
TextDC: Exploring Multidimensional Text Detection via a New Benchmark and Solution
Abstract
:1. Introduction
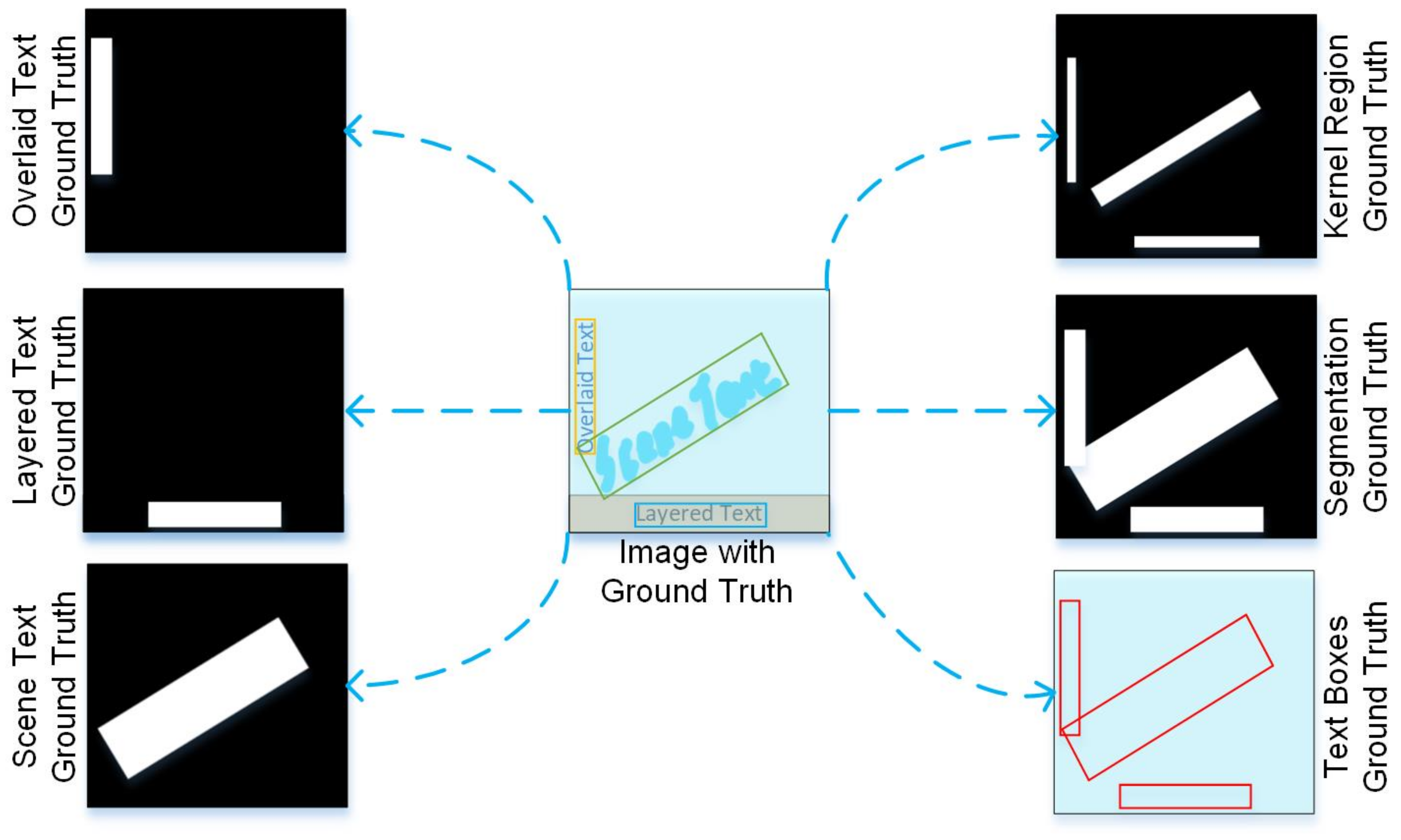
- We establish a large-scale multi-type text detection benchmark, termed Text3C, which consists of 40,340 images, including 595,691 text instances, and addresses the challenges of overlaid text, layered text, and scene text.
- We propose a new task to detect and classify text in images and video frames simultaneously, named TextDC, which can consider the current types of streaming media with multi-view representations.
