
A Review of Deep Learning Methods for Compressed Sensing Image Reconstruction and Its Medical Applications



{kind=link}
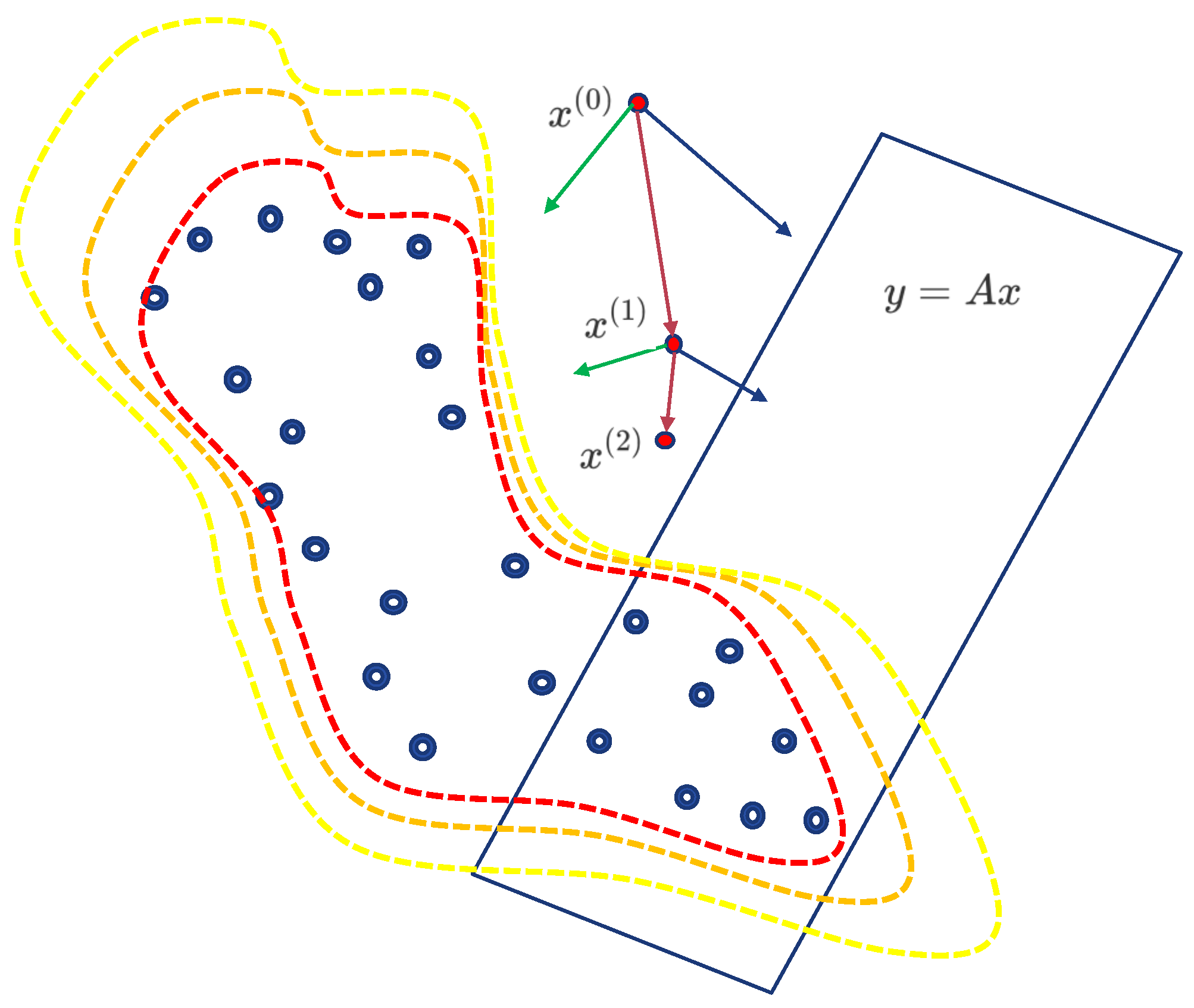{kind=link}
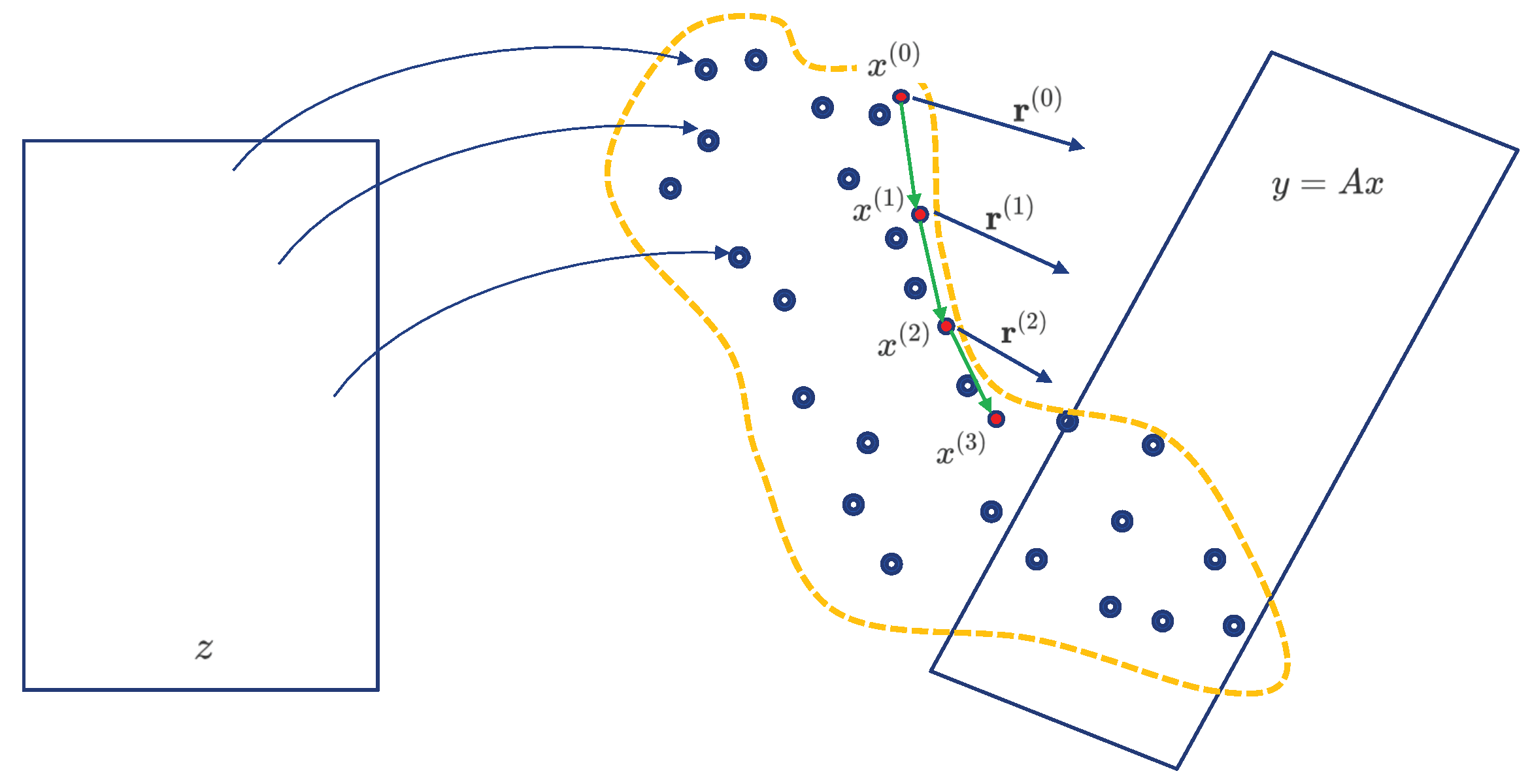{kind=link}
Abstract
:1. Introduction
- We proposed a framework which unifies traditional iterative algorithms and deep learning approaches for CS reconstruction and its medical applications.
