
HRER: A New Bottom-Up Rule Learning for Knowledge Graph Completion


Abstract
:1. Introduction
- •
- This paper proposes the new index—Horn rule reliability (), which alleviates the problem caused by incompleteness and biased distribution. Experiments show that the Horn rule based on this metric achieves state-of-the-art performance in the link prediction task.
- •
- This paper proposes the reasoning of entity rules, which makes up for insufficient representation of relation rules to some extent. Experiments show that the inference based on entity rules can improve link prediction by at least 2% on Hit@10.
- •
- HRER is explainable, providing the basis for the prediction. Unlike the embedding models, which are sensitive to parameters, HRER has only a few parameters for controlling the number of rules.
2. Related Work
2.1. Methods Based on Latent Features
2.2. Methods Based on Observed Features
3. Background
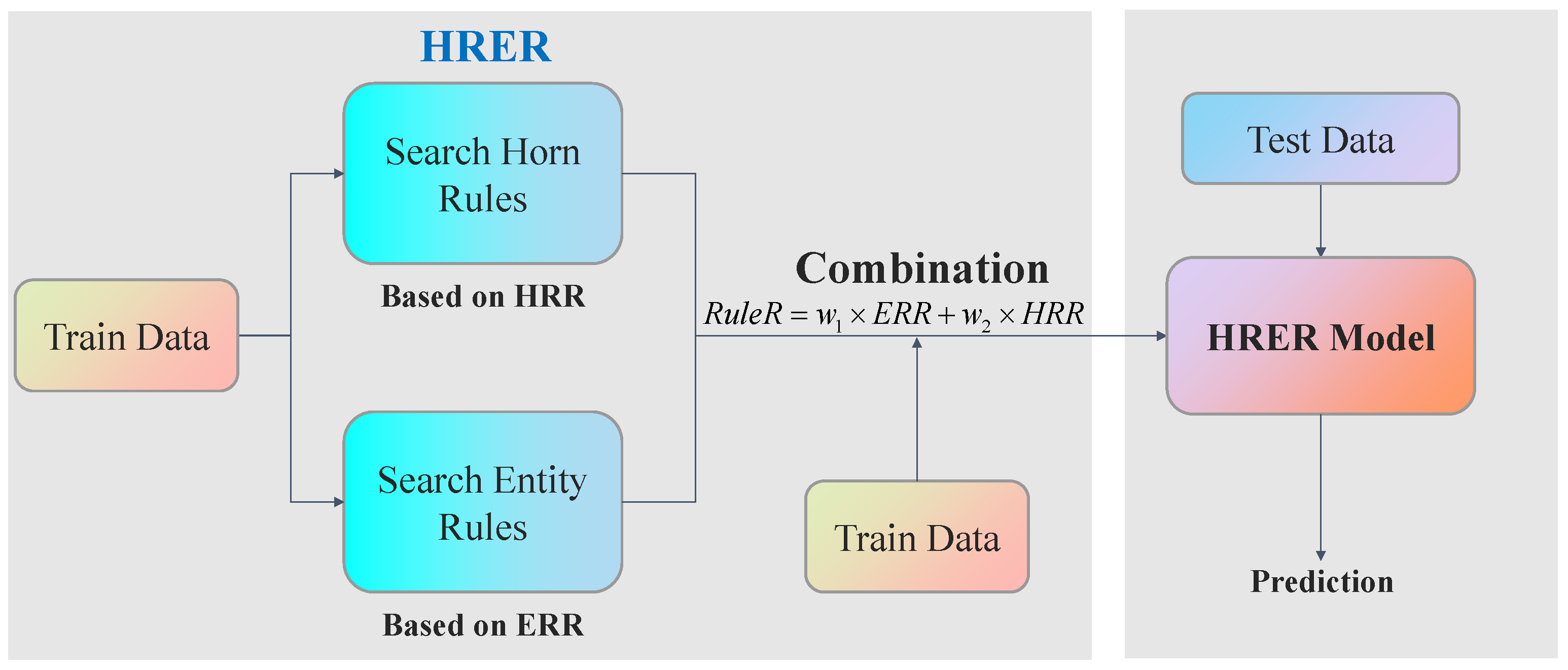
4. HRER Model
4.1. Model Overview
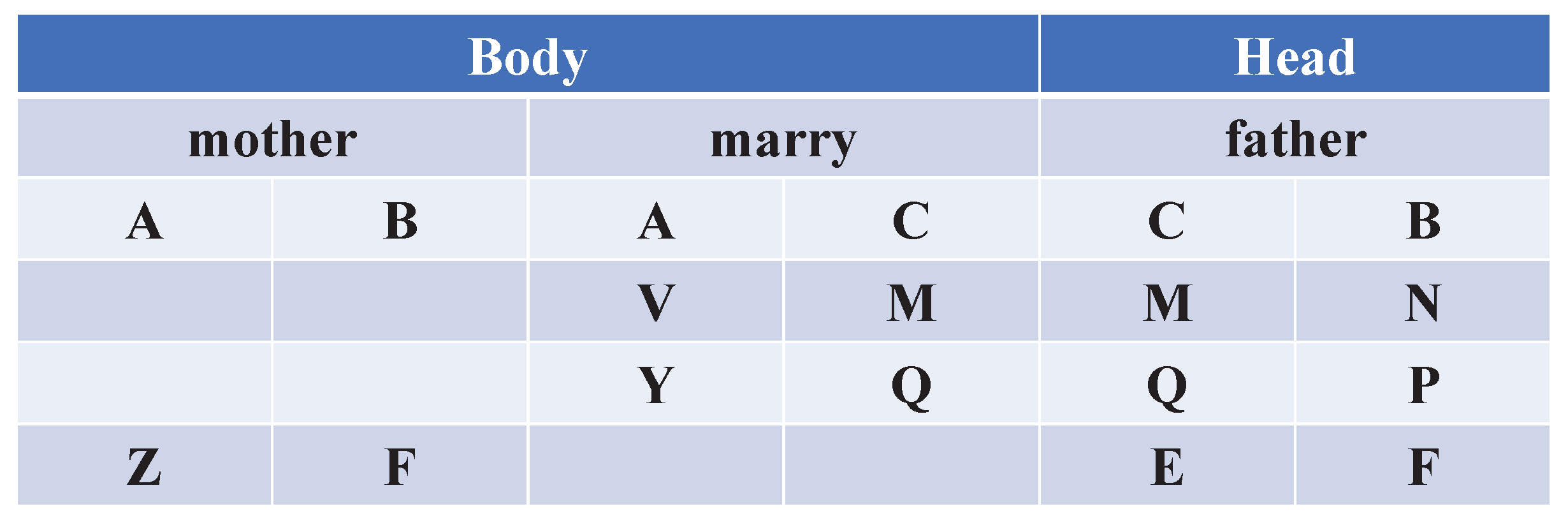
4.2. Reasoning Based on Relation Rules
4.3. Reasoning Based on Entity Rules
5. Experiments and Results
5.1. Datasets and Evaluations
- FB15k [1]. This dataset is a subset of Freebase, a large, growing knowledge base of the real world.
- FB15k-237 [37]. This dataset is obtained by eliminating the inverse and equal relations in FB15K, making it more difficult for simple models to do well.
- WN18 [1]. This dataset is a subset of WordNet, a hierarchical database containing lexical relations between words.
- WN18RR [27]. This dataset is achieved by excluding inverse and equal relations in WN18.
