7.2. Result Analysis
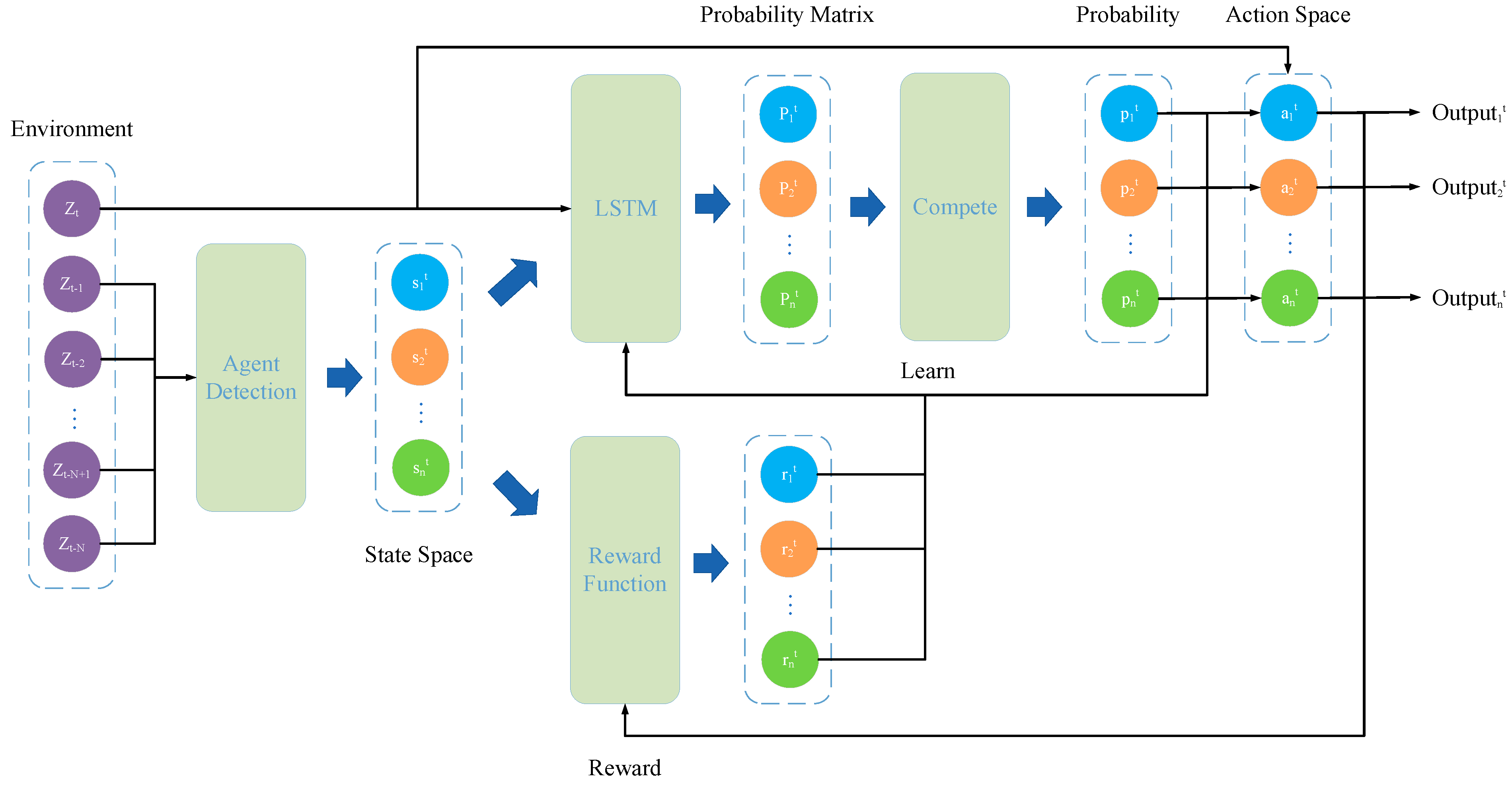
The whole experiment is divided into the single-target data association learning process and the multi-target data association testing process. The movement time of target is 30 s in the single-target data association learning process. The number of data in the training set is 5 groups. The measurement error is , and each measurement error corresponds to one group of data. Each group has 10000 data, and the clutter parameter is randomly selected from 0 to 90. The motion model of each track consists of any combination of the CV model, CA model, and CT model. The number of data in the testing set also is 5 groups. The measurement error is , and each measurement error corresponds to one group of data. Each group has 100 data. The clutter parameter is , and each clutter parameter has 10 data. The motion model of each track consists of any combination of CV model, CA model, and CT model.