- We propose a simple and effective solution for the TextDC task. Based on an open text detection and recognition framework, we model the similarities (i.e., backbone and neck stages) while reserving the differences (prediction head) of some state-of-the-art methods, and then modify them by adding category-related feature layers to match the proposed new task.
- Extensive experiments are conducted on the proposed dataset with a multi-stage evaluation protocol to demonstrate the usefulness of the proposed Text3C and its potential to promote community research.
2. Related Work
2.1. Benchmarks
2.2. Methods
3. Text3C Benchmarks
3.1. Collection
3.2. Annotation
3.3. Analysis
3.4. Comparison
3.5. Evaluation Protocol
4. The Proposed Method
4.1. Generalized Network Architecture
4.2. Classification Head
4.3. Training and Inference
4.4. Loss Function
4.5. Label Generation
5. Experiments
5.1. Experiment Settings
5.2. Metrics
5.3. Performance Comparisons for Text Detection
5.4. Performance Comparisons for Text Detection and Classification
5.5. Visualization Comparison
5.6. Joint Analysis
6. Limitation and Discussion
6.1. Limitation Analysis
6.2. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ye, Q.; Doermann, D.S. Text Detection and Recognition in Imagery: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1480–1500. [Google Scholar] [CrossRef] [PubMed]
- Yin, X.; Zuo, Z.; Tian, S.; Liu, C. Text Detection, Tracking and Recognition in Video: A Comprehensive Survey. IEEE Trans. Image Process. 2016, 25, 2752–2773. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Yao, C.; Bai, X. Scene text detection and recognition: Recent advances and future trends. Front. Comput. Sci. 2016, 10, 19–36. [Google Scholar] [CrossRef]
- Long, S.; He, X.; Yao, C. Scene Text Detection and Recognition: The Deep Learning Era. Int. J. Comput. Vis. 2021, 129, 161–184. [Google Scholar] [CrossRef]
- Tian, S.; Yin, X.; Su, Y.; Hao, H. A Unified Framework for Tracking Based Text Detection and Recognition from Web Videos. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 542–554. [Google Scholar] [CrossRef] [PubMed]
- Zayene, O.; Hennebert, J.; Touj, S.M.; Ingold, R.; Amara, N.E.B. A dataset for Arabic text detection, tracking and recognition in news videos- AcTiV. In Proceedings of the International Conference on Document Analysis and Recognition, Tunis, Tunisia, 23–26 August 2015; pp. 996–1000. [Google Scholar]
- Karatzas, D.; Gomez-Bigorda, L.; Nicolaou, A.; Ghosh, S.K.; Bagdanov, A.D.; Iwamura, M.; Matas, J.; Neumann, L.; Chandrasekhar, V.R.; Lu, S.; et al. ICDAR 2015 competition on Robust Reading. In Proceedings of the International Conference on Document Analysis and Recognition, Tunis, Tunisia, 23–26 August 2015; pp. 1156–1160. [Google Scholar]
- Karatzas, D.; Mestre, S.R.; Mas, J.; Nourbakhsh, F.; Roy, P.P. ICDAR 2011 Robust Reading Competition—Challenge 1: Reading Text in Born-Digital Images (Web and Email). In Proceedings of the International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 1485–1490. [Google Scholar]
- Karatzas, D.; Shafait, F.; Uchida, S.; Iwamura, M.; i Bigorda, L.G.; Mestre, S.R.; Mas, J.; Mota, D.F.; Almazán, J.; de las Heras, L. ICDAR 2013 Robust Reading Competition. In Proceedings of the International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1484–1493. [Google Scholar]
- Wang, K.; Belongie, S.J. Word Spotting in the Wild. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6311, pp. 591–604. [Google Scholar]
- Wang, K.; Babenko, B.; Belongie, S.J. End-to-end scene text recognition. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1457–1464. [Google Scholar]
- Cai, Y.; Wang, W.; Huang, S.; Ma, J.; Lu, K. Spatiotemporal text localization for videos. Multimed. Tools Appl. 2018, 77, 29323–29345. [Google Scholar] [CrossRef]
