
Feature Enhancement-Based Ship Target Detection Method in Optical Remote Sensing Images

 , ,
, ,
Abstract
:1. Introduction
- Aiming at the problems of insufficient receptive field and insufficient feature information of the feature maps extracted from the backbone network, EIRM is proposed for feature enhancement. This module can capture feature information of different dimensions and provide receptive fields of different scales for feature maps, effectively improving the detection accuracy of small and medium-sized ships.
- In view of the problem that the ReLu6 activation function may cause the gradient to be 0 in the case of negative input, Leaky ReLu is used to replace the ReLu6 activation function in the SandGlass block, and the SandGlass-L block is proposed.
- SGLPANet is proposed based on SandGlass-L block. Using SandGlass-L to replace ordinary convolution in PANet alleviates the problem of information loss caused by channel transformation, enabling it to retain more semantic information and location information, thereby improving detection accuracy.
2. Related Work
2.1. Object Detection in Natural Images
2.2. Object Detection in ORSIs
3. Materials and Methods
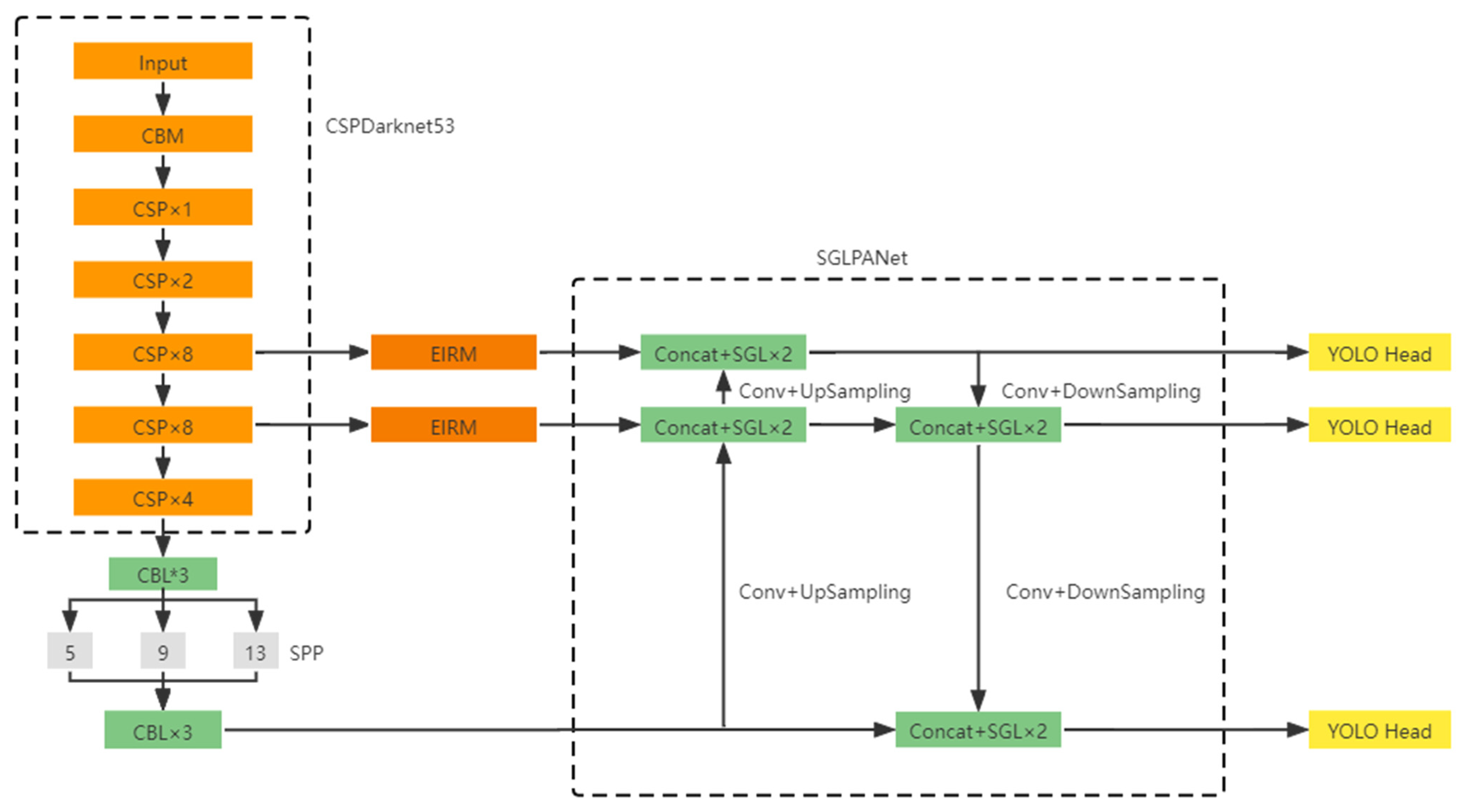
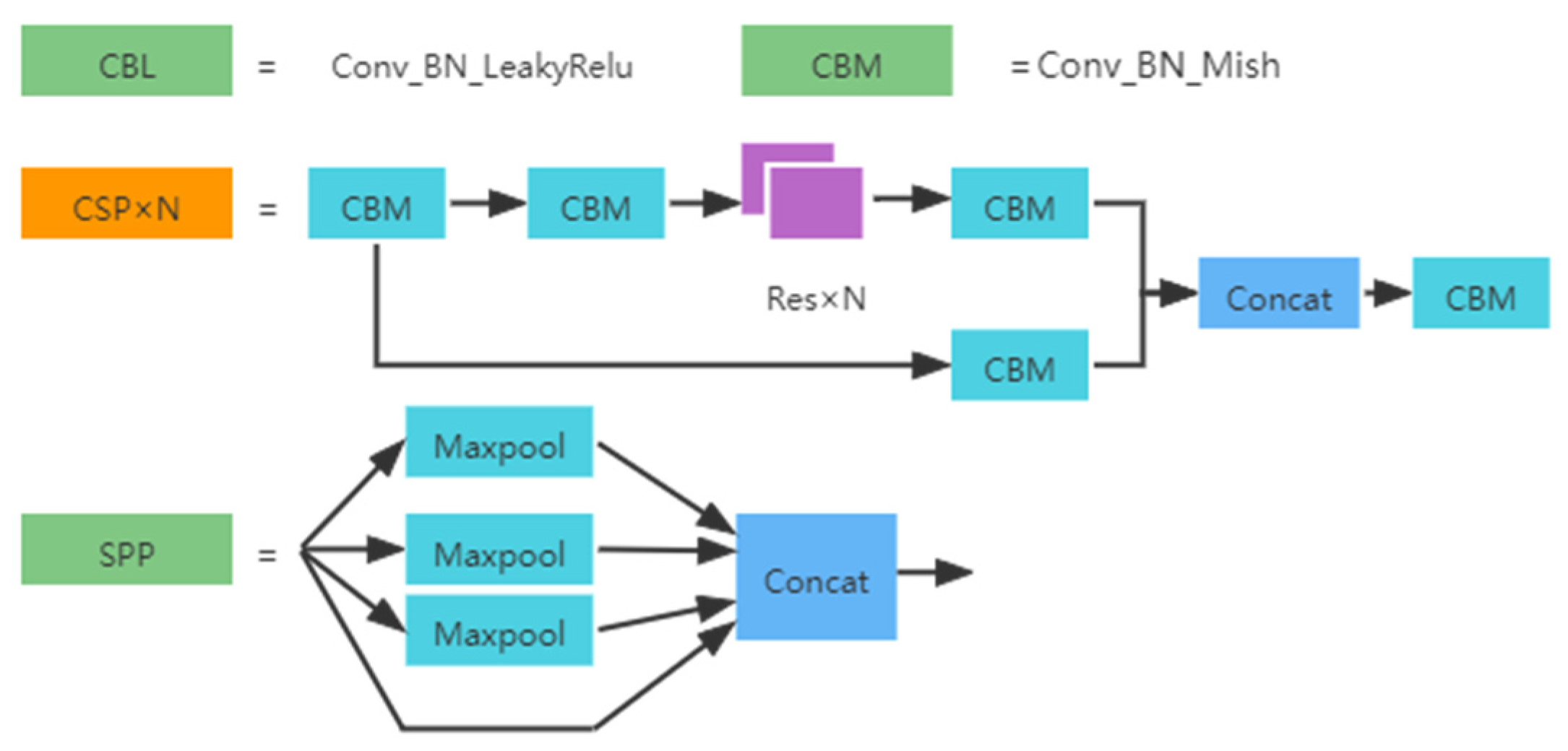
3.1. The Overall Structure of the Proposed Method
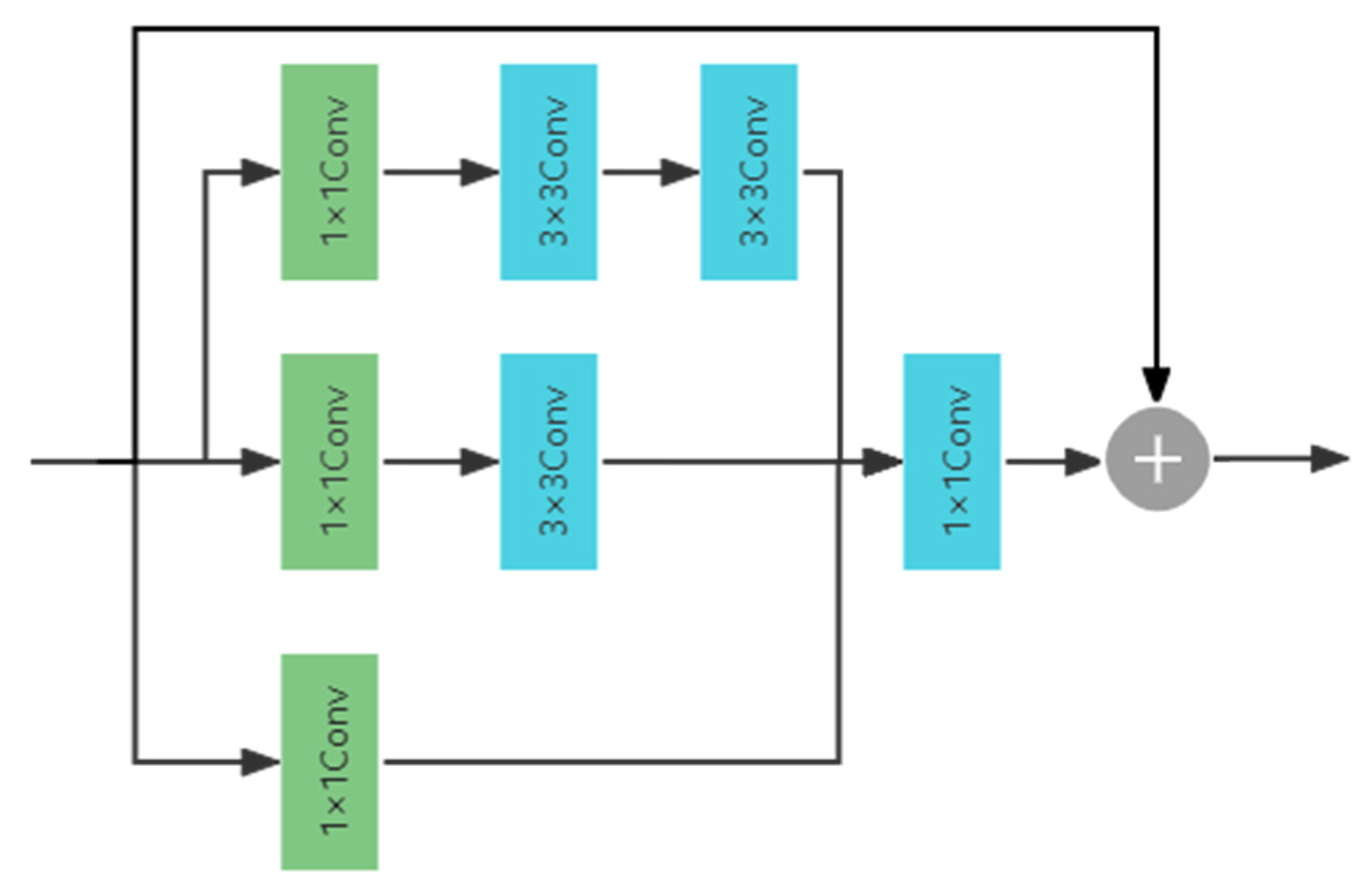
3.2. EIRM
3.2.1. Inception-ResNet-A Module and Elastic Mechanism
3.2.2. EIRM Structure
3.3. SandGlass-L Block
3.4. SGLPANet
4. Experimental Results and Analysis
4.1. Dataset and Evaluation Metric
4.1.1. Dataset Description
4.1.2. Evaluation Metric
4.2. Experimental Details
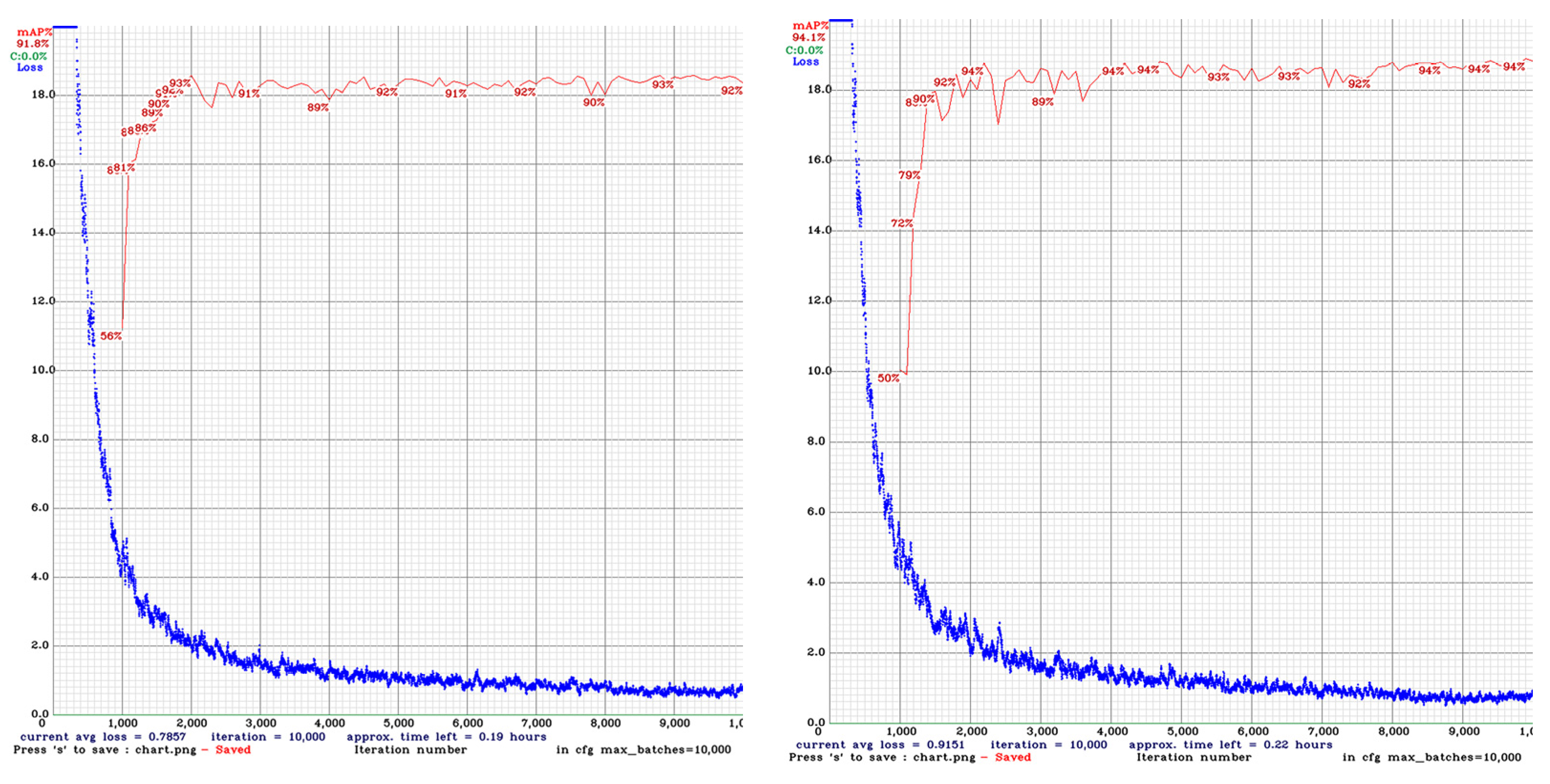
4.3. Experimental Results
4.3.1. Experimental Results and Comparative Analysis
