1. Introduction
Credit cards are used extensively for online shopping, which has substantially increased due to globalization. However, the higher number of credit card transactions (CCTs) has also resulted in an increased incidence of fraud [
1], necessitating the development of novel fraud detection methods. A wrongful or illegal falsehood performed for individual gain is called fraud [
2]. The process of stealing someone’s identity and performing fraudulent transactions by pretending to be the card owner is called credit card crime (CCC), and credit card fraud detection (CCFD) methods are applied to detect such fraudulent transactions.
There are two types of fraudulent transactions, i.e., offline fraud and online fraud. Offline fraud is conducted by physically stealing the card and physically using it afterward, whereas online fraud is conducted by stealing the victim’s personal information, such as the card holder’s name, card number, and pin code [
3]. Distinguishing between regular and fraudulent transactions is a challenging task, as routine transactions are more common than fraudulent transactions. Therefore, regardless of the fraud identification model (FIM) used, fraudulent transactions should be identified first [
3].
Several studies have been performed in which data mining (DM) and machine learning (ML) methods were used to expose credit card fraud (CCF). In these studies, two main types of methods have been developed for the detection and identification of fraudulent transactions, i.e., unsupervised and supervised methods [
4]. In a supervised method, classification is performed by an algorithm based on the transactional data record. Hidden Markov models, artificial neural networks [
5,
6], support vector machines, k-nearest neighbors, random forests, and Bayesian belief networks are some state-of-the-art algorithms used as supervised approaches [
4].
In unsupervised methods, algorithms detect hidden patterns in non-labeled transactional data. K-Means and SOMs (self-organized maps) are used as unsupervised approaches [
7]. CCFD investigations are restricted to financial organizations, and banks avoid sharing their sensitive records on CCT [
8]. For the identification and detection of fraudulent transactions, specificity and accuracy are used as conventional metrics for evaluating the correctness of predictions. However, we cannot rely on these metrics only, so a sensitivity metric is utilized to estimate the model efficiency. For this purpose, the F-score is recognized as a practical metric for measuring the performance of a CCF test by consolidating precision metrics and sensitivity [
9].
1.1. Traditional Card-Related Fraud
In this case, significant credit card information, such as the pin code, card number, and owner’s name, is compromised and used for fraudulent transactions. The fraudster impersonates the card owner and performs transactions. However, such transactions can be easily recognized.
1.2. Merchant-Related Fraud
Such fraud is conducted by dishonest employees or owners of merchant companies. Merchant collusion transpires when a client’s credit card details are provided to fraudsters by employees or owners. In triangulation fraud, the customer is attracted by substantial discounts on products, provides their card information to purchase these items, and is deceived by the phishing websites of fraudsters.
1.3. Internet-Related Fraud
This is the easiest method used by fraudsters, and it is often used without the fraudster being caught. Several methods, such as credit card generators, false merchant sites, and site cloning, are used for this purpose. For example, the Luhn algorithm is used to create accurate combinations of credit card numbers [
10].
1.4. Other Types of Fraudulent Activities
Other fraud types involve phishing, skimming, cardholder-not-present (CNP), account takeover, etc., can be used by a fraudster.In skimming, data from a card’s magnetic strip are copied by using an electromagnetic card reader, whereas in phishing, the personal information of the card owner is stolen to conduct fraudulent transactions [
11].
An effective fraud detection approach is characterized by the following features [
11]:
Fraudulent activities are reliably and precisely identified.
Fraudulent practices are identified as soon as possible.
Problems in tracing a fraudulent operation are mitigated by not identifying a standard transaction as fraud.