- Veit, A.; Matera, T.; Neumann, L.; Matas, J.; Belongie, S.J. COCO-Text: Dataset and Benchmark for Text Detection and Recognition in Natural Images. arXiv 2016, arXiv:1601.07140. [Google Scholar]
- Yuan, T.; Zhu, Z.; Xu, K.; Li, C.; Mu, T.; Hu, S. A Large Chinese Text Dataset in the Wild. J. Comput. Sci. Technol. 2019, 34, 509–521. [Google Scholar] [CrossRef]
- Nayef, N.; Yin, F.; Bizid, I.; Choi, H.; Feng, Y.; Karatzas, D.; Luo, Z.; Pal, U.; Rigaud, C.; Chazalon, J.; et al. ICDAR2017 Robust Reading Challenge on Multi-Lingual Scene Text Detection and Script Identification—RRC-MLT. In Proceedings of the International Conference on Document Analysis and Recognition, Kyoto, Japan, 9–15 November 2017; pp. 1454–1459. [Google Scholar]
- Nayef, N.; Liu, C.; Ogier, J.; Patel, Y.; Busta, M.; Chowdhury, P.N.; Karatzas, D.; Khlif, W.; Matas, J.; Pal, U.; et al. ICDAR2019 Robust Reading Challenge on Multi-lingual Scene Text Detection and Recognition—RRC-MLT-2019. In Proceedings of the International Conference on Document Analysis and Recognition, Sydney, NSW, Australia, 20–25 September 2019; pp. 1582–1587. [Google Scholar]
- Sun, Y.; Liu, J.; Liu, W.; Han, J.; Ding, E.; Liu, J. Chinese Street View Text: Large-Scale Chinese Text Reading With Partially Supervised Learning. In Proceedings of the International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9085–9094. [Google Scholar]
- Ch’ng, C.K.; Chan, C.S.; Liu, C. Total-Text: Towards Orientation Robustness in Scene Text Detection. Int. J. Doc. Anal. Recognit. (IJDAR) 2020, 23, 31–52. [Google Scholar] [CrossRef]
- Liu, Y.; Jin, L.; Zhang, S.; Luo, C.; Zhang, S. Curved scene text detection via transverse and longitudinal sequence connection. Pattern Recognit. 2019, 90, 337–345. [Google Scholar] [CrossRef]
- Chng, C.K.; Ding, E.; Liu, J.; Karatzas, D.; Chan, C.S.; Jin, L.; Liu, Y.; Sun, Y.; Ng, C.C.; Luo, C.; et al. ICDAR2019 Robust Reading Challenge on Arbitrary-Shaped Text—RRC-ArT. In Proceedings of the International Conference on Document Analysis and Recognition, Sydney, NSW, Australia, 20–25 September 2019; pp. 1571–1576. [Google Scholar]
- Zayene, O.; Seuret, M.; Touj, S.M.; Hennebert, J.; Ingold, R.; Amara, N.E.B. Text Detection in Arabic News Video Based on SWT Operator and Convolutional Auto-Encoders. In Proceedings of the IAPR Workshop on Document Analysis Systems, Santorini, Greece, 11–14 April 2016; pp. 13–18. [Google Scholar]
- Liu, X.; Wang, W. Extracting captions from videos using temporal feature. In Proceedings of the 18th International Conference on Multimedia 2010, Firenze, Italy, 25–29 October 2010; pp. 843–846. [Google Scholar]
- Liu, X.; Wang, W. Robustly Extracting Captions in Videos Based on Stroke-Like Edges and Spatio-Temporal Analysis. IEEE Trans. Multim. 2012, 14, 482–489. [Google Scholar] [CrossRef]
- Shivakumara, P.; Phan, T.Q.; Tan, C.L. A Laplacian Approach to Multi-Oriented Text Detection in Video. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 412–419. [Google Scholar] [CrossRef] [PubMed]
- Fang, S.; Xie, H.; Chen, Z.; Zhu, S.; Gu, X.; Gao, X. Detecting Uyghur text in complex background images with convolutional neural network. Multim. Tools Appl. 2017, 76, 15083–15103. [Google Scholar] [CrossRef]
- Cai, Y.; Wang, W. Robustly detect different types of text in videos. Neural Comput. Appl. 2020, 32, 12827–12840. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Liao, M.; Shi, B.; Bai, X.; Wang, X.; Liu, W. TextBoxes: A Fast Text Detector with a Single Deep Neural Network. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4161–4167. [Google Scholar]