4.3.2. Ablation Experiment
4.4. Extended Experiment
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Han, G.U.O. Gaojing No. 1 is officially commercially available, and China’s commercial remote sensing has entered the 0.5 meter era. Satell. Appl. 2017, 5, 62–63. [Google Scholar]
- Zhang, C.; Tao, R. Research progress on optical remote sensing object detection based on CNN. Spacecr. Recovery Remote Sens. 2020, 41, 45–55. [Google Scholar]
- Wang, W. Overview of ship detection technology based on remote sensing images. Telecommun. Eng. 2020, 60, 1126–1132. [Google Scholar]
- Liu, T. Deep learning based object detection in optical remote sensing image: A survey. Radio Commun. Technol. 2020, 624–634. [Google Scholar]
- Qu, Z.; Zhu, F.; Qi, C. Remote sensing image target detection: Improvement of the YOLOv3 model with auxiliary networks. Remote Sens. 2021, 13, 3908. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Li, Z.; Zhou, F. FSSD: Feature fusion single shot multibox detector. arXiv 2017, arXiv:1712.00960. [Google Scholar]
- Yang, J.; Wang, L. Feature fusion and enhancement for single shot multibox detector. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 2766–2770. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Li, X.; Shang, M.; Qin, H.; Chen, L. Fast accurate fish detection and recognition of underwater images with fast r-cnn. In Proceedings of the OCEANS 2015—MTS/IEEE Washington, Washington, DC, USA, 19–22 October 2015; pp. 1–5. [Google Scholar]
- Qian, R.; Liu, Q.; Yue, Y.; Coenen, F.; Zhang, B. Road surface traffic sign detection with hybrid region proposal and fast R-CNN. In Proceedings of the 2016 12th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Changsha, China, 13–15 August 2016; pp. 555–559. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; Volume 28, pp. 91–99. [Google Scholar]
