
A Novel ISO 26262-Compliant Test Bench to Assess the Diagnostic Coverage of Software Hardening Techniques against Digital Components Random Hardware Failures




{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. State of the Art
2.1. Fault Injection
Simular Contributions on SIHFT
2.2. ISO 26262
3. Proposed Approach
3.1. Fault Models
- CPU_FM1.1—given instruction flow(s) not executed (total omission) due to program counter hang up and CPU_FM1.2—given instruction flow(s) not executed (total omission) due to instruction fetch hang up:fault injected in the PC such that the control flow jumps to a location outside the program area or trigger a not handled exception. The program may enter an endless loop.
- CPU_FM2—un-intended instruction(s) flow executed (commission):fault injected in the PC such that the control flow jumps inside the program area but to a wrong address, creating an instruction flow that is different to the intended one.
- CPU_FM3—incorrect instruction flow timing (too early/late):Fault injected in the PC such that a few instructions of the original program flow are omitted, leading to early/late program termination.
- CPU_FM4—incorrect instruction flow result:fault injected in the PC such that the control flow jumps inside the program area but creating an instruction flow different than the intended one leading to wrong results.
- CPU_INTH_FM1—ISR not executed (omission/too few):upon the interrupt request, the fault injected in the PC does not allow the execution of the ISR (the PC points to an address other than that of the ISR to be executed).
- CPU_INTH_FM2—un-intended ISR execution (commission/too many):a fault has been injected into the PC such that the instruction flow is abnormally brought to enter an ISR.
