
Dense Residual Transformer for Image Denoising




Abstract
:1. Introduction
- We propose an end-to-end Transformer-based network for image denoising, where both Transformer and convolutional layers are utilized to implement the fusion between the local and global features.
- We design a residual in residual architecture to assemble multiple Transformers and convolutional layers to achieve better performance in a deeper network.
- We introduce a depth-wise convolutional layer into Transformer, which is used to preserve the local information in the forward process of Transformer.
2. Related Work
2.1. CNN-Based Image Denoising
2.2. Vision Transformer
3. Proposed Work
3.1. Network Architecture
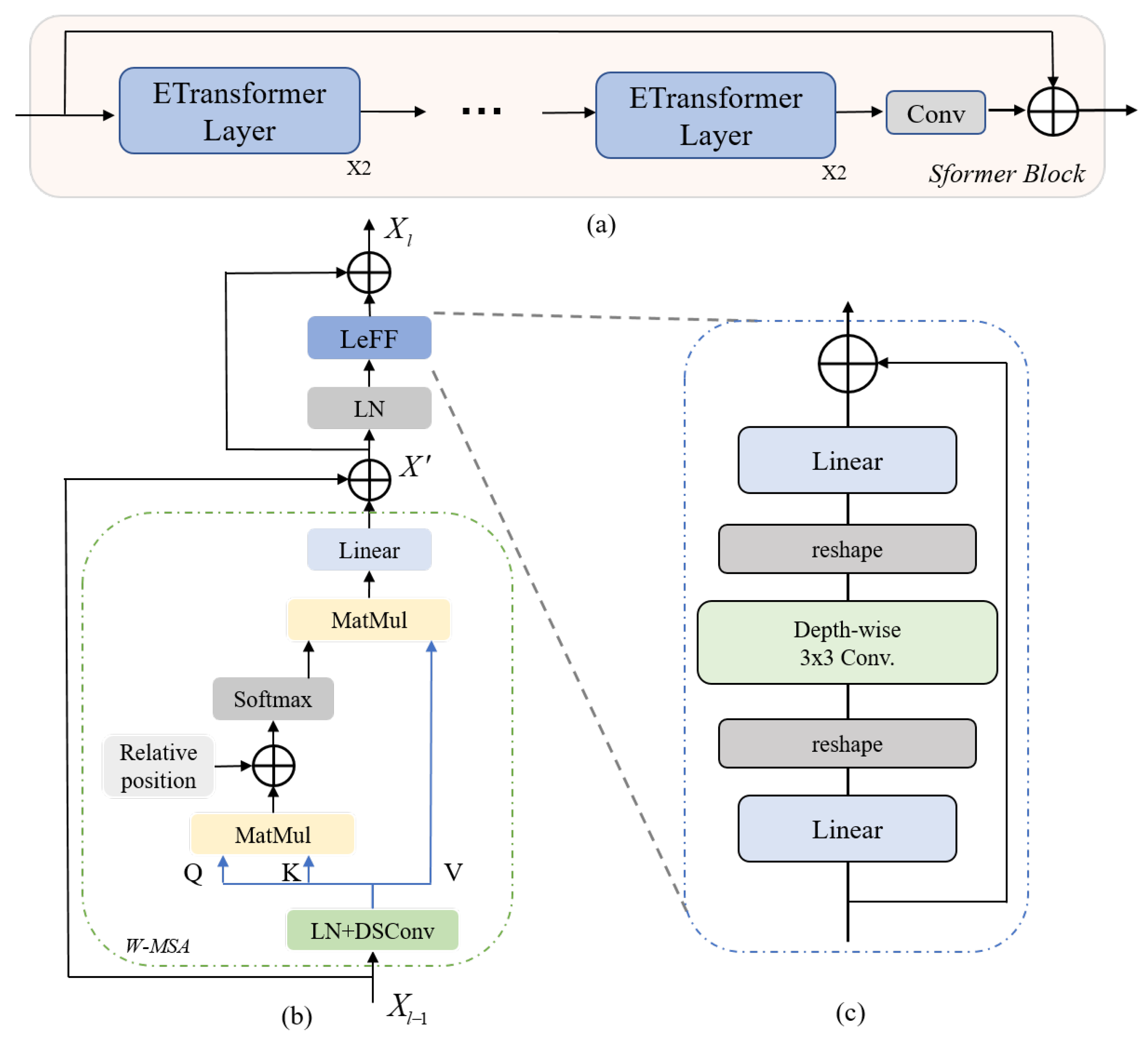
3.2. Sfomer Block
3.3. Dense Residual Skip Connection
4. Experiments
4.1. Experimental Settings
4.2. Synthetic Noisy Images
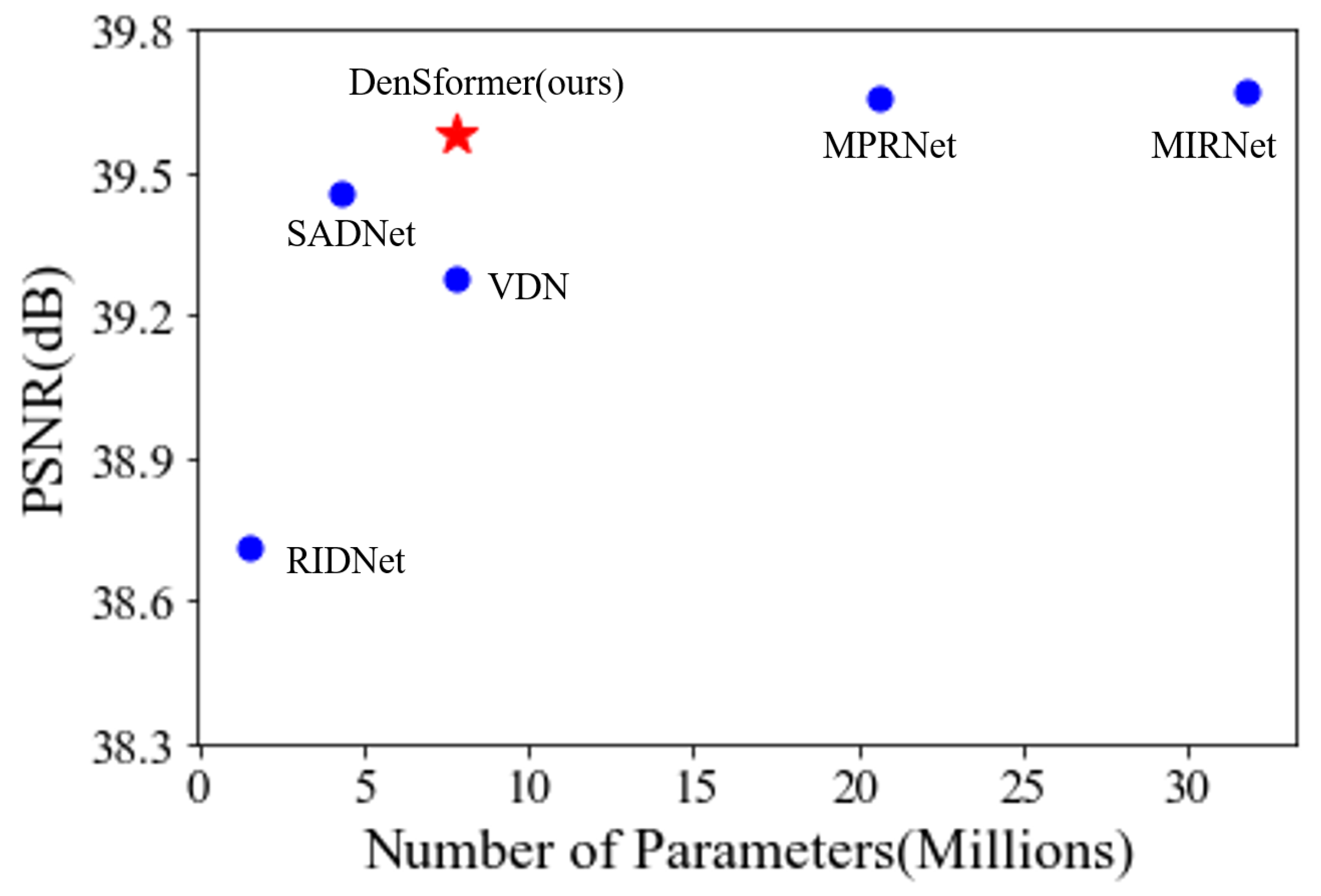
4.3. Real Noisy Images
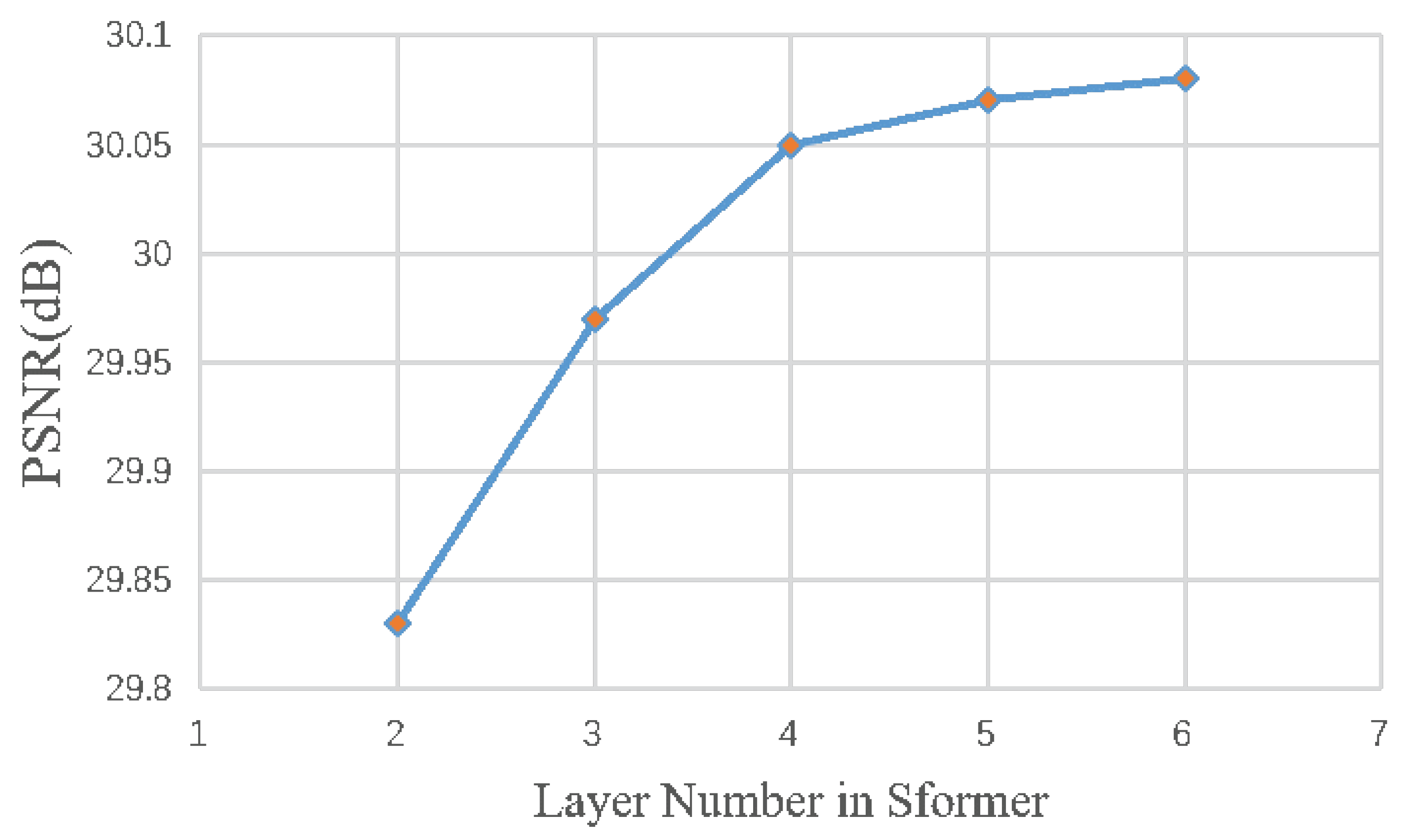
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Buades, A.; Coll, B.; Morel, J.M. A non-local algorithm for image denoising. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 60–65. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image Denoising by Sparse 3-D Transform-Domain Collaborative Filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 June 2017; pp. 1132–1140. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual Dense Network for Image Restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2480–2495. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the 31st Conference on Neural Information Processing System, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision (ICCV), Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In International Conference on Machine Learning; PMLR: London, UK, 2021; pp. 10347–10357. [Google Scholar]
- Chen, Y.; Pock, T. Trainable Nonlinear Reaction Diffusion: A Flexible Framework for Fast and Effective Image Restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1256–1272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [Green Version]