- Mhalla, A.; Chateau, T.; Gazzah, S.; Ben Amara, N.E. Scene-specific pedestrian detector using monte carlo framework and faster r-cnn deep model: Phd forum. In Proceedings of the 10th International Conference on Distributed Smart Camera, New York, NY, USA, 12–15 September 2016; pp. 228–229. [Google Scholar]
- Zhai, M.; Liu, H.; Sun, F.; Zhang, Y. Ship detection based on faster R-CNN network in optical remote sensing images. In Proceedings of the 2019 Chinese Intelligent Automation Conference, Jiangsu, China, 20–22 September 2019; pp. 22–31. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Zhao, T.; Yang, Y.; Niu, H.; Wang, D.; Chen, Y. Comparing U-Net convolutional network with mask R-CNN in the performances of pomegranate tree canopy segmentation. In Proceedings of the Multispectral, Hyperspectral, and Ultraspectral Remote Sensing Technology, Techniques and Applications VII, Honolulu, HI, USA, 24–26 September 2018; Volume 10780, p. 107801J. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Zhang, J.; Zhao, Z.; Su, F. Efficient-receptive field block with group spatial attention mechanism for object detection. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 3248–3255. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Tan, M.; Le, Q.V. Mixnet: Mixed depthwise convolutional kernels. arXiv 2019, arXiv:1907.09595. [Google Scholar]
- Sifre, L.; Mallat, P.S. Rigid-Motion Scattering for Image Classification. Ph.D. Thesis, Ecole Polytechnique, Palaiseau, France, 2014. [Google Scholar]
