
Inverse Transform Using Linearity for Video Coding



Abstract
:1. Introduction
2. VVC Transforms and Proposed Method
2.1. Introduction to DCT-II, DST-VII, and DCT-VIII
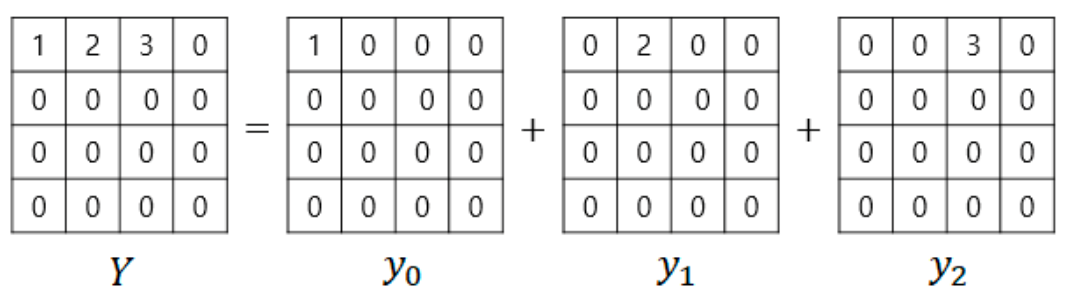
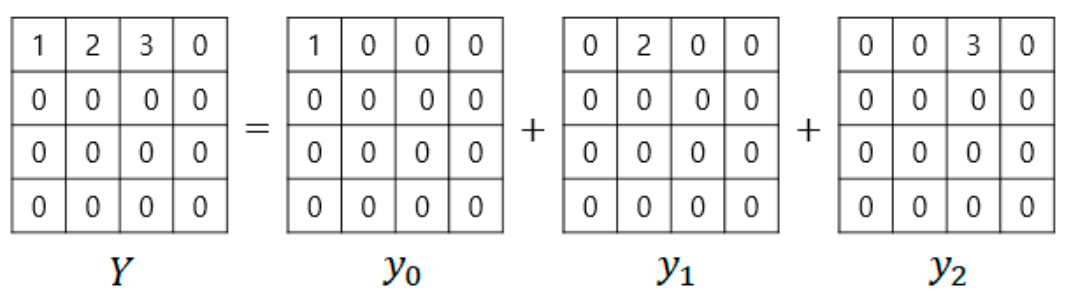
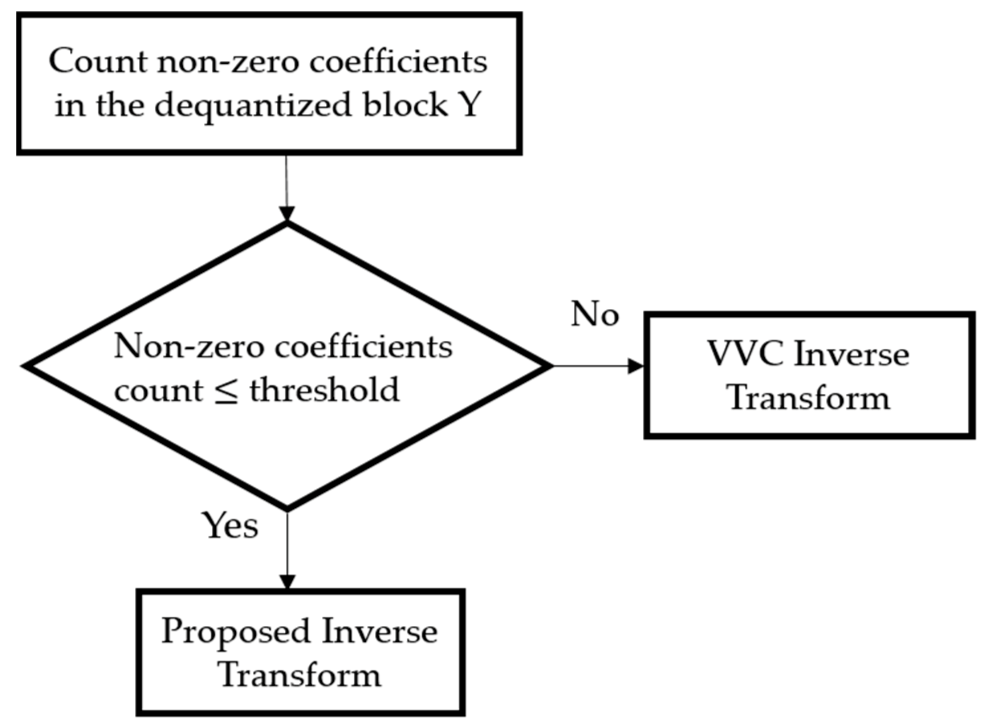
2.2. Propose Fast Inverse Transform Using Linearity
3. Experimental Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Advanced Video Coding (AVC). Standard ITU-T Recommendation H.264 and ISO/IEC 14496-10. May 2003. Available online: https://www.itu.int/rec/T-REC-H.264 (accessed on 28 February 2022).
