
A Multi-Level Attentive Context-Aware Trajectory Prediction Algorithm for Mobile Social Users


Abstract
:1. Introduction
- A new trajectory representation modeling method is designed. In this method, not only are conventional time and space considered, but also the semantic context of trajectories, such as social relations and location categories, is fully considered;
- A novel MACTP model is proposed to obtain trajectory point representation and capture users’ preferences. In terms of personal preferences, the friend-level attention layer and user-check-in attention layer are used to mine users’ check-in and social preferences, while for group preferences, the trajectory representation incorporating a priori knowledge is obtained by a multi-level attention module;
- Experiments are conducted on these datasets: Gowalla–LA, Gowalla–Houston, and Foursquare–NYC. The results indicate that the proposed model considerably improves trajectory prediction.
2. Related Work
2.1. Trajectory Prediction
2.2. Neural Network Applications in Trajectory Prediction
3. Preliminaries
4. Multi-Level Attentive Context-Aware Trajectory Prediction Model
4.1. Trajectory Embedding Module
4.1.1. Time Embedding
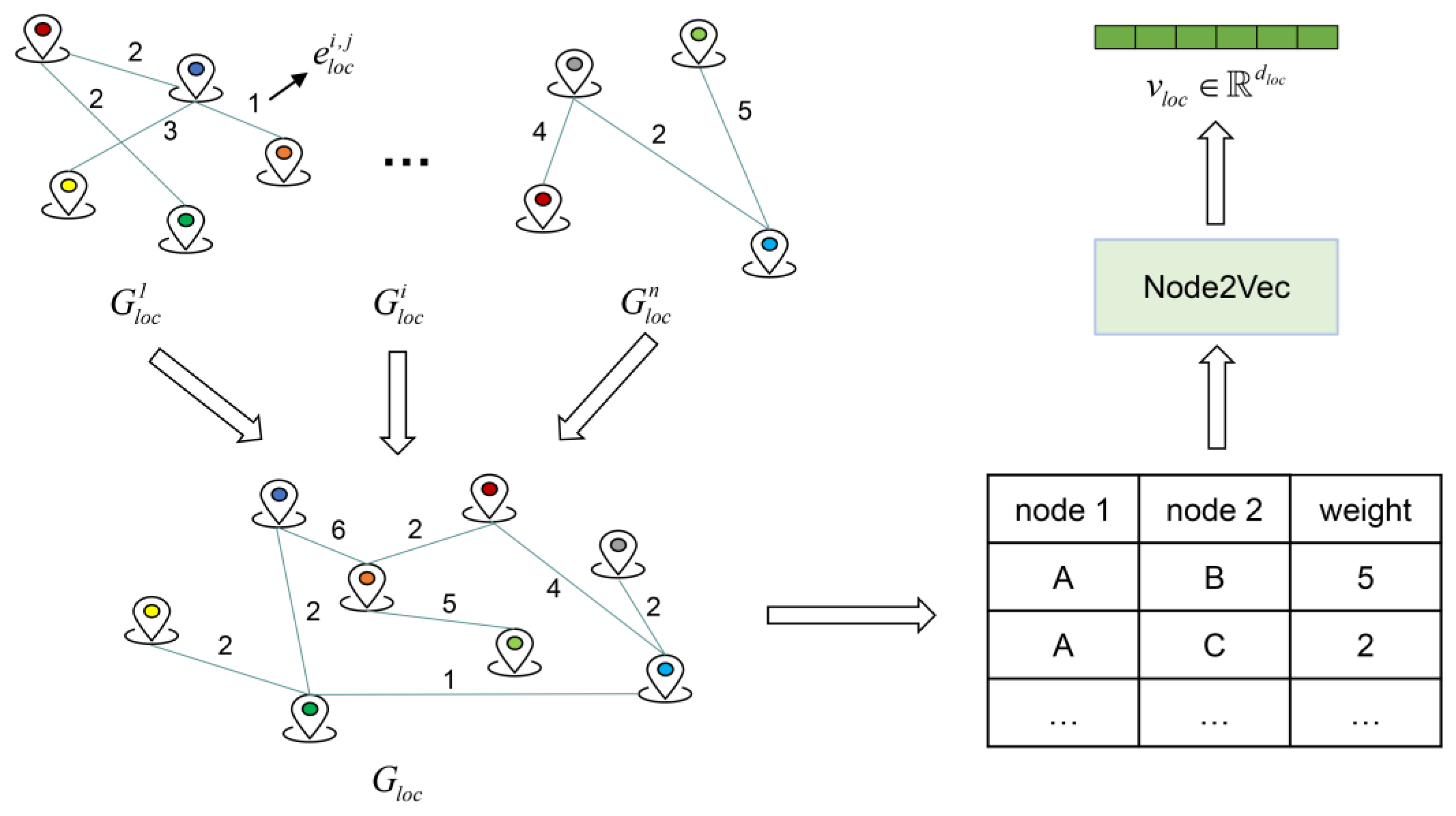
4.1.2. Spatial Interaction Embedding
4.1.3. Social Relationship Embedding
4.2. Multi-Level Attention Module
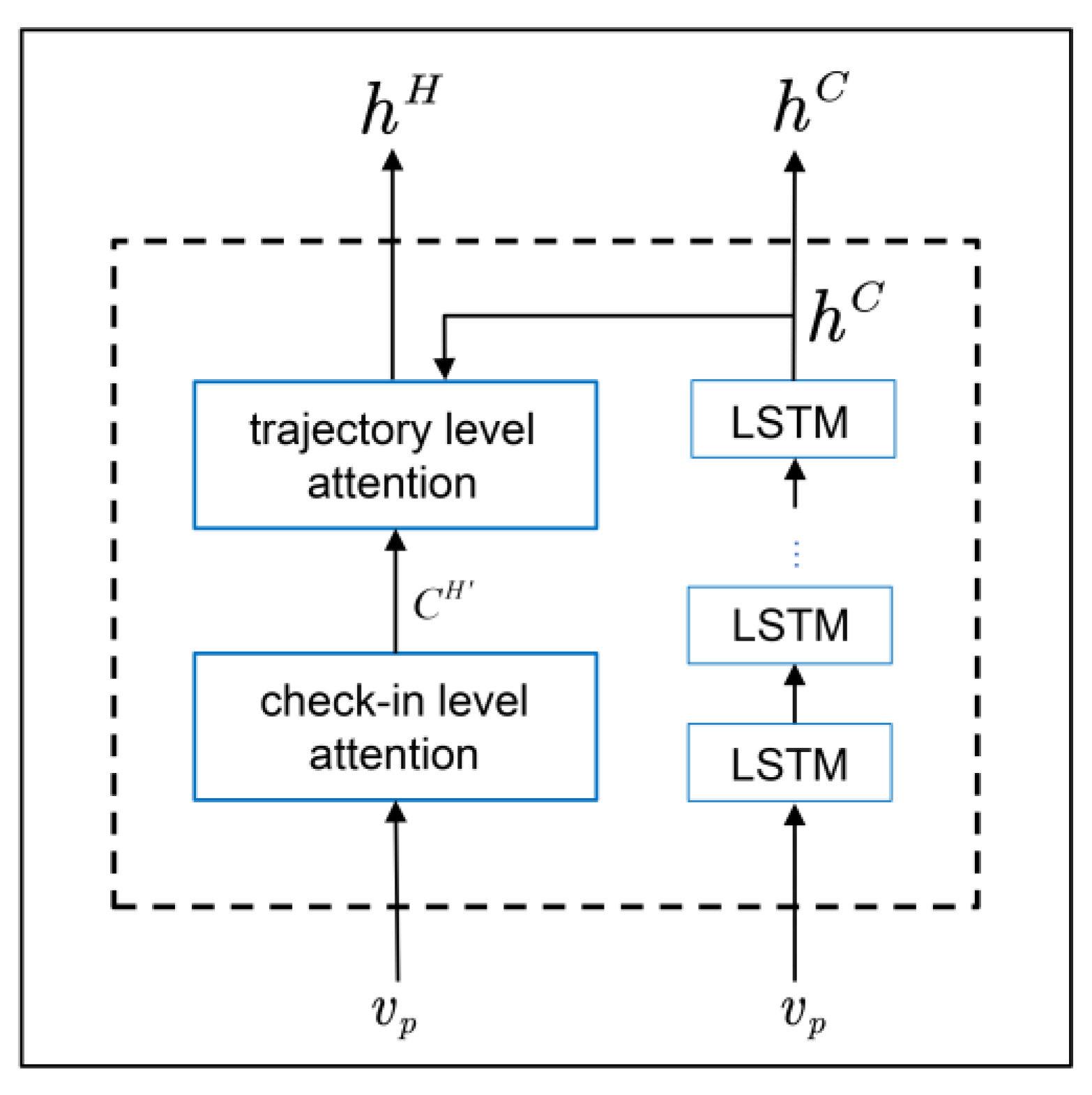
4.2.1. Personal Preference Learning