- Lim, J.S.; Astrid, M.; Yoon, H.J.; Lee, S.I. Small object detection using context and attention. In Proceedings of the 2021 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Korea, 13–16 April 2021; pp. 181–186. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Diverse branch block: Building a convolution as an inception-like unit. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10886–10895. [Google Scholar]
- Sun, W.; Zhang, X.; Zhang, T.; Zhu, P.; Gao, L.; Tang, X.; Liu, B. Adaptive feature aggregation network for object detection in remote sensing images. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 1635–1638. [Google Scholar]
- Xu, D.; Wu, Y. MRFF-YOLO: A multi-receptive fields fusion network for remote sensing target detection. Remote Sens. 2020, 12, 3118. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Wang, J.; Yang, L.; Li, F. Predicting arbitrary-oriented objects as points in remote sensing images. Remote Sens. 2021, 13, 3731. [Google Scholar] [CrossRef]
- Fu, K.; Li, Y.; Sun, H.; Yang, X.; Xu, G.; Li, Y.; Sun, X. A ship rotation detection model in remote sensing images based on feature fusion pyramid network and deep reinforcement learning. Remote Sens. 2018, 10, 1922. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Ma, W.; Gong, M.; Bai, Z.; Zhao, W.; Guo, Q.; Chen, X.; Miao, Q. A coarse-to-fine network for ship detection in optical remote sensing images. Remote Sens. 2020, 12, 246. [Google Scholar] [CrossRef] [Green Version]
- Hou, X.; Xu, Q.; Ji, Y. Ship detection from optical remote sensing image based on size-adapted CNN. In Proceedings of the 2018 Fifth International Workshop on Earth Observation and Remote Sensing Applications (EORSA), Xi’an, China, 18–20 June 2018; pp. 1–5. [Google Scholar]
