
Recognition of Children’s Facial Expressions Using Deep Learned Features

 ,
,  ,
, 
Abstract
:1. Introduction
2. Related Work
Child FER Datasets
3. Materials and Methods
3.1. LIRIS-CSE Dataset
3.2. Pre-Processing
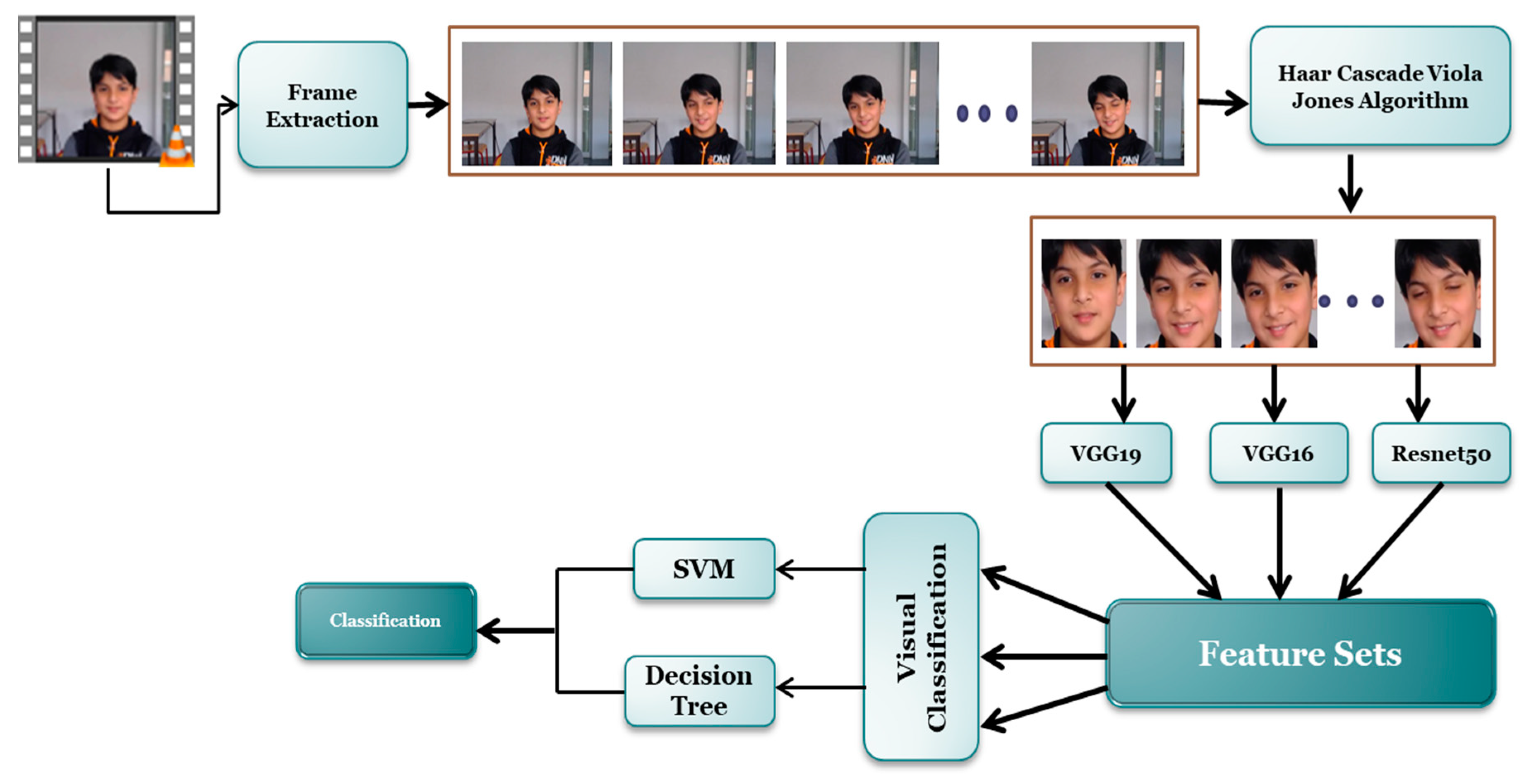
3.2.1. Image-Based Approach
3.2.2. Video-Based Approach
3.3. Feature Extraction
3.4. Classification
- Support Vector Machine
- 2.