4.2.2. Group Preference Learning
4.3. Trajectory Prediction Module
4.4. Trajectory Prediction Algorithm and Model Training
| Algorithm 1. Multi-level attentive context-aware trajectory prediction algorithm for mobile social users. |
| Input: Preprocessed user trajectory data Output: List of predicted locations |
|
5. Experiments
5.1. Datasets and Data Preprocessing
5.2. Evaluation Metrics
5.3. Baselines
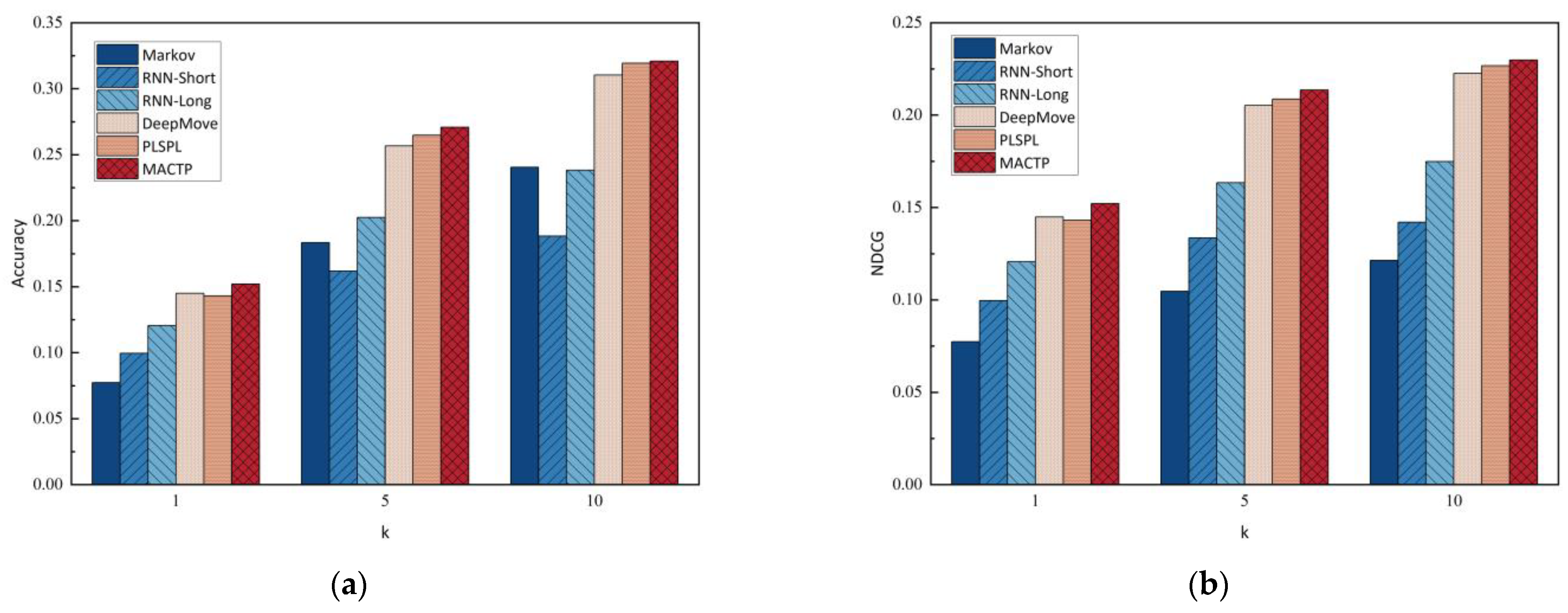
5.4. Method Comparison
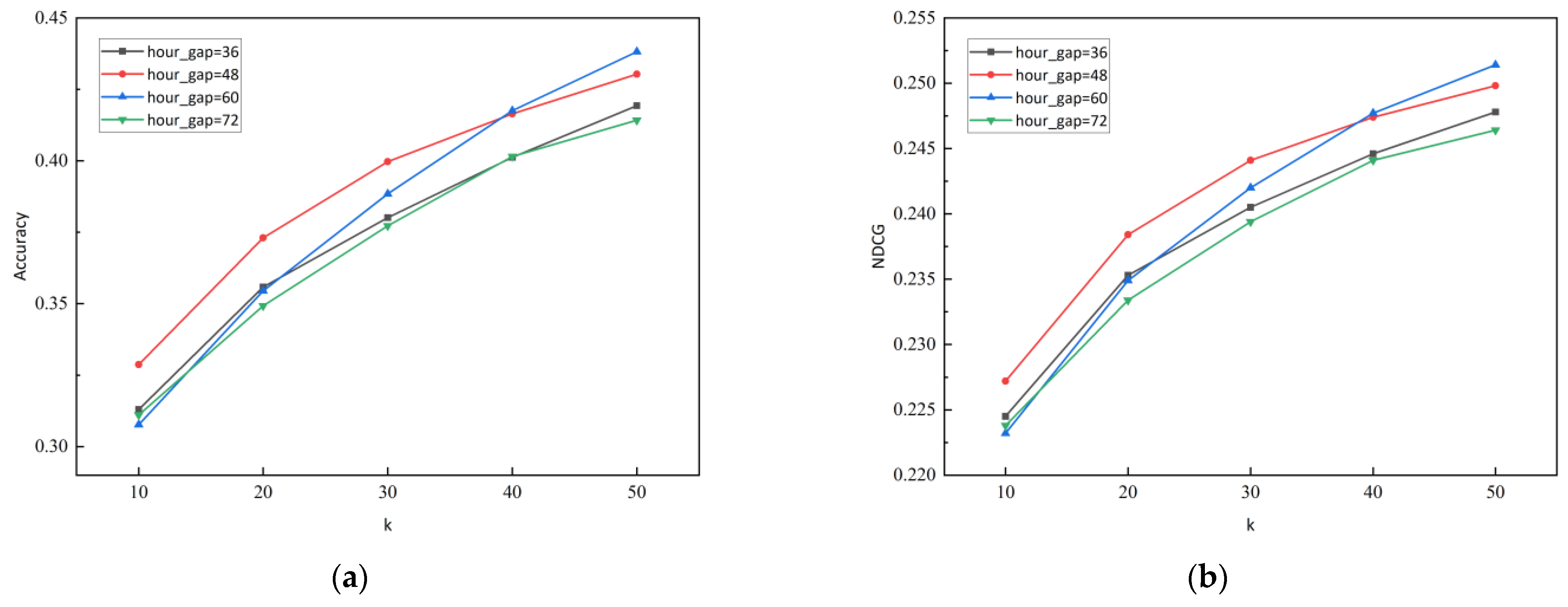
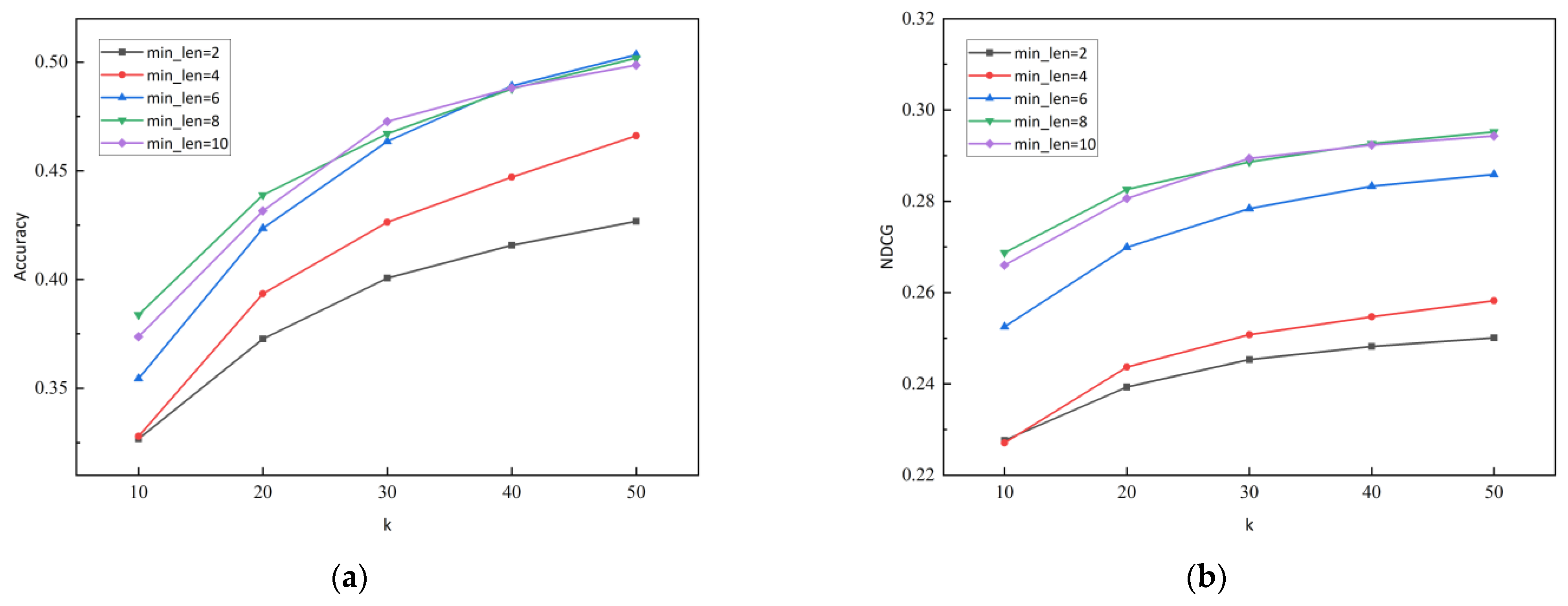
5.5. Hyperparameter Settings
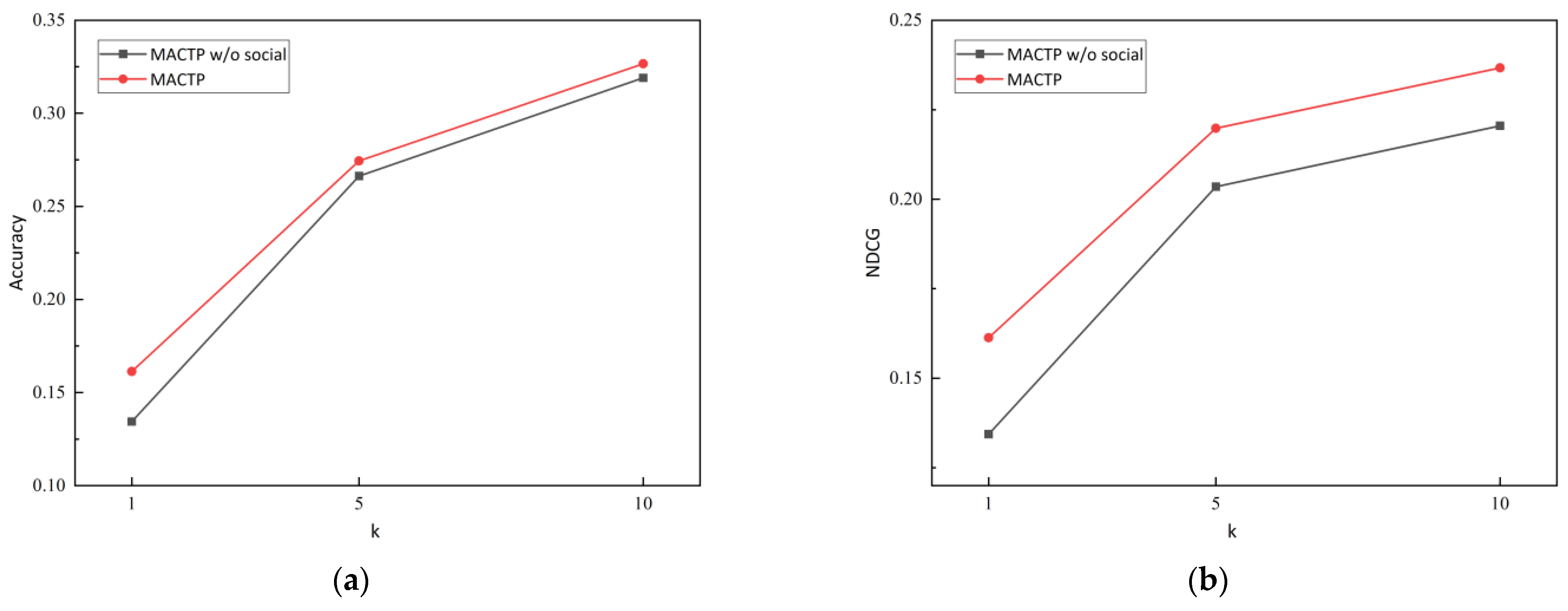
5.6. Ablation Study
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, Y.; Pham, T.-A.; Cong, G.; Yuan, Q. An experimental evaluation of point-of-interest recommendation in location-based social networks. In Proceedings of the VLDB Endowment; VLDB Endowment: Sydney, Australia, 2017; pp. 1010–1021. [Google Scholar]
- Liu, Q.; Zuo, Y.; Yu, X.; Chen, M. TTDM: A travel time difference model for next location prediction. In Proceedings of the 2019 20th IEEE International Conference on Mobile Data Management (MDM), Hong Kong, China, 10–13 June 2019; pp. 216–225. [Google Scholar]
- Liu, C.H.; Wang, Y.; Piao, C.; Dai, Z.; Yuan, Y.; Wang, G.; Wu, D. Time-aware location prediction by convolutional area-of-interest modeling and memory-augmented attentive LSTM. IEEE Trans. Knowl. Data Eng. 2022, 34, 2472–2484. [Google Scholar] [CrossRef]