- Li, Z.; You, Y.; Liu, F. Analysis on saliency estimation methods in high-resolution optical remote sensing imagery for multi-scale ship detection. IEEE Access 2020, 8, 194485–194496. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Wang, H.; Kembhavi, A.; Farhadi, A.; Yuille, A.L.; Rastegari, M. Elastic: Improving cnns with dynamic scaling policies. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2258–2267. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Zhou, D.; Hou, Q.; Chen, Y.; Feng, J.; Yan, S. Rethinking bottleneck structure for efficient mobile network design. In Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 680–697. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. Computer Seience. 2013, 30, 3. [Google Scholar]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z. Random access memories: A new paradigm for target detection in high resolution aerial remote sensing images. IEEE Trans. Image Processing A Publ. IEEE Signal Processing Soc. 2018, 27, 1100–1111. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. UnitBox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, New York, NY, USA, 15–19 October 2016. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems 29 (NIPS 2016), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Guo, J.; Han, K.; Wang, Y.; Zhang, C.; Yang, Z.; Wu, H.; Chen, X.; Xu, C. Hit-detector: Hierarchical trinity architecture search for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11405–11414. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; pp. 9627–9636. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Li, L.; Shi, J. Foveabox: Beyound anchor-based object detection. IEEE Trans. Image Processing 2020, 29, 7389–7398. [Google Scholar] [CrossRef]
- Chen, H.; Zhang, L.; Ma, J.; Zhang, J. Target heat-map network: An end-to-end deep network for target detection in remote sensing images. Neurocomputing 2019, 331, 375–387. [Google Scholar] [CrossRef]