- Decision Tree
4. Experimental Results
4.1. Image-Based Results
4.1.1. 80–20% Split
4.1.2. K-Fold Cross-Validation
4.2. Video-Based Results
4.2.1. 80–20% Split
4.2.2. K-Fold Cross-Validation
4.2.3. Leave One Out Cross-Validation
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Khan, R.A.; Crenn, A.; Meyer, A.; Bouakaz, S. A novel database of children’s spontaneous facial expressions (LIRIS-CSE). Image Vis. Comput. 2019, 83, 61–69. [Google Scholar] [CrossRef]
- Pantic, M.; Pentland, A.; Nijholt, A.; Huang, T.S. Human computing and machine understanding of human behavior: A survey. In Artifical Intelligence for Human Computing; Springer: Berlin/Heidelberg, Germany, 2007; pp. 47–71. [Google Scholar]
- Ravi, A. Pre-trained convolutional neural network features for facial expression recognition. arXiv 2018, arXiv:1812.06387. [Google Scholar]
- Bibbo’, L.; Cotroneo, F.; Vellasco, M. Emotional Health Detection in HAR: New Approach Using Ensemble SNN. Appl. Sci. 2023, 13, 3259. [Google Scholar] [CrossRef]
- Zahid, Z.; Shaukat, A.; Khan, R.A.; Akram, U.; Byun, Y.C. Emotion Recognition in Video Clips Using Simple and Extended Center Symmetric LBP. In Proceedings of the 2019 IEEE Transportation Electrification Conference and Expo, Asia-Pacific (ITEC Asia-Pacific), Seogwipo, Republic of Korea, 8–10 May 2019; IEEE: Manhattan, NY, USA, 2019; pp. 1–6. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ding, S.F.; Qi, B.J.; Tan, H.Y. An overview on theory and algorithm of support vector machines. J. Univ. Electron. Sci. Technol. China 2011, 40, 2–10. [Google Scholar]
- Tian, Y.; Shi, Y.; Liu, X. Recent advances on support vector machines research. Technol. Econ. Dev. Econ. 2012, 18, 5–33. [Google Scholar] [CrossRef]
- Song, Y.Y.; Ying, L.U. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry 2015, 27, 130. [Google Scholar]
- Liu, H.; Cocea, M.; Ding, W. Decision tree learning based feature evaluation and selection for image classification. In Proceedings of the 2017 International Conference on Machine Learning and Cybernetics (ICMLC), Ningbo, China, 9–12 July 2017; IEEE: Manhattan, NY, USA, 2017; Volume 2, pp. 569–574. [Google Scholar]
- Cervantes, J.; Li, X.; Yu, W.; Li, K. Support vector machine classification for large data sets via minimum enclosing ball clustering. Neurocomputing 2008, 71, 611–619. [Google Scholar] [CrossRef]
- Pantic, M. Machine analysis of facial behaviour: Naturalistic and dynamic behaviour. Philos. Trans. R. Soc. B Biol. Sci. 2009, 364, 3505–3513. [Google Scholar] [CrossRef] [PubMed]
- Ko, B.C. A brief review of facial emotion recognition based on visual information. Sensors 2018, 18, 401. [Google Scholar] [CrossRef] [PubMed]
- Ekman, P.; Friesen, W.V. A new pan-cultural facial expression of emotion. Motiv. Emot. 1986, 10, 159–168. [Google Scholar] [CrossRef]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; IEEE: Manhattan, NY, USA, 2010; pp. 94–101. [Google Scholar]
- Pantic, M.; Valstar, M.; Rademaker, R.; Maat, L. Web-based database for facial expression analysis. In Proceedings of the 2005 IEEE International Conference on Multimedia and Expo, Amsterdam, The Netherlands, 6–9 July 2005; IEEE: Manhattan, NY, USA, 2005; p. 5. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Egger, H.L.; Pine, D.S.; Nelson, E.; Leibenluft, E.; Ernst, M.; Towbin, K.E.; Angold, A. The NIMH Child Emotional Faces Picture Set (NIMH-ChEFS): A new set of children’s facial emotion stimuli. Int. J. Methods Psychiatr. Res. 2011, 20, 145–156. [Google Scholar] [CrossRef]
