
InfoMax Classification-Enhanced Learnable Network for Few-Shot Node Classification


Abstract
:1. Introduction
- •
- A new few-shot node classification framework (ICELN) is proposed, where we emphasize learning task-specific classifiers from a limited number of labeled nodes and transfer the discriminative class characteristics to unlabeled nodes. The ICELN is able to explore the limited number of support nodes to achieve a better generalization ability.
- •
- We explore the effectiveness of the mutual information maximization principle in node representation learning. By increasing the amount of mutual information shared between the known class representation and the corresponding node representation, the most representative features and information can be transferred, enhancing the node representation learning.
- •
- To demonstrate the effectiveness of the ICELN, we test it using a broad range of datasets derived from the actual world and conduct a number of intensive experiments. The experiments show that the ICELN achieves competitive performance on several challenging few-shot node classification datasets.
2. Related Works
2.1. Graph Representation Learning
2.2. Few-Shot Learning
2.3. Mutual Information Maximization
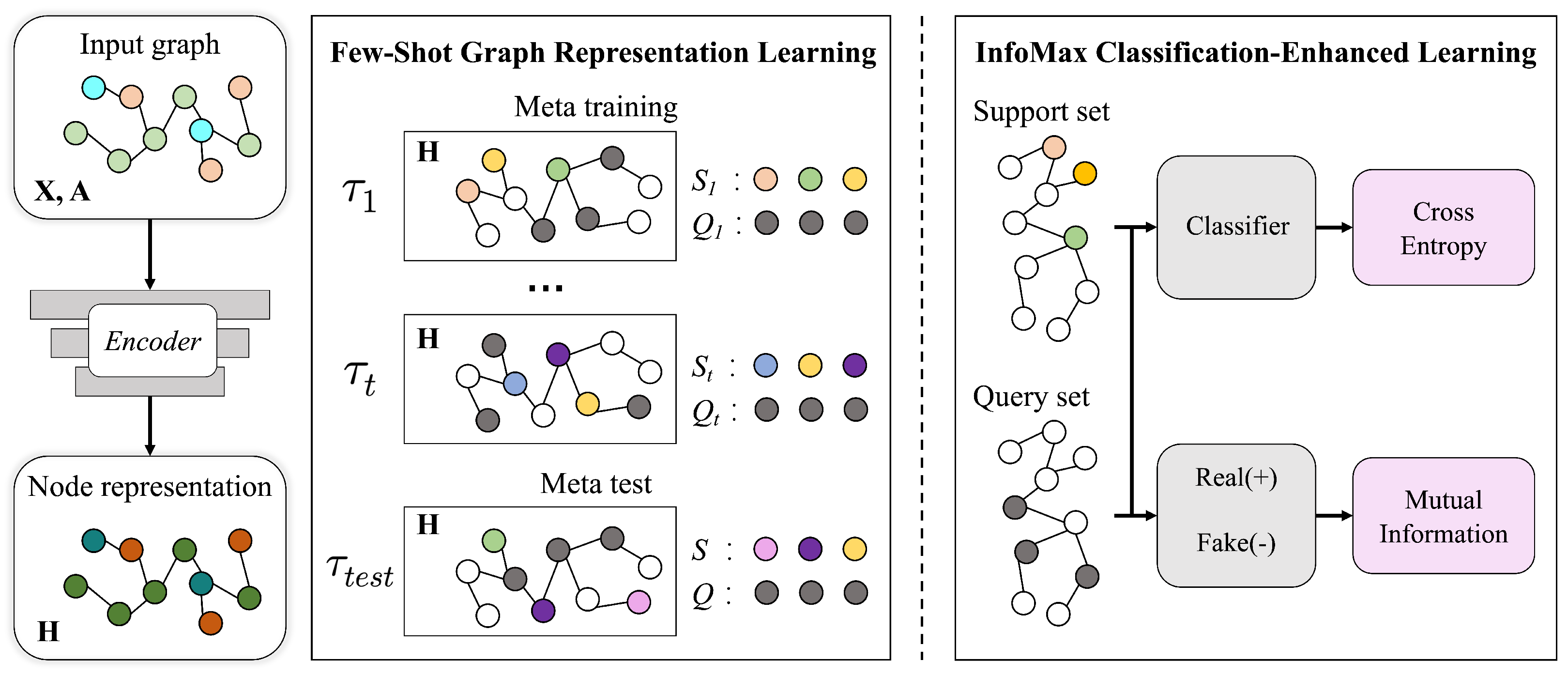
3. The Proposed Method
3.1. Notation and Problem Definition
3.2. Few-Shot Graph Representation Learning
- •
- How to conduct meta-learning on graph structure data and how to extract information that can be transferred from the training data to testing data when there are only a handful of labeled nodes available.
