1. Introduction
1.1. Motivation
Subword segmentation has been established as a standard preprocessing method in neural machine translation (NMT) [
1,
2]. In particular, byte-pair encoding (BPE)/BPE-dropout [
3,
4] is the most successful compression-based subword segmentation. We propose another compression-based algorithm, denoted by LCP-dropout, that generates multiple subword segmentations for the same input; thus, enabling data augmentation especially for small training data.
In NMT, a set of training data is given to the learning algorithm, where training data are pairs of sentences from the source and target languages. The learning algorithm first transforms each given sentence into a sequence of tokens. In many cases, the tokens correspond to words in the unigram language model.
The extracted words are projected from a high-dimensional space consisting of all words to a low-dimensional vector space by
word embedding [
5], which enables us to easily handle distances and relationships between words and phrases. The word embedding has been shown to boost the performance of various tasks [
6,
7] in natural language processing. The space of word embedding is defined by a dictionary constructed from the training data, where each component of the dictionary is called
vocabulary. Embedding a word means representing it by a set of related vocabularies.
Constructing an appropriate dictionary is one of the most important tasks in this study. Here, consider the simplest strategy that uses the words themselves in the training data as the vocabularies. If a word does not exist in the current dictionary, it is called an unknown word, and the algorithm decides whether or not to register it in the dictionary. Using a sufficiently large dictionary can reduce the number of unknown words as much as desired; however, as a trade-off, overtraining is likely to occur, so the number of vocabularies is usually limited to
and
. As a result, subword segmentation has been widely used to construct a small dictionary with high generalization performance [
8,
9,
10,
11,
12].
1.2. Related Works
Subword segmentation is a recursive decomposition of a word into substrings. For example, let the word ‘study’ be registered as a current vocabulary. By embedding other words ’studied’ and ’studying’, we can learn that these three words are similar; however, each time a new word appears, the number of vocabularies grows monotonically.
On the other hand, when we focus on the common substrings of these words, we can obtain a decomposition, such as ‘stud_y’, ‘stud_ied’, and ‘stud_ying’ with the explicit blank symbol ‘_’; therefore, the idea of subword segmentation is not to register the word itself as a vocabulary but to register its subwords. In this case, ‘study’ and ‘studied’ are regarded as known words because they can be represented by combining subwords already registered. These subwords can also be reused as parts of other words (e.g., student and studied), which can suppress the growth of vocabulary size.
In the last decade, various approaches have been proposed along this line. SentencePiece [
13] is a pioneering study based on likelihood estimation over the unigram language model, which has high performance. Since maximum likelihood estimation requires quadratic time in the size of training data and the length of the longest subword, a simpler subword segmentation [
3] based on BPE [
14,
15], which is known as one of fastest data compression algorithms, and therefore has many applications, especially in information retrieval [
16,
17] has been proposed.
BPE-based segmentation starts from a state where a sentence is regarded as a sequence of vocabularies where the set of vocabularies is initially identical to the set of alphabet symbols (e.g., ASCII characters). BPE calculates the frequency of any bigram, merges all occurrences of the most frequent bigram, and registers the bigram as a new vocabulary. This process is repeated until the number of vocabularies reaches the limit. Thanks to the simplicity of the frequency-based subword segmentation, BPE runs in linear time in the size of input string.
However, frequency-based approaches may generate inconsistent subwords for the same substring occurrences. For example, ‘impossible’ and its substring ‘possible’ are possibly decomposed into undesirable subwords, such as ‘po_ss_ib_le’ and ‘i_mp_os_si_bl_e’, depending on the frequency of bigrams. Such merging disagreements can also be caused by misspellings of words or grammatical errors. BPE-dropout [
4] proposed a robust subword segmentation for this problem by ignoring each merge with a certain probability. It has been confirmed that BPE-dropout can be trained with higher accuracy than the original BPE and SentencePiece on various languages.
1.3. Our Contribution
We propose LCP-dropout: a novel compression-based subword segmentation employing the stochastic compression algorithm, called locally consistent parsing (LCP) [
18,
19], to improve the shortcomings of BPE. Here, we describe an outline of the original LCP. Suppose we are given an input string and a set of vocabularies, where similarly to BPE, the set of vocabularies is initially identical to the set of symbols appearing in the string. LCP randomly assigns the binary label for each vocabulary. Then, we obtain a binary string corresponding to the input string where the bigram ‘10’ works as a landmark. LCP merges any bigram in the input string corresponding to a landmark in the binary string, and adds the bigram to the set of vocabularies. The above process is repeated until the number of vocabularies reaches the limit.