- Wiegand, T.; Sullivan, G.J.; Bjontegaard, G.; Luthra, A. Overview of the H.264/AVC Video Coding Standard. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 560–576. [Google Scholar] [CrossRef] [Green Version]
- High Efficient Video Coding (HEVC). Standard ITU-T Recommendation H.265 and ISO/IEC 23008-2. April 2013. Available online: https://www.itu.int/rec/T-REC-H.265 (accessed on 28 February 2022).
- Sullivan, G.J.; Ohm, J.; Han, W.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Bross, B.; Chen, J.; Liu, S.; Wang, Y.-K. Versatile Video Coding (Draft 10). In Proceedings of the 19th Meeting Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11, Teleconference (Online), 22 June–1 July 2020. [Google Scholar]
- Bross, B.; Wang, Y.-K.; Ye, Y.; Liu, S.; Sullivan, G.J.; Ohm, J. Overview of the Versatile Video Coding (VVC) Standard and its Applications. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3736–3764. [Google Scholar] [CrossRef]
- Jain, A.K. Fundamentals of Digital Image Processing. Prentice Hall: Englewood Cliffs, NJ, USA, 1989; pp. 163–175. [Google Scholar]
- Ahmed, N.; Natarajan, T.; Rao, K.R. Discrete Cosine Transform. IEEE Trans. Comput. 1974, C-23, 90–93. [Google Scholar] [CrossRef]
- Rose, K.; Heiman, A.; Dinstein, I. DCT/DST Alternate-Transform Image Coding. IEEE Trans. Commun. 1990, 38, 94–101. [Google Scholar] [CrossRef]
- Zhao, X.; Chen, J.; Karczewicz, M.; Zhang, L.; Li, X.; Chien, W.-J. Enhanced Multiple Transform for Video Coding. In Proceedings of the 2016 Data Compress. Conf. (DCC), Snowbird, UT, USA, 30 March–1 April 2016; pp. 73–82. [Google Scholar] [CrossRef]
- Han, J.; Saxena, A.; Melkote, V.; Rose, K. Jointly Optimized Spatial Prediction and Block Transform for Video and Image Coding. IEEE Trans. Image Process. 2012, 21, 1874–1884. [Google Scholar] [CrossRef] [PubMed]
- Budagavi, M.; Fuldseth, A.; Bjøntegaard, G.; Sze, V.; Sadafale, M. Core Transform Design in the High Efficiency Video Coding (HEVC) Standard. IEEE J. Sel. Top. Signal Process. 2013, 7, 1029–1041. [Google Scholar] [CrossRef]
- Zhao, X.; Chen, J.; Karczewicz, M.; Said, A.; Seregin, V. Joint Separable and Non-Separable Transforms for Next-Generation Video Coding. IEEE Trans. Image Process. 2018, 27, 2514–2525. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Chen, J.; Said, A.; Seregin, V.; Egilmez, H.E.; Karczewicz, M. NSST: Non-separable secondary transforms for next generation video coding. In Proceedings of the 2016 Picture Coding Symposium (PCS), Nuremberg, Germany, 4–7 December 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Zhao, X.; Kim, S.-H.; Zhao, Y.; Eglimez, H.; Koo, M.; Liu, S.; Lainema, J.; Karczewicz, M. Transform Coding in the VVC Standard. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3878–3890. [Google Scholar] [CrossRef]
- Koo, M.; Salehifar, M.; Lim, J.; Kim, S.-H. CE6-Related: 32 Point MTS Based on Skipping High Frequency Coefficients. In Proceedings of the 13th Meeting Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11, Marrakech, Morocco, 9–18 January 2019. [Google Scholar]