- We reviewed many works on reconstruction of CS, CT, MRI and PET, and analyzed them based on the proposed framework.
- Through the proposed framework, we built relationship between different reconstruction methods of deep learning and indicated that the key to solve CS problem and its medical applications is how to depict the image prior.
2. Deep Learning Methods for Compressed Sensing
2.1. Overview
2.2. Model-Based Methods with Learnable Parts
2.3. Neural Networks as Image Projections
2.4. Latent Variable Search of Generative Models
2.5. Neural Networks Based Probability Models
2.6. Unsupervised Methods
2.7. Discussion
3. Deep Learning Methods for Computed Tomography
3.1. Overview
3.2. Model-Based Methods with Learnable Parts
3.3. Neural Networks as Image Projections
3.4. Discussion
4. Deep Learning Methods for Magnetic Resonance Imaging
4.1. Overview
4.2. Model-Based Methods with Learnable Parts
4.2.1. Non-Parallel Imaging
4.2.2. Parallel Imaging
4.3. Neural Networks as Image Projections
4.3.1. Non-Parallel Imaging
4.3.2. Parallel Imaging
4.4. Latent Variable Search of Generative Models
4.5. Neural Networks Based Probability Models
4.6. Unsupervised Methods
4.7. Discussion
5. Deep Learning Methods for Positron-Emission Tomography
5.1. Overview
5.2. Neural Networks as Image Projections
5.3. Latent Variable Search of Generative Models
5.4. Unsupervised Methods
5.5. Discussion
6. Discussion and Future Directions
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Liang, D.; Cheng, J.; Ke, Z.; Ying, L. Deep mri reconstruction: Unrolled optimization algorithms meet neural networks. arXiv 2019, arXiv:1907.11711. [Google Scholar]
- Rudin, L.I.; Osher, S.; Fatemi, E. Nonlinear total variation based noise removal algorithms. Phys. D Nonlinear Phenom. 1992, 60, 259–268. [Google Scholar] [CrossRef]
- Gregor, K.; LeCun, Y. Learning fast approximations of sparse coding. In Proceedings of the 27th International Conference on International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 399–406. [Google Scholar]
- Kamilov, U.S.; Mansour, H. Learning optimal nonlinearities for iterative thresholding algorithms. IEEE Signal Process. Lett. 2016, 23, 747–751. [Google Scholar] [CrossRef] [Green Version]
- Bostan, E.; Kamilov, U.S.; Waller, L. Learning-based image reconstruction via parallel proximal algorithm. IEEE Signal Process. Lett. 2018, 25, 989–993. [Google Scholar] [CrossRef] [Green Version]
- Mahapatra, D.; Mukherjee, S.; Seelamantula, C.S. Deep sparse coding using optimized linear expansion of thresholds. arXiv 2017, arXiv:1705.07290. [Google Scholar]
- Zhang, J.; Ghanem, B. ISTA-Net: Interpretable optimization-inspired deep network for image compressive sensing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 1828–1837. [Google Scholar]
- Mukherjee, S.; Mahapatra, D.; Seelamantula, C.S. DNNs for sparse coding and dictionary learning. In Proceedings of the NIPS Bayesian Deep Learning Workshop, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Lu, X.; Dong, W.; Wang, P.; Shi, G.; Xie, X. Convcsnet: A convolutional compressive sensing framework based on deep learning. arXiv 2018, arXiv:1801.10342. [Google Scholar]
- Pokala, P.K.; Mahurkar, A.G.; Seelamantula, C.S. FirmNet: A Sparsity Amplified Deep Network for Solving Linear Inverse Problems. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2982–2986. [Google Scholar]
- Perdios, D.; Besson, A.; Rossinelli, P.; Thiran, J.P. Learning the weight matrix for sparsity averaging in compressive imaging. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3056–3060. [Google Scholar]
- Zhang, X.; Yuan, X.; Carin, L. Nonlocal low-rank tensor factor analysis for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 8232–8241. [Google Scholar]
- Mousavi, A.; Patel, A.B.; Baraniuk, R.G. A deep learning approach to structured signal recovery. In Proceedings of the 2015 53rd Annual Allerton Conference on Communication, Control, and Computing (Allerton), Champaign, IL, USA, 30 September–2 October 2015; pp. 1336–1343. [Google Scholar]
- Kulkarni, K.; Lohit, S.; Turaga, P.; Kerviche, R.; Ashok, A. Reconnet: Non-iterative reconstruction of images from compressively sensed measurements. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 449–458. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef]
- Mousavi, A.; Baraniuk, R.G. Learning to invert: Signal recovery via deep convolutional networks. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2272–2276. [Google Scholar]
- Shi, W.; Jiang, F.; Zhang, S.; Zhao, D. Deep networks for compressed image sensing. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 877–882. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Yao, H.; Dai, F.; Zhang, S.; Zhang, Y.; Tian, Q.; Xu, C. Dr2-net: Deep residual reconstruction network for image compressive sensing. Neurocomputing 2019, 359, 483–493. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Bai, H.; Zhao, L.; Zhao, Y. Cascaded reconstruction network for compressive image sensing. EURASIP J. Image Video Process. 2018, 2018, 77. [Google Scholar] [CrossRef]
- Huang, H.; Nie, G.; Zheng, Y.; Fu, Y. Image restoration from patch-based compressed sensing measurement. Neurocomputing 2019, 340, 145–157. [Google Scholar] [CrossRef]
- Xie, X.; Wang, C.; Du, J.; Shi, G. Full image recover for block-based compressive sensing. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 1–6. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Lohit, S.; Kulkarni, K.; Kerviche, R.; Turaga, P.; Ashok, A. Convolutional neural networks for noniterative reconstruction of compressively sensed images. IEEE Trans. Comput. Imaging 2018, 4, 326–340. [Google Scholar] [CrossRef] [Green Version]
- Du, J.; Xie, X.; Wang, C.; Shi, G. Perceptual compressive sensing. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Guangzhou, China, 23–26 November 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 268–279. [Google Scholar]
- Zur, Y.; Adler, A. Deep Learning of Compressed Sensing Operators with Structural Similarity Loss. arXiv 2019, arXiv:1906.10411. [Google Scholar]
- Zhang, Z.; Gao, D.; Xie, X.; Shi, G. Dual-Channel Reconstruction Network for Image Compressive Sensing. Sensors 2019, 19, 2549. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, K.; Zhang, Z.; Ren, F. Lapran: A scalable laplacian pyramid reconstructive adversarial network for flexible compressive sensing reconstruction. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 485–500. [Google Scholar]