5.2. Parameter Settings
5.3. Link Prediction Results
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NE, USA, 5–10 December 2013; pp. 2787–2795. [Google Scholar]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. Dbpedia: A nucleus for a web of open data. In The Semantic Web; Springer: Berlin/Heidelberg, Germany, 2007; pp. 722–735. [Google Scholar]
- Carlson, A.; Betteridge, J.; Kisiel, B.; Settles, B.; Hruschka, E.R.; Mitchell, T.M. Toward an architecture for never-ending language learning. In Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 11–15 July 2010. [Google Scholar]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A large ontology from wikipedia and wordnet. J. Web Semant. 2008, 6, 203–217. [Google Scholar] [CrossRef] [Green Version]
- Galárraga, L.A.; Teflioudi, C.; Hose, K.; Suchanek, F. AMIE: Association rule mining under incomplete evidence in ontological knowledge bases. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 413–422. [Google Scholar]
- Mahdy, A.; Lotfy, K.; Ismail, E.; El-Bary, A.; Ahmed, M.; El-Dahdouh, A. Analytical solutions of time-fractional heat order for a magneto-photothermal semiconductor medium with Thomson effects and initial stress. Results Phys. 2020, 18, 103174. [Google Scholar] [CrossRef]
- Mahdy, A.M. Numerical solutions for solving model time-fractional Fokker–Planck equation. Numer. Methods Partial Differ. Equ. 2021, 37, 1120–1135. [Google Scholar] [CrossRef]
- Gao, L.; Zhu, H.; Zhuo, H.H.; Xu, J. Dual Quaternion Embeddings for Link Prediction. Appl. Sci. 2021, 11, 5572. [Google Scholar] [CrossRef]
- Wang, P.; Zhou, J.; Liu, Y.; Zhou, X. TransET: Knowledge Graph Embedding with Entity Types. Electronics 2021, 10, 1407. [Google Scholar] [CrossRef]
- Wang, M.; Qiu, L.; Wang, X. A Survey on Knowledge Graph Embeddings for Link Prediction. Symmetry 2021, 13, 485. [Google Scholar] [CrossRef]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; Volume 1, pp. 687–696. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Balažević, I.; Allen, C.; Hospedales, T.M. Tucker: Tensor factorization for knowledge graph completion. arXiv 2019, arXiv:1901.09590. [Google Scholar]
- Sun, Z.; Deng, Z.H.; Nie, J.Y.; Tang, J. RotatE: Knowledge graph embedding by relational rotation in complex space. arXiv 2019, arXiv:1902.10197. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex Embeddings for Simple Link Prediction. In Proceedings of the ICML, New York, NY, USA, 20–22 June 2016. [Google Scholar]
- Goethals, B.; Van den Bussche, J. Relational association rules: Getting Warmer. In Proceedings of the Pattern Detection and Discovery, London, UK, 16–19 September 2002; pp. 125–139. [Google Scholar]
- Schoenmackers, S.; Davis, J.; Etzioni, O.; Weld, D. Learning first-order horn clauses from web text. In Proceedings of the 2010 Conference on Empirical Methods on Natural Language Processing, Cambridge, MA, USA, 9–11 October 2010; pp. 1088–1098. [Google Scholar]
- Meilicke, C.; Fink, M.; Wang, Y.; Ruffinelli, D.; Gemulla, R.; Stuckenschmidt, H. Fine-grained evaluation of rule-and embedding-based systems for knowledge graph completion. In Proceedings of the International Semantic Web Conference, Monterey, CA, USA, 8–12 October 2018; pp. 3–20. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the AAAI, Quebec City, QC, Canada, 27–31 July 2014; Volume 14, pp. 1112–1119. [Google Scholar]
- Zhang, Z.; Cai, J.; Zhang, Y.; Wang, J. Learning Hierarchy-Aware Knowledge Graph Embeddings for Link Prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 3065–3072. [Google Scholar]
- Maximilian, N.; Volker, T.; Hans-Peter, K. A Three-Way Model for Collective Learning on Multi-Relational Data. In Proceedings of the 28th International Conference on Machine Learning, ICML 2011, Bellevue, WA, USA, 28 June–2 July 2011; pp. 809–816. [Google Scholar]