After the test, the association accuracy can be calculated by comparing the test results with the true points originating from the target, namely ( represents the number of true points originating from the target in the association result of agent, and represents the number of real points originating from the target, here ). After the test, the average association accuracy can be calculated, namely ( represents the amount of data in the test set, here ). The experimental results of test are shown in Algorithm 1.
As shown in the
Table 1, the average association accuracy is inversely proportional to measurement error and clutter parameters in terms of the general trend, and the values of
are affected by both. However, the value of
exceeds 80% in all cases, and there are only a few cases where the value of
is below 90%. Therefore, the test results of single-target learning process are relatively good and can basically assist in implementing the multi-target data association process.
The movement time of the target is 30 s in the multi-target data association testing process. The number of data in the testing set is 5 groups. The measurement error is
, and each measurement error corresponds to one group of data. Each group has 10 data, and the clutter parameter is
. The motion model of each track consists of any combination of
CV model,
CA model, CT1 model, CT2 model, and CT3 model.
Figure 7 is the real track where target 5 appears suddenly at the fifth sampling interval. The state transition matrix and process noise distribution matrix of
CV model and
CA model are unchanged, namely
,
,
, and
. However,
and
of the CT model are also basically unchanged; only
in
changes, and the corresponding relationship is
Here, set the abbreviation of the algorithm in this paper as TDA.
Figure 8,
Figure 9,
Figure 10,
Figure 11 and
Figure 12 show the measurement and association result of TDA at
,
,
,
, and
, respectively. In the figure of measurement, the blue dots are measurements, and Target 1–Target 5 are the real points originating from the target. In the figure of association as result of TDA, the red dots are the real points originating from the target, and the green lines are the association track.
As shown in the following figure, when two targets have similar motion trends, close spatial distances, and close locations of real points for consecutive moments, there may be the “wrong selection”, and the agent may choose to associate the clutter if the real measurement at the next moment is close to the spatial location of the clutter. However, from the association results, these problems do not affect the association process in the subsequent moments and have the minimal impact on the whole process. There are two reasons to guarantee the performance of TDA. First, the fundamental method of TDA to achieve multi-target data association is to select the point that best matches the target motion trend from the next moment of measurement based on the motion trend of consecutive moments. An incorrectly associated point has less impact on this track, much less on the whole association process. Second, if the association process is interrupted due to the wrong association of some points, TDA can correct the error in time through the Adaptive Adjustment Mechanism to ensure the accuracy of association results. So, TDA can basically accurately associate to the points originating from the targets, and there are no problems of association interruptions, missed targets, and incorrect associations. It can effectively solve the data association problem of multiple targets.
In order to evaluate the performance of the algorithm more conveniently, several metrics are proposed in this paper. Assuming that the number of real points originating from the target is
, the number of all points in the measurement data is
, and the number of all real points originating from the target in the association result of agent is
, the average overall association accuracy
is
The average association accuracy
is
The average accuracy of association results for each agent is
. Assuming that the association result of an agent corresponds to the track of a real target, if the number of real points originating from the target in the association result is
, and the number of real points originating from the target is
, then
Set the number of targets in the association result to .
Table 2,
Table 3,
Table 4,
Table 5,
Table 6 and
Table 7 show the performance of TDA when
and
. Monte Carlo simulation is 100 times.
Table 2 and
Table 3 show the change of
and
, respectively. As can be seen from the figure, when
is larger,
is more affected by clutter. As
gets bigger,
gets smaller. However, the lowest of
remains at 0.95, which shows the validity of association results.
Table 4 and
Table 5 show the change of
and
, respectively. As shown in the figure, when
is larger,
is more affected by clutter. As
gets bigger,
gets smaller. However, the lowest of
is 0.96. So, the
is high and stable.
Table 6 and
Table 7 show the change of
and
, respectively. As can be seen from the table,
is stable at about 0.9, which is slightly affected by clutter and has good association performance. However, combined with
and
,
decreases with the increase in
. This indicates that there may be a little crossover, aliasing, and other phenomena in the association tracks when the target is moving in parallel or hedging. However, the decrease in
is not large, which proves that the association performance is still very good. The
is stable. It is only at
that a large error occurs, and
is only 6. This indicates that there are few interruptions in the association track.