- Shi, W.; Jiang, F.; Liu, S.; Zhao, D. Scalable Convolutional Neural Network for Image Compressed Sensing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 12290–12299. [Google Scholar]
- Chen, D.; Davies, M.E. Deep Decomposition Learning for Inverse Imaging Problems. arXiv 2019, arXiv:1911.11028. [Google Scholar]
- Li, W.; Liu, F.; Jiao, L.; Hu, F. Multi-Scale Residual Reconstruction Neural Network with Non-Local Constraint. IEEE Access 2019, 7, 70910–70918. [Google Scholar] [CrossRef]
- Rick Chang, J.; Li, C.L.; Poczos, B.; Vijaya Kumar, B.; Sankaranarayanan, A.C. One Network to Solve Them All–Solving Linear Inverse Problems Using Deep Projection Models. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5888–5897. [Google Scholar]
- Zhao, C.; Zhang, J.; Wang, R.; Gao, W. CREAM: CNN-REgularized ADMM framework for compressive-sensed image reconstruction. IEEE Access 2018, 6, 76838–76853. [Google Scholar] [CrossRef]
- Kelly, B.; Matthews, T.P.; Anastasio, M.A. Deep learning-guided image reconstruction from incomplete data. arXiv 2017, arXiv:1709.00584. [Google Scholar]
- Metzler, C.; Mousavi, A.; Baraniuk, R. Learned D-AMP: Principled neural network based compressive image recovery. Adv. Neural Inf. Process. Syst. 2017, 30, 1772–1783. [Google Scholar]
- Zhou, S.; He, Y.; Liu, Y.; Li, C. Multi-Channel Deep Networks for Block-Based Image Compressive Sensing. arXiv 2019, arXiv:1908.11221. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aggarwal, H.K.; Mani, M.P.; Jacob, M. Modl: Model-based deep learning architecture for inverse problems. IEEE Trans. Med. Imaging 2018, 38, 394–405. [Google Scholar] [CrossRef] [PubMed]
- Diamond, S.; Sitzmann, V.; Heide, F.; Wetzstein, G. Unrolled optimization with deep priors. arXiv 2017, arXiv:1705.08041. [Google Scholar]
- Adler, J.; Öktem, O. Learned primal-dual reconstruction. IEEE Trans. Med. Imaging 2018, 37, 1322–1332. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Q.; Chen, Y. Extra Proximal-Gradient Inspired Non-local Network. arXiv 2019, arXiv:1911.07144. [Google Scholar]
- Raj, A.; Li, Y.; Bresler, Y. GAN-Based Projector for Faster Recovery with Convergence Guarantees in Linear Inverse Problems. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 5602–5611. [Google Scholar]
- Zhang, M.; Yuan, Y.; Zhang, F.; Wang, S.; Wang, S.; Liu, Q. Multi-Noise and Multi-Channel Derived Prior Information for Grayscale Image Restoration. IEEE Access 2019, 7, 150082–150092. [Google Scholar] [CrossRef]
- Liu, P.; Zhang, H.; Zhang, K.; Lin, L.; Zuo, W. Multi-level wavelet-CNN for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 19–21 June 2018; pp. 773–782. [Google Scholar]
- He, Z.; Zhou, J.; Liang, D.; Wang, Y.; Liu, Q. Learning Priors in High-frequency Domain for Inverse Imaging Reconstruction. arXiv 2019, arXiv:1910.11148. [Google Scholar]
- Bora, A.; Jalal, A.; Price, E.; Dimakis, A.G. Compressed sensing using generative models. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 537–546. [Google Scholar]
- Dhar, M.; Grover, A.; Ermon, S. Modeling sparse deviations for compressed sensing using generative models. arXiv 2018, arXiv:1807.01442. [Google Scholar]
- Kabkab, M.; Samangouei, P.; Chellappa, R. Task-aware compressed sensing with generative adversarial networks. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Chen, L.; Yang, H. Generative Imaging and Image Processing via Generative Encoder. arXiv 2019, arXiv:1905.13300. [Google Scholar]
- Xu, S.; Zeng, S.; Romberg, J. Fast Compressive Sensing Recovery Using Generative Models with Structured Latent Variables. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2967–2971. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2180–2188. [Google Scholar]
- Wu, Y.; Rosca, M.; Lillicrap, T. Deep compressed sensing. arXiv 2019, arXiv:1905.06723. [Google Scholar]
- Dave, A.; Kumar, A.; Mitra, K. Compressive image recovery using recurrent generative model. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 1702–1706. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Dave, A.; Vadathya, A.K.; Subramanyam, R.; Baburajan, R.; Mitra, K. Solving inverse computational imaging problems using deep pixel-level prior. IEEE Trans. Comput. Imaging 2018, 5, 37–51. [Google Scholar] [CrossRef] [Green Version]
- Van den Oord, A.; Kalchbrenner, N.; Vinyals, O.; Espeholt, L.; Graves, A.; Kavukcuoglu, K. Conditional image generation with pixelcnn decoders. arXiv 2016, arXiv:1606.05328. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Deep image prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 9446–9454. [Google Scholar]
- Van Veen, D.; Jalal, A.; Soltanolkotabi, M.; Price, E.; Vishwanath, S.; Dimakis, A.G. Compressed sensing with deep image prior and learned regularization. arXiv 2018, arXiv:1806.06438. [Google Scholar]
- Ravula, S.; Dimakis, A.G. One-dimensional deep image prior for time series inverse problems. arXiv 2019, arXiv:1904.08594. [Google Scholar]
- Leong, O.; Sakla, W. Low Shot Learning with Untrained Neural Networks for Imaging Inverse Problems. arXiv 2019, arXiv:1910.10797. [Google Scholar]
- Kobler, E.; Muckley, M.; Chen, B.; Knoll, F.; Hammernik, K.; Pock, T.; Sodickson, D.; Otazo, R. Variational deep learning for low-dose computed tomography. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 6687–6691. [Google Scholar]
- Zhang, H.; Dong, B.; Liu, B. JSR-Net: A deep network for joint spatial-radon domain CT reconstruction from incomplete data. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3657–3661. [Google Scholar]
- Boublil, D.; Zibulevsky, M.; Elad, M. Compressed Sensing and Computed Tomography with Deep Neural Networks. 2015. Available online: https://pdfs.semanticscholar.org/c1de/cfd99ce8affed9fef1ae9292a0f242493813.pdf (accessed on 11 January 2022).
- Zhao, J.; Chen, Z.; Zhang, L.; Jin, X. Few-view CT reconstruction method based on deep learning. In Proceedings of the 2016 IEEE Nuclear Science Symposium, Medical Imaging Conference and Room-Temperature Semiconductor Detector Workshop (NSS/MIC/RTSD), Strasbourg, France, 29 October–6 November 2016; pp. 1–4. [Google Scholar]
- Zhang, H.; Li, L.; Qiao, K.; Wang, L.; Yan, B.; Li, L.; Hu, G. Image prediction for limited-angle tomography via deep learning with convolutional neural network. arXiv 2016, arXiv:1607.08707. [Google Scholar]
- Jin, K.H.; McCann, M.T.; Unser, M. BPConvNet for Compressed Sensing Recovery in Bioimaging. 2016. Available online: http://spars2017.lx.it.pt/index_files/papers/SPARS2017_Paper_119.pdf (accessed on 11 January 2022).
