
Machine Learning for Radio Resource Management in Multibeam GEO Satellite Systems

 , ,
, ,  , ,
, ,  , , and
, , and
Abstract
:1. Introduction
1.1. Related Works
- The proposal based on [33] is the only model that uses a CNN for RRM and has flexibility in three resources;
- In [34], the superiority of using MA concerning SA is demonstrated; thus, the proposals that use an MA scheme were selected to evaluate three different algorithms (QL, DQL and DDQL) and because it has flexibility in three resources.
- The work presented in [30] represents a beam hopping (BH) system with full frequency reuse, and it is also the only one that uses an ML-assisted optimization model.
1.2. Motivation and Contribution
- We define two different system architectures based on ML techniques for RRM depending on whether the AI Chipset is at the ground station or onboard the satellite depending on the training–learning characteristics.
- We study and compare the proposed ML techniques to evaluate their performance and feasibility for both systems.
- We evaluate the performance and processing time required depending on whether training is online or offline.
- We identify the main trade-offs for selecting the commercial AI Chipset that could be used for ML implementation in SatCom systems with a flexible payload.
- We identify different critical challenges for implementing ML techniques for the new lines of research needed.
2. Radio Resource Management
2.1. Power, Beamwidth and Bandwidth Flexibility
2.2. Beam Hopping
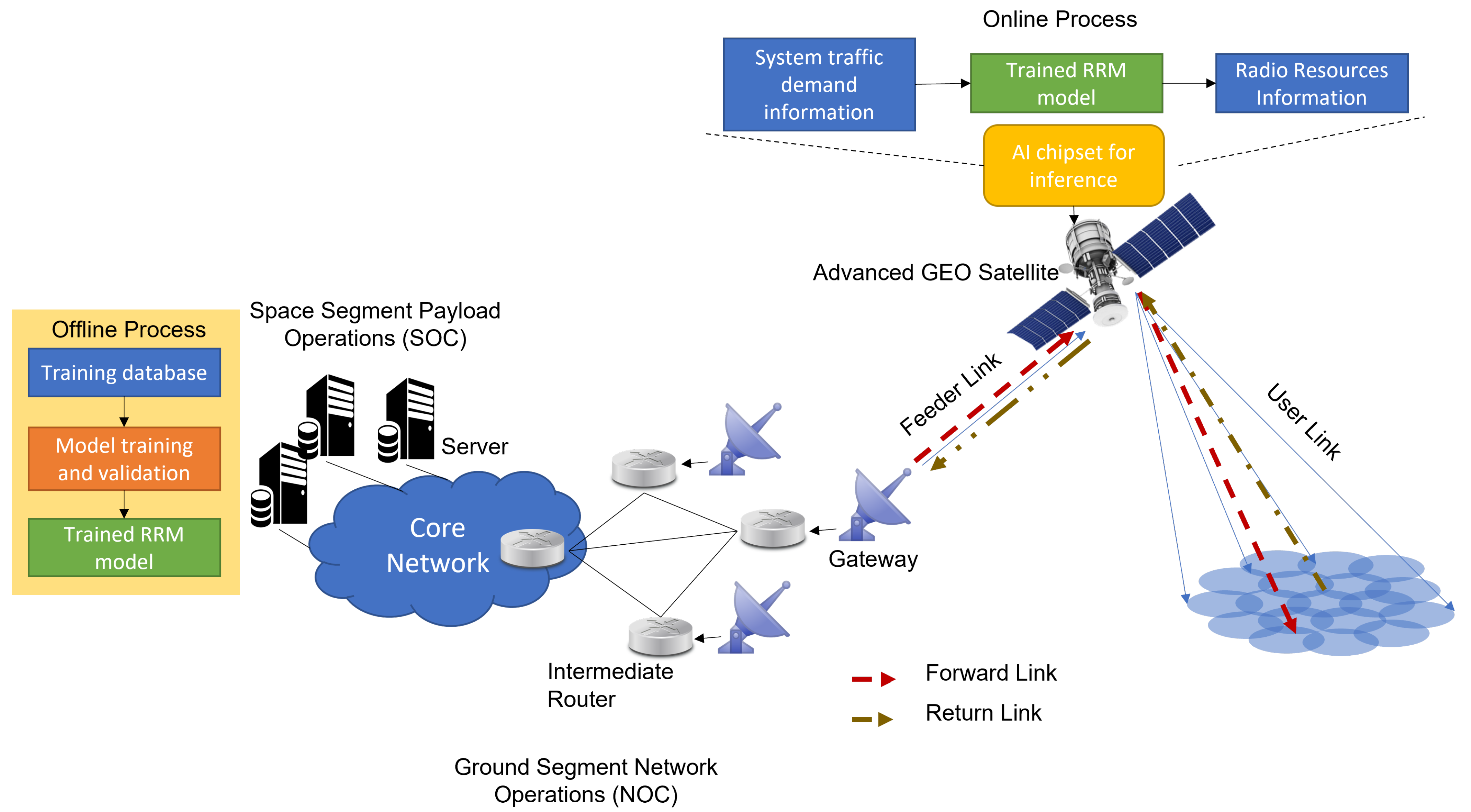
3. ML for SatCom RRM: Architecture and Techniques
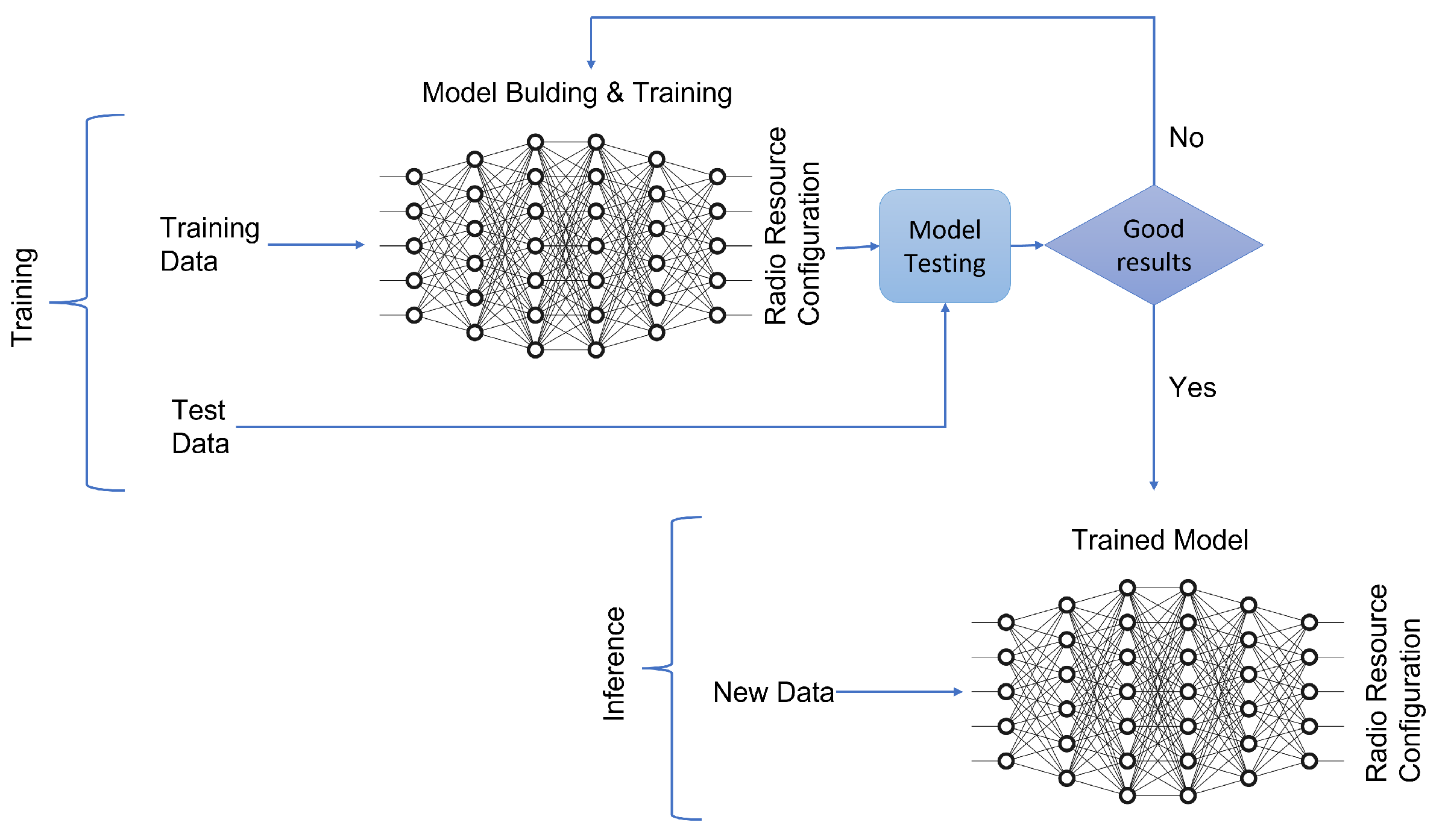
3.1. Machine Learning Implementation in SatComs Systems
3.1.1. Online or Offline Learning
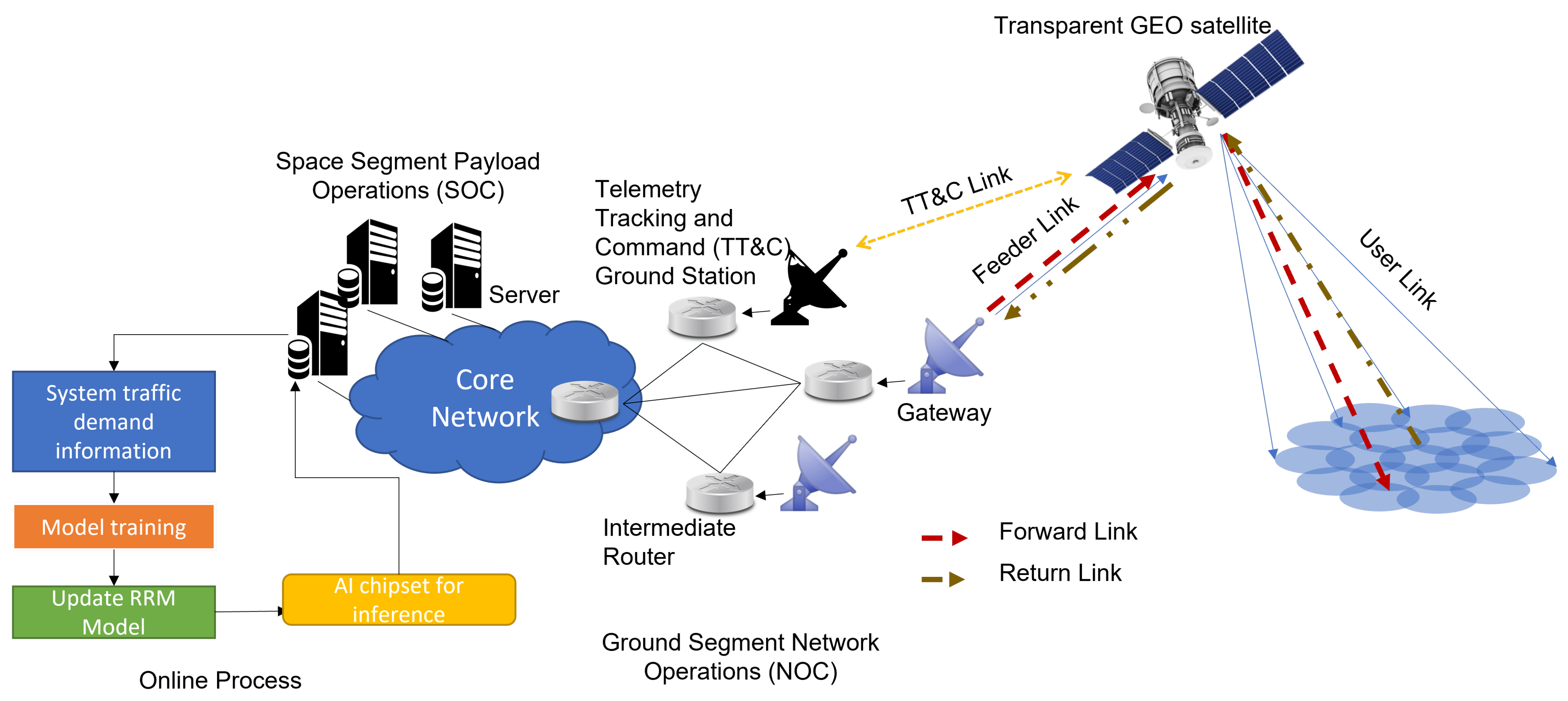
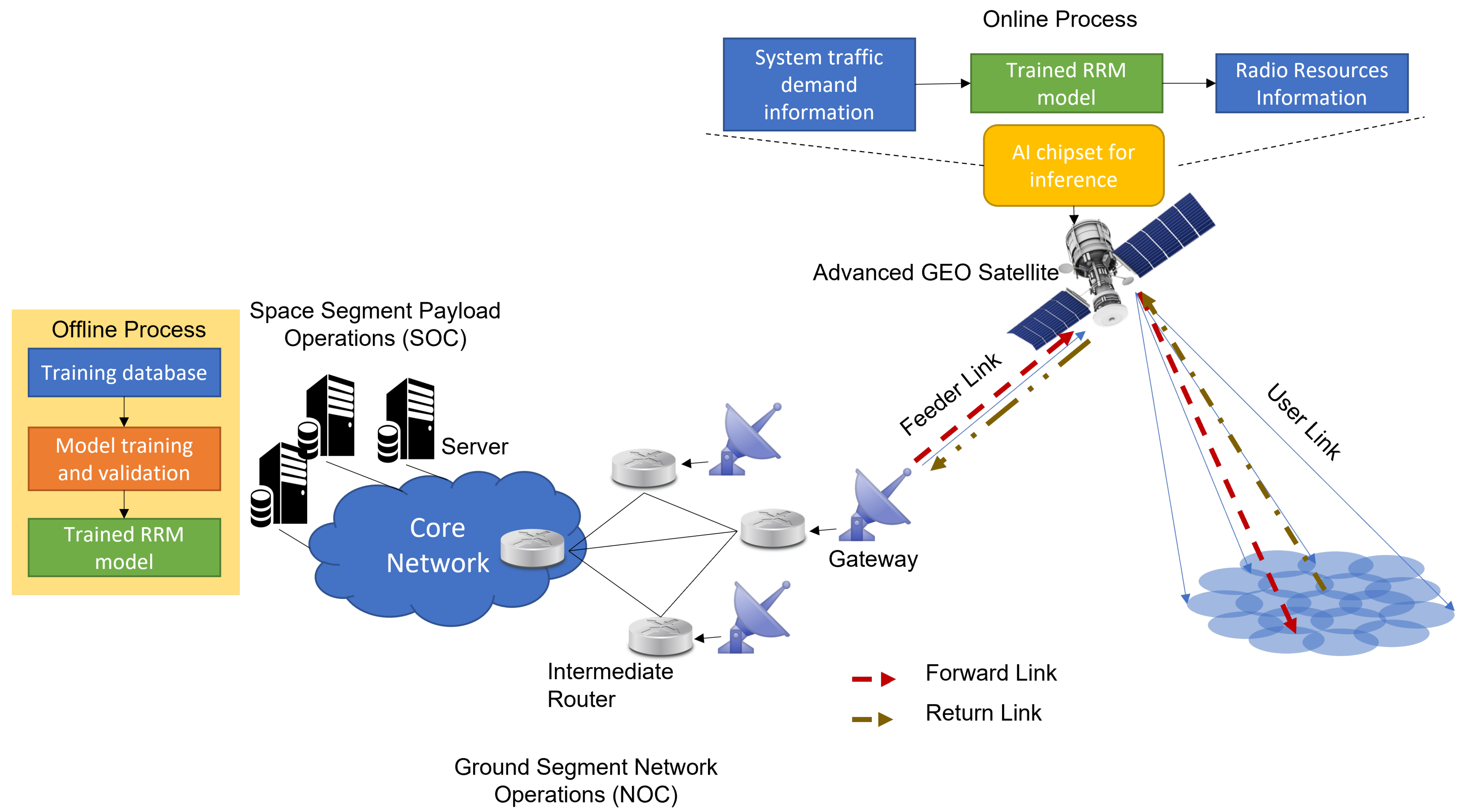
3.1.2. Ai Chipset On-Ground or On-Board
3.2. Supervised Learning for RRM
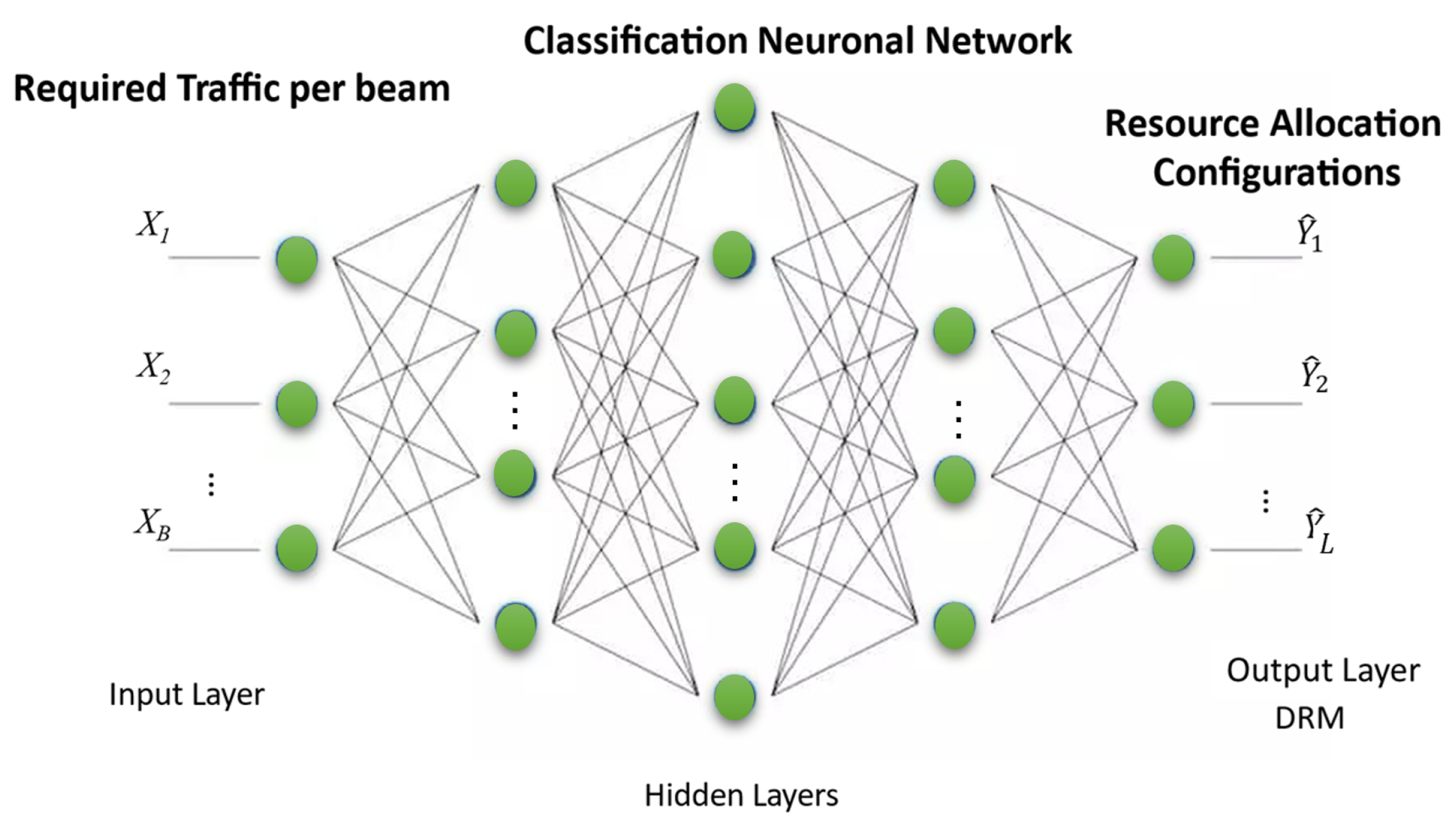
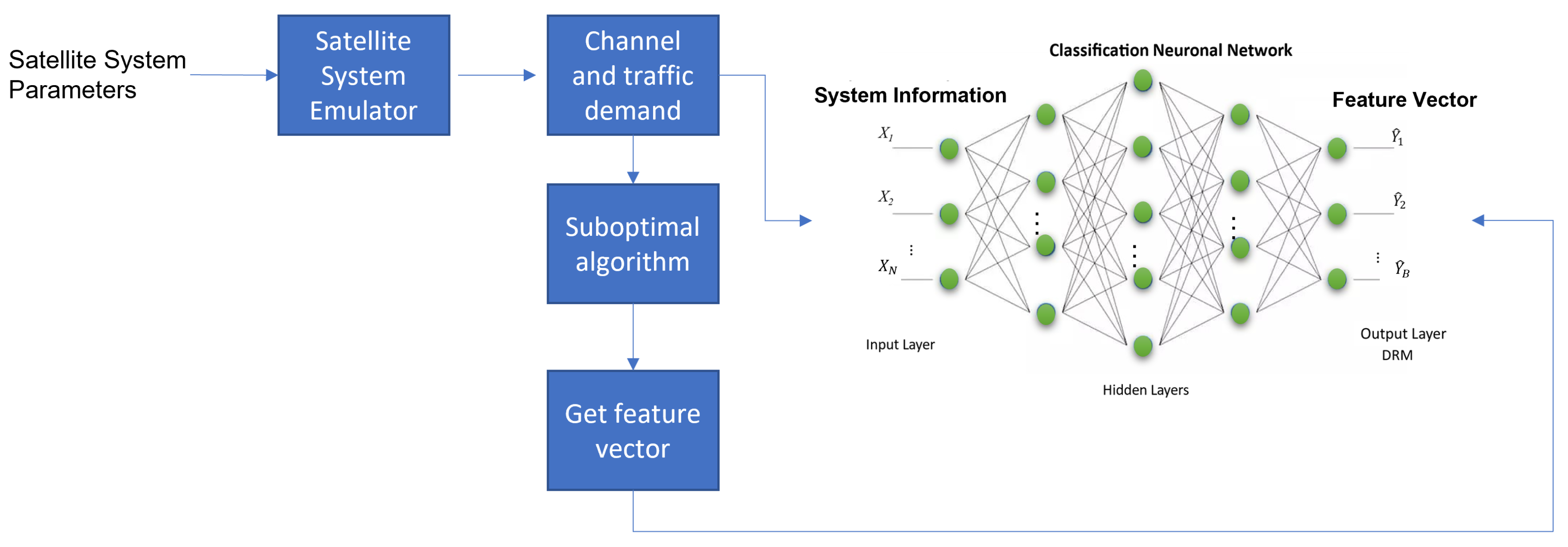
3.2.1. Dnn-Based RRM: Power, Beamwidth and Bandwidth Flexibility
3.2.2. DNN-Assisted RRM: Beam Hopping
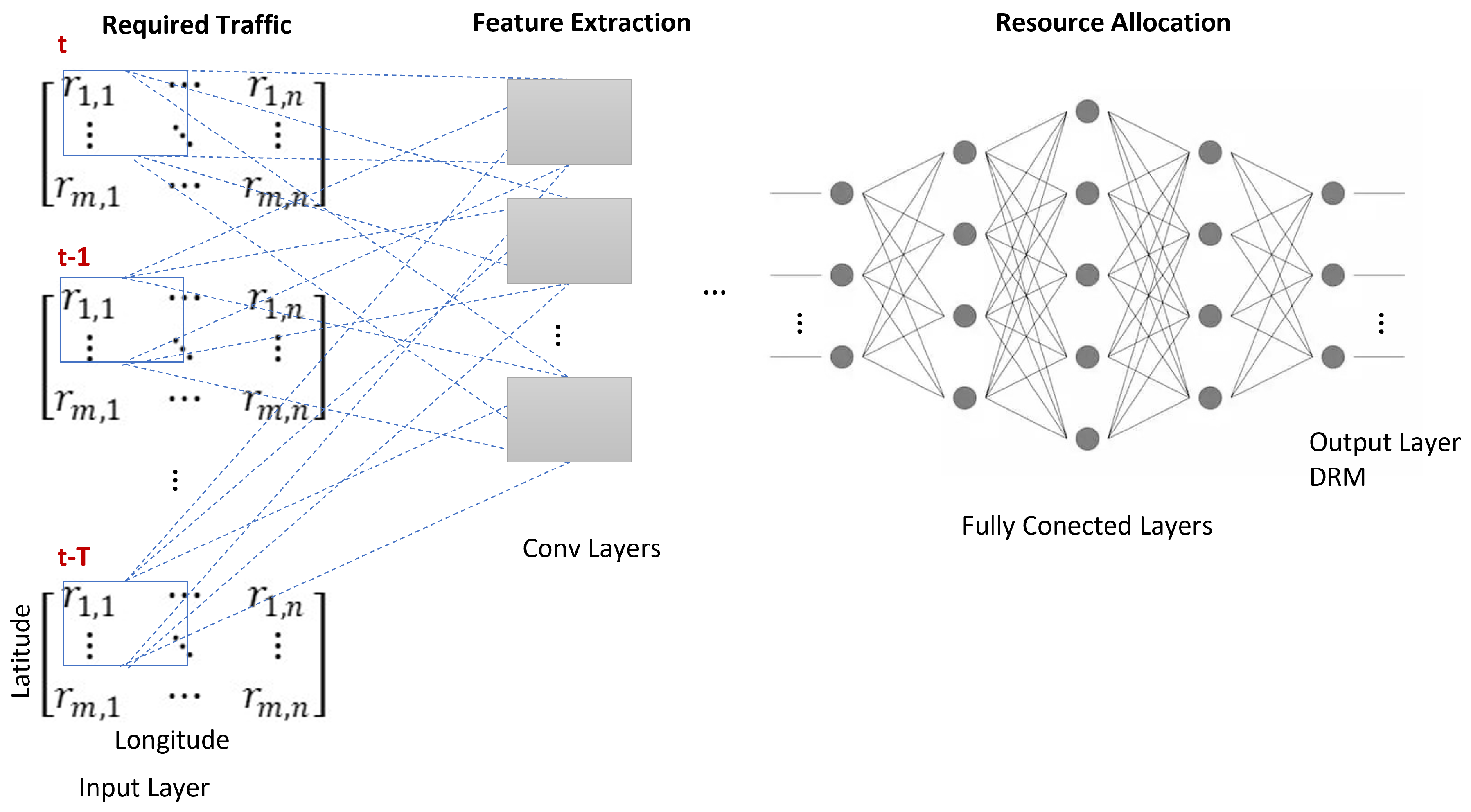
3.2.3. Cnn-Based RRM: Power and Bandwidth Flexible