- Koo, M.; Salehifar, M.; Lim, J.; Kim, S.-H. Low Frequency Non-Separable Transform (LFNST). In Proceedings of the 2019 Picture Coding Symposium (PCS), Ningbo, China, 12–15 November 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Koo, M.; Salehifar, M.; Lim, J.; Kim, S.-H. CE6: Reduced Secondary Transform (RST) (CE6-3.1). In Proceedings of the 14th Meeting Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11, Geneva, Switzerland, 19–27 March 2019. [Google Scholar]
- Chiang, M.-S.; Hsu, C.-W.; Huang, U.-W.; Lei, S.-M. CE6-related: Simplifications for LFNST, document-O0292. In Proceedings of the 15th Meeting Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11, Gothenburg, Sweden, 3–12 July 2019. [Google Scholar]
- Siekmann, M.; Schwarz, H.; Marpe, D.; Wiegand, T. CE6-2.1: Simplification of Low Frequency Non-Separable Transform, document-O0094. In Proceedings of the 15th Meeting Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11, Gothenburg, Sweden, 3–12 July 2019. [Google Scholar]
- Schwarz, H.; Coban, M.; Karczewicz, M.; Chuang, T.-D.; Bossen, F.; Alshin, A.; Lainema, J.; Helmrich, C.; Wiegand, T. Quantization and Entropy Coding in the Versatile Video Coding (VVC) Standard. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3891–3906. [Google Scholar] [CrossRef]
- VVC Test Model (VTM-8.2) Reference Software. Available online: https://vcgit.hhi.fraunhofer.de/jvet/VVCSoftware_VTM/-/tree/VTM-8.2 (accessed on 6 September 2021).
- Hung, C.-Y.; Landman, P. Compact inverse discrete cosine transform circuit for MPEG video decoding. In Proceedings of the 1997 IEEE Workshop on Signal Processing Systems. SiPS 97 Design and Implementation formerly VLSI Signal Processing, Leicester, UK, 5 November 1997; pp. 364–373. [Google Scholar] [CrossRef]
- Zhao, X.; Li, X.; Luo, Y.; Liu, S. CE6: Fast DST-7/DCT-8 With Dual Implementation Support (Test 6.2.3), document-M0497. In Proceedings of the 13th Meeting Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11, Marrakech, Morocco, 9–18 January 2019. [Google Scholar]
- Zhang, Z.; Zhao, X.; Li, X.; Li, L.; Luo, Y.; Liu, S.; Li, Z. Fast DST-VII/DCT-VIII with Dual Implementation Support for Versatile Video Coding. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 355–371. [Google Scholar] [CrossRef]
- Bossen, F.; Boyce, J.; Suehring, K.; Li, X.; Seregin, V. JVET Common Test Conditions and Software Reference Configurations for SDR Video, document JVET-T2010. In Proceedings of the 20th Meeting Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11, Teleconference (Online), 7–16 October 2020. [Google Scholar]
- Bjontegaard, G. Calculation of Average PSNR Differences between Rd-Curves, Austin, TX, USA. 10–18 April 2001. Available online: http://wftp3.itu.int/av-arch/video-site/0104_Aus/ (accessed on 3 January 2022).
- Bjontegaard, G. Improvement of Bd-PSNR Model, Berlin, Germany. 10–18 July 2008. Available online: https://www.itu.int/wftp3/av-arch/video-site/0807_Ber/ (accessed on 3 January 2022).