- Han, Y.S.; Yoo, J.; Ye, J.C. Deep residual learning for compressed sensing CT reconstruction via persistent homology analysis. arXiv 2016, arXiv:1611.06391. [Google Scholar]
- Han, Y.; Ye, J.C. Framing U-Net via deep convolutional framelets: Application to sparse-view CT. IEEE Trans. Med. Imaging 2018, 37, 1418–1429. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, Q.; Yan, P.; Kalra, M.K.; Wang, G. CT image denoising with perceptive deep neural networks. arXiv 2017, arXiv:1702.07019. [Google Scholar]
- Choi, K.; Kim, S.W.; Lim, J.S. Real-time image reconstruction for low-dose CT using deep convolutional generative adversarial networks (GANs). In Medical Imaging 2018: Physics of Medical Imaging; International Society for Optics and Photonics: Bellingham, WA, USA, 2018; Volume 10573, p. 1057332. [Google Scholar]
- Gu, J.; Ye, J.C. Multi-scale wavelet domain residual learning for limited-angle CT reconstruction. arXiv 2017, arXiv:1703.01382. [Google Scholar]
- Ye, D.H.; Buzzard, G.T.; Ruby, M.; Bouman, C.A. Deep back projection for sparse-view CT reconstruction. In Proceedings of the 2018 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Anaheim, CA, USA, 26–29 November 2018; pp. 1–5. [Google Scholar]
- Dong, X.; Vekhande, S.; Cao, G. Sinogram interpolation for sparse-view micro-CT with deep learning neural network. In Medical Imaging 2019: Physics of Medical Imaging; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 10948, p. 109482O. [Google Scholar]
- Li, Z.; Cai, A.; Wang, L.; Zhang, W.; Tang, C.; Li, L.; Liang, N.; Yan, B. Promising Generative Adversarial Network Based Sinogram Inpainting Method for Ultra-Limited-Angle Computed Tomography Imaging. Sensors 2019, 19, 3941. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Würfl, T.; Ghesu, F.C.; Christlein, V.; Maier, A. Deep learning computed tomography. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Athens, Greece, 17–21 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 432–440. [Google Scholar]
- Chen, H.; Zhang, Y.; Zhou, J.; Wang, G. Deep learning for low-dose CT. In Developments in X-ray Tomography XI; International Society for Optics and Photonics: Bellingham, WA, USA, 2017; Volume 10391, p. 103910I. [Google Scholar]
- Nguyen, T.C.; Bui, V.; Nehmetallah, G. Computational optical tomography using 3-D deep convolutional neural networks. Opt. Eng. 2018, 57, 043111. [Google Scholar]
- Clark, D.; Badea, C. Convolutional regularization methods for 4D, X-ray CT reconstruction. In Medical Imaging 2019: Physics of Medical Imaging; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 10948, p. 109482A. [Google Scholar]
- Liu, J.; Zhang, Y.; Zhao, Q.; Lv, T.; Wu, W.; Cai, N.; Quan, G.; Yang, W.; Chen, Y.; Luo, L.; et al. Deep iterative reconstruction estimation (DIRE): Approximate iterative reconstruction estimation for low dose CT imaging. Phys. Med. Biol. 2019, 64, 135007. [Google Scholar] [CrossRef] [PubMed]
- Cong, W.; Shan, H.; Zhang, X.; Liu, S.; Ning, R.; Wang, G. Deep-learning-based breast CT for radiation dose reduction. In Developments in X-ray Tomography XII; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 11113, p. 111131L. [Google Scholar]
- Beaudry, J.; Esquinas, P.L.; Shieh, C.C. Learning from our neighbours: A novel approach on sinogram completion using bin-sharing and deep learning to reconstruct high quality 4DCBCT. In Medical Imaging 2019: Physics of Medical Imaging; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 10948, p. 1094847. [Google Scholar]
- Chen, H.; Zhang, Y.; Chen, Y.; Zhang, J.; Zhang, W.; Sun, H.; Lv, Y.; Liao, P.; Zhou, J.; Wang, G. LEARN: Learned experts’ assessment-based reconstruction network for sparse-data CT. IEEE Trans. Med. Imaging 2018, 37, 1333–1347. [Google Scholar] [CrossRef]
- He, J.; Yang, Y.; Wang, Y.; Zeng, D.; Bian, Z.; Zhang, H.; Sun, J.; Xu, Z.; Ma, J. Optimizing a parameterized plug-and-play ADMM for iterative low-dose CT reconstruction. IEEE Trans. Med. Imaging 2018, 38, 371–382. [Google Scholar] [CrossRef]
- Wang, J.; Zeng, L.; Wang, C.; Guo, Y. ADMM-based deep reconstruction for limited-angle CT. Phys. Med. Biol. 2019, 64, 115011. [Google Scholar] [CrossRef]
- Cheng, W.; Wang, Y.; Chi, Y.; Xie, X.; Duan, Y. Learned Full-Sampling Reconstruction. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 375–384. [Google Scholar]
- Chun, I.Y.; Zheng, X.; Long, Y.; Fessler, J.A. BCD-Net for Low-dose CT Reconstruction: Acceleration, Convergence, and Generalization. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 31–40. [Google Scholar]
- Ding, Q.; Chen, G.; Zhang, X.; Huang, Q.; Gao, H.J.H. Low-Dose CT with Deep Learning Regularization via Proximal Forward Backward Splitting. arXiv 2019, arXiv:1909.09773. [Google Scholar] [CrossRef] [Green Version]
- Hauptmann, A.; Adler, J.; Arridge, S.; Öktem, O. Multi-Scale Learned Iterative Reconstruction. arXiv 2019, arXiv:1908.00936. [Google Scholar] [CrossRef]
- Li, Z.; Ye, S.; Long, Y.; Ravishankar, S. SUPER Learning: A Supervised-Unsupervised Framework for Low-Dose CT Image Reconstruction. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- He, J.; Wang, Y.; Yang, Y.; Bian, Z.; Zeng, D.; Sun, J.; Xu, Z.; Ma, J. LdCT-net: Low-dose CT image reconstruction strategy driven by a deep dual network. In Medical Imaging 2018: Physics of Medical Imaging; International Society for Optics and Photonics: Bellingham, WA, USA, 2018; Volume 10573, p. 105733G. [Google Scholar]
- Wu, D.; Kim, K.; Li, Q. Computationally efficient deep neural network for computed tomography image reconstruction. Med. Phys. 2019, 46, 4763–4776. [Google Scholar] [CrossRef] [Green Version]
- Dedmari, M.A.; Conjeti, S.; Estrada, S.; Ehses, P.; Stöcker, T.; Reuter, M. Complex fully convolutional neural networks for mr image reconstruction. In International Workshop on Machine Learning for Medical Image Reconstruction; Springer: Berlin/Heidelberg, Germany, 2018; pp. 30–38. [Google Scholar]
- Pruessmann, K.P.; Weiger, M.; Scheidegger, M.B.; Boesiger, P. SENSE: Sensitivity encoding for fast MRI. Magn. Reson. Med. Off. J. Int. Soc. Magn. Reson. Med. 1999, 42, 952–962. [Google Scholar] [CrossRef]
- Sun, J.; Li, H.; Xu, Z. Deep ADMM-Net for compressive sensing MRI. Adv. Neural Inf. Process. Syst. 2016, 29, 10–18. [Google Scholar]
- Yang, Y.; Sun, J.; Li, H.; Xu, Z. ADMM-CSNet: A Deep Learning Approach for Image Compressive Sensing. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 521–538. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Huang, L.; Yin, Y.; Wang, Y.; Gui, G. ADMM-Net for Robust Compressive Sensing Image Reconstruction in the Presence of Symmetric α-Stable Noise. In Proceedings of the APSIPA Annual Summit and Conference, Hawaii, HI, USA, 12–15 November 2018; Volume 2018, pp. 12–15. [Google Scholar]
