
A Novel Un-Supervised GAN for Fundus Image Enhancement with Classification Prior Loss


Abstract
:1. Introduction
2. Related Work
2.1. Natural Image Enhancement
2.2. Fundus Image Enhancement
3. Method
3.1. U-Net Generator with Skip Connection
- Most of the important features, e.g., lesions, vessels, macula and optic disc can be well preserved after enhancement and have no obvious spatial shift;
- The generator network is easy to train with skip connections and saves a lot of training time;
- With the condition of inputting a low quality image, the generator will not produce unexpected features as other vanilla GANs do without this condition.
3.2. Adversarial Training for Unpaired Image Enhancement
3.3. Classification Prior Loss Guided Generator
3.4. Objective Function
4. Experiments
4.1. Datasets
4.2. Implementation
4.3. Quantitative and Qualitative Evaluation
4.3.1. Quantitative Results
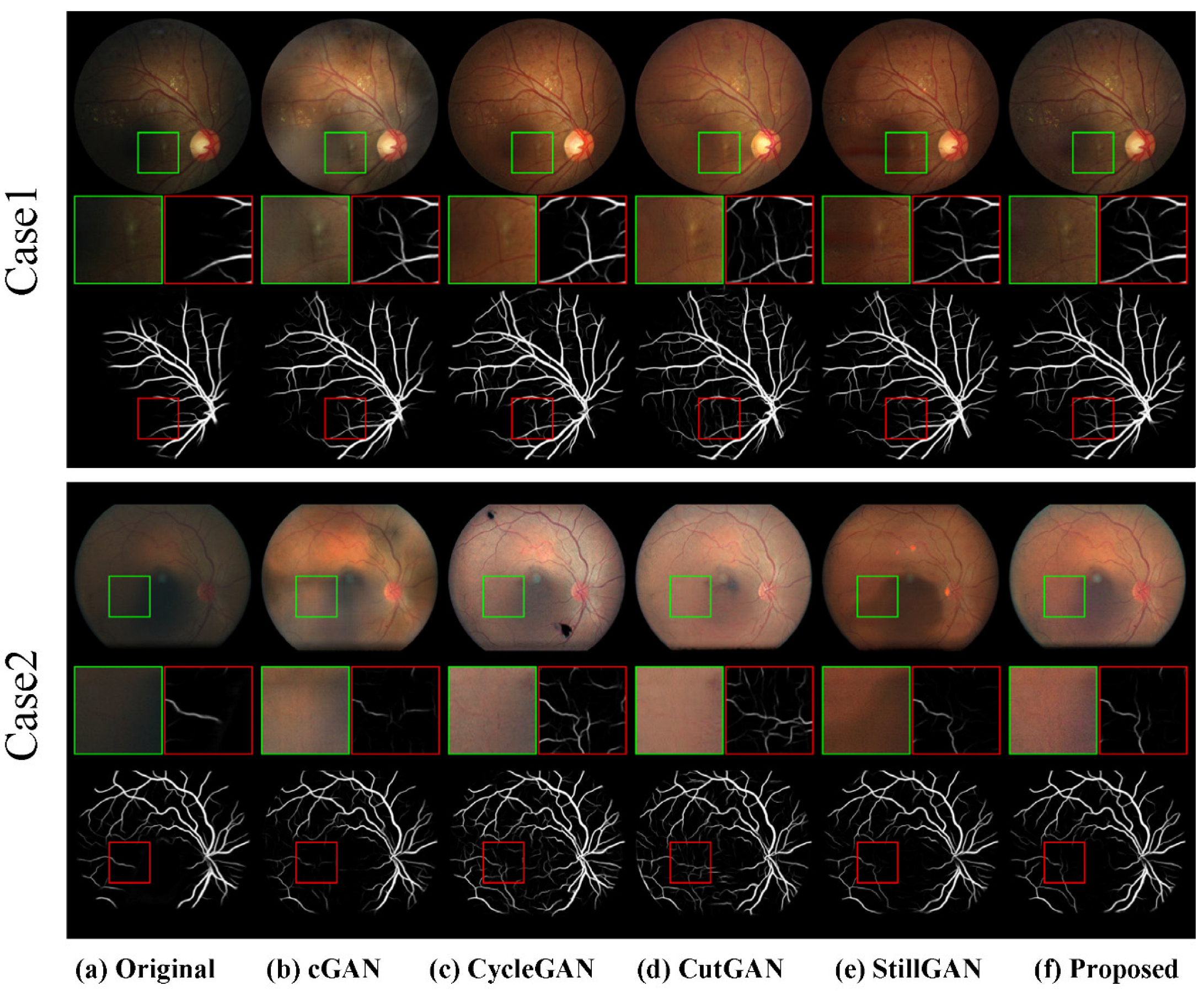
4.3.2. Qualitative Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shen, Z.; Fu, H.; Shen, J.; Shao, L. Modeling and Enhancing Low-Quality Retinal Fundus Images. IEEE Trans. Med. Imaging 2020, 40, 996–1006. [Google Scholar] [CrossRef] [PubMed]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. SwinIR: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Li, R.; Pan, J.; Li, Z.; Tang, J. Single image dehazing via conditional generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8202–8211. [Google Scholar]
- Wei, P.; Wang, X.; Wang, L.; Xiang, J. SIDGAN: Single Image Dehazing without Paired Supervision. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 2958–2965. [Google Scholar]
- Ren, D.; Zuo, W.; Hu, Q.; Zhu, P.; Meng, D. Progressive image deraining networks: A better and simpler baseline. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3937–3946. [Google Scholar]
- Bulat, A.; Yang, J.; Tzimiropoulos, G. To learn image super-resolution, use a gan to learn how to do image degradation first. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 185–200. [Google Scholar]
- Chen, C.; Xiong, Z.; Tian, X.; Zha, Z.; Wu, F. Camera Lens Super-Resolution. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1652–1660. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Wolf, V.; Lugmayr, A.; Danelljan, M.; Gool, L.; Timofte, R. DeFlow: Learning Complex Image Degradations from Unpaired Data with Conditional Flows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Yuan, Y.; Liu, S.; Zhang, J.; Zhang, Y.; Dong, C.; Lin, L. Unsupervised image super-resolution using cycle-in-cycle generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 701–710. [Google Scholar]
