
Modified Yolov3 for Ship Detection with Visible and Infrared Images



Abstract
:1. Introduction
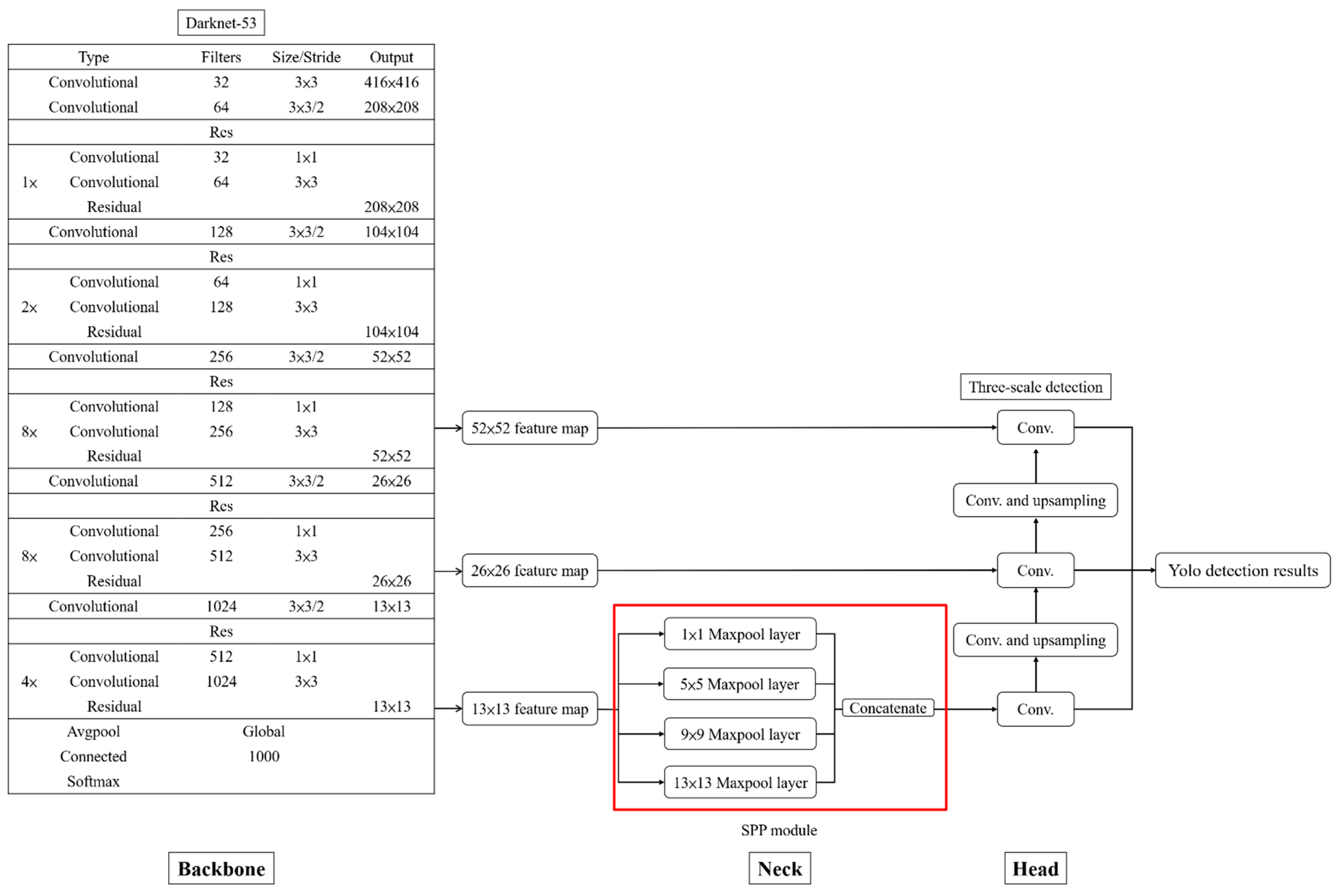
2. Yolov3 Network Architecture
3. Methodology
3.1. Proposed Modified Yolov3 Network Architecture
3.2. Spatial Pyramid Pooling
4. Dataset and Experiment Results
4.1. Ship Dataset
4.2. Evaluation Methods
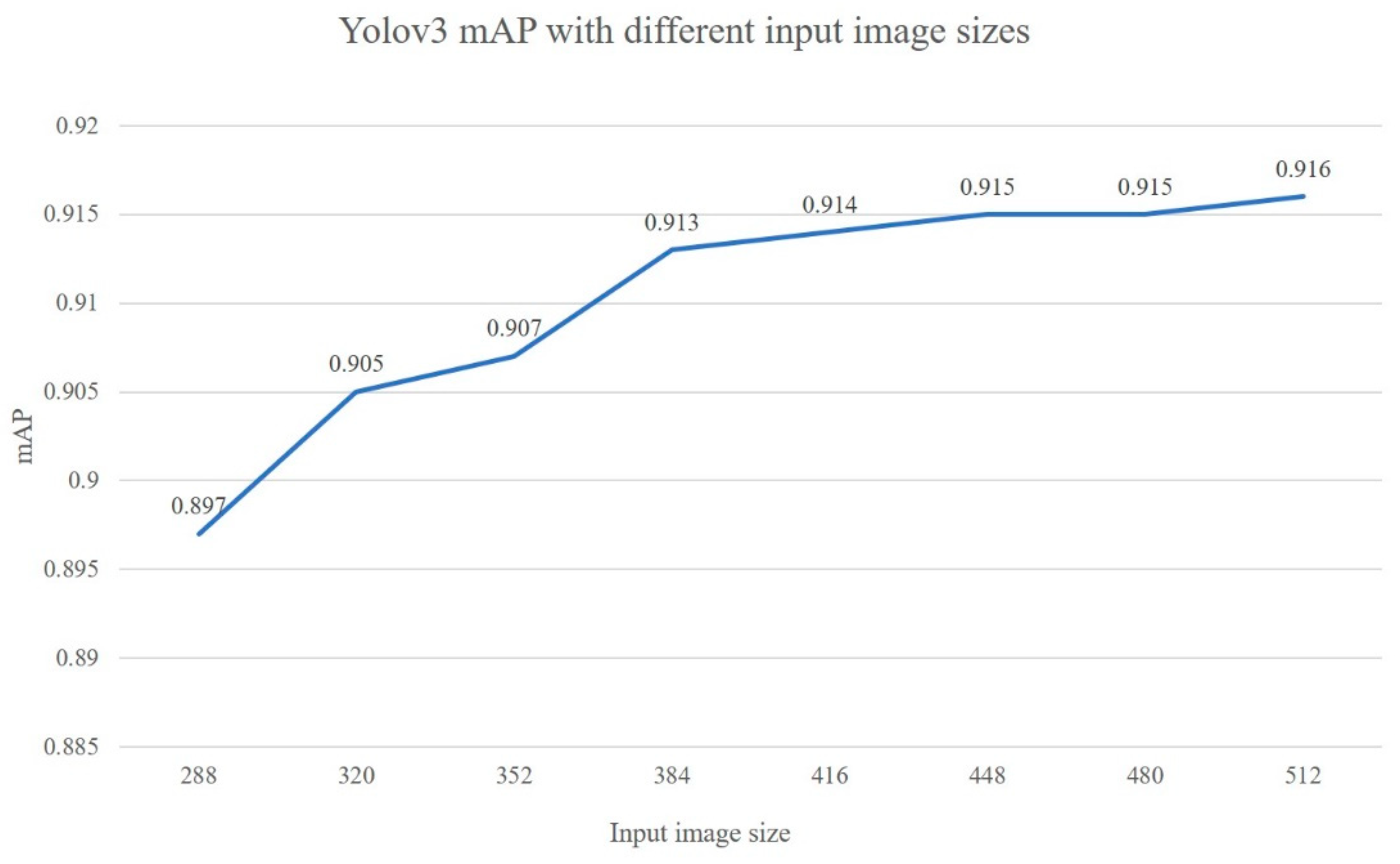
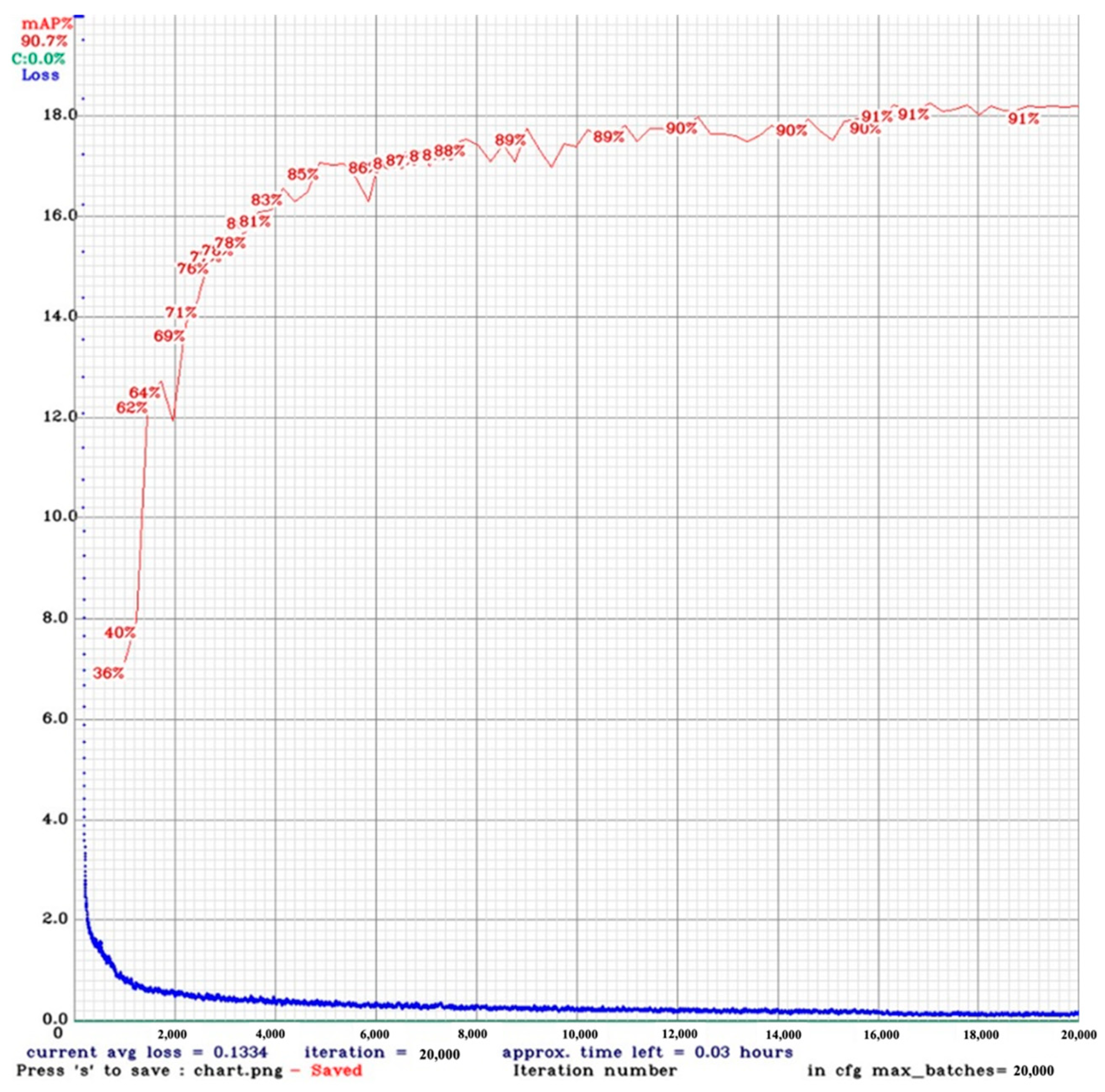
4.3. Modified Yolov3 Performance
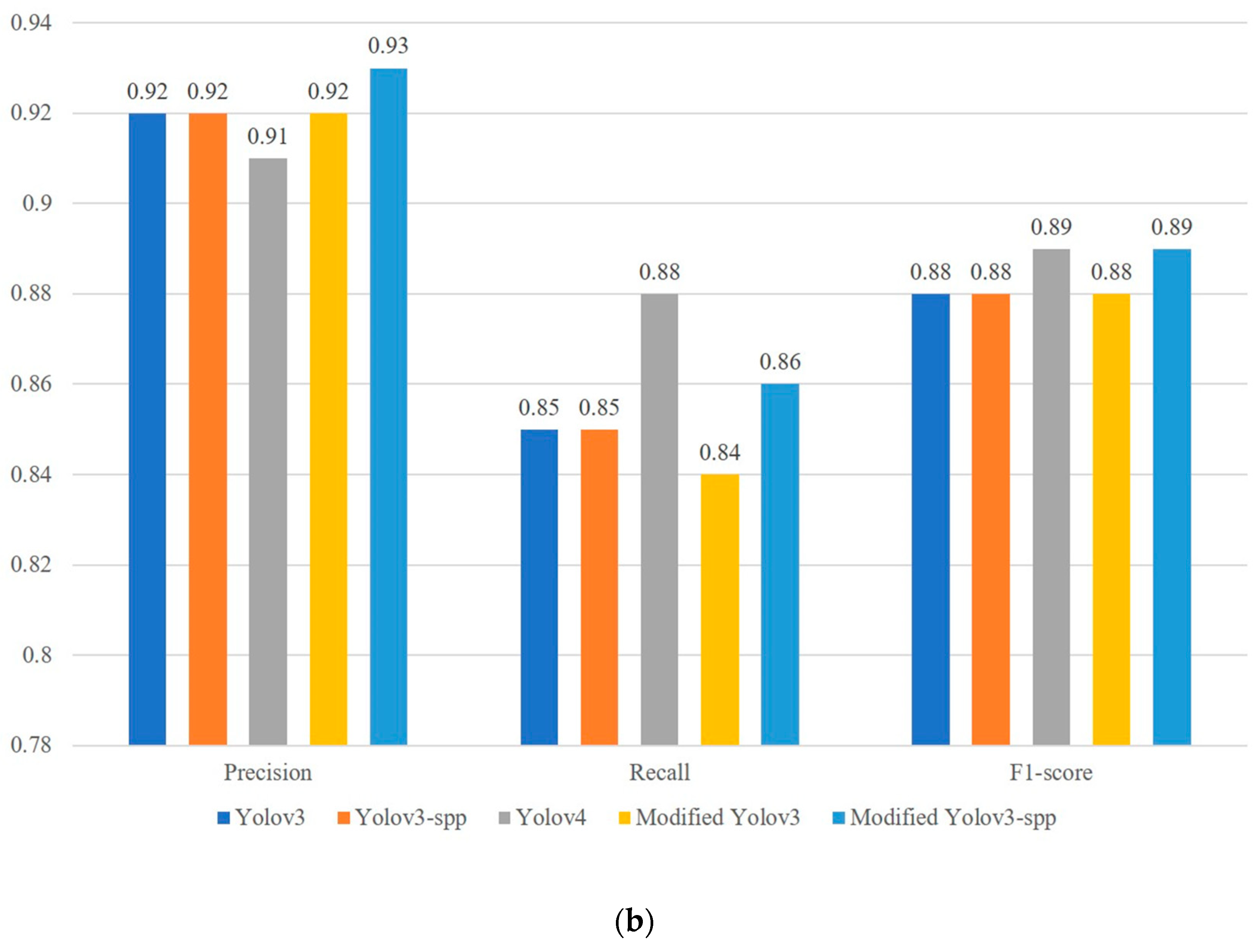
4.4. Network Comparison
4.5. Real Image Verification
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, X.; Chen, H.; Wu, H.; Huang, Y.; Yang, Y.; Zhang, W.; Xiong, P. Robust visual ship tracking with an ensemble framework via multi-view learning and wavelet filter. Sensors 2020, 20, 932. [Google Scholar] [CrossRef] [Green Version]
- Hu, W.C.; Yang, C.Y.; Huang, D.Y. Robust real-time ship detection and tracking for visual surveillance of cage aquaculture. J. Vis. Commun. Image Represent. 2011, 22, 543–556. [Google Scholar] [CrossRef]
- Wang, X.; Chen, C. Adaptive ship detection in SAR images using variance WIE-based method. Signal Image Video Process. 2016, 10, 1219–1224. [Google Scholar] [CrossRef]
- Hwang, J.; Kim, D.; Jung, H.S. An efficient ship detection method for KOMPSAT-5 synthetic aperture radar imagery based on adaptive filtering approach. Korean J. Remote Sens. 2017, 33, 89–95. [Google Scholar] [CrossRef]