- Liu, Y.; Liu, Q.; Zhang, M.; Yang, Q.; Wang, S.; Liang, D. IFR-Net: Iterative Feature Refinement Network for Compressed Sensing MRI. IEEE Trans. Comput. Imaging 2019, 6, 434–446. [Google Scholar] [CrossRef] [Green Version]
- Hammernik, K.; Klatzer, T.; Kobler, E.; Recht, M.P.; Sodickson, D.K.; Pock, T.; Knoll, F. Learning a variational network for reconstruction of accelerated MRI data. Magn. Reson. Med. 2018, 79, 3055–3071. [Google Scholar] [CrossRef] [PubMed]
- Uecker, M.; Lai, P.; Murphy, M.J.; Virtue, P.; Elad, M.; Pauly, J.M.; Vasanawala, S.S.; Lustig, M. ESPIRiT—An eigenvalue approach to autocalibrating parallel MRI: Where SENSE meets GRAPPA. Magn. Reson. Med. 2014, 71, 990–1001. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Xiao, T.; Li, C.; Liu, Q.; Wang, S. Model-based Convolutional De-Aliasing Network Learning for Parallel MR Imaging. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 30–38. [Google Scholar]
- Chen, F.; Taviani, V.; Malkiel, I.; Cheng, J.Y.; Tamir, J.I.; Shaikh, J.; Chang, S.T.; Hardy, C.J.; Pauly, J.M.; Vasanawala, S.S. Variable-density single-shot fast spin-echo MRI with deep learning reconstruction by using variational networks. Radiology 2018, 289, 366–373. [Google Scholar] [CrossRef] [Green Version]
- Ravishankar, S.; Lahiri, A.; Blocker, C.; Fessler, J.A. Deep dictionary-transform learning for image reconstruction. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, WA, USA, 4–7 April 2018; pp. 1208–1212. [Google Scholar]
- Lu, T.; Zhang, X.; Huang, Y.; Yang, Y.; Guo, G.; Bao, L.; Huang, F.; Guo, D.; Qu, X. pISTA-SENSE-ResNet for Parallel MRI Reconstruction. arXiv 2019, arXiv:1910.00650. [Google Scholar]
- Wang, S.; Su, Z.; Ying, L.; Peng, X.; Zhu, S.; Liang, F.; Feng, D.; Liang, D. Accelerating magnetic resonance imaging via deep learning. In Proceedings of the 2016 IEEE 13th International Symposium on Biomedical Imaging (ISBI), Prague, Czech Republic, 13–16 April 2016; pp. 514–517. [Google Scholar]
- Lee, D.; Yoo, J.; Ye, J.C. Deep artifact learning for compressed sensing and parallel MRI. arXiv 2017, arXiv:1703.01120. [Google Scholar]
- Yu, S.; Dong, H.; Yang, G.; Slabaugh, G.; Dragotti, P.L.; Ye, X.; Liu, F.; Arridge, S.; Keegan, J.; Firmin, D.; et al. Deep de-aliasing for fast compressive sensing MRI. arXiv 2017, arXiv:1705.07137. [Google Scholar]
- Sandino, C.M.; Dixit, N.; Cheng, J.Y.; Vasanawala, S.S. Deep Convolutional Neural Networks for Accelerated Dynamic Magnetic Resonance Imaging. 2017. Available online: http://cs231n.stanford.edu/reports/2017/pdfs/513.pdf (accessed on 11 January 2022).
- Yang, G.; Yu, S.; Dong, H.; Slabaugh, G.; Dragotti, P.L.; Ye, X.; Liu, F.; Arridge, S.; Keegan, J.; Guo, Y.; et al. DAGAN: Deep de-aliasing generative adversarial networks for fast compressed sensing MRI reconstruction. IEEE Trans. Med. Imaging 2017, 37, 1310–1321. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Deora, P.; Vasudeva, B.; Bhattacharya, S.; Pradhan, P.M. Robust Compressive Sensing MRI Reconstruction using Generative Adversarial Networks. arXiv 2019, arXiv:1910.06067. [Google Scholar]
- Mardani, M.; Gong, E.; Cheng, J.Y.; Vasanawala, S.S.; Zaharchuk, G.; Xing, L.; Pauly, J.M. Deep generative adversarial neural networks for compressive sensing MRI. IEEE Trans. Med. Imaging 2018, 38, 167–179. [Google Scholar] [CrossRef] [PubMed]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Li, Z.; Zhang, T.; Wan, P.; Zhang, D. SEGAN: Structure-enhanced generative adversarial network for compressed sensing MRI reconstruction. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 1012–1019. [Google Scholar]
- Xu, C.; Tao, J.; Ye, Z.; Xu, J.; Kainat, W. Adversarial training and dilated convolutions for compressed sensing MRI. In Proceedings of the Eleventh International Conference on Digital Image Processing (ICDIP 2019), Guangzhou, China, 10–13 May 2019; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 11179, p. 111793T. [Google Scholar]
- Quan, T.M.; Nguyen-Duc, T.; Jeong, W.K. Compressed sensing MRI reconstruction using a generative adversarial network with a cyclic loss. IEEE Trans. Med. Imaging 2018, 37, 1488–1497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hyun, C.M.; Kim, H.P.; Lee, S.M.; Lee, S.; Seo, J.K. Deep learning for undersampled MRI reconstruction. Phys. Med. Biol. 2018, 63, 135007. [Google Scholar] [CrossRef]
- Souza, R.; Frayne, R. A hybrid frequency-domain/image-domain deep network for magnetic resonance image reconstruction. In Proceedings of the 2019 32nd SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Rio de Janeiro, Brazil, 28–30 October 2019; pp. 257–264. [Google Scholar]
- Eo, T.; Jun, Y.; Kim, T.; Jang, J.; Lee, H.J.; Hwang, D. KIKI-net: Cross-domain convolutional neural networks for reconstructing undersampled magnetic resonance images. Magn. Reson. Med. 2018, 80, 2188–2201. [Google Scholar] [CrossRef]
- Schlemper, J.; Caballero, J.; Hajnal, J.V.; Price, A.N.; Rueckert, D. A deep cascade of convolutional neural networks for dynamic MR image reconstruction. IEEE Trans. Med. Imaging 2017, 37, 491–503. [Google Scholar] [CrossRef] [Green Version]
- Wu, H.; Wu, Y.; Sun, L.; Cai, C.; Huang, Y.; Ding, X. A Deep Ensemble Network for Compressed Sensing MRI. In Proceedings of the International Conference on Neural Information Processing, Siem Reap, Cambodia, 13–16 December 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 162–171. [Google Scholar]
- Liu, J.; Kuang, T.; Zhang, X. Image reconstruction by splitting deep learning regularization from iterative inversion. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 224–231. [Google Scholar]
- Wang, H.; Cheng, J.; Jia, S.; Qiu, Z.; Shi, C.; Zou, L.; Su, S.; Chang, Y.; Zhu, Y.; Ying, L.; et al. Accelerating MR imaging via deep Chambolle–Pock network. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 6818–6821. [Google Scholar]
- Sun, L.; Fan, Z.; Huang, Y.; Ding, X.; Paisley, J. Compressed sensing MRI using a recursive dilated network. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Zeng, K.; Yang, Y.; Xiao, G.; Chen, Z. A Very Deep Densely Connected Network for Compressed Sensing MRI. IEEE Access 2019, 7, 85430–85439. [Google Scholar] [CrossRef]
- Ke, Z.; Wang, S.; Cheng, H.; Ying, L.; Liu, Q.; Zheng, H.; Liang, D. CRDN: Cascaded Residual Dense Networks for Dynamic MR Imaging with Edge-enhanced Loss Constraint. arXiv 2019, arXiv:1901.06111. [Google Scholar]
- Malkiel, I.; Ahn, S.; Taviani, V.; Menini, A.; Wolf, L.; Hardy, C.J. Conditional WGANs with Adaptive Gradient Balancing for Sparse MRI Reconstruction. arXiv 2019, arXiv:1905.00985. [Google Scholar]
- Huang, Q.; Yang, D.; Wu, P.; Qu, H.; Yi, J.; Metaxas, D. MRI reconstruction via cascaded channel-wise attention network. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 1622–1626. [Google Scholar]
- Wang, P.; Chen, E.Z.; Chen, T.; Patel, V.M.; Sun, S. Pyramid Convolutional RNN for MRI Reconstruction. arXiv 2019, arXiv:1912.00543. [Google Scholar]