- Bao, Y.; Huang, Z.; Li, L.; Wang, Y.; Liu, Y. A BiLSTM-CNN model for predicting users’ next locations based on geotagged social media. Int. J. Geogr. Inf. Sci. 2020, 35, 639–660. [Google Scholar]
- Yang, D.; Li, B.; Cudré-Mauroux, P. Poisketch: Semantic place labeling over user activity streams. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI), New York, NY, USA, 9–15 July 2016; pp. 2697–2703. [Google Scholar]
- Yang, D.; Zhang, D.; Zheng, V.W.; Yu, Z. Modeling user activity preference by leveraging user spatial temporal characteristics in LBSNs. IEEE Trans. Syst. Man Cybern. Syst. 2015, 45, 129–142. [Google Scholar] [CrossRef]
- Mathew, W.; Raposo, R.; Martins, B. Predicting future locations with hidden Markov models. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 5–8 September 2012; pp. 911–918. [Google Scholar]
- Feng, J.; Li, Y.; Zhang, C.; Sun, F.; Meng, F.; Guo, A.; Jin, D. Deepmove: Predicting human mobility with attentional recurrent networks. In Proceedings of the 2018 World Wide Web Conference on World Wide Web—WWW ‘18, Lyon, France, 23–27 April 2018; pp. 1459–1468. [Google Scholar]
- Li, J.; Wang, Y.; McAuley, J. Time interval aware self-attention for sequential recommendation. In Proceedings of the 13th International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; pp. 322–330. [Google Scholar]