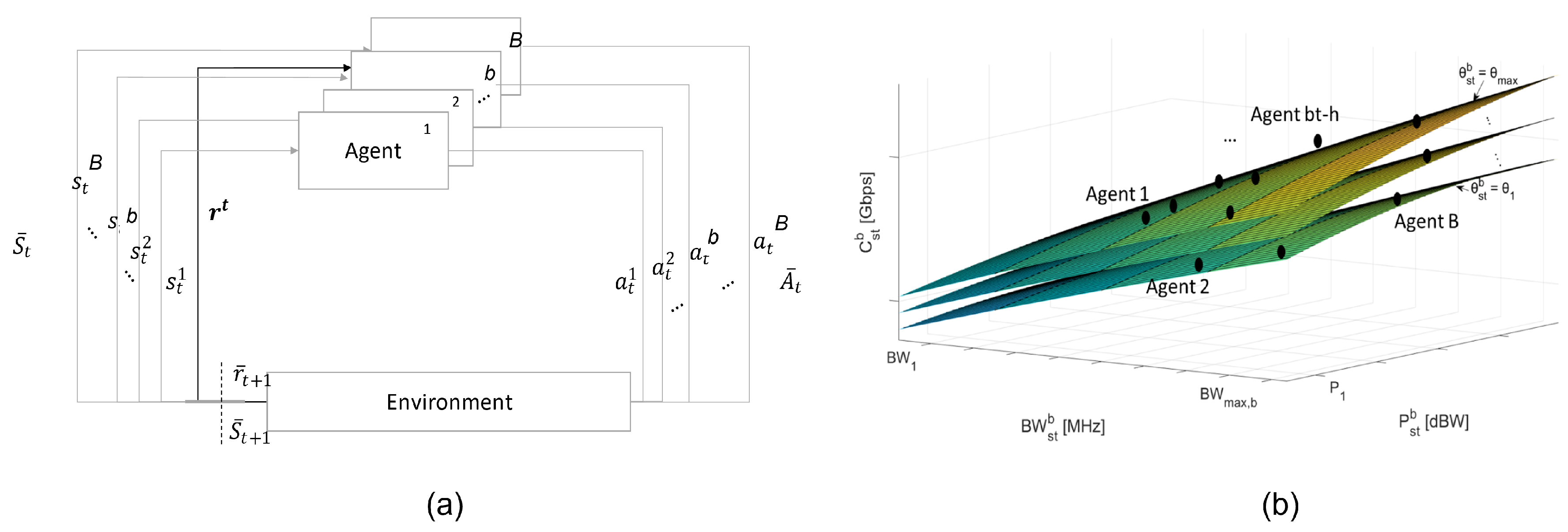
3.3. Reinforcement Learning for RRM
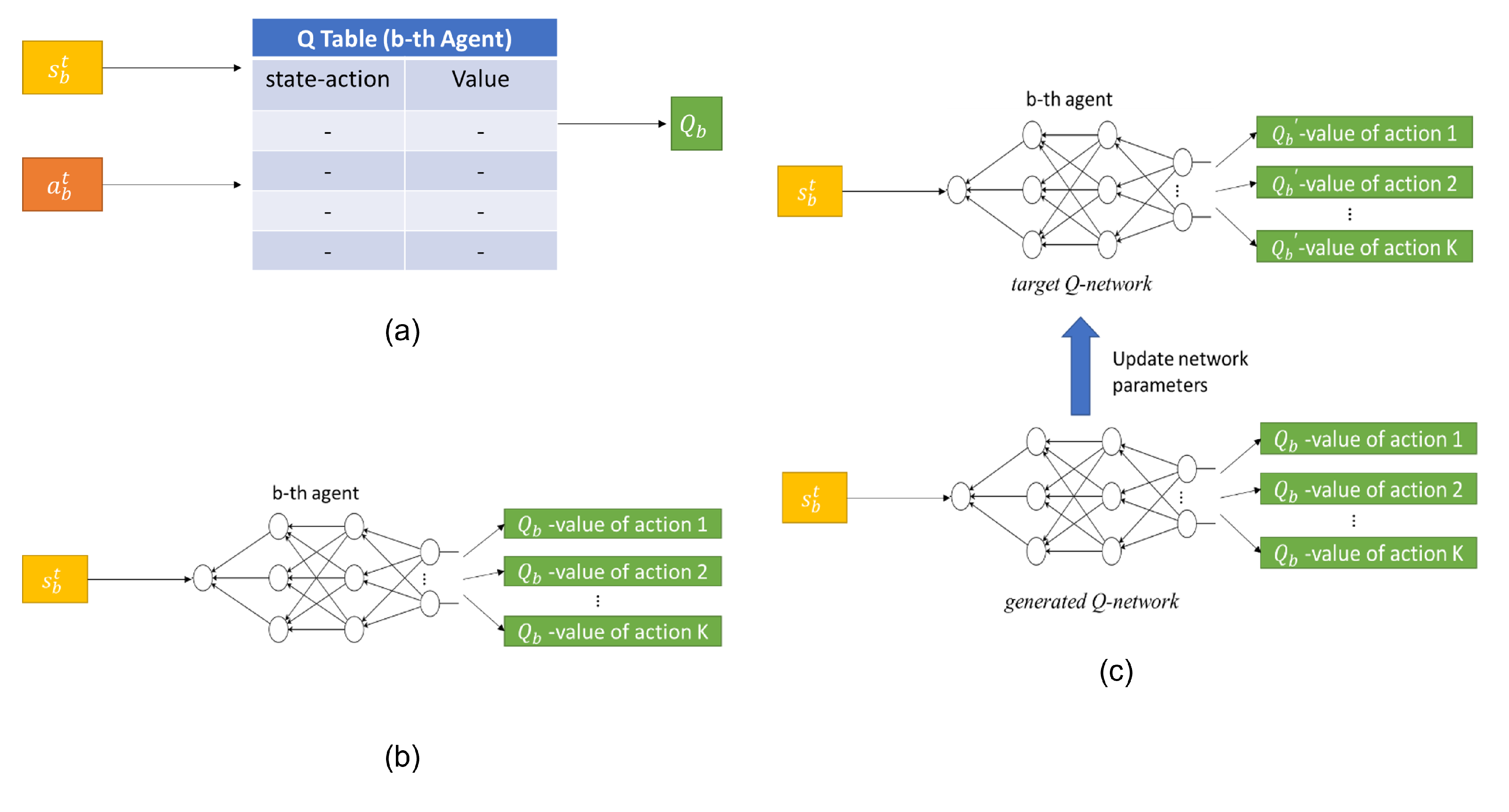
3.3.1. Q Learning
3.3.2. Deep Q Learning
3.3.3. Double Deep Q Learning
4. Performance Evaluation
4.1. Simulation Parameters
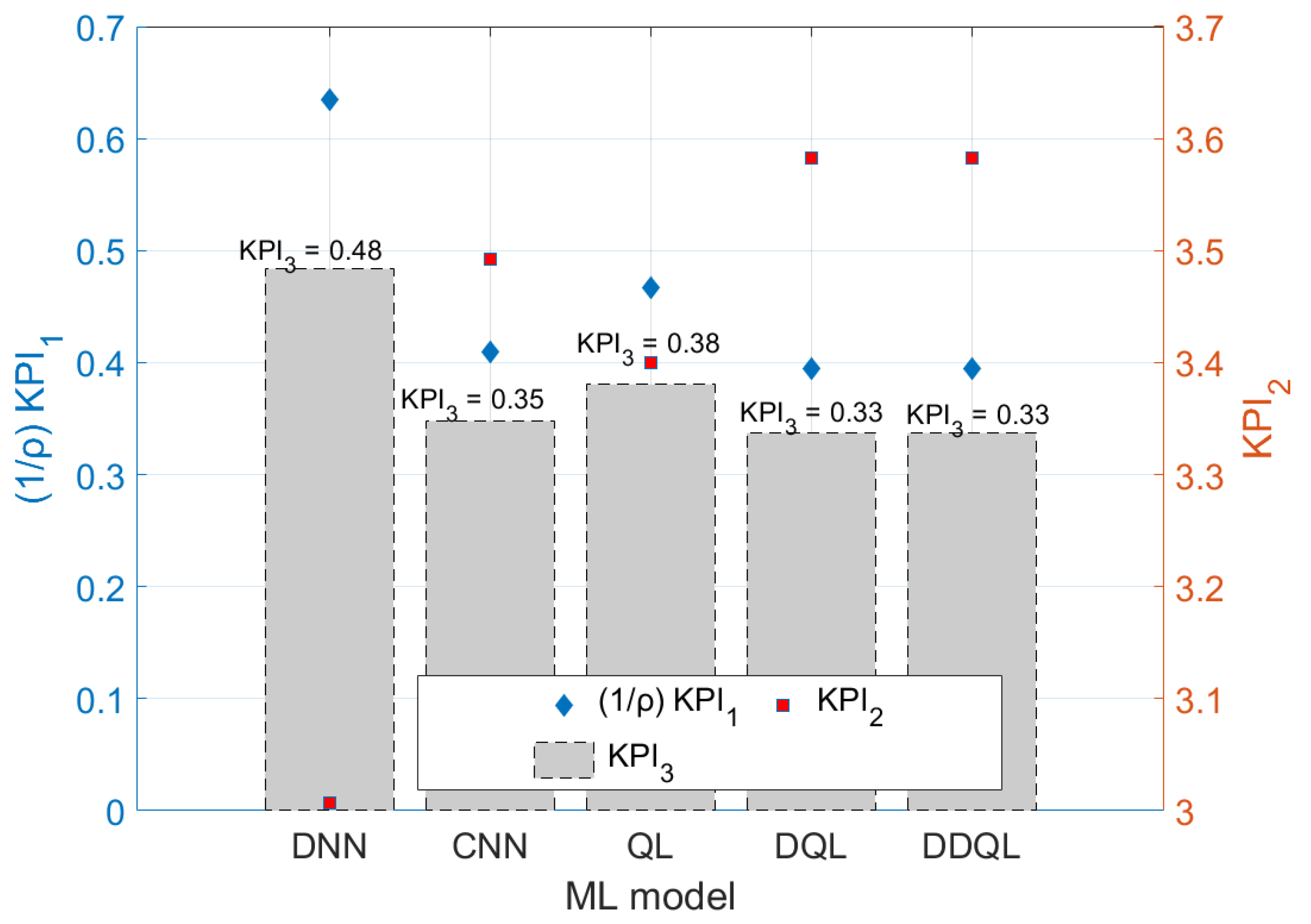
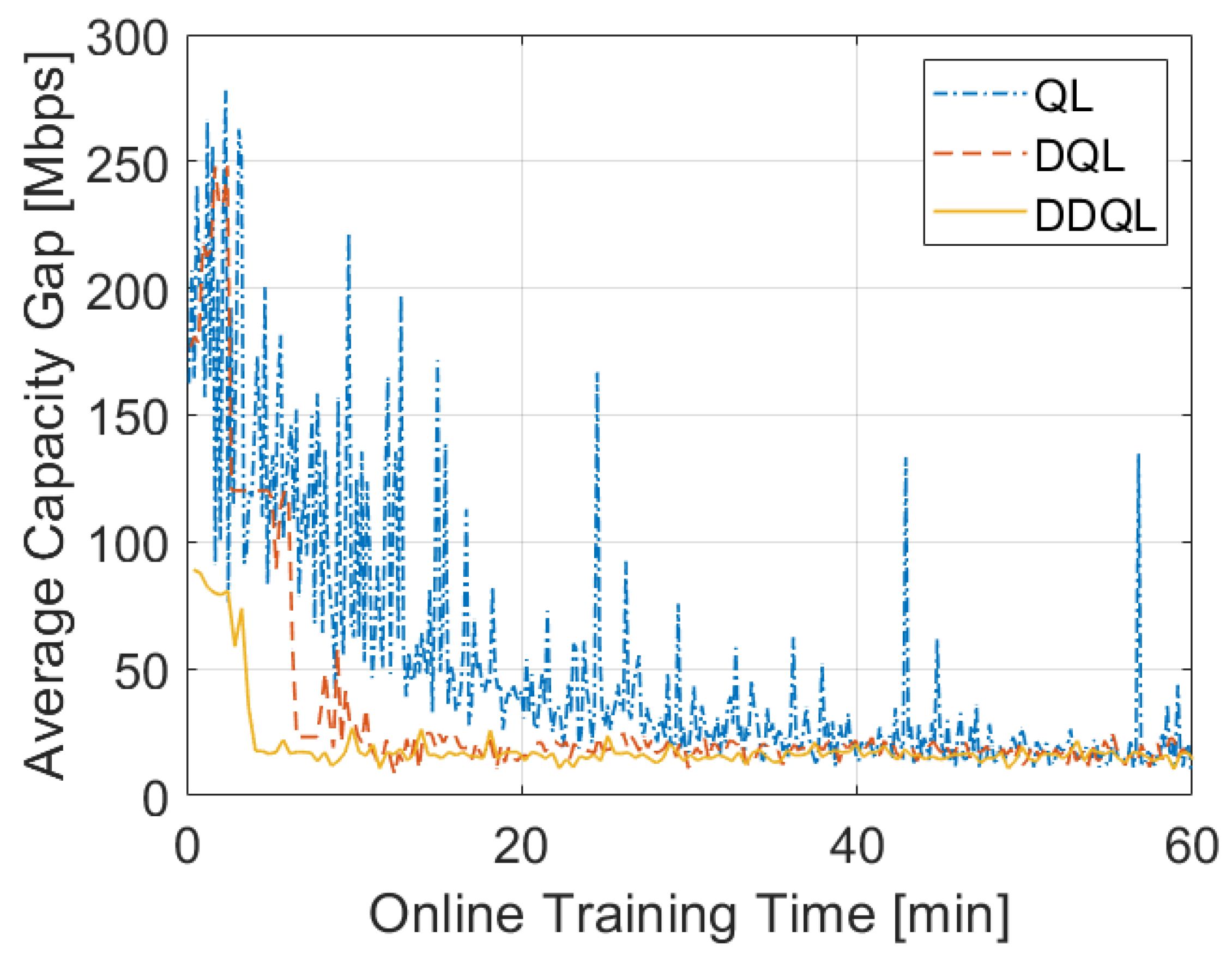
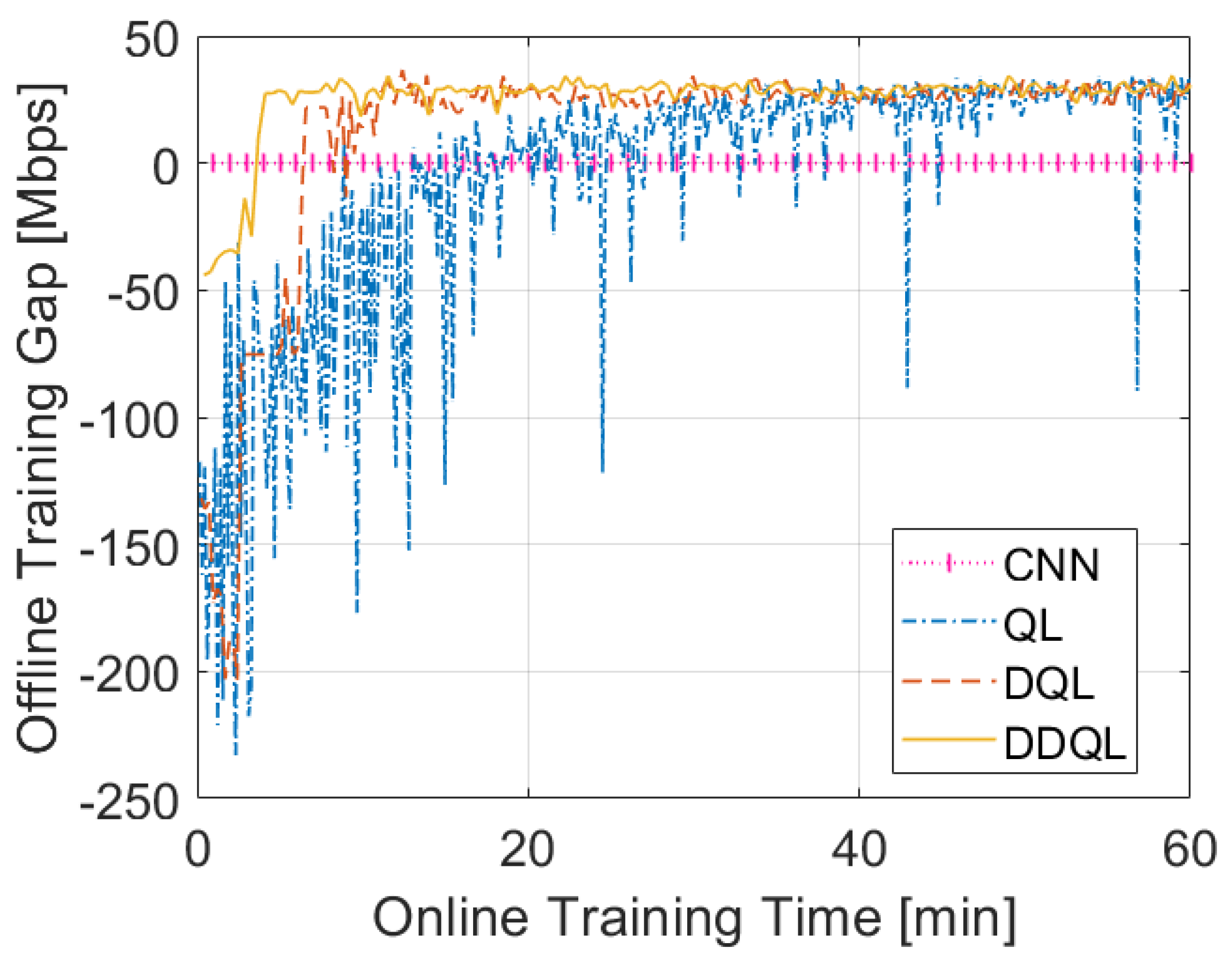
4.2. Performance Comparison
4.3. Delay Added to the System
5. Discussion
5.1. ML Technique Selection
5.2. AI Chipset Selection
- Scalar processing elements (e.g., CPUs) are very efficient at complex algorithms with diverse decision trees and a broad set of libraries, but they are limited in performance scaling.
- Vector processing elements (e.g., DSPs, GPUs and VPUs) are more efficient at a narrower set of parallelizable compute functions. Still, they experience latency and efficiency penalties because of an inflexible memory hierarchy.
- Programmable logic (e.g., FPGAs) can be customized to a particular compute function, making them the best at latency-critical real-time applications and irregular data structures. Still, algorithmic changes have traditionally taken hours to compile versus minutes.