- Dalrymple, K.A.; Gomez, J.; Duchaine, B. The Dartmouth Database of Children’s Faces: Acquisition and validation of a new face stimulus set. PLoS ONE 2013, 8, e79131. [Google Scholar] [CrossRef]
- LoBue, V.; Thrasher, C. The Child Affective Facial Expression (CAFE) set: Validity and reliability from untrained adults. Front. Psychol. 2015, 5, 1532. [Google Scholar] [CrossRef]
- Langner, O.; Dotsch, R.; Bijlstra, G.; Wigboldus, D.H.; Hawk, S.T.; Van Knippenberg, A.D. Presentation and validation of the Radboud Faces Database. Cogn. Emot. 2010, 24, 1377–1388. [Google Scholar] [CrossRef]
- Nojavanasghari, B.; Baltrušaitis, T.; Hughes, C.E.; Morency, L.P. Emoreact: A multimodal approach and dataset for recognizing emotional responses in children. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo Japan, 12–16 November 2016; pp. 137–144. [Google Scholar]
- Dapogny, A.; Grossard, C.; Hun, S.; Serret, S.; Grynszpan, O.; Dubuisson, S.; Cohen, D.; Bailly, K. On Automatically Assessing Children’s Facial Expressions Quality: A Study, Database, and Protocol. Front. Comput. Sci. 2019, 1, 5. [Google Scholar] [CrossRef]
- Uddin, M.A.; Joolee, J.B.; Sohn, K.A. Dynamic Facial Expression Understanding Using Deep Spatiotemporal LDSP On Spark. IEEE Access 2021, 9, 16866–16877. [Google Scholar] [CrossRef]
- Florea, C.; Florea, L.; Badea, M.A.; Vertan, C. Annealed label transfer for face expression recognition. In Proceedings of the British Machine Vision Conference (BMVC), Cardiff, UK, 9–12 September 2019. [Google Scholar]
- Zhao, Y.; Xu, K.; Wang, H.; Li, B.; Qiao, M.; Shi, H. MEC-Enabled Hierarchical Emotion Recognition and Perturbation-Aware Defense in Smart Cities. IEEE Internet Things J. 2021, 8, 16933–16945. [Google Scholar] [CrossRef]
- Lopez-Rincon, A. Emotion recognition using facial expressions in children using the NAO Robot. In Proceedings of the 2019 International Conference on Electronics, Communications and Computers (CONIELECOMP), Cholula, Mexico, 27 February–1 March 2019; IEEE: Manhattan, NY, USA, 2019; pp. 146–153. [Google Scholar]
- Yu, G. Emotion Monitoring for Preschool Children Based on Face Recognition and Emotion Recognition Algorithms. Complexity 2021, 2021, 6654455. [Google Scholar] [CrossRef]
- Wang, W.; Xu, K.; Niu, H.; Miao, X. Emotion Recognition of Students Based on Facial Expressions in Online Education Based on the Perspective of Computer Simulation. Complexity 2020, 2020, 4065207. [Google Scholar] [CrossRef]
- Witherow, M.A.; Samad, M.D.; Iftekharuddin, K.M. Transfer learning approach to multiclass classification of child facial expressions. In Proceedings of the Applications of Machine Learning, Long Beach, CA, USA, 9–15 June 2019; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 11139, p. 1113911. [Google Scholar]
- Farzaneh, A.H.; Kim, Y.; Zhou, M.; Qi, X. Developing a deep learning-based affect recognition system for young children. In Proceedings of the International Conference on Artificial Intelligence in Education, Chicago, IL, USA, 25–29 June 2019; Springer: Cham, Switzerland; pp. 73–78. [Google Scholar]
- Awatramani, J.; Hasteer, N. Facial Expression Recognition using Deep Learning for Children with Autism Spectrum Disorder. In Proceedings of the 2020 IEEE 5th International Conference on Computing Communication and Automation (ICCCA), Greater Noida, India, 30–31 October 2020; IEEE: Manhattan, NY, USA, 2020; pp. 35–39. [Google Scholar]