- •
- How to make the most of the limited number of nodes that are available in the support set and restrict the query set to obtain informative and discriminative representations?
3.3. InfoMax Classification-Enhanced Learning
| Algorithm 1: The detailed ICELN learning framework for few-shot node classification. |
 |
4. Experiments and Analysis
4.1. Datasets
- •
- Cora [30] and CiteSeer [30] are two similar datasets related to machine learning topics. Their networks are built with the paper citation relation and attached with different words describing the papers’ information. There are seven subcategories and six subcategories in Cora and CiteSeer, respectively.
- •
- DBLP [31] is also a citation network which was taken from “DBLP dataset (version v11)”. The network is linked with the papers’ citation relation, and the nodes’ attributed information comes from the papers’ abstract information. The node class labels represent the locations of the paper’s presentations.
- •
- Amazon-Clothing [32] is known as a product network built on Amazon (https://www.amazon.com/, accessed on 12 December 2022, Amazon review dataset released in 2014). This dataset was first generated in [32], and in [3], the authors preprocessed this dataset so that it could be used in the few-shot problem. The network’s nodes are individual goods that are categorized under the heading of “Clothing, Shoes and Jewelry” on Amazon, and the edges are the “also reviewed” relationship between two products. The labels of the nodes represent the lower-level classifications of the products. The attributed information for a node is the description of a product.
- •
- Amazon-Electronics [32] is another Amazon product network analogy to Amazon-Clothing. Nodes in this dataset are products belonging to “Electronics”. The nodes’ attributed information and labels are created in the same way as in Amazon-Clothing. However, the edges are created with a complementary relationship “bought together” between two products.
4.2. Evaluation Metrics
4.3. Compared Methods
- •
- DeepWalk [33] acquires the node embedding by making use of the local data obtained through a truncated random walk around the graph.
- •
- Node2vec [34] extends DeepWalk. With a given node, its diverse neighborhoods are explored, and the random walk then becomes biased.
- •
- GCN [10] uses the spectral graph convolution as the basis for obtaining node representations. The graph’s topology information and nodes’ features are aggregated and passed through the layer-wise propagation pipeline.
- •
- SGC [13] follows the learning paradigm of the GCN while simplifying the extra complexity of the convolution function. There are no nonlinearities and collapsing weight matrices between the layers that boost the training process.
- •
- PN [19] presents a metric-based space for meta-learning. The prototypes learned from the encoder are used for distance computing when performing classification in a limited-data regime.
- •
- MAML [14] is known as a general optimization-based meta-learning framework. It is model-agnostic and can be expanded with a number of similar meta-training tasks beyond classification problems. The universal model may easily be fine-tuned to accommodate new unseen tasks within only a few simple stages of optimization.
- •
- Meta-GNN [1] proposes a meta-learning approach as a solution for the few-shot node classification problem. It is trained and optimized based on the training paradigm of MAML, and the classification is learned based on the parameter initialization of GNNs.
- •
- GPN [3] combines the training strategy from Meta-GNN and the idea of prototypes from PN to generate class prototypes as anchors to perform node classification tasks on attributed graphs. This semi-supervised model generalized well in testing scenarios.
4.4. Experimental Settings
4.5. Performance Comparison
- •
- On each of the five datasets, our proposed ICELN delivered performance that was competitive for the few-shot node classification tasks. The high accuracies and F1 scores demonstrate that the ICELN was able to extract the meta-knowledge across diverse tasks and could achieve a better generalization ability in unseen target tasks. In general, the classification accuracies of the ICELN outperformed the most comparative method (GPN) by 12.7% under the 5-way 3-shot task on Amazon-Electronics.
- •
- We found that the accuracies and F1 scores of DeepWalk and Node2vec were not at the same level as other methods. These two random walk-based methods are supervised and rely largely on sufficient training samples to obtain good node representations. Meanwhile, the GCN and SGC are GNN-based models and use an end-to-end training paradigm, which fluctuates in different task settings. The fact that standard GNN models are susceptible to overfitting when the training instances are restricted to a small number and tasks are distinct from one another demonstrates the requirement for a meta-learning architecture for the low-data challenge.