- Zhao, P.; Luo, A.; Liu, Y.; Zhuang, F.; Xu, J.; Li, Z.; Zhou, X. Where to go next: A spatio-temporal gated network for next poi recommendation. IEEE Trans. Knowl. Data Eng. 2022, 34, 2512–2524. [Google Scholar] [CrossRef]
- Martin, H.; Bucher, D.; Suel, E.; Zhao, P.; Perez-Cruz, F.; Raubal, M. Graph convolutional neural networks for human activity purpose imputation from GPS-based trajectory data. In Proceedings of the NIPS Spatiotemporal Workshop at the 32nd Annual Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Tang, J.; Wang, K. Personalized top-n sequential recommendation via convolutional sequence embedding. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina del Rey, LA, USA, 5–9 February 2018; pp. 565–573. [Google Scholar]
- Yao, D.; Zhang, C.; Huang, J.; Bi, J. Serm: A recurrent model for next location prediction in semantic trajectories. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 2411–2414. [Google Scholar]
- Li, M.; Lu, F.; Zhang, H.; Chen, J. Predicting future locations of moving objects with deep fuzzy-LSTM networks. Transp. A 2018, 16, 119–136. [Google Scholar] [CrossRef]
- Zhang, X.; Li, B.; Song, C.; Huang, Z.; Li, Y. SASRM: A semantic and attention spatio-temporal recurrent model for next location prediction. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Guo, Q.; Sun, Z.; Zhang, J.; Theng, Y.L. An attentional recurrent neural network for personalized next location recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–20 February 2020; pp. 83–90. [Google Scholar]
