
Intelligent Distributed Swarm Control for Large-Scale Multi-UAV Systems: A Hierarchical Learning Approach


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
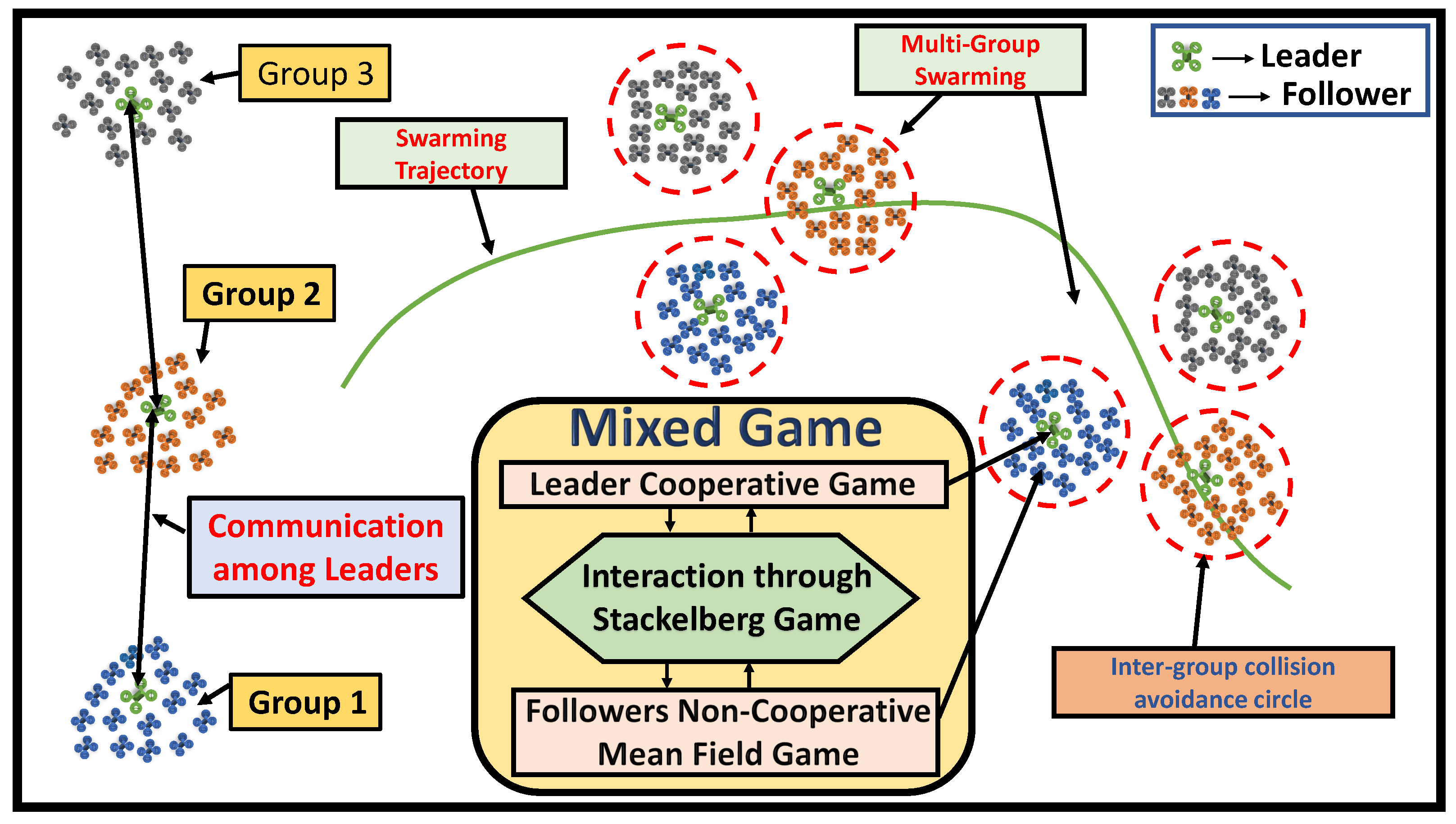
- A novel mixed game theory is developed with cooperative leaders and non-cooperative followers in order to achieve multi-group optimal swarming control which addresses the challenge of the curse of dimensionality and unrealistic communication.
- A hierarchical learning structure with actor–critic-based, leader-distributed swarming and actor–critic–mass-based, large-scale followers decentralized swarming is implemented in real time to learn the solution of the overall intelligent optimal swarming control.