- •
- Classic meta-learning approaches such as PN and MAML provided results that performed pretty well when used for the classification of few-shot images, while they were only passable for few-shot node classification. Images and graphs are inherently different, and the nodes’ correlation and attributed features are the most crucial information during graph learning. Thus, these two models failed to characterize the topological and semantic information, resulting in unsatisfactory performance.
- •
- Both the Meta-GNN and the GPN are two correlative approaches that were developed for the few-shot node classification problem. They are capable of achieving significant gains in comparison with other baselines. Meta-GNN is an optimization-based model that needs to be fine-tuned on target tasks. The GPN learns the informative prototypes for each class while neglecting to pass the support set’s class-specific information to the query set. However, by taking full advantage of the handful support set and performing InfoMax classification-enhanced learning, the proposed ICELN was capable of providing better results than these baselines in the majority of situations.
- •
- The following are some of the reasons why the proposed ICELN was successful in achieving outstanding results in few-shot node classification: (1) The ICELN trains a task-specific classifier with the finite support set nodes and successfully passes this valid information to the query set nodes. (2) The ICELN maximizes the information transferred from the support class representation to the query nodes representation, which in turn improves the learning ability of the node representation.
4.6. Parameter Analysis
4.7. Ablation Study
4.8. Visualization
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, F.; Cao, C.; Zhang, K.; Trajcevski, G.; Zhong, T.; Geng, J. Meta-gnn: On few-shot node classification in graph meta-learning. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2357–2360. [Google Scholar]
- Wang, N.; Luo, M.; Ding, K.; Zhang, L.; Li, J.; Zheng, Q. Graph Few-shot Learning with Attribute Matching. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual, 19–23 October 2020; pp. 1545–1554. [Google Scholar]
- Ding, K.; Wang, J.; Li, J.; Shu, K.; Liu, C.; Liu, H. Graph prototypical networks for few-shot learning on attributed networks. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual, 19–23 October 2020; pp. 295–304. [Google Scholar]
- Cai, H.; Zheng, V.W.; Chang, K.C.C. A comprehensive survey of graph embedding: Problems, techniques, and applications. IEEE Trans. Knowl. Data Eng. 2018, 30, 1616–1637. [Google Scholar] [CrossRef] [Green Version]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive representation learning on large graphs. arXiv 2017, arXiv:1706.02216. [Google Scholar]
- Fan, W.; Ma, Y.; Li, Q.; He, Y.; Zhao, E.; Tang, J.; Yin, D. Graph neural networks for social recommendation. In Proceedings of the the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 417–426. [Google Scholar]
- Song, W.; Xiao, Z.; Wang, Y.; Charlin, L.; Zhang, M.; Tang, J. Session-based social recommendation via dynamic graph attention networks. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, VIC, Australia, 11–15 February 2019; pp. 555–563. [Google Scholar]
- Yu, W.; Yu, M.; Zhao, T.; Jiang, M. Identifying referential intention with heterogeneous contexts. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 962–972. [Google Scholar]