By this random assignment, it is expected that any sufficiently long substring contains a landmark. Furthermore, we note that two different landmarks never overlap each other; therefore, LCP can merge bigrams appropriately, avoiding the undesirable subword segmentation that occurs in BPE. Using these characteristics, LCP has been theoretically shown to achieve almost optimal compression [
19]. The mechanism of LCP has also been mainly applied to information retrieval [
18,
20,
21].
A notable feature of the stochastic algorithm is that LCP assigns a new label to each vocabulary for each execution. Owing to this randomness, the LCP-based subword segmentation is expected to generate different subword sequences representing a same input; thus, it is more robust than BPE/BPE-dropout. Moreover, these multiple subword sequences can be considered as data augmentation for small training data in NMT.
LCP-dropout consists of two strategies: landmark by random labeling for all vocabularies and dropout of merging bigrams depending on the rank in the frequency table. Our algorithm requires no segmentation training in addition to counting by BPE and labeling by LCP and uses standard BPE/LCP in test time; therefore, our algorithm is simple. With various language corpora including small datasets, we show that LCP-dropout outperforms the baseline algorithms: BPE/BPE-dropout/SentencePiece.
2. Background
We use the following notations throughout this paper. Let be the set of alphabet symbols, including the blank symbol. A sequence S formed by symbols is called a string. and are i-th symbol and substring from to of S, respectively. We assume the meta symbol ‘−’ not in to explicitly represent each subwords in S. For a string S from , a maximal substring of S including no − is called a subword. For example, contains the subwords in , respectively.
In subword segmentation, the algorithm decomposes all the symbols in S by the meta symbol. When a trigram is merged, the meta symbol is erased and the new subword is added to the vocabulary, i.e., is treated as a single vocabulary.
In the following, we describe previously proposed subword segmentation algorithms, called SentencePiece (Kudo [
13]), BPE (Sennrich et al. [
3]), and BPE-dropout (Provilkov et al. [
4]). We assume that our task in NMT is to predict a target sentence
T given a source sentence
S, where these methods including our approach are not task-specific.
2.1. SentencePiece
SentencePiece [
13] can generate different segmentations for each execution. Here, we outline SentencePiece in the unigram language model. Given a set of vocabularies,
V, a sentence
T, and the probability
of occurrence of
, the probability of the partition
for
is represented as
, where
. The optimum partition
for
T is obtained by searching for the
x that maximizes
from all candidate partitions
.
Given a set of sentences,
D, as training data for a language, the subword segmentation for
D can be obtained through the maximum likelihood estimation of the following
with
as a hidden variable by using EM algorithm, where
is the
s-th sentence in
D.
SentencePiece was shown to achieve significant improvements over the method based on subword sequences; however, this method is rather complicated because it requires a unigram language model to predict the probability of subword occurrence, EM algorithm to optimize the lexicon, and Viterbi algorithm to create segmentation samples.
2.2. BPE and BPE-Dropout
BPE [
14] is one of practical implementations of Re-pair [
15], which is known as the algorithm with the highest compression ratio. Re-pair counts the frequency of occurrence of all bigrams
in the input string
T. For the most frequent
, it replaces all occurrences of
in
T such that
, with some unused character
z. This process is repeated until there are no more frequent bigrams in
T. The compressed
T can be recursively decoded by the stored substitution rules
.
Since the naive implementation of Re-pair requires
time, we use a complex data structure to achieve linear time; however, it is not practical for large-scale data because it consumes
of space. As a result, we usually split
into substrings of a constant length and process each
by the naive Re-pair without special data structure, called BPE. Naturally, there is a trade-off between the size of the split and the compression ratio. BPE-based subword segmentation [
3] (called BPE simply) determines the priority of bigrams according to their frequency and adds the merged bigrams as the vocabularies.
Since BPE is a deterministic algorithm, it splits a given
T in one way. Thus, it is not easy to generate multiple partitions such as the stochastic approach (e.g., [
13]). As a result, BPE-dropout [
4], ignoring the merging process with a certain probability, was proposed. In BPE-dropout, for the current
T and the most frequent
, for each occurrence
i satisfying
, merging
is dropped with a certain small probability
p (e.g.,
). This mechanism makes BPE-dropout probabilistic and generates a variety of splits. BPE-dropout has been recorded to outperform SentencePiece in various languages. Additionally, BPE-based methods are faster and easier to implement than likelihood-based approaches.