- Chang, Y.L.; Anagaw, A.; Chang, L.; Wang, Y.C.; Hsiao, C.Y.; Lee, W.H. Ship Detection Based on YOLOv2 for SAR Imagery. Remote Sens. 2019, 11, 786. [Google Scholar] [CrossRef] [Green Version]
- Shi, Z.; Yu, X.; Jiang, Z.; Li, B. Ship detection in high-resolution optical imagery based on anomaly detector and local shape feature. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4511–4523. [Google Scholar]
- Liu, G.; Zhang, Y.; Zheng, X.; Sun, X.; Fu, K.; Wang, H. A new method on inshore ship detection in high-resolution satellite images using shape and context information. IEEE Geosci. Remote Sens. Lett. 2014, 11, 617–621. [Google Scholar] [CrossRef]
- Nie, T.; He, B.; Bi, G.; Zhang, Y. A Method of Ship Detection under Complex Background. ISPRS Int. J. Geo-Inf. 2017, 6, 159. [Google Scholar] [CrossRef] [Green Version]
- Dong, C.; Liu, J.; Xu, F. Ship detection in optical remote sensing images based on saliency and a rotation-invariant descriptor. Remote Sens. 2018, 10, 400. [Google Scholar] [CrossRef] [Green Version]
- Takeda, H.; Farsiu, S.; Milanfar, P. Kernel regression for image processing and reconstruction. IEEE Trans. Image Process. 2007, 16, 349–366. [Google Scholar] [CrossRef] [Green Version]
- Pitas, I.; Venetsanopoulos, A.N. Nonlinear Digital Filters: Principles and Applications; Kluwer: Boston, MA, USA, 1990. [Google Scholar]
- Ouahabi, A. Signal and Image Multiresolution Analysis; ISTE-Wiley: London, UK; Hoboken, NJ, USA, 2013. [Google Scholar]