- CPU_INTH_FM3—delayed ISR execution (too early/late):upon an interrupt request, a fault injected in the PC brings the execution flow to an address before the ISR, where the memory is initialized with NOPs. The PC then advances up to the ISR address.
- CPU_INTH_FM4—incorrect ISR execution (see CPU_ FM1/2/4):Fault injected in the PC such that the control flow jumps inside the program area but creates an instruction flow that is different from the intended one.
- ICU_FM1— Interrupt request to CPU missing:upon an interrupt request, the fault injected in the PC does not allow the execution of the ISR (the PC points to an address other than that of the ISR to be executed).
- ICU_FM2—Interrupt request to CPU without triggering event:fault injected in the PC such that the instruction flow is abnormally brought to enter an ISR.
- ICU_FM3—Interrupt request too early/late:fault injected in the PC such that the instruction flow is abnormally brought to enter an ISR (too early). Upon the interrupt request, the fault injected in the PC brings the execution flow to an address before the ISR, where the memory is initialized with NOP. The PC then advances up to the ISR address (too late).
- ICU_FM4: Interrupt request sent with incorrect data:fault injected in the PC such that a different ISR than the correct one is executed.
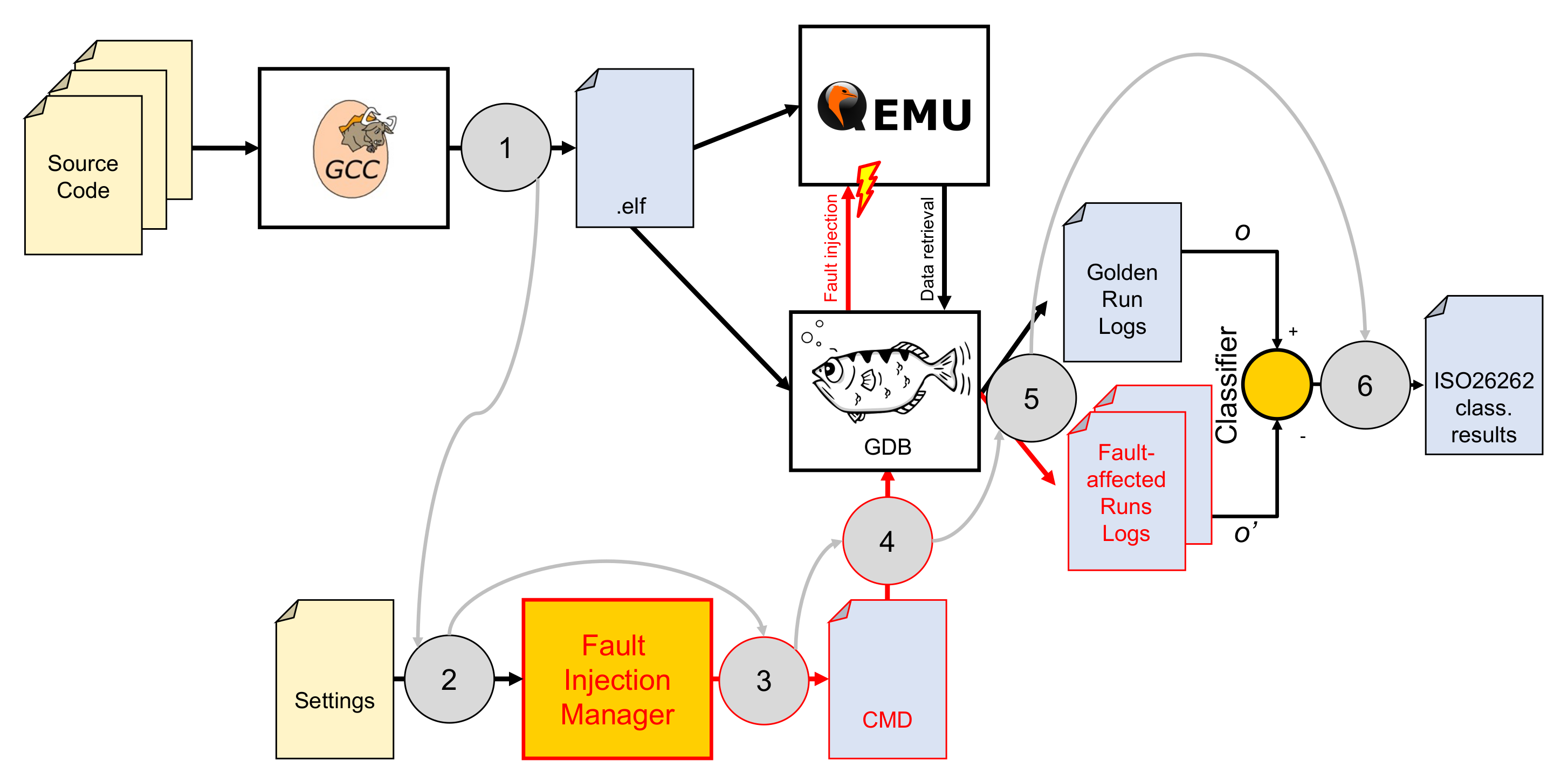
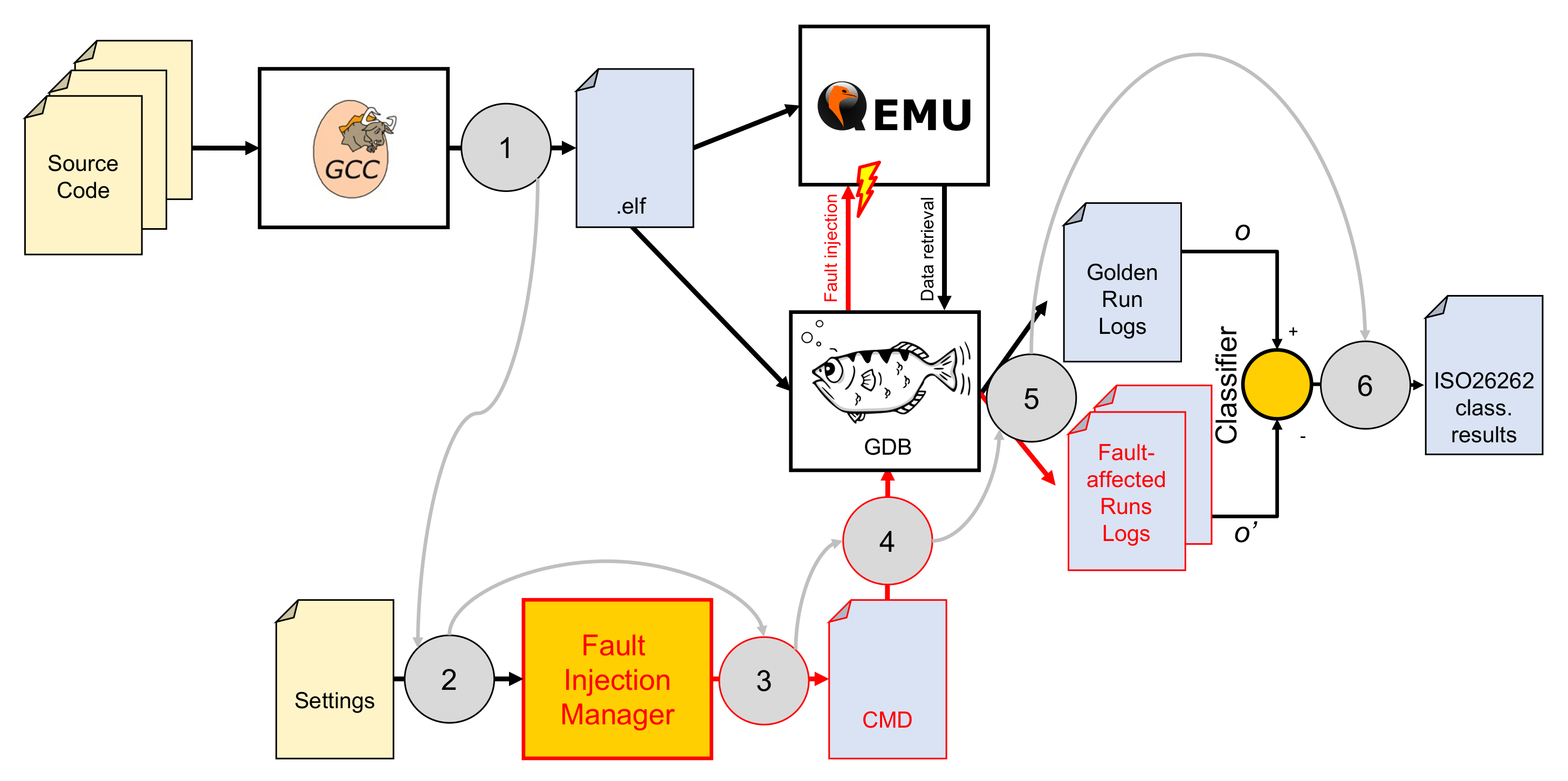
3.2. The Test Bench
- The software developers compile their source code for the target platform (in this case, an RISC-V RV32I microcontroller [21]) using one of the available toolchains, such as [22]. We chose to use RISC-V since it is an open-source ISA that is gaining interest for automotive and space applications [23].
- A settings file is prepared, containing information on the campaign to be performed.
- The FIM (controller) is launched. It reads the settings file to generate all the scripts (represented by the CMD file in the figure) needed to perform the injections. Alongside the scripts, it also prepares the classifier source code.
