
Object Segmentation for Autonomous Driving Using iseAuto Data


Abstract
:1. Introduction
- The development of a ResNet50 [17]-based FCN to carry out a late fusion of LiDAR point clouds and camera images for semantic segmentation.
- A custom dataset (https://autolab.taltech.ee/data/) (accessed on 27 February 2022) that was generated by the real-traffic-deployed iseAuto shuttle in different illumination and weather scenes. The dataset contains high-resolution RGB images and point clouds information that was projected into the camera plane. Furthermore, the dataset contains manual annotations for two classes: humans and vehicles.
- The performance evaluation for the domain adaptation of the neural network from the Waymo Open dataset to custom iseAuto dataset.
- The evaluation of the contribution of pseudo-annotated data to the performance on the iseAuto dataset.
2. Related Work
3. Dataset
3.1. Waymo Open Dataset
3.2. iseAuto Dataset
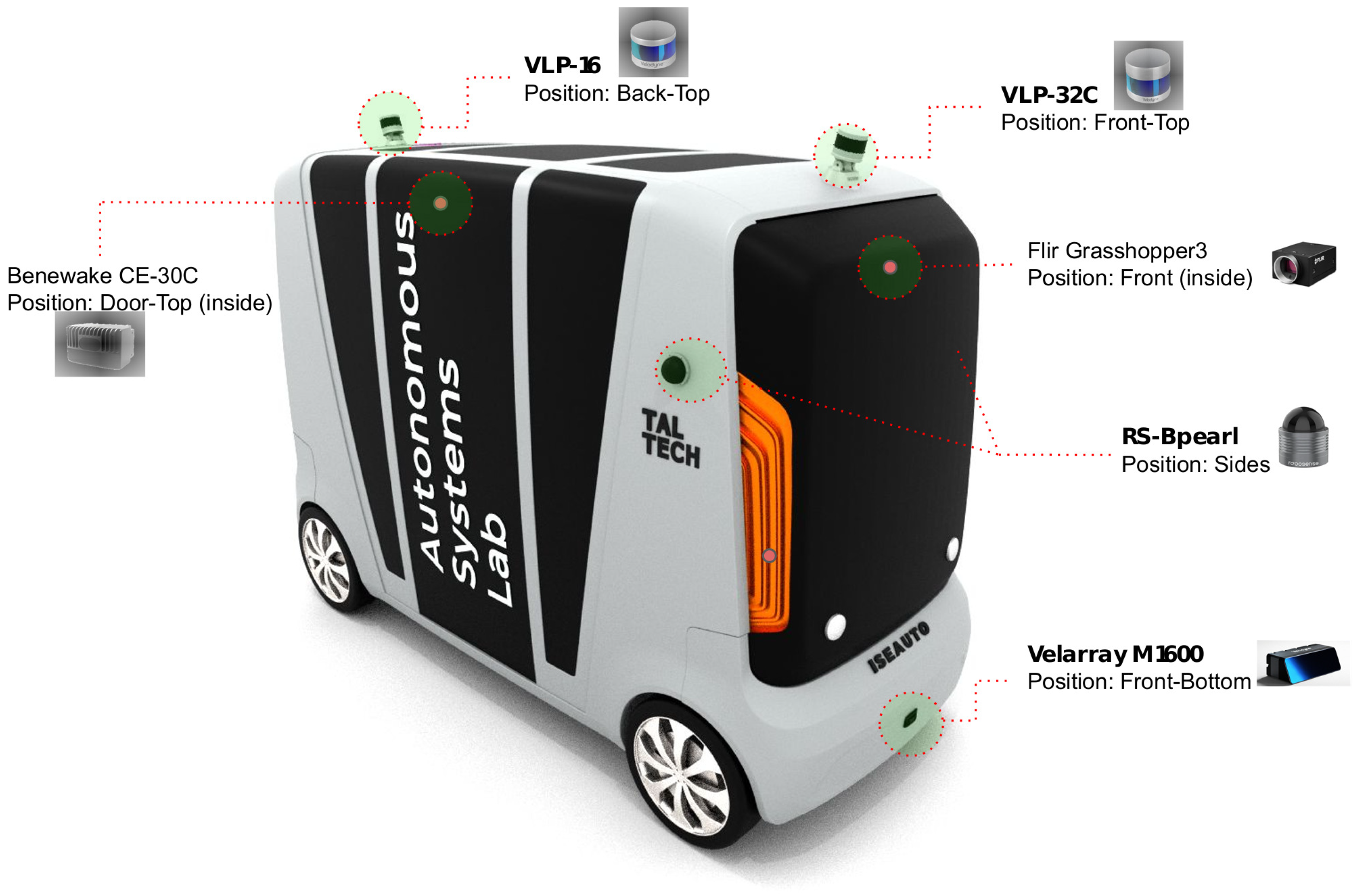
3.2.1. iseAuto Sensor Configuration
3.2.2. iseAuto Dataset Split
4. Methodology
4.1. LiDAR Point Cloud Projection
4.2. Object Segmentation
4.3. Model
4.4. Training
4.5. Metrics
5. Results and Discussion
5.1. Waymo Supervised Learning Baseline
5.2. Transfer Learning to iseAuto
5.3. Semi-Supervised Learning with Pseudo-Labeled Data
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the 2017 IEEE Transactions on Pattern Analysis and Machine Intelligence, Venice, Italy, 22–29 October 2017; pp. 386–397. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. Rangenet++: Fast and accurate lidar semantic segmentation. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4213–4220. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 4–9 December 2017. [Google Scholar]
- Caltagirone, L.; Bellone, M.; Svensson, L.; Wahde, M. LIDAR-Camera fusion for road detection using fully convolutional neural networks. Robot. Auton. Syst. 2019, 111, 125–131. [Google Scholar] [CrossRef] [Green Version]
- Pang, S.; Morris, D.; Radha, H. CLOCs: Camera-LiDAR object candidates fusion for 3D object detection. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October–24 January 2021; pp. 10386–10393. [Google Scholar]
- Van Gansbeke, W.; Neven, D.; De Brabandere, B.; Van Gool, L. Sparse and noisy lidar completion with rgb guidance and uncertainty. In Proceedings of the 2019 16th International Conference on Machine Vision Applications (MVA), Tokyo, Japan, 27–31 May 2019; pp. 1–6. [Google Scholar]
- Caltagirone, L.; Bellone, M.; Svensson, L.; Wahde, M.; Sell, R. LiDAR-Camera Semi-Supervised Learning for Semantic Segmentation. Sensors 2021, 21, 4813. [Google Scholar] [CrossRef] [PubMed]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–18 June 2020; pp. 2443–2451. [Google Scholar]
- Chang, M.F.; Lambert, J.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; Lucey, S.; Ramanan, D.; et al. Argoverse: 3D Tracking and Forecasting with Rich Maps. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8740–8749. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. Nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–18 June 2020; pp. 11621–11631. [Google Scholar]
