All simulation experiments in this paper are run under the Python Constant Source Cloud_GPUSHARE environment on a personal computer configured with a 2.90 GHz Intel (R) Core (TM) i5-9400 CPU, 32.0 GB RAM, and 64-bit Windows 10.
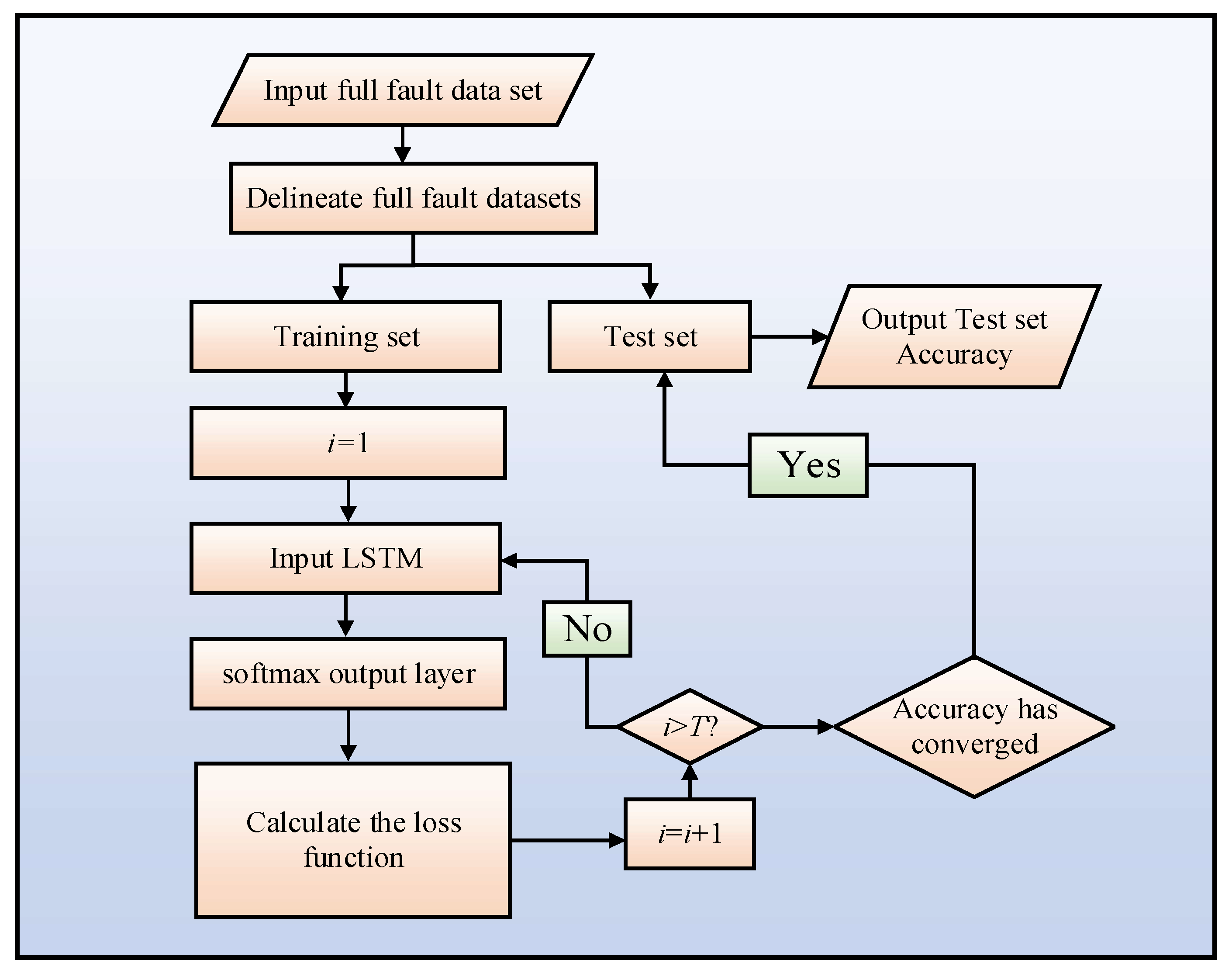
5.1. LSTM Network Parameter Settings
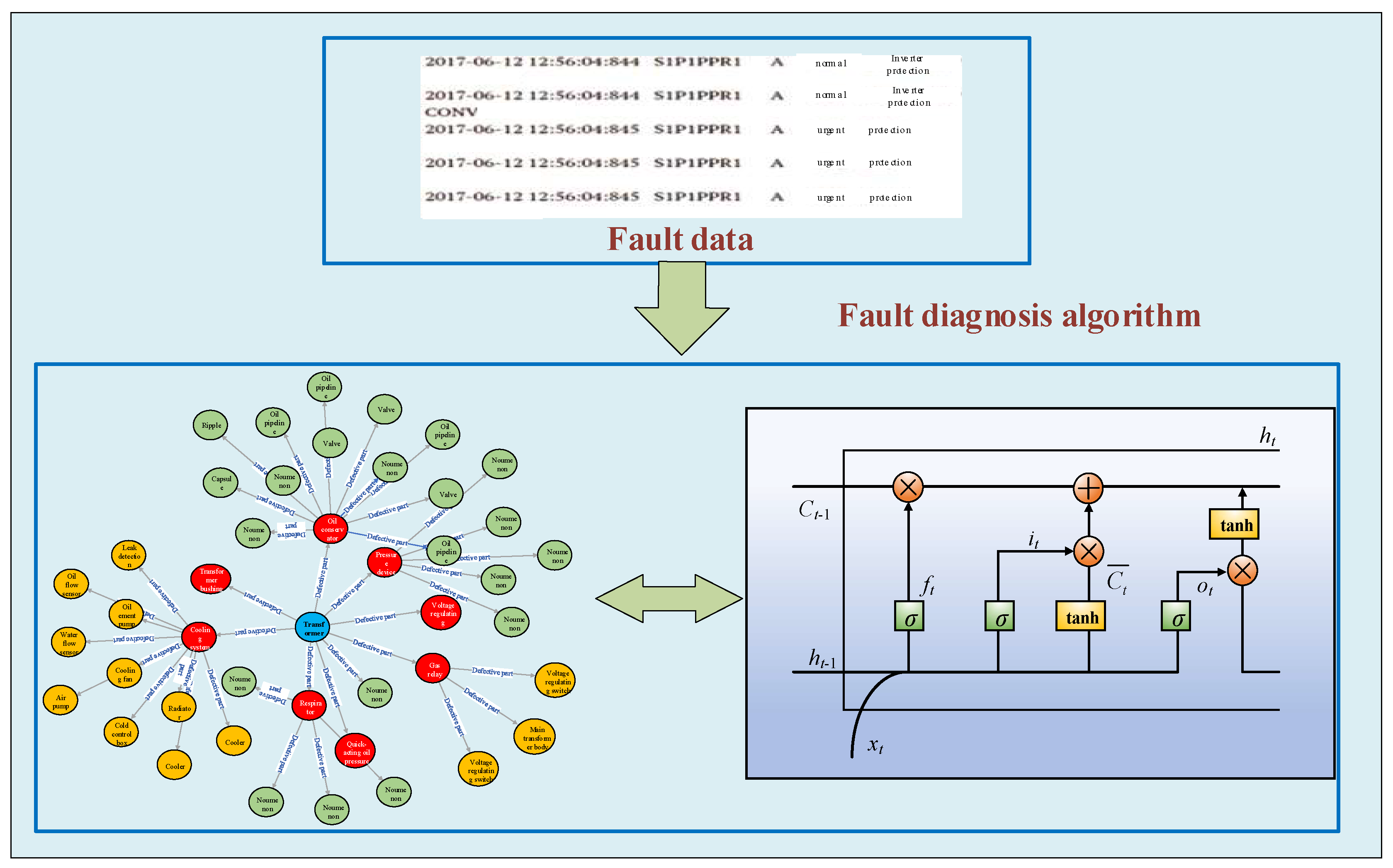
The fault data is substituted into the knowledge graph to analyze and process the fault data. The fault data is then divided into 409 samples with 33,000 dimensions and combined with the probability of previous failures in the knowledge graph database; the data is divided into training data sets and test data sets with the optimal solution; four fault types are extracted according to the knowledge graph; and the output target dimension is set as [
1,
2,
3,
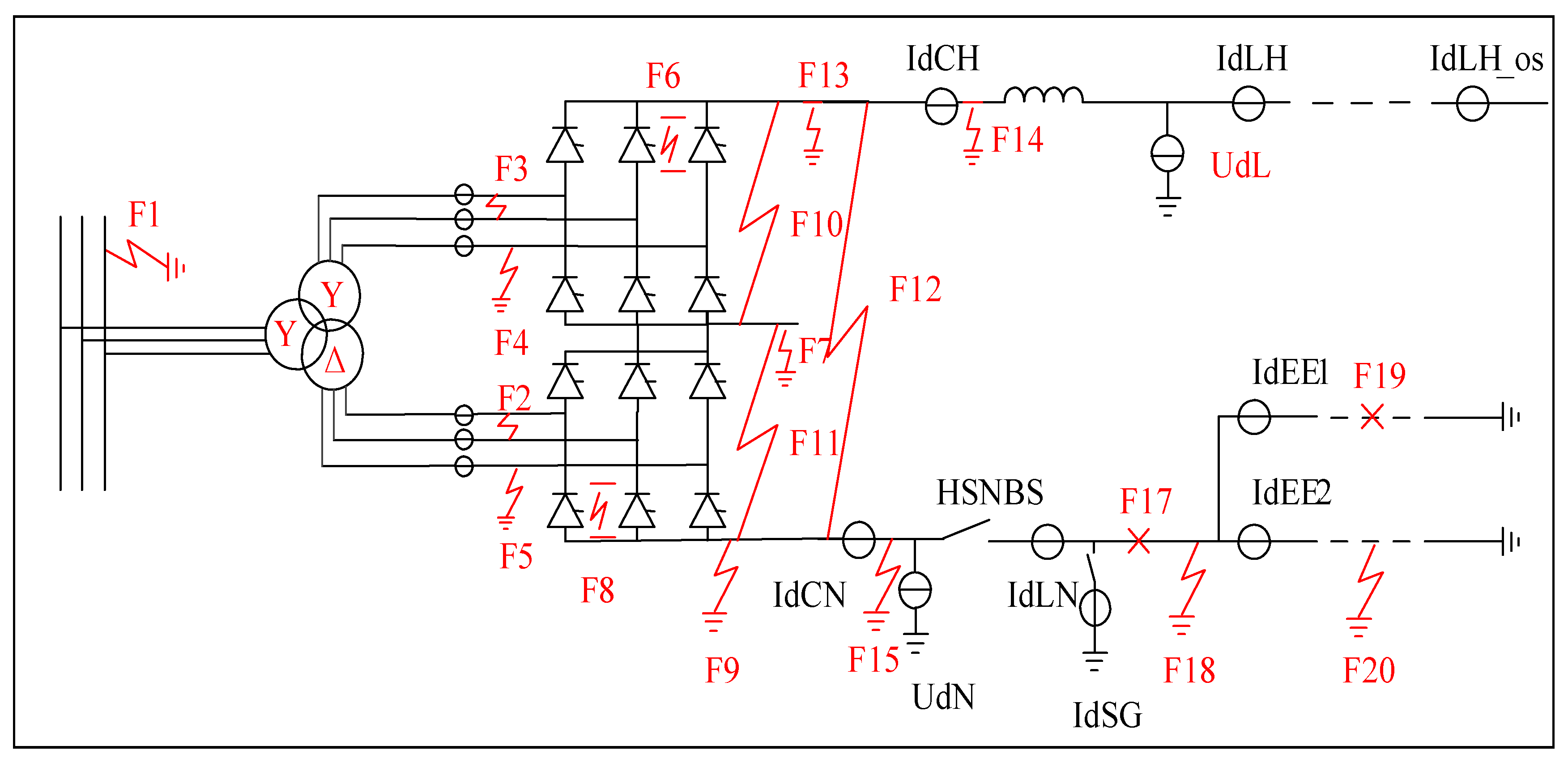
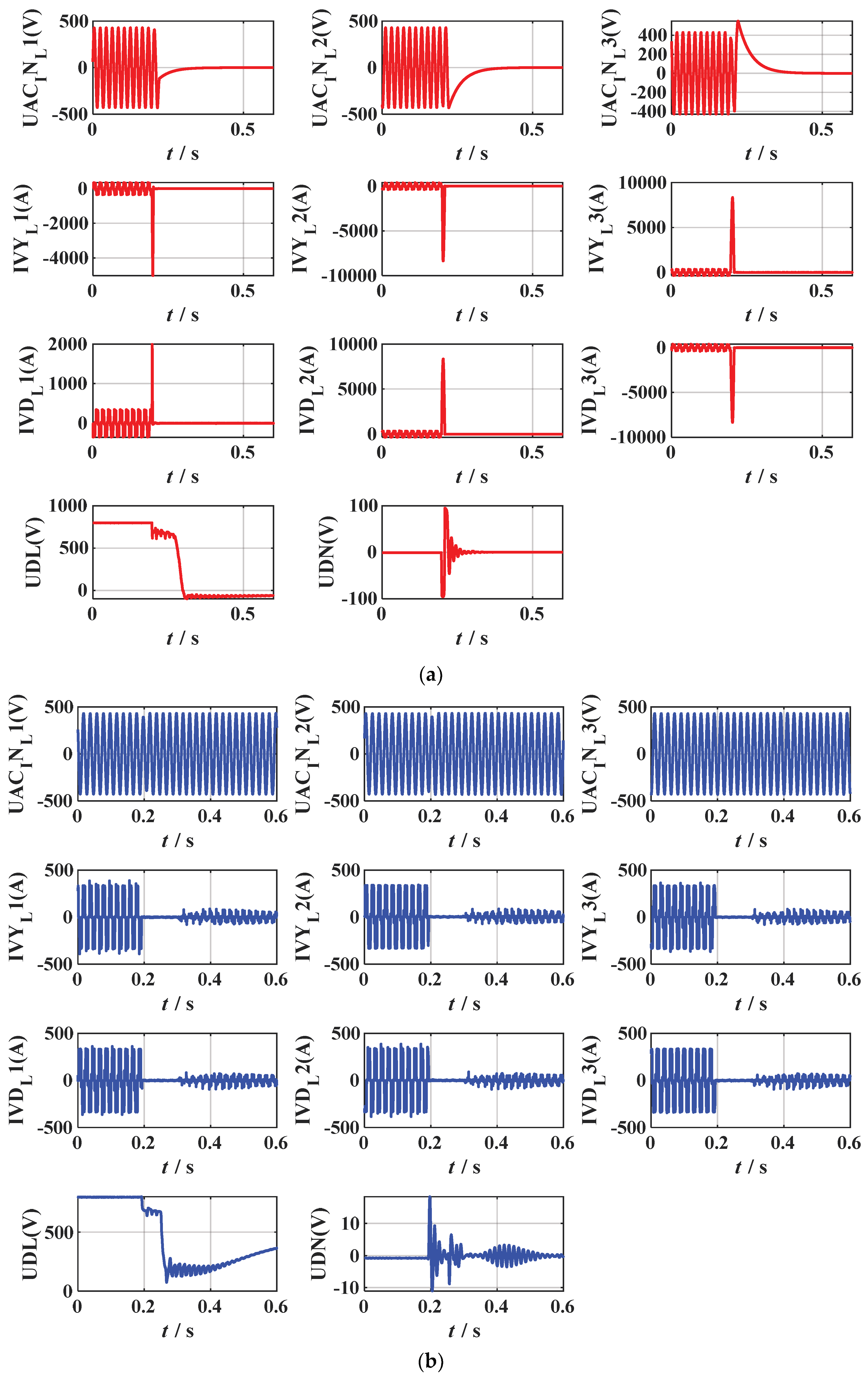
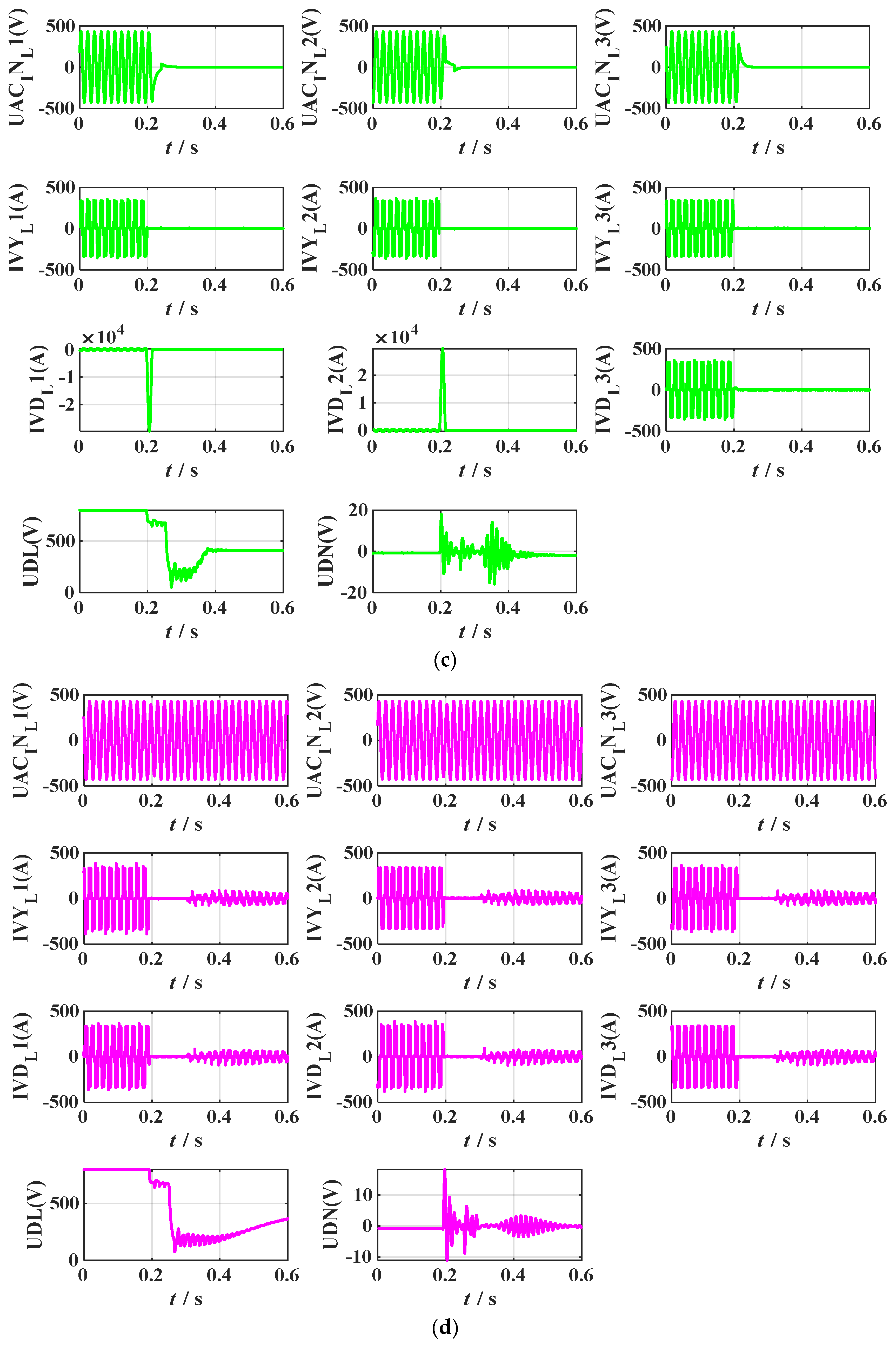