- Yang, B.; Yih, W.t.; He, X.; Gao, J.; Deng, L. Embedding entities and relations for learning and inference in knowledge bases. arXiv 2014, arXiv:1412.6575. [Google Scholar]
- Liu, H.; Wu, Y.; Yang, Y. Analogical inference for multi-relational embeddings. arXiv 2017, arXiv:1705.02426. [Google Scholar]
- Kazemi, S.M.; Poole, D. SimplE Embedding for Link Prediction in Knowledge Graphs. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montréal, QC, Canada, 3–8 December 2018; pp. 4289–4300. [Google Scholar]
- Nickel, M.; Rosasco, L.; Poggio, T.A. Holographic Embeddings of Knowledge Graphs. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Schuurmans, D., Wellman, M.P., Eds.; AAAI Press: Palo Alto, CA, USA, 2016; pp. 1955–1961. [Google Scholar]
- Zhang, Y.; Yao, Q.; Dai, W.; Chen, L. AutoSF: Searching Scoring Functions for Knowledge Graph Embedding. In Proceedings of the 36th IEEE International Conference on Data Engineering, ICDE 2020, Dallas, TX, USA, 20–24 April 2020; pp. 433–444. [Google Scholar] [CrossRef]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2D knowledge graph embeddings. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Nguyen, D.Q.; Nguyen, T.; Nguyen, D.Q.; Phung, D.Q. A Novel Embedding Model for Knowledge Base Completion Based on Convolutional Neural Network. arXiv 2018, arXiv:1712.02121. [Google Scholar]
- Nguyen, D.Q.; Vu, T.; Nguyen, T.; Nguyen, D.Q.; Phung, D.Q. A Capsule Network-based Embedding Model for Knowledge Graph Completion and Search Personalization. arXiv 2019, arXiv:1808.04122. [Google Scholar]
- Vashishth, S.; Sanyal, S.; Nitin, V.; Talukdar, P. Composition-based Multi-Relational Graph Convolutional Networks. arXiv 2020, arXiv:1911.03082. [Google Scholar]
- Nathani, D.; Chauhan, J.; Sharma, C.; Kaul, M. Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, 28 July–2 August 2019; Korhonen, A., Traum, D.R., Màrquez, L., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1, pp. 4710–4723. [Google Scholar] [CrossRef]
- Muggleton, S. Inverse entailment and Progol. New Gener. Comput. 1995, 13, 245–286. [Google Scholar] [CrossRef]
- Tan, P.N.; Kumar, V.; Srivastava, J. Selecting the right interestingness measure for association patterns. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002; pp. 32–41. [Google Scholar]
- Meilicke, C.; Chekol, M.W.; Ruffinelli, D.; Stuckenschmidt, H. Anytime Bottom-Up Rule Learning for Knowledge Graph Completion. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; pp. 3137–3143. [Google Scholar]
- Meilicke, C.; Chekol, M.W.; Fink, M.; Stuckenschmidt, H. Reinforced Anytime Bottom Up Rule Learning for Knowledge Graph Completion. arXiv 2020, arXiv:2004.04412. [Google Scholar]
- Galárraga, L.; Teflioudi, C.; Hose, K.; Suchanek, F.M. Fast rule mining in ontological knowledge bases with AMIE+. VLDB J. 2015, 24, 707–730. [Google Scholar] [CrossRef] [Green Version]
- Toutanova, K.; Chen, D.; Pantel, P.; Poon, H.; Choudhury, P.; Gamon, M. Representing text for joint embedding of text and knowledge bases. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1499–1509. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | #Entities | #Relations | #Triples | #Testset |
|---|---|---|---|---|
| FB15K | 14,951 | 1345 | 483,142 | 59,071 |
| FB15K-237 | 14,541 | 237 | 272,115 | 20,466 |
| WN18 | 40,943 | 18 | 141,442 | 5000 |
| Wn18RR | 40,599 | 11 | 86,835 | 3134 |
| FB15K | FB15K-237 | WN18 | Wn18RR | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FHit@1/% | FHit@10/% | FMRR | FHit@1/% | FHit@10/% | FMRR | FHit@1/% | FHit@10/% | FMRR | FHit@1/% | FHit@10/% | FMRR | |
| TransE | 49.36 | 84.73 | 0.628 | 21.72 | 49.68 | 0.315 | 40.56 | 94.87 | 0.646 | 2.70 | 49.52 | 0.206 |