- Sun, K.; Qian, T.; Chen, T.; Liang, Y.; Nguyen, Q.-V.H.; Yin, H. Where to go next: Modeling long-and short-term user preferences for point-of-interest recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–20 February 2020; pp. 214–221. [Google Scholar]
- Liang, W.; Zhang, W. Learning social relations and spatiotemporal trajectories for next check-in inference. IEEE Trans. Neural Netw. Learn. Syst. 2020, 34, 1789–1799. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Chen, Y.; Huang, X.; Li, J.; Min, G. GNN-based long and short term preference modeling for next-location prediction. Inform. Sci. 2023, 629, 1–14. [Google Scholar] [CrossRef]
- Liu, A.; Zhang, Y.; Zhang, X.; Liu, G.; Zhang, Y.; Li, Z.; Zhao, L.; Li, Q.; Zhou, X. Representation learning with multi-level attention for activity trajectory similarity computation. IEEE Trans. Knowl. Data Eng. 2022, 34, 2387–2400. [Google Scholar] [CrossRef]
- Wang, S.; Li, A.; Xie, S.; Li, W.; Wang, B.; Yao, S.; Asif, M.; Xia, M. A spatial-temporal self-attention network (STSAN) for location prediction. Complexity 2021, 2021, 6692313. [Google Scholar] [CrossRef]
- Abideen, Z.U.; Sun, H.; Yang, Z.; Ahmad, R.Z.; Iftekhar, A.; Ali, A. Deep wide spatial-temporal based transformer networks modeling for the next destination according to the taxi driver behavior prediction. Appl. Sci. 2021, 11, 17. [Google Scholar] [CrossRef]