- Sun, L.; Fan, Z.; Fu, X.; Huang, Y.; Ding, X.; Paisley, J. A deep information sharing network for multi-contrast compressed sensing MRI reconstruction. IEEE Trans. Image Process. 2019, 28, 6141–6153. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jin, K.H.; Unser, M. 3D BBPConvNet to reconstruct parallel MRI. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, WA, USA, 4–7 April 2018; pp. 361–364. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; PMLR: Cambridge, MA, USA, 2017; pp. 214–223. [Google Scholar]
- Jiang, M.; Yuan, Z.; Yang, X.; Zhang, J.; Gong, Y.; Xia, L.; Li, T. Accelerating CS-MRI Reconstruction with Fine-Tuning Wasserstein Generative Adversarial Network. IEEE Access 2019, 7, 152347–152357. [Google Scholar] [CrossRef]
- Jun, Y.; Eo, T.; Shin, H.; Kim, T.; Lee, H.J.; Hwang, D. Parallel imaging in time-of-flight magnetic resonance angiography using deep multistream convolutional neural networks. Magn. Reson. Med. 2019, 81, 3840–3853. [Google Scholar] [CrossRef] [PubMed]
- Sandino, C.M.; Lai, P.; Vasanawala, S.S.; Cheng, J.Y. Accelerating cardiac cine MRI beyond compressed sensing using DL-ESPIRiT. arXiv 2019, arXiv:1911.05845. [Google Scholar]
- Pour Yazdanpanah, A.; Afacan, O.; Warfield, S. Deep Plug-and-Play Prior for Parallel MRI Reconstruction. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Schlemper, J.; Duan, J.; Ouyang, C.; Qin, C.; Caballero, J.; Hajnal, J.V.; Rueckert, D. Data consistency networks for (calibration-less) accelerated parallel MR image reconstruction. arXiv 2019, arXiv:1909.11795. [Google Scholar]
- Zhou, Z.; Han, F.; Ghodrati, V.; Gao, Y.; Yin, W.; Yang, Y.; Hu, P. Parallel imaging and convolutional neural network combined fast MR image reconstruction: Applications in low-latency accelerated real-time imaging. Med. Phys. 2019, 46, 3399–3413. [Google Scholar] [CrossRef]
- Liu, Q.; Yang, Q.; Cheng, H.; Wang, S.; Zhang, M.; Liang, D. Highly undersampled magnetic resonance imaging reconstruction using autoencoding priors. Magn. Reson. Med. 2020, 83, 322–336. [Google Scholar] [CrossRef]
- Duan, J.; Schlemper, J.; Qin, C.; Ouyang, C.; Bai, W.; Biffi, C.; Bello, G.; Statton, B.; O’Regan, D.P.; Rueckert, D. VS-Net: Variable splitting network for accelerated parallel MRI reconstruction. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 713–722. [Google Scholar]
- Wang, S.; Cheng, H.; Ying, L.; Xiao, T.; Ke, Z.; Liu, X.; Zheng, H.; Liang, D. DeepcomplexMRI: Exploiting deep residual network for fast parallel MR imaging with complex convolution. arXiv 2019, arXiv:1906.04359. [Google Scholar] [CrossRef] [Green Version]
- Meng, N.; Yang, Y.; Xu, Z.; Sun, J. A Prior Learning Network for Joint Image and Sensitivity Estimation in Parallel MR Imaging. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 732–740. [Google Scholar]
- Liu, R.; Zhang, Y.; Cheng, S.; Fan, X.; Luo, Z. A theoretically guaranteed deep optimization framework for robust compressive sensing mri. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4368–4375. [Google Scholar]
- Zhu, B.; Liu, J.Z.; Cauley, S.F.; Rosen, B.R.; Rosen, M.S. Image reconstruction by domain-transform manifold learning. Nature 2018, 555, 487–492. [Google Scholar] [CrossRef] [Green Version]
- Lee, D.; Yoo, J.; Ye, J.C. Deep residual learning for compressed sensing MRI. In Proceedings of the 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017), Melbourne, Australia, 18–21 April 2017; pp. 15–18. [Google Scholar]
- Lee, D.; Yoo, J.; Tak, S.; Ye, J.C. Deep residual learning for accelerated MRI using magnitude and phase networks. IEEE Trans. Biomed. Eng. 2018, 65, 1985–1995. [Google Scholar] [CrossRef] [Green Version]
- Gong, E.; Pauly, J.M.; Wintermark, M.; Zaharchuk, G. Deep learning enables reduced gadolinium dose for contrast-enhanced brain MRI. J. Magn. Reson. Imaging 2018, 48, 330–340. [Google Scholar] [CrossRef] [PubMed]
- Han, Y.; Yoo, J.; Kim, H.H.; Shin, H.J.; Sung, K.; Ye, J.C. Deep learning with domain adaptation for accelerated projection-reconstruction MR. Magn. Reson. Med. 2018, 80, 1189–1205. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ding, P.L.K.; Li, Z.; Zhou, Y.; Li, B. Deep residual dense U-Net for resolution enhancement in accelerated MRI acquisition. In Medical Imaging 2019: Image Processing; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 10949, p. 109490F. [Google Scholar]
- Muckley, M.J.; Ades-Aron, B.; Papaioannou, A.; Lemberskiy, G.; Solomon, E.; Lui, Y.W.; Sodickson, D.K.; Fieremans, E.; Novikov, D.S.; Knoll, F. Training a Neural Network for Gibbs and Noise Removal in Diffusion MRI. arXiv 2019, arXiv:1905.04176. [Google Scholar] [CrossRef]
- Oksuz, I.; Clough, J.; Bustin, A.; Cruz, G.; Prieto, C.; Botnar, R.; Rueckert, D.; Schnabel, J.A.; King, A.P. Cardiac mr motion artefact correction from k-space using deep learning-based reconstruction. In International Workshop on Machine Learning for Medical Image Reconstruction; Springer: Berlin/Heidelberg, Germany, 2018; pp. 21–29. [Google Scholar]
- Seitzer, M.; Yang, G.; Schlemper, J.; Oktay, O.; Würfl, T.; Christlein, V.; Wong, T.; Mohiaddin, R.; Firmin, D.; Keegan, J.; et al. Adversarial and perceptual refinement for compressed sensing MRI reconstruction. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 232–240. [Google Scholar]
- Dai, Y.; Zhuang, P. Compressed sensing MRI via a multi-scale dilated residual convolution network. Magn. Reson. Imaging 2019, 63, 93–104. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xiang, L.; Chen, Y.; Chang, W.; Zhan, Y.; Lin, W.; Wang, Q.; Shen, D. Deep-Learning-Based Multi-Modal Fusion for Fast MR Reconstruction. IEEE Trans. Biomed. Eng. 2018, 66, 2105–2114. [Google Scholar] [CrossRef] [PubMed]
- Zhou, W.; Du, H.; Mei, W.; Fang, L. Efficient Structurally-Strengthened Generative Adversarial Network for MRI Reconstruction. arXiv 2019, arXiv:1908.03858. [Google Scholar] [CrossRef]
- Han, Y.; Sunwoo, L.; Ye, J.C. k-space deep learning for accelerated MRI. IEEE Trans. Med. Imaging 2019, 39, 377–386. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, L.; Fan, Z.; Huang, Y.; Ding, X.; Paisley, J. A Deep Error Correction Network for Compressed Sensing MRI. arXiv 2018, arXiv:1803.08763. [Google Scholar] [CrossRef] [Green Version]
- Eo, T.; Shin, H.; Kim, T.; Jun, Y.; Hwang, D. Translation of 1d inverse fourier transform of k-space to an image based on deep learning for accelerating magnetic resonance imaging. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 241–249. [Google Scholar]
- An, H.; Zhang, Y.J. A Structural Oriented Training Method for GAN Based Fast Compressed Sensing MRI. In Proceedings of the International Conference on Image and Graphics, Beijing, China, 23–25 August 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 483–494. [Google Scholar]