- The scripts are launched. These, by controlling GDB, perform the golden run and then all the required injections. For the golden run and each one of the injections (injector), a log file with the output of the program is saved (the log task of the monitor).
- The classifier is compiled and run, taking the golden run and each of the fault-affected logs as its input.
- The classifier results (one for each injection) are merged into the ISO 26262 classification, as described in Section 3.3.
3.2.1. FIM Settings File
Campaign
- A list of watches. One of these, called the end watch, defines the termination condition that allows the simulation system to determine if the software component under test finished its task.
- A list of faults to be injected.
Watches
- Symbol: the name of the variable to be watched. This field can be left blank if we want to monitor a memory location.
- Address: the address of the memory location to be watched. This field is ignored in case the symbol name has been defined.
- Description: a textual description of the watch. This field can be helpful for automatic report generation but is not required to perform the injection, and is hence left blank.
- DetectionWatch and DetectedCondition: if DetectionWatch is true, it means that the variable/memory address contains the results of a RHF detection mechanism. The DetectedCondition field contains the condition that represents whether or not the detection occurred in relation to the DetectionWatch variable.
Fault Representation
- Type: the fault model to be injected.At the moment, two kinds of faults are available: Permanent and PermanentStuckAt.
- Target: the name of the target register.
- bitPosMaks: a 64-bit mask, used to a perform bitwise-level configuration of the fault.