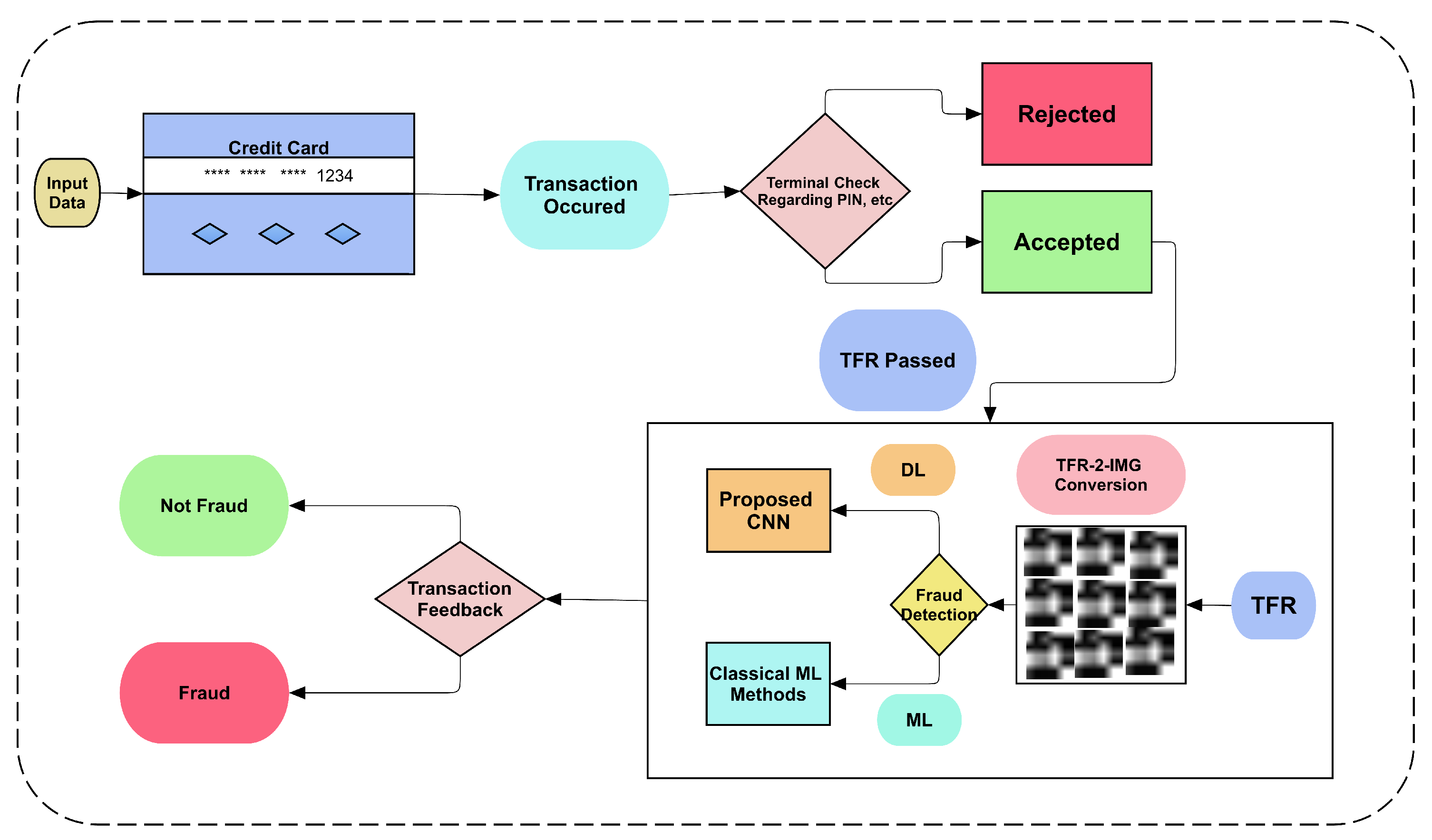
This research proposes a deep learning (DL) strategy to solve the text data problem for online credit card fraud detection using the Kaggle dataset. It was inspired by another study that used binary images data that were generated using ECG signal data [
12]. That said, it generated patches from text data. However, another study used a capsuleNet that introduced and utilized deep features to detect the fraud or legal transaction. The pre-trained architecture of CapsuleNet was utilized, and different ML classifiers were applied that gave promising testing results [
13].
In this study a novel text2IMG conversion mechanism that generates small images is proposed. The generated images are fed to CNN layers with class weights to tackle the imbalanced target class problem. DL and ML techniques were used to verify the proposed system’s robustness and validity. The used deep features reduced the time complexity for machine learning classifiers. The experimental results show that Coarse-KNN achieved 99.87% accuracy by utilizing deep features provided by the proposed CNN.
The rest of the article consists of four sections.
Section 2 and
Section 3 contain the all proposed work.