- Intel Movidius Myriad X VPU: The Intel® Movidius™ Myriad™ X VPU is Intel’s first VPU to feature a Neural Compute Engine—a dedicated hardware accelerator for deep neural network inference. The Neural Compute Engine in conjunction with the 16 powerful SHAVE cores and high throughput intelligent memory fabric makes Intel® Movidius™ Myriad™ X ideal for on-device deep neural networks and computer vision applications [49]. This chipset has been already tested and flown in ESA missions Phi-Sat 1 and Phi-Sat 2 (in preparation) integrated into the UB0100 CubeSat Board [50].
- Nvidia Jetson TX2:The Jetson family of modules all use the same NVIDIA CUDA-X™ software. Support for cloud-native technologies such as containerization and orchestration makes it easier to build, deploy and manage AI at the edge. Given the specifications of the TX2 version [51], it promises suitability for in-orbit demonstrations.
- Qualcomm Cloud AI 100: The Qualcomm Cloud AI 100 is a GPU-based AI chipset designed for AI inference acceleration, addressing the main power efficiency, scale, process node advancements and signal processing challenges. The computational capacity of the AI 100 family ranges from 70 to 400 TOPS, with a power consumption ranging from 15 to 75 W [52].
- AMD Instinct™ MI25: The AMD Instinct family is equipped with the Vega GPU architecture to handle large data sets and diverse compute workloads. The MI25 model contains 4096 processors with a maximum computational capacity of 12.29 TFlops [53].
- Lattice sensAI: The Lattice sensAI is an FPGA-based ML/AI solution targeting low power applications in the range of 1 mW–1 W [13]. In this case, the programmable architecture of the FPGA can be defined using custom NN cores tailored for AI applications and implemented directly using the major ML frameworks [54].
- Xilinx Versal AI Core: This chipset from Xilinx combines all the three architectures in a single device, providing complete flexibility. In terms of performance, it is on the top of the food chain; however, power consumption may be too elevated [55].