- Fault tolerance time interval (FTTI): the maximum allowed assembly instructions that the emulator can execute from the injection time until the detection occurs. After this time elapses, an eventual detection is considered invalid and hence not considered in the diagnostic coverage computation.
- Minimum injection time: the minimum time (measured as number of machine instructions) that must elapse from the start of the simulation to the moment when the fault is injected.
- Maximum injection time: the maximum time (measured as number of machine instructions) that can elapse from the start of the simulation to the moment when the fault is injected.
- Permanence time: the number of assembly instructions executed after the fault injection if the software unit under testing does not set the termination condition.
- Number of injections: the number of faults with the previous parameters to be randomly generated and injected.
- An end-watch to let the test bench know when the software unit ended its function: if it were not specified, the FIM would not know when to finish the golden run.
- A watch configured as a detection one, to enable the classifier to determine whether or not the detection mechanism has been triggered.
- A watch configured as a normal one to allow the classifier to check if the behavior of the payload algorithm is the same as the golden run or not.
3.2.2. Classifier
- Latent: before injection of the fault.
- Latent after injection: fault injected and behavior identical w.r.t. the golden run.
- Erratic behavior: behavior different w.r.t. the golden run.
- Infinite loop: PC moves in an infinite loop that is not present in the original program flow, but created by the interaction between the source code and the defective PC register.
- Stuck at some instruction: PC remains stuck pointing to a valid instruction.
- (Detected) by SW hardening: detected by the software hardening mechanism.
- (Detected) by HW (mechanism): PC pointing outside the FLASH/RAM addressing space.
- As golden: detected and with an output identical to the golden run.
- False positive: detection before a fault is injected.
- Moreover, states Undefined and Error indicate internal errors of the classifier. These states are not indicated in Figure 2.
3.3. ISO 26262-Compliant Classification
- Safe: if the detection mechanism is triggered, and the output is the same as the one obtained from the golden run (regardless of whether it is due to the type of fault or the algorithm by itself, or thanks to a software-based mitigation strategy). Of course, to apply such a hypothesis, it is required that the software component is developed in compliance with the prescriptions of ISO 26262 part 6.
- Latent: if the detection is not triggered, but the output is the same as the one obtained from the golden run.
- Dangerous: the set of failure modes for which the detection mechanism is not triggered and for which the output is different from the golden run; so, it also includes multiple-point perceived faults.
- Residual: based on the frequency of latent after injection (false negatives) obtained during the fault injections for a given fault.
- False positive: when the detection mechanism is triggered, but no fault has been yet injected. ISO 26262 does not describe this class (coherently, since it mandates avoiding the presence of systematic errors, a.k.a., defects in the embedded software), but it is useful since we want to use this performance assessment system to aid developers of software detection strategies.
- Safe detected: the percentage of the injections for a given fault that ended up with a classification of as golden.
- Detected: the percentage of the injections for a given fault that ended up with a classification of detected by either the software or a hardware detection mechanism. We chose to name them Detected since the effectiveness of the mitigation strategy was not considered.
- Latent: the percentage of the injections for a given fault that ended up with a classification of latent after injection.