2.3. LCP
Frequency-based compression algorithms (e.g., [
14,
15]) are known to be not optimum from a theoretical point of view. Optimum compression here means a polynomial-time algorithm that satisfies
with the output
of the algorithm for the input
T and an optimum solution
. Note that computing
is NP-hard [
22].
For example, consider a string . Assuming the rank of these frequencies: , merging for T is possibly ; however, the desirable merging would be considering the similarity of these substrings.
Since such pathological merging cannot be prevented by frequency information alone, frequency-based algorithms cannot obtain asymptotically optimum compression [
23]. Various linear time and optimal compressions have been proposed to improve this drawback. LCP is one of the simplest optimum compression algorithms. The original LCP, similar to Re-pair, is a deterministic algorithm. Recently, the introduction of probability into LCP [
19] has been proposed, and in this study, we focus on the probabilistic variant. The following is a brief description of the probabilistic LCP.
We are given an input string of length n and a set of vocabularies, V. Here, V is initialized as the set of all characters appearing in T.
Randomly assign a label to each .
According to , compute the sequence .
Merge all bigram provided .
Set and repeat the above process.
The difference between LCP and BPE is that BPE merges bigrams with respect to frequencies, whereas LCP pays no attention to them. Instead, LCP merges based on the binary labels assigned randomly. The most important point is that any two occurrences of ‘10’ never overlap. For example, when T contains a trigram , there is no possible assignment allowing and simultaneously. By this property, LCP can avoid the problem that frequently occurs in BPE. Although LCP theoretically guarantees almost optimum compression, as far as the authors know, this study is the first result of applying LCP to machine translation.
3. Our Approach: LCP-Dropout
BPE-dropout allows diverse subword segmentation for BPE by ignoring bigram merging with a certain probability; however, since BPE is a deterministic algorithm, it is not trivial to generate various candidates of bigram. In this study, we propose an algorithm that enables multiple subword segmentation for the same input by combining the theory of LCP with the original strategy of BPE.
3.1. Algorithm Description
We define the notations used in our LCP-dropout (Algorithm 1) and its subroutine (Algorithm 2). Let be an alphabet and ‘_’ be the explicit blank symbol not in . A string w formed from is called word, denoted by , and a string is called a sentence.
We also assume the meta symbol ‘−’ not in . By this, a sentence x is extended to have all possible merges: Let be the string of all symbols in x separated by −, e.g., for . For strings x and y, if y is obtained by removing some occurrences of − in x, then we express the relation and y is said to be a subword segmentation of x.
After merging
(i.e.,
is replaced by
), the substring
is treated as a single symbol. Thus, we extend the notion of bigram to vocabularies of length more than two. For a string of the form
such that each
contains no −, each
is defined to be a bigram consisting of the vocabularies
and
.
| Algorithm 1 LCP-dropout. |
- Input:
for a set of sentences, , and hyperparameters {: #total vocabularies, : #partial vocabularies, : threshold of frequencies} - Output:
Set of subword sequences, , where satisfies , and - 1:
and - 2:
while (TRUE) do - 3:
initialize - 4:
while () do - 5:
- 6:
end while - 7:
if () then - 8:
return - 9:
end if - 10:
, - 11:
end while
|
| Algorithm 2 %subroutine of LCP-dropout. |
- 1:
assign randomly - 2:
the set of top-k frequent bigrams in Y of the form with - 3:
merge all occurrences of in Y for each - 4:
add all the vocabularies to V
|
3.2. Example Run
Table 1 presents an example of subword segmentation using LCP-dropout. Here, the input
X consists of a single sentence
. The hyperparameters are
. First, the set of vocabularies is initialized to
; for each
, a label
is randomly assigned (depth 0). Next, find all occurrences of 10 in
L, and the corresponding bigrams are merged depending on their frequencies. Here,
but only
is top-
k bigram assigned 10, and then
is merged to
. The resulting string is shown in the depth 1 over the new vocabularies
. This process is repeated while
for the next
m. The condition
terminates the inner-loop of LCP-dropout, and then the subword
is generated. Since
, the algorithm generates the next subword segmentations
for the same input. Finally, we obtain the multiple subword segmentation
and
for the same input string.