- Lin, Q.; He, R.; Jiang, P. Feature Guided CNN for Baby’s Facial Expression Recognition. Complexity 2020, 2020, 8855885. [Google Scholar] [CrossRef]
- Shaheen, F.; Verma, B.; Asafuddoula, M. Impact of automatic feature extraction in deep learning architecture. In Proceedings of the 2016 International conference on digital image computing: Techniques and Applications (DICTA), Goldcoast, Australia, 30 November–2 December 2016; IEEE: Manhattan, NY, USA, 2016; pp. 1–8. [Google Scholar]
- Li, B.; Lima, D. Facial expression recognition via ResNet-50. Int. J. Cogn. Comput. Eng. 2021, 2, 57–64. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Cuimei, L.; Zhiliang, Q.; Nan, J.; Jianhua, W. Human face detection algorithm via Haar cascade classifier combined with three additional classifiers. In Proceedings of the 2017 13th IEEE International Conference on Electronic Measurement & Instruments (ICEMI), Harbin, China, 9–11 August 2017; IEEE: Manhattan, NY, USA, 2017; pp. 483–487. [Google Scholar]
- Ramalingam, S.; Garzia, F. Facial expression recognition using transfer learning. In Proceedings of the 2018 International Carnahan Conference on Security Technology (ICCST), Montreal, QC, Canada, 22–25 October; IEEE: Manhattan, NY, USA, 2018; pp. 1–5. [Google Scholar]
- Tammina, S. Transfer learning using vgg-16 with deep convolutional neural network for classifying images. Int. J. Sci. Res. Public 2019, 9, 143–150. [Google Scholar] [CrossRef]
- Akhand, M.A.H.; Roy, S.; Siddique, N.; Kamal, M.A.S.; Shimamura, T. Facial Emotion Recognition Using Transfer Learning in the Deep CNN. Electronics 2021, 10, 1036. [Google Scholar] [CrossRef]
- Scherer, D.; Müller, A.; Behnke, S. Evaluation of pooling operations in convolutional architectures for object recognition. In Proceedings of the International Conference on Artificial Neural Networks, Thessaloniki, Greece, 15–18 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 92–101. [Google Scholar]
- Agarap, A.F. An architecture combining convolutional neural network (CNN) and support vector machine (SVM) for image classification. arXiv 2017, arXiv:1712.03541. [Google Scholar]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Myles, A.J.; Feudale, R.N.; Liu, Y.; Woody, N.A.; Brown, S.D. An introduction to decision tree modeling. J. Chemom. A J. Chemom. Soc. 2004, 18, 275–285. [Google Scholar] [CrossRef]
- Khan, R.A.; Meyer, A.; Bouakaz, S. Automatic affect analysis: From children to adults. In Proceedings of the Advances in Visual Computing: 11th International Symposium, ISVC 2015, Las Vegas, NV, USA, 14–16 December 2015; Springer International Publishing: Berlin/Heidelberg, Germany, 2015. Part II 11. pp. 304–313. [Google Scholar]
- Farkhod, A.; Abdusalomov, A.B.; Mukhiddinov, M.; Cho, Y.I. Development of Real-Time Landmark-Based Emotion Recognition CNN for Masked Faces. Sensors 2022, 22, 8704. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
| Task | Explanation |
|---|---|
| Classification | A pre-trained network can be used directly for a classification task. The network will return a predicted label and class probabilities of the test image after classification. |
| Feature Extraction | A pre-trained network can be used as a feature extractor. These features can then be used to train a classifier such as SVM or Decision Tree to learn a new task. |
| Transfer Learning | The layers of a pre-trained network can be fine-tuned on a new/smaller dataset to solve—a different classification problem. Fine-tuning a network is very useful approach, as it is much cheaper and a faster option compared with training a network initially from scratch. |