- Sell, R.; Leier, M.; Rassõlkin, A.; Ernits, J.P. Self-driving car ISEAUTO for research and education. In Proceedings of the 2018 19th International Conference on Research and Education in Mechatronics (REM), Delft, The Netherlands, 7–8 June 2018; pp. 111–116. [Google Scholar]
- Rassõlkin, A.; Gevorkov, L.; Vaimann, T.; Kallaste, A.; Sell, R. Calculation of the traction effort of ISEAUTO self-driving vehicle. In Proceedings of the 2018 25th International Workshop on Electric Drives: Optimization in Control of Electric Drives (IWED), Moscow, Russia, 31 January–2 February 2018; pp. 1–5. [Google Scholar]
- Sell, R.; Rassõlkin, A.; Wang, R.; Otto, T. Integration of autonomous vehicles and Industry 4.0. Proc. Est. Acad. Sci. 2019, 68, 389–394. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Bellone, M.; Ismailogullari, A.; Müür, J.; Nissin, O.; Sell, R.; Soe, R.M. Autonomous driving in the real-world: The weather challenge in the Sohjoa Baltic project. In Towards Connected and Autonomous Vehicle Highways; Springer: Berlin/Heidelberg, Germany, 2021; pp. 229–255. [Google Scholar]
- Brostow, G.J.; Fauqueur, J.; Cipolla, R. Semantic object classes in video: A high-definition ground truth database. Pattern Recognit. Lett. 2009, 30, 88–97. [Google Scholar] [CrossRef]
- Geyer, J.; Kassahun, Y.; Mahmudi, M.; Ricou, X.; Durgesh, R.; Chung, A.S.; Hauswald, L.; Pham, V.H.; Mühlegg, M.; Dorn, S.; et al. A2d2: Audi autonomous driving dataset. arXiv 2004, arXiv:2004.06320. [Google Scholar]
- Jeong, J.; Cho, Y.; Shin, Y.S.; Roh, H.; Kim, A. Complex urban dataset with multi-level sensors from highly diverse urban environments. Int. J. Robot. Res. 2019, 38, 642–657. [Google Scholar] [CrossRef] [Green Version]
- Behrendt, K.; Soussan, R. Unsupervised labeled lane markers using maps. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27 October–2 November 2019; pp. 832–839. [Google Scholar]
- Huang, X.; Wang, P.; Cheng, X.; Zhou, D.; Geng, Q.; Yang, R. The apolloscape open dataset for autonomous driving and its application. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2702–2719. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Song, Z.; King, I.; Xu, Z. A survey on deep semi-supervised learning. arXiv 2021, arXiv:2103.00550. [Google Scholar]
- Miller, D.J.; Uyar, H. A mixture of experts classifier with learning based on both labelled and unlabelled data. In Proceedings of the 9th International Conference on Neural Information Processing Systems, Cambridge, MA, USA, 3–5 December 1996. [Google Scholar]
- Shahshahani, B.M.; Landgrebe, D.A. The effect of unlabeled samples in reducing the small sample size problem and mitigating the Hughes phenomenon. IEEE Trans. Geosci. Remote Sens. 1994, 32, 1087–1095. [Google Scholar] [CrossRef] [Green Version]
- Joachims, T. Transductive inference for text classification using support vector machines. In Proceedings of the Sixteenth International Conference on Machine Learning (ICML), Bled, Slovenia, 27–30 June 1999; Volume 99, pp. 200–209. [Google Scholar]