- Lin, M.-H.; Hou, Z.-X.; Cheng, K.-H.; Wu, C.-H.; Peng, Y.-T. Image Denoising Using Adaptive and Overlapped Average Filtering and Mixed-Pooling Attention Refinement Networks. Mathematics 2021, 9, 1130. [Google Scholar] [CrossRef]
- Liu, P.; Zhang, H.; Zhang, K.; Lin, L.; Zuo, W. Multi-level Wavelet-CNN for Image Restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 773–782. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a Fast and Flexible Solution for CNN-Based Image Denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef] [Green Version]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Learning Enriched Features for Real Image Restoration and Enhancement. In Proceedings of the Europeon Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 492–511. [Google Scholar]
- Liu, Y.; Sun, G.; Qiu, Y.; Zhang, L.; Chhatkuli, A.; Gool, L.V. Transformer in Convolutional Neural Networks. arXiv 2021, arXiv:2106.03180. [Google Scholar]
- Li, Y.; Zhang, K.; Cao, J.; Timofte, R.; Gool, L.V. LocalViT: Bringing Locality to Vision Transformers. arXiv 2021, arXiv:2104.05707. [Google Scholar]
- Hu, C.; Wang, Y.Y.; Chen, J.; Jian, D.S.; Zhang, X.P.; Tian, Q.; Wang, M.N. Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation. arXiv 2021, arXiv:2105.05537. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 6881–6890. [Google Scholar]
- Tete, X.; Singh, M.; Mintun, E.; Darrell, T.; Dollár, P.; Girshick, R.B. Early Convolutions Help Transformers See Better. arXiv 2021, arXiv:2106.14881. [Google Scholar]
- Wang, S.; Zhou, T.; Lu, Y.; Di, H. Detail-Preserving Transformer for Light Field Image Super-Resolution. arXiv 2022, arXiv:2201.00346. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; Gao, W. Pre-Trained Image Processing Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 12299–12310. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H. Uformer: A General U-Shaped Transformer for Image Restoration. arXiv 2021, arXiv:2106.03106. [Google Scholar]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss Functions for Image Restoration With Neural Networks. IEEE Trans. Comput. Imaging 2017, 3, 47–57. [Google Scholar] [CrossRef]
- Ramachandran, P.; Parmar, N.; Vaswani, A.; Bello, I.; Levskaya, A.; Shlens, J. Stand-Alone Self-Attention in Vision Models. arXiv 2019, arXiv:1906.05909. [Google Scholar]
- Vaswani, A.; Ramachandran, P.; Srinivas, A.; Parmar, N.; Hechtman, B.; Shlens, J. Scaling Local Self-Attention for Parameter Efficient Visual Backbones. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 12894–12904. [Google Scholar]
- Abdelhamed, A.; Lin, S.; Brown, M.S. A High-Quality Denoising Dataset for Smartphone Cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 19–21 June 2018; pp. 1692–1700. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Khan, A.; Jin, W.; Haider, A.; Rahman, M.; Wang, D. Adversarial Gaussian Denoiser for Multiple-Level Image Denoising. Sensors 2021, 21, 2998. [Google Scholar] [CrossRef]
- Plotz, T.; Roth, S. Benchmarking denoising algorithms with real photographs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 1586–1595. [Google Scholar]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning Deep CNN Denoiser Prior for Image Restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1–10. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. MemNet: A Persistent Memory Network for Image Restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4549–4557. [Google Scholar]
- Guo, S.; Yan, Z.; Zhang, K.; Zuo, W.; Zhang, L. Toward Convolutional Blind Denoising of Real Photographs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1712–1722. [Google Scholar]