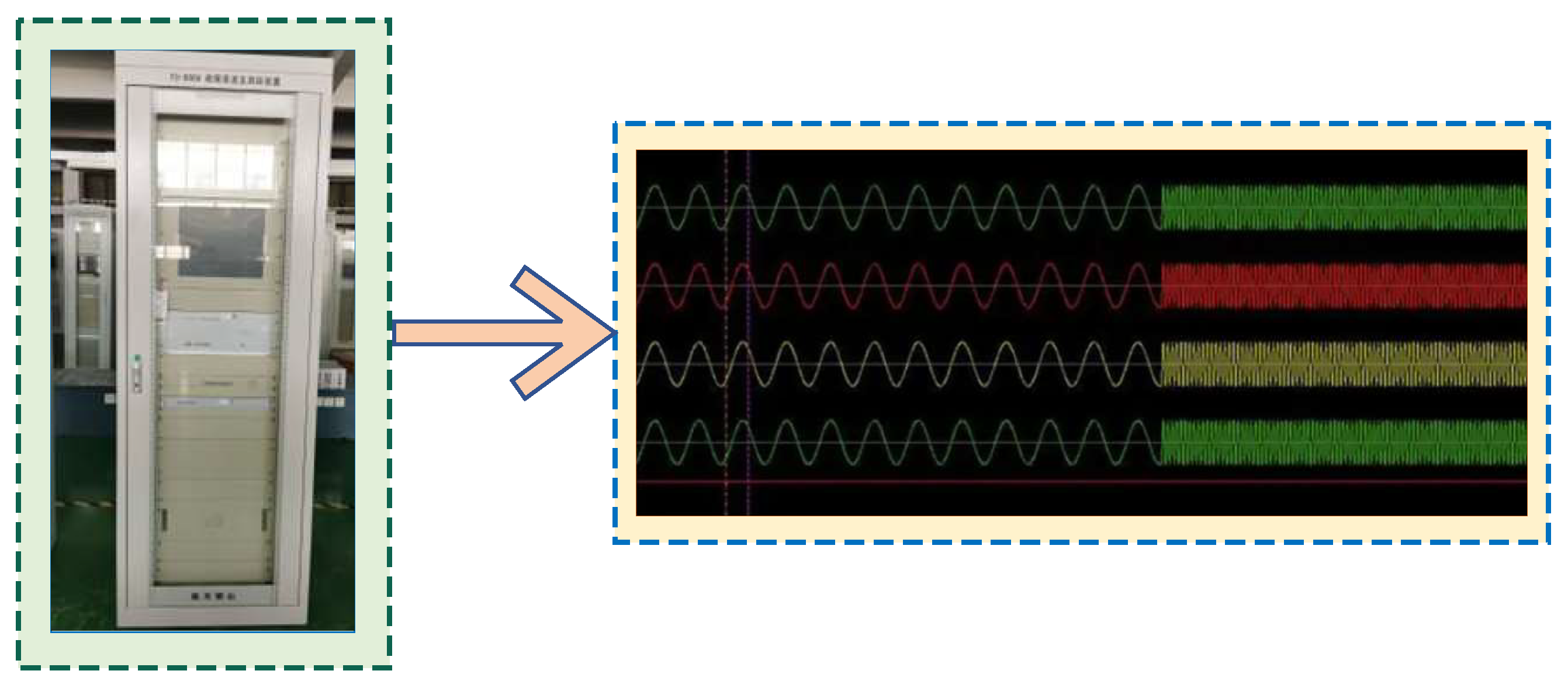
4], where 1, 2, 3, 4 represent single-phase faults of DC-side transmission lines, faults of converter valve arms, faults of converter valve groups, and phase-to-phase faults of DC-side transmission lines, respectively. Among these, the test data set will be used to verify its performance. In addition, 11 channel data waveforms measured from the fault recording device installed along the transmission line of Tianshengqiao-Guangzhou and the converter station (Niucong and Xindong) fault data from 2018–2022, which correspond to four types of faults in HVDC systems, are shown in
Figure 11. It can be seen from the graph that the waveform diagrams of the four types of faults are very inconsistent and all have their unique characteristics. The setting of the hidden layer parameters is crucial to the training of the network and will directly determine the final fault classification performance, and overfitting and underfitting may also occur if improperly chosen.