- Schlemper, J.; Yang, G.; Ferreira, P.; Scott, A.; McGill, L.A.; Khalique, Z.; Gorodezky, M.; Roehl, M.; Keegan, J.; Pennell, D.; et al. Stochastic deep compressive sensing for the reconstruction of diffusion tensor cardiac mri. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 295–303. [Google Scholar]
- Dar, S.U.H.; Özbey, M.; Çatlı, A.B.; Çukur, T. A transfer-learning approach for accelerated MRI using deep neural networks. arXiv 2017, arXiv:1710.02615. [Google Scholar] [CrossRef] [Green Version]
- Mardani, M.; Sun, Q.; Donoho, D.; Papyan, V.; Monajemi, H.; Vasanawala, S.; Pauly, J. Neural proximal gradient descent for compressive imaging. Adv. Neural Inf. Process. Syst. 2018, 31, 9573–9583. [Google Scholar]
- Liu, R.; Zhang, Y.; Cheng, S.; Luo, Z.; Fan, X. Converged Deep Framework Assembling Principled Modules for CS-MRI. arXiv 2019, arXiv:1910.13046. [Google Scholar]
- Chen, F.; Cheng, J.Y.; Taviani, V.; Sheth, V.R.; Brunsing, R.L.; Pauly, J.M.; Vasanawala, S.S. Data-driven self-calibration and reconstruction for non-cartesian wave-encoded single-shot fast spin echo using deep learning. J. Magn. Reson. Imaging 2020, 51, 841–853. [Google Scholar] [CrossRef] [PubMed]
- Biswas, S.; Aggarwal, H.K.; Jacob, M. Dynamic MRI using model-based deep learning and SToRM priors: MoDL-SToRM. Magn. Reson. Med. 2019, 82, 485–494. [Google Scholar] [CrossRef] [PubMed]
- Cheng, J.; Wang, H.; Ying, L.; Liang, D. Model learning: Primal dual networks for fast MR imaging. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 21–29. [Google Scholar]
- Cheng, J.; Wang, H.; Zhu, Y.; Liu, Q.; Ying, L.; Liang, D. Model-based Deep MR Imaging: The roadmap of generalizing compressed sensing model using deep learning. arXiv 2019, arXiv:1906.08143. [Google Scholar]
- Golbabaee, M.; Pirkl, C.M.; Menzel, M.I.; Buonincontri, G.; Gómez, P.A. Deep MR Fingerprinting with total-variation and low-rank subspace priors. arXiv 2019, arXiv:1902.10205. [Google Scholar]
- Zeng, W.; Peng, J.; Wang, S.; Liu, Q. A comparative study of CNN-based super-resolution methods in MRI reconstruction and its beyond. Signal Process. Image Commun. 2020, 81, 115701. [Google Scholar] [CrossRef]
- Zeng, D.Y.; Shaikh, J.; Nishimura, D.G.; Vasanawala, S.S.; Cheng, J.Y. Deep Residual Network for Off-Resonance Artifact Correction with Application to Pediatric Body Magnetic Resonance Angiography with 3D Cones. arXiv 2018, arXiv:1810.00072. [Google Scholar]
- Chun, Y.; Fessler, J.A. Deep BCD-net using identical encoding-decoding CNN structures for iterative image recovery. In Proceedings of the 2018 IEEE 13th Image, Video, and Multidimensional Signal Processing Workshop (IVMSP), Aristi Village, Greece, 10–12 June 2018; pp. 1–5. [Google Scholar]
- Haber, E.; Lensink, K.; Triester, E.; Ruthotto, L. IMEXnet: A Forward Stable Deep Neural Network. arXiv 2019, arXiv:1903.02639. [Google Scholar]
- Narnhofer, D.; Hammernik, K.; Knoll, F.; Pock, T. Inverse GANs for accelerated MRI reconstruction. In Wavelets and Sparsity XVIII; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 11138, p. 111381A. [Google Scholar]
- Tezcan, K.C.; Baumgartner, C.F.; Luechinger, R.; Pruessmann, K.P.; Konukoglu, E. MR image reconstruction using deep density priors. IEEE Trans. Med. Imaging 2018, 38, 1633–1642. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Salimans, T.; Karpathy, A.; Chen, X.; Kingma, D.P. Pixelcnn++: Improving the pixelcnn with discretized logistic mixture likelihood and other modifications. arXiv 2017, arXiv:1701.05517. [Google Scholar]
- Luo, G.; Zhao, N.; Jiang, W.; Cao, P. MRI Reconstruction Using Deep Bayesian Inference. arXiv 2019, arXiv:1909.01127. [Google Scholar]
- Yazdanpanah, A.P.; Afacan, O.; Warfield, S.K. Non-learning based deep parallel MRI reconstruction (NLDpMRI). In Medical Imaging 2019: Image Processing; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 10949, p. 1094904. [Google Scholar]
- Jin, K.H.; Gupta, H.; Yerly, J.; Stuber, M.; Unser, M. Time-Dependent Deep Image Prior for Dynamic MRI. arXiv 2019, arXiv:1910.01684. [Google Scholar]
- Senouf, O.; Vedula, S.; Weiss, T.; Bronstein, A.; Michailovich, O.; Zibulevsky, M. Self-supervised learning of inverse problem solvers in medical imaging. In Domain Adaptation and Representation Transfer and Medical Image Learning with Less Labels and Imperfect Data; Springer: Berlin/Heidelberg, Germany, 2019; pp. 111–119. [Google Scholar]
- Yaman, B.; Hosseini, S.A.H.; Moeller, S.; Ellermann, J.; Uǧurbil, K.; Akçakaya, M. Self-Supervised Physics-Based Deep Learning MRI Reconstruction Without Fully-Sampled Data. arXiv 2019, arXiv:1910.09116. [Google Scholar]
- Yang, B.; Ying, L.; Tang, J. Artificial neural network enhanced Bayesian PET image reconstruction. IEEE Trans. Med. Imaging 2018, 37, 1297–1309. [Google Scholar] [CrossRef]
- Xu, J.; Gong, E.; Pauly, J.; Zaharchuk, G. 200x low-dose PET reconstruction using deep learning. arXiv 2017, arXiv:1712.04119. [Google Scholar]
- Gong, K.; Guan, J.; Liu, C.C.; Qi, J. PET image denoising using a deep neural network through fine tuning. IEEE Trans. Radiat. Plasma Med. Sci. 2018, 3, 153–161. [Google Scholar] [CrossRef]
- Gong, Y.; Teng, Y.; Shan, H.; Xiao, T.; Li, M.; Liang, G.; Wang, G.; Wang, S. Parameter Constrained Transfer Learning for Low Dose PET Image Denoising. arXiv 2019, arXiv:1910.06749. [Google Scholar]
- Wang, Y.; Yu, B.; Wang, L.; Zu, C.; Lalush, D.S.; Lin, W.; Wu, X.; Zhou, J.; Shen, D.; Zhou, L. 3D conditional generative adversarial networks for high-quality PET image estimation at low dose. NeuroImage 2018, 174, 550–562. [Google Scholar] [CrossRef]
- Chen, K.T.; Gong, E.; de Carvalho Macruz, F.B.; Xu, J.; Boumis, A.; Khalighi, M.; Poston, K.L.; Sha, S.J.; Greicius, M.D.; Mormino, E.; et al. Ultra–low-dose 18F-florbetaben amyloid PET imaging using deep learning with multi-contrast MRI inputs. Radiology 2019, 290, 649–656. [Google Scholar] [CrossRef] [PubMed]
- Xiang, L.; Qiao, Y.; Nie, D.; An, L.; Lin, W.; Wang, Q.; Shen, D. Deep auto-context convolutional neural networks for standard-dose PET image estimation from low-dose PET/MRI. Neurocomputing 2017, 267, 406–416. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Chen, H.; Liu, H. Deep Learning Based Framework for Direct Reconstruction of PET Images. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 48–56. [Google Scholar]
- Häggström, I.; Schmidtlein, C.R.; Campanella, G.; Fuchs, T.J. DeepPET: A deep encoder–decoder network for directly solving the PET image reconstruction inverse problem. Med. Image Anal. 2019, 54, 253–262. [Google Scholar] [CrossRef] [PubMed]
- Guazzo, A. Deep Learning for PET Imaging: From Denoising to Learned Primal-Dual Reconstruction. 2020. Available online: http://tesi.cab.unipd.it/64113/1/alessandro_guazzo_tesi.pdf (accessed on 11 January 2022).