Section 4 contains results and discussion that illustrate the working of the proposed method using appropriate evaluation measures. Lastly, the overall work is concluded with contributions, limitations, and future work.
2. Related Work
The authors of a previous study proposed a novel hybrid approach [
14] utilizing a divide-and-conquer strategy for solving the issue of imbalanced classes. They trained a model of anomaly detection on the original dataset, and then they utilized a non-linear classifier for a complex subset. Dynamic weighted entropy (DWE) was used to evaluate the quality of the subset. They further tested a real electronic transaction dataset and the Kaggle fraud detection dataset to verify their method.
In another study [
15], a sequential modeling-based ensemble model was developed by utilizing deep recurrent neural networks for the detection of fraudulent transactions. The authors utilized two real datasets to verify their model’s performance. Their model performed better than previous models according to all evaluation criteria.
The authors of another study [
16] utilized machine learning algorithms such as an artificial neural network (ANN), k-nearest neighbors (KNN), and a support vector machine (SVM) to predict fraud occurrences. Then, they applied deep learning and supervised machine learning techniques to classify regular and fraudulent transactions.
Many other studies on various methods have applied anomaly detection using new and to the point features, such as an efficient method that proposed an IoT2Vec feature. A multi-agent system was proposed that assists cluster the unusual activities using the suggested feature [
17]. The large datasets to detect anomalies are scaled using the swarm intelligence method, which makes the algorithms more scalable via parallelism and decentralization approaches. The validation of this evolutionary computing method on synthetic and real-world data was approved, proving its robustness [
18].
The random forest classifier-based fraud detection of a Chinese E-Commerce dataset was proposed in [
19]. In this study, an improved random forest classifier is also presented, and the class imbalance issue between fraud and non-fraud datasets is also discussed.
Prusti et al. proposed a fraud detection system [
20] utilizing a graph database model. In their model, the features of the graph are extracted using the Neo4j tool and then combined with various attributes of transaction databases. Afterward, they applied two unsupervised and five supervised machine learning algorithms. They tested the performances of these machine learning algorithms based on the features extracted from graph and transaction databases.
A novel pattern recognition k-nearest neighbor (PR-KNN) method [
21] was developed to resolve fraud detection problems. The intention behind this new extended method was to prevent hackers from tracing anyone’s online transactions. The authors used genetic algorithms to reduce false alarms and improve fraud detection. Customer behavior was studied to detect fraud. Other authors proposed a novel majority vote ensemble classifier [
22] to detect fraudulent transactions. They used the Web Markov Skeleton Process (WMSP) model to classify user behaviors from data collected through a bank website to detect fraudulent transactions. They used Support Vector Machine (SVM) and Random Forest (RF) classifiers. The MVE classifier showed highly accurate results.
Another study was carried out [
23] to explore various techniques of data engineering to enhance the analytical model’s performance while maintaining features of interpretability. The authors divided their data engineering process into various features and phases of instance engineering. They demonstrated enhanced performance with the data engineering phases on a real dataset of payment transactions.
Seera et al. [
24] implemented 13 machine learning and statistical techniques to detect credit card fraud by utilizing actual public records of transactions. They performed a statistical hypothesis test to determine whether the features acquired through the genetic algorithm performed well compared with basic features for fraud detection. The aggregated features showed reliable outcomes.
In another study [
25], artificial bee colony (ABC) and k-means algorithms were utilized to propose an enhanced two-level credit card fraud tracking model. The model utilized an integrated rule engine to refine dataset features and detect whether each transaction was normal or fraudulent based on several parameters of customer profiles, such as account balance, usage frequency, and geographical location.
Another study was carried out [
26] using three machine learning algorithms, i.e., k-nearest neighbor, naive Bayes, and logistic regression. The authors measured the performances of the algorithms using the area under curve, F-measure, precision, specificity, sensitivity, and accuracy. The results showed that the logistic regression model had the best results.
Zhu et al. carried out a study [
27] to implement several methods of intelligent optimization of WELM. Empirical outcomes proved that dandelion algorithm-based WELM had better performance than the others, including self-learning dandelion, dandelion, genetic, bat, and particle swarm optimization algorithms. Their results demonstrated exceptional detection performance.