In the training process of the LSTM network, the hyper-parameters that have a significant impact on the fault classification accuracy are learning rate, training times, and optimizer. By adjusting these parameters, the fault prediction accuracy is finally obtained after continuous iterations.
The batch size affects the training speed and model optimization. The variance of the gradient is expressed as:
where
m is the value set by the batch size.
The increasing batch size can reduce the gradient variance. If the batch size is set as the total number of fault samples, it is equivalent to directly training the entire sample data set. This will lead to a long training time, but the gradient is more accurate, so it is only suitable for small sample training. If the batch size is set too small, the gradient change fluctuates greatly, and the network is not easy to converge.
Since the input LSTM fault data set is relatively large, this paper set batch size = 64 through the trial-and-error method. At the same time, to achieve higher training network accuracy, the epoch is increased appropriately, thus increasing the training time.
There is usually no definite selection method for the setting of LSTM parameters, which can be set by empirical formulas and continuous experiments; the specific parameter settings in this paper are shown in
Table 3.
5.3. Analysis of Diagnostic Results and Comparison of Programs
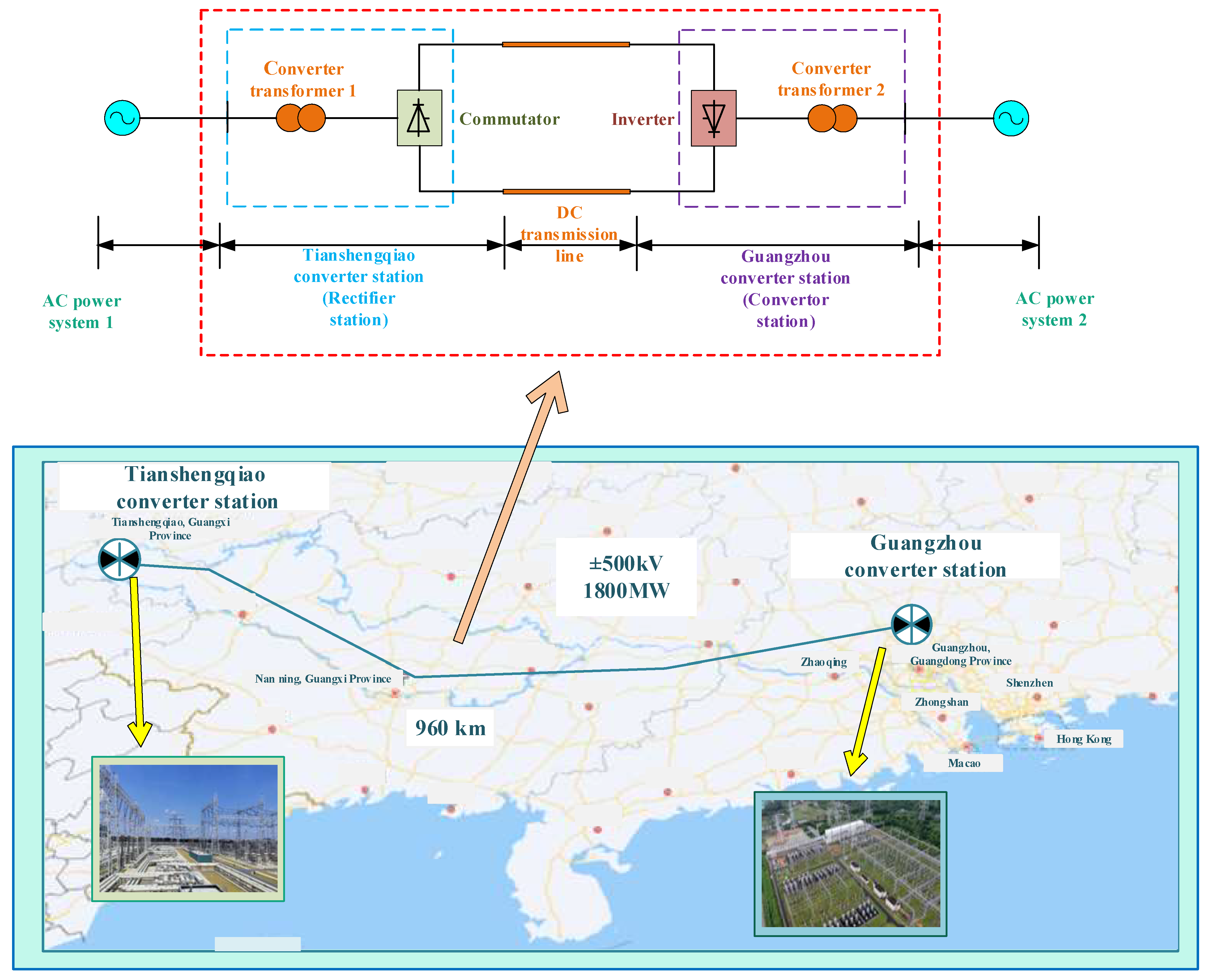
In this section, all stored fault data of the Tianshengqiao-Guangzhou HVDC transmission project is used as the input of LSTM, which contains 409 fault samples. The input fault samples are the voltage and current waveform after the failure, and the length of each fault sample sequence is 33,000.