- Liao, M.; Zhu, Z.; Shi, B.; Xia, G.; Bai, X. Rotation-Sensitive Regression for Oriented Scene Text Detection. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5909–5918. [Google Scholar]
- Lyu, P.; Yao, C.; Wu, W.; Yan, S.; Bai, X. Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7553–7563. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature Pyramid Networks for Object Detection. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Wan, Q.; Ji, H.; Shen, L. Self-Attention Based Text Knowledge Mining for Text Detection. In Proceedings of the Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5983–5992. [Google Scholar]
- Zhang, S.; Zhu, X.; Yang, C.; Wang, H.; Yin, X. Adaptive Boundary Proposal Network for Arbitrary Shape Text Detection. In Proceedings of the International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 1285–1294. [Google Scholar]
- Cai, Y.; Liu, C.; Cheng, P.; Du, D.; Zhang, L.; Wang, W.; Ye, Q. Scale-Residual Learning Network for Scene Text Detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 2725–2738. [Google Scholar] [CrossRef]
- Cai, Y.; Wang, W.; Chen, Y.; Ye, Q. IOS-Net: An inside-to-outside supervision network for scale robust text detection in the wild. Pattern Recognit. 2020, 103, 107304. [Google Scholar] [CrossRef]
- Yang, Q.; Cheng, M.; Zhou, W.; Chen, Y.; Qiu, M.; Lin, W. IncepText: A New Inception-Text Module with Deformable PSROI Pooling for Multi-Oriented Scene Text Detection. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 1071–1077. [Google Scholar]
- Tang, J.; Zhang, W.; Liu, H.; Yang, M.; Jiang, B.; Hu, G.; Bai, X. Few Could Be Better Than All: Feature Sampling and Grouping for Scene Text Detection. In Proceedings of the Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4553–4562. [Google Scholar]
- Zhou, X.; Yao, C.; Wen, H.; Wang, Y.; Zhou, S.; He, W.; Liang, J. EAST: An Efficient and Accurate Scene Text Detector. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2642–2651. [Google Scholar]
- Zhu, Y.; Chen, J.; Liang, L.; Kuang, Z.; Jin, L.; Zhang, W. Fourier Contour Embedding for Arbitrary-Shaped Text Detection. In Proceedings of the Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3123–3131. [Google Scholar]
- Wang, F.; Chen, Y.; Wu, F.; Li, X. TextRay: Contour-based Geometric Modeling for Arbitrary-shaped Scene Text Detection. In Proceedings of the ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 111–119. [Google Scholar]
- Liao, M.; Wan, Z.; Yao, C.; Chen, K.; Bai, X. Real-Time Scene Text Detection with Differentiable Binarization. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11474–11481. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Hou, W.; Lu, T.; Yu, G.; Shao, S. Shape Robust Text Detection With Progressive Scale Expansion Network. In Proceedings of the Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9336–9345. [Google Scholar]
- Wang, W.; Xie, E.; Song, X.; Zang, Y.; Wang, W.; Lu, T.; Yu, G.; Shen, C. Efficient and Accurate Arbitrary-Shaped Text Detection With Pixel Aggregation Network. In Proceedings of the International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8439–8448. [Google Scholar]
- Liu, Y.; Chen, H.; Shen, C.; He, T.; Jin, L.; Wang, L. ABCNet: Real-Time Scene Text Spotting With Adaptive Bezier-Curve Network. In Proceedings of the Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9806–9815. [Google Scholar]
- Huang, M.; Liu, Y.; Peng, Z.; Liu, C.; Lin, D.; Zhu, S.; Yuan, N.; Ding, K.; Jin, L. SwinTextSpotter: Scene Text Spotting via Better Synergy between Text Detection and Text Recognition. In Proceedings of the Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4583–4593. [Google Scholar]