- Dong, X.; Shen, L.; Yu, M.; Yang, H. Fast Intra Mode Decision Algorithm for Versatile Video Coding. IEEE Trans. Multimed. 2022, 24, 400–414. [Google Scholar] [CrossRef]
- Yang, H.; Shen, L.; Dong, X.; Ding, Q.; An, P.; Jiang, G. Low-Complexity CTU Partition Structure Decision and Fast Intra Mode Decision for Versatile Video Coding. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1668–1682. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Width (m) | ||||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 4 | 8 | 16 | 32 | 64 | ||
| Height (n) | 1 | N/A | 2 | 8 | 24 | 88 | 344 | 684 |
| 2 | 2 | 8 | 24 | 64 | 208 | 752 | 1432 | |
| 4 | 8 | 24 | 64 | 160 | 480 | 1632 | 2992 | |
| 8 | 24 | 64 | 160 | 384 | 1088 | 3520 | 6240 | |
| 16 | 88 | 208 | 480 | 1088 | 2816 | 8320 | 13,760 | |
| 32 | 344 | 752 | 1632 | 3520 | 8320 | 22,016 | 32,896 | |
| 64 | 684 | 1496 | 3248 | 7008 | 16,576 | 43,904 | 65,664 | |
| Width (m) | |||||
|---|---|---|---|---|---|
| 4 | 8 | 16 | 32 | ||
| Height (n) | 4 | 64 | 320 | 636 | 2608 |
| 8 | 320 | 1024 | 2040 | 5984 | |
| 16 | 636 | 2040 | 4064 | 11,952 | |
| 32 | 2736 | 7008 | 13,984 | 29,760 | |
| Width (m) | ||||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 4 | 8 | 16 | 32 | 64 | ||
| Height (n) | 1 | N/A | 2 | 8 | 28 | 100 | 372 | 802 |
| 2 | 2 | 8 | 24 | 72 | 232 | 808 | 1668 | |
| 4 | 8 | 24 | 64 | 176 | 528 | 1744 | 3464 | |
| 8 | 28 | 72 | 176 | 448 | 1248 | 3872 | 7312 | |
| 16 | 100 | 232 | 528 | 1248 | 3200 | 9152 | 16,032 | |
| 32 | 372 | 808 | 1744 | 3872 | 9152 | 23,808 | 37,568 | |
| 64 | 802 | 1732 | 3720 | 8208 | 19,232 | 49,472 | 76,992 | |
| Width (m) | |||||
|---|---|---|---|---|---|
| 4 | 8 | 16 | 32 | ||
| Height (n) | 4 | 88 | 344 | 796 | 3048 |
| 8 | 344 | 1024 | 2264 | 6768 | |
| 16 | 796 | 2264 | 4960 | 13,968 | |
| 32 | 3224 | 7792 | 16,448 | 34,464 | |
| Class | QP | DCT-II/DCT-II | DST-VII/DCT-VIII (DST-VII, DST-VII), (DST-VII, DCT-VIII), (DCT-VIII, DST-VII), (DCT-VIII, DCT-VIII) | Other Combinations |
|---|---|---|---|---|
| A1 | 22 | 62.92% | 33.29% | 3.79% |
| 27 | 67.21% | 30.02% | 2.77% | |
| 32 | 72.08% | 25.60% | 2.32% | |
| 37 | 77.10% | 20.79% | 2.11% | |
| Average | 69.83% | 27.43% | 2.75% | |
| A2 | 22 | 65.48% | 34.02% | 1.4% |
| 27 | 59.97% | 37.99% | 2.03% | |
| 32 | 60.65% | 37.55% | 1.80% | |
| 37 | 61.71% | 36.25% | 2.04% | |
| Average | 61.95% | 36.45% | 1.82% | |
| B | 22 | 68.48% | 29.58% | 1.94% |
| 27 | 59.57% | 36.17% | 4.26% | |
| 32 | 60.21% | 34.36% | 5.42% | |
| 37 | 64.46% | 30.15% | 5.39% | |
| Average | 63.18% | 32.57% | 4.25% | |
| C | 22 | 59.38% | 33.70% | 6.91% |
| 27 | 58.50% | 32.83% | 8.67% | |
| 32 | 59.02% | 31.35% | 9.63% | |
| 37 | 61.95% | 27.88% | 10.17% | |
| Average | 59.71% | 31.44% | 8.85% | |
| D | 22 | 56.15% | 37.07% | 6.78% |
| 27 | 53.47% | 37.21% | 9.32% | |
| 32 | 54.84% | 33.94% | 11.22% | |
| 37 | 58.66% | 29.10% | 12.24% | |
| Average | 55.78% | 34.33% | 9.89% |
| Width (m) | ||||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 4 | 8 | 16 | 32 | 64 | ||