To prove the efficiency of the fault diagnosis, RNN, XGBoost, SVM, Naive Bayes classifier, PNN, and CL are taken to compare the effect of fault diagnosis, and the parameter settings of RNN, XGBoost [
10], SVM, Naive Bayes classifier, PNN, and CL are shown in
Table 5,
Table 6,
Table 7,
Table 8 and
Table 9.
It is worth noting that the total measured fault data, e.g., from 2018–2022, are all used to better train LSTM and other alternatives (these data are all the stored fault data collected from the Tianshengqiao transmission project of the China Southern Power Grid).
For fault 1, 84 samples were trained and 20 samples were tested. Additionally, the overall training set and test set are summarized in
Table 10.
Note that because the fault data set is relatively small, the selection of hyper-parameters in the seven methods used in this study is the optimal result after adjustment using the uniform design method [
48].
The RNN, XGBoost, SVM, Naive Bayes, PNN, and CL are trained using the same training data set, and the same test data set is used for accuracy testing after training. The diagnostic accuracies of the seven methods are shown in
Table 11. The five evaluating indicators of F1-score, precision score, recall score, AUC score, and test time are shown in
Table 12.
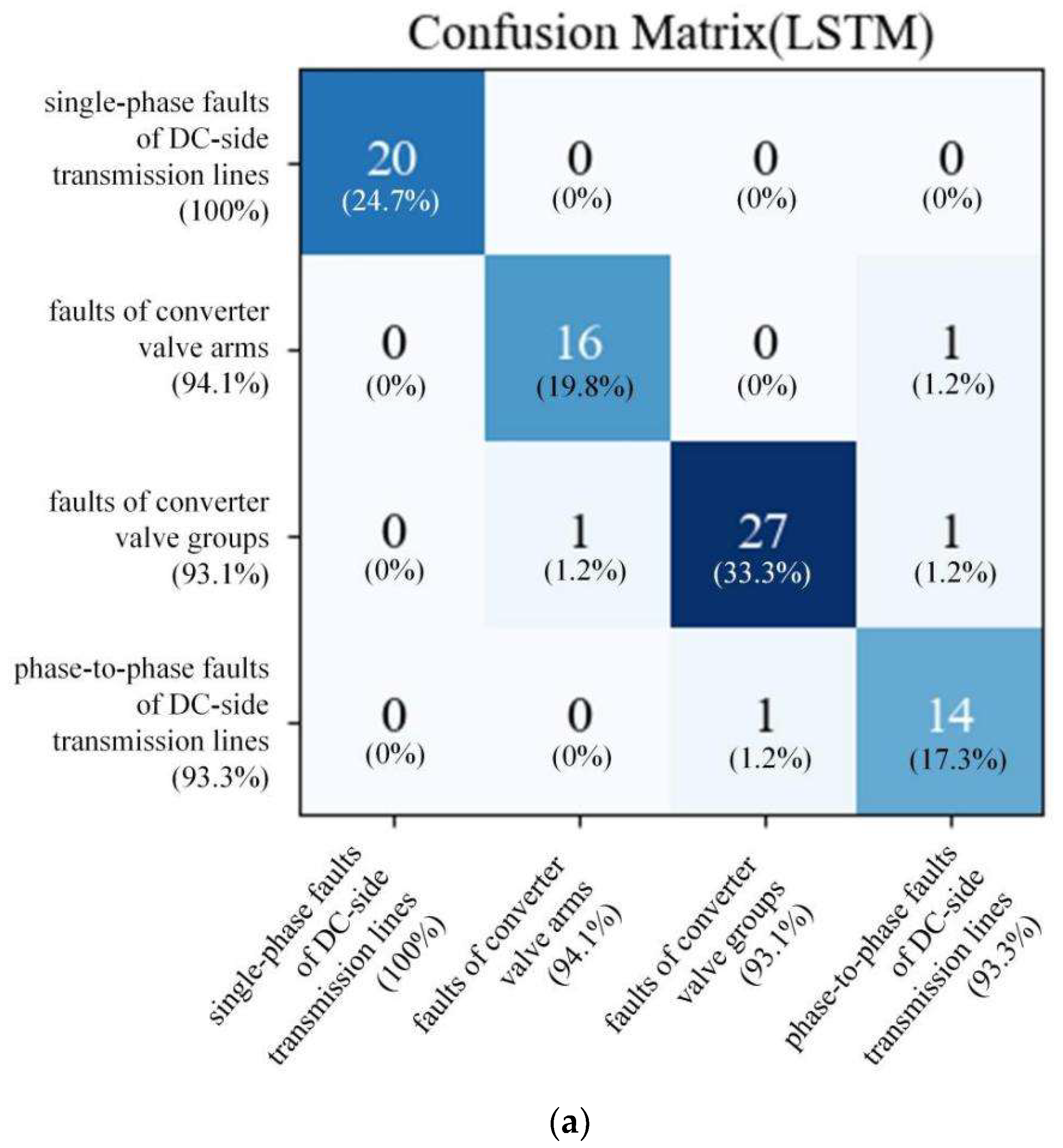
To visualize the fault diagnosis accuracy of the test, the confusion matrix is used for analysis. The fault diagnosis results of the seven methods are shown in
Figure 12. Although the seven methods are subject to misdiagnosis, the misdiagnosis rate of the LSTM method is significantly lower than that of the other methods.