5.2.1. Compatibility Matrix and Trade-Off and Selection
5.2.2. Future Proof of Concept
5.3. Open Challenges
5.3.1. Time-Varying Environment
5.3.2. Flexible Irregular Beams
5.3.3. Hardware Implementations
5.3.4. Cost Optimization
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Size | Activation Function |
|---|---|---|
| Input | Number of beams | - |
| Hidden Layer 1 | 256 | Sigmoid |
| Hidden Layer 2 | 128 | Sigmoid |
| Hidden Layer 3 | 128 | Sigmoid |
| Hidden Layer 4 | 32 | Sigmoid |
| Hidden Layer 5 | 32 | Sigmoid |
| Output | Total number of possible configurations | Softmax |
| Layer | Input | Kernel | Activation Function | Output |
|---|---|---|---|---|
| Conv1 | 256 × 256 × T | 10 × 10, 16 | ReLu | 247 × 247 × 6 |
| Pool1 | 247 × 247 × 6 | NA | NA | 123 × 123 × 16 |
| Conv2 | 123 × 123 × 16 | 8 × 8, 16 | ReLu | 116 × 116 × 16 |
| Pool2 | 116 × 116 × 16 | NA | NA | 58 × 58 × 16 |
| Conv3 | 58 × 58 × 16 | 5 × 5, 32 | ReLu | 54 × 54 × 32 |
| Pool3 | 54 × 54 × 32 | NA | NA | 27 × 27 × 32 |
| Conv4 | 27 × 27 × 32 | 3 × 3, 32 | ReLu | 25 × 25 × 32 |
| Pool4 | 25 × 25 32 | NA | NA | 12 × 12 × 32 |
| Flatten | 12 × 12 × 32 | NA | NA | 4608 |
| FC1 | 4608 | NA | tanh | 512 |
| FC2 | 512 | NA | tanh | 512 |
| Class | 512 | NA | Softmax | Number of configurations available in the payload |
| Layer | DQL | DDQL | Activation Function |
|---|---|---|---|
| Size | Size | ||
| Input | shape of the state | shape of the state | - |
| Hidden Layer 1 | 132 | 132 | ReLu |
| Hidden Layer 2 | 132 | 132 | ReLu |
| Output | number of actions | number of actions | Softmax |
References
- Guerster, M.; Grotz, J.; Belobaba, P.; Crawley, E.; Cameron, B. Revenue Management for Communication Satellite Operators—Opportunities and Challenges. In Proceedings of the 2020 IEEE Aerospace Conference, Big Sky, MT, USA, 7–14 March 2020; pp. 1–15. [Google Scholar] [CrossRef]
- Kodheli, O.; Lagunas, E.; Maturo, N.; Sharma, S.K.; Shankar, B.; Montoya, J.F.M.; Duncan, J.C.M.; Spano, D.; Chatzinotas, S.; Kisseleff, S.; et al. Satellite Communications in the New Space Era: A Survey and Future Challenges. IEEE Commun. Surv. Tutor. 2021, 23, 70–109. [Google Scholar] [CrossRef]
- Li, F.; Lam, K.Y.; Jia, M.; Zhao, K.; Li, X.; Wang, L. Spectrum Optimization for Satellite Communication Systems with Heterogeneous User Preferences. IEEE Syst. J. 2020, 14, 2187–2191. [Google Scholar] [CrossRef]
- Kuang, L.; Chen, X.; Jiang, C.; Zhang, H.; Wu, S. Radio Resource Management in Future Terrestrial-Satellite Communication Networks. IEEE Wirel. Commun. 2017, 24, 81–87. [Google Scholar] [CrossRef]
- Cocco, G.; de Cola, T.; Angelone, M.; Katona, Z.; Erl, S. Radio Resource Management Optimization of Flexible Satellite Payloads for DVB-S2 Systems. IEEE Trans. Broadcast. 2018, 64, 266–280. [Google Scholar] [CrossRef] [Green Version]
- Abdu, T.S.; Kisseleff, S.; Lagunas, E.; Chatzinotas, S. Flexible Resource Optimization for GEO Multibeam Satellite Communication System. IEEE Trans. Wirel. Commun. 2021, 20, 7888–7902. [Google Scholar] [CrossRef]
- Kawamoto, Y.; Kamei, T.; Takahashi, M.; Kato, N.; Miura, A.; Toyoshima, M. Flexible Resource Allocation With Inter-Beam Interference in Satellite Communication Systems With a Digital Channelizer. IEEE Trans. Wirel. Commun. 2020, 19, 2934–2945. [Google Scholar] [CrossRef]
- Kisseleff, S.; Lagunas, E.; Abdu, T.S.; Chatzinotas, S.; Ottersten, B. Radio Resource Management Techniques for Multibeam Satellite Systems. IEEE Commun. Lett. 2020, 25, 2448–2452. [Google Scholar] [CrossRef]
- Vazquez, M.A.; Henarejos, P.; Pappalardo, I.; Grechi, E.; Fort, J.; Gil, J.C.; Lancellotti, R.M. Machine Learning for Satellite Communications Operations. IEEE Commun. Mag. 2021, 59, 22–27. [Google Scholar] [CrossRef]
- Cronk, R.; Callahan, P.; Bernstein, L. Rule-based expert systems for network management and operations: An introduction. IEEE Netw. 1988, 2, 7–21. [Google Scholar] [CrossRef]
- Ferreira, P.V.R.; Paffenroth, R.; Wyglinski, A.M.; Hackett, T.M.; Bilén, S.G.; Reinhart, R.C.; Mortensen, D.J. Multiobjective Reinforcement Learning for Cognitive Satellite Communications Using Deep Neural Network Ensembles. IEEE J. Sel. Areas Commun. 2018, 36, 1030–1041. [Google Scholar] [CrossRef]
- Hu, X.; Liao, X.; Liu, Z.; Liu, S.; Ding, X.; Helaoui, M.; Wang, W.; Ghannouchi, F.M. Multi-Agent Deep Reinforcement Learning-Based Flexible Satellite Payload for Mobile Terminals. IEEE Trans. Veh. Technol. 2020, 69, 9849–9865. [Google Scholar] [CrossRef]
- Jiang, C.; Zhang, H.; Ren, Y.; Han, Z.; Chen, K.C.; Hanzo, L. Machine Learning Paradigms for Next-Generation Wireless Networks. IEEE Wirel. Commun. 2017, 24, 98–105. [Google Scholar] [CrossRef] [Green Version]
- Jagannath, J.; Polosky, N.; Jagannath, A.; Restuccia, F.; Melodia, T. Machine learning for wireless communications in the Internet of Things: A comprehensive survey. Ad Hoc Netw. 2019, 93, 101913. [Google Scholar] [CrossRef] [Green Version]
- Morocho-Cayamcela, M.E.; Lee, H.; Lim, W. Machine Learning for 5G/B5G Mobile and Wireless Communications: Potential, Limitations, and Future Directions. IEEE Access 2019, 7, 137184–137206. [Google Scholar] [CrossRef]
- Bega, D.; Gramaglia, M.; Banchs, A.; Sciancalepore, V.; Costa-Pérez, X. A Machine Learning Approach to 5G Infrastructure Market Optimization. IEEE Trans. Mob. Comput. 2020, 19, 498–512. [Google Scholar] [CrossRef]
- Vazquez, M.A.; Henarejos, P.; Pérez-Neira, A.I.; Grechi, E.; Voight, A.; Gil, J.C.; Pappalardo, I.; Credico, F.D.; Lancellotti, R.M. On the Use of AI for Satellite Communications. arXiv 2020, arXiv:2007.10110. [Google Scholar]
- Rath, M.; Mishra, S. Security Approaches in Machine Learning for Satellite Communication. In Machine Learning and Data Mining in Aerospace Technology; Hassanien, A.E., Darwish, A., El-Askary, H., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 189–204. [Google Scholar] [CrossRef]
- Yu, H.; Zhang, R.; Ding, R. Interference Recognition Based on Machine Learning for Satellite Communications. In Proceedings of the 2018 International Conference on Machine Learning Technologies, Stockholm, Sweden, 10–15 July 2018; Association for Computing Machinery: New York, NY, USA, 2018. ICMLT’18. pp. 18–23. [Google Scholar] [CrossRef]
- SATAI—Machine Learning and Artificial Intelligence for Satellite Communication. 2021. Available online: https://artes.esa.int/projects/satai (accessed on 12 October 2021).
- MLSAT—Machine Learning and Artificial Intelligence for Satellite Communication. Available online: https://artes.esa.int/projects/mlsat (accessed on 10 November 2021).
- ATRIA. 2021. Available online: https://www.atria-h2020.eu/ (accessed on 12 October 2021).
- Kato, N.; Fadlullah, Z.M.; Tang, F.; Mao, B.; Tani, S.; Okamura, A.; Liu, J. Optimizing Space-Air-Ground Integrated Networks by Artificial Intelligence. IEEE Wirel. Commun. 2019, 26, 140–147. [Google Scholar] [CrossRef] [Green Version]
- Wang, A.; Lei, L.; Lagunas, E.; Chatzinotas, S.; Ottersten, B. Dual-DNN Assisted Optimization for Efficient Resource Scheduling in NOMA-Enabled Satellite Systems. In Proceedings of the IEEE GLOBECOM, Madrid, Spain, 7–11 December 2021; pp. 1–4. [Google Scholar]
- Deng, B.; Jiang, C.; Yao, H.; Guo, S.; Zhao, S. The Next Generation Heterogeneous Satellite Communication Networks: Integration of Resource Management and Deep Reinforcement Learning. IEEE Wirel. Commun. 2020, 27, 105–111. [Google Scholar] [CrossRef]
- Luis, J.J.G.; Guerster, M.; del Portillo, I.; Crawley, E.; Cameron, B. Deep Reinforcement Learning for Continuous Power Allocation in Flexible High Throughput Satellites. In Proceedings of the 2019 IEEE Cognitive Communications for Aerospace Applications Workshop (CCAAW), Cleveland, OH, USA, 25–26 June 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Liu, S.; Hu, X.; Wang, W. Deep Reinforcement Learning Based Dynamic Channel Allocation Algorithm in Multibeam Satellite Systems. IEEE Access 2018, 6, 15733–15742. [Google Scholar] [CrossRef]
- Liao, X.; Hu, X.; Liu, Z.; Ma, S.; Xu, L.; Li, X.; Wang, W.; Ghannouchi, F.M. Distributed Intelligence: A Verification for Multi-Agent DRL-Based Multibeam Satellite Resource Allocation. IEEE Commun. Lett. 2020, 24, 2785–2789. [Google Scholar] [CrossRef]
- Hu, X.; Zhang, Y.; Liao, X.; Liu, Z.; Wang, W.; Ghannouchi, F.M. Dynamic Beam Hopping Method Based on Multi-Objective Deep Reinforcement Learning for Next Generation Satellite Broadband Systems. IEEE Trans. Broadcast. 2020, 66, 630–646. [Google Scholar] [CrossRef]
- Lei, L.; Lagunas, E.; Yuan, Y.; Kibria, M.G.; Chatzinotas, S.; Ottersten, B. Beam Illumination Pattern Design in Satellite Networks: Learning and Optimization for Efficient Beam Hopping. IEEE Access 2020, 8, 136655–136667. [Google Scholar] [CrossRef]
- Ortiz-Gomez, F.G.; Tarchi, D.; Rodriguez-Osorio, R.M.; Vanelli-Coralli, A.; Salas-Natera, M.A.; Landeros-Ayala, S. Supervised Machine Learning for Power and Bandwidth Management in VHTS Systems. In Proceedings of the 2020 10th Advanced Satellite Multimedia Systems Conference and the 16th Signal Processing for Space Communications Workshop (ASMS/SPSC), Graz, Austria, 20–21 October 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Ortiz-Gomez, F.G.; Tarchi, D.; Martínez, R.; Vanelli-Coralli, A.; Salas-Natera, M.A.; Landeros-Ayala, S. Supervised machine learning for power and bandwidth management in very high throughput satellite systems. Int. J. Satell. Commun. Netw. 2021, 1–16. [Google Scholar] [CrossRef]
- Ortiz-Gomez, F.; Tarchi, D.; Martínez, R.; Vanelli-Coralli, A.; Salas-Natera, M.A.; Landeros-Ayala, S. Convolutional Neural Networks for Flexible Payload Management in VHTS Systems. IEEE Syst. J. 2021, 15, 4675–4686. [Google Scholar] [CrossRef]
- Ortiz-Gomez, F.G.; Tarchi, D.; Martínez, R.; Vanelli-Coralli, A.; Salas-Natera, M.A.; Landeros-Ayala, S. Cooperative Multi-Agent Deep Reinforcement Learning for Resource Management in Full Flexible VHTS Systems. IEEE Trans. Cogn. Commun. Netw. 2021, 8, 335–349. [Google Scholar] [CrossRef]
- SPAICE—Satellite Signal Processing Techniques Using a Commercial Off-The-Shelf AI Chipset. Available online: https://wwwen.uni.lu/snt/research/sigcom/projects/spaice (accessed on 9 November 2021).