- Kim, K.; Wu, D.; Gong, K.; Dutta, J.; Kim, J.H.; Son, Y.D.; Kim, H.K.; El Fakhri, G.; Li, Q. Penalized PET reconstruction using deep learning prior and local linear fitting. IEEE Trans. Med. Imaging 2018, 37, 1478–1487. [Google Scholar] [CrossRef]
- Gong, K.; Wu, D.; Kim, K.; Yang, J.; Sun, T.; El Fakhri, G.; Seo, Y.; Li, Q. MAPEM-Net: An unrolled neural network for Fully 3D PET image reconstruction. In 15th International Meeting on Fully Three-Dimensional Image Reconstruction in Radiology and Nuclear Medicine; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 11072, p. 110720O. [Google Scholar]
- Xie, Z.; Baikejiang, R.; Gong, K.; Zhang, X.; Qi, J. Generative adversarial networks based regularized image reconstruction for PET. In 15th International Meeting on Fully Three-Dimensional Image Reconstruction in Radiology and Nuclear Medicine; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 11072, p. 110720P. [Google Scholar]
- Gong, K.; Guan, J.; Kim, K.; Zhang, X.; Yang, J.; Seo, Y.; El Fakhri, G.; Qi, J.; Li, Q. Iterative PET image reconstruction using convolutional neural network representation. IEEE Trans. Med. Imaging 2018, 38, 675–685. [Google Scholar] [CrossRef]
- Gong, K.; Kim, K.; Cui, J.; Guo, N.; Catana, C.; Qi, J.; Li, Q. Learning personalized representation for inverse problems in medical imaging using deep neural network. arXiv 2018, arXiv:1807.01759. [Google Scholar]
- Cui, J.; Gong, K.; Guo, N.; Wu, C.; Meng, X.; Kim, K.; Zheng, K.; Wu, Z.; Fu, L.; Xu, B.; et al. PET image denoising using unsupervised deep learning. Eur. J. Nucl. Med. Mol. Imaging 2019, 46, 2780–2789. [Google Scholar] [CrossRef]
- Yokota, T.; Kawai, K.; Sakata, M.; Kimura, Y.; Hontani, H. Dynamic PET Image Reconstruction Using Nonnegative Matrix Factorization Incorporated with Deep Image Prior. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3126–3135. [Google Scholar]
- Hashimoto, F.; Ohba, H.; Ote, K.; Teramoto, A.; Tsukada, H. Dynamic PET image denoising using deep convolutional neural networks without prior training datasets. IEEE Access 2019, 7, 96594–96603. [Google Scholar] [CrossRef]
- Gong, K.; Catana, C.; Qi, J.; Li, Q. Direct patlak reconstruction from dynamic PET using unsupervised deep learning. In 15th International Meeting on Fully Three-Dimensional Image Reconstruction in Radiology and Nuclear Medicine; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 11072, p. 110720R. [Google Scholar]
- Cui, J.; Gong, K.; Guo, N.; Kim, K.; Liu, H.; Li, Q. CT-guided PET parametric image reconstruction using deep neural network without prior training data. In Medical Imaging 2019: Physics of Medical Imaging; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 10948, p. 109480Z. [Google Scholar]
- Antun, V.; Renna, F.; Poon, C.; Adcock, B.; Hansen, A.C. On instabilities of deep learning in image reconstruction-Does AI come at a cost? arXiv 2019, arXiv:1902.05300. [Google Scholar]
- Ahmed, S.S.; Messali, Z.; Ouahabi, A.; Trepout, S.; Messaoudi, C.; Marco, S. Nonparametric denoising methods based on contourlet transform with sharp frequency localization: Application to low exposure time electron microscopy images. Entropy 2015, 17, 3461–3478. [Google Scholar] [CrossRef] [Green Version]
- Ouahabi, A. A review of wavelet denoising in medical imaging. In Proceedings of the 2013 8th International Workshop on Systems, Signal Processing and Their Applications (WoSSPA), Algiers, Algeria, 12–15 May 2013; pp. 19–26. [Google Scholar]
- Kumar, M.; Aggarwal, J.; Rani, A.; Stephan, T.; Shankar, A.; Mirjalili, S. Secure video communication using firefly optimization and visual cryptography. Artif. Intell. Rev. 2021, 1–21. [Google Scholar] [CrossRef]
- Dhasarathan, C.; Kumar, M.; Srivastava, A.K.; Al-Turjman, F.; Shankar, A.; Kumar, M. A bio-inspired privacy-preserving framework for healthcare systems. J. Supercomput. 2021, 77, 11099–11134. [Google Scholar] [CrossRef]
- Khan, S.; Khan, M.A.; Alhaisoni, M.; Tariq, U.; Yong, H.S.; Armghan, A.; Alenezi, F. Human Action Recognition: A Paradigm of Best Deep Learning Features Selection and Serial Based Extended Fusion. Sensors 2021, 21, 7941. [Google Scholar] [CrossRef] [PubMed]
- Syed, H.H.; Khan, M.A.; Tariq, U.; Armghan, A.; Alenezi, F.; Khan, J.A.; Rho, S.; Kadry, S.; Rajinikanth, V. A Rapid Artificial Intelligence-Based Computer-Aided Diagnosis System for COVID-19 Classification from CT Images. Behav. Neurol. 2021, 2021, 2560388. [Google Scholar] [CrossRef] [PubMed]
- Khan, M.A.; Alqahtani, A.; Khan, A.; Alsubai, S.; Binbusayyis, A.; Ch, M.; Yong, H.S.; Cha, J. Cucumber Leaf Diseases Recognition Using Multi Level Deep Entropy-ELM Feature Selection. Appl. Sci. 2022, 12, 593. [Google Scholar] [CrossRef]
- Haneche, H.; Boudraa, B.; Ouahabi, A. A new way to enhance speech signal based on compressed sensing. Measurement 2020, 151, 107117. [Google Scholar] [CrossRef]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, Y.; Li, Q. A Review of Deep Learning Methods for Compressed Sensing Image Reconstruction and Its Medical Applications. Electronics 2022, 11, 586. https://doi.org/10.3390/electronics11040586
Xie Y, Li Q. A Review of Deep Learning Methods for Compressed Sensing Image Reconstruction and Its Medical Applications. Electronics. 2022; 11(4):586. https://doi.org/10.3390/electronics11040586
Chicago/Turabian StyleXie, Yutong, and Quanzheng Li. 2022. "A Review of Deep Learning Methods for Compressed Sensing Image Reconstruction and Its Medical Applications" Electronics 11, no. 4: 586. https://doi.org/10.3390/electronics11040586
APA StyleXie, Y., & Li, Q. (2022). A Review of Deep Learning Methods for Compressed Sensing Image Reconstruction and Its Medical Applications. Electronics, 11(4), 586. https://doi.org/10.3390/electronics11040586