It can be observed from
Figure 12a that 1 misdiagnosis data appears in faults of converter valve arms, 2 misdiagnosis data appear in faults of converter valve groups, and 1 misdiagnosis data appears in phase-to-phase faults of DC-side transmission lines in the results of the LSTM method. Furthermore, for the results of the RNN method in
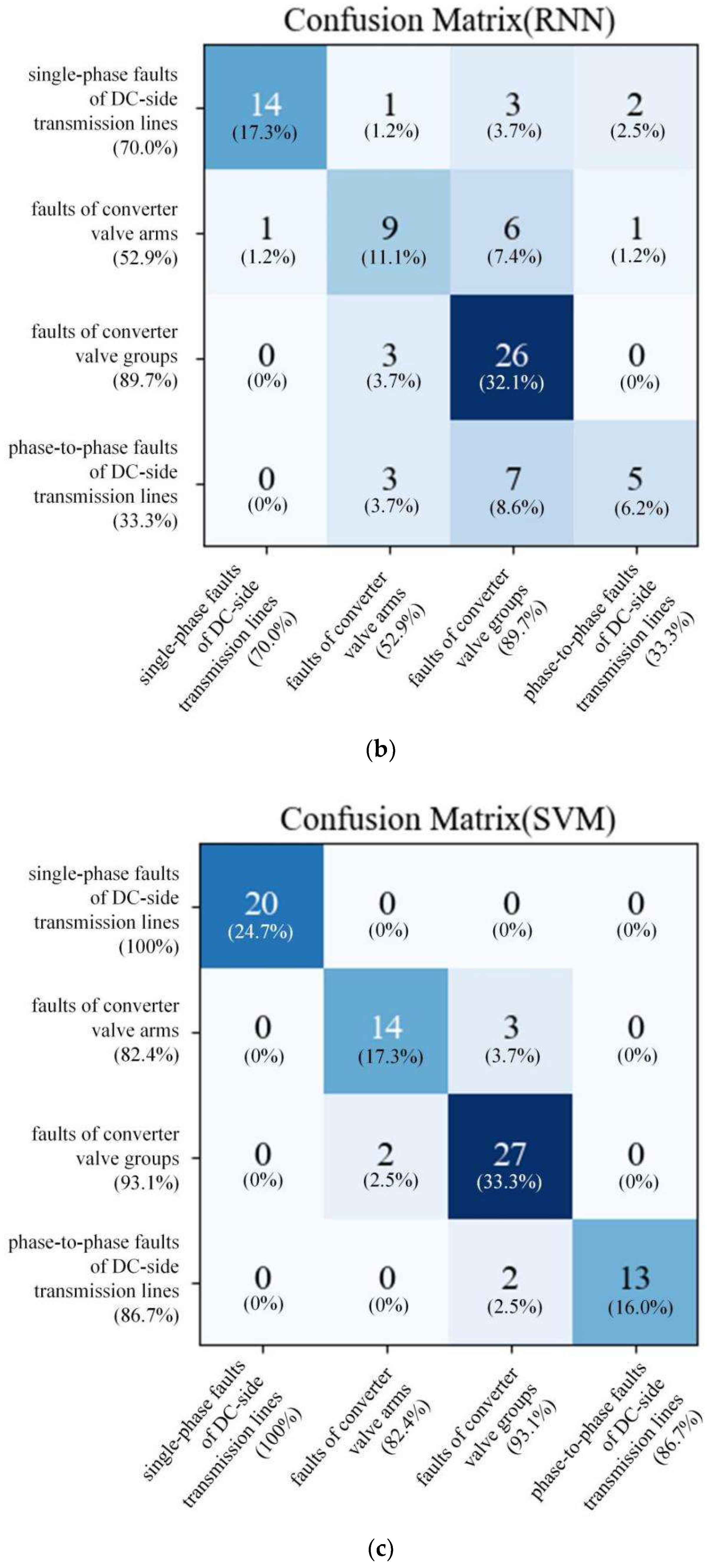
Figure 12b, 6 misdiagnosis data appear in single-phase faults of DC-side transmission lines, 8 misdiagnosis data appear in faults of converter valve arms, 3 misdiagnosis data appear in faults of converter valve groups, and 10 misdiagnosis data appear in phase-to-phase faults of DC-side transmission lines. In addition, from the result of the SVM method in
Figure 12c, 3 misdiagnosis data appear in faults of converter valve arms, 2 misdiagnosis data appear in faults of converter valve groups, and 2 misdiagnosis data appear in phase-to-phase faults of DC-side transmission lines. Then it can be observed from
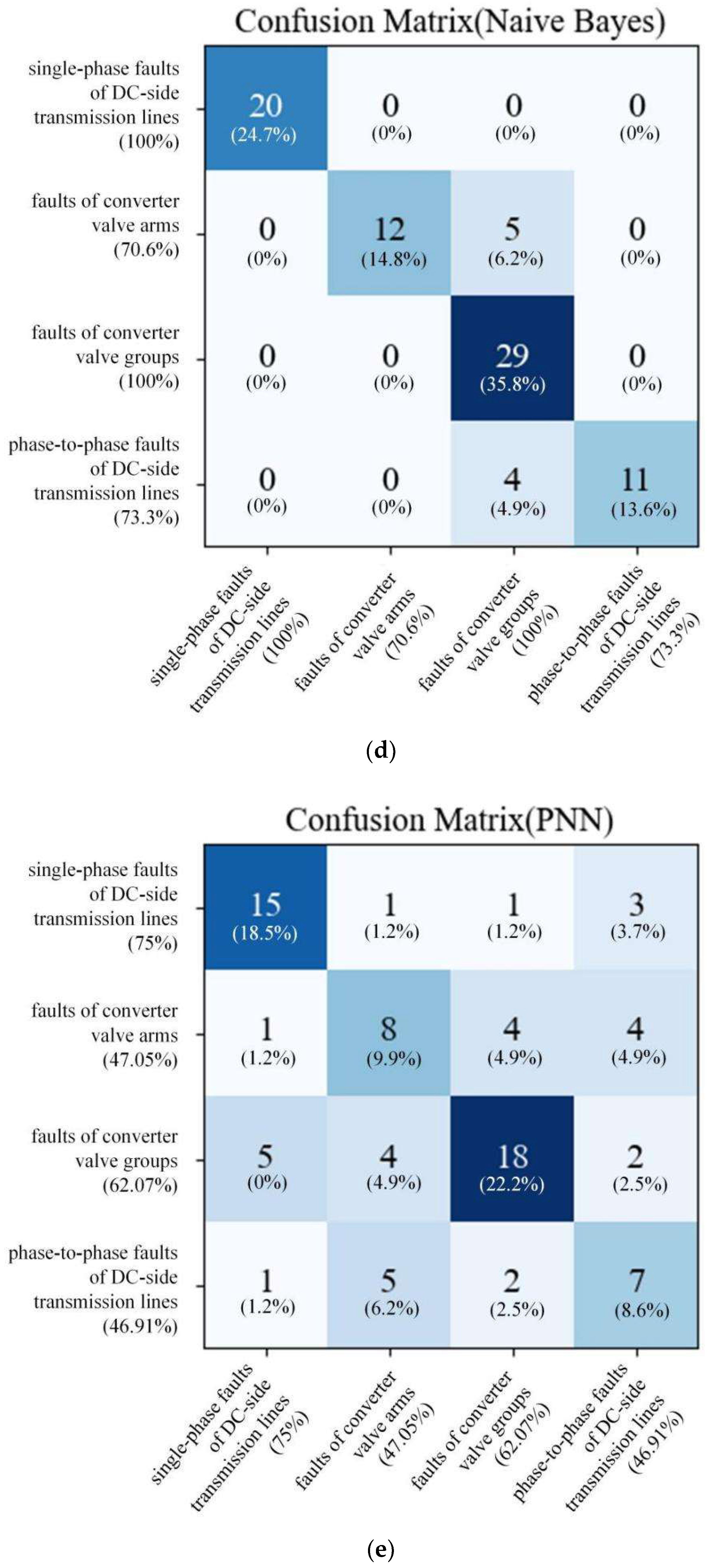
Figure 12d that 0 misdiagnosis data appear in single-phase faults of DC-side transmission lines, 5 misdiagnosis data appear in faults of converter valve arms, 0 misdiagnosis data appear in faults of converter valve groups, and 4 misdiagnosis data appear in phase-to-phase faults of DC-side transmission lines in the Naive Bayes method. After that, from the result of the PNN method in