- What Are NASA’s Technology Educational Satellites? Available online: https://www.nasa.gov/ames/techedsat (accessed on 19 November 2021).
- Top Facts for Space Enthusiasts|SES. Available online: https://www.ses.com/news/ses-17-experience-endless-connectivity/top-facts-space-enthusiasts (accessed on 19 October 2021).
- Future Eutelsat Satellite Launches|Eutelsat. Available online: https://www.eutelsat.com/satellites/future-satellites.html (accessed on 19 October 2021).
- Komiyama, N.; Miura, A.; Orikasa, T.; Fujino, Y. Development of Resource Allocation Re-construction Technology (Digital Beam Former and Digital Channelizer). J. Natl. Inst. Inf. Commun. Technol. 2016, 62, 151–163. [Google Scholar] [CrossRef]
- Ortiz-Gomez, F.G.; Rodriguez-Osorio, R.M.; Salas-Natera, M.; Landeros-Ayala, S. Adaptive resources allocation for flexible payload enabling VHTS systems: Methodology and architecture. In Proceedings of the 36th International Communications Satellite Systems Conference (ICSSC 2018), Niagara Falls, ON, Canada, 15–18 October 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Digital Video Broadcasting (DVB). Second generation framing structure, channel coding and modulation systems for Broadcasting, Interactive Services, News Gathering and other broadband satellite applications; Part 2: DVB-S2 Extensions (DVB-S2X). In European Standard EN 302 307-2; European Telecommunications Standards Institute: Sophia Antipolis, France, 2014. [Google Scholar]
- Caruana, R.; Niculescu-Mizil, A. An empirical comparison of supervised learning algorithms. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; Association for Computing Machinery: New York, NY, USA; pp. 161–168. [Google Scholar] [CrossRef] [Green Version]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Tan, Z.; Karakose, M. Optimized Deep Reinforcement Learning Approach for Dynamic System. In Proceedings of the 2020 IEEE International Symposium on Systems Engineering (ISSE), Vienna, Austria, 12 October–12 November 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Eutelsat KA-SAT 9A (KASAT, KA-Sat). Available online: https://www.satbeams.com/satellites?norad=37258 (accessed on 19 November 2021).
- Architecture Apocalypse Dream Architecture for Deep Learning Inference and Compute—VERSAL AI Core. Available online: https://www.xilinx.com/support/documentation/white_papers/EW2020-Deep-Learning-Inference-AICore.pdf (accessed on 19 November 2021).
- AI Chip (ICs and IPs). Available online: https://basicmi.github.io/AI-Chip/ (accessed on 19 November 2021).
- Intel Movidius Myriad X Vision Processing Unit (VPU) with Neural Compute Engine. Available online: https://www.intel.com/content/www/us/en/products/docs/processors/movidius-vpu/myriad-x-product-brief.html (accessed on 19 November 2021).
- UB0100 CubeSat Board for AI and Computer Vision Acceleration. Available online: https://ubotica.com/publications/ (accessed on 19 November 2021).
- Jetson Modules. Available online: https://developer.nvidia.com/embedded/jetson-modules (accessed on 19 November 2021).
- Qualcomm®Cloud AI 100. Available online: https://www.qualcomm.com/media/documents/files/qualcomm-cloud-ai-100-product-brief.pdf (accessed on 19 November 2021).
- Radeon Instinct™ MI25 Accelerator. Available online: https://www.amd.com/en/products/professional-graphics/instinct-mi25 (accessed on 19 November 2021).
- Lattice sensAI. Available online: https://www.latticesemi.com/sensAI (accessed on 19 November 2021).
- Versal™ ACAP AI Core Series Product Selection Guide. Available online: https://www.xilinx.com/support/documentation/selection-guides/versal-ai-core-product-selection-guide.pdf (accessed on 19 November 2021).
- Ponulak, F.; Kasinski, A. Introduction to spiking neural networks: Information processing, learning and applications. Acta Neurobiol. Exp. 2011, 71, 409–433. [Google Scholar]
- Ortiz-Gomez, F.G.; Salas-Natera, M.A.; Martínez, R.; Landeros-Ayala, S. Optimization in VHTS Satellite System Design with Irregular Beam Coverage for Non-Uniform Traffic Distribution. Remote Sens. 2021, 13, 2642. [Google Scholar] [CrossRef]
- Honnaiah, P.J.; Lagunas, E.; Spano, D.; Maturo, N.; Chatzinotas, S. Demand-based Scheduling for Precoded Multibeam High-Throughput Satellite Systems. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Mazzali, N.; Bhavani Shankar, M.R.; Ottersten, B. On-board signal predistortion for digital transparent satellites. In Proceedings of the 2015 IEEE 16th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Stockholm, Sweden, 28 June–1 July 2015; pp. 535–539. [Google Scholar] [CrossRef] [Green Version]
- Opportunity: The Application of Neuromorphic Processors to SatCom Applications|ESA TIA. Available online: https://artes.esa.int/news/opportunity-application-neuromorphic-processors-satcom-applications (accessed on 19 November 2021).
- Ortiz-Gomez, F.G.; Martínez, R.; Salas-Natera, M.A.; Cornejo, A.; Landeros-Ayala, S. Forward Link Optimization for the Design of VHTS Satellite Networks. Electronics 2020, 9, 473. [Google Scholar] [CrossRef] [Green Version]
