
A Novel Deep Learning Model Compression Algorithm


Abstract
:1. Introduction
2. Related Work
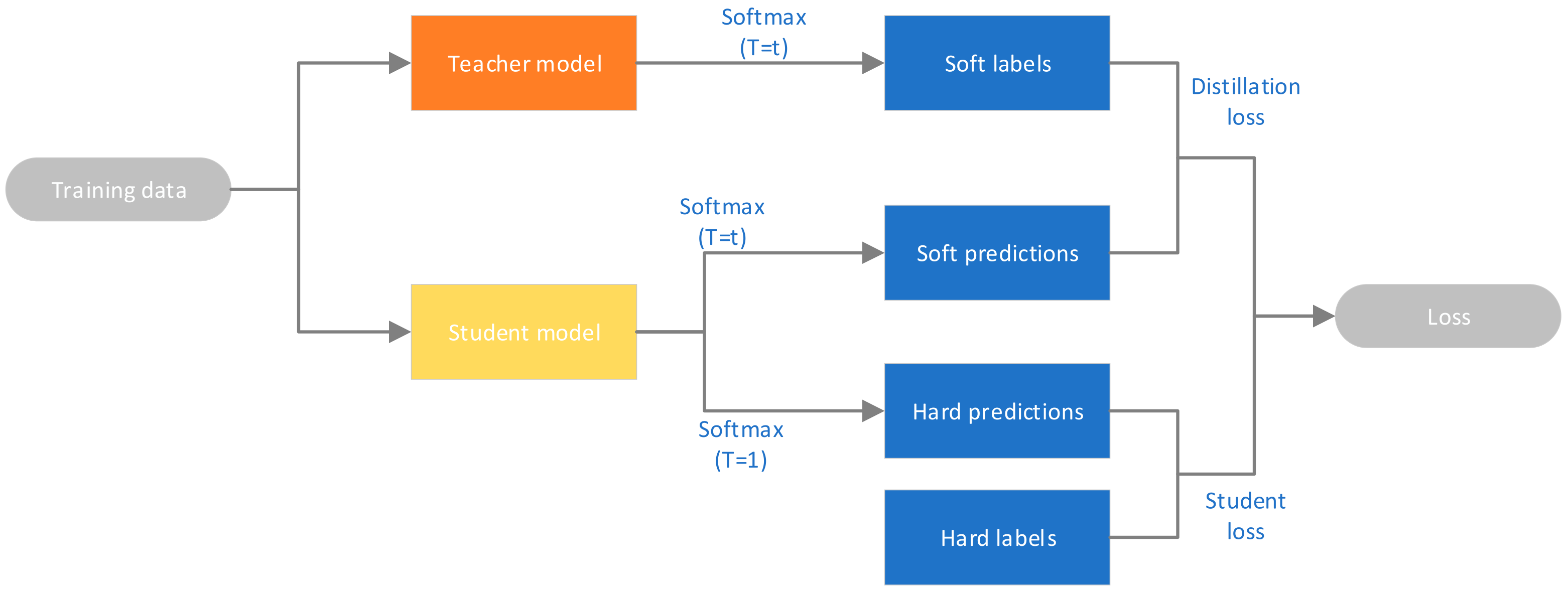
2.1. Knowledge Distillation (KD)
2.2. Quantization
2.3. Pruning
- (1)
- Less training time. With less computation, the speed of each iteration of connections in the network is improved and the network model can converge to the optimal solution faster.
- (2)
- Faster operation. The sparse network has fewer convolutional layers and fewer convolutional kernels in the convolutional layers, and the simpler and lighter model means more efficient and fast weight updates.
- (3)
- More viable embedded deployments. The pruned network offers a wider range of possibilities for applications on mobile and other embedded devices.
3. Fusion Pruning Algorithm
- (1)
- The standard deviation of the norm is sufficiently large.
- (2)
- The smallest norm is close to zero.
4. Experiment and Model Deployment
4.1. Experiment
4.2. Model Deployment
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Geoffrey, E. Hinton and Ruslan R Salakhutdinov. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- LeCun, Y. LeNet-5, Convolutional Neural Networks. Available online: http://yann.lecun.com/exdb/lenet (accessed on 1 January 2020).
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin Transformer V2: Scaling Up Capacity and Resolution. arXiv 2021, arXiv:2111.09883. [Google Scholar]
- LeCun, Y.; Denker, J.S.; Solla, S.A. Optimal brain damage. Adv. Neural Inf. Process. Syst. 1990, 2, 598–605. [Google Scholar]
- Anwar, S.; Hwang, K.; Sung, W. Structured pruning of deep convolutional neural networks. ACM J. Emerg. Technol. Comput. Syst. (JETC) 2017, 13, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning Filters for Efficient Convnets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- Chin, T.W.; Ding, R.; Zhang, C.; Marculescu, D. Towards efficient model compression via learned global ranking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1518–1528. [Google Scholar]
- Hu, H.; Peng, R.; Tai, Y.W.; Tang, C.K. Network trimming: A data-driven neuron pruning approach towards efficient deep architectures. arXiv 2016, arXiv:1607.03250. [Google Scholar]
- Lim, S.M.; Jun, S.W. MobileNets Can Be Lossily Compressed: Neural Network Compression for Embedded Accelerators. Electronics 2022, 11, 858. [Google Scholar] [CrossRef]
- Vanhoucke, V.; Senior, A.; Mao, M.Z. Improving the Speed of Neural Networks on CPUs. Deep Learning and Unsupervised Feature Learning Workshop, NIPS 2011. Available online: http://audentia-gestion.fr/Recherche-Research-Google/37631.pdf (accessed on 20 February 2022).