2. Significance of Mixed Game Theory-Based Intelligent Distributed Swarm Control
3. Problem Formulation
3.1. Multi-Group Optimal Swarming Control Formulation
3.2. Mixed Game Theory-Based Multi-Group, Large-Scale Leader–Follower-Distributed Optimal Swarming Control
4. Hierarchical Learning-Based Intelligent Optimal Distributed Swarming Control
4.1. Hierarchical Learning-Based Control for Multi-Group Leader–Follower Systems
4.2. Optimal Swarming Control Performance Analysis
5. Simulation Results
5.1. Performance Evaluation of Mixed Game Theory-Based Intelligent Distributed Swarm Control
5.2. Performance Comparison of Mixed Game Theory against Traditional Cooperative Control
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Proof of Theorem 1
Appendix B. Proof of Theorem 2
Appendix C. Proof of Theorem 3
Appendix D. Proof of Theorem 4
References
- Topaz, C.M.; Bertozzi, A.L. Swarming patterns in a two-dimensional kinematic model for biological groups. SIAM J. Appl. Math. 2004, 65, 152–174. [Google Scholar] [CrossRef]
- Okubo, A. Dynamical aspects of animal grouping: Swarms, schools, flocks, and herds. Adv. Biophys. 1986, 22, 1–94. [Google Scholar] [CrossRef] [PubMed]
- Toner, J.; Tu, Y. Flocks, herds, and schools: A quantitative theory of flocking. Phys. Rev. E 1998, 58, 4828. [Google Scholar] [CrossRef] [Green Version]
- Kube, C.R.; Bonabeau, E. Cooperative transport by ants and robots. Robot. Auton. Syst. 2000, 30, 85–101. [Google Scholar] [CrossRef]
- Li, W.; Shen, W. Swarm behavior control of mobile multi-robots with wireless sensor networks. J. Netw. Comput. Appl. 2011, 34, 1398–1407. [Google Scholar] [CrossRef]
- Cao, L.; Cai, Y.; Yue, Y. Swarm intelligence-based performance optimization for mobile wireless sensor networks: Survey, challenges, and future directions. IEEE Access 2019, 7, 161524–161553. [Google Scholar] [CrossRef]
- Berman, S.; Halász, A.; Hsieh, M.A.; Kumar, V. Optimized stochastic policies for task allocation in swarms of robots. IEEE Trans. Robot. 2009, 25, 927–937. [Google Scholar] [CrossRef] [Green Version]
- Bayındır, L. A review of swarm robotics tasks. Neurocomputing 2016, 172, 292–321. [Google Scholar] [CrossRef]
- Jevtic, A.; Gutiérrez, A.; Andina, D.; Jamshidi, M. Distributed bees algorithm for task allocation in swarm of robots. IEEE Syst. J. 2011, 6, 296–304. [Google Scholar] [CrossRef] [Green Version]
- Engelen, S.; Gill, E.; Verhoeven, C. On the reliability, availability, and throughput of satellite swarms. IEEE Trans. Aerosp. Electron. Syst. 2014, 50, 1027–1037. [Google Scholar] [CrossRef]
- Xu, D.; Zhang, X.; Zhu, Z.; Chen, C.; Yang, P. Behavior-based formation control of swarm robots. Math. Probl. Eng. 2014, 2014, 205759. [Google Scholar] [CrossRef] [Green Version]
- Soni, A.; Hu, H. Formation control for a fleet of autonomous ground vehicles: A survey. Robotics 2018, 7, 67. [Google Scholar] [CrossRef] [Green Version]
- Tahir, A.; Böling, J.; Haghbayan, M.H.; Toivonen, H.T.; Plosila, J. Swarms of unmanned aerial vehicles—A survey. J. Ind. Inf. Integr. 2019, 16, 100106. [Google Scholar] [CrossRef]
- Zhu, B.; Xie, L.; Han, D. Recent developments in control and optimization of swarm systems: A brief survey. In Proceedings of the 2016 12th IEEE international conference on control and automation (ICCA), Kathmandu, Nepal, 1–3 June 2016; pp. 19–24. [Google Scholar]
- Lan, X.; Liu, Y.; Zhao, Z. Cooperative control for swarming systems based on reinforcement learning in unknown dynamic environment. Neurocomputing 2020, 410, 410–418. [Google Scholar] [CrossRef]
- Skobelev, P.; Budaev, D.; Gusev, N.; Voschuk, G. Designing multi-agent swarm of uav for precise agriculture. In Proceedings of the International Conference on Practical Applications of Agents and Multi-Agent Systems, Toledo, Spain, 20–22 June 2018; pp. 47–59. [Google Scholar]
- Kada, B.; Khalid, M.; Shaikh, M.S. Distributed cooperative control of autonomous multi-agent UAV systems using smooth control. J. Syst. Eng. Electron. 2020, 31, 1297–1307. [Google Scholar] [CrossRef]
- Xia, Z.; Du, J.; Wang, J.; Jiang, C.; Ren, Y.; Li, G.; Han, Z. Multi-Agent Reinforcement Learning Aided Intelligent UAV Swarm for Target Tracking. IEEE Trans. Veh. Technol. 2022, 71, 931–945. [Google Scholar] [CrossRef]
- Zhao, W.; Chu, H.; Zhang, M.; Sun, T.; Guo, L. Flocking control of fixed-wing UAVs with cooperative obstacle avoidance capability. IEEE Access 2019, 7, 17798–17808. [Google Scholar] [CrossRef]