- Belkin, M.; Niyogi, P.; Sindhwani, V. Manifold regularization: A geometric framework for learning from labeled and unlabeled examples. J. Mach. Learn. Res. 2006, 7, 2399–2434. [Google Scholar]
- Blum, A.; Mitchell, T. Combining labeled and unlabeled data with co-training. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory, Madison, WI, USA, 24–26 July 1998; pp. 92–100. [Google Scholar]
- Agrawala, A. Learning with a probabilistic teacher. IEEE Trans. Inf. Theory 1970, 16, 373–379. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Y.; Zhang, Z.; Wu, C.; Zhang, Z.; He, T.; Zhang, H.; Manmatha, R.; Li, M.; Smola, A. Improving semantic segmentation via self-training. arXiv 2020, arXiv:2004.14960. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Brostow, G.J.; Shotton, J.; Fauqueur, J.; Cipolla, R. Segmentation and recognition using structure from motion point clouds. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2008; pp. 44–57. [Google Scholar]
- Xie, Q.; Luong, M.T.; Hovy, E.; Le, Q.V. Self-training with noisy student improves imagenet classification. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–18 June 2020; pp. 10684–10695. [Google Scholar]
- Zhai, X.; Oliver, A.; Kolesnikov, A.; Beyer, L. S4l: Self-supervised semi-supervised learning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 1476–1485. [Google Scholar]
- Ma, F.; Cavalheiro, G.V.; Karaman, S. Self-supervised sparse-to-dense: Self-supervised depth completion from lidar and monocular camera. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 3288–3295. [Google Scholar]
- Park, K.; Kim, S.; Sohn, K. High-precision depth estimation using uncalibrated LiDAR and stereo fusion. IEEE Trans. Intell. Transp. Syst. 2019, 21, 321–335. [Google Scholar] [CrossRef]
- Xu, D.; Anguelov, D.; Jain, A. Pointfusion: Deep sensor fusion for 3d bounding box estimation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 244–253. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 June 2017; pp. 77–85. [Google Scholar]
- Liang, M.; Yang, B.; Chen, Y.; Hu, R.; Urtasun, R. Multi-task multi-sensor fusion for 3d object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 7337–7345. [Google Scholar]
- Su, H.; Jampani, V.; Sun, D.; Maji, S.; Kalogerakis, E.; Yang, M.H.; Kautz, J. Splatnet: Sparse lattice networks for point cloud processing. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2530–2539. [Google Scholar]
- Bai, M.; Mattyus, G.; Homayounfar, N.; Wang, S.; Lakshmikanth, S.K.; Urtasun, R. Deep multi-sensor lane detection. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 3102–3109. [Google Scholar]
- Chen, Z.; Zhang, J.; Tao, D. Progressive lidar adaptation for road detection. IEEE/CAA J. Autom. Sin. 2019, 6, 693–702. [Google Scholar] [CrossRef] [Green Version]
- Gu, J.; Chhetri, T.R. Range Sensor Overview and Blind-Zone Reduction of Autonomous Vehicle Shuttles. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2021; Volume 1140, p. 012006. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2010 (VOC2010) Results. Available online: http://www.pascal-network.org/challenges/VOC/voc2010/workshop/index.html (accessed on 17 December 2021).