| STransE | 39.77 | 79.60 | 0.543 | 22.48 | 49.56 | 0.315 | 43.12 | 93.45 | 0.656 | 10.13 | 42.21 | 0.226 |
| CrossE | 60.08 | 86.23 | 0.702 | 21.21 | 47.05 | 0.298 | 73.28 | 95.03 | 0.834 | 38.07 | 44.99 | 0.405 |
| TorusE | 68.85 | 83.98 | 0.746 | 19.62 | 44.71 | 0.281 | 94.33 | 95.44 | 0.947 | 42.68 | 53.35 | 0.463 |
| RotatE | 73.93 | 88.10 | 0.791 | 23.83 | 53.06 | 0.336 | 94.30 | 96.0 | 0.949 | 42.80 | 57.15 | 0.476 |
| DistMult | 73.61 | 86.32 | 0.784 | 22.44 | 49.01 | 0.313 | 72.60 | 94.61 | 0.824 | 39.68 | 50.22 | 0.433 |
| ComplEx | 81.56 | 90.53 | 0.848 | 25.72 | 52.97 | 0.349 | 94.53 | 95.50 | 0.949 | 42.55 | 52.12 | 0.458 |
| ANALOGY | 65.59 | 83.74 | 0.726 | 12.59 | 35.38 | 0.202 | 92.61 | 94.42 | 0.934 | 35.82 | 38.00 | 0.366 |
| SimplE | 66.13 | 83.63 | 0.726 | 10.03 | 34.35 | 0.179 | 93.25 | 94.58 | 0.938 | 38.27 | 42.65 | 0.398 |
| HolE | 75.85 | 86.78 | 0.800 | 21.37 | 47.64 | 0.303 | 93.11 | 94.94 | 0.938 | 40.28 | 48.79 | 0.432 |
| TuckER | 72.89 | 88.88 | 0.788 | 25.90 | 53.61 | 0.352 | 94.64 | 95.80 | 0.951 | 42.95 | 51.40 | 0.459 |
| ConvE | 59.46 | 84.94 | 0.688 | 21.90 | 47.62 | 0.305 | 93.89 | 95.68 | 0.945 | 38.99 | 50.75 | 0.427 |
| ConvKB | 11.44 | 40.83 | 0.211 | 13.98 | 41.46 | 0.230 | 52.89 | 94.89 | 0.70 | 95.63 | 52.50 | 0.249 |
| ConvR | 70.57 | 88.55 | 0.773 | 25.56 | 52.63 | 0.346 | 94.56 | 95.85 | 0.950 | 43.73 | 52.68 | 0.467 |
| CapsE | 1.93 | 21.78 | 0.087 | 7.34 | 35.60 | 0.160 | 84.55 | 95.08 | 0.890 | 33.69 | 55.98 | 0.415 |
| RSN | 72.34 | 87.01 | 0.777 | 19.84 | 44.44 | 0.280 | 91.23 | 95.10 | 0.928 | 34.59 | 48.34 | 0.395 |
| AMIE | 67.40 | 88.15 | 0.797 | 24.47 | 47.79 | 0.308 | 87.21 | 94.03 | 0.931 | 31.05 | 35.60 | 0.357 |
| Horn Rule | 84.27 | 89.01 | 0.861 | 25.10 | 48.22 | 0.312 | 93.47 | 95.32 | 0.941 | 44.16 | 50.98 | 0.465 |
| Ent Rule | 13.82 | 17.37 | 0.142 | 10.75 | 20.03 | 0.113 | 15.81 | 20.74 | 0.171 | 10.08 | 11.87 | 0.107 |
| HRER | 84.87 | 91.09 | 0.871 | 25.39 | 48.98 | 0.328 | 97.52 | 97.87 | 0.976 | 46.94 | 53.32 | 0.489 |
| Dataset | #Entities | #Relations |
|---|---|---|
| Rule 1 | head | (X, /sports/sports_team/roster./American_football/football_roster_position/position, Y) |
| body | (X, /sports/sports_position/players./sports/sports_team_roster/team, Y) | |
| Rule 2 | head | (X, /award/award_category/winners./award/award_honor/ceremony/football_roster_position/position, Y) |
| body | (X, /award/award_category/category_of, Z) | |
| (Z, /time/event/instance_of_recurring_event, Y) | ||
| Rule 3 | head | (X,/film/film/release_date_s./film/film_regional_release_date/film_release_region, Y) |
| body | (X, /film/film/release_date_s./film/film_regional_release_date/film_release_region, Z) | |
| (Z, /location/location/adjoin_s./location/adjoining_relationship/adjoins, Y) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, Z.; Yang, J.; Liu, H.; Huang, K.; Cui, L.; Qu, L.; Li, X. HRER: A New Bottom-Up Rule Learning for Knowledge Graph Completion. Electronics 2022, 11, 908. https://doi.org/10.3390/electronics11060908
Liang Z, Yang J, Liu H, Huang K, Cui L, Qu L, Li X. HRER: A New Bottom-Up Rule Learning for Knowledge Graph Completion. Electronics. 2022; 11(6):908. https://doi.org/10.3390/electronics11060908
Chicago/Turabian StyleLiang, Zongwei, Junan Yang, Hui Liu, Keju Huang, Lin Cui, Lingzhi Qu, and Xiang Li. 2022. "HRER: A New Bottom-Up Rule Learning for Knowledge Graph Completion" Electronics 11, no. 6: 908. https://doi.org/10.3390/electronics11060908
APA StyleLiang, Z., Yang, J., Liu, H., Huang, K., Cui, L., Qu, L., & Li, X. (2022). HRER: A New Bottom-Up Rule Learning for Knowledge Graph Completion. Electronics, 11(6), 908. https://doi.org/10.3390/electronics11060908