- Zhao, T.; Ni, B.; Yu, W.; Jiang, M. Early anomaly detection by learning and forecasting behavior. arXiv 2020, arXiv:2010.10016. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the 6th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How powerful are graph neural networks? arXiv 2018, arXiv:1810.00826. [Google Scholar]
- Wu, F.; Souza, A.; Zhang, T.; Fifty, C.; Yu, T.; Weinberger, K. Simplifying graph convolutional networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6861–6871. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Ravi, S.; Larochelle, H. Optimization as a model for few-shot learning. In Proceedings of the 5th International Conference on Learning Representations, ICLR, Toulon, France, 24–26 April 2017. (Oral). [Google Scholar]
- Li, Z.; Zhou, F.; Chen, F.; Li, H. Meta-sgd: Learning to learn quickly for few-shot learning. arXiv 2017, arXiv:1707.09835. [Google Scholar]
- Mishra, N.; Rohaninejad, M.; Chen, X.; Abbeel, P. A Simple Neural Attentive Meta-Learner. In Proceedings of the 6th International Conference on Learning Representation, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. Adv. Neural Inf. Process. Syst. 2016, 29, 3630–3638. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical networks for few-shot learning. arXiv 2017, arXiv:1703.05175. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar]
- Belghazi, M.I.; Baratin, A.; Rajeswar, S.; Ozair, S.; Bengio, Y.; Courville, A.; Hjelm, R.D. Mine: Mutual information neural estimation. arXiv 2018, arXiv:1801.04062. [Google Scholar]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hjelm, R.D.; Fedorov, A.; Lavoie-Marchildon, S.; Grewal, K.; Bachman, P.; Trischler, A.; Bengio, Y. Learning deep representations by mutual information estimation and maximization. arXiv 2018, arXiv:1808.06670. [Google Scholar]
- Velickovic, P.; Fedus, W.; Hamilton, W.L.; Liò, P.; Bengio, Y.; Hjelm, R.D. Deep Graph Infomax. ICLR Poster 2019, 2, 4. [Google Scholar]
- Sun, F.Y.; Hoffmann, J.; Verma, V.; Tang, J. Infograph: Unsupervised and semi-supervised graph-level representation learning via mutual information maximization. arXiv 2019, arXiv:1908.01000. [Google Scholar]
- Mavromatis, C.; Karypis, G. Graph infoclust: Leveraging cluster-level node information for unsupervised graph representation learning. arXiv 2020, arXiv:2009.06946. [Google Scholar]
- Park, C.; Han, J.; Yu, H. Deep multiplex graph infomax: Attentive multiplex network embedding using global information. Knowl.-Based Syst. 2020, 197, 105861. [Google Scholar] [CrossRef]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 6–11 July 2015; Volume 2. [Google Scholar]
- Linsker, R. Self-organization in a perceptual network. Computer 1988, 21, 105–117. [Google Scholar] [CrossRef]
- Sen, P.; Namata, G.; Bilgic, M.; Getoor, L.; Galligher, B.; Eliassi-Rad, T. Collective classification in network data. AI Mag. 2008, 29, 93. [Google Scholar] [CrossRef]
- Tang, J.; Zhang, J.; Yao, L.; Li, J.; Zhang, L.; Su, Z. Arnetminer: Extraction and mining of academic social networks. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2009; pp. 990–998. [Google Scholar]
- McAuley, J.; Pandey, R.; Leskovec, J. Inferring networks of substitutable and complementary products. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 785–794. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | No. of Nodes | No. of Edges | No. of Attributes | No. of Labels |
|---|---|---|---|---|
| Cora | 2708 | 5429 | 1433 | 7 |
| CiteSeer | 3327 | 4732 | 3703 | 6 |
| DBLP | 40,672 | 288,270 | 7202 | 41 |
| Amazon-Clothing | 24,919 | 91,680 | 9034 | 77 |
| Amazon-Electronics | 42,318 | 43,556 | 8669 | 167 |
| Cora | CiteSeer | |||
|---|---|---|---|---|
| Methods | 2-Way 1-Shot | 2-Way 3-Shot | 2-Way 1-Shot | 2-Way 3-Shot |