- Zhong, T.; Zhang, S.; Zhou, F.; Zhang, K.; Trajcevski, G.; Wu, J. Hybrid graph convolutional networks with multi-head attention for location recommendation. World Wide Web 2020, 23, 3125–3151. [Google Scholar] [CrossRef]
- Wu, J.; Hu, R.; Li, D.; Ren, L.; Hu, W.; Xiao, Y. Where have you been: Dual spatiotemporal-aware user mobility modeling for missing check-in POI identification. Inform. Process. Manag. 2022, 59, 103030. [Google Scholar] [CrossRef]
- Fang, J.; Meng, X.; Qi, X. A top-k POI recommendation approach based on LBSN and multi-graph fusion. Neurocomputing 2023, 518, 219–230. [Google Scholar] [CrossRef]
- Fang, J.; Meng, X. URPI-GRU: An approach of next POI recommendation based on user relationship and preference information. Knowl. Based Syst. 2022, 256, 109848. [Google Scholar] [CrossRef]
- Gao, Q.; Zhou, F.; Zhong, T.; Trajcevski, G.; Yang, X.; Li, T. Contextual spatio-temporal graph representation learning for reinforced human mobility mining. Inform. Sci. 2022, 606, 230–249. [Google Scholar] [CrossRef]
- Feng, J.; Li, Y.; Yang, Z.; Qiu, Q.; Jin, D. Predicting human mobility with semantic motivation via multi-task attentional recurrent networks. IEEE Trans. Knowl. Data Eng. 2022, 34, 2360–2374. [Google Scholar] [CrossRef]
- Grover, A.; Leskovec, J. Node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–7 December 2017; pp. 5998–6008. [Google Scholar]