- Zhao, T.; Ren, W.; Zhang, C.; Ren, D.; Hu, Q. Unsupervised degradation learning for single image super-resolution. arXiv 2018, arXiv:1812.04240. [Google Scholar]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Zhang, Y.; Zhang, J.; Guo, X. Kindling the darkness: A practical low-light image enhancer. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1632–1640. [Google Scholar]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. EnlightenGAN: Deep Light Enhancement Without Paired Supervision. IEEE Trans. Image Processing 2021, 30, 2340–2349. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Shao, Y.; Li, L.; Ren, W.; Gao, C.; Sang, N. Domain adaptation for image dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2808–2817. [Google Scholar]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning Deep CNN Denoiser Prior for Image Restoration. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2808–2817. [Google Scholar]
- McCann, J. Retinex Theory. In Encyclopedia of Color Science and Technology; Luo, M.R., Ed.; Springer: New York, NY, USA, 2016; pp. 1118–1125. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Processing 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Wei, C.; Yang, W.; Liu, J. GLADNet: Low-Light Enhancement Network with Global Awareness. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 751–755. [Google Scholar]
- Zhao, Z.; Xiong, B.; Wang, L.; Ou, Q.; Yu, L.; Kuang, F. RetinexDIP: A Unified Deep Framework for Low-light Image Enhancement. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1076–1088. [Google Scholar] [CrossRef]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1780–1789. [Google Scholar]
- Cheng, J.; Li, Z.; Gu, Z.; Fu, H.; Wong, D.W.K.; Liu, J. Structure-preserving guided retinal image filtering and its application for optic disk analysis. IEEE Trans. Med. Imaging 2018, 37, 2536–2546. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- You, Q.; Wan, C.; Sun, J.; Shen, J.; Ye, H.; Yu, Q. Fundus Image Enhancement Method Based on CycleGAN. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 4500–4503. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Woo, S.H.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Ma, Y.; Liu, J.; Liu, Y.; Fu, H.; Hu, Y.; Cheng, J.; Qi, H.; Wu, Y.; Zhang, J.; Zhao, Y. Structure and Illumination Constrained GAN for Medical Image Enhancement. IEEE Trans. Med. Imaging 2021, 40, 3955–3967. [Google Scholar] [CrossRef] [PubMed]
- Cheng, P.; Lin, L.; Huang, Y.; Lyu, J.; Tang, X. Prior Guided Fundus Image Quality Enhancement Via Contrastive Learning. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; pp. 521–525. [Google Scholar]
- Wang, J.; Li, Y.-J.; Yang, K.-F. Retinal fundus image enhancement with image decomposition and visual adaptation. Comput. Biol. Med. 2021, 128, 104116. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Webers, C.A.B.; Berendschot, T.T.J.M. A double-pass fundus reflection model for efficient single retinal image enhancement. Signal Processing 2022, 192, 108400. [Google Scholar] [CrossRef]