- Yao, C.; Bai, X.; Liu, W.; Ma, Y.; Tu, Z. Detecting texts of arbitrary orientations in natural images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1083–1090. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.J.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Long, S.; Ruan, J.; Zhang, W.; He, X.; Wu, W.; Yao, C. TextSnake: A Flexible Representation for Detecting Text of Arbitrary Shapes. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2018; Volume 11206, pp. 19–35. [Google Scholar]
- Zhang, S.; Zhu, X.; Hou, J.; Liu, C.; Yang, C.; Wang, H.; Yin, X. Deep Relational Reasoning Graph Network for Arbitrary Shape Text Detection. In Proceedings of the Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9696–9705. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | #Image/Frame | #Text Instance | Language | Type | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Train | Test | All | Train | Test | All | Chn | Eng | Oth | OT | LT | ST | |
| ICDAR 2013 [9] | 229 | 233 | 462 | 848 | 1095 | 1943 | - | √ | - | - | - | √ |
| ICDAR 2015 [7] | 1000 | 500 | 1500 | 11,886 | 5230 | 17,116 | - | √ | √ | - | - | √ |
| MSRA-TD500 [47] | 300 | 200 | 500 | 1068 | 651 | 1719 | - | √ | - | - | - | √ |
| COCO-Text [13] | 43,686 | 20,000 | 63,686 | 118,309 | 27,550 | 145,859 | - | √ | √ | - | - | √ |
| AcTiV-D [20] | 1480 | 363 | 1843 | 4133 | 1000 | 5133 | - | - | √ | - | √ | - |
| USTB-VidTEXT [5] | 9839 | 17,831 | 27,670 | 14,492 | 27,440 | 41,932 | - | √ | - | √ | - | - |
| UCAS-STLData [12] | 36,564 | 20,506 | 57,070 | 26,837 | 14,358 | 41,195 | - | √ | - | √ | - | - |
| ICDAR 2013 VT [9] | 9790 | 5487 | 15,277 | 67,800 | 26,134 | 93,934 | - | √ | √ | - | - | √ |
| Text3C (Ours) | 29,534 | 10,806 | 40,340 | 396,096 | 199,595 | 595,691 | √ | √ | √ | √ | √ | √ |
| Method | ICDAR15 Protocol | TextDC Protocol | ||||
|---|---|---|---|---|---|---|
| DBNet[42] | 0.747 | 0.249 | 0.374 | 0.439 | 0.147 | 0.220 |
| TextSnake[49] | 0.789 | 0.526 | 0.631 | 0.452 | 0.301 | 0.361 |
| DRRG [50] | 0.761 | 0.569 | 0.651 | 0.488 | 0.312 | 0.381 |
| PAN [44] | 0.783 | 0.608 | 0.685 | 0.440 | 0.312 | 0.365 |
| FCENet [40] | 0.893 | 0.688 | 0.777 | 0.564 | 0.435 | 0.491 |
| PSENet [43] | 0.881 | 0.617 | 0.726 | 0.631 | 0.442 | 0.520 |
| Method | ICDAR15 Protocol | TextDC Protocol | ||||
|---|---|---|---|---|---|---|
| TextDC(DBNet [42]) | 0.507 | 0.169 | 0.254 | 0.320 | 0.107 | 0.160 |
| TextDC(TextSnake [49]) | 0.690 | 0.460 | 0.552 | 0.406 | 0.270 | 0.325 |
| TextDC(DRRG [50]) | 0.646 | 0.482 | 0.552 | 0.425 | 0.272 | 0.332 |
| TextDC(PAN [44]) | 0.694 | 0.539 | 0.606 | 0.399 | 0.283 | 0.331 |
| TextDC(FCENet [40]) | 0.676 | 0.521 | 0.588 | 0.433 | 0.333 | 0.377 |
| TextDC(PSENet [43]) | 0.790 | 0.553 | 0.651 | 0.576 | 0.403 | 0.474 |
| Method | Epoch | Backbone | |||
|---|---|---|---|---|---|
| TextDC(DBNet [42]) | 30 | ResNet50 | 0.160 | 0.784 | 11.1 |
| TextDC(TextSnake [49]) | 30 | ResNet50 | 0.325 | 0.923 | 2.1 |
| TextDC(DRRG [50]) | 30 | ResNet50 | 0.332 | 0.845 | 3.1 |
| TextDC(PAN [44]) | 30 | ResNet50 | 0.331 | 0.907 | 39.6 |
| TextDC(FCENet [40]) | 30 | ResNet50 | 0.377 | 0.805 | 21.6 |
| TextDC(PSENet [43]) | 30 | ResNet50 | 0.474 | 0.920 | 6.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, F.; Cai, Y.; Tian, Y. TextDC: Exploring Multidimensional Text Detection via a New Benchmark and Solution. Electronics 2023, 12, 159. https://doi.org/10.3390/electronics12010159
Zhou F, Cai Y, Tian Y. TextDC: Exploring Multidimensional Text Detection via a New Benchmark and Solution. Electronics. 2023; 12(1):159. https://doi.org/10.3390/electronics12010159
Chicago/Turabian StyleZhou, Fenfen, Yuanqiang Cai, and Yingjie Tian. 2023. "TextDC: Exploring Multidimensional Text Detection via a New Benchmark and Solution" Electronics 12, no. 1: 159. https://doi.org/10.3390/electronics12010159