- Zhang, W.; Jiao, L.; Liu, X.; Liu, J. Multi-scale feature fusion network for object detection in vhr optical remote sensing images. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 330–333. [Google Scholar]
- Xie, W.; Qin, H.; Li, Y.; Wang, Z.; Lei, J. A novel effectively optimized one-stage network for object detection in remote sensing imagery. Remote Sens. 2019, 11, 1376. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Cheng, G.; Bu, S.; You, X. Rotation-insensitive and context-augmented object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2337–2348. [Google Scholar] [CrossRef]
- Zhu, D.; Xia, S.; Zhao, J.; Zhou, Y.; Niu, Q.; Yao, R.; Chen, Y. Spatial hierarchy perception and hard samples metric learning for high-resolution remote sensing image object detection. Appl. Intell. 2021, 52, 3193–3208. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Operator | Output |
|---|---|---|
| DSC, ReLu6 | ||
| Conv, Linear | ||
| Conv, ReLu6 | ||
| DSC, Linear |
| Input | Operator | Output |
|---|---|---|
| DSC, Leaky ReLu | ||
| Conv, Linear | ||
| Conv, Leaky ReLu | ||
| DSC |
| Methods | mAP | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| R-FCN [51] | 99.80 | 80.82 | 90.48 | 97.88 | 90.69 | 72.38 | 98.99 | 87.18 | 70.44 | 88.62 | 87.74 |
| HitDet [52] | 99.36 | 77.26 | 90.66 | 98.46 | 88.72 | 75.51 | 95.89 | 65.80 | 60.00 | 85.93 | 83.76 |
| FCOS [53] | 90.47 | 73.72 | 90.36 | 98.94 | 89.38 | 80.82 | 96.74 | 87.91 | 61.92 | 88.16 | 85.84 |
| Foveabox [54] | 99.49 | 75.22 | 89.50 | 98.14 | 92.65 | 50.05 | 96.58 | 41.70 | 63.50 | 86.27 | 79.31 |
| Dong et al. [55] | 90.8 | 80.5 | 59.2 | 90.8 | 80.8 | 90.9 | 99.8 | 90.3 | 67.8 | 78.1 | 82.9 |
| MS-FF [56] | 95.79 | 72.50 | 70.90 | 97.83 | 85.62 | 97.20 | 98.82 | 92.40 | 81.74 | 64.64 | 85.64 |