Figure 12e, 5 misdiagnosis data appear in single-phase faults of DC-side transmission lines, 9 misdiagnosis data appear in faults of converter valve arms, 11 misdiagnosis data appear in faults of converter valve groups, and 8 misdiagnosis data appear in phase-to-phase faults of DC-side transmission lines. From the results of the SVM method in
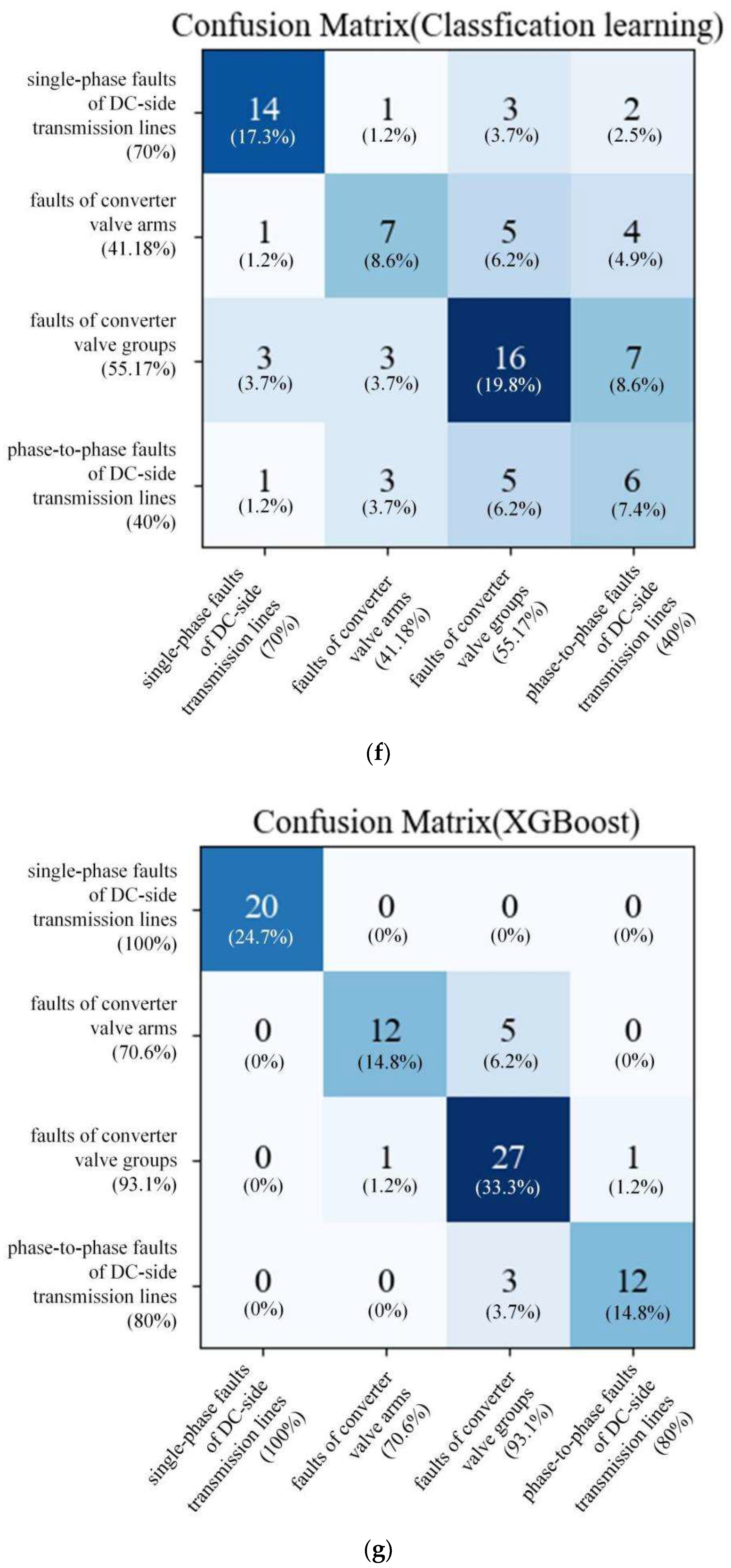
Figure 12f, 6 misdiagnosis data appear in single-phase faults of DC-side transmission lines, 10 misdiagnosis data appear in faults of converter valve arms, 13 misdiagnosis data appear in faults of converter valve groups, and 9 misdiagnosis data appear in phase-to-phase faults of DC-side transmission lines. Lastly, for the results of the XGBoost method in
Figure 12g, 0 misdiagnosis data appear in single-phase faults of DC-side transmission lines, 5 misdiagnosis data appear in faults of converter valve arms, 2 misdiagnosis data appear in faults of converter valve groups, and 3 misdiagnosis data appear in phase-to-phase faults of DC-side transmission lines.
The parameters of the seven methods were optimized, and the results showed that the diagnostic accuracy of the LSTM method is 95.06%.
Because RNN is prone to gradient disappearance, it cannot process a long input sequence, so traditional RNN easily forgets the information of the previous relatively distant period, resulting in the failure of training accuracy convergence. This limits the use of RNN to a large extent. Therefore, the diagnostic accuracy of the RNN method is limited to 66.67%, and it is difficult to improve the diagnostic accuracy.