- Jiang, C.; Xu, H.; Zhang, W.; Liang, X.; Li, Z. Sp-nas: Serial-to-parallel backbone search for object detection. Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–18 June 2020; pp. 11860–11869. [Google Scholar]
- Zhang, Y.; Song, X.; Bai, B.; Xing, T.; Liu, C.; Gao, X.; Wang, Z.; Wen, Y.; Liao, H.; Zhang, G.; et al. 2nd Place Solution for Waymo Open Dataset Challenge–Real-time 2D Object Detection. arXiv 2021, arXiv:2106.08713. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FoV () | Range (m)/Resolution | Update Rate (Hz) | |
|---|---|---|---|
| Velodyne VLP-32C | 40 (vertical) | 200 | 20 |
| Grasshopper3 | 89.3 (D) 77.3 (H) 61.7 (V) | 4240 × 2824 | 7 |
| IoU (%) | Precision (%) | Recall (%) | auc-AP (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Vehicle | Human | Vehicle | Human | Vehicle | Human | Vehicle | Human | ||
| Day-Fair | camera | 88.08 | 55.57 | 91.21 | 59.77 | 96.25 | 88.77 | 92.60 | 71.13 |
| LiDAR | 88.58 | 53.04 | 91.23 | 55.94 | 96.82 | 91.08 | 93.23 | 69.89 | |
| fusion | 91.07 | 62.50 | 93.05 | 65.16 | 97.72 | 93.87 | 94.35 | 76.05 | |
| Day-Rain | camera | 88.54 | 52.13 | 91.14 | 57.43 | 96.88 | 84.97 | 94.04 | 76.12 |
| LiDAR | 89.47 | 50.06 | 91.38 | 53.04 | 97.73 | 89.92 | 94.83 | 73.63 | |
| fusion | 92.77 | 64.66 | 94.35 | 68.53 | 98.23 | 91.97 | 95.80 | 84.55 | |
| Night-Fair | camera | 81.16 | 42.87 | 86.77 | 49.33 | 92.62 | 76.60 | 86.74 | 61.10 |
| LiDAR | 86.16 | 48.83 | 89.35 | 52.51 | 96.02 | 87.46 | 92.38 | 68.98 | |
| fusion | 89.41 | 60.33 | 91.96 | 65.08 | 97.00 | 89.22 | 92.18 | 73.02 | |
| Night-Rain | camera | 74.49 | 43.14 | 83.39 | 51.91 | 87.47 | 71.87 | 85.83 | 53.04 |
| LiDAR | 87.51 | 46.68 | 90.72 | 48.44 | 96.11 | 92.77 | 92.90 | 53.87 | |
| fusion | 89.90 | 56.70 | 92.86 | 60.84 | 96.58 | 89.28 | 94.52 | 66.81 | |
| IoU (%) | Precision (%) | Recall (%) | auc-AP (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Vehicle | Human | Vehicle | Human | Vehicle | Human | Vehicle | Human | ||
| Day-Fair | camera | 63.64 | 64.39 | 84.15 | 66.74 | 72.07 | 94.81 | 83.04 | 71.30 |
| LiDAR | 40.56 | 0.06 | 63.19 | 57.87 | 53.12 | 0.06 | 49.68 | 0.35 | |
| fusion | 60.07 | 12.68 | 81.48 | 76.20 | 69.57 | 13.20 | 72.45 | 24.98 | |
| Day-Rain | camera | 51.51 | 13.66 | 54.28 | 16.60 | 91.00 | 43.58 | 68.11 | 27.39 |
| LiDAR | 43.56 | 2.86 | 67.96 | 11.96 | 54.81 | 3.62 | 51.98 | 7.62 | |
| fusion | 69.19 | 14.75 | 81.86 | 40.28 | 81.73 | 18.89 | 75.84 | 35.33 | |
| Night-Fair | camera | 45.06 | 29.42 | 73.21 | 63.85 | 53.96 | 35.30 | 62.84 | 55.86 |
| LiDAR | 41.75 | 0.54 | 56.92 | 20.72 | 61.04 | 0.55 | 48.20 | 1.61 | |
| fusion | 55.68 | 5.07 | 75.33 | 69.82 | 68.09 | 5.18 | 68.26 | 13.36 | |