- Dettmers, T. 8-bit approximations for parallelism in deep learning. arXiv 2015, arXiv:1511.04561. [Google Scholar]
- Zhu, F.; Gong, R.; Yu, F.; Liu, X.; Wang, Y.; Li, Z.; Yang, X.; Yan, J. Towards unified int8 training for convolutional neural network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1969–1979. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2704–2713. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Wu, S.; Li, G.; Chen, F.; Shi, L. Training and inference with integers in deep neural networks. arXiv 2018, arXiv:1802.04680. [Google Scholar]
- Wang, K.; Liu, Z.; Lin, Y.; Lin, J.; Han, S. Haq: Hardware-aware automated quantization with mixed precision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8612–8620. [Google Scholar]
- Stewart, R.; Nowlan, A.; Bacchus, P.; Ducasse, Q.; Komendantskaya, E. Optimising hardware accelerated neural networks with quantisation and a knowledge distillation evolutionary algorithm. Electronics 2021, 10, 396. [Google Scholar] [CrossRef]
- Hansen, L.K.; Salamon, P. Neural network ensembles. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 993–1001. [Google Scholar] [CrossRef] [Green Version]
- Krogh, A.; Vedelsby, J. Neural network ensembles, cross validation, and active learning. Adv. Neural Inf. Process. Syst. 1995, 7, 231–238. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Zhang, L.; Song, J.; Gao, A.; Chen, J.; Bao, C.; Ma, K. Be your own teacher: Improve the performance of convolutional neural networks via self distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 3713–3722. [Google Scholar]
- Liu, Y.; Zhang, W.; Wang, J. Adaptive multi-teacher multi-level knowledge distillation. Neurocomputing 2020, 415, 106–113. [Google Scholar] [CrossRef]
- Widrow, B.; Kollár, I. Quantization Noise; Cambridge University Press: Cambridge, UK, 2008; Volume 2, p. 228. [Google Scholar]
- Cheng, Y.; Wang, D.; Zhou, P.; Zhang, T. Model compression and acceleration for deep neural networks: The principles, progress, and challenges. IEEE Signal Process. Mag. 2018, 35, 126–136. [Google Scholar] [CrossRef]
- He, Y.; Liu, P.; Wang, Z.; Hu, Z.; Yang, Y. Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- He, Y.; Kang, G.; Dong, X.; Fu, Y.; Yang, Y. Soft filter pruning for accelerating deep convolutional neural networks. arXiv 2018, arXiv:1808.06866. [Google Scholar]
- Lin, M.; Ji, R.; Wang, Y.; Zhang, Y.; Zhang, B.; Tian, Y.; Shao, L. Hrank: Filter pruning using high-rank feature map. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1529–1538. [Google Scholar]
- Pham, P.; Chung, J. Improving Model Capacity of Quantized Networks with Conditional Computation. Electronics 2021, 10, 886. [Google Scholar] [CrossRef]
- Lee, E.; Hwang, Y. Layer-Wise Network Compression Using Gaussian Mixture Model. Electronics 2021, 10, 72. [Google Scholar] [CrossRef]
- Han, Z.; Jiang, J.; Qiao, L.; Dou, Y.; Xu, J.; Kan, Z. Accelerating event detection with DGCNN and FPGAS. Electronics 2020, 9, 1666. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Name | Number of Network Layers | Parameters (M) |
|---|---|---|
| AlexNet | 8 | 61.1 |
| Vgg16 | 16 | 138.36 |
| Vgg19 | 19 | 143.67 |
| GoogleNet | 22 | 6.62 |
| ResNet50 | 50 | 25.58 |
| Weight Distribution () | Accuracy after Knowledge Distillation |
|---|---|
| (baseline) | 92% |
| 91.32% | |
| 91.74% | |
| 92.68% | |
| 93.07% | |
| 92.89% | |
| 92.57% | |
| 93.74% | |
| 93.78% | |
| 93.27% |
| Model Name | Method | Accuracy | Flops |
|---|---|---|---|
| Vgg16 (Pruning rate 50%) | Baseline | 93.14% | 6.26 × 108 |
| PF [12] | 93.27% | 2.31 × 108 | |
| HRank [33] | 92.47% | ||
| Ours | 93.86% | ||
| Resnet32 (Pruning rate 50%) | Baseline | 91.97% | 6.88 × 107 |
| PF [12] | 92.54% | 2.49 × 107 | |
| HRank [33] | 92.67% | ||
| Ours | 93.28% |
| Model | Time |
|---|---|
| Original model (Vgg16) | 867 ms |
| Pruned model | 472 ms |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, M.; Li, M.; Peng, S.-L.; Li, J. A Novel Deep Learning Model Compression Algorithm. Electronics 2022, 11, 1066. https://doi.org/10.3390/electronics11071066
Zhao M, Li M, Peng S-L, Li J. A Novel Deep Learning Model Compression Algorithm. Electronics. 2022; 11(7):1066. https://doi.org/10.3390/electronics11071066
Chicago/Turabian StyleZhao, Ming, Meng Li, Sheng-Lung Peng, and Jie Li. 2022. "A Novel Deep Learning Model Compression Algorithm" Electronics 11, no. 7: 1066. https://doi.org/10.3390/electronics11071066