| ACC | ACC | ACC | ACC | |
| DeepWalk | 16.1 | 25.7 | 14.5 | 21.2 |
| Node2vec | 15.2 | 25.7 | 13.0 | 20.0 |
| GCN | 60.3 | 75.2 | 58.4 | 68.0 |
| SGC | 61.6 | 75.7 | 56.9 | 65.7 |
| PN | 56.2 | 63.5 | 54.3 | 58.4 |
| MAML | 58.3 | 68.2 | 56.9 | 62.8 |
| Meta-GNN | 65.3 | 77.2 | 61.9 | 69.4 |
| GPN | 64.3 | 67.5 | 62.2 | 64.2 |
| ICELN | 71.4 | 81.9 | 67.6 | 72.9 |
| DBLP | ||||||||
|---|---|---|---|---|---|---|---|---|
| Methods | 5-Way 3-Shot | 5-Way 5-Shot | 10-Way 3-Shot | 10-Way 5-Shot | ||||
| ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | |
| DeepWalk | 44.7 | 43.1 | 62.4 | 60.4 | 33.8 | 30.8 | 45.1 | 43.0 |
| Node2vec | 40.7 | 38.5 | 58.6 | 57.2 | 31.5 | 27.8 | 41.2 | 39.6 |
| GCN | 59.6 | 54.9 | 68.3 | 66.0 | 43.9 | 39.0 | 51.2 | 47.6 |
| SGC | 57.3 | 55.2 | 65.0 | 62.1 | 40.2 | 36.8 | 50.3 | 46.4 |
| PN | 37.2 | 36.7 | 43.4 | 44.3 | 26.2 | 26.0 | 32.6 | 32.8 |
| MAML | 39.7 | 39.7 | 45.5 | 43.7 | 30.8 | 25.3 | 34.7 | 31.2 |
| Meta-GNN | 70.9 | 70.3 | 78.2 | 78.2 | 60.7 | 60.4 | 68.1 | 67.2 |
| GPN | 74.5 | 73.9 | 80.1 | 79.8 | 62.6 | 62.6 | 69.0 | 69.4 |
| ICELN | 76.8 | 75.7 | 82.9 | 82.5 | 63.4 | 62.6 | 70.8 | 69.9 |
| Amazon-Clothing | ||||||||
|---|---|---|---|---|---|---|---|---|
| Methods | 5-Way 3-Shot | 5-Way 5-Shot | 10-Way 3-Shot | 10-Way 5-Shot | ||||
| ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | |
| DeepWalk | 36.7 | 36.3 | 46.5 | 46.6 | 21.3 | 19.1 | 35.3 | 32.9 |
| Node2vec | 36.2 | 35.8 | 31.9 | 40.7 | 17.5 | 15.1 | 32.6 | 30.2 |
| GCN | 54.3 | 51.4 | 59.3 | 56.6 | 41.3 | 37.5 | 44.8 | 40.3 |
| SGC | 56.8 | 55.2 | 62.2 | 61.5 | 43.1 | 41.6 | 46.3 | 44.7 |
| PN | 53.7 | 53.6 | 63.5 | 63.7 | 41.5 | 41.9 | 44.8 | 46.2 |
| MAML | 55.2 | 54.5 | 66.1 | 67.8 | 43.3 | 46.8 | 45.6 | 53.3 |
| Meta-GNN | 74.1 | 73.6 | 77.3 | 77.5 | 61.4 | 59.7 | 64.2 | 62.9 |
| GPN | 75.4 | 74.7 | 78.6 | 79.0 | 65.0 | 66.1 | 67.7 | 68.9 |
| ICELN | 77.0 | 75.8 | 82.1 | 81.4 | 67.2 | 66.2 | 71.0 | 70.0 |
| Amazon-Electronics | ||||||||
|---|---|---|---|---|---|---|---|---|
| Methods | 5-Way 3-Shot | 5-Way 5-Shot | 10-Way 3-Shot | 10-Way 5-Shot | ||||
| ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | |
| DeepWalk | 23.5 | 22.2 | 26.1 | 25.7 | 14.7 | 12.9 | 16.0 | 14.7 |
| Node2vec | 25.5 | 23.7 | 27.1 | 24.3 | 15.1 | 13.1 | 17.7 | 15.5 |
| GCN | 53.8 | 49.8 | 59.6 | 55.3 | 42.4 | 38.4 | 47.4 | 48.3 |
| SGC | 54.6 | 53.4 | 60.8 | 59.4 | 43.2 | 41.5 | 50.0 | 47.6 |
| PN | 53.5 | 55.6 | 59.7 | 61.5 | 39.9 | 40.0 | 45.0 | 44.8 |
| MAML | 52.1 | 59.0 | 58.3 | 37.4 | 36.1 | 43.4 | 43.4 | 41.4 |
| Meta-GNN | 63.2 | 61.5 | 67.9 | 66.8 | 58.2 | 55.8 | 60.8 | 60.1 |
| GPN | 64.6 | 62.9 | 70.9 | 70.6 | 60.3 | 60.7 | 62.4 | 63.7 |
| ICELN | 77.3 | 76.8 | 82.9 | 82.5 | 63.4 | 62.6 | 70.8 | 69.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, X.; Du, J.; Song, J.; Xue, Z. InfoMax Classification-Enhanced Learnable Network for Few-Shot Node Classification. Electronics 2023, 12, 239. https://doi.org/10.3390/electronics12010239
Xu X, Du J, Song J, Xue Z. InfoMax Classification-Enhanced Learnable Network for Few-Shot Node Classification. Electronics. 2023; 12(1):239. https://doi.org/10.3390/electronics12010239
Chicago/Turabian StyleXu, Xin, Junping Du, Jie Song, and Zhe Xue. 2023. "InfoMax Classification-Enhanced Learnable Network for Few-Shot Node Classification" Electronics 12, no. 1: 239. https://doi.org/10.3390/electronics12010239
APA StyleXu, X., Du, J., Song, J., & Xue, Z. (2023). InfoMax Classification-Enhanced Learnable Network for Few-Shot Node Classification. Electronics, 12(1), 239. https://doi.org/10.3390/electronics12010239