| Height (n) | 1 | N\A | 1 | 2 | 3 | 5 | 10 | 10 |
| 2 | 1 | 1 | 2 | 3 | 6 | 11 | 11 | |
| 4 | 2 | 2 | 3 | 4 | 7 | 12 | 11 | |
| 8 | 3 | 2 | 4 | 5 | 8 | 13 | 12 | |
| 16 | 5 | 4 | 6 | 7 | 10 | 15 | 13 | |
| 32 | 10 | 7 | 10 | 12 | 15 | 20 | 15 | |
| 64 | 10 | 7 | 10 | 12 | 15 | 20 | 15 | |
| Width (m) | |||||
|---|---|---|---|---|---|
| 4 | 8 | 16 | 32 | ||
| Height (n) | 4 | 3 | 8 | 9 | 19 |
| 8 | 8 | 14 | 15 | 22 | |
| 16 | 7 | 14 | 14 | 22 | |
| 32 | 17 | 24 | 25 | 28 | |
| Class | Sequence Name | Frame Count | Frame Rate | Bit Depth |
|---|---|---|---|---|
| A1 (4K) | Tango2 | 294 | 60 | 10 |
| FoodMarket4 | 300 | 60 | 10 | |
| Campfire | 300 | 30 | 10 | |
| A2 (4K) | CatRobot | 300 | 60 | 10 |
| DaylightRoad2 | 300 | 60 | 10 | |
| ParkRunnung3 | 300 | 50 | 10 | |
| B (1080p) | MarketPlace | 600 | 60 | 10 |
| RitualDance | 600 | 60 | 10 | |
| Cactus | 500 | 50 | 8 | |
| BasketballDrive | 500 | 50 | 8 | |
| BQTerrace | 600 | 60 | 8 | |
| C (WVGA) | RaceHorses | 300 | 30 | 8 |
| BQMall | 600 | 60 | 8 | |
| PartyScene | 500 | 50 | 8 | |
| BasketballDrill | 500 | 50 | 8 | |
| D (WQVA) | RaceHorses | 300 | 30 | 8 |
| BQSquare | 600 | 60 | 8 | |
| BlowingBubbles | 500 | 50 | 8 | |
| BasketballPass | 500 | 50 | 8 |
| QP | Class | Y | Cb | Cr | |||
|---|---|---|---|---|---|---|---|
| VVC Inverse Transform | Proposed | VVC Inverse Transform | Proposed | VVC Inverse Transform | Proposed | ||
| 22 | A1 | 56.84% | 43.16% | 44.38% | 55.62% | 33.62% | 66.38% |
| A2 | 63.99% | 36.01% | 60.88% | 39.12% | 62.73% | 37.27% | |
| B | 66.76% | 33.24% | 51.27% | 48.73% | 50.71% | 49.29% | |
| C | 66.92% | 33.08% | 60.14% | 39.86% | 63.28% | 36.72% | |
| D | 74.04% | 25.96% | 62.21% | 37.79% | 63.38% | 36.62% | |
| Average | 65.71% | 34.29% | 55.78% | 44.22% | 54.74% | 45.26% | |
| 27 | A1 | 43.20% | 56.80% | 42.60% | 57.40% | 31.22% | 68.78% |
| A2 | 46.66% | 53.34% | 53.77% | 46.23% | 58.91% | 41.09% | |
| B | 54.20% | 45.80% | 43.86% | 56.14% | 45.41% | 54.59% | |
| C | 58.04% | 41.96% | 53.30% | 46.70% | 55.03% | 44.97% | |
| D | 66.22% | 33.78% | 54.34% | 45.66% | 56.23% | 43.77% | |
| Average | 53.66% | 46.34% | 49.57% | 50.43% | 49.36% | 50.64% | |
| 32 | A1 | 41.50% | 58.50% | 39.82% | 60.18% | 27.06% | 72.94% |
| A2 | 38.67% | 61.33% | 47.81% | 52.19% | 52.77% | 47.23% | |
| B | 48.24% | 51.76% | 38.22% | 61.78% | 40.61% | 59.39% | |
| C | 52.07% | 47.93% | 45.14% | 54.86% | 46.65% | 53.35% | |
| D | 61.53% | 38.47% | 45.39% | 54.61% | 48.38% | 51.62% | |
| Average | 48.40% | 51.60% | 43.28% | 56.72% | 43.09% | 56.91% | |
| 37 | A1 | 43.63% | 56.37% | 33.00% | 67.00% | 22.67% | 77.33% |
| A2 | 36.98% | 63.02% | 43.11% | 56.89% | 47.07% | 52.93% | |
| B | 46.69% | 53.51% | 33.19% | 66.81% | 35.73% | 64.27% | |
| C | 49.65% | 50.35% | 38.41% | 61.59% | 41.10% | 58.90% | |
| D | 58.27% | 41.73% | 39.13% | 60.87% | 42.51% | 57.49% | |
| Average | 47.00% | 53.00% | 37.37% | 62.63% | 37.81% | 62.19% | |
| Class | Sequence | BD-Rates (%) and Runtime Ratios in AI | BD-Rates (%) and Runtime Ratios in RA | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Y | Cb | Cr | EncT | DecT | Y | Cb | Cr | EncT | DecT | ||