| NEOON [57] | 78.29 | 81.68 | 94.62 | 89.74 | 61.25 | 65.04 | 93.23 | 73.15 | 59.46 | 78.26 | 77.50 |
| HRBM [58] | 99.70 | 90.80 | 90.61 | 92.91 | 90.29 | 80.13 | 90.81 | 80.29 | 68.53 | 87.14 | 87.12 |
| SHDET [59] | 100 | 81.36 | 90.90 | 98.66 | 90.84 | 82.57 | 98.68 | 91.11 | 76.43 | 89.82 | 90.04 |
| YOLO v4 | 99.9 | 89.66 | 98.33 | 97.14 | 97.46 | 93.39 | 99.82 | 84.32 | 75.92 | 93.41 | 92.94 |
| Ours | 99.92 | 92.8 | 98.3 | 97.49 | 98.58 | 96.7 | 99.9 | 83.83 | 83.41 | 92.75 | 94.37 |
| Baseline (CSPDarknet53 + SPP) | mAP | Inference Time | BFLOPS |
|---|---|---|---|
| PANet (YOLO v4) | 92.94% | 0.015 | 59.628 |
| IRA, PANet | 93.87% | 0.015 | 65.720 |
| EIRM, PANet | 94.12% | 0.018 | 67.338 |
| SGPANet | 93.93% | 0.018 | 48.402 |
| SGLPANet | 93.23% | 0.018 | 48.402 |
| Ours | 94.37% | 0.018 | 56.112 |
| YOLO v4 | Ours | |
|---|---|---|
| airplane | 76.61% | 77.82% |
| ship | 71.25% | 72.74% |
| storage tank | 79.71% | 82.05% |
| mAP | 75.86% | 77.54% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, L.; Li, Y.; Rao, X.; Wang, Y.; Zuo, X.; Qiao, B.; Yang, Y. Feature Enhancement-Based Ship Target Detection Method in Optical Remote Sensing Images. Electronics 2022, 11, 634. https://doi.org/10.3390/electronics11040634
Zhou L, Li Y, Rao X, Wang Y, Zuo X, Qiao B, Yang Y. Feature Enhancement-Based Ship Target Detection Method in Optical Remote Sensing Images. Electronics. 2022; 11(4):634. https://doi.org/10.3390/electronics11040634
Chicago/Turabian StyleZhou, Liming, Yahui Li, Xiaohan Rao, Yadi Wang, Xianyu Zuo, Baojun Qiao, and Yong Yang. 2022. "Feature Enhancement-Based Ship Target Detection Method in Optical Remote Sensing Images" Electronics 11, no. 4: 634. https://doi.org/10.3390/electronics11040634