- Zhou, Z.; Xu, H. A Novel Mean-Field-Game-Type Optimal Control for Very Large-Scale Multiagent Systems. IEEE Trans. Cybern. 2022, 52, 5197–5208. [Google Scholar] [CrossRef]
- Mehlfuhrer, C.; Caban, S.; Rupp, M. Cellular system physical layer throughput: How far off are we from the Shannon bound? IEEE Wirel. Commun. 2011, 18, 54–63. [Google Scholar] [CrossRef]
- Branzei, R.; Dimitrov, D.; Tijs, S. Models in Cooperative Game Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008; Volume 556. [Google Scholar]
- Gulzar, M.M.; Rizvi, S.T.H.; Javed, M.Y.; Munir, U.; Asif, H. Multi-agent cooperative control consensus: A comparative review. Electronics 2018, 7, 22. [Google Scholar] [CrossRef]
- Zhou, Z.; Xu, H. Decentralized Adaptive Optimal Tracking Control for Massive Autonomous Vehicle Systems With Heterogeneous Dynamics: A Stackelberg Game. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 5654–5663. [Google Scholar] [CrossRef]
- Yu, M.; Hong, S.H. A Real-Time Demand-Response Algorithm for Smart Grids: A Stackelberg Game Approach. IEEE Trans. Smart Grid 2016, 7, 879–888. [Google Scholar] [CrossRef]
- Cardaliaguet, P.; Porretta, A. An introduction to mean field game theory. In Mean Field Games; Springer: Berlin/Heidelberg, Germany, 2020; pp. 1–158. [Google Scholar]
- Yang, Y.; Luo, R.; Li, M.; Zhou, M.; Zhang, W.; Wang, J. Mean field multi-agent reinforcement learning. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5571–5580. [Google Scholar]
- Shiri, H.; Park, J.; Bennis, M. Massive autonomous UAV path planning: A neural network based mean-field game theoretic approach. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Bogachev, V.I.; Krylov, N.V.; Röckner, M.; Shaposhnikov, S.V. Fokker–Planck–Kolmogorov Equations; American Mathematical Society: Providence, RI, USA, 2022; Volume 207. [Google Scholar]
- Peng, S. Stochastic hamilton–jacobi–bellman equations. SIAM J. Control Optim. 1992, 30, 284–304. [Google Scholar] [CrossRef]
- Murray, J.J.; Cox, C.J.; Lendaris, G.G.; Saeks, R. Adaptive dynamic programming. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2002, 32, 140–153. [Google Scholar] [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef] [Green Version]
- Ju, C.; Son, H.I. Multiple UAV systems for agricultural applications: Control, implementation, and evaluation. Electronics 2018, 7, 162. [Google Scholar] [CrossRef] [Green Version]
- Gupta, J.K.; Egorov, M.; Kochenderfer, M. Cooperative multi-agent control using deep reinforcement learning. In Proceedings of the International Conference on Autonomous Agents and Multiagent Systems, Sao Paulo, Brazil, 8–12 May 2017; pp. 66–83. [Google Scholar]
- Oroojlooy, A.; Hajinezhad, D. A review of cooperative multi-agent deep reinforcement learning. Appl. Intell. 2022, 1–46. [Google Scholar] [CrossRef]
- Zhang, S.; Li, T.; Cheng, X.; Li, J.; Xue, B. Multi-Group Formation Tracking Control for Second-Order Nonlinear Multi-Agent Systems Using Adaptive Neural Networks. IEEE Access 2021, 9, 168207–168215. [Google Scholar] [CrossRef]
- Wu, Z.; Liu, X.; Sun, J.; Wang, X. Multi-group formation tracking control via impulsive strategy. Neurocomputing 2020, 411, 487–497. [Google Scholar] [CrossRef]
- Luo, L.; Wang, X.; Ma, J.; Ong, Y.S. Grpavoid: Multigroup collision-avoidance control and optimization for UAV swarm. IEEE Trans. Cybern. 2021. [Google Scholar] [CrossRef]
- Lewis, F.L.; Vrabie, D.; Vamvoudakis, K.G. Reinforcement learning and feedback control: Using natural decision methods to design optimal adaptive controllers. IEEE Control. Syst. Mag. 2012, 32, 76–105. [Google Scholar]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dey, S.; Xu, H. Intelligent Distributed Swarm Control for Large-Scale Multi-UAV Systems: A Hierarchical Learning Approach. Electronics 2023, 12, 89. https://doi.org/10.3390/electronics12010089
Dey S, Xu H. Intelligent Distributed Swarm Control for Large-Scale Multi-UAV Systems: A Hierarchical Learning Approach. Electronics. 2023; 12(1):89. https://doi.org/10.3390/electronics12010089
Chicago/Turabian StyleDey, Shawon, and Hao Xu. 2023. "Intelligent Distributed Swarm Control for Large-Scale Multi-UAV Systems: A Hierarchical Learning Approach" Electronics 12, no. 1: 89. https://doi.org/10.3390/electronics12010089
APA StyleDey, S., & Xu, H. (2023). Intelligent Distributed Swarm Control for Large-Scale Multi-UAV Systems: A Hierarchical Learning Approach. Electronics, 12(1), 89. https://doi.org/10.3390/electronics12010089