- Anwar, S.; Barnes, N. Real Image Denoising With Feature Attention. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 3155–3164. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Multi-Stage Progressive Image Restoration. arXiv 2021, arXiv:2102.02808. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Yue, Z.; Yong, H.; Zhao, Q.; Zhang, L.; Meng, D. Variational denoising network: Toward blind noise modeling and removal. arxiv 2019, arXiv:1908.11314. [Google Scholar]
- Chang, M.; Li, Q.; Feng, H.; Xu, Z. Spatial-adaptive network for single image denoising. arXiv 2020, arXiv:2001.10291. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Set12 | Kodak24 | BSD68 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 30 | 50 | 70 | 30 | 50 | 70 | 30 | 50 | 70 | |
| BM3D [2] | 29.13 | 26.72 | 25.22 | 29.13 | 26.99 | 25.73 | 27.76 | 25.62 | 24.44 |
| TNRD [10] | 28.63 | 26.81 | 24.12 | 28.87 | 27.20 | 24.95 | 27.66 | 25.97 | 23.83 |
| IRCNN [31] | 29.45 | 27.14 | N/A | 29.53 | 27.45 | N/A | 28.26 | 26.15 | N/A |
| DnCNN [11] | 29.53 | 27.18 | 25.52 | 29.62 | 27.51 | 26.08 | 28.36 | 26.23 | 24.90 |
| MemNet [32] | 29.63 | 27.38 | 25.90 | 29.72 | 27.68 | 26.42 | 28.43 | 26.35 | 25.09 |
| MWCNN [13] | N/A | 27.74 | N/A | N/A | N/A | N/A | N/A | 26.53 | N/A |
| FFDNet [14] | 29.61 | 27.32 | 25.81 | 29.70 | 27.63 | 26.34 | 28.39 | 26.30 | 25.04 |
| RDN [4] | 29.94 | 27.60 | 26.05 | 30.00 | 27.85 | 26.54 | 28.56 | 26.41 | 25.10 |
| DenSformer | 29.97 | 27.88 | 26.24 | 30.24 | 27.91 | 26.76 | 28.73 | 26.52 | 25.24 |
| Method | Kodak24 | BSD68 | McMaster | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 30 | 50 | 70 | 30 | 50 | 70 | 30 | 50 | 70 | |
| BM3D [2] | 30.89 | 28.63 | 27.27 | 29.73 | 27.38 | 26.00 | 30.71 | 28.51 | 26.99 |
| TNRD [10] | 28.83 | 27.17 | 24.94 | 27.63 | 25.96 | 23.83 | N/A | 27.35 | N/A |
| IRCNN [31] | 31.24 | 28.93 | N/A | 30.22 | 27.86 | N/A | 31.11 | 28.91 | N/A |
| DnCNN [11] | 31.39 | 29.16 | 27.64 | 30.40 | 28.01 | 26.56 | 30.82 | 28.62 | 27.10 |
| MemNet [32] | 29.67 | 27.65 | 26.40 | 28.39 | 26.33 | 25.08 | N/A | 27.63 | 26.11 |