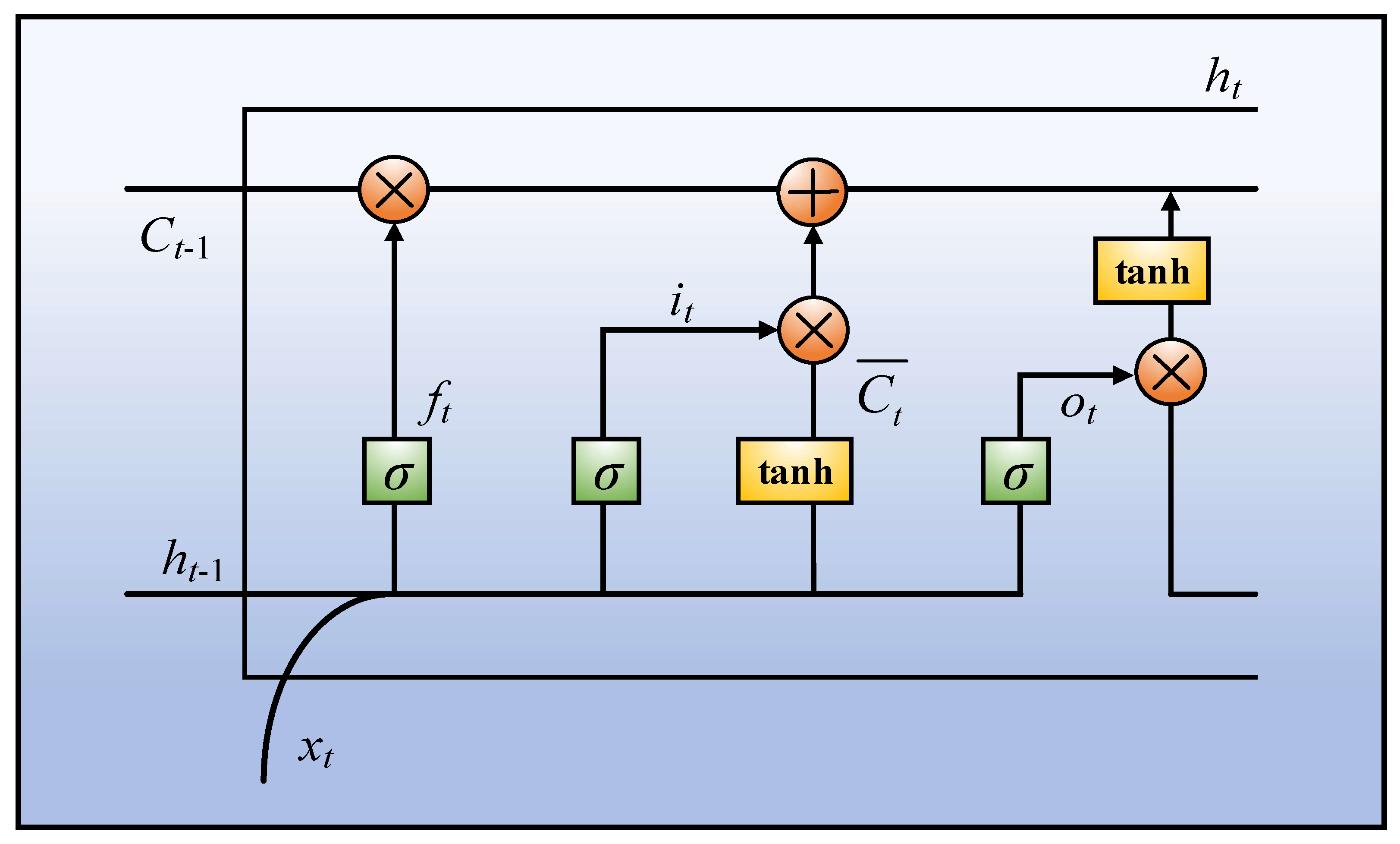
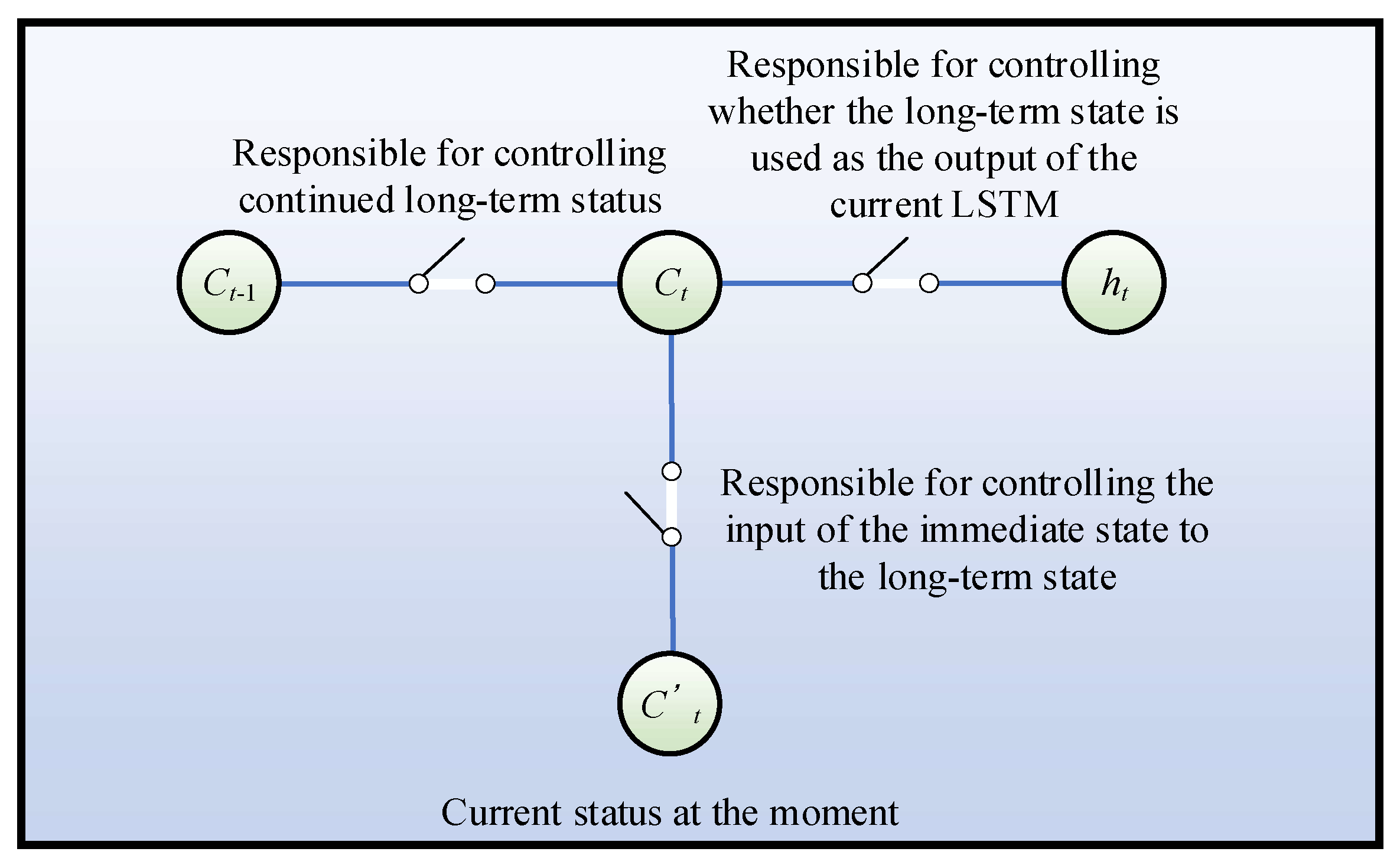
LSTM corrects the traditional RNN by designing a gated unit, solves the problem of long-term dependence common in general cyclic neural networks, and enables information to be transmitted and expressed flexibly in a long time series, without causing useful information from long ago to be forgotten, which is suitable for modeling sequential data. At the same time, the proposed fault diagnosis method based on the LSTM model does not require feature extraction and screening, which not only reduces the difficulty of using machine learning for fault diagnosis training, but also avoids fault prediction caused by improper feature selection.
The accuracy of XGBoost, SVM, Naive Bayes, PNN, and CL is 87.65%, 91.36%, 88.89%, 46.91%, and 53.07%, respectively, but it is still lower than that of the LSTM method. Therefore, this paper puts forward the advanced fault diagnosis method of HVDC systems.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}