- Dangerous: the percentage of the injections for a given fault that ended up with the classifications stuck at some instruction, erratic behavior, or infinite loop.These injections are referred to as Residual if they correspond to the same fault with different parameters found for simulation outcomes classified as Latent, or Detected.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| COTS | Commercial Off-The-Shelf |
| DC | Diagnostic Coverage |
| E/E | Eletrical and Electronics |
| FI | Fault Injection |
| FIM | Fault Injection Manager |
| FM | Failure Mode |
| FMEDA | Failure Mode, Effects, and Diagnostic Analysis |
| FSC | Functional Safety Concept |
| FSM | Finite State Machine |
| FTA | Fault Tree Analysis |
| FTTI | Fault Tolerance Time Interval |
| HSI | Hardware/Software Interfaces |
| IP | Intellectual Property |
| ISA | Instruction Set Architecture |
| ISO | International Standard Organization |
| MBSD | Model-Based Software Design |
| PC | Program Counter |
| PLD | Programmable Logic Device |
| RHF | Random Hardware Failure |
| RISC | Reduced Instruction Set Computing |
| RSCFC | Relationship Signatures for Control Flow Checking |
| SEooC | Safety Element out of Context |
| SETA | Software-only Error-detection Technique using Assertions |
| SG | Safety Goal |
| SIED | Software implemented error detection |
| SIHFT | Software Implemented Hardware Fault Tolerance |
| TSC | Technical Safety Concept |
| TSR | Technical Safety Requirements |
| WD | Watchdog |
References
- Avizienis, A.; Laprie, J.C.; Randell, B.; Landwehr, C. Basic concepts and taxonomy of dependable and secure computing. IEEE Trans. Dependable Secur. Comput. 2004, 1, 11–33. [Google Scholar] [CrossRef] [Green Version]
- Hsueh, M.C.; Tsai, T.K.; Iyer, R.K. Fault injection techniques and tools. Computer 1997, 30, 75–82. [Google Scholar] [CrossRef] [Green Version]
- Natella, R.; Cotroneo, D.; Madeira, H.S. Assessing dependability with software fault injection: A survey. ACM Comput. Surv. 2016, 48, 1–55. [Google Scholar] [CrossRef]
- Bernardi, P.; Bovi, C.; Cantoro, R.; De Luca, S.; Meregalli, R.; Piumatti, D.; Sansonetti, A. Software-based self-test techniques of computational modules in dual issue embedded processors. In Proceedings of the 2015 20th IEEE European Test Symposium (ETS), Cluj-Napoca, Romania, 25–29 May 2015; pp. 1–2. [Google Scholar]
- Piumatti, D.; Sanchez, E.; Bernardi, P.; Martorana, R.; Pernice, M.A. An efficient strategy for the development of software test libraries for an automotive microcontroller family. Microelectron. Reliab. 2020, 115, 113962. [Google Scholar] [CrossRef]
- Cantoro, R.; Firrincieli, A.; Piumatti, D.; Restifo, M.; Sánchez, E.; Reorda, M.S. About on-line functionally untestable fault identification in microprocessor cores for safety-critical applications. In Proceedings of the 2018 IEEE 19th Latin-American Test Symposium (LATS), Sao Paulo, Brazil, 12–14 March 2018; pp. 1–6. [Google Scholar]
- Ruospo, A.; Piumatti, D.; Floridia, A.; Sanchez, E. A Suitability Analysis of Software Based Testing Strategies for the On-line Testing of Artificial Neural Networks Applications in Embedded Devices. In Proceedings of the 2021 IEEE 27th International Symposium on On-Line Testing and Robust System Design (IOLTS), Torino, Italy, 28–30 June 2021; pp. 1–6. [Google Scholar]
- Das, A.K.; Mishra, D.K.; Yu, J.; Leung, C.K. Smart Self-Healing and Self-Sensing Cementitious Composites-Recent Developments, Challenges, and Prospects. Adv. Civ. Eng. Mater. 2019, 8, 554–578. [Google Scholar] [CrossRef]
- Piumatti, D.; Sini, J.; Borlo, S.; Sonza Reorda, M.; Bojoi, R.; Violante, M. Multilevel Simulation Methodology for FMECA Study Applied to a Complex Cyber-Physical System. Electronics 2020, 9, 1736. [Google Scholar] [CrossRef]
- de Aguiar Geissler, F.; Kastensmidt, F.L.; Souza, J.E.P. Soft error injection methodology based on QEMU software platform. In Proceedings of the 2014 15th Latin American Test Workshop—LATW, Fortaleza, Brazil, 12–15 March 2014; pp. 1–5. [Google Scholar] [CrossRef]
- Bellard, F. QEMU, a Fast and Portable Dynamic Translator. In Proceedings of the ATEC ’05 Proceedings of the Annual Conference on USENIX Annual Technical Conference, Anaheim, CA, USA, 10–15 April 2005. [Google Scholar]
- Amarnath, R.; Bhat, S.N.; Munk, P.; Thaden, E. A Fault Injection Approach to Evaluate Soft-Error Dependability of System Calls. In Proceedings of the 2018 IEEE International Symposium on Software Reliability Engineering Workshops (ISSREW), Memphis, TN, USA, 15–18 October 2018; pp. 71–76. [Google Scholar]
- Schirmeier, H.; Hoffmann, M.; Dietrich, C.; Lenz, M.; Lohmann, D.; Spinczyk, O. FAIL*: An Open and Versatile Fault-Injection Framework for the Assessment of Software-Implemented Hardware Fault Tolerance. In Proceedings of the 2015 11th European Dependable Computing Conference (EDCC), Paris, France, 7–11 September 2015; pp. 245–255. [Google Scholar]
- Esposito, S.; Sini, J.; Violante, M. Real-Time Validation of Fault-Tolerant Mixed-Criticality Systems. In Proceedings of the 2018 IEEE 24th International Symposium on On-Line Testing And Robust System Design (IOLTS), Costa Brava, Spain, 2–4 July 2018; pp. 245–246. [Google Scholar]
- ISO 26262:2018 Road Vehicles—Functional Safety. 2018. Available online: https://www.iso.org/standard/68383.html (accessed on 23 November 2021).