| FFDNet [14] | 31.39 | 29.10 | 27.68 | 30.31 | 27.96 | 26.53 | N/A | 29.18 | 27.66 |
| RDN [4] | 31.94 | 29.66 | 28.20 | 30.67 | 28.31 | 26.85 | 32.39 | 30.19 | 27.98 |
| DenSformer | 32.51 | 30.07 | 28.59 | 31.56 | 28.94 | 26.46 | 33.58 | 31.16 | 27.49 |
| Method | Parameters (MB) | SIDD Dataset | Dnd Dataset | ||
|---|---|---|---|---|---|
| PSNR (dB) | SSIM | PSNR (dB) | SSIM | ||
| BM3D [2] | - | 25.65 | 0.685 | 34.51 | 0.851 |
| CBDNet [33] | 4.3 | 30.78 | 0.801 | 38.06 | 0.942 |
| RIDNet [34] | 1.5 | 38.71 | 0.951 | 39.26 | 0.953 |
| VDN [37] | 7.8 | 39.28 | 0.956 | 39.38 | 0.952 |
| SADNet [38] | 4.3 | 39.46 | 0.957 | 39.59 | 0.952 |
| MPRNet [35] | 20.1 | 39.71 | 0.958 | 39.80 | 0.954 |
| Uformer [23] | 20.6 | 39.77 | 0.970 | 39.96 | 0.956 |
| DenSformer | 7.8 | 39.68 | 0.958 | 39.87 | 0.955 |
| Model | Local Connection | Global Connection | Cross Connection | PSNR | Training Time /Epoch |
|---|---|---|---|---|---|
| Cross | 🗸 | - | 🗸 | 30.03 | 1.84 h |
| Local | 🗸 | 🗸 | - | 30.02 | 1.95 h |
| Dense | 🗸 | 🗸 | 🗸 | 30.07 | 2.00 h |
| Model | DSConv | Linear | MLP Layer | LeFF Layer | PSNR |
|---|---|---|---|---|---|
| Vanilla | - | 🗸 | 🗸 | - | 29.86 |
| Vanilla-C | 🗸 | - | 🗸 | - | 29.84 |
| LeWin | - | 🗸 | - | 🗸 | 29.95 |
| Enhanced LeWin | 🗸 | - | - | 🗸 | 30.07 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, C.; Jin, S.; Liu, M.; Ban, X. Dense Residual Transformer for Image Denoising. Electronics 2022, 11, 418. https://doi.org/10.3390/electronics11030418
Yao C, Jin S, Liu M, Ban X. Dense Residual Transformer for Image Denoising. Electronics. 2022; 11(3):418. https://doi.org/10.3390/electronics11030418
Chicago/Turabian StyleYao, Chao, Shuo Jin, Meiqin Liu, and Xiaojuan Ban. 2022. "Dense Residual Transformer for Image Denoising" Electronics 11, no. 3: 418. https://doi.org/10.3390/electronics11030418
APA StyleYao, C., Jin, S., Liu, M., & Ban, X. (2022). Dense Residual Transformer for Image Denoising. Electronics, 11(3), 418. https://doi.org/10.3390/electronics11030418