- Raj, A.; Shah, N.A.; Tiwari, A.K. A novel approach for fundus image enhancement. Biomed. Signal Processing Control. 2022, 71, 103208. [Google Scholar] [CrossRef]
- Jolicoeur-Martineau, A. The relativistic discriminator: A key element missing from standard GAN. arXiv 2018, arXiv:1807.00734. [Google Scholar]
- Mao, X.D.; Li, Q.; Xie, H.R.; Lau, R.Y.K.; Wang, Z.; Smolley, S.P. Least Squares Generative Adversarial Networks. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2813–2821. [Google Scholar]
- Li, C.; Fu, H.; Cong, R.; Li, Z.; Xu, Q. NuI-Go: Recursive Non-Local Encoder-Decoder Network for Retinal Image Non-Uniform Illumination Removal. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1478–1487. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Fu, H.; Wang, B.; Shen, J.; Cui, S.; Xu, Y.; Liu, J.; Shao, L. Evaluation of retinal image quality assessment networks in different color-spaces. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October2019; pp. 48–56. [Google Scholar]
- Cuadros, J.; Bresnick, G. EyePACS: An adaptable telemedicine system for diabetic retinopathy screening. J. Diabetes Sci. Technol. 2009, 3, 509–516. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Park, T.; Efros, A.A.; Zhang, R.; Zhu, J.-Y. Contrastive learning for unpaired image-to-image translation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 319–345. [Google Scholar]
- Li, L.; Verma, M.; Nakashima, Y.; Nagahara, H.; Kawasaki, R. Iternet: Retinal image segmentation utilizing structural redundancy in vessel networks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 3656–3665. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| Method | Synthetic Dataset | |
|---|---|---|
| PSNR (dB) | SSIM | |
| cGAN | 23.2 | 0.8946 |
| CycleGAN | 22.84 | 0.843 |
| CutGAN | 21.89 | 0.8534 |
| StillGAN | 23.44 | 0.8693 |
| Proposed w.o. CPL | 23.82 | 0.8753 |
| Proposed | 23.93 | 0.8859 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Zhou, Q.; Zou, H. A Novel Un-Supervised GAN for Fundus Image Enhancement with Classification Prior Loss. Electronics 2022, 11, 1000. https://doi.org/10.3390/electronics11071000
Chen S, Zhou Q, Zou H. A Novel Un-Supervised GAN for Fundus Image Enhancement with Classification Prior Loss. Electronics. 2022; 11(7):1000. https://doi.org/10.3390/electronics11071000
Chicago/Turabian StyleChen, Shizhao, Qian Zhou, and Hua Zou. 2022. "A Novel Un-Supervised GAN for Fundus Image Enhancement with Classification Prior Loss" Electronics 11, no. 7: 1000. https://doi.org/10.3390/electronics11071000
APA StyleChen, S., Zhou, Q., & Zou, H. (2022). A Novel Un-Supervised GAN for Fundus Image Enhancement with Classification Prior Loss. Electronics, 11(7), 1000. https://doi.org/10.3390/electronics11071000