| A1 | Tango2 | 0.03% | −0.22% | 0.05% | 98% | 98% | 0.04% | −0.30% | 0.11% | 90% | 89% |
| FoodMarket4 | −0.01% | 0.12% | 0.09% | 98% | 99% | 0.04% | −0.08% | −0.05% | 87% | 82% | |
| Campfire | 0.00% | −0.07% | −0.11% | 99% | 97% | 0.02% | −0.01% | 0.04% | 93% | 96% | |
| Average | 0.01% | −0.06% | 0.01% | 98% | 98% | 0.03% | −0.13% | 0.03% | 90% | 89% | |
| A2 | CatRobot | 0.01% | 0.00% | 0.08% | 98% | 94% | −0.02% | −0.11% | −0.12% | 95% | 87% |
| DaylightRoad2 | 0.02% | −0.10% | 0.03% | 99% | 98% | −0.01% | −0.06% | 0.31% | 97% | 90% | |
| ParkRunnung3 | 0.00% | 0.00% | 0.00% | 98% | 95% | −0.01% | 0.01% | 0.02% | 94% | 86% | |
| Average | 0.01% | −0.04% | 0.04% | 98% | 96% | −0.01% | −0.05% | 0.07% | 95% | 88% | |
| B | MarketPlace | −0.01% | 0.07% | 0.05% | 88% | 95% | 0.01% | 0.03% | 0.14% | 99% | 84% |
| RitualDance | −0.01% | −0.13% | 0.07% | 89% | 95% | 0.07% | 0.18% | 0.08% | 98% | 99% | |
| Cactus | 0.01% | −0.03% | 0.00% | 87% | 92% | 0.01% | −0.03% | −0.11% | 98% | 97% | |
| BasketballDrive | 0.04% | −0.12% | −0.03% | 88% | 97% | 0.06% | −0.21% | −0.02% | 99% | 93% | |
| BQTerrace | 0.00% | 0.15% | 0.15% | 87% | 91% | −0.01% | −0.05% | −0.39% | 95% | 96% | |
| Average | 0.01% | −0.01% | 0.05% | 88% | 94% | 0.03% | −0.01% | −0.06% | 98% | 94% | |
| C | RaceHorses | 0.01% | 0.10% | −0.05% | 99% | 94% | 0.02% | −0.25% | −0.03% | 98% | 77% |
| BQMall | 0.00% | −0.13% | −0.16% | 100% | 92% | 0.07% | 0.05% | 0.15% | 98% | 86% | |
| PartyScene | 0.00% | 0.07% | −0.11% | 101% | 92% | 0.00% | −0.03% | −0.10% | 99% | 91% | |
| BasketballDrill | 0.00% | −0.04% | 0.06% | 99% | 98% | 0.01% | −0.03% | −0.13% | 99% | 94% | |
| Average | 0.00% | 0.00% | −0.06% | 100% | 94% | 0.02% | −0.07% | −0.03% | 99% | 87% | |
| D | RaceHorses | 0.02% | 0.00% | −0.27% | 98% | 98% | 0.01% | −0.07% | 0.18% | 99% | 95% |
| BQSquare | −0.01% | 0.34% | 0.06% | 99% | 97% | 0.04% | 0.40% | 0.25% | 99% | 100% | |
| BlowingBubbles | 0.01% | −0.26% | −0.03% | 99% | 95% | 0.00% | 0.02% | −0.35% | 97% | 98% | |
| BasketballPass | −0.01% | −0.13% | 0.22% | 99% | 99% | 0.04% | 0.35% | −0.02% | 98% | 81% | |
| Average | 0.00% | −0.01% | −0.01% | 99% | 97% | 0.02% | 0.18% | 0.02% | 98% | 93% | |
| Overall | 0.00% | −0.02% | 0.01% | 96% | 96% | 0.02% | −0.01% | 0.00% | 96% | 90% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, H.; Lee, Y.-L. Inverse Transform Using Linearity for Video Coding. Electronics 2022, 11, 760. https://doi.org/10.3390/electronics11050760
Song H, Lee Y-L. Inverse Transform Using Linearity for Video Coding. Electronics. 2022; 11(5):760. https://doi.org/10.3390/electronics11050760
Chicago/Turabian StyleSong, Hyeonju, and Yung-Lyul Lee. 2022. "Inverse Transform Using Linearity for Video Coding" Electronics 11, no. 5: 760. https://doi.org/10.3390/electronics11050760
APA StyleSong, H., & Lee, Y.-L. (2022). Inverse Transform Using Linearity for Video Coding. Electronics, 11(5), 760. https://doi.org/10.3390/electronics11050760