Other authors proposed a novel framework [
28] to analyze a series of credit card transactions from three distinct aspects, i.e., (1) the sequence does or does not contain fraud, (2) the series is acquired by adjusting the payment terminal or cardholder, and (3) the series of time spent between previous and current transactions. A hidden Markov model (HMM) was used to model every sequence.
A hybrid-based credit card fraud detection (CCFD) method [
29] was proposed and showed better results than traditional models. The model combines the abilities of synthetic minority oversampling (SMOTE), hyper-parameter optimization (HPO), and recursive feature elimination (RFE). The authors tested their model on several real-world datasets.
A system was proposed [
30] in which the authors ignored the non-additivity of the composition of rules in the pool. The authors suggested utilizing a method for predicting every rule’s contribution to the pool’s performance by using the Shapley value (SV). They tested their model on real-world datasets of credit card fraud. Their proposed approach showed more reliable results compared to traditional approaches.
Bagga et al. carried out a study [
31] to compare the performances of ensemble learning, pipelining, random forests, quadrant discriminant analysis, Ada boost, multi-layer perceptron, k-nearest neighbors, naive Bayes, and logistic regression in credit card fraud detection. They trained nine classifiers on a real-world dataset. They used the ADASYN approach to balance the dataset.
Other authors proposed a strategy [
32] to solve the issue of imbalanced classes in the process of fraud detection while using supervised classification. They trained their model on a dataset with a large number of instances of the minority class compared to the original dataset. They tested their framework on aboveboard datasets and achieved highly accurate results.
In a previous study [
33], a hybrid approach was developed by combining unsupervised and supervised techniques to enhance the accuracy of fraud detection systems. The authors tested unsupervised outlier scores collected at several phases of granularity on real, annotated datasets of fraud detection. Empirical outcomes showed very accurate results of detection.
Another study was carried out [
34] to develop a fraud detection system using an advanced feature engineering process with a deep learning architecture employing homogeneity-oriented behavior analysis (HOBA). The authors verified their system on a large dataset from a bank in China. Their system efficiently detected fraudulent transactions in the dataset.
Kim et al. carried out a study [
35] to compare a deep learning approach and hybrid ensemble by proposing a champion-challenger framework. After development, they tested their models on a massive dataset of a card distribution organization in South Korea. They utilized several evaluation metrics to verify their models and used them as actual fraud detection systems.
A loss function improvement for a deep learning model was presented, and the authors compared the traditional and proposed loss functions [
36]. Lightweight models of CNNs are proposed daily. Repetitive feature maps is the mostly used approach in all of these proposed lightweight CNNs. The generalization in all of these models is the biggest problem. However, to create robustness and generalization in a lightweight CNN, a dynamic adaptation algorithm was proposed [
37]. It integrates the convolution layers module in it. However, it reduces the floating-point operations by 54% and yet achieved the same accuracy on the CIFAR-10 dataset. It also increased the accuracy on IMAGENET by 1.2%. It also used a credit card fraud detection case study to validate its proposed methods and loss function. Many of the other studies that worked on deep learning model loss functions, such as softmax, used CNNs. However, it shows their relevant weakness when we discuss inter-class compactness rather than inter-class separability. Therefore, the authors proposed a pair-wise Gaussian loss function, and compared the softmax and other loss functions. Their method had greatly superior results [
38]. A special domain-specific deep learning model that uses behavioral patterns of transaction record data was proposed [
39]. The aggregation strategy is applied in this method. The behavioral pattern algorithm based on a non-linear model of a Gradient boosting decision tree was proposed. A linear regression method at the end was used that utilized the neighbors’ information, behavioral patterns, and cross features. The results on a real dataset showed efficient performance.
A novel method [
40] called hierarchical clusters-based deep neural networks (HC-DNN) was proposed for credit card fraud detection. This system performed well and included a description of the type of fraud. Cross-validation of the proposed method showed that it achieved better performance than traditional approaches.
Table 1 summarizes recent studies based on computer vision for credit card fraud detection.
By analyzing all related work discussed above, we can conclude that data imbalance is still an open challenge in order to make an unbiased method of machine learning to detect credit-card fraud. Another problem is to make a time-efficient and more miniature yet complex model to detect fraud detection. Therefore, the class imbalance, time efficiency, and space efficiency must be considered, along with an appropriate evaluation measure that considers the class unbalancing issue. The proposed study solves these problems to some extent with an efficient and less time-consuming method that solves the credit-card fraud detection problem.