| Night-Rain | camera | 17.34 | 5.64 | 19.34 | 13.71 | 62.72 | 8.74 | 24.43 | 20.33 |
| LiDAR | 33.55 | 0.01 | 48.09 | 0.33 | 52.59 | 0.01 | 41.26 | 0.08 | |
| fusion | 44.90 | 7.72 | 59.60 | 55.61 | 64.53 | 8.23 | 51.83 | 56.41 | |
| IoU (%) | Precision (%) | Recall (%) | auc-AP (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Vehicle | Human | Vehicle | Human | Vehicle | Human | Vehicle | Human | ||
| Day-Fair | camera | 77.10 | 75.87 | 85.02 | 79.40 | 89.22 | 94.46 | 84.59 | 81.67 |
| LiDAR | 72.14 | 55.71 | 81.07 | 57.48 | 86.75 | 94.75 | 80.65 | 61.08 | |
| fusion | 83.27 | 74.24 | 89.41 | 76.46 | 92.38 | 96.24 | 88.34 | 82.91 | |
| Day-Rain | camera | 80.26 | 48.11 | 85.82 | 67.13 | 92.53 | 62.93 | 84.15 | 72.22 |
| LiDAR | 77.33 | 40.27 | 82.35 | 45.06 | 92.70 | 79.11 | 81.48 | 63.36 | |
| fusion | 84.92 | 57.61 | 88.75 | 65.08 | 95.16 | 83.37 | 87.99 | 73.99 | |
| Night-Fair | camera | 66.07 | 52.38 | 75.02 | 61.38 | 84.71 | 78.13 | 77.61 | 74.58 |
| LiDAR | 74.50 | 45.38 | 80.58 | 47.78 | 90.79 | 90.04 | 82.93 | 60.75 | |
| fusion | 80.43 | 64.03 | 86.55 | 73.18 | 91.92 | 83.67 | 87.66 | 76.88 | |
| Night-Rain | camera | 51.70 | 41.39 | 63.11 | 47.21 | 74.09 | 77.06 | 61.50 | 63.29 |
| LiDAR | 62.51 | 26.46 | 68.24 | 27.05 | 88.15 | 92.38 | 73.02 | 50.79 | |
| fusion | 67.89 | 45.68 | 75.26 | 49.48 | 87.40 | 85.61 | 79.46 | 74.34 | |
| IoU (%) | Precision (%) | Recall (%) | auc-AP (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Vehicle | Human | Vehicle | Human | Vehicle | Human | Vehicle | Human | ||
| Day-Fair | camera | 75.97 | 71.31 | 86.43 | 74.10 | 86.26 | 94.99 | 84.26 | 79.01 |
| LiDAR | 71.19 | 56.87 | 78.74 | 59.01 | 88.14 | 94.03 | 78.00 | 66.99 | |
| fusion | 80.39 | 74.56 | 87.26 | 77.63 | 91.08 | 94.97 | 86.40 | 83.10 | |
| Day-Rain | camera | 77.71 | 39.87 | 81.15 | 51.82 | 94.82 | 63.35 | 82.28 | 66.49 |
| LiDAR | 76.00 | 42.10 | 81.44 | 46.52 | 91.93 | 81.58 | 80.43 | 59.12 | |
| fusion | 83.20 | 56.24 | 87.37 | 65.16 | 94.58 | 80.43 | 87.52 | 75.12 | |
| Night-Fair | camera | 68.89 | 54.98 | 76.04 | 62.79 | 87.99 | 81.54 | 79.27 | 73.55 |
| LiDAR | 74.25 | 47.19 | 80.03 | 50.52 | 91.13 | 87.75 | 82.96 | 54.16 | |
| fusion | 76.79 | 62.48 | 85.75 | 75.66 | 88.02 | 78.19 | 87.11 | 77.40 | |
| Night-Rain | camera | 52.17 | 29.40 | 60.88 | 32.26 | 78.49 | 76.81 | 66.67 | 54.27 |
| LiDAR | 59.49 | 36.76 | 64.82 | 37.91 | 87.85 | 92.33 | 82.30 | 62.08 | |
| fusion | 64.68 | 46.09 | 74.42 | 50.30 | 83.17 | 84.64 | 78.96 | 76.59 | |
| IoU (%) | Precision (%) | Recall (%) | auc-AP (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Vehicle | Human | Vehicle | Human | Vehicle | Human | Vehicle | Human | ||