The performance of this algorithm can be verified by combining the data in
Table 2,
Table 3,
Table 4,
Table 5,
Table 6 and
Table 7. First, the Adaptive Adjustment Mechanism plays the positive role to ensure the continuity of association track. Second, TDA can basically learn the real motion trend of the target, which ensures the accuracy of association results. Third, the agent detection mechanism can detect new targets that appear suddenly in the environment in time. Even if the association process is interrupted, it can still find the target and restart the association in the subsequent association process. In summary, although the performance of TDA decreases when
and
increase, the results show that the performance of TDA decreases insignificantly, and the validity of association results can still be guaranteed. It is also proved that TDA can effectively handle the problems of data association for strongly maneuvering targets, even when multiple targets doing special maneuvers are also unaffected. Moreover, TDA does not require any impractical prerequisites and meets the requirements for solving practical problems.
In this paper, the TDA algorithm is compared with the JPDAF algorithm, MHTF algorithm, Fuzzy C-Means Clustering Filter (FCMF) algorithm [
29], and Generalized Multi-Bernoulli Filter (GLMBF) algorithm [
30]. Considering that most targets are maneuvering in the environment, the IMM model is added to the original algorithm, namely IMM-JPDAF algorithm, IMM-MHTF algorithm, IMM-FCMF algorithm, and IMM-GLMB algorithm. In the following, the four algorithms are described by their abbreviations, namely JPDA, MHT, FCM, and GLMB. Given the shortcomings of the four algorithms, it is necessary to assume that the initial position, motion model, and starting time of all target are known during the experiment. However, the TDA algorithm does not have this priori information.
Table 8,
Table 9,
Table 10,
Table 11,
Table 12 and
Table 13 show the performance comparison of five algorithms when
.
Table 8 and
Table 9 show the performance comparison of
and
, respectively. As can be seen from the table, the
of TDA, MHT, and FCM is relatively stable, and the
of TDA is the highest.
Table 10 and
Table 11 show the performance comparison of
and
, respectively. As shown in the table, the
of TDA and FCM is high and stable. FCM is based on the principle of “one target corresponds to one measurement”, and the number of targets is assumed to be known, so
is higher. MHT adopts the principle of “target: measurement = 1: N”. JPDA is greatly affected by clutter.
increases as clutter density increases, and
decreases for both MHT and JPDA. GLMB is slightly affected by clutter, and its performance is stable. However, there are so many cases of incorrect association in the association process that make
of GLMB very low.
Table 12 and
Table 13 show the performance comparison of
and
, respectively. As can be seen from the table, JPDA and FCM assume that the number of targets is known;
of TDA is the most accurate, followed by MHT. Compared with the
of other algorithms, the difference of GLMB is larger, and there are clearly too many interruptions of association. Combined with
and
, the performance difference between FCM and TDA is not significant. However, according to
, the association performance of TDA is better. Obviously, when the targets do parallel motion or hedging motion, there are track crossings and track blending in the association results of FCM. The
of JPDA is determined by
,
,
, and other factors. The
is known, and the
is significantly higher than other algorithms, which makes the
small. So the
are all 0.
In summary, when , the association performance of TDA is the best, followed by FCM, MHT, JPDA, and GLMB. When solving practical problems, the algorithm complexity is high, and the algorithm performance is not necessarily good. The complexity of GLMB is obviously higher than other algorithms, but its association results are not satisfactory. JPDA and MHT are affected by clutter, and their performance is unstable. FCM is difficult to deal with strong maneuvering targets effectively. Especially, when multiple targets perform special maneuvers, the performance of FCM algorithm will be affected. Moreover, FCM, MHT, JPDA, and GLMB require many assumptions, such as target motion model, the number of targets, and other information that is impossible to know when solving the practical problem. Compared with FCM, MHT, JPDA, and GLMB, TDA does not require assuming any unpredictable information as the priori information. It can also utilize the learning network to process the data quickly and efficiently and reduce the complexity of algorithm. Moreover, TDA provides solutions to various problems that may exist in the process of multi-target data association and ensures the accuracy of association results. Based on RL technology, TDA creates a new multi-target data association architecture, which breaks all the limitations of traditional data association algorithms and significantly improves the association accuracy. It has certain practical application value.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}