4. Results and Discussion
Two methods were used to classify the data in the given dataset by converting text into image format. In particular, both deep and machine learning domains were tested on the proposed text2IMG conversion method. The classification results prove the robustness and confidence of the proposed method for credit card fraud detection.
4.1. Dataset Description
A public dataset [
49] of credit card transaction records was utilized in this study. It contains 30 variables as features, including time and the amount that is being debited, to identify fraudulent and non-fraudulent transactions. The dataset was obtained in csv format, where the attribute class is given a value of 0 or 1 for non-fraudulent and fraudulent transactions, respectively. The dataset was then converted into (6 × 5)-dimensional images using the proposed text2IMG conversion method. The details of the dataset are described in
Table 3.
Table 3 shows that the input data instances were the same before and after data conversion. No information or data were lost during the conversion of data.
4.2. Evaluation Measures
Several evaluation measures can be used to assess performance. These measures were used to evaluate the trained models in our study. We chose the most commonly used evaluation measures, namely, accuracy, sensitivity, and specificity. These evaluation measures can provide a more in-depth analysis of the predictive ability of the proposed models [
50] and are expressed as:
In Equation (10), the general measures include four individual terms: true positives (TP), false positives (FP), true negatives (TN), and false negatives (FN). In the proposed method, the dataset must contain two types of classes, fraud and non-fraud. A TP indicates the correct classification of fraud. Similarly, a TN indicates the correct classification of a non-fraudulent transaction. An FP means that a non-fraud transaction was classified as fraud, whereas an FN indicates that fraud was classified as non-fraud.
Among these four terms, accuracy provides the most intuitive overall measure of the model’s predictive ability. In this measure, the numerator contains all correctly labeled positive and negative class instances. The second measure is sensitivity, which is the ratio of correctly labeled fraud instances over the sum of all actual fraud instances, regardless of whether or not they were correctly predicted. The third measure is specificity, which is a measure of the model’s ability to detect negative instances. It is calculated by dividing the number of correct non-fraud predictions by the sum of all actual non-fraud instances, regardless of whether or not they were correctly predicted.
4.3. CNN Classification Results
The proposed CNN uses data converted into images with the previously discussed layers and parameters. The training and testing data were divided in a 70/30 split ratio, and the fraud detection results on testing data were measured in terms of accuracy, sensitivity, and specificity.
Table 4 shows the three measures used to indicate the overall accuracy and the true positive and true negative prediction ratios. The table shows that the accuracy is higher than the sensitivity. However, these results are from tests on 30% of the data, which might not be highly reliable if big data are input. Although the proposed CNN does not achieve high classification scores for the detection of credit card fraud, the trained CNN extracts meaningful high-level features that can be used in the classification pipeline. These feature maps are transferred from the fully connected layer of the trained CNN model and further fed into classical machine learning classifiers.
4.4. Machine Learning Classification Results
Different types of training and testing variations of the given data can be used to test machine learning methods. Different data splits for cross-correlation can also be applied, but we opted to use 5 and 10-fold cross-validation. This removes any bias involved in the overfitting and underfitting of models, if present.
Table 5 shows the 5-fold-based predictions. The best accuracy was achieved by the KNN variants, as is also shown in the performance graphs in
Figure 3. The accuracy values vary slightly but generally remain the same. For KNN methods, the accuracy ranges from 99.80% to 99.87%. However, the accuracy measure range changes for ensemble methods, varying from 80.29% to 99.85%, which is lower compared to the KNN variants. Sensitivity, also known as recall, is an important measure of the model’s ability to detect positive instances. Its low value compared to accuracy and specificity may be explained as follows. The F1-score is an important measure to look in regard to the class imbalance issue. Therefore, if we look at the CNN classified results, the 33.24% is low, whereas in the ML approaches, the F1-score is improved, the highest (57.31%) being achieved via Coarse-KNN. As previously discussed, there is a great class imbalance in the dataset. However, we attempted to solve this problem in the CNN by assigning weights to the classes by using the frequency of each class. Therefore, the CNN’s sensitivity is higher than those of the ML methods. If we look at specificity, we can see that it is slightly higher than the accuracy for all KNN variants and the two best-performing ensemble methods. This explains the rarity of false negatives in the results. Therefore, we can conclude that the model performs well in predicting the negative class. To discuss each class instance in the evaluation, we show a confusion matrix in
Table 6 containing all of the above-discussed models.