| Sr. No. | Recording Conditions | Age | Gender |
|---|---|---|---|
| S1 | Controlled | 9 | M |
| S2 | Controlled | 5 | M |
| S3 | Controlled | 6 | M |
| S4 | Controlled | 10 | F |
| S5 | Controlled | 12 | F |
| S6 | Controlled | 7 | F |
| S7 | Controlled | 6 | M |
| S8 | Home | 4 | F |
| S9 | Home | 7 | F |
| S10 | Home | 7 | F |
| S11 | Home | 8 | F |
| S12 | Home | 7 | M |
| Network | Layer | Type | FV Size | No of Parameters |
|---|---|---|---|---|
| VGG16 | fc7 | Fully Connected | 4096 | Weights: 4096 × 4096 Biases: 4096 × 1 |
| 16,781,312 | ||||
| VGG19 | fc8 | Fully Connected | 1000 | Weights: 1000 × 4096 Biases: 1000 × 1 |
| 4,097,000 | ||||
| ResNet50 | fc1000 | Fully Connected | 1000 | Weights: 1000 × 2048 Biases: 1000 × 1 |
| 2,049,000 |
| Image-Based Approach | Setup 1 | Setup 2 | |
|---|---|---|---|
| Feature Extractor | Classifier | 80–20% Split | K-Fold CV |
| VGG16 | SVM | 99.9% | 99.8% |
| Decision Tree | 97.8% | 94.8% | |
| VGG19 | SVM | 99.5% | 99.0% |
| Decision Tree | 97.5% | 94.2% | |
| Resnet50 | SVM | 99.8% | 99.5% |
| Decision Tree | 96.9% | 93.2% | |
| Video-Based Approach | Setup 1 | Setup 2 | Setup 3 | |
|---|---|---|---|---|
| Feature Extractor | Classifier | 80–20% Split | K-Fold CV | LOOCV |
| VGG16 | SVM | 55% | 69% | 91% |
| Decision Tree | 52% | 65% | 89% | |
| VGG19 | SVM | 57% | 73% | 94% |
| Decision Tree | 47% | 64% | 91% | |
| Resnet50 | SVM | 55% | 71% | 93% |
| Decision Tree | 45% | 63% | 88% | |
| Disgust | Fear | Happy | Sad | Surprise | |
|---|---|---|---|---|---|
| Disgust | 167 | 0 | 0 | 0 | 0 |
| Fear | 0 | 709 | 0 | 0 | 0 |
| Happy | 0 | 0 | 1253 | 0 | 3 |
| Sad | 0 | 0 | 0 | 813 | 0 |
| Surprise | 0 | 1 | 0 | 0 | 911 |
| Disgust | Fear | Happy | Sad | Surprise | |
|---|---|---|---|---|---|
| Disgust | 819 | 0 | 2 | 0 | 0 |
| Fear | 0 | 3495 | 4 | 0 | 5 |
| Happy | 0 | 0 | 6302 | 1 | 6 |
| Sad | 0 | 0 | 1 | 4082 | 4 |
| Surprise | 0 | 4 | 7 | 2 | 4539 |
| Disgust | Fear | Happy | Sad | Surprise | |
|---|---|---|---|---|---|
| Disgust | 7 | 0 | 1 | 0 | 1 |
| Fear | 1 | 28 | 1 | 0 | 3 |
| Happy | 0 | 0 | 62 | 0 | 0 |
| Sad | 0 | 0 | 0 | 29 | 0 |
| Surprise | 0 | 1 | 3 | 0 | 48 |
| Author | Technique | Visual Recognition Rate |
|---|---|---|
| Khan et al. [1] | Transfer learning
|
|
| Uddin et al. [26] |
|
|
| Zhao et al. [28] |
|
|
| Proposed method | Feature extraction
| Image-based classification (max)
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Laraib, U.; Shaukat, A.; Khan, R.A.; Mustansar, Z.; Akram, M.U.; Asgher, U. Recognition of Children’s Facial Expressions Using Deep Learned Features. Electronics 2023, 12, 2416. https://doi.org/10.3390/electronics12112416
Laraib U, Shaukat A, Khan RA, Mustansar Z, Akram MU, Asgher U. Recognition of Children’s Facial Expressions Using Deep Learned Features. Electronics. 2023; 12(11):2416. https://doi.org/10.3390/electronics12112416
Chicago/Turabian StyleLaraib, Unqua, Arslan Shaukat, Rizwan Ahmed Khan, Zartasha Mustansar, Muhammad Usman Akram, and Umer Asgher. 2023. "Recognition of Children’s Facial Expressions Using Deep Learned Features" Electronics 12, no. 11: 2416. https://doi.org/10.3390/electronics12112416
APA StyleLaraib, U., Shaukat, A., Khan, R. A., Mustansar, Z., Akram, M. U., & Asgher, U. (2023). Recognition of Children’s Facial Expressions Using Deep Learned Features. Electronics, 12(11), 2416. https://doi.org/10.3390/electronics12112416