images. Electronics 2022, 11, 4200. https://doi.org/10.3390/electronics11244200
Yu L, Zhou X, Wang L, Zhang J. Boundary-Aware Salient Object Detection in Optical Remote-Sensing Images. Electronics. 2022; 11(24):4200. https://doi.org/10.3390/electronics11244200
Chicago/Turabian StyleYu, Longxuan, Xiaofei Zhou, Lingbo Wang, and Jiyong Zhang. 2022. "Boundary-Aware Salient Object Detection in Optical Remote-Sensing Images" Electronics 11, no. 24: 4200. https://doi.org/10.3390/electronics11244200
APA StyleYu, L., Zhou, X., Wang, L., & Zhang, J. (2022). Boundary-Aware Salient Object Detection in Optical Remote-Sensing Images. Electronics, 11(24), 4200. https://doi.org/10.3390/electronics11244200