As indicated in
Table 6, among the KNN variants, Coarse-KNN performed the best (fraud case detection) with 249 correctly predicted instances, whereas Fine-KNN and Medium-KNN correctly predicted 210 and 219 instances of the fraud (positive) class, respectively. The ensemble method with the lowest accuracy had better sensitivity than all the KNN methods. Thus, LP-boost is not the worst method in terms of positive class predictions if we compare it to all KNN methods. Similarly, the better performing ensemble methods, the bagged and subspace classifiers, also achieved better results for positive class predictions, as they correctly predicted 264 and 270 instances of the positive class and thus outperformed KNN methods. Next, we explore the numbers of negative class predictions, which were overestimated. For KNN variant-based predictions of the negative class, only 285 class predictions were incorrect, whereas 284,030 were correctly predicted to be normal or non-fraudulent transactions. This number of correct predictions increased for Medium-KNN and Coarse-KNN, which correctly predicted 284,203 and 284,187, respectively, and they produced fewer incorrect predictions than Fine-KNN, with only 112 and 128 wrong predictions. However, if we look at ensemble method-based negative class predictions, then the situation is different. LP-boost has the worst results as compared to the other five classifiers, with 5591 wrong class predictions. However, the bagged and subspace ensemble methods produced 149 and 517 wrong predictions, respectively. It seems that the bagged-boost ensemble method performed best among the ensemble methods, and of all six classifiers, Medium-KNN provided the fewest incorrect predictions of the negative class. To cross-check the robustness of the classifiers, 10-fold validation was also applied to the given set of deep features. The 5-fold prediction results for the six classification methods are presented in
Figure 3.
The 10-fold-based results of the same six classification methods are shown in
Table 7. Increasing the number of folds means that the confidence of the validation method also increases. If using more folds enhances the confidence of the classifiers, then the accuracy is expected to decrease, but in this case, the accuracy increased for all six classifiers. This suggests that more data require more folds of validation for training and testing, which will ultimately enhance the validation results. For example, the method with the worst accuracy in the 5-fold method improved its accuracy from 80.29 to 90.75, an almost 10% increase. Therefore, we consider this to support our argument. However, let us look at the other 10-fold evaluation measures as compared to 5-fold measures. The sensitivity value increased for all KNN variants, meaning that using more folds not only increased the accuracy of these methods, but also improved their sensitivity. However, the ensemble methods did not show this increase in sensitivity. The specificity values of all six classifiers remained almost the same in both 5 and 10-fold validation. The F1-scores slightly improved as compared to 5-Fold methods, as the F1-score of Coarse-KNN was improved from 57.31% to 57.80%. Kappa is a statistical measure that provides the level of agreement on data integrity. The maximum kappa value achieved in the 5-fold method was 0.5725, which indicates a low level of agreement on data integrity, as the data have a great class imbalance. With the 10-fold method, Coarse-KNN achieved the highest kappa value of 0.5773, which is slightly higher than in the 5-fold case. A plot is shown in
Figure 4 for all of these values.
Overall, we can conclude that more data require more folds, which will ultimately improve the evaluation measures.
In
Table 8, the confusion matrix of all classification methods using 10-fold validation is shown. Fine-KNN had 215 correct predictions of the positive class (fraud). Medium-KNN and Coarse-KNN achieved better results than Fine-KNN, with 222 and 252 correct predictions. Among the negative class instances predicted by KNN variants, 275, 112, and 128 were incorrect predictions, whereas correct predictions were large in number. The overall performances of KNN variants in predicting the positive class were better using the 10-fold method compared to the 5-fold method.
The ensemble methods correctly predicted 255, 231, and 249 instances of fraud, which was an improvement for bagged-ensemble but not for the other two methods. Among 26,104 negative instance predictions, 137 and 413 were incorrectly predicted with bagged and subspace ensemble methods, which was an improvement. If we analyze the overall results for positive and negative instances, then we can confirm that the results support our hypothesis above: that big data might need more folds for training and testing on positive and negative classes.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}