| Day-Fair | camera | 79.85 | 67.06 | 85.27 | 68.18 | 92.63 | 97.62 | 85.86 | 75.88 |
| LiDAR | 73.69 | 58.05 | 81.61 | 59.37 | 88.37 | 96.32 | 80.55 | 64.68 | |
| fusion | 82.38 | 68.98 | 87.24 | 69.98 | 93.67 | 97.96 | 87.72 | 76.36 | |
| Day-Rain | camera | 80.27 | 53.61 | 82.57 | 56.91 | 96.64 | 90.24 | 84.41 | 67.23 |
| LiDAR | 80.58 | 44.09 | 84.84 | 48.41 | 94.13 | 83.14 | 84.25 | 59.23 | |
| fusion | 83.98 | 54.28 | 87.13 | 56.95 | 95.87 | 92.06 | 88.63 | 66.87 | |
| Night-Fair | camera | 73.14 | 55.07 | 78.67 | 61.71 | 91.23 | 83.66 | 81.74 | 69.23 |
| LiDAR | 75.75 | 49.59 | 79.99 | 52.96 | 93.46 | 88.63 | 84.24 | 60.42 | |
| fusion | 79.28 | 56.32 | 82.34 | 59.81 | 95.52 | 90.61 | 86.68 | 71.81 | |
| Night-Rain | camera | 60.42 | 42.06 | 66.33 | 43.80 | 87.16 | 91.37 | 69.26 | 68.97 |
| LiDAR | 64.89 | 41.32 | 70.75 | 42.21 | 88.69 | 95.15 | 75.68 | 67.30 | |
| fusion | 63.97 | 43.63 | 69.38 | 44.74 | 89.13 | 94.59 | 75.67 | 67.84 | |
| IoU (%) | Precision (%) | Recall (%) | auc-AP (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Vehicle | Human | Vehicle | Human | Vehicle | Human | Vehicle | Human | ||
| Day-Fair | camera | 80.32 | 69.25 | 87.41 | 70.53 | 90.83 | 97.45 | 85.04 | 76.99 |
| LiDAR | 76.10 | 61.81 | 83.28 | 63.30 | 89.83 | 96.34 | 81.32 | 71.22 | |
| fusion | 82.85 | 71.09 | 87.93 | 72.55 | 93.49 | 97.24 | 87.91 | 78.48 | |
| Day-Rain | camera | 82.49 | 57.12 | 86.33 | 60.85 | 94.87 | 90.31 | 87.75 | 69.98 |
| LiDAR | 81.00 | 44.85 | 85.03 | 49.57 | 94.48 | 82.50 | 85.05 | 60.68 | |
| fusion | 85.04 | 54.84 | 88.16 | 61.61 | 96.00 | 83.32 | 88.36 | 70.4 | |
| Night-Fair | camera | 75.97 | 55.46 | 83.13 | 65.45 | 89.81 | 78.41 | 84.64 | 71.00 |
| LiDAR | 76.01 | 51.63 | 80.16 | 55.07 | 93.63 | 89.20 | 84.01 | 64.51 | |
| fusion | 79.82 | 60.21 | 83.88 | 67.71 | 94.28 | 84.46 | 88.20 | 73.43 | |
| Night-Rain | camera | 60.79 | 48.30 | 69.38 | 51.45 | 83.07 | 88.76 | 71.65 | 72.03 |
| LiDAR | 64.40 | 41.15 | 69.95 | 42.17 | 89.04 | 94.45 | 73.63 | 64.49 | |
| fusion | 66.92 | 48.36 | 73.19 | 50.64 | 88.65 | 91.49 | 77.76 | 72.81 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gu, J.; Bellone, M.; Sell, R.; Lind, A. Object Segmentation for Autonomous Driving Using iseAuto Data. Electronics 2022, 11, 1119. https://doi.org/10.3390/electronics11071119
Gu J, Bellone M, Sell R, Lind A. Object Segmentation for Autonomous Driving Using iseAuto Data. Electronics. 2022; 11(7):1119. https://doi.org/10.3390/electronics11071119
Chicago/Turabian StyleGu, Junyi, Mauro Bellone, Raivo Sell, and Artjom Lind. 2022. "Object Segmentation for Autonomous Driving Using iseAuto Data" Electronics 11, no. 7: 1119. https://doi.org/10.3390/electronics11071119