- Ouahabi, A. A review of wavelet denoising in medical imaging. In Proceedings of the 8th International Workshop on Systems, Signal Processing and Their Applications (IEEE/WoSSPA), Algiers, Algeria, 12–15 May 2013; pp. 19–26. [Google Scholar]
- Ahmed, S.S.; Messali, Z.; Ouahabi, A.; Trepout, S.; Messaoudi, C.; Marco, S. Nonparametric denoising methods based on contourlet transform with sharp frequency localization: Application to low exposure time electron microscopy images. Entropy 2015, 17, 3461–3478. [Google Scholar] [CrossRef] [Green Version]
- Yang, F.; Xu, Q.; Li, B. Ship detection from optical satellite images based on saliency segmentation and structure-LBP feature. IEEE Geosci. Remote Sens. Lett. 2017, 14, 602–606. [Google Scholar] [CrossRef]
- Xia, Y.; Wan, S.; Yue, L. A novel algorithm for ship detection based on dynamic fusion model of multi-feature and support vector machine. In Proceedings of the IEEE Sixth International Conference on Image and Graphics (ICIG), Hefei, China, 12–15 August 2011; pp. 521–526. [Google Scholar]
- Xu, J.; Sun, X.; Zhang, D.; Fu, K. Automatic detection of inshore ships in high-resolution remote sensing images using robust invariant generalized Hough transform. IEEE Geosci. Remote Sens. Lett. 2014, 11, 2070–2074. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. IEEE Conf. Comput. Vis. Pattern Recognit. 2005, 1, 886–893. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Schapire, R.E. Explaining AdaBoost. In Empirical Inference; Springer: Berlin/Heidelberg, Germany, 2013; pp. 37–52. [Google Scholar]