- Sini, J.; Violante, M. A simulation-based methodology for aiding advanced driver assistance systems hazard analysis and risk assessment. Microelectron. Reliab. 2020, 109, 113661. [Google Scholar] [CrossRef]
- Sini, J.; Violante, M. An Automatic Approach to Perform FMEDA Safety Assessment on Hardware Designs. In Proceedings of the 2018 IEEE 24th International Symposium on On-Line Testing and Robust System Design (IOLTS), Costa Brava, Spain, 2–4 July 2018; pp. 49–52. [Google Scholar]
- Autonomous Car: A New Driver for Resilient Computing and Design-for-Test Online. Available online: https://nepp.nasa.gov/workshops/etw2016/talks/15WED/20160615-0930-Autonomous_Saxena-Nirmal-Saxena-Rec2016Jun16-nasaNEPP.pdf (accessed on 9 December 2021).
- Ries, G.L.; Choi, G.S.; Iyer, R.K. Device-level transient fault modeling. In Proceedings of the IEEE 24th International Symposium on Fault- Tolerant Computing, Austin, TX, USA, 15–17 June 1994; pp. 86–94. [Google Scholar] [CrossRef]
- The GNU Debugger. Available online: https://www.gnu.org/software/gdb/ (accessed on 23 November 2021).
- The RISC-V Instruction Set Manual Volume I: Unprivileged ISA Document Version 20191213. Available online: https://riscv.org/wp-content/uploads/2019/12/riscv-spec-20191213.pdf (accessed on 23 November 2021).
- GNU RISC-V Toolchain. Available online: https://github.com/johnwinans/riscv-toolchain-install-guide (accessed on 30 October 2021).
- Mascio, S.D.; Menicucci, A.; Furano, G.; Monteleone, C.; Ottavi, M. The case for RISC-V in space. In Applications in Electronics Pervading the Industry, Environment, and Society; Saponara, S., De Gloria, A., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 319–325. [Google Scholar]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sini, J.; Violante, M.; Tronci, F. A Novel ISO 26262-Compliant Test Bench to Assess the Diagnostic Coverage of Software Hardening Techniques against Digital Components Random Hardware Failures. Electronics 2022, 11, 901. https://doi.org/10.3390/electronics11060901
Sini J, Violante M, Tronci F. A Novel ISO 26262-Compliant Test Bench to Assess the Diagnostic Coverage of Software Hardening Techniques against Digital Components Random Hardware Failures. Electronics. 2022; 11(6):901. https://doi.org/10.3390/electronics11060901
Chicago/Turabian StyleSini, Jacopo, Massimo Violante, and Fabrizio Tronci. 2022. "A Novel ISO 26262-Compliant Test Bench to Assess the Diagnostic Coverage of Software Hardening Techniques against Digital Components Random Hardware Failures" Electronics 11, no. 6: 901. https://doi.org/10.3390/electronics11060901
APA StyleSini, J., Violante, M., & Tronci, F. (2022). A Novel ISO 26262-Compliant Test Bench to Assess the Diagnostic Coverage of Software Hardening Techniques against Digital Components Random Hardware Failures. Electronics, 11(6), 901. https://doi.org/10.3390/electronics11060901