3.3. Framework of Neural Machine Translation
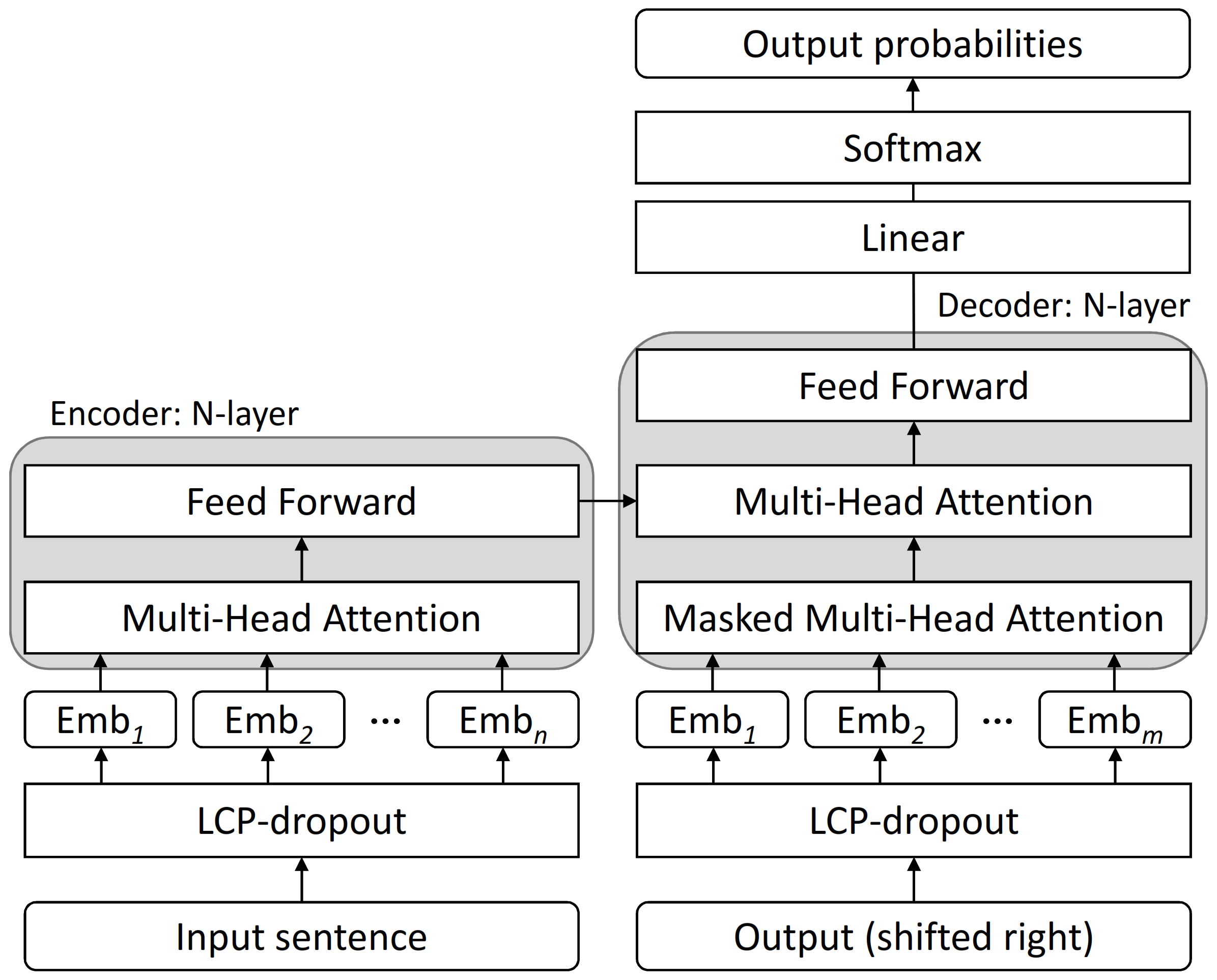
Figure 1 shows the framework of our transformer-based machine translation model with LCP-dropout. Transformer is the most successful NMT model [
24]. The model mainly consists of an encoder and decoder. The encoder converts the input sentence in the source language into a word embedding (Emb
in
Figure 1), taking into account the positional information of the characters. Here, the notion of word is extended to that of subword in this study. The subwords are obtained by our proposed method, LCP-dropout. Next, the correspondences in the input sentence are acquired as attention (Multi-Head Attention). Then, the normalization is performed through a forward propagation network formed by linear transformation, activation by ReLU function, and linear transformation. These processes are performed in
N = 6 layers for the decoder.
For the decoder, it receives the candidate sentence generated by the encoder and the input sentence for the decoder. Then, it acquires the correspondence between those sentences as attention (Multi-Head Attention). This process is also performed in N = 6 layers. Finally, the predicted probability of each label is calculated by linear transformation and softmax function.


 ,
, 



{kind=link}
{kind=link}