- Liu, Q.; Wu, S.; Wang, L.; Tan, T. Predicting the next location: A recurrent model with spatial and temporal contexts. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 194–200. [Google Scholar]
- Wu, Y.; Li, K.; Zhao, G.; Qian, X. Personalized long-and short-term preference learning for next POI recommendation. IEEE Trans. Knowl. Data Eng. 2022, 34, 1944–1957. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | The No. of Users | The No. of Locations | Locs./Users. |
|---|---|---|---|
| Gowalla–LA | 1057 | 10,657 | 10.08 |
| Gowalla–Houston | 821 | 10,282 | 12.52 |
| Foursquare–NYC | 1082 | 34,440 | 31.83 |
| Methods | Acc@1 | Acc@5 | Acc@10 | NDCG@1 | NDCG@5 | NDCG@10 |
|---|---|---|---|---|---|---|
| Markov | 0.0774 | 0.1833 | 0.2405 | 0.0774 | 0.1047 | 0.1214 |
| RNN-Short | 0.0996 | 0.1619 | 0.1883 | 0.0996 | 0.1336 | 0.1420 |
| RNN-Long | 0.1206 | 0.2024 | 0.2383 | 0.1206 | 0.1634 | 0.1749 |
| DeepMove | 0.1449 | 0.2567 | 0.3103 | 0.1449 | 0.2052 | 0.2225 |
| PLSPL | 0.1431 | 0.2648 | 0.3194 | 0.1431 | 0.2087 | 0.2267 |
| MACTP | 0.1521 | 0.2707 | 0.3209 | 0.1521 | 0.2136 | 0.2298 |
| Methods | Acc@1 | Acc@5 | Acc@10 | NDCG@1 | NDCG@5 | NDCG@10 |
|---|---|---|---|---|---|---|
| Markov | 0.1114 | 0.2095 | 0.2470 | 0.1114 | 0.1189 | 0.1246 |
| RNN-Short | 0.1066 | 0.1745 | 0.1966 | 0.1066 | 0.1417 | 0.1487 |
| RNN-Long | 0.1249 | 0.2115 | 0.2514 | 0.1249 | 0.1702 | 0.1830 |
| DeepMove | 0.1437 | 0.2492 | 0.2939 | 0.1437 | 0.1998 | 0.2142 |
| PLSPL | 0.1404 | 0.2531 | 0.3026 | 0.1404 | 0.2013 | 0.2183 |