- Guan, Y.; Geng, F.; Saleh, J.H. Review of High Throughput Satellites: Market Disruptions, Affordability-Throughput Map, and the Cost Per Bit/Second Decision Tree. IEEE Aerosp. Electron. Syst. Mag. 2019, 34, 64–80. [Google Scholar] [CrossRef]








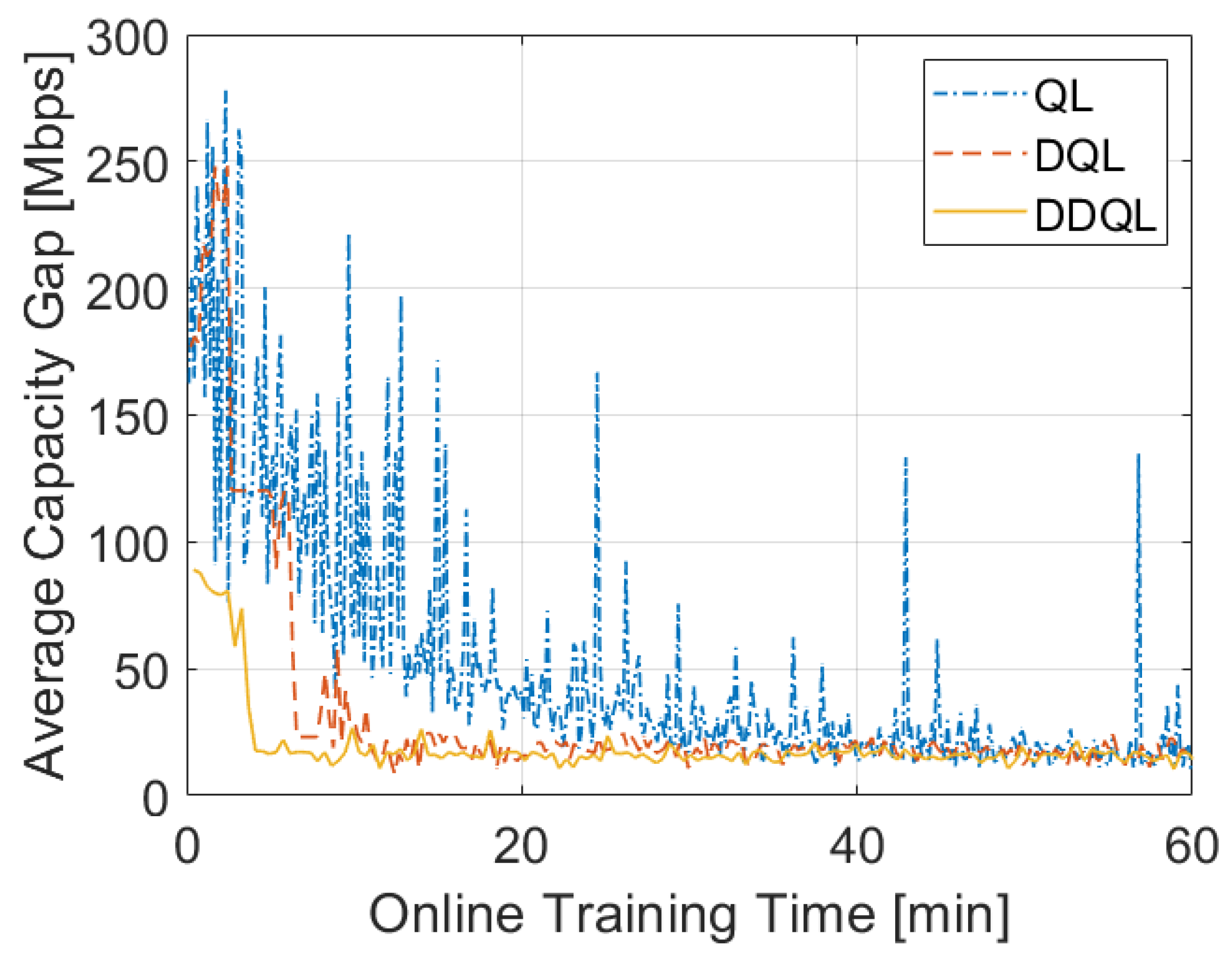
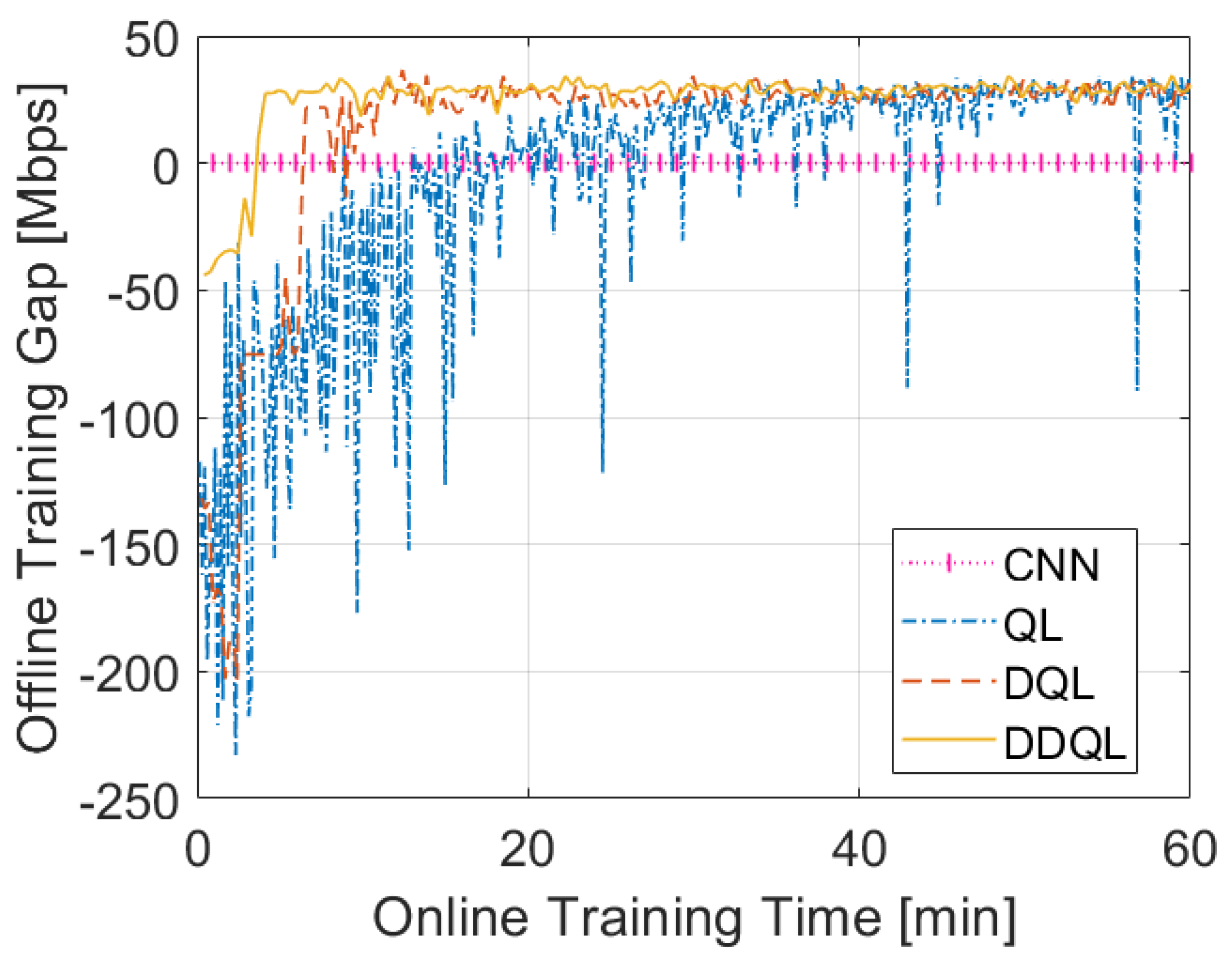
| Project | Identified but Not Investigated Case Studies | Investigated Case Studies |
|---|---|---|
| SATAI |
|
|
| MLSAT |
|
|
| Proposal | Flexible Resources | Frequency Reuse | Optimization | ML Technique | Evaluated in Our Paper | |||
|---|---|---|---|---|---|---|---|---|
| Powe | Bandwidth | Beamwidth | Illumination Time | |||||
| [29] | o | Full | ML-based | RL-DQL (SA) | ||||
| [30] | o | Full | ML-assisted | SL-DNN | o | |||
| [12] | o | 4-colors | ML-based | RL-DQL (MA) | ||||
| [26] | o | 4-colors | ML-based | RL-PPO (SA) | ||||
| [27] | o | 4-colors | ML-based | RL-DQL (SA) | ||||
| [31,32] | o | o | 4-colors | ML-based | SL-DNN | o | ||
| [33] | o | o | o | 4-colors | ML-based | SL-CNN | o | |
| QL-[34] | o | o | o | 4-colors | ML-based | RL-QL (MA) | o | |
| DQL-[34] | o | o | o | 4-colors | ML-based | RL-DQL (MA) | o | |
| DDQL-[34] | o | o | o | 4-colors | ML-based | RL-DDQL (MA) | o | |
| ML Technique | Model | Training | Implementation |
|---|---|---|---|
| Supervised Learning | DNN | offline | On-board |
| CNN | |||
| Reinforcement Learning | QL | online | On-ground |
| DQL | |||
| DDQL |
| Parameter | Value |
|---|---|
| Satellite Orbit | 9° E |
| Number of Beams | 82 |
| Noise power density | −204 dBW/MHz |
| Max. beam gai | 51.8 dBi |
| User antenna gai | 39.8 dBi |
| Maximum bandwidth per beam | 500 MHz |
| Maximum power per beam | 100 W |
| Total available transmit power | 1000 W |
| Machine Learning Technique | Algorithm | Training | Advantages | Disadvantages |
|---|---|---|---|---|
| Supervised Learning | Deep Neural Network | Off-line | Very low computational cost | When the number of beams or resources increases it can have a bad performance |
| Convolutional Neural Network | Off-line | It solves the challenges of using NN. For the DRM system, it works only as an intelligent switch that modifies the resources according to the traffic demand | It will require knowledge of the onboard traffic demand, which will add complexity to the payload design. In order to train, it is necessary to know previously how the traffic demand changes in the service area | |
| Reinforcement Learning | Q-Learning | Online | Adapts to traffic demand. Low computer cost | Requires many episodes to converge and can add a large delay to the system |
| Deep Q-Learning | Online | Adapts to traffic demand. Good performance for resource management and requires few episodes to converge | High computational cost | |
| Double Deep Q-Learning | Online | Adapts to traffic demand. Very good performance for resource management and requires very few episodes to converge | Very high computational cost |
| ML Framework/AI Chipset | Intel Movidius Myriad | Nvidia Jetson | Qualcomm Cloud AI | AMD Instinct | Lattice Sens AI | Xilinx Versal AI Core |
|---|---|---|---|---|---|---|
| TensorFlow | ||||||
| Keras | ||||||
| CNTK | ||||||
| Caffe/Caffe2 | ||||||
| Torch/PyTorch | ||||||
| MXNet | ||||||
| Kaldi | ||||||
| ONNX |
| AI Chipset/Trade-Off KPIs | Computational Capacity | Memory | Power Consumption |
|---|---|---|---|
| Intel Movidius Myriad 2 | 1 TOPS | 2 MB (DRAM 8 GB) | ∼1 W |
| Intel Movidius Myriad X | 4 TOPS | 2.5 MB (DRAM 16 GB) | ∼2 W |
| Nvidia Jetson TX2 | 1.33 TOPS | 4 GB | 7.5 W |
| Nvidia Jetson TX2i | 1.26 TOPS | 8 GB | 10 W |
| Qualcomm Cloud AI 100 family | +70 TOPS | 144 MB (DRAM 32 GB) | >15 W |
| AMD Instinct MI25 | +12 TOPS | 16 GB | >20 W |
| Lattice sensAI | <1 TOPS | <1 MB | <1 W |
| Xilinx Versal AI Core family | +43 TOPS | +4 GB | >20 W |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ortiz-Gomez, F.G.; Lei, L.; Lagunas, E.; Martinez, R.; Tarchi, D.; Querol, J.; Salas-Natera, M.A.; Chatzinotas, S. Machine Learning for Radio Resource Management in Multibeam GEO Satellite Systems. Electronics 2022, 11, 992. https://doi.org/10.3390/electronics11070992
Ortiz-Gomez FG, Lei L, Lagunas E, Martinez R, Tarchi D, Querol J, Salas-Natera MA, Chatzinotas S. Machine Learning for Radio Resource Management in Multibeam GEO Satellite Systems. Electronics. 2022; 11(7):992. https://doi.org/10.3390/electronics11070992
Chicago/Turabian StyleOrtiz-Gomez, Flor G., Lei Lei, Eva Lagunas, Ramon Martinez, Daniele Tarchi, Jorge Querol, Miguel A. Salas-Natera, and Symeon Chatzinotas. 2022. "Machine Learning for Radio Resource Management in Multibeam GEO Satellite Systems" Electronics 11, no. 7: 992. https://doi.org/10.3390/electronics11070992
APA StyleOrtiz-Gomez, F. G., Lei, L., Lagunas, E., Martinez, R., Tarchi, D., Querol, J., Salas-Natera, M. A., & Chatzinotas, S. (2022). Machine Learning for Radio Resource Management in Multibeam GEO Satellite Systems. Electronics, 11(7), 992. https://doi.org/10.3390/electronics11070992