- Kim, K.; Hong, S.; Choi, B.; Kim, E. Probabilistic ship detection and classification using deep learning. Appl. Sci. 2018, 8, 936. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Sun, D.; Wang, R.; Zhu, C.; Liu, B. Ship target detection based on improved Yolo network. Math. Probl. Eng. 2020, 2020, 6402149. [Google Scholar] [CrossRef]
- Li, H.; Deng, L.; Yang, C.; Liu, J.; Gu, Z. Enhanced Yolov3 tiny network for real-time ship detection from visual image. IEEE Access. 2021, 9, 16692–16706. [Google Scholar] [CrossRef]
- Li, Z.; Zhao, L.; Han, X.; Pan, M. Lightweight ship detection methods based on Yolov3 and DenseNet. Math. Probl. Eng. 2020, 2020, 4813183. [Google Scholar] [CrossRef]
- Yao, Y.; Jiang, Z.; Zhang, H.; Zhao, D.; Cai, B. Ship detection in optical remote sensing images based on deep convolutional neural networks. J. Appl. Remote Sens. 2017, 11, 042611. [Google Scholar] [CrossRef]
- Lin, H.; Shi, Z.; Zou, Z. Fully convolutional network with task partitioning for inshore ship detection in optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1665–1669. [Google Scholar] [CrossRef]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic ship detection in remote sensing images from google earth of complex scenes based on multiscale rotation dense feature pyramid networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Mou, L.; Liu, Q.; Wang, Y.; Zhu, X.X. HSF-Net: Multiscale deep feature embedding for ship detection in optical remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 7147–7161. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Fan, W.; Zhou, F.; Bai, X.; Tao, M.; Tian, T. Ship detection using deep convolutional neural networks for PolSAR images. Remote Sens. 2019, 11, 2862. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Sun, H.; Sun, X.; Yan, M.; Guo, Z.; Fu, K. Position detection and direction prediction for arbitrary-oriented ships via multitask rotation region convolutional neural network. IEEE Access. 2018, 6, 50839–50849. [Google Scholar] [CrossRef]
- Zhasng, S.; Wu, R.; Xu, K.; Wang, J.; Sun, W. R-CNN-Based ship detection from high resolution remote sensing imagery. Remote Sens. 2019, 11, 631. [Google Scholar] [CrossRef] [Green Version]
- Dong, Z.; Lin, B. Learning a robust CNN-based rotation insensitive model for ship detection in VHR remote sensing images. Int. J. Remote Sens. 2020, 41, 3614–3626. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Amsterdam, The Netherlands, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Mark Liao, H.Y. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, Y.; Wang, C.; Zhang, H. Combining a single shot multibox detector with transfer learning for ship detection using Sentinel-1 SAR images. Remote Sens. Lett. 2018, 9, 780–788. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. High-speed ship detection in SAR images based on a grid convolutional neural network. Remote Sens. 2019, 11, 1206. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.; Wang, S.; Zhao, J.; Li, M. Ship tracking and recognition based on Darknet network and YOLOv3 algorithm. J. Comput. Appl. 2019, 39, 1663–1668. [Google Scholar]
- Zhang, Y.; Shu, J.; Hu, L.; Zhou, Q.; Du, Z. A Ship Target Tracking Algorithm Based on Deep Learning and Multiple Features; SPIE: Bellingham, WA, USA, 2020; Volume 11433. [Google Scholar]
- Chang, L.; Chen, Y.T.; Hung, M.H.; Wang, J.H.; Chang, Y.L. Yolov3 based ship detection in visible and infrared images. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision (ECCV) 2014, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Kanungo, T.; Mount, D.M.; Netanyahu, N.S.; Piatko, C.D.; Silverman, R.; Wu, A.Y. An efficient k-means clustering algorithm: Analysis and implementation. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 881–892. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Wang, J. DC-SPP-YOLO: Dense connection and spatial pyramid pooling based YOLO for object detection. Inf. Sci. 2020, 522, 241–258. [Google Scholar] [CrossRef] [Green Version]
- AlexeyAB. AlexeyAB/Darknet: Yolov3. 2020. Available online: https://github.com/AlexeyAB/darknet (accessed on 10 February 2022).
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Tzutalin. Tzutalin/Labelimg. 2018. Available online: https://github.com/tzutalin/labelImg (accessed on 10 February 2022).
- Li, K.; Huang, Z.; Cheng, Y.C.; Lee, C.H. A maximal figure-of-merit learning approach to maximizing mean average precision with deep neural network based classifiers. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 4503–4507. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 10781–10790. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Container | Cruise | War Ship | Yacht | Sailboat | Fishing Boat |
|---|---|---|---|---|---|---|
| Total numbers | 1009 | 528 | 1008 | 1043 | 1000 | 969 |
| Parameters | BFLOPs | FPS | mAP | Precision | Recall | F1-Score | |
|---|---|---|---|---|---|---|---|
| Input image size (Three detection scales) | 448 × 448 | 75.8 | 94.0 | 91.5% | 0.92 | 0.85 | 0.88 |
| 416 × 416 | 65.3 | 95.2 | 91.4% | 0.92 | 0.85 | 0.88 | |
| 384 × 384 | 55.7 | 96.9 | 91.3% | 0.92 | 0.85 | 0.88 | |
| 352 × 352 | 46.8 | 97.8 | 90.7% | 0.92 | 0.85 | 0.88 | |
| Scales (Input image size 384 × 384) | Two detection scales | 51.0 | 98.4 | 90.8% | 0.93 | 0.84 | 0.88 |
| Small target scale | 46.3 | 101.2 | 88.0% | 0.93 | 0.80 | 0.86 | |
| Filters (Input image size 384 × 384 and two detection scales) | −20% | 36.8 | 102.5 | 90.1% | 0.92 | 0.83 | 0.87 |
| −30% | 28.9 | 106.2 | 90.7% | 0.92 | 0.84 | 0.88 | |
| −40% | 23.9 | 119.3 | 89.8% | 0.90 | 0.80 | 0.86 | |
| Parameters | Warship | Container Ship | Cruise Ship | Yacht | Sailboat | Fishing Boat | mAP | |
|---|---|---|---|---|---|---|---|---|
| Input image size (Three detection scales) | 448 × 448 | 88.4 | 91.2 | 90.1 | 87.1 | 94.4 | 87.8 | 89.8 |
| 416 × 416 | 84.6 | 91.1 | 88.0 | 85.1 | 92.0 | 84.0 | 87.5 | |
| 384 × 384 | 84.5 | 91.2 | 87.6 | 85.2 | 92.4 | 83.8 | 87.4 | |
| 352 × 352 | 82.4 | 92.3 | 85.8 | 82.7 | 94.6 | 81.0 | 86.4 | |
| Scales (Input image size 384 × 384) | Two detection scales | 90.4 | 93.1 | 88.6 | 90.5 | 93.0 | 83.6 | 89.9 |
| Small target scale | 87.6 | 92.2 | 85.0 | 87.2 | 89.4 | 80.4 | 87.0 | |
| Filters (Input image size 384 × 384 and two detection scales) | −20% | 89.6 | 93.2 | 95.1 | 93.0 | 92.7 | 83.7 | 91.2 |
| −30% | 91.8 | 92.4 | 94.5 | 94.1 | 96.3 | 87.6 | 92.8 | |
| −40% | 90.4 | 90.3 | 92.4 | 90.1 | 93.8 | 81.6 | 89.4 | |
| BFLOPs | FPS | mAP | Precision | Recall | F1-Score | |
|---|---|---|---|---|---|---|