| MACTP | 0.1613 | 0.2744 | 0.3266 | 0.1613 | 0.2198 | 0.2367 |
| Methods | Acc@1 | Acc@5 | Acc@10 | NDCG@1 | NDCG@5 | NDCG@10 |
|---|---|---|---|---|---|---|
| Markov | 0.1228 | 0.2526 | 0.3178 | 0.1228 | 0.1204 | 0.1141 |
| RNN-Short | 0.0976 | 0.1951 | 0.2262 | 0.0976 | 0.1495 | 0.1596 |
| RNN-Long | 0.1179 | 0.2374 | 0.2758 | 0.1179 | 0.1817 | 0.1942 |
| DeepMove | 0.1453 | 0.2756 | 0.3087 | 0.1453 | 0.2159 | 0.2267 |
| PLSPL | 0.1468 | 0.2937 | 0.3349 | 0.1468 | 0.2203 | 0.2358 |
| MACTP | 0.1653 | 0.3445 | 0.4062 | 0.1653 | 0.2584 | 0.2784 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xin, M.; Zang, C. A Multi-Level Attentive Context-Aware Trajectory Prediction Algorithm for Mobile Social Users. Electronics 2023, 12, 2240. https://doi.org/10.3390/electronics12102240
Xin M, Zang C. A Multi-Level Attentive Context-Aware Trajectory Prediction Algorithm for Mobile Social Users. Electronics. 2023; 12(10):2240. https://doi.org/10.3390/electronics12102240
Chicago/Turabian StyleXin, Mingjun, and Chunjuan Zang. 2023. "A Multi-Level Attentive Context-Aware Trajectory Prediction Algorithm for Mobile Social Users" Electronics 12, no. 10: 2240. https://doi.org/10.3390/electronics12102240
APA StyleXin, M., & Zang, C. (2023). A Multi-Level Attentive Context-Aware Trajectory Prediction Algorithm for Mobile Social Users. Electronics, 12(10), 2240. https://doi.org/10.3390/electronics12102240