| EfficientDet | 2.9 | 69.4 | 63.2% | 0.65 | 0.61 | 0.63 |
| ResNet152 | 86.5 | 59.8 | 85.4% | 0.89 | 0.78 | 0.83 |
| SSD | 39.7 | 66.7 | 76.2% | 0.77 | 0.72 | 0.74 |
| Yolov2 | 25.0 | 97.6 | 76.5% | 0.76 | 0.72 | 0.74 |
| Yolov3 | 55.7 | 96.9 | 91.3% | 0.92 | 0.85 | 0.88 |
| Yolov3-spp | 56.0 | 96.8 | 91.7% | 0.92 | 0.85 | 0.88 |
| Yolov4 | 50.8 | 94.5 | 94.8% | 0.91 | 0.88 | 0.89 |
| Yolov2-tiny | 4.6 | 113.7 | 67.5% | 0.61 | 0.69 | 0.64 |
| Yolov3-tiny | 4.7 | 121.1 | 76.7% | 0.73 | 0.68 | 0.70 |
| Yolov4-tiny | 5.0 | 119.6 | 83.4% | 0.81 | 0.78 | 0.79 |
| Modified Yolov3 | 28.9 | 106.2 | 90.7% | 0.92 | 0.84 | 0.88 |
| Modified Yolov3-spp | 29.2 | 104.7 | 93.0% | 0.93 | 0.86 | 0.89 |
| Warship | Container Ship | Cruise Ship | Yacht | Sailboat | Fishing Boat | mAP | |
|---|---|---|---|---|---|---|---|
| EfficientDet | 64.9 | 62.1 | 63.8 | 68.1 | 65.2 | 47.4 | 61.9 |
| Resnet151 | 81.2 | 86.5 | 83.5 | 86.8 | 87.8 | 80.2 | 84.3 |
| SSD | 75.2 | 73.5 | 83.6 | 79.8 | 81.5 | 65.5 | 76.5 |
| Yolov2 | 74.8 | 72.6 | 80.4 | 78.2 | 78.1 | 67.4 | 75.3 |
| Yolov3 | 84.5 | 91.2 | 87.6 | 85.2 | 92.4 | 83.8 | 87.4 |
| Yolov3-spp | 86.7 | 92.1 | 90.7 | 84.1 | 95.6 | 83.5 | 88.8 |
| Yolov4 | 92.9 | 93.8 | 95.7 | 92.9 | 97.2 | 93.4 | 94.3 |
| Yolov2-tiny | 65.8 | 67.8 | 64.7 | 65.3 | 71.8 | 53.4 | 64.8 |
| Yolov3-tiny | 71.1 | 78.7 | 72.5 | 70.2 | 74.8 | 67.8 | 72.5 |
| Yolov4-tiny | 79.6 | 87.0 | 82.3 | 77.3 | 87.5 | 77.2 | 81.8 |
| Modified Yolov3 | 91.8 | 92.4 | 94.5 | 94.1 | 96.3 | 87.6 | 92.8 |
| Modified Yolov3-spp | 92.9 | 93.2 | 95.4 | 93.5 | 95.8 | 88.9 | 93.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, L.; Chen, Y.-T.; Wang, J.-H.; Chang, Y.-L. Modified Yolov3 for Ship Detection with Visible and Infrared Images. Electronics 2022, 11, 739. https://doi.org/10.3390/electronics11050739
Chang L, Chen Y-T, Wang J-H, Chang Y-L. Modified Yolov3 for Ship Detection with Visible and Infrared Images. Electronics. 2022; 11(5):739. https://doi.org/10.3390/electronics11050739
Chicago/Turabian StyleChang, Lena, Yi-Ting Chen, Jung-Hua Wang, and Yang-Lang Chang. 2022. "Modified Yolov3 for Ship Detection with Visible and Infrared Images" Electronics 11, no. 5: 739. https://doi.org/10.3390/electronics11050739
APA StyleChang, L., Chen, Y.-T., Wang, J.-H., & Chang, Y.-L. (2022). Modified Yolov3 for Ship Detection with Visible and Infrared Images. Electronics, 11(5), 739